



タブレット スタンド 【2024最新型 4つの関節を採用安定で揺れない】 タブレット アーム スタンド スマホスタンド ipadスタンド ipad アーム 横/縱き ベッドサイド 寝ながら ベッド用 360回転 スマホ スタンド/ホルダー 4〜13インチ for iPhone&Android&iPad&Kindle &N-Switch、android surface 多機種対応日本語取扱説明書
¥2,026 (2025年5月5日 13:15 GMT +09:00 時点 - 詳細はこちら価格および発送可能時期は表示された日付/時刻の時点のものであり、変更される場合があります。本商品の購入においては、購入の時点で当該の Amazon サイトに表示されている価格および発送可能時期の情報が適用されます。)
【2024新安定版】 SDカードリーダー type-c メモリカードリーダー 3in1 USB/SD/TF変換アダプタ 0TG機能 設定不要 写真/ビデオ 高速伝送 双方向転送 カメラリーダー iPhone15/タイプC スマホ/MacBook/PC/Galaxy/Android/Type-Cなど機器に適用
¥1,599 (2025年5月5日 13:15 GMT +09:00 時点 - 詳細はこちら価格および発送可能時期は表示された日付/時刻の時点のものであり、変更される場合があります。本商品の購入においては、購入の時点で当該の Amazon サイトに表示されている価格および発送可能時期の情報が適用されます。)
この記事は2025年5月時点のSnowflake Cortexの最新状況を踏まえたCOMPLETE関数について私自身が学んだ結果をハンズオン形式でまとめた解説記事です。プログラミングに詳しくない方でもSQLの知識だけでLLM機能を活用する方法を学べるようになっています。
と偉そうな入り方をしましたが、私自身がそもそもプログラミングが苦手なデータエンジニアです。Python、TypeScript…そんな単語を聞くだけで緊張してしまう典型的なSQLエンジニアです。
最近のAIの流行に対して、概念的な事はある程度理解しつつも自分自身では手を動かして実装したことがなく、AIエンジニア、データサイエンティストにお任せするしかないと言った状況で、そういう自分自身をもどかしく思うようになってきました。
そんな時、SnowVillage unconference 第五回で、Snowflake Data Superheroesの喜田さんのLTでSnowflake CortexのCOMPLETE関数の存在を知りました。そのLTの内容や質疑応答を通じて、SQLだけでLLMが使える事の価値を改めて知り、「これなら私にもできるかも!」と一歩を踏み出しました。そんな私のチャレンジをまとめたこの記事は、同じく「AIは専門家の領域」と諦めかけていた方々への、小さな希望の灯火になれば幸いです。
SnowVillageのUnConference第五回イベント
エクスチュア 喜田さんの最新ブログはこちら
Snowflake Cortexとは:AIへの新しいアプローチ
改めて解説を始めますと、Snowflake Cortexは、SQLやPythonを通じて最先端の大規模言語モデル(LLM)やAI機能にアクセスできるフルマネージド型サービスです。これにより、データエンジニアやアナリストは複雑なインフラ構築やMLOpsの知識なしに、高度なAI機能を活用できるようになりました。
Cortexの最大の特徴は、データがSnowflake内に留まったまま処理されることで、セキュリティとレスポンス速度を両立している点です。従来のAI導入では、データを外部のAIサービスに送信する必要があり、セキュリティやレイテンシーの懸念がありましたが、Cortexではこれらの問題を解決しています。
なぜSQLでのLLM活用が重要か
さて、多くのデータプロフェッショナルにとって、SQLは日常的に使用するツールです。一方、Python等のプログラミング言語の習得には時間がかかります。そんななか、Snowflake Cortexの素晴らしい点は、SQLの知識だけで最新のLLMを活用できることにあります。(今回の記事を書く動機もほぼその一点にあります!)
SQLでのLLM活用には以下のメリットがあります
- 学習コストの低減(SQLを既に知っていれば、追加の言語学習不要)
- 既存のETLパイプラインへの統合が容易
- チーム間のコラボレーションしやすい(SQLはデータチーム共通の言語)
- 本番環境への展開が迅速
そのSnowflake Cortexの中心となるのがCOMPLETE関数です。この関数を使うと、LLMにプロンプトを送信し、生成された回答を取得できます。
基本的な使い方
最もシンプルな使い方は以下の通りです。
SELECT SNOWFLAKE.CORTEX.COMPLETE('snowflake-arctic', 'データ分析の重要なトレンドを3つ教えてください');
この例では、’snowflake-arctic’というモデルを使用して、プロンプトに対する回答を生成しています。
基本的な権限周り
これらのCortex関数を利用するためには以下のような権限設定が必要です。
GRANT EXECUTE FUNCTION ON FUNCTION SNOWFLAKE.CORTEX.COMPLETE(VARCHAR, VARCHAR) TO ROLE MY_ROLE;
GRANT EXECUTE FUNCTION ON FUNCTION SNOWFLAKE.CORTEX.COMPLETE(VARCHAR, ARRAY, OBJECT) TO ROLE MY_ROLE;
GRANT EXECUTE FUNCTION ON FUNCTION SNOWFLAKE.CORTEX.SENTIMENT(VARCHAR) TO ROLE MY_ROLE;
注意:クロスリージョン推論について
またCortexで利用出来るモデルについてはリージョンの制約があるモデルがあります。
そのため、以下のようなエラーが出た場合、他リージョンで実行可能なモデルを呼び出すための権限付与が必要となります。
また海外のリージョンへのデータ転送について、データの種別や利用目的によっては制限を掛けるべきケースもありますので、特に個人情報に関わるデータについては自社内で十分に確認を行いましょう。

最初のころ、クロスリージョン知らなくてアホみたいにエラー出したよ・・
ALTER ACCOUNT SET CORTEX_ENABLED_CROSS_REGION = 'AWS_US';
ALTER ACCOUNT SET CORTEX_ENABLED_CROSS_REGION = 'DISABLED';
SHOW FUNCTIONS LIKE 'cortex.complete%';
サポートされている主なモデル
2025年5月現在、以下のモデルが利用可能です。
-
snowflake-arctic(Snowflakeが開発したエンタープライズ向けモデル) -
llama3.1-8b、llama3.1-70b、llama3.1-405b(Meta AI製) -
llama3.3-70b、llama4-maverick(最新のMeta AIモデル) -
mistral-large、mistral-large2、mistral-7b -
claude-3-5-sonnet(Anthropic製) - その他多数
それぞれのモデルには特徴があり、タスクや要件に応じて選択できます。
推奨されるウェアハウス
Snowflake Cortex LLM関数、Cortex LLM Playground等のUI利用時ともに以下が推奨のようです。
・SMALL もしくは MEDIUM
・大きなウェアハウスを使っても性能向上が見込めず、コスト増となるため
Snowflake Cortex 機能一覧(2025年5月時点)
さて、本題に入る前にCortexの機能について一通り理解しておきたいと思います。ここ一年でかなりの機能追加やアップデートがあり、全体像が分かりづらい状況です。
汎用LLM関数であるCOMPLETE関数以外にも目的特化型のタスク固有関数とそれらをサービス化したCortexサービス(Analyst、Search、Agents)に分類されると考えています。
| 機能カテゴリ | 機能名 | 目的・特徴 | リリース・アップデート |
|---|---|---|---|
| 汎用AI関数 | COMPLETE | プロンプトエンジニアリングによる高度なカスタマイズが可能な汎用LLM処理。チャット、構造化出力、画像分析も対応。複雑な推論や特殊なビジネスロジックに最適。 | 2024年3月:リリース2025年2月:構造化出力2025年4月:マルチモーダル対応 |
| タスク固有関数 | SENTIMENT | テキストから-1~1の感情スコアを抽出。レビューやSNSの感情分析に最適。 | 2024年3月:リリース |
| タスク固有関数 | SUMMARIZE | テキスト要約を自動生成。長文やレポートの要点抽出に特化。 | 2024年3月:リリース |
| タスク固有関数 | TRANSLATE | 言語間翻訳を実行。多言語データ処理や国際展開に活用。 | 2024年3月:リリース2024年11月:多言語・長文対応 |
| タスク固有関数 | CLASSIFY_TEXT | 定義したカテゴリにテキスト分類。文書分類やスパム検出に。 | 2024年3月:リリース |
| タスク固有関数 | EXTRACT_ANSWER | 非構造化データから質問の回答を抽出。FAQやドキュメント検索に。 | 2024年3月:リリース |
| タスク固有関数 | PARSE_DOCUMENT | OCRやレイアウト分析で文書内容を抽出・解析。契約書やレポート処理に。 | 2024年3月:リリース |
| タスク固有関数 | EMBED_TEXT_768 | 768次元のテキスト埋め込みベクトル生成。セマンティック検索や類似度分析に。 | 2024年3月:リリース |
| タスク固有関数 | EMBED_TEXT_1024 | 1024次元のテキスト埋め込みベクトル生成。より高精度な検索や分析に。 | 2024年3月:リリース |
| ヘルパー関数 | COUNT_TOKENS | 入力テキストのトークン数をカウント。コスト見積もりや入力制限確認に。 | 2024年3月:リリース |
| ヘルパー関数 | TRY_COMPLETE | エラー時にNULL返却し処理継続。バッチ処理や大量データ分析の安定性向上。 | 2024年3月:リリース |
| 高度AI分析機能 | Cortex Analyst | 自然言語でデータに質問し、SQL不要で分析可能。データ探索やセルフサービスBIに最適。 | 2024年11月:リリース |
| 高度AI分析機能 | Cortex Search | ハイブリッド検索・セマンティックリランキング。キーワードとベクトル検索を統合。 | 2025年1月:リリース |
| 自動化・オーケストレーション | Cortex Agents | 複雑なユーザークエリを分解し、構造化・非構造化データから情報取得。AI駆動の業務自動化に。 | 2025年3月:リリース |
補足
- COMPLETE関数はCortexの中核であり、プロンプト自由記述・チャット・構造化出力・画像分析(マルチモーダル)など“何でもできる”万能関数です。
- タスク固有関数は、プロンプト設計不要でワンライナーで使える定型処理用。業務の自動化や大量処理に最適。
- Cortex Analyst/Search/Agentsは、LLM関数の枠を超えた“高度AI分析・自動化機能”として、セルフサービス分析や業務オーケストレーションを担います。
※Snowflakeの方々、この全体像が分かりやすくまとまった画像があればくださいw
本記事のこれ以降は、汎用性と応用範囲の広いCOMPLETE関数にフォーカスして解説していきたいと思います。
COMPLETE関数は単一のプロンプトだけでなく、対話履歴も扱えます。これにより、チャットボットのような会話体験を実現できます。
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'mistral-large2',
[
{'role': 'system', 'content': '小学生向けの家庭教師のように教えてください'},
{'role': 'user', 'content': '日本の四季について教えてください'}
],
{'temperature': 0.7}
) AS RESPONSE;
このクエリでは
-
systemロールで「小学生向け家庭教師」というペルソナを設定 -
userロールでユーザーからの質問を提供 -
temperatureパラメータで応答のランダム性を調整
応答のJSONから実際のテキスト部分を取り出す場合は以下のようにします:
SELECT
response:choices[0].messages::STRING AS content,
response:usage.completion_tokens::INT AS tokens_used
FROM (
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'mistral-large2',
[
{'role': 'system', 'content': '小学生向けの家庭教師のように教えてください'},
{'role': 'user', 'content': '日本の四季について教えてください'}
],
{'temperature': 0.7}
) AS response
);
Snowflake Cortex COMPLETE モデル別出力構造比較表
COMPLETE関数では多数のモデルが利用出来ます。また色々試していたところ、モデルによって出力構造が微妙に異なる事が分かりました。
マニュアル読まずにすぐ試そうとするので、モデルを変える度に上手く抜き出せず、エラーになったり・・w
| モデル名 | 出力パス指定例 | コンテキストウィンドウ | 主な特徴 | 推奨ユースケース |
|---|---|---|---|---|
mistral-large2 |
response:choices.messages |
128K tokens | 高度な推論・多言語対応 | 複雑なテキスト生成・コード生成 |
snowflake-arctic |
response:choices.message.content |
128K tokens | コスト効率最適化(SwiftKV採用) | 汎用ビジネス文書処理 |
claude-3-5-sonnet |
response:content.text |
200K tokens | 学術レベルの推論能力 | 研究資料分析・複雑なワークフロー |
llama3.1-405b |
response:generations.generation |
128K tokens | 長文処理・多言語サポート | ドキュメント要約・モデル蒸留 |
reka-core |
response:output.text |
128K tokens | コード生成・多言語流暢性 | マルチリンガルテキスト分析 |
deepseek-r1 |
response:result.answer |
128K tokens | 数学/コードタスクに特化 | 数式処理・プログラミング支援 |
モデルを頻繁に変える事はそれほどないですし、癖が分かれば、それほど詰まるところではないですが、このようなモデル別の差異を吸収し、同じレスポンスに整形するための関数を作成してみました。
Snowflake Cortexユニバーサル解析関数の効能と目的
設計目的
-
マルチモデル環境の効率化
モデルごとのレスポンス構造の差異を吸収し、クエリの再利用性を向上(モデル切替時のコード変更不要)。 -
データパイプラインの統一
複雑なJSONパス指定を関数内にカプセル化し、SQLクエリの可読性を維持。 -
将来の機能拡張対応
新しいモデルの追加時でも関数内部のみを修正すれば済む拡張性を確保。
ユニバーサル解析関数(案)
CREATE OR REPLACE FUNCTION parse_cortex_response(response VARIANT)
RETURNS STRING
AS
$$
CASE
WHEN IS_OBJECT(response) THEN
COALESCE(
response:choices[0].messages::STRING,
response:choices[0].message.content::STRING,
response:content[0].text::STRING,
response:generations[0].generation::STRING,
'Unsupported format'
)
ELSE
'Invalid response'
END
$$;
上記を利用して同じリクエストに対するCortexの各モデルの結果をまとめて確認してみましょう。
WITH model_responses AS (
SELECT
'mistral-large2' AS model_name,
SNOWFLAKE.CORTEX.COMPLETE(
'mistral-large2',
[
{'role':'system','content':'小学生向けの家庭教師のように教えてください'},
{'role':'user','content':'日本の四季について教えてください'}
],
{'temperature':0.5, 'max_tokens':500}
) AS response
UNION ALL
SELECT
'snowflake-arctic' AS model_name,
SNOWFLAKE.CORTEX.COMPLETE(
'snowflake-arctic',
[
{'role':'system','content':'小学生向けの家庭教師のように教えてください'},
{'role':'user','content':'日本の四季について教えてください'}
],
{'temperature':0.5, 'max_tokens':500}
) AS response
UNION ALL
SELECT
'claude-3-5-sonnet' AS model_name,
SNOWFLAKE.CORTEX.COMPLETE(
'claude-3-5-sonnet',
[
{'role':'system','content':'小学生向けの家庭教師のように教えてください'},
{'role':'user','content':'日本の四季について教えてください'}
],
{'temperature':0.5, 'max_tokens':500}
) AS response
)
SELECT
model_name,
parse_cortex_response(response) AS parsed_response,
response:usage.completion_tokens::INT AS tokens_used
FROM model_responses;
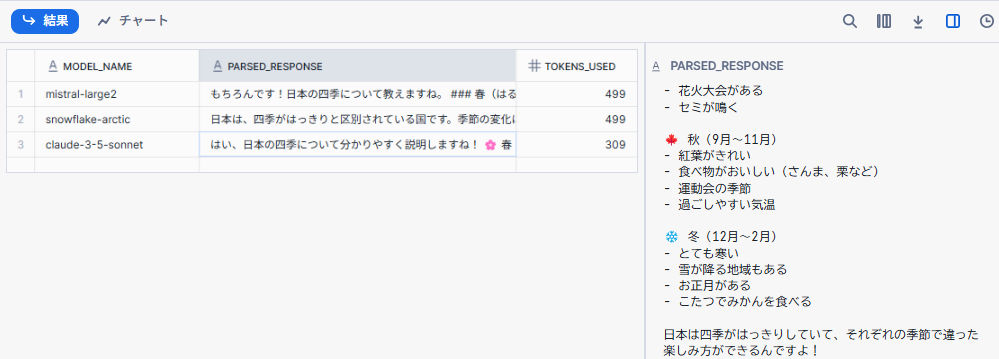
本文だけパースされて比較しやすくなりました。
Snowflake Cortexモデル比較:日本の四季説明タスク
実行結果比較表
| 項目 | mistral-large2 | snowflake-arctic | claude-3-5-sonnet |
|---|---|---|---|
| モデル | mistral-large2 | snowflake-arctic | claude-3-5-sonnet |
| レスポンス | もちろんです!日本の四季について教えますね。### 春(はる)- 季節: 3月から5月まで- 特徴: 暖かくなり、花が咲き始めます。特に桜(さくら)が美しく咲きます。- イベント: 花見(はなみ)が有名です。家族や友達と一緒に桜の木の下でお弁当を食べたり、お花見を楽しんだりします。### 夏(なつ)- 季節: 6月から8月まで- 特徴: とても暑く、湿気も多いです。海やプールで泳ぐのが楽しいです。- イベント: 夏祭り(なつまつり)や花火大会(はなびたいかい)があります。祭りでは焼きそばやかき氷を食べたり、金魚すくいを楽しんだりします。### 秋(あき)- 季節: 9月から11月まで- 特徴: 涼しくなり、紅葉(もみじ)が美しくなります。- イベント: 月見(つきみ)や紅葉狩り(もみじがり)があります。月見では月見団子(つきみだんご)を食べたり、紅葉を見に行ったりします。### 冬(ふゆ)- 季節: 12月から2月まで- 特徴: 寒くなり、雪が降る | 日本は、四季がはっきりと区別されている国です。季節の変化は、自然環境や気候によって左右されます。以下が、日本の四季についての簡単な説明です。1. 春 (3月~5月)春は、暖かくなり始め、草木が芽吹き始める季節です。花粉症の方にとっては、アレルギー反応が強くなることがあります。また、桜の花観賞が人気で、春の花粉で有名な山桜も見られます。2. 夏 (6月~8月)夏は、気温が上がり、日差しが強くなります。海や山への旅行が人気で、夏祭りや花火大会などのイベントが開催されます。暑さ対策のため、冷房や水分補給が大切です。3. 秋 (9月~11月)秋は、気温が下がり、落ち葉が美しい季節です。天気が良い日には、山や海岸から見る美しい夕日が楽しめます。さくらんぼやぶどう、キウイなどの秋の味覚も人気です。4. 冬 (12月~2月)冬は、寒くなり、雪が降ることがあります。北海道や東北地方では、氷見や雪国 | はい、日本の四季について分かりやすく説明しますね!🌸 春(3月~5月)- 桜が咲いてとってもきれい- 新学期が始まる- 気温が暖かくて過ごしやすい- お花見をする人が多い☀️ 夏(6月~8月)- とても暑い- 海や山で遊ぶ人が多い- 花火大会がある- セミが鳴く🍁 秋(9月~11月)- 紅葉がきれい- 食べ物がおいしい(さんま、栗など)- 運動会の季節- 過ごしやすい気温❄️ 冬(12月~2月)- とても寒い- 雪が降る地域もある- お正月がある- こたつでみかんを食べる日本は四季がはっきりしていて、それぞれの季節で違った楽しみ方ができるんですよ! |
| トークン数 | 499 | 499 | 309 |
| スタイル・表現方法 | マークダウン形式、体系的、特徴・イベントで整理、子ども向けの平易な説明 | 番号付きリスト、気候や健康(花粉症、暑さ対策)など実用情報が多く、やや大人向け | 絵文字を活用し親しみやすい会話調、文化・生活の楽しみ(こたつでみかん、運動会など)を重視 |
| 情報の網羅性・正確性 | 各季節の特徴・イベントを網羅。ただし冬の説明が途中で切れる(トークン上限の影響か) | 秋の味覚に「さくらんぼ」「ぶどう」と記載(実際は夏の果物でやや誤り)。健康や生活情報が多い。冬も途中で途切れる | 各季節の象徴や行事、食べ物などを簡潔にまとめる。短いトークンで多くの要素をカバー |
| トークン効率 | 499トークンで詳細な説明 | 499トークンで詳細な説明 | 309トークンで簡潔かつ情報密度が高い |
| 文化的・生活的要素 | 花見、月見団子など日本特有の文化行事に言及 | 花粉症や冷房・水分補給など生活実用面に寄った内容 | こたつでみかん、運動会、食べ物など生活文化や子ども向けイベントにフォーカス |
| 子ども向け適正 | 平易な表現や親しみやすさが高く、教育用途に適している | やや大人向けの内容や専門用語が含まれる | 平易な表現や親しみやすさが高く、教育用途に適している |
| 出力の安定性 | 長文だと途中で切れる場合があるため、max_tokensの調整が必要 | 長文だと途中で切れる場合があるため、max_tokensの調整が必要 | 短くまとめる傾向があるが、要点はしっかり押さえている |
| モデル選択のヒント | 教育・子ども向け:mistral-large2 | 実用情報・大人向け:snowflake-arctic | 短く親しみやすい説明:claude-3-5-sonnet |
モデルによってかなり出力内容に差がある事が分かりました。具体的実装を進めていく上ではどのモデルが適しているかも確認していく必要がありますね。
またSQLで実行するのでエラーハンドリングも設計しやすくなりましたので最低限のエラーハンドリングを考えてみました。
6. よくあるエラーと対処法
ケース1:NULLが返る
WITH raw_data AS (
SELECT SNOWFLAKE.CORTEX.TRY_COMPLETE(...) AS response
)
SELECT
response,
SNOWFLAKE.CORTEX.EXPLAIN_COMPLETE(LAST_QUERY_ID()) AS error_info
FROM raw_data;
ケース2:不完全な出力
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'mistral-large2',
[...],
{'max_tokens': 1024}
);
ケース3:JSONパースエラー
SELECT PARSE_JSON(response) AS raw_json
FROM (
SELECT SNOWFLAKE.CORTEX.COMPLETE(...) AS response
);
実践的なユースケースとして、テーブル内のデータに対してLLM処理を適用してみましょう。
今回はECサイトを想定した、顧客からのレビューを分析してみましょう。
まずはサンプルデータを作成します。
USE DATABASE DATA_PRIVACY;
USE SCHEMA TEST;
CREATE OR REPLACE TABLE customer_reviews (
id INT,
review_text STRING,
review_date DATE
);
INSERT INTO customer_reviews VALUES
(1, '商品の品質は素晴らしいですが、配送が少し遅れました。', CURRENT_DATE()),
(2, 'とても良い買い物ができました。次回も利用します!', CURRENT_DATE()),
(3, '期待していたほど良くなかったです。返品を検討しています。', CURRENT_DATE());
そのレビューに対して感情分析を行います。
SELECT
id,
review_text,
SNOWFLAKE.CORTEX.SENTIMENT(review_text) AS sentiment_score,
CASE
WHEN SNOWFLAKE.CORTEX.SENTIMENT(review_text) > 0.3 THEN 'ポジティブ'
WHEN SNOWFLAKE.CORTEX.SENTIMENT(review_text) -0.3 THEN 'ネガティブ'
ELSE '中立'
END AS sentiment_category
FROM customer_reviews;
| ID | REVIEW_TEXT | SENTIMENT_SCORE | SENTIMENT_CATEGORY |
|---|---|---|---|
| 1 | 商品の品質は素晴らしいですが、配送が少し遅れました。 | -0.18097965 | 中立 |
| 2 | とても良い買い物ができました。次回も利用します! | -0.015108005 | 中立 |
| 3 | 期待していたほど良くなかったです。返品を検討しています。 | -0.06819384 | 中立 |
レビューから具体的な問題点を抽出するには
SELECT
id,
review_text,
SNOWFLAKE.CORTEX.COMPLETE(
'snowflake-arctic',
CONCAT('以下の顧客レビューから主な問題点を1つだけ抽出してください。問題がない場合は「問題なし」と回答してください: ', review_text)
) AS extracted_issue
FROM customer_reviews;
| ID | REVIEW_TEXT | EXTRACTED_ISSUE |
|---|---|---|
| 1 | 商品の品質は素晴らしいですが、配送が少し遅れました。 | 問題点: 配送が少し遅れました。 |
| 2 | とても良い買い物ができました。次回も利用します! | 問題なし |
| 3 | 期待していたほど良くなかったです。返品を検討しています。 | 問題点: 返品を検討していること |
簡単なテストではありますが、文脈をちゃんと読み取れており、十分な機能を有しているのではないでしょうか?
このような基本機能や性能を踏まえると様々な活用用途があるように思います。
あなたの業界でのCortex活用アイデア
- 小売業: POS/ECデータと顧客レビューを統合分析し、商品改善ポイントを自動抽出
- 製造業: 機器センサーデータと作業報告書をLLMで分析し、異常予兆を検出
- 金融業: 取引データと市場ニュースを組み合わせたリスク分析
- 医療業: 匿名化された診療記録からの治療パターン分析
私のようなSQLオンリーのエンジニアでも、今まで以上に自社、自業界の様々な課題解決に対し、SQLベースのAI活用でさらに活躍できるチャンスが広がっていく気がします。
次に2025年2月にリリースされた新機能「Structured Outputs」を試したいと思います。この機能を使うと、LLMの出力を指定したJSONスキーマに沿った形で取得できます。
SELECT
id,
review_text,
SNOWFLAKE.CORTEX.COMPLETE(
'claude-3-5-sonnet',
[
{
'role': 'user',
'content': $$
{
"instruction": "レビューを分析し、以下のJSON形式で出力:",
"example": {
"sentiment": "positive",
"key_issue": "配送遅延",
"recommend_action": "物流改善"
},
"review": "$$ || review_text || $$"
}
$$
}
],
{
'response_format': {
'type': 'json',
'schema': {
'type': 'object',
'properties': {
'sentiment': {'type': 'string', 'enum': ['positive','neutral','negative']},
'key_issue': {'type': 'string'},
'recommend_action': {'type': 'string'}
},
'required': ['sentiment','key_issue','recommend_action']
}
}
}
) AS analysis_result
FROM customer_reviews;

出力結果をまとめるとこんな感じでした。
| ID | レビュー本文 | 感情分析 | 主要課題 | 改善提案 | モデル | 総トークン数 |
|---|---|---|---|---|---|---|
| 1 | 商品の品質は素晴らしいですが、配送が少し遅れました。 | neutral | 配送遅延 | 配送スピードの改善と配送状況の適切な追跡管理の実施 | claude-3-5-sonnet | 589 |
| 2 | とても良い買い物ができました。次回も利用します! | positive | 顧客満足度が高い | サービス品質維持とリピート促進のためのロイヤルティプログラム検討 | claude-3-5-sonnet | 578 |
| 3 | 期待していたほど良くなかったです。返品を検討しています。 | negative | 商品満足度の低さ | 商品品質の確認と返品対応プロセスの円滑化 | claude-3-5-sonnet | 583 |
この機能により、LLMからの出力を構造化されたフォーマットで取得でき、後続の処理が格段に容易になります。
ただこの回答レベルでは情報が浅く、改善提案にはまだ使いづらいと感じました。
そこでプロンプトを強化してみましょう。
SELECT
id,
review_text,
SNOWFLAKE.CORTEX.COMPLETE(
'claude-3-5-sonnet',
[
{
'role': 'user',
'content': $$
顧客レビューを分析し、以下を含むJSONを出力:
- sentiment: positive/neutral/negative
- key_issue: 主要な問題点(50文字以内)
- recommend_action: 具体的な改善策(動詞で開始)
例:
{
"sentiment": "positive",
"key_issue": "配送遅延",
"recommend_action": "配送業者のパフォーマンス監査を実施"
}
【分析対象レビュー】
$$ || review_text
}
],
{
'response_format': {
'type': 'json',
'schema': {
'type': 'object',
'properties': {
'sentiment': {'type': 'string', 'enum': ['positive','neutral','negative']},
'key_issue': {'type': 'string'},
'recommend_action': {'type': 'string'}
},
'required': ['sentiment','key_issue','recommend_action']
}
},
'temperature': 0.5,
'max_tokens': 500
}
) AS analysis_result
FROM customer_reviews;

| ID | レビュー本文 | 感情分析 | 主要課題 | 改善提案 | トークン使用量 |
|---|---|---|---|---|---|
| 1 | 商品の品質は素晴らしいですが、配送が少し遅れました。 | neutral | 配送遅延 | 配送状況のリアルタイムモニタリングを強化する | 656 |
| 2 | とても良い買い物ができました。次回も利用します! | positive | 特に問題点なし。顧客満足度が高い | 現在の顧客サービス品質を維持し、リピート購入を促進する施策を実施 | 662 |
| 3 | 期待していたほど良くなかったです。返品を検討しています。 | negative | 商品の品質・性能が期待を下回る | 商品の品質管理を強化し、商品説明の正確性を見直す | 655 |
先ほどに比べ、課題の抽出や改善提案がより具体的に出力されたように思います。やはり、Cortexにおいてもプロンプトエンジニアリングが重要だと判断出来ます。
さて、ここまでのところでは一般的なLLMとしての活用、ついで自社の顧客レビューデータ(半構造化データ)を用いた感情分析を行ってきました。
これに加え、さらに非構造化データに対するSQLによるLLM分析を試していきましょう。
2025年4月にパブリックプレビューが開始されたCOMPLETE関数のマルチモーダル機能を使うと、画像分析も可能になります。
この詳細は、我らのソリューションアーキテクトの菅野さんがめちゃ分かりやすい記事を書いてくれています!
それをなぞるような流れですが、自分でも試してみます!
Pythonとか画像処理とか全然出来ない私が、SQLで画像解析が出来るとは感無量!
USE DATABASE DATA_PRIVACY;
USE SCHEMA TEST;
CREATE OR REPLACE STAGE TEST_STAGE
DIRECTORY = (ENABLE = TRUE)
ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE');
アップロードした画像は、先日来日したSnowflake創業者の Benoit と Thierry と 僕のスリーショット写真❤
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'claude-3-5-sonnet',
'この画像について簡潔に日本語で説明してください。',
TO_FILE('@DATA_PRIVACY.TEST.TEST_STAGE', '1743052614718.jpg')
) AS image_analysis;
ビジネスの場面での集合写真です。中央の方はSnowflakeのロゴが入った青いパーカーを着用しており、両サイドの方々はスーツを着用しています。オフィスや会議室のような室内での撮影のようです。背景には白い壁とアート作品が見えます。
SELECT SNOWFLAKE.CORTEX.COMPLETE('claude-3-5-sonnet',
'この画像に写っている3人の関係性を分析し、ビジネス上の関係について推測してください。',
TO_FILE('@DATA_PRIVACY.TEST.TEST_STAGE', '1743052614718.jpg'));
この画像からは、ビジネス関係の興味深い力学が見て取れます:
中央の人物はSnowflakeの社員で(青いパーカーのロゴから判断)、おそらくテクニカルな立場の人物だと推測されます。両サイドのスーツ姿の2人は、ビジネス側のエグゼクティブクラスの立場の方々のように見えます。
服装の違いから、これは以下のような状況が考えられます:
- ビジネスミーティングやカンファレンスでの出会い
- Snowflakeと他社とのパートナーシップや取引に関する話し合い
- テクノロジー企業と従来型企業の協業の場面
3人の表情が友好的なことから、良好な関係性や成功的な商談の場面である可能性が高いと思われます。
このような異なる企業文化(テクノロジー企業のカジュアルさと従来型企業のフォーマル性)が交わる場面は、現代のビジネスシーンでは一般的になってきています。
期待通り、Snowflake社員に間違われました笑
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'claude-3-5-sonnet',
'画像に写っている人物の感情と雰囲気およびその環境やシーンを分析し、以下の形式でJSON出力してください:
{
"positive_score": 0-10のスケール,
"professional_atmosphere": 0-10のスケール,
"dominant_emotion": "主な感情",
"confidence": 0-1の確信度,
"indoor_probability": 0-1の確率,
"scene_type": "イベント種別",
"formality_level": 0-10のスケール,
"spatial_openness": 0-10のスケール
}',
TO_FILE('@DATA_PRIVACY.TEST.TEST_STAGE', '1743052614718.jpg')
) AS emotion_analysis;
{
"positive_score": 9,
"professional_atmosphere": 7,
"dominant_emotion": "joy",
"confidence": 0.9,
"indoor_probability": 1.0,
"scene_type": "business meeting or conference",
"formality_level": 6,
"spatial_openness": 7
}
この分析結果について説明すると:
- 写真全体から非常にポジティブな雰囲気が伝わってきます(positive_score: 9)
- ビジネス環境でありながら、カジュアルな要素も含まれています(professional_atmosphere: 7)
- 全員が笑顔で、友好的な雰囲気が強く感じられます(dominant_emotion: "joy")
- 室内のオフィスや会議施設での撮影と思われます(indoor_probability: 1.0)
- フォーマルなスーツ姿の人とカジュアルなパーカー姿の人が混在しており、現代的なビジネス環境を反映しています(formality_level: 6)
- 明るい照明と壁面アートのある開放的な空間です(spatial_openness: 7)
全体の特徴も良く掴んで分析結果を出力してくれているように思います。
というように、画像の説明生成だけでなく、係数化や分析を行う事が出来ますし、これらを元に構造化データに変換する事も可能となってきます。
さて、最後はデータエンジニアらしく、実践的なビジネスユースケースとして、マーケティングチームの業務効率化を考えてみましょう。
キャンペーン案件に対し、より効果的なマーケティング施策となるように改善提案をCOMPLETE関数で実装しましょう。
CREATE OR REPLACE TABLE marketing_campaigns (
campaign_id INT,
campaign_name STRING,
target_audience STRING,
description STRING,
start_date DATE,
end_date DATE,
budget FLOAT,
roi FLOAT
);
INSERT INTO marketing_campaigns VALUES
(1, '夏のセール', '20代〜30代女性', '夏物衣料の大幅値引きキャンペーン', '2025-06-01', '2025-06-30', 500000, 1.8),
(2, 'SNS広告', '10代後半', 'インフルエンサーを活用したSNSプロモーション', '2025-05-15', '2025-07-15', 800000, 1.2),
(3, 'メルマガ施策', '既存顧客', '特典クーポン付きメールマガジン配信', '2025-05-01', '2025-05-31', 200000, 2.5);
SELECT
campaign_id,
campaign_name,
roi,
SNOWFLAKE.CORTEX.COMPLETE(
'llama3.1-70b',
CONCAT(
'あなたはマーケティング専門家です。以下のキャンペーン情報を分析し、ROIを向上させるための具体的な改善提案を3つ提示してください。',
'キャンペーン名: ', campaign_name,
', ターゲット: ', target_audience,
', 説明: ', description,
', 期間: ', start_date, ' 〜 ', end_date,
', 予算: ', budget, '円',
', 現在のROI: ', roi
)
) AS improvement_suggestions
FROM marketing_campaigns
WHERE roi 2.0;
このクエリでは、ROIが低いキャンペーンに対して、LLMを使って自動的に改善提案を生成しています。マーケティング担当者はこれらの提案を検討し、次の施策に活かすことができます。
(実際の施策分析に必要な情報は多岐に渡りますが、イメージをつかむためにだいぶ簡略化しています)
このようなデータ活用において、AIが最適な答えを出すには、コンテキストを如何に流し込めるかが重要です。
キャンペーン情報などのマスタ系や実績情報だけでは情報不足で、説明欄や補足情報、クライアントやセグメント情報などのテキスト情報、場合によっては時事やトピックなどの情報も有用だったりします。
この辺り弊社も様々なキャンペーンを行っており、それらの成果数値は管理していますが、そもそもどういうキャンペーンや販促だったのか?その結果に与える変数や特異値がなかったか?など、今まで以上にデータ化する事も重要性をひしひしと感じています。
さて、ここまでは機能中心に学んできましたが、Snowflake Cortex機能は使用量に応じた課金になるため、最適化が重要です。以下にいくつかのベストプラクティスというか注意事項を紹介します。
-
適切なモデルの選択:タスクの複雑さに応じてモデルを選びましょう。単純な文章生成なら小さいモデル、複雑な推論には大きいモデルが適しています。個人的にはclaude好きなので3.7が利用出来るようになったら、そればかり使いたくなりますが、コスト意識を持つことが重要です。(自戒)
-
max_tokensの設定:必要最小限の出力長を指定することで、処理時間とコストを削減できます。
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'snowflake-arctic',
[
{
'role': 'user',
'content': '企業におけるデータ活用のベストプラクティスを教えてください'
}
],
{
'max_tokens': 200
}
) AS best_practices;
- TRY_COMPLETEの活用:大量データ処理時にエラーで中断するのを防ぐため、TRY_COMPLETE関数を使いましょう。
SELECT
id,
review_text,
SNOWFLAKE.CORTEX.TRY_COMPLETE(
'snowflake-arctic',
CONCAT('次のレビューを一言で要約: ', review_text)
) AS summary
FROM customer_reviews;
参考:今回のハンズオン一式の費用
ちなみに今回の一連のハンズオンとそのテストまで含めたコストは以下でした。
SELECT * FROM SNOWFLAKE.ACCOUNT_USAGE.METERING_DAILY_HISTORY WHERE SERVICE_TYPE='AI_SERVICES';
| SERVICE_TYPE | USAGE_DATE | CREDITS_USED_COMPUTE | CREDITS_USED_CLOUD_SERVICES | CREDITS_USED | CREDITS_ADJUSTMENT_CLOUD_SERVICES | CREDITS_BILLED |
|---|---|---|---|---|---|---|
| AI_SERVICES | 2025-05-02 | 0.055460050 | 0.000000000 | 0.055460050 | 0.0000000000 | 0.0554600500 |
0.055 × $4/クレジット × 150円 ≒ 33円
安い!
SELECT * FROM SNOWFLAKE.ACCOUNT_USAGE.CORTEX_FUNCTIONS_USAGE_HISTORY;
| START_TIME | END_TIME | FUNCTION_NAME | MODEL_NAME | WAREHOUSE_ID | TOKEN_CREDITS | TOKENS |
|---|---|---|---|---|---|---|
| 2025-05-02 21:00:00.000 +0900 | 2025-05-02 22:00:00.000 +0900 | COMPLETE | llama3.1-70b | 11 | 0.002929410 | 2421 |
| 2025-05-02 18:00:00.000 +0900 | 2025-05-02 19:00:00.000 +0900 | SENTIMENT | 11 | 0.000010000 | 125 | |
| 2025-05-02 17:00:00.000 +0900 | 2025-05-02 18:00:00.000 +0900 | COMPLETE | claude-3-5-sonnet | 11 | 0.000877200 | 344 |
| 2025-05-02 18:00:00.000 +0900 | 2025-05-02 19:00:00.000 +0900 | COMPLETE | claude-3-5-sonnet | 11 | 0.013578750 | 5325 |
| 2025-05-02 18:00:00.000 +0900 | 2025-05-02 19:00:00.000 +0900 | COMPLETE | mistral-large2 | 11 | 0.000824850 | 423 |
| 2025-05-02 18:00:00.000 +0900 | 2025-05-02 19:00:00.000 +0900 | COMPLETE | snowflake-arctic | 11 | 0.000569520 | 678 |
| 2025-05-02 21:00:00.000 +0900 | 2025-05-02 22:00:00.000 +0900 | COMPLETE | claude-3-5-sonnet | 11 | 0.007838700 | 3074 |
| 2025-05-02 21:00:00.000 +0900 | 2025-05-02 22:00:00.000 +0900 | COMPLETE | snowflake-arctic | 11 | 0.000823200 | 980 |
| 2025-05-02 20:00:00.000 +0900 | 2025-05-02 21:00:00.000 +0900 | COMPLETE | claude-3-5-sonnet | 11 | 0.018987300 | 7446 |
| 2025-05-02 17:00:00.000 +0900 | 2025-05-02 18:00:00.000 +0900 | COMPLETE | snowflake-arctic | 11 | 0.000846720 | 1008 |
| 2025-05-02 17:00:00.000 +0900 | 2025-05-02 18:00:00.000 +0900 | COMPLETE | mistral-large2 | 11 | 0.008174400 | 4192 |
これらを見る限り、ハンズオンぐらいであればコストを気にせずにガンガン試せそうです!
Snowflake Cortexは、SQLの知識だけで高度なAI機能を活用できる革新的なサービスです。本記事では、COMPLETE関数を中心に基本的な使い方から最新機能まで紹介しました。
特に注目すべき点は以下と考えています
- SQLのみでLLMを活用できるアクセシビリティの高さ
- データがSnowflake内に留まるセキュリティ
- 構造化出力やマルチモーダル機能などの最新機能
- ビジネスユースケースへの直接的な適用可能性
- カスタマイズが必要な場合はCOMPLETE関数、定型処理はタスク固有関数という使い分け
私自身、プログラミングは苦手なので、勝手知ったるSQLで出来るのは非常に心理的にも技術的にもハードルが低く、慣れると色々可能性が広がるなと思った次第です。
諸先輩方が素晴らしい記事を書いていただいており、それをなぞるだけで多くの事が学べました。一方でそれらを含めた全体像や自分が改めて実装をしようとした時、自分のペースでのハンズオンや気になるところがまとまっていて欲しいと思い、それぞれの記事から学びつつ、自分なりに調べた事などを、のちに自分で体系的に振り返るためという私利私欲でこの記事を書いています。
また社内で何か実装しようという話が出た時には自分の記事をメンバーに紹介すると思います。そんな今すぐではなく少し先に向けた準備として知識を取り入れ、学び、教えられるようになっておくのは非常に大事だなと思っています。
Snowflake Cortexは機能拡張はさらに続くと予想されます。例えば、ファインチューニング機能の拡充や、より高度なマルチモーダル機能の追加などが期待されます。
それらも全てSQLベースで実行出来るとなれば、今のデータエンジニアの知識やスキルを活かしたまま、データサイエンスやAIエンジニアリングへと自分の活躍領域を広げられることにつながります。
このような機能の最終的な商用実装を考えるとオーケストレーション機能が欲しいなーと切に願う次第で、ぜひ更なる機能拡張を期待してこの記事を終えたいと思います!
その時にはまた少し先にこれらを学び、何か残して置ければよいなと考えています。
またこのような記事を書くきっかけとなったのは、SnowflakeのユーザーコミュニティであるSnowVillageのイベント参加を通じた新たな発見や気付きがあったからです。
コミュニティに参加するだけで様々な知見や学びを得られますし、イベントに参加することでより実践的で深い技術やノウハウを学ぶことが出来、それらを通じてデータエンジニアとして成長する機会も大きく増えると思いますので、ぜひ皆さんもご参加ください。
SnowVillage
イベント案内
Views: 0

Amazon Fire HD 10 タブレット - 10インチHD ディスプレイ 32GB ブラック
¥19,980 (2025年5月5日 13:18 GMT +09:00 時点 - 詳細はこちら価格および発送可能時期は表示された日付/時刻の時点のものであり、変更される場合があります。本商品の購入においては、購入の時点で当該の Amazon サイトに表示されている価格および発送可能時期の情報が適用されます。)


{kind=link}