

はじめに
ローカルLLM は M4 の Mac mini でばかり試していたのですが、Windows でも少し試してみました。
- Ollama を利用
- MLX LM・MLX-VLM を利用
なお、モデルは以下 2つを試します。
- gemma3:12b-it-q8_0
- gemma3:27b-it-q4_K_M
さっそく試す
さっそく試していきます。
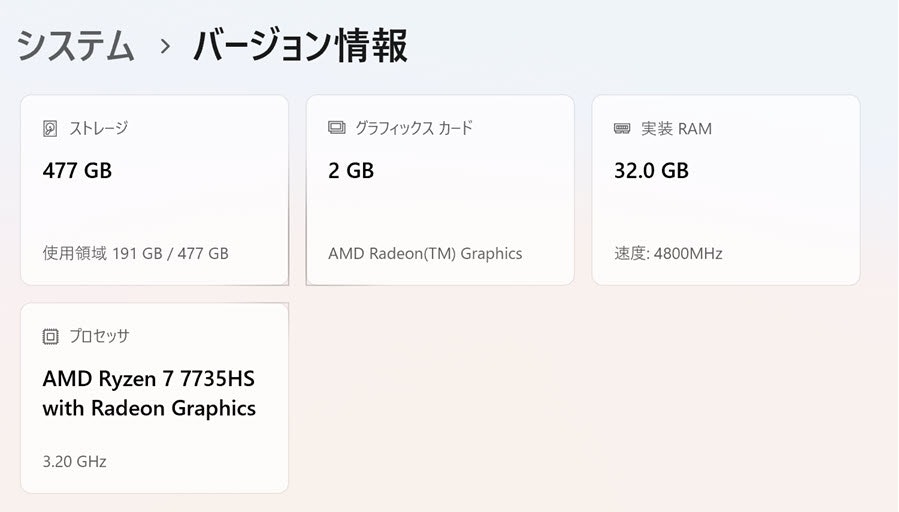
利用する PC
今回使う PC は以下のマシンです。
スペックはこんな感じです。
Windows用のインストーラーでインストール
以下のページから Windows用のインストーラーをダウンロードしてインストールします。
●Download Ollama on Windows
https://ollama.com/download/windows
以下、インストール中の様子です。
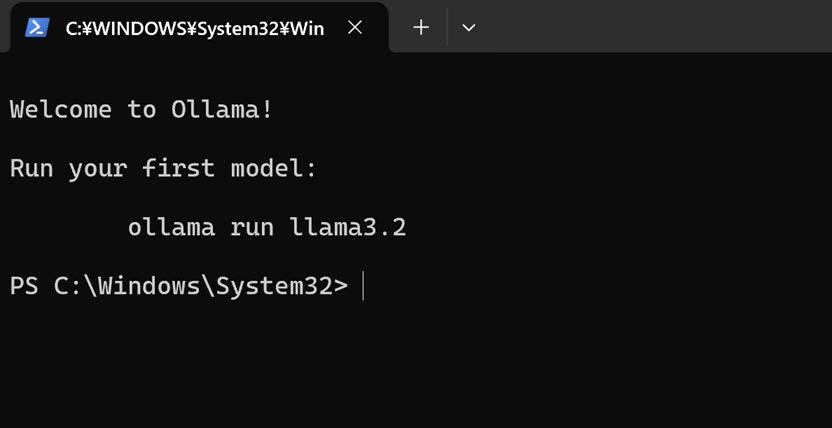
インストール完了後
インストールが完了すると、以下の PowerShell が立ち上がりました。
gemma3:12b-it-q8_0 を使えるようにする
Mac で試していた gemma3:12b-it-q8_0 を使うことにします。
以下のコマンドを実行すると、モデルがダウンロードされます。
ollama run gemma3:12b-it-q8_0
ちなみに Windows の場合は、以下にダウンロードされるようです。
C:\Users\【Windowsのユーザー名】\.ollama\models
gemma3:12b-it-q8_0 を使う
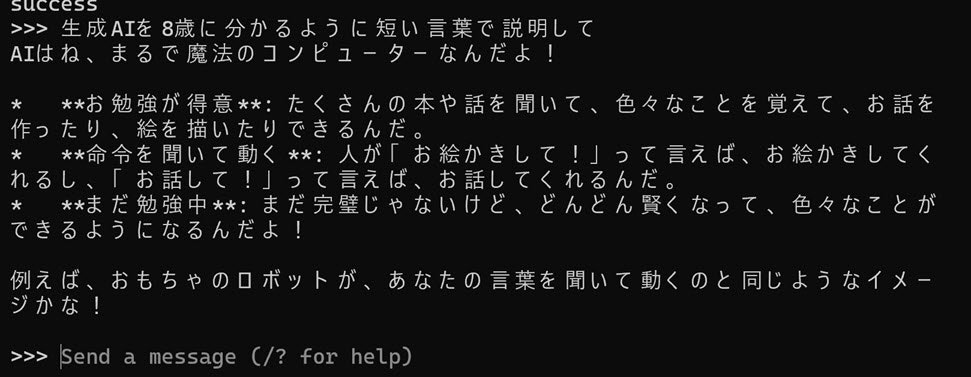
ダウンロードが完了したら、プロンプトを入力して試してみます。
Mac で試していた時と同じプロンプトの 「生成AIを8歳に分かるように短い言葉で説明して」 という内容で試してみました。そして得られた結果は以下のとおりです。
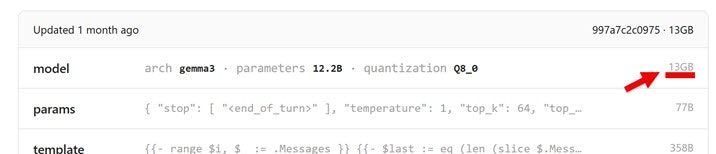
以下のとおり、13GB のサイズのモデルですが、問題なく動作しました。
●gemma3:12b-it-q8_0
https://ollama.com/library/gemma3:12b-it-q8_0
gemma3:27b-it-q4_K_M を使う
もう 1種類使ってみます。
17GB ほどのサイズになる gemma3:27b-it-q4_K_M を、以下でダウンロードして実行します。
ollama run gemma3:27b-it-q4_K_M
以下、ダウンロード中です。

ダウンロードが完了した後、先ほどと同じプロンプトの 「生成AIを8歳に分かるように短い言葉で説明して」 という内容で試してみます。その結果、以下の応答を得られました。

実行中のパフォーマンスなどの情報
Ollama を今回のマシンで起動している時、またプロンプトに対する回答が生成されている時の、パフォーマンスなどの情報を掲載してみます。
メモリの利用
こちらは Ollama を起動している時のメモリの利用状況です。14GBくらい使っている状態になっていました。

処理負荷
また、プロンプトに対する回答が生成されている時の処理負荷を見てみます。
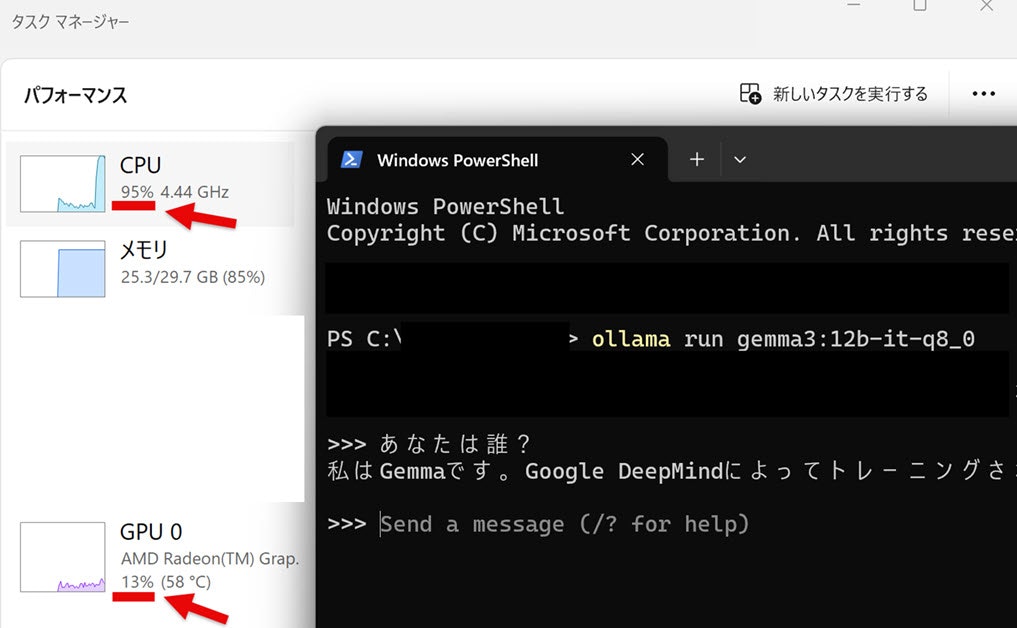
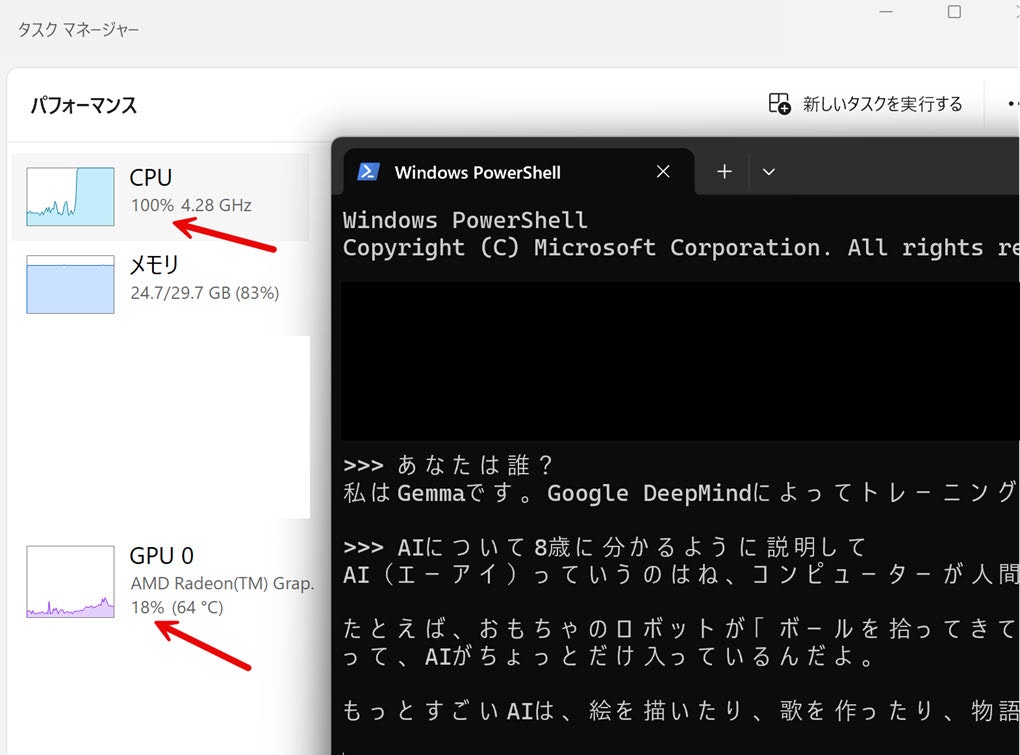
CPU での処理になっているようでした。
Views: 3

{kind=link}