

はじめに
私は、かれこれ2年間プログラミングを学習してきました。
今まで書籍、動画教材(YouTubeやUdemy)を使いフレームワーク・ライブラリを使い開発することをやってきました。
勉強を進める中でなぜ?LaravelやRails等のフレームワークやライブラリは人気なのか?
フレームワークやライブラリがなぜ?開発されたのか?てかそもそもWebってなに?って疑問を持つようになりました。
読んでいる人の中にも私と同じ疑問に持っている人たちの為の記事です。
「そんなの知ってるよ」とか「なにを今更」って思っている人は回れ右でお願いします。
それでは「Webの基本」というテーマで解説していきます!!
この記事で得られること
「Webの基本」URLやプロトコル、HTTP、リクエスト、レスポンス、
クッキーまでまるっと丸分かり!
目次
URLとは
ブラウザのアドレスバーに表示される、スラッシュ(/)で区切られた英数字の列のことです
URL(Uniform Resource Locator)とはインターネットにおける住所のことです。要するにインターネット上のどこにあるページなのかを表しています。
http://example.jp/index.html
http:スキーム(scheme)・・・URLが表す情報にアクセスするための方法
example.jp:ホスト(host)・・・接続先のコンピュータを表す文字列(ドメイン部分)
index.html:パス(path)・・・相手コンピュータにおける情報の位置を示す文字列
実は上記のURLは省略されています。
http://user:[email protected]:8042/over/there?name=ferrent#nose
user:ユーザー(user)・password:パスワード(password)
- 認証が必要なサーバへアクセスする時、必要となる認証情報を指定する
8042:ポート(port)
- ポートはホストと組み合わせて使われ、通信の入り口
name=ferret:クエリ(query)
- Webサーバに渡すパラメータ部分。パスの後に?で区切り、
名前=値の形式で記述する
nose:フラグメント(fragment)
- Webサーバに送られる情報ではなくブラウザが解釈する情報で、HTML内の特定位置を表す
HTTPメソッド
HTTPメソッドの種類と説明
| メソッド | 説明 | パラメータ | Formからの送信 | 使用頻度 |
|---|---|---|---|---|
| GET | リソースの取得を行う | クエリパラメータとして含める | 可 | ★★★★★ |
| POST | 新しいリソースの作成や送信を行う | ボディに含める | 可 | ★★★★★ |
| PUT | リソースの全体更新を行う | ボディに含める | 通常は不可(JavaScriptなどで可) | ★★★★☆ |
| PATCH | リソースの部分更新を行う | ボディに含める | 通常は不可(JavaScriptなどで可) | ★★★☆☆ |
| DELETE | リソースの削除を行う | クエリまたはボディに含める場合あり | 通常は不可(JavaScriptなどで可) | ★★★★☆ |
| HEAD | レスポンスヘッダーのみ取得する | クエリパラメータとして含める | 不可 | ★★☆☆☆ |
| OPTIONS | 利用可能なメソッドの確認を行う | 通常なし | 不可 | ★★☆☆☆ |
| CONNECT | プロキシ接続の確立を行う | 通常なし(トンネル対象を指定) | 不可 | ★☆☆☆☆ |
| TRACE | リクエストのループバック診断 | 通常なし | 不可 | ★☆☆☆☆ |
GET POST DELETE PUT PATCH はウェブサービスを解決する時に特に頻繁に使う
- GET:データを取得する(読む)
- POST:新しいデータを作成する(送る)
- PUT:データをまるごと上書き(完全更新)
- PATCH:一部のデータを更新(部分更新)
- DELETE:データを削除する
HTTPリクエスト
クライアント(ブラウザなど)がサーバに対して何かを「お願いする」メッセージ
//リクエスト構造
GET /index.html HTTP/1.1
Host: [www.example.com](http://www.example.com/)
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)
Accept: text/html
Accept-Language: ja,en-US;q=0.9
Connection: keep-alive
リクエスト良く使われるヘッダ
| ヘッダ名 | 用途・目的 |
|---|---|
Host |
リクエスト先のホスト名を指定。バーチャルホスト環境で必須。 |
User-Agent |
クライアントの種類やバージョン情報。サーバ側の最適化やログ収集に使用。 |
Accept |
受け入れ可能なレスポンスのMIMEタイプを指定(例:text/html)。 |
Accept-Language |
優先する言語を指定(例:ja, en-US;q=0.9)。多言語対応サイトで重要。 |
Connection |
接続の維持方針(例:keep-alive)。パフォーマンス向上に寄与。 |
Cookie |
サーバに送るクッキー。セッション管理や状態保持に使用。 |
Referer |
現在のリクエストの直前に表示されていたページのURL。アクセス解析などに利用。 |
Content-Type |
(POST時など)リクエストボディのMIMEタイプを指定(例:application/json)。 |
Authorization |
認証情報を付与(例:BearerトークンやBasic認証)。 |
Origin |
リクエスト元のオリジン。CSRFやWebSocketの保護に活用される。 |
Hostヘッダ
上記の表の中でも特に重要なヘッダです
Hostヘッダを参照することでWebサーバーはどのドメイン宛のリクエストかを判断している
- ヘッダにはアクセスしようとするURLのドメイン部分が入る
例:http://example.jp/index.htmlというURLにアクセスした時- example.jpというドメイン名がHostヘッダに入る
- /index.htmlというパスはリクエストターゲットに入る

出典:小森裕介著『[改訂新版]プロになるためのWeb技術入門』より
HTTPレスポンス
リクエストを受けたサーバがクライアントに返す「答え」
//レスポンス構造
HTTP/1.1 200 OK
Date: Mon, 27 May 2025 12:00:00 GMT
Content-Type: text/html; charset=UTF-8
Content-Length: 1234
(空行)
Example
Hello World!
レスポンスに使われるヘッダ
| ヘッダ名 | 用途・目的 |
|---|---|
| ステータスライン | HTTPバージョン、ステータスコード、ステータスメッセージを示す(例: HTTP/1.1 200 OK) |
| Date | レスポンスがサーバで生成された日時を示す(例: Mon, 27 May 2025 12:00:00 GMT) |
| Content-Type | ボディのMIMEタイプと文字コードを指定(例: text/html; charset=UTF-8) |
| Content-Length | レスポンスボディのバイト数を指定し、クライアントが読み取り終了を判断しやすくする |
| Server | サーバソフトウェアの名前やバージョン情報を示す(例: Apache/2.4.41 (Ubuntu)) |
| Set-Cookie | クッキーをクライアントに設定するための情報を送信 |
| Cache-Control | キャッシュの制御に関する指示(例: no-cache, max-age=3600) |
| Location | リダイレクト先のURLを示す(主に3xxレスポンスで使用) |
| Access-Control-Allow-Origin | CORS(クロスオリジンリソースシェアリング)で許可するオリジンを指定 |
| Connection | 接続の継続/終了を指定(例: keep-alive, close) |
| Keep-Alive |
Connection: keep-alive 使用時に、接続の継続時間や最大リクエスト数などを指定(例: timeout=5, max=1000) |
| Content-Encoding | 圧縮方式など、レスポンスボディのエンコーディング方式を示す(例: gzip) |
| ETag | レスポンス内容の識別子(バージョン管理やキャッシュの検証に利用) |
| Last-Modified | コンテンツの最終更新日時を示す(例: Tue, 20 May 2025 14:00:00 GMT) |
| 空行 | ヘッダの終了を示す1行の空行。ここでヘッダ部分が終わり、その後にレスポンスボディが続く |
MIMEタイプ
| MIMEタイプ | 説明 |
|---|---|
text/plain |
プレーンテキスト(装飾なしの文字情報) |
text/html |
HTML形式の文書 |
text/css |
CSSスタイルシート |
text/javascript または application/javascript
|
JavaScriptコード |
application/json |
JSON形式のデータ |
application/xml |
XML形式のデータ |
application/pdf |
PDF文書 |
application/zip |
ZIP形式の圧縮ファイル |
application/octet-stream |
バイナリデータ(ファイルのダウンロードなど汎用) |
image/jpeg |
JPEG画像 |
image/png |
PNG画像 |
image/gif |
GIF画像 |
image/svg+xml |
SVGベクター画像 |
audio/mpeg |
MP3音声データ |
audio/wav |
WAV音声データ |
video/mp4 |
MP4動画 |
video/webm |
WebM動画形式 |
multipart/form-data |
フォーム送信でファイルを含む際のエンコーディングタイプ |
application/x-www-form-urlencoded |
通常のフォーム送信時のエンコーディング(URLエンコード形式) |
MIMEタイプはファイル種類の示す。拡張子のようなもの
HTTPステータスコード一覧
| ステータスコード | 意味 | 説明 |
|---|---|---|
| 1xx | 情報 | リクエストは受け取られ、処理が継続されている |
| 100 | Continue | 続けてリクエストを送ってよい |
| 2xx | 成功 | リクエストが正常に処理された |
| 200 | OK | 正常に成功 |
| 201 | Created | 新規リソースが作成された |
| 3xx | リダイレクト | リソースの場所が移動している |
| 301 | Moved Permanently | 恒久的に移動 |
| 302 | Found (一時的リダイレクト) | 一時的に移動 |
| 4xx | クライアントエラー | リクエストに誤りがある |
| 400 | Bad Request | リクエストが不正 |
| 401 | Unauthorized | 認証が必要 |
| 403 | Forbidden | アクセス禁止 |
| 404 | Not Found | 見つからない |
| 5xx | サーバエラー | サーバ側の問題 |
| 500 | Internal Server Error | サーバ内部エラー |
| 502 | Bad Gateway | ゲートウェイエラー |
| 503 | Service Unavailable | 一時的に利用不可 |
プロトコル・ポート番号
プロトコル
プロトコルとは:メットワーク上でデータをやり取りする際の手順や形式を定めたもの
主なプロトコルの例
| プロトコル名 | 説明 |
|---|---|
| HTTP (Hyper Text Transfer Protocol) | Webページを取得するためのプロトコル |
| HTTPS | HTTPの通信を暗号化したもの(安全な通信) |
| TCP (Transmission Control Protocol) | 信頼性の高い通信を実現するプロトコル |
| UDP (User Datagram Protocol) | 高速だが信頼性の低い通信を行うプロトコル |
| FTP (File Transfer Protocol) | ファイル転送用のプロトコル |
| SMTP (Simple Mail Transfer Protocol) | 電子メールの送信を行うためのプロトコル |
| DNS (Domain Name System) | ドメイン名とIPアドレスを対応付けるための名前解決を行うプロトコル |
| SSH (Secure Shell) | ネットワーク上で安全にリモート操作や管理を行うためのプロトコル |
ポート番号
ポート番号とは:コンピュータ内の通信窓口。一つのIPアドレスで複数の通信を区別するために使う
- 0~1023:ウェルノウンポート(良く使われる主要サービス用、管理者権限が必要)
- 1024~49151:登録済みポート(特定のアプリケーション用)
- 49152~65535:動的・プライベートポート(クライアント側で一時的に使用)
主なプロトコルと標準ポート番号の例
| プロトコル | 標準ポート番号 | 用途例 |
|---|---|---|
| HTTP | 80 | Webサイト閲覧 |
| HTTPS | 443 | セキュアなWeb通信 |
| FTP | 21 | ファイル転送 |
| SMTP | 25 | メール送信 |
| DNS | 53 | ドメイン名の名前解決 |
| SSH | 22 | リモートログイン・管理用 |
ステートフルとは
- 状態(セッション)を維持する通信方式であり、プロトコルによって通信の開始から終了までの状態が管理される。これにより、一連のリクエスト同士の関連性をサーバー側で把握できる。
- イメージ:あるクライアントと通信を始めると「これはクライアントAからの通信で、前回届いたリクエストA-1に続くリクエストA−2である」というように紐づけられる
ステートフルは、人間同士のコミュニケーションでいうと「電話」のようなもの。
通話が始まると切るまで双方向の会話が続く。この一連の流れがセッションであり、ステートフルな通信に該当する
-
コンピュータ間の一連の通信を「セッション(Session)」と呼び、そのセッションに付随する情報(例えば、ログイン状態や現在のディレクトリなど)を保存・管理する仕組みが必要になる
-
このような文脈情報をコンピュータの世界では「コンテキスト(Context)」と呼ぶことが多い
例:FTPでは、ログイン中のユーザー名やカレントディレクトリなどの情報がコンテキストとしてFTPサーバーに保持される。
ステートフルプロトコル例
- FTP(File Transfer Protocol)
- Telnet
- SMTP(セッションの中でコマンドを連続的に処理するため)
- POP3(セッションを通してメールをやりとりする)
ステートレスとは
- 状態(セッション)を維持しない通信方式であり、各リクエストが独立して処理され、サーバ側は過去のリクエストやユーザーの状態を保持しない
例:WebブラウザからHTMLファイルをリクエストする際、サーバーはその都度、ファイルを返すだけで、前回のリクエストとの関連性を認識しない
ステートレスは、人間のコミュニケーションでいうと「手紙」のやり取りに似ている。
各手紙は独立した内容であり、前回のやり取りを知らなくても成り立つ。
ステートレスプロトコル例
- HTTP(Hypertext Transfer Protocol)
- DNS(Domain Name System)
- DHCP(Dynamic Host Configuration Protocol)
- SNMP(Simple Network Management Protocol)
- REST API
Cookieとは
Cookieとは、サーバーとクライアント間で状態を保持するために考案された仕組みです。
主に、ユーザーの識別やログイン情報の保存などに使われます。
なぜCookieが必要なのか?
HTTPはステートレスなプロトコルのため、Webアプリケーション上で以下のようなニーズを満たすためには、アプリケーション側で独自に状態管理する仕組みが必要です。
- ログイン状態の維持
- 同じユーザーからのアクセスの識別
- ショッピングカートの保持
これを解決するために登場するのが、Cookie(クッキー)
Cookieの基本的な流れ
- クライアントがWebサーバーに初回リクエスト
- サーバーがレスポンス時に
Set-Cookieヘッダーでクッキーを発行 - クライアント(ブラウザ)はそのクッキーを保存
- 次回以降、同じサーバーにリクエストを送る際、保存していたクッキーを
Cookieヘッダーに含めて送信
Cookieの構造とヘッダーのやり取り
サーバー → クライアント:クッキーの発行
Set-Cookie: sessionId=abc123; Path=/; HttpOnly
クライアント → サーバー:クッキーの送信
クッキーの特徴
- 名前=値 のKey-Value形式
- 複数のクッキーを送る場合、Set-Cookieを複数行使用可能
Cookieの利用例:クライアントの識別
典型的な流れ
-
サーバーがクライアントに対して識別用のトークン(例:user_id)を発行し、Set-Cookieでクッキーとして送信
-
クライアントがそのクッキーを保存
-
次回以降のアクセス時にそのクッキーを含めてリクエスト
-
サーバーはクッキーを参照し、クライアントを識別する
現実社会でいうと、「受付番号札」のようなイメージ。
番号札を渡された人が次に窓口に来た時、店側はその番号で誰かを識別できる
「同じサーバー」にクッキーを送る条件
クッキーは「同じオリジン」のリクエストに対してのみ送信される
オリジン(Origin)とは?
オリジンは以下3つの組み合わせで構成されます。
-
スキーム(例:http / https)
-
ホスト(例:example.com)
-
ポート番号(例::3000)
ポイント
オリジンがすべて一致している場合に限り、クッキーは自動的に送信されます。
これにより、セキュリティを保ちつつ状態を管理することができる
Set-Cookieヘッダとは?
Set-Cookieヘッダは、サーバーがクライアントにクッキーを設定するためのレスポンスヘッダ
基本形式
Set-Cookie: 名前=値; 属性名1=値1; 属性名2=値2; ...
属性を使うことで、クッキーの有効期限や送信条件などを細かく制御可能
RFC6265で規定されているCookie属性
| 属性名 | 用途 |
|---|---|
Expires / Max-Age
|
有効期限を設定(Max-Ageが優先) |
Domain |
クッキーを送るドメインの指定 |
Path |
クッキーを送るパスの指定 |
Secure |
HTTPS通信時のみクッキーを送信 |
HttpOnly |
JavaScriptからのアクセスを禁止(セキュリティ対策) |
1. Expires / Max-Age(有効期限)
- クッキーの有効期限を指定する属性
-
Expiresは 日時 で指定、Max-Ageは 秒数 で指定する - 両方設定されている場合、Max-Ageが優先される
特殊な設定
-
0または 負の数 を指定すると、即座に期限切れとなる - クッキーを削除したい場合は、以下のようにする
Set-Cookie: sessionId=; Max-Age=0; //0の部分はマイナスでも良い
セッションクッキー
-
ExpiresやMax-Ageも 未設定の場合は、「セッションクッキー」になる - セッションクッキーは、基本的にはブラウザ終了時に削除されるとされますが、
- 近年のブラウザは完全にはこの仕様に従わないこともある
2. Domain(送信先のドメイン)
- クライアントがどのドメインにアクセスしたとき、クッキーを送信するかを指定する
- 通常は 指定しない のが安全(必要最小限のドメインにのみ送信させるため)
デフォルト挙動
-
Domain属性が省略された場合- 発行元と完全一致するドメイン に対してのみ送信される
指定した場合の例
Set-Cookie: id=123; Domain=example.com;
| ケース | 発行元ドメイン | Domain属性 | アクセス先 | クッキー送信されるか? | 理由 |
|---|---|---|---|---|---|
| 1 | example.com | Domain=example.com | example.com | される | 自ドメインなのでOK |
| 2 | example.com | Domain=example.com | www.example.com | される | サブドメインにも送信される |
| 3 | www.example.com | (未指定) | www.example.com | される | 完全一致でOK |
| 4 | www.example.com | (未指定) | example.com | されない | サブドメイン→親は不可 |
| 5 | www.example.com | Domain=example.com | www.example.com | される | Domain指定により送信される |
-
Domain属性を指定すると、サブドメインにも適用範囲が広がる -
ただし、上位ドメインのクッキーをサブドメインから発行する場合は、明示的にDomain=example.comを指定する必要がある(省略すると完全一致のみに適用)
3. Path(送信先のパス)
- クッキーをどのパスに対して送信すべきか指定
指定した場合の例
Set-Cookie: token=abc; Path=/admin;
- 上記の場合、
/admin配下のページ(例:/admin/dashboard)にアクセスしたときだけクッキーが送信される
| リクエスト送信先(パス) | Path属性 | クッキー送信されるか? | 理由 |
|---|---|---|---|
| /admin/page.html | /admin | される |
/admin直下なのでOK |
| /admin/sub/page.html | /admin | される |
/admin配下なのでOK |
| /dir/page.html | /admin | されない |
/adminで始まらないから |
| /dir/sub/page.html | /admin | されない | 同上 |
| /other/page.html | /admin | されない | 同上 |
4. Secure(HTTPSのみ送信)
-
Secure属性を付与すると、HTTPS通信時のみクッキーが送信される
注意点
- 平文HTTPでは送信されない
- サイト全体がHTTPSで保護されているのが現在の標準
- 特別な理由がない限りSecure属性は付ける
- 値は不要で、属性名のみを記述
5. HttpOnly(JSからのアクセス制限)
-
HttpOnly属性が付与されたクッキーは、JavaScriptからアクセスできなくなる - 主にXSS(クロスサイト・スクリプティング)対策として使われる
- JavaScriptの
document.cookieで取得できなくなり、クッキーの盗み見や不正送信を防止する - 特別な理由がない限りHttpOnly属性は付ける
- 値は不要で、属性名のみを記述
まとめ
一旦ここまでの内容をまとめます
URLとは
- Web上の場所を表しており「住所」のようなもの
HTTPメソッド
- Webサービスを作成する時にクライアントからサーバにリクエストする時、「このリクエストでなにをするのか?」指示するメソッド
-
GETPOSTDELETEなど
HTTPリクエスト
- クライアントからサーバに対して操作をお願いすること
- ヘッダにはHost,User-Agent,Accept,Cookieなどを使う
HTTPレスポンス
- リクエストを受けたサーバがクライアントに対して返信すること
- ステータスやヘッダをつけ、レスポンスボディにはHTML等を返す
プロトコル・ポート番号
- プロトコル:メットワーク上でデータをやり取りする際のルール
- ポート番号:コンピュータ内の窓口(港や、桟橋のようなイメージ)
ステートフル
- プロトコルによって通信の開始と終了の状態(セッション)が管理されている
- FTPやSMTPなどのプロトコル
ステートレス
- 状態(セッション)を維持しない通信方式。サーバ側は過去のリクエストやユーザー状態を保持しない
- HTTPやDNSなどのプロトコル
Cookie
-
状態を持たないステートレスのプロトコルでサーバとクライアント感で状態を保持するために作られた仕組み
下記の状態をアプリケーション上で保持するために使われる- ログイン情報
- 同じユーザーからのアクセス認識
- ショッピングカートの保持
-
名前=値 のKey-Value形式で設定する
-
同じオリジンのリクエストのみ送信される
-
オリジン(Origin)とは
- スキーム(例:http / https)
- ホスト(例:example.com)
- ポート番号(例::3000)
これら全てが一致している場合に限りクッキーは自動的に送信される
-
Set-Cookieヘッダはサーバーがクライアントにクッキーを設定するためのレスポンスヘッダ。属性に値を設定することでクッキーを送信するDmainPathを絞ることができる基本形式
Set-Cookie: 名前=値; 属性名1=値1; 属性名2=値2; ...
応用
ここからは応用編です。時間があるひとは読んで下さい
でも、読んだらみんな「なるほど!!役に立つ〜」ってなることは私が保証します!!
フレームワークの裏側を知るべき理由
フレームワークを使った開発のメリット
-
初心者でも開発可能
Webの仕組みを深く理解していなくてもWebアプリケーションを作れる -
開発効率の向上
典型的な機能を自作する必要がなく、コード量を減らせる(=車輪の再発明を避けられる) -
品質の担保
実績あるフレームワークは、セキュリティやパフォーマンスなどの品質が高く、安心して利用できる
フレームワークを使った開発のデメリット
-
依存リスク
フレームワーク任せの開発だと、トラブル時に原因特定や修正が難しくなる -
技術の流行り廃り
新しいフレームワークが登場すると、古いものは使われなくなる可能性がある -
設計の制約
フレームワークの設計思想に従う必要があり、自由度が下がる
なぜ裏側を理解する必要があるのか?
- 問題発生時に「なぜ起きているか?」を把握し、自分で対応できるようになるため
- フレームワークが隠している仕組み(ルーティング、状態管理、描画の仕組みなど)を理解することで、より柔軟で本質的な開発が可能になる
SPAとは
主にブラウザの画面遷移に起因する操作性や応答性の悪さを克服したWebアプリケーションの一体型。
単一のWebページで構成され、HTML全体の再読み込みを極力廃止して表示を切り替える。
SPAの仕組み
- HTML全体を再読み込みせずに画面の一部だけを更新する
- 非同期通信でサーバーにアクセスする
例:地図アプリの場合
- 従来は、ユーザーが見たい方向のボタンを押すと、次のエリアの画像をまるごとダウンロードして再描画していた
- しかし、Google Mapsなどでは、マウスによるドラッグ操作を検知し、現在の地図画像を動かす
- 動かした余白部分に必要な画像を、JavaScriptがサーバーへリクエストして埋め込む
- 地図画像は多くのタイルに分割されており、必要な分だけを取得・描画すれば良い
- 並列処理により、ユーザーを待たせないスムーズな表示切り替えを実現
なぜSPA(Single Page Application)が人気になったのか?
Webアプリケーションの進化
- 現代では、ショッピングサイト・予約サービス・金融系・SNS・業務システムなど、幅広くWebアプリが使われている
- 利用者のニーズが高まり、**UX(ユーザー体験)**がますます重要になった
従来型のWebアプリの問題点
1. 画面遷移が遅い
- 例えば、Todoアプリでタスクを1つ追加するだけでも、裏ではHTMLの再生成・再描画が行われている
- データ数が増えたり、UIが複雑になると表示処理に時間がかかり、ユーザー体験が悪化する
2. 変更のたび画面遷移が発生する
- Todoを編集するだけでも、編集画面に遷移し、保存後に再び元の画面へ遷移という2ステップ(画面遷移2回) が必要になる
3.サーバー通知に弱い
- 従来のWebアプリは、サーバーからの通知ができない
- 例:スマホで編集した内容がPCにリアルタイム反映されない(手動でリロードが必要)
- 原因はHTTP通信がクライアントに任せっきりであるため
- サーバーが情報をプッシュすることができず、リアルタイム性が乏しい
SPAの利点
- ページ全体の再読み込みをせず、必要なデータだけを非同期で取得・描画できる
- 編集や追加などの操作も画面遷移なしで完結し、スムーズな操作体験が可能
- WebSocketやSSEなどの技術と組み合わせることで、サーバー発信の通知も実現可能
初期のSPAアプリの問題
検索エンジンとの相性の悪さ(SEO)
- JavaScriptを実行するまでページの中身がわからない
- WebクローラーがHTMLを解析できず、SEO不利
- 例:
/items#item-aや/items#item-bのようなURLでは、検索結果に個別ページが表示されない
→ 本来は/items/item-aや/items/item-bにするべき
初期表示の遅さ
- 単純なサイトはVanilla JSで済むが、本格的アプリはフレームワークやライブラリが必要
- それにより、JavaScriptの読み込み・実行に時間がかかる
- データを非同期通信で取得するため、ユーザーが画面を見られるまで数秒かかる
- 商業サイトではこの数秒がユーザー離脱の原因になりうる
- DOM APIを使用し情報を非同期でサーバーへ問い合わせる
- 複雑なアプリなら通信が複数回発生してページ表示までに時間がかかる
対策:URLが検索エンジンに表示されるようにするには?
1. aタグで画面遷移せずにURLだけ変更する
2. History API を使ってURLだけ変更する
3.サーバーサイドレンダリング(SSR)
サーバーサイドレンダリングHTMLをサーバー側で生成し、クライアントに返す仕組み
処理の流れ
- 初回リクエスト時、サーバー側で必要な情報を取得し、HTMLを生成。
- 完成されたHTMLをクライアントに返す。
- クライアントではJSが動き出し、SPA的な動きが可能に。
メリット
- 初期表示が高速
- SEO(検索エンジン対策)に強い
- 通信回数が減るため軽量
デメリット
- サーバーがJS以外(PHP, Rubyなど)の場合、実装が複雑
- 表示処理がクライアント・サーバーに分かれることで開発コストが増える
JavaScriptがサーバーでも使える時代へ
- Node.jsの登場により、JavaScriptをサーバー側でも実行可能に
- 表示処理を クライアントとサーバーで共通化できる ようになった
- SSRがより現実的に導入しやすくなった
SSRに使われる主なフレームワーク
| フレームワーク | ベース技術 | 特徴 |
|---|---|---|
| Next.js | React | ReactのSSRフレームワーク。豊富な機能と開発体験の良さが魅力 |
| Nuxt.js | Vue.js | VueのSSRフレームワーク。構成がシンプルで学習コストが低い |
SPAとSSRの比較まとめ
| 項目 | SPA | SSR |
|---|---|---|
| 初期表示速度 | 遅い(JS実行が必要) | 速い(HTMLを即時表示) |
| SEO対応 | 弱い(HTMLに中身がない) | 強い(HTMLが最初からある) |
| 開発の複雑さ | シンプル | やや複雑(共通コードや構成が必要) |
| JSへの依存度 | 高い | 中程度 |
| 使用フレームワーク | React, Vue + SPA構成 | Next.js, Nuxt.js |
API(Application Programming Interface)
プログラム同士がやり取りするための取り決め
APIを使うメリット
- 製造効率が良い
- 品質を上げやすい
- 部品の交換がしやすい
例:電化製品の部品
- 部品同士の接続方法(ネジのサイズや電子部品のコネクタ形状)を決める「インターフェース」が重要
- インターフェースさえ一致していれば、中身を詳しく知らなくても接続・交換できる
ソフトウェアのAPI
- ソフトウェアも部品(コンポーネントやライブラリ)の集合体
- APIは部品を呼び出す名前、引数、返り値の取り決め
- 裏側の実装を知らなくても使える
API設計の考え方(設計思想)
SOAP
- Web技術でRPC(遠隔手続き呼び出し)をXML + HTTPで実現しようとした
- 仕様が厳密で重く、小規模アプリには導入しにくい
REST
- Webの成功要因となったシンプルなアーキテクチャ
- 軽量で柔軟性が高い
API公開で広がるWebの世界
例:Todoアプリの一覧取得APIを他アプリが利用可能になる
クロスサイト通信と同一オリジンポリシー
- 異なるドメイン間でAPIを呼ぶことを「クロスサイト通信」という
- ブラウザはセキュリティのため「同一オリジンポリシー」を持つ
- 異なるオリジン間でのJavaScriptからのデータアクセスは制限され、CORSエラーとなる
同一オリジンポリシーが必要な理由
例:銀行の口座残高を取得するAPIを公開すると、ログイン中のユーザーに対して便利な機能を提供できる。
しかし、同一オリジンポリシーがなかった場合、次のような危険が起こる:
- 悪意のあるサイトが、ログイン中のユーザーの**セッション情報(クッキー)**を利用できてしまう
- 銀行のAPIに勝手にアクセス
- 口座情報を盗み取るような攻撃が可能
上記のような悪意のある攻撃から大切な情報を守る仕組み
しかし、外部からAPIを使って処理するようなときには障壁となる
CORS(Cross-Origin Resource Sharing)
- クロスオリジン通信を許可するための仕組み
- ブラウザはAPI呼び出し前に「プリフライトリクエスト」(HTTP OPTIONSメソッド)で許可を確認する
- サーバーは適切なヘッダを付けて許可を返す必要がある
別のサイトのリソースがあなたのサイトにアクセスを要求していますが、構いませんか?と事前確認。
プリフライトリクエストの省略条件(シンプルリクエスト)

出典:小森裕介著『[改訂新版]プロになるためのWeb技術入門』より
-
HTTPメソッドが GET, POST(HTMLメソッド範囲), HEAD のいずれか
- GET、HEADメソッドでは送信してもサーバーに影響を与えない
- HTMLフォームから送信される範囲のPOSTリクエストでクロスオリジンリクエストが許容されているのは互換を重視している
- HTMLのフォームはCSRF(クロスサイトリクエストフォージュリ)対策がされていることを前提
-
送信ヘッダが特定の安全なものだけ(例:Accept, Content-Typeなど)
-
Content-Typeが
application/x-www-form-urlencoded,multipart/form-data,text/plainのいずれか
この条件を満たすとプリフライトリクエストは送られず直接リクエストができる。
サーバー側の対応
- OPTIONSリクエストに対応してCORS許可ヘッダを返す
- これをしないとブラウザはクロスオリジン通信を拒否する
APIの粒度について:RESTとGraphQLの比較
RESTful API(粒度が細かい)
特徴
-
URLでリソースを表現する
- 例:
-
/users→ ユーザー一覧 -
/users/123→ ID=123のユーザー詳細
-
- 例:
-
HTTPメソッドで操作を指定する
-
GET: データ取得 -
POST: 新規作成 -
PUT: 更新 -
DELETE: 削除
-
-
単一責任・リソース志向
-
GET /articles→ 記事一覧 -
GET /articles/1→ 特定記事の詳細
-
RESTのデメリット(粒度が細かすぎる問題)
例:3日間の予約リクエスト
//空き情報確認
GET /reservations/20240501/room123
GET /reservations/20240502/room123
GET /reservations/20240503/room123
//予約
POST /reservations/20240501/room123
POST /reservations/20240502/room123
POST /reservations/20240503/room123
問題点
解決策
- 目的ベースのAPI設計にする
- まとめて予約できるようなAPIを作る
//より適切なAPI設計例
//POST /reserve
//Content-Type: application/json
{
"reserveRequest": {
"from": "2024-05-01",
"to": "2024-05-03"
}
}
//※REST full APIでは無い
オーバーフェッチ・N+1問題(RESTの課題)
REST設計に忠実な実装例
//GET /todos/
{
"todos": [
"http://example.com/todos/1",
"http://example.com/todos/2"
]
}
問題点
- オーバーフェッチ:不要な情報まで取得
- アンダーフェッチ:必要な情報が不足
- N+1問題:1件取得後(一覧)、N件個別(詳細)に取得が必要
- 多くのリクエストが必要かつ1つづつ重いデータのやり取りすることになる
解決
- 表示用途に特化したAPIを用意する
//UI向けAPI例
//GET /todos/listview
[
{
"id": "1",
"title": "買い物",
"deadline": "2024-06-01"
},
{
"id": "2",
"title": "原稿提出",
"deadline": "2024-06-05"
}
]
しかし、用途ごとにAPIを作成する必要があるため同じようなAPIを作る必要がある
→ 将来を考えて多くの情報を返すAPIを作成する
→ オーバーフェッチングになる
→ 用途ごとにAPIを作成。同じようなAPI増える
※以後繰り返し(堂々巡り)
GraphQLによる柔軟なデータ取得
特徴
- クライアントが必要な項目だけを指定可能
- 単一のエンドポイントで多様な用途に対応
- SQLとGraphQLは同じ位置づけ
- SPLは表形式で表示されたデータ対象
- GraphQLはプログラミング言語で扱うオブジェクト対象
- 扱うデータ構造はスキーマと呼ばれる形式
- スキーマに対して問い合せパターンを定義しておく。これをクエリという
GraphQLスキーマ例
type TodoItem {
id: ID!
todo: String!
detail: String
deadline: String
status: Boolean!
}
type Query {
todos: [TodoItem!]!
}
クエリの例(クライアント側)
query {
todos {
id
todo
deadline
status
}
}
Mutation(データ追加)
mutation {
addTodo(
todo: "勉強する"
detail: "GraphQLのMutationについて"
deadline: "2025-06-01"
status: false
) {
id
todo
status
}
}
| 種類 | 意味 | RESTでの対応 |
|---|---|---|
| Query | データを「取得」する操作 | GET メソッド |
| Mutation | データを「変更(追加・更新・削除)」する操作 | POST、PUT、DELETE など |
-
GraphQLでは、型のあとに !を付けることで「必須(Non-Null)」という意味を持たせる
-
UIに必要な項目のみ取得
-
N+1問題やオーバーフェッチを回避
REST vs GraphQL 比較
| 項目 | REST API | GraphQL |
|---|---|---|
| エンドポイント設計 | 複数必要(用途別) | 単一(/graphql) |
| データ取得方式 | 固定レスポンス | 必要な項目だけを選択して取得可能 |
| 操作 | HTTPメソッド(GET, POST など) | Query / Mutation |
| オーバーフェッチ問題 | 起きやすい | 原則なし |
| フロント主導の柔軟性 | 低い | 高い |
| 用途に合わせた拡張性 | エンドポイントごとに追加が必要 | スキーマを拡張すれば対応可能 |
-
REST:リソース志向でURL設計が明確。シンプルだが用途別にAPIを多数作る必要あり
-
GraphQL:柔軟でフロントエンド主導の開発に向いている。オーバーフェッチ・N+1問題も回避可能
-
使い分けが重要:システム規模やチーム構成、要件に応じて選定するのがベスト
-
RESTがカバーしきれない部分を埋めようとしているGraphQLという関係がある
サーバープッシュ(Push型通信)
昔のWeb(WWW)は「Pull型」だった
昔のWebは、ユーザーがページを再読み込みしないと新しい情報が表示されませんでした。
これはHTTPの仕組み上、ユーザー(クライアント)からのリクエストに対してサーバーが応答する「Pull型」の通信だったためです。
メタリフレッシュ(擬似的なPush)
- HTMLの
タグを使って、一定時間ごとにページを自動でリロードする方法 - これも実質的には「Pull」で、ページを定期的に更新しているだけの擬似的なPush通信
問題点
- 毎回サーバーへアクセスするため無駄な通信が多い
- ページ全体がリロードされるのでユーザー操作が中断されてしまう
対策と進化
キャッシュの活用
- 一度取得したデータをブラウザに保存(キャッシュ)しておくことで、毎回サーバーにアクセスしなくてよくなる
- キャッシュの有効期限を設定し、更新が必要な時だけサーバーにリクエストを送る仕組み
JavaScript(Ajax)によるポーリング
- JavaScriptを使い、一定間隔で必要な情報だけをサーバーから取得する方法
JavaScriptを使ったポーリング例setInterval(update, 5000); function update() { // Fetch APIで必要なデータだけ取得し、画面を更新する }
サーバープッシュ(Push型通信)
- サーバーからクライアント(ユーザーのブラウザ)に自動で情報を送る通信
Comet

出典:小森裕介著『[改訂新版]プロになるためのWeb技術入門』より
- クライアントリクエストが来てもサーバーはすぐ返さず保留にする
- 通知すべきデータが来たらレスポンスを繰り返す
- ユーザーはサーバから瞬時に通知が来るように感じる
問題点
- 頻繁は再接続が必要でポーリングと同じかそれ以上に通信・サーバー負荷が大きい
- 通知が長時間発生しないと、通信がプロキシやブラウザによって勝手に切られる可能性がある
- 接続と接続の合間に発生した通知はすぐ受け取れない
Server-Sent Events(SSE)
- SSE(Server-Sent Events)は、サーバーからクライアント(主にブラウザ)へ、一方向にリアルタイムでデータを送信できる通信方式。
- HTML5から登場し、ロングポーリングの発展形としてHTTPストリーミングを実現できる
SSEの特徴
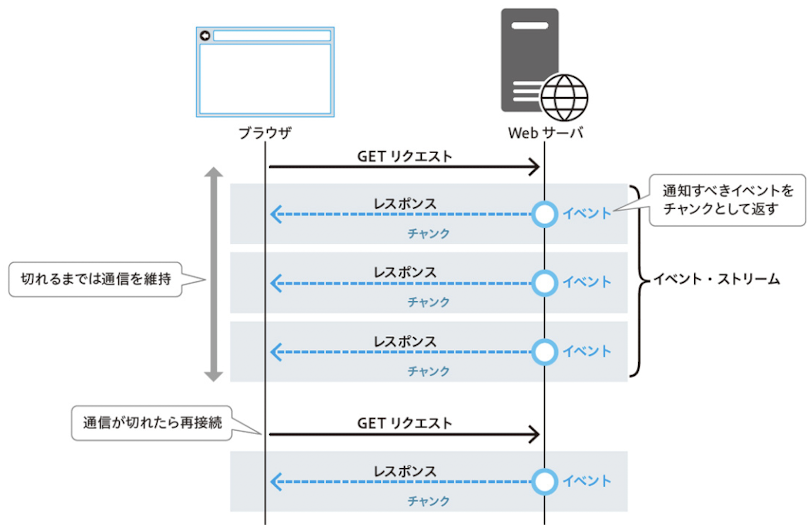
出典:小森裕介著『[改訂新版]プロになるためのWeb技術入門』より
- 一方向通信:サーバー → クライアントへの送信のみ
- HTTPストリーミング:1回のHTTPレスポンスで複数回データ(通知)を送信
-
チャンク転送の利用:HTTP/1.1の
Transfer-Encoding: chunkedを活用 -
接続の維持:
Connection: keep-aliveにより接続を持続 - イベント形式のデータ:イベント+データの形で送信される
-
Content-Type:
text/event-streamを指定することでSSEであることを示す - 軽量・ブラウザ標準サポート:追加ライブラリ不要で利用可能(多くのモダンブラウザで対応)
Server-Sent Eventsでのレスポンスヘッダーの例
HTTP/1.1 200 OK
Connection: keep-alive
Content-Type: text/event-stream
Transfer-Encoding: chunked
チャンク転送とは?
- チャンク(塊)単位でデータを送信するHTTP/1.1の機能
- すべてのデータを準備する前に送信できるため、リアルタイム性に優れる
- Transfer-Encoding: chunked を使用
- チャンクの構造:
通常は、最後に「0」のチャンクを送信して通信を終了します
→ SSEではこの終了チャンクは不要
イベントの形式(サーバー送信)
イベント形式例
event: ping
data: 2023-10-10 22:57:00
| タグの種類 | 説明 |
|---|---|
| id | イベントを識別するためのID |
| event | イベントの種類 |
| data | サーバから通知される情報の本体 |
| retry | 再接続時の待ち時間(ミリ秒) |
クライアント側の受信方法(JavaScript)
JavaScript の EventSource オブジェクトを使用する
const eventSource = new EventSource("/sse-endpoint");
// イベント名が指定されたデータを受信
eventSource.addEventListener("ping", (e) => {
console.log("pingイベント:", e.data);
});
// イベント名がないデータを受信
eventSource.onmessage = (e) => {
console.log("デフォルトメッセージ:", e.data);
};
問題点
- 接続数の制限(HTTP/1.1)
- 同一オリジンに対して 最大6接続 まで
→ 複数のSSE接続があると制限に達する可能性がある
- 同一オリジンに対して 最大6接続 まで
回避策
- ドメインシャーディング(HTTP/2以降)
- サブドメインに分けて同時接続制限を回避
例:sse1.example.com, sse2.example.com
- サブドメインに分けて同時接続制限を回避
※同時接続数の制限はドメイン単位でカウントされる
WebSocket

小森裕介著『[改訂新版]プロになるためのWeb技術入門』より
背景と登場の理由
- 従来のHTTP通信は「クライアントからのリクエスト → サーバからのレスポンス」という一方向通信のみ
- サーバーからのプッシュ通知やチャット・ゲームなど双方向・リアルタイム通信が必要な場面では不十分
- WebSocketは、これを解決するために登場した新しい通信プロトコル
WebSocketの概要
- 双方向通信が可能で、サーバーとクライアントが自由にデータをやり取りできる
- 通常のHTTP通信からプロトコルをアップグレードしてWebSocketに切り替える
- HTTPに比べてヘッダが小さく、通信のオーバーヘッドが少ない
- TCPなどの低レイヤー通信を抽象化したインタフェースに由来する
WebSocketのハンドシェイク
-
クライアントのリクエスト
GET /chat HTTP/1.1 Host: server.example.com Upgrade: websocket Connection: Upgrade Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ== Origin: http://example.com Sec-WebSocket-Protocol: chat, superchat Sec-WebSocket-Version: 13- HTTPのGETリクエストとして始まる
-
Sec-WebSocket-Key: クライアントが生成したランダムな文字列(nonce) -
Sec-WebSocket-Protocol: 任意のサブプロトコルを指定可能(例: chat, gameなど)
-
サーバーの応答
HTTP/1.1 101 Switching Protocols Upgrade: websocket Connection: Upgrade Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo=- ステータスコード
101 Switching Protocolsを返すことでWebSocketへの切り替えを承諾 -
Sec-WebSocket-Accept:Sec-WebSocket-Key+ 固定文字列258EAFA5-E914-47DA-95CA-C5AB0DC85B11をSHA-1でハッシュしてBase64エンコード - これはセキュリティのためではなく、正当なWebSocket通信であることの検証
- ステータスコード
なぜHTTP経由で始めるのか?
- 多くのファイアウォールやプロキシが HTTP/HTTPS(ポート80/443)しか許可していない
- HTTPリクエストとして始めることで、既存のネットワーク機器を通過しやすくなる
- その後、プロトコルをアップグレードしてWebSocket通信に移行
通信が切れた場合の対処法
- 一部ネットワーク機器がアイドル状態の接続を切断することがある
- WebSocketは
Ping/Pongフレームで定期的に接続を維持できる - JavaScriptライブラリ(例: Socket.IO)を使用すれば、自動再接続や切断時のハンドリングが容易
WebSocketのメリット
- サーバー⇔クライアントのリアルタイム双方向通信が可能
- オーバーヘッドが少なく、効率的な通信ができる
ポーリング・SSE・WebSocketの比較表
| 特徴 | SSE | Polling | WebSocket |
|---|---|---|---|
| 通信方向 | サーバー → クライアント | クライアント主導 | 双方向 |
| プロトコル | HTTP(text/event-stream) | HTTP | 独自プロトコル(ws://) |
| 接続維持 | 常時 | 都度接続 | 常時 |
| ブラウザ対応 | 高(IE除く) | 高 | 高(古い環境は非対応) |
| 双方向通信が必要? | ✕ | ✕ | ○ |
| ファイアウォール対応 | ◎(HTTP準拠) | ◎ | △(制限される場合あり) |
最後に
今回私は初めてWeb技術の基礎についてガッツリ学びました。
基礎の基礎だけでもこんなにあります。広いですねWebの世界。
今回学習して思ったことがあります。
それは技術の進化は 『課題 → 改善 → 検証 → 振り返り』の連続で
論理的に進化している。このことを自分の体験(勉強)することにより
身を持って実感することができました。
Web技術を学んだ分だけフレームワークやライブラリは『神』と思うようになりました。
今回のようにアウトプットできるよう、日々インプットを続けます。
最後に、こんな長い記事を最後まで記事を読んでいただきありがとうございます。
参考教材
Views: 0

{kind=link}