
日本時間2025年07月03日(水)、dbtのコミュニティイベント「Tokyo dbt Meetup #15」が開催されました。
オンライン&オフラインのハイブリッド形式で開催された当回、当エントリではオフライン参加した内容を踏まえてその雰囲気などを踏まえてレポートしたいと思います。
なお、当日のつぶやきを以下Posfieでまとめています。合わせてお読み頂くことで当日の雰囲気をより感じて頂けるかと思いますので宜しければどうぞ。
概要情報
イベントページは以下です。
開催会場は株式会社CARTA HOLDINGS。


オフィスからの景色の眺めもよく、またフロアや会場内もとてもおしゃれな場所でした。


今回のテーマは 「dbt × LLM」 となっています。
生成AI(大規模言語モデル)との組み合わせにより、dbtの活用がどのように進化しているのか。
実際に社内で先進的な取り組みを行っている3名のスピーカーをお招きし、
メタデータ活用、開発支援、民主化といった観点からその挑戦を紹介いただきます。
なお、当日のイベントは宮崎一輝さん(stable株式会社 / 代表取締役)司会進行のもと執り行われました。

セッション: dbt民主化とLLMによる開発ブースト
- 登壇者:Shunya Yoshikawaさん(Ubie株式会社 / Data Engineer)

登壇資料はこちら:
- 自己紹介、企業紹介
- Ubieでのデータ利活用とデータ分析基盤の位置付け
- Ubieはデータの会社
- 扱っている事業(医療関連)の背景からも信頼性の高いデータが必須
- データの利活用促進と信頼性の維持・向上がUbieのプロダクトプラットフォームそのものの価値向上に寄与している
1.はじめに dbt,LLMの動向とこれからのUbieデータ分析基盤
革新的なツールの登場で開発環境が激変し、効率も飛躍的に向上している。
公式 dbt MCP Serverのリリース:
AI Coding Agentの発達:
dbt Fusion engine on BigQuery(Public Beta):
Lightdash AI Agentsの登場:
これからのUbieデータ基盤:ADLC全体のEnablingに焦点
- ADLC:The Analytics Development Lifecycle。
- dbt/LLMの進化でdbt開発が加速、データを知っていれば誰でも透過的に開発出来る状態に近づいている
- 分析基盤に求められる責務は『end-to-endの分析ライフサイクル(ADLC)のenabling』。
2.Develop: LLMの積極的な導入
- dbtリポジトリの開発規模遷移から、今後は開発規模を品質高く維持するために、生成AI活用を前提とした開発プロセスの再構築と効率化が必須 と考えている。
- 生成AI活用に関する変遷
- GitHub CopilitやCursor(2024)→Cursor/Devin(2025/01)→Claude Code/Claude Code GitHub Action(2025/06)
- 現在はエディタを開かない開発も普及
- Claude Code Action
- Claude Code GitHub Actions – Anthropic
- token/Vertex AI部分が共通化された社内GitHub Actionをdbt Repoでも利用、issueからのタスク依頼も可能となり、軽微な変更が楽に
- 開発補助:柔軟なReviewと自動修正の導入
- ナレッジの属人化とレビュアー負担を軽減
- 今後はEnd-to-Endなデータパイプラン開発を透過的に進めていきたい
- AIがアクセス出来ない暗黙知やガードレール(Validate, test)の不在による品質低下がボトルネックになる懸念はある。
- ドキュメントの生成と構造化
- ドキュメントもAIで作りたいが、人間にもAIに優しいように体系化したい
- →Diátaxis(ディアタクシス)フレームワークで構造化
- ドキュメントの置き場所:環境・状況に応じて使い分け
3.Plan: Data Contractを起点にした協業
- データに関わる横断的な協業(Plan)
- Data Value Chainと称して定期的、かつ必要に応じて横断的な連携を実施している
- Data Contructの策定
- エンジニアからアナリストへとオーナーシップが移るようなdbt modelの実装時は、GitHub PRで双方が議論し、Data Contructを定めるように開発プロセスを改めた
- Data Contructのこれから
- Planとして全社標準として根付かせつつ、Data Contruct及びPlanの過程で決まった仕様を後続のプロセスにシームレスに接続することが重要
4.Discovery/Analysis: コード管理による効用を最大化
- Discovery/Analysis
- 社内生成内AIエージェント:Dev GeniusやMCP toolからdbt repoを取得、用途に応じたDiscovery体験を構築
- HTML形式のレポートやJupyter notebookでアドホックな分析結果を共有
詳細は下記エントリを参照。
- これからのDicsoveryについて:Garbage in Garbage outの法則は変わらない。LLM & Human Friendlyなモデリングを進めていく
- dbt & LLMの普及で見えたこと
- これからのUbieデータ分析基盤
- フルサイクルエンジニアリングの考えを持ってデータ分析の質・速度を底上げしていく
- Eneblingやドキュメント・メタデータの蓄積はツールが変わっても不変
- dbt MCP tool, AI Agentへの投資は変わらず積極的に行っていく
セッション: dbt モデルをLLMに作らせたい!
- 登壇者: Yuta Hishinumaさん(ちゅらデータ株式会社 / CTO)

2人目の発表はちゅらデータ株式会社CTO、菱沼 雄太さん。
Claude Codeを活用したSnowflakeデータベース上でのdbt開発を実演する様子をデモする内容となっていました。実際のデモ風景は配信アーカイブが公開された暁にご覧頂ければと思います。ここでは当日のX投稿から幾つか抜粋してその雰囲気をお伝えできればと思います。
セッション: ユーザーライクなセマンティックレイヤーの命名を探求してみた
- 登壇者: Kenta Nagatsukaさん(株式会社NTTデータグループ / 主任)

3人目は株式会社NTTデータグループより長塚さん。
-
自己紹介、企業紹介
-
本日お話しすること:
- 近年注目を集める 「自然言語でのメタデータ分析」 において、その回答の質向上に不可欠な メタデータ をどう開発していけばいいか、「設計」「テスト」「運用」の観点で解説。
- dbt-mcpはかなりカスタマイズして使っているのでその理由も合わせて紹介。
-
導入:「AIによる自然言語でのデータ分析」というトレンド
- 従来はデータに対して「直接SQLで見るのはスキル的に難しい」「エンジニアのリソースにも限界がある」という課題がある。これが未来ではAIに自然言語で質問が出来るようになると利用者も喜ぶのでは?
-
そんなときに「メタデータが無い!」という課題が表出
- よくある「メタデータがない場面」
- 引き継いだEXCELのテーブル定義書にカラムの論理名しか書いてない
- データカタログの内容を見に行ったら何も書いてない、整備されてない
- よくある「メタデータがない場面」
-
メタデータ管理の従来と理想の姿
- 「開発者の決め打ちで一方的な管理」から、ユーザーのフィードバックとテストに基づく管理へ
- 知りたかった情報が追加されている、教えた情報が反映されている
設計:テストしやすい設計・ツールとは
- 基本アーキテクチャ:MCP Serverでdbtを利用し、ユーザーの質問に答えるシステム

- インプット:MCPとは
- 実装上:MCP tool用のデコレータを付けて関数を実装、toolをMCP Clientに登録しておくとLLMが必要なタイミングと引数を判断して実行する
- 前提:Semantic Layer越しのクエリ、mart層に対する直接クエリ、両方を許可する仕組みとした。
- まずmerrics(Semantic Layer)があればそちらを使い、無ければmart層に問い合わせ。

- 目標:同じMCPツールをDev(開発環境)でもStg(ステージング環境)/Prd(本番環境)でも使えるようにする
- これを実現出来ると、後段で行うメタデータのテストを”Dev(開発環境)でもやって良い”ことの根拠に出来る。
- 言い換えるとこれが出来ないと「Devと同じ回答がPrdでも得られるかどうか」の保証が難しくなる。
dbt-mcpの概要
- dbt Labs社公式のMCPツール
- dbt CLI(Core/Cloud)、dbt Cloud API系、Remote MCP Serverに対応するツールが実装されている。
- dbt-mcpではdbtのパス指定によってdbt Coreとdbt Cloud CLIの事項を切り替え可能に
- 目指していた目標(Devで動作確認をしながらの開発)が可能に!
#
dbt-mcp:改善して欲しいところ
- MetricFlowを利用するツールが無い:Semantic Layerに関してはDevで動作確認しながらの開発が難しい
- 出力が冗長
- lsツールでの情報取得が荒い
工夫している点を幾つか



テスト:どうやってメタデータをテストするのか
- 「メタデータテスト」の例:Databricks AI/BI Genie(Databricks社が提供するAIデータ分析チャット機能)
-
事前用意した正解SQLとチャットが出したSQLが完全一致ならPass/一致していなければ要レビュー
- 内部ロジックでassertすると、with句の有無などの”SQLの書き方の違い”でも要レビューとなってしまい、エンジニアの負担が増えてしまう。
-
クエリの書き方ではなく、クエリ実行の結果でAssertする方針に変更。


運用:開発時に知り得なかったメタデータをどう扱うか
- リリース前に全ての必要なメタデータを集めることは不可能
- メタデータは一回登録して終わり、ではない
- 運用しながらメタデータを育てていく必要がある
- ユーザーからのフィードバックを集める
- merticsやmart層へのクエリを試みる
- mart層のモデルに関して、ユーザーからの情報提供を求める
- クエリ条件を直接ユーザーに聞く

- メタデータを集める専用のMCPサーバを作成し、チャットで利用
- 会話中ユーザーからの回答が得られた際、その情報をSnowflake上のテーブルレコードとしてinsert、情報収集に用いる。(以下実践例)

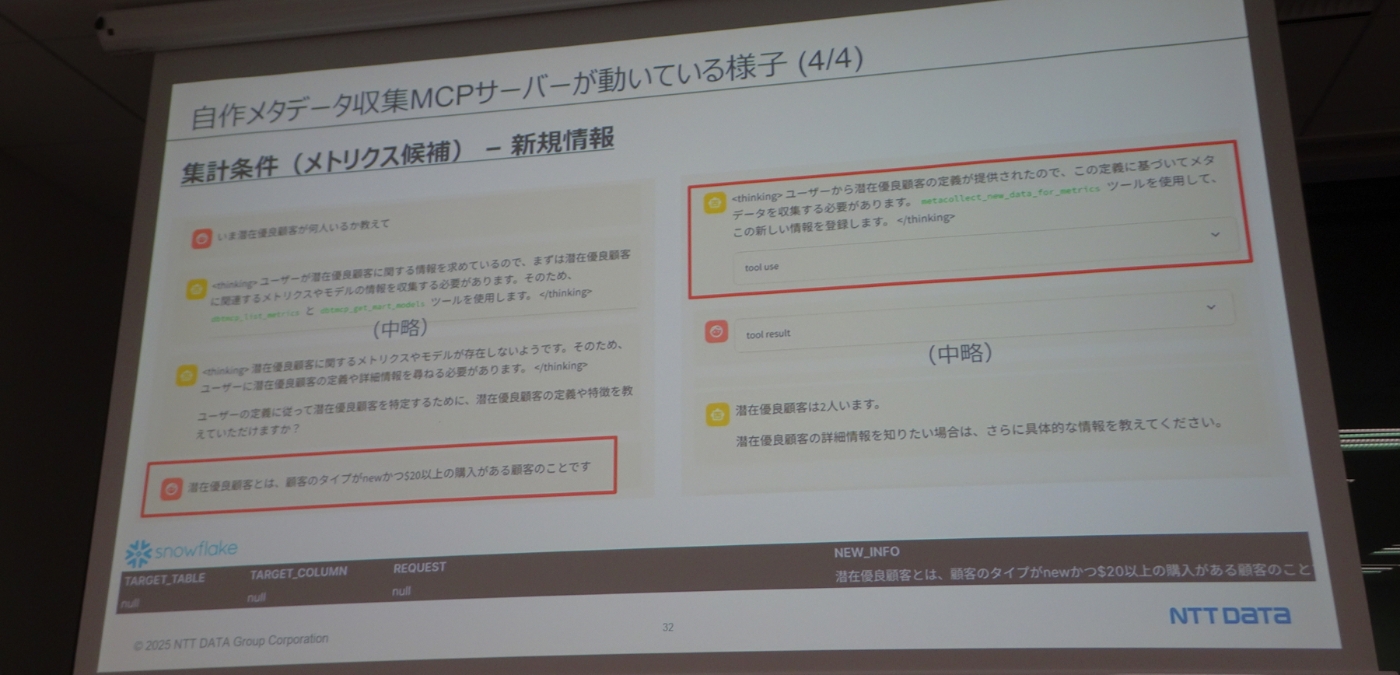
セッションまとめ

交流会
セッション終了後は同じ会場内にてオフライン参加者による交流会(懇親会)が行われました。私自身もオフライン参加でしたのでそのまま参加。オフライン参加者の多くが交流会にも参加し、至るところで会話が盛り上がっておりました。
今回は 「dbt × LLM」 という大変ホットなテーマであり、実際に参加者の関心も非常に高かったように思います。(懇親会での盛り上がりを見てもそこは明らかでした) そして実際に各登壇者の皆さんの発表を拝聴し、ここはやはり「データエンジニアリングにおいてもLLM、生成AI活用はマスト。各種製品と組み合わせて生成AIを併用していかなければこの先生き残っていけないな、ガンガン使っていく方向に進まねば」と興味関心、そして危機感を抱いた次第でした。
また「生成AIを活用する」というアクションは必須である、やっていくべきトピックとして理解をしつつも、「生成AIを活用する対象となる任意のテーマの基礎知識、基本スキルはどのように身に付けていくべきか?そもそもそこすらも生成AI活用によってすっ飛ばす、スキップしちゃっても良いのか?そういう未来が来るのか?」という部分は自分の中でもモヤモヤというか、答えあるいは方向性を見通せていない部分がありました。例えばデータ分析の分野で言えば、「SQLの基礎知識があるユーザーならば、その基礎知識を以て生成AIが作成したSQLをレビューすることが出来るが、SQLの基礎知識が無いユーザーの場合どうするのか?やはりそこは人が(自分で)基本的な部分を学んでおくのは必須なのか、はたまたその必須ステップを生成AIの力を借りて身につけるのか、更には生成AIを使う事で0-1スキルの習得すら不要になるのか?みたいな感じです。
その部分に関しては交流会参加者の方々と幾つか会話をしていくなかで、自分の中でも幾分クリアになってきた気がします。
- データ分析においても生成AI活用は必須。どんどん活用していけるように頑張る。
- 生成AI活用云々の前に、データ分析やデータ分析に関するプロダクトの基礎知識習得は必要か?→勿論必要。そこは人間が頑張る、または生成AIの力を借りて0-1スキルとして習得していく。ここは(現状当面は?)無くならないのでは。
- 基礎をおろそかにしていい、という形にはならない。地道に少しずつでも積み重ねていくのは変わらず大事。
- 基礎知識基礎スキルを身に付けた上で、生成AIの力を最大限活用して「界王拳」の如く高速化、効率化をあらゆる局面で追い求めていく。
というわけで、dbtのユーザーコミュニティイベント「Tokyo dbt Meetup #15」の参加レポートでした。発表のあったセッションのいずれも、データ分析然りdbtの今後の利用が楽しくなる、とても興味深い内容だったと思います。登壇者の皆様、スタッフの皆様、そして会場ご提供頂いた株式会社CARTA HOLDINGS様、ありがとうございました!


Views: 0

{kind=link}