
大規模言語モデル(Large Language Model: LLM)を提供する上で、推論速度は顧客体験を左右する非常に重要な要素です。一方で、LLMのパラメータ数は年々増加し続けており、LLM推論処理速度のボトルネックとなる計算量やRAMとGPUメモリ間のデータ転送時のI/Oボトルネックが実運用上の課題となっています。
ELYZAでは過去に開発したLlama-3.1-ELYZA-JP-70BやELYZA-Shortcut-1.0-Qwen-32BをGoogle Kubernetes Engineに構築した推論基盤上で運用し、顧客やデモ向けに提供しています(2025年7月22日現在)。 いずれのモデルも数百億オーダーのパラメータでOpen Weight Modelとしては中〜大規模なモデルであるため、弊社で運用を始めた当初は推論処理の遅さが問題となりました。一方で、事業上の採算を考慮するとより性能が高いハードウェア(GPUなど)の使用が困難な状態でした。
そこで、同一のハードウェア構成のまま推論処理速度の高速化するため、弊社で運用しているvLLMを用いた推論サーバに対してSpeculative Decodingを適用し推論速度の改善に取り組みました。その結果、推論時のthroughput比較において最大で約1.7倍の高速化を達成しました。本記事では、Speculative Decodingの概要とこれまでの取り組みについて紹介します。
なお、本ブログは芹沢(@seri_k)が代表して執筆しましたが、著者退職のため村山(@zakktakk)が本人許諾の上加筆修正を行い、公開しております。
一般的なTransformerベースのLLMの推論処理は、1回の推論処理毎に次の1 tokenのみを生成する実装になっています。これは直前まで生成されたtokenに基づいて次のtokenを生成するTransformerの自己回帰型の設計によるものですが、この設計により推論処理自体の並列化が妨げられ、throughputの改善が困難です。
LLM推論処理の高速化手法としてはパラメータの量子化が知られていますが、量子化はLLM自体の性能を劣化させる可能性があり、要件によっては採用が困難な場合があります。モデル自体に手を加える以外のソリューションとしては、よりスペックが高いGPUの採用が挙げられますが、LLMの訓練環境とは異なりリアルタイム推論サーバは24時間365日稼働させ続ける必要があるため、サーバを従量課金で利用している場合、GPUアップグレードによるコスト増加は無視できない規模になります。
Speculative Decoding(投機的デコーディング)は前述したような課題に対してLLMの性能を落とさず、かつGPUを含めたハードウェアへの追加投資も無しに推論時のthroughputを改善する方法です。
Speculative Decodingは多くの先行研究が存在しますが、最もベースとなるdraft tokenの生成と検証を行う手法を提唱した論文(Stern et al., 2018)[1] から分かりやすい図解を引用します。
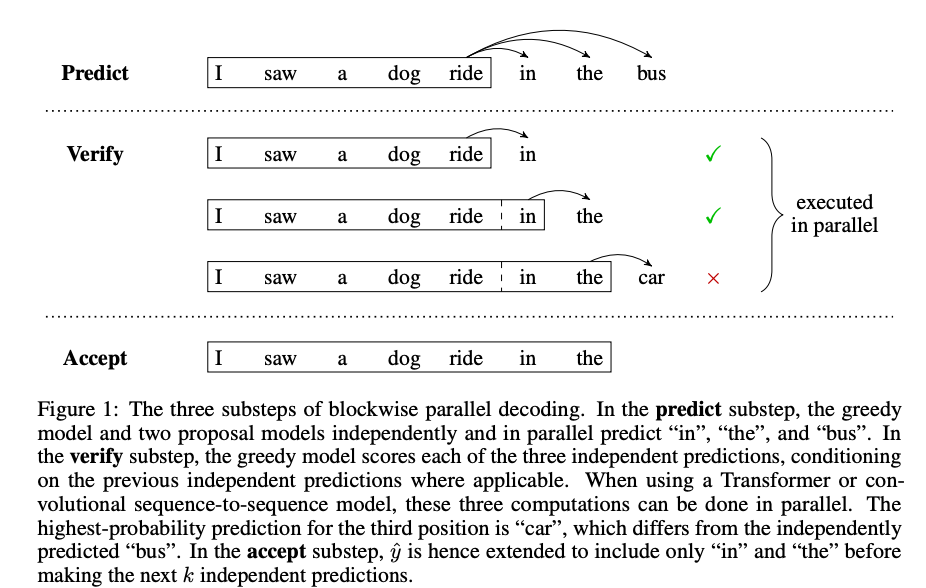
Speculative Decodingは以下の2ステップで構成されます。
1. Draft token生成ステップ
予測済みのtokenに続くtokenを複数個生成します。これは仮決定のtokenであり、一般に draft tokenと呼称されます。つまり最終的に採用されるかどうか確定していない、”draft = 下書き” 状態のtokenです。vLLMやtransformersではdraft modelと呼ばれる軽量なLLMを使用してdraft tokenを生成する手法が実装されています (他にはN-Gramを用いる手法なども存在します。詳しくはvllmのドキュメントをご覧ください)。上記の図でいうところの in, the, bus がdraft tokenに該当します。
2. Draft token検証ステップ
1で生成されたdraft tokenをまとめて入力し、それぞれのdraft tokenの検証を並列に行います。実際に行われる処理はLLMの推論処理と同等ですが、内部で各位置のtokenに対応するlogitsが生成されます。これを利用して、それぞれのdraft tokenのlogitsを用いて得られた確率分布と、target model(= 高速化の対象となる大規模モデル)が生成したlogitsから生成された確率分布を比較することで検証が行われます。
検証アルゴリズムは複数の手法が提案されていますが、例えばシンプルな「一番確率が高いtoken同士を比較する」というアプローチのgreedy decodingにおいては以下のように評価を行います [2]。上記に引用した図のでは以下のように検証が行われます。
- 入力済みの
I saw a dog rideからtarget modelが予測したinは、draft modelのinと一致しているので採択されます - 同様に、draft modelとして入力された
inを含めたI saw a dog ride inからtarget modelが予測したtheも一致しているので採択されます - 一方で、
I saw a dog ride in theから予測されたcarは draft tokenのbusとは異なります。そのためdraft tokenのbusは採択されません - 1,2,3の結果から最終的に最も長く採択された
I saw a dog ride in theまでが正式なtokenとして採択されます
この場合、一度のtarget modelの推論処理で in と the の2 tokenが生成されたことにより、通常の自己回帰型の推論と比べて2倍のtokenを生成することになります。また、追加でtarget modelが修正した car のtokenも同時に得ることが可能です(vLLMではこのように実装されています)。
このようにして1回の推論時間で生成されるtoken数の増加により推論throughputが増加するという仕組みです。確率分布同士の比較によるオーバーヘッドはゼロではありませんが、throughputの増加のメリットが上回れば無視することが可能になります。これは後述する実際の評価実験にて確認しましょう。
なぜ投機的なトークン生成が高速化に寄与するのか
draft modelによるSpeculative Decodingは以下3つの前提によって成り立ちます。
軽量なLLMはGPUの余剰リソースを利用して高速に推論処理ができる
LLMはGPUメモリ上のメモリバンド幅によって推論速度が律速されていることが知られており [1]、GPUの演算ユニット自体には余裕があるケースがあります。軽量なモデルはその分計算量も少ないため、この余裕がある演算ユニットを活用してdraft tokenを生成できます。
簡単な予測においては軽量なモデルでもある程度正確に予測できる
慣用句、冠詞などのある程度簡単に予測できるtokenの予測であれば軽量なモデルでもある程度正確に予測できることが観測によって知られています [2]。そのため、すべてのtokenを正確に予測できなくてもthroughput向上に寄与することが可能になります。
target modelで検証を行うので推論精度が劣化しない
draft tokenの検証はtarget modelが生成する確率分布との比較で行われるのでtarget model本来の推論性能を下回ることが無いことが保証されています。この仕組みにより推論精度の維持とthroughput向上の両立を実現しています。
実験方法
弊社が開発したELYZA-tasks-100データセットを使用し、vLLMに日本語Q&Aタスクを100問推論させるスクリプトを実行します。なおこのベンチマークは独自に実装したものです。推論処理自体の並列度は1で、直列に1タスクずつ推論を実施しています。
計測するメトリクス
上記のスクリプトを実行中に以下2つの数値を計測します。
- Tokens per second: 1秒辺りに出力したtoken数 (以下
TPSと略記します)。 - LLM-as-a-judgeスコア: 各推論結果に対してGPT-4oを用いてLLM-as-a-judgeで定量評価した0から5までのスコア(以下
GPT-4oスコアと表記します)。評価基準はELYZA-tasks-100のeval_aspectをそのまま評価用のプロンプトに埋め込んで使用しています。
実験環境
実験環境は下記の通りです。
Hardware
| machine type | g2-standard-96 |
|---|---|
| GPU | NVIDIA L4 |
| GPU枚数 | 8 |
| 合計GPU memory size | 192 GB |
| vCPUコア数 | 96 |
| 合計RAM size | 384 GB |
Software
| OS | Ubuntu 20.04.6 LTS |
|---|---|
| vLLM version | v0.8.2 |
| torch version | 2.6.0 |
| python version | 3.11.7 |
| NVIDIA driver version | 550.90.07 |
| CUDA toolkit | 12.1 |
主要なvllmパラメータ
| max_model_len | 56000 |
|---|---|
| max_num_seqs | 32 |
| tensor_parallel_size | 8 |
| distributed_executor_backend | ray |
| gpu_memory_utilization | 0.8 |
実験結果
まずベースラインとしてSpeculative Decoding無しで計測を行いました。この時の結果は下記の通りです。ここからどの程度改善していくかを検証します。
| TPS | GPT-4oスコア |
|---|---|
| 18.90 | 4.06 |
draft modelを用いたSpeculative Decoding
Speculative Decodingではdraft modelが投機的に生成するtoken数をvLLM起動時のパラメータnum_speculative_tokensで指定します。今回は2, 4, 6, 8, 10で評価を行いました。また、使用するdraft modelはMeta社が開発している以下3種類のmodelを弊社でFP8量子化したものを使用しました。
実験結果の一覧は以下の通りです。以降で特に注目すべき点についてグラフとともに確認を行います。
実験結果一覧
| draft model | num_speculative_tokens | TPS | GPT-4oスコア | draft token採択率 | 平均draft token生成時間 [ms / token] |
|---|---|---|---|---|---|
| Llama3.2-1B | 2 | 30.11 | 4.03 | 0.68 | 5.66 |
| Llama3.2-1B | 4 | 32.25 | 4.00 | 0.68 | 5.06 |
| Llama3.2-1B | 6 | 31.28 | 3.9 | 0.66 | 5.01 |
| Llama3.2-1B | 8 | 25.79 | 4.01 | 0.65 | 5.16 |
| Llama3.2-1B | 10 | 24.13 | 4.01 | 0.65 | 4.9 |
| Llama3.2-3B | 2 | 29.23 | 4.05 | 0.73 | 8.63 |
| Llama3.2-3B | 4 | 30.84 | 4.03 | 0.72 | 8.45 |
| Llama3.2-3B | 6 | 30.52 | 3.99 | 0.71 | 7.86 |
| Llama3.2-3B | 8 | 26.21 | 4.00 | 0.70 | 7.83 |
| Llama3.2-3B | 10 | 21.51 | 4.09 | 0.67 | 7.87 |
| Llama3.1-8B | 2 | 28.35 | 3.96 | 0.79 | 12.16 |
| Llama3.1-8B | 4 | 28.91 | 4.01 | 0.78 | 11.13 |
| Llama3.1-8B | 6 | 27.29 | 4.05 | 0.77 | 11.68 |
| Llama3.1-8B | 8 | 23.61 | 4.01 | 0.76 | 11.13 |
| Llama3.1-8B | 10 | 21.86 | 4.02 | 0.76 | 11.22 |
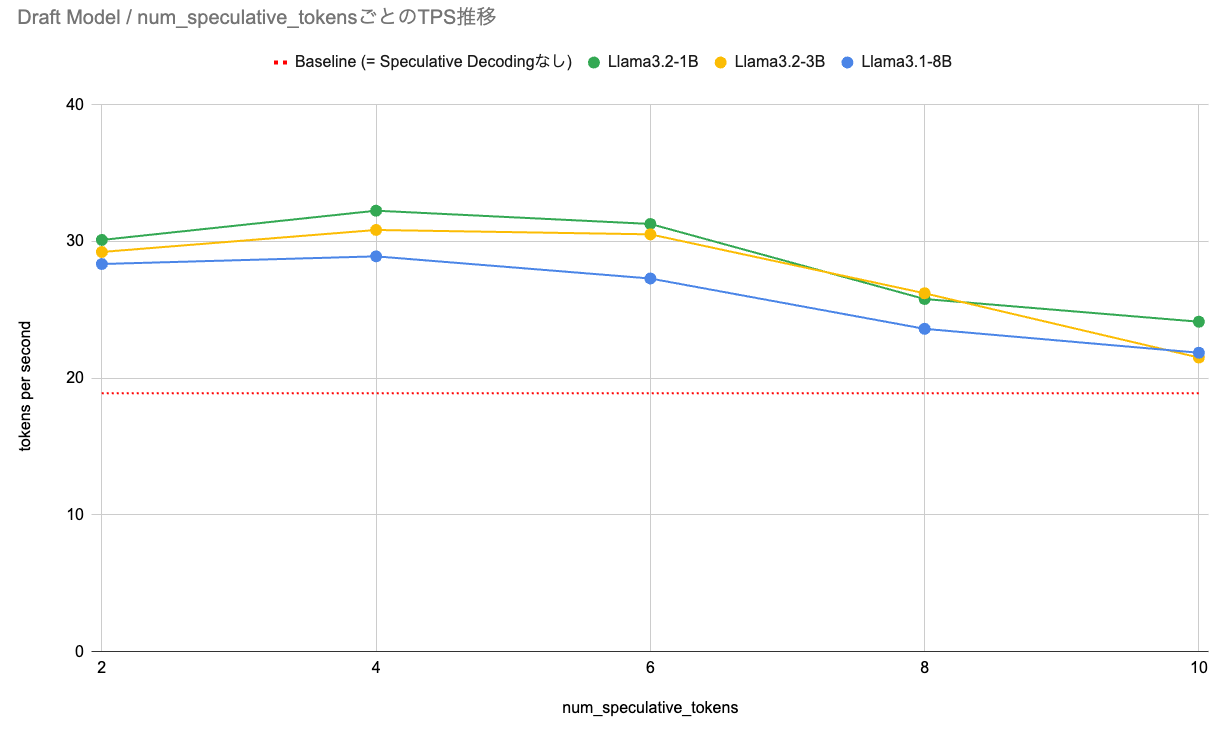
TPSを比較したグラフを以下の図に示します。赤い点線はbaselineを示します。
この図に示す通り、Speculative Decodingを使用したすべてのケースにおいてbaselineを上回っています。その中で、Llama3.2-1Bをdraft modelとして使用し、 num_speculative_tokens=4 のケースで最も高いTPSを記録しました。また、全体を通じてパラメータ数の少ない軽量なモデルをdraft modelで使用する方がTPSが高くなる傾向を示しています。実験結果一覧を参照すると、いずれの実験においてもGPT-4oスコアはbaselineの4.03とほぼ同値であるため、性能を劣化させることなく高速化を実現できていることがわかります。
1 token当たりのdraft token生成時間(ミリ秒)での比較を以下のグラフに示します。パラメータ数が多いほど時間が長い結果となっています。パラメータ数と計算量は相関関係にあるため自明な結果と言えます。

draft token採択率を以下のグラフに示します。パラメータ数が多いモデルほど高い傾向になっており、モデルパラメータ大きくなるほど対象モデルの確率分布に近くなる様子を見て取ることができます。しかし、系列が長くなると分布の乖離は大きくなっていくため、num_speculative_tokensの増加につれて徐々にdraft token採択率が低下している傾向も確認できます。

最終的な評価結果
Speculative Decoding無し(baseline)とdraft Speculative Decodingにおいてそれぞれ最も高いTPSを一覧にしたものを以下に示します。この表に示すように、全く同じハードウェア構成で、推論自体の定量評価を維持しながらTPSを18.90から最大32.25へと改善できました。
| TPS | GPT-4oによる定量評価 | |
|---|---|---|
| Speculative Decoding無し (baseline) | 18.90 | 4.06 |
| draft Speculative Decoding | 32.25 | 4.00 |
考察
num_speculative_tokensごとのTPSの変化について
num_speculative_tokens ごとのTPSの推移を観察すると、2と4のTPSにおいては上昇傾向が見られますが、それ以降は減少傾向が見られます。num_speculative_tokensが大きいほどdraft token採択率は小さくなる傾向があるため、num_speculative_tokensが4より大きい場合はdraft tokenの検証プロセスでの処理時間がdraft token採択によるthroughput向上効果を上回ってしまうことを示唆しています。
draft token生成速度と採択率のトレードオフについて
Llama3.1-1B-Instructモデルをdraft modelとして使用するケースが最も高いTPSを示しました。この理由について考察してみます。
Speculative Decodingがtarget modelの推論速度を高速化できる背景には以下の性能が関与しています。
- draft token生成速度
- draft token採択率
1 draft token当たりの生成時間を比較すると、draft tokenの生成速度においてはLlama3.2-1B-Instructが最も短くなっています。これは、パラメータ数がそのまま推論時の計算量に影響するため、最もパラメータ数が少ないLlama3.2-1Bが最も高速にdraft tokenを生成する結果となっています。
一方で、draft token採択率を比較するとLlama3.1-8B-Instructが最も高く、Llama3.2-1B-Instructが最も低い結果となっています。draft tokenを高速に生成できてもdraft token採択率が低ければTPSは増加しません。採択率の高さはそのままdraft model単体の推論性能に比例するため、同じアーキテクチャのモデル同士での比較ならパラメータ数が多い方が有利になります。要するに、draft tokenの生成速度と採択率の間にはトレードオフが存在します。
| draft modelのパラメータ数 | 少ない | 多い |
|---|---|---|
| draft token生成速度 | 速い | 遅い |
| draft token採択率 | 低い | 高い |
Llamaシリーズにおいては3.2の1Bがパラメータ数が最も少ないモデルですが、例えば仮に0.6B, 0.3Bといったパラメータ数のバリエーションが存在していてそれらをdraft modelとして使った場合、本記事に記載した結果を考慮するとTPSが改善する可能性もありますが、逆にTPSが悪化する可能性もあります。逆に、draft token採択率を高める方向でパラメータ数がより多いモデル、例えば32B程度のモデルを使用したとしても、今度はdraft token生成速度がボトルネックになってTPSが上がらない可能性も考えられます。
また、実運用で使用するタスクの難易度によってもdraft token採択率は変化することが予想されます。今回使用したELYZA-tasks-100に含まれるタスクよりも難しいタスクを使用するようなケースでは、Llama3.1-1Bでのdraft token採択率がボトルネックとなり、Llama3.1-1Bよりも3Bの方が結果が改善する可能性も考えられます。今回は検証していませんが、異なるdatasetを用いて検証した場合はまた違った結果になった可能性も考えられます。
このように、最適なdraft modelの選択においては、前述のトレードオフのバランスを考慮した上で実運用で使用するタスクに近い難易度のプロンプトを用いてTPSを計測しながら探索する必要があります。 弊社では本記事で紹介したアプローチで多数のbenchmark結果を収集して検討を行い、production環境におけるTPS改善を実際に行いました。また、本記事では省略しましたが、draft modelの使用によるGPUメモリ使用量の変化も同時に観測し、運用中の推論サーバGPUメモリのOOMを防ぐためにcontext lengthの調整も同時に行っています。
本稿では、Speculative Decodingの概要と、実例として弊社が提供するローカルLLM推論サーバの推論速度改善の取組みとその効果について説明しました。Speculative Decodingはシンプルな仕組みでありながらもGPUの余剰計算リソースをうまく活用してthroughput改善を実現できる効果的な手段です。本稿で紹介した内容がローカルLLM運用の改善にお役に立てば幸いです。
株式会社ELYZAは、「未踏の領域で、あたりまえを創る」という理念のもと、生成AIの業務活用を支える法人向け生成AISaaSの開発を進めています。ソフトウェアエンジニアはもちろん、機械学習エンジニア、AIコンサルタントなど、様々な職種で一緒に事業を前に進めてくれる仲間を募集しています。詳しくは下記をご覧ください。
- [1] M. Stern, N. Shazeer, J. Uszkoreit, “Blockwise Parallel Decoding for Deep Autoregressive Models,” in Advances in Neural Information Processing Systems, 2018. [url]
- [2] Xia, H., et al, “Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding,” in Findings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 7655–7671. [url]
- Xia, H., et al, “Speculative Decoding: Exploiting Speculative Execution for Accelerating Seq2seq Generation,” in Findings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 3909–3925. [url]
- Charlie Chen, undefined., et al, “Accelerating Large Language Model Decoding with Speculative Sampling,” 2023. [url]
Views: 3

{kind=link}