
1. はじめに
背景として、PDFやDocsなど非構造データからテキスト抽出したい場合、Snowflakeが提供するDocument AIは日本語のサポートができておりませんでした。また、Parse_document関数もOCRモードでは日本語が最適化されていない + Layoutモードでは完全に対応していないという状況であり、日本語のテキスト抽出するのが非常に困難でありました。従来、Snowflakeでは簡単な非構造化処理であれば、ユーザ定義関数のUDF/UDTFを利用し、Pythonで処理を実行することができました。しかし、Jupyter Notebook上での記述に慣れているデータサイエンスティストの視点からは、UDF/UDTFには柔軟性の欠如やDBに精通しない人には馴染みがないという点で、あまり広く浸透していない印象を受けておりました。また、外部サービスを頼り、AWS Lambda/AWS Bedrockなども利用しておりましたが、AWS特有の権限周りの管理や使用するサービス群が増加する傾向に伴い、学習コストの増加などから非常に面倒な点がございました。そういった課題を解決する一つの機能となるSnowflake ML Jobs は Python 関数をリモート実行としてスケジュール/並列化できる新サービスです。本記事では Snowflake ML Jobs で PDF→PNG 変換を並列実行し、生成された画像を Snowflake Cortex AI の COMPLETE Multimodal 関数で解析してデータを抽出するワークフローを整理しました。ステージ名を test_stage に変更し、外部 API(Bedrock)は使わずに Snowflake ネイティブのマルチモーダル機能だけで完結させています。Snowflake Notebook on SPCS で検証したコードと SQL をそのまま抜粋しながら解説します。以下に全体概要も記載しておきます。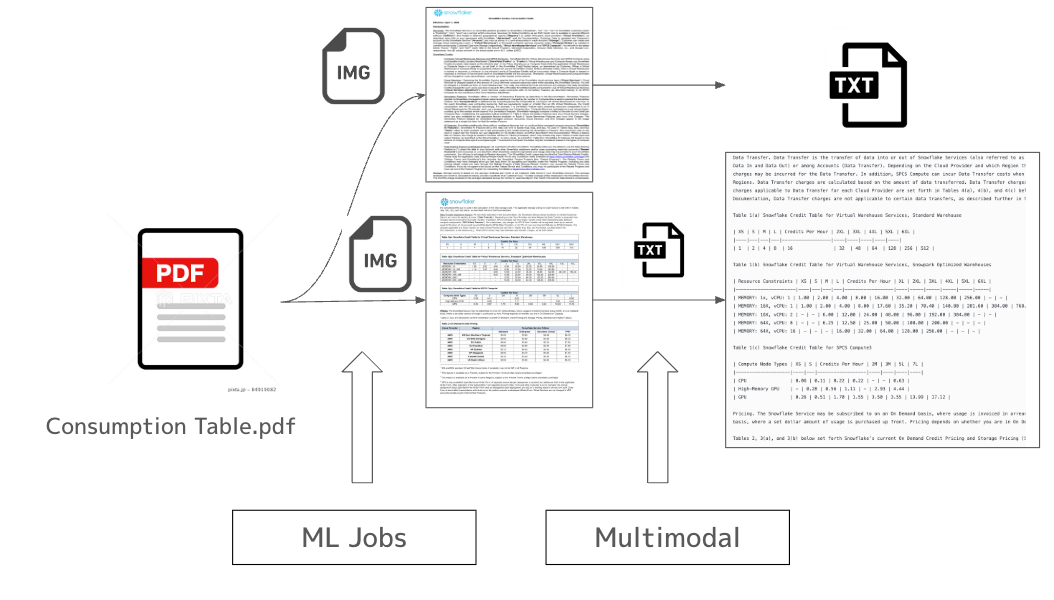
TL;DR
ML Jobs
- Python 関数をremoteメソッドだけで登録が可能 → GPU/大メモリ付き Compute Pool 上で自動スケール実行が可能で、SPCSに必要なコンテナイメージの作成も不要
- Snowflake ML 全体とシームレス統合。VS Code、Cursorなどの好きなIDEからシームレス接続。
- 従来のウェアハウスでは難しかったファイルベースでの処理が容易に実施
- ステージ(ディレクトリテーブル)・権限・外部アクセスを宣言的に添えるだけで再現性あるMLパイプラインを構築
- SPCSでベースで稼動するため、従来のウェアハウスと比較しても非常に安価で完了する可能性がある。(SPCS CPU XSでは0.06クレジット/時間なので最大で1/16倍になる可能性がある)
Complete -MultiModal-
- COMPLETE ひとつの SQL 関数で画像+テキストを同時に処理できるようになり、ステージ上の .jpg/.png などを直接渡して推論可能
- 画像キャプション、分類、比較、エンティティ抽出、グラフ/表 QA まで網羅し、テーブル結合で数百枚をバッチ推論—追加インフラは不要。
- 2025-04 時点で Pixtral Large(GA)や Claude 3.5 Sonnet など複数の視覚モデルを選択可能で、セキュアなガバナンス・課金体系も Snowflake に統合
2. 前提と環境構築
2-1. 専用ステージの作成
まずは PDF を置く内部ステージ @test_stageとML Jobsで利用する@payload_stageを作成します。Snowflake SSE 暗号化を指定している点がポイントです。
CREATE OR REPLACE STAGE test_stage
ENCRYPTION = (TYPE = 'snowflake_sse');
CREATE OR REPLACE STAGE payload_stage
ENCRYPTION = (TYPE = 'snowflake_sse');
2-2. コンピュートプールの作成
ML Jobs は専用プール(例: MY_COMPUTE_POOL)上で動きます。プール作成方法は公式ドキュメントを参照してください。
2-3. 依存ライブラリ
PyMuPDF だけは PyPI から取得するため、PYPI_ACCESS_INTEGRATION を許可しておきます。外部ネットワークアクセスを作成していない場合、こちらを参考にしてください。
3.ML Jobs の実装
3-1. PDFから画像化する関数の作成
以下のコードの通り、関数の冒頭にあるデコレータ @remoteにより、Snowflake に登録され、スケールアウト実行が可能になります。PyPiなどのレポジトリからライブラリをインストールしたい場合、外部ネットワークアクセスと必要なライブラリをパラメータとして与えておく必要があります。なお、pythonファイルを実行するためのメソッドのsubmit_file() やフォルダ内の一括実行するためのsubmit_directory() のメソッドも用意されており、既存のコードからもマイグレーションが非常にしやすいものとなっています。公式ドキュメントも載せておきます。
一点の注意点として、関数内でsnowparkで利用される場合、冒頭に session = get_active_session() を設定することを推奨しています。
from snowflake.ml.jobs import remote
import fitz, os, traceback
compute_pool = "MY_COMPUTE_POOL"
@remote(
compute_pool,
stage_name="payload_stage",
pip_requirements=['PyMuPDF'],
external_access_integrations=['PYPI_ACCESS_INTEGRATION'])
def convert_pdfs_to_images(stage_name, file_name, temp_input="tmp/input/", temp_output="tmp/output/"):
"""
指定されたPDFファイルを画像に変換し、出力ディレクトリに保存します。
Parameters:
- stage_name (str): ステージの名前(例: '@pdf/')
- file_list (list): 変換するPDFファイル名のリスト
- temp_input (str): 入力ファイルを保存する一時ディレクトリのパス
- temp_output (str): 出力画像を保存する一時ディレクトリのパス
Returns:
- dict: 処理結果を含む辞書。例:
{
'success': True,
'output_files': ['CreditConsumptionTable_page_1.png', 'Invoice2025_page_1.png'],
'errors': []
}
"""
session = get_active_session()
os.makedirs(temp_input, exist_ok=True)
os.makedirs(temp_output, exist_ok=True)
file_list = [file_name]
output_files = []
errors = []
for file_name in file_list:
try:
session.file.get(os.path.join(stage_name, file_name), temp_input)
base_name = os.path.splitext(file_name)[0]
doc = fitz.open(os.path.join(temp_input, file_name))
for i, page in enumerate(doc):
pix = page.get_pixmap()
output_filename = f"{base_name}-page_{i + 1}.png"
output_path = os.path.join(temp_output, output_filename)
pix.save(output_path)
session.file.put(output_path, os.path.join(stage_name, 'output_image'), auto_compress=False)
output_files.append(output_filename)
except Exception as e:
error_message = f"エラーが発生しました: {file_name}\n{traceback.format_exc()}"
print(error_message)
errors.append({'file': file_name, 'error': str(e)})
success = len(errors) == 0
return {
'success': success,
'output_files': output_files,
'errors': errors
}
3-2. 一括での適用 & モニタリング
すでに test_stageステージ内にPDFが格納されているという前提として、格納されているPDFを一括実行するために、Snowflakeが提供するディレクトリテーブルの機能を利用しています。これらから取得した情報を3-1で作成した convert_pdfs_to_images 関数に与えることで非同期で実行することが可能です。
stage = '@test_stage'
df = session.sql(
"SELECT * FROM directory(@test_stage) WHERE relative_path LIKE ('%.pdf')"
).to_pandas()
for f in df['RELATIVE_PATH']:
job = convert_pdfs_to_images(stage, f)
また、ステージ内に順次PDFファイルが取り込め、それらを処理したい場合、ディレクトリーテーブルではStreamに対応しているため、そちらの機能と併用することが可能です。こちらの公式ドキュメントによるパイプライン生成方法が参考となります。
3-3. ステータス管理
Jobのステータスは、こちらの公式ドキュメントをご参照ください。下記では、よく使用するコマンドの一覧を記載いたします。
job.id
job.status
job.get_logs()
また一括で取得したいときは下記のコマンドでも処理が可能です。
from snowflake.ml.jobs import list_jobs
print(list_jobs())
デフォルトではML Jobsは非同期処理となっています。もし、AirflowなどのオーケストレーションツールからETLパイプラインを組んでおり、その中で出力結果によってエラーハンドリングを行いたい場合、以下のresultメソッドを使用することで、同期処理することが可能です。
4. Snowflake Cortex COMPLETE Multimodal で画像解析
4-1. COMPLETE Multimodal とは
Snowflake Cortex の SNOWFLAKE.CORTEX.COMPLETE には 画像入力対応のマルチモーダル版 があり、キャプション生成・分類・テーブル/グラフ読み取りなどを SQL 一行で実行できます。2025/4現在では claude-3-5-sonnetと pixtral-largeの二つのモデルが対応済みです。
4-2. 単一画像に対する抽出例
以下の例では、単一画像に対する適用方法を記載しています。なお、TO_FILEは、非構造化データ分析への入力として、テーブルを簡単に作成できる新しい非構造化データ型「FILE」に変換するための機能で、現在プレビュー中です。FILE型を使用すると、内部ステージまたは外部ステージに保存されたファイルへの参照を作成できます。これらの参照は、COMPLETEなどのCortex AI関数を使用してマルチモーダル分析用のテーブルに保存できます
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'pixtral-large',
'入力された画像内にあるテキスト情報を、JSON形式で抽出してください',
TO_FILE('@test_stage', 'consumptiontable-page_1.png')
) AS result;
出力結果の例
Table 1(b) Snowflake Credit Table for Virtual Warehouse Services, Snowpark Optimized Warehouses
| Resource Constraints | XS | S | M | L | Credits Per Hour | XL | 2XL | 3XL | 4XL | 5XL | 6XL |
|----------------------|----|---|---|---|------------------|----|-----|-----|-----|-----|-----|
| MEMORY: 1x, vCPU: 1 | 1.00 | 2.00 | 4.00 | 8.00 | 16.00 | 32.00 | 64.00 | 128.00 | 256.00 | - | - |
| MEMORY: 16X, vCPU: 1 | 1.00 | 2.00 | 4.00 | 8.00 | 17.60 | 35.20 | 70.40 | 140.80 | 281.60 | 384.00 | 768.00 |
| MEMORY: 16X, vCPU: 2 | - | - | 6.00 | 12.00 | 24.00 | 48.00 | 96.00 | 192.00 | 384.00 | - | - |
| MEMORY: 64X, vCPU: 8 | - | - | 6.25 | 12.50 | 25.00 | 50.00 | 100.00 | 200.00 | - | - | - |
| MEMORY: 64X, vCPU: 16 | - | - | - | 16.00 | 32.00 | 64.00 | 128.00 | 256.00 | - | - | - |
4-3. 複数ページを一括で処理
次に以下の一つのクエリで数百ページを並列推論できます。
WITH pages AS (
SELECT relative_path
FROM directory(@test_stage)
WHERE relative_path ILIKE '%-page_%.png'
)
SELECT relative_path,
SNOWFLAKE.CORTEX.COMPLETE(
'pixtral-large',
'入力された画像内にあるテキスト情報を、JSON形式で抽出してください',
TO_FILE('@test_stage', relative_path)
) AS result
FROM pages;
5. 結果の永続化
これで後段の Cortex SearchのようなRAGパイプラインへと接続可能です。
CREATE OR REPLACE TABLE extract_text_raw (
relative_path STRING,
extracted_json VARIANT,
processed_at TIMESTAMP_TZ DEFAULT CURRENT_TIMESTAMP()
);
INSERT INTO extract_text_raw
WITH pages AS (
SELECT relative_path
FROM directory(@test_stage)
WHERE relative_path ILIKE '%-page_%.png'
)
SELECT relative_path,
SNOWFLAKE.CORTEX.COMPLETE(
'pixtral-large',
'入力された画像内にあるテキスト情報を、JSON形式で抽出してください',
TO_FILE('@test_stage', relative_path)
) AS result
FROM pages;
6. まとめ
- ステージ名は test_stage に統一し、PDF から画像への変換を ML Jobs で水平展開。
- Snowflake Cortex の COMPLETE Multimodal を使えば追加インフラや外部 API なしで画像→テキスト抽出が可能。
- 結果を Snowflake テーブルへ保存することで、RAG、可視化、監査ログまで一気通貫。
Snowflake データクラウド上で 「データ取り込み → マルチモーダル AI 推論 → データ活用」 が完結するため、外部にAWS lambdaなどのランタイムを用意することない + 外部 GPGPU を持たない組織でも高度な視覚 AI ワークロードを手軽に運用できます。
Views: 0

{kind=link}