
こんにちは。ナウキャストでデータエンジニアをしているTakumiです。
ついにSnowflake IntelligenceがPublic Previewになりました!!!!!
Snowflake Intelligence触れるようになったので実際に構築してみました!!
実際に作ってみて&触ってみて感じたSnowflake Intelligenceのいいところ、改善してほしいところを共有します。
- Snowflake Intelligenceの初期構築方法
- Cortex Family, Snowflake AI Application FrameworkにおけるSnowflake Intelligenceの立ち位置
- Cortex Analyst, Cortex Search, Cortex Agentの作成方法
Snowflake US West (Oregon) Region
概要編
Snowflake Intelligenceとは、構造化データ・非構造化データの両方を対象として問い合わせ可能なインターフェースを提供するプロダクトです。Snowflake Summit2025にて発表された新機能で、Snowflake の開発思想であるSimplicityと Easyを体現しています。
Cortex Family内での立ち位置
Snowflake IntelligenceはCortex Familyの中でUserと最も近い場所にあるInterfaceの立ち位置にあります。
Snowflakeが丁寧に積み上げてきた、Cortex Analyst、Cortex Search、Cortex Agentを1つのInterfaceで統括して扱えるようになっています。

Snowflake を使ったAI Application Frameworkにおける立ち位置
AI Application Framework全体でも、Snowflake Intelligenceはユーザーが直接操作するインターフェースの役割を担っており、ちょうどReactやStreamlitのようなアプリケーションUI層と同じ立ち位置にあります。

構成要素
Cortex Analyst
概要
Snowflake上の構造化データを自然言語による問い合わせを可能にするAgentシステムです。
構成要素
Semantic Model
AIが組織のデータを理解して、活用するために不可欠なものです。
独自のビジネスロジック、用語の定義をデータに付与するために使用します。
このSemantic ModelをCortex Analystが参照することでビジネスユーザーの意図を読み取って高品質なSQLを作成することが可能になります。
また、Cortex AnalystがSQL生成のために参照するのはデータではなくSemantic Modelであるため、ガバナンスも保たれています。
Snowflake におけるSemantic Modelの立ち位置については、以下の図がわかりやすいです。

Verified Query Repository(VQR)
Semantic Model内に定義できるセクションで、自然言語の質問とその質問に対して正しいことを確認済みのSQLをペアで登録する仕組みです。
Cortex Analystはユーザーの質問がVQR内の質問と似ていると判断した時に、対応するSQLを流用して回答を生成します。
VQRを使うことで生成するSQLの精度向上を図るのはもちろん、以下の様な場面にも有効です。
VQRの活用パターン
| 役割 | 効果 |
|---|---|
|
ドメイン知識の注入点 メトリクスやエンティティでは表現しづらい複雑ロジックを明示的に提供。 |
ビジネスロジックの共有 専門家が承認した計算ロジックを組織横断で再利用。 |
|
ユーザー体験ブースター 似た質問を検知して Suggested Questions を提示。 |
オンボーディング支援 入門者に “まずはこれを聞いてみよう” とガイドを表示。 |
|
ガバナンスフック 検証日時・検証者をメタデータで管理し、監査証跡を確保。 |
データガバナンス強化 ACL を順守した安全な SQL のみを公開し、リスクを最小化。 |
参考文献
Planner
質問を「分類」「特徴抽出」「コンテキスト強化(関連クエリや語彙の検索)」「SQL生成」という複数ステップのエージェントで処理します。生成されたSQLはそのままSnowflakeの仮想ウェアハウスで実行されます。
LLM
Meta LlamaやMistralなどのLLMをSnowflake Cortexプラットフォーム上で稼働させています。
制約・課題
- Semantic Modelの設計にはデータエンジニアリング能力に加えドメイン知識が必要です。
- 大規模、複雑なクエリ、長時間処理には向きません。
Cortex Search
概要
Snowflake内の非構造化データに対して、意味検索・雑な検索を行うサービスです。
RAGに必要な検索エンジンをフルマネージドサービスとして構築できます。
ハイブリッド検索(ベクトル検索+キーワード検索)、Re-Rankingを行って高精度な検索を実現することが可能です。
構成要素
ハイブリッド検索+Re-Ranking
具体的には以下の手順を踏むことで、高精度な検索を実現しています。
- Embedding空間で意味的に類似する文章をベクトル検索で取得
- 表面的に一致する文章をキーワード検索で取得
- Semantic Rankingを行うことで最終的な検索順位を決定
Embeddingsモデル
Embeddingには、Snowflake独自のArctic Embeddingシリーズを使用しています。
具体的には、
- snowflake-arctic-embed-m-v1.5(約1.1億パラメータ)
- snowflake-arctic-embed-l-v2.0(約5.68億パラメータ)
が利用されます。
制約・課題
- トークン長制限
512トークンを超えるチャンクは先頭512トークンのみsemantic retrieval(ベクトル検索とか)される。
※キーワード検索はコンテキスト制限なし - Cortex Searchの実行ロールがオブジェクト所有ロールになること
呼び出しユーザーのロール(invoker)オブジェクト所有ロール(Cortex Searchのowner)で実行されるため、生成結果にマスキングされているはずのデータが入る危険性がある。
参考文献
Cortex Agent
概要
構造化・非構造化データの両方に跨って複数のToolを使って、自然言語による問い合わせに回答します。
Cortex AgentではLRM(Large Reasoning Model)とLLMの二段構えで動作します。
LRMがマルチステップ計画を生成し、LLM(Claude Sonnet 3.5)が自然言語理解、応答生成、リフレクションを担当する交互推論 ループを形成します。
構成要素
Orchestration
自然言語で受けた質問をワークフロー(計画→分割→ルーティング)に沿って、計画を生成し、最適な実行パスを決定します。ワークフローはAgent GatewayとしてSnowflakeが公開しています。
ワークフローの詳細は以下の通りです。
| ステップ | 説明 |
|---|---|
| 計画 | 要求を解析して、複数の実行パス候補を生成。その中から最適なプランを策定。 |
| 分割 | “今年の売上を昨年と比較し、増減が大きかった上位 3 商品について理由を説明して” のような複合クエリを、小さなタスクに分割して並列/逐次実行を最適化。 |
| ルーティング | Cortex Analyst、Cortex Search を自動選択。Custom Tool も登録可能。Custom Tool は Stored Procedure に対応している言語なら実装できる。 |
Tool Use
Orchestrationで生成した計画に沿って、必要なツールを呼び出します。
現在公式サポートされているのは、
- cortex_search
- cortex_analyst_text_to_sql
- sql_exec
- data_to_chart (line, bar)
- Custom Tool
の5つ。
Reflection
各ツールの呼び出し後、得られた結果を自己評価し、コンテキストの修正、追加情報の検索を行います。これを行うことで、回答のハルシネーションを防ぎます。
Cortexでは、一般的なRe-Act、Self Reflection系列の研究を応用したものを使っていて、以下が研究としては合致していそう。
ReAct: Synergizing Reasoning and Acting in Language Models
Self-Reflection in LLM Agents: Effects on Problem-Solving
Monitoring
デプロイ後のLLMアプリケーションの挙動をAI Observabilityで可視化します。
TruLensがSnowflakeに付属していて、トレース収集・メトリクス計算を行ってSnowSight上でダッシュボードを提供します。
具体的な機能は以下の通りです。
| 機能 | 内容 |
|---|---|
| Evaluations | LLM-as-a-Judge による回答の精度・網羅性・コスト・レイテンシー指標を自動計測 |
| Comparison | モデル・プロンプト・ツール構成を横並び比較 |
| Tracing | 各ステップ(入力、検索、生成 SQL、LLM 出力)のフローを可視化し、デバッグ可能な状態にする |
OSSのTruLensを使うと以下みたいなStreamlitベースで、LLMアプリケーションの挙動を確認することができます。
構築編
前提条件
ここからの構築は、
- 利用するデータはSnowflake上のTable, Stage等にPush済みであること
を前提としています。
事前準備
利用データ
今回利用したデータは以下の通りです。
想定としては、家の価格トレンドを構造化データから取り出して可視化してもらい、なぜそのようなトレンドが生まれているのかをFRBの資料から理由づけしてもらうイメージです。
設定環境準備
Snowflake Intelligence用 Role, Warehouse, Database構築
まず、Snowflake Intelligenceを構築するためのRole, Warehouse, Databaseを構築します。
Databaseと後続で構築するSchemaを作成することで、Snowflake Intelligenceの画面を正常に開けるようになります。
use role accountadmin;
create role snowflake_intelligence_admin_rl;
create role snowflake_intelligence_modeling_rl;
create role snowflake_intelligence_ro_rl;
grant role snowflake_intelligence_modeling_rl to role snowflake_intelligence_admin_rl;
grant role snowflake_intelligence_ro_rl to role snowflake_intelligence_modeling_rl;
create warehouse snowflake_intelligence_wh with warehouse_size = 'X-SMALL';
grant usage on warehouse snowflake_intelligence_wh to role snowflake_intelligence_admin_rl;
grant usage on warehouse snowflake_intelligence_wh to role snowflake_intelligence_modeling_rl;
grant usage on warehouse snowflake_intelligence_wh to role snowflake_intelligence_ro_rl;
create database snowflake_intelligence;
grant ownership on database snowflake_intelligence to role snowflake_intelligence_admin_rl;
DECLARE
sql_command STRING;
BEGIN
sql_command := 'GRANT ROLE snowflake_intelligence_admin_rl TO USER "' || CURRENT_USER() || '";';
EXECUTE IMMEDIATE sql_command;
END;
Snowflake Intelligence用 Config Schema、Stageの構築
create schema if not exists config;
grant usage on schema config to role snowflake_intelligence_modeling_rl;
grant usage on schema config to role snowflake_intelligence_ro_rl;
use schema config;
create stage semantic_models encryption = (type = 'SNOWFLAKE_SSE');
grant read on stage snowflake_intelligence.config.semantic_models to role snowflake_intelligence_modeling_rl; grant read on stage snowflake_intelligence.config.semantic_models to role snowflake_intelligence_ro_rl;
Snowflake Intelligenceで使うAgent用のSchema, Table構築
use role snowflake_intelligence_admin_rl;
create schema if not exists snowflake_intelligence.agents;
grant usage on schema snowflake_intelligence.agents to role public;
create or replace row access policy snowflake_intelligence.agents.agent_policy
AS (grantee_roles ARRAY) RETURNS BOOLEAN ->
ARRAY_SIZE(FILTER(grantee_roles::ARRAY(VARCHAR), role ->
is_role_in_session(role))) 0;
Snowflake Intelligenceに対するUser FeedBackを保存するTable構築
ここでは、Snowflake Intelligenceに関するFeedbackを保存するTableを構築します。
Feedbackを保存する方法は2つあり、
- Snowflake Intelligenceの回答が良いものかどうかをFeedback(Thumbs up or Thumbs down)
- 使っているAgentについて、うまく動作した、しなかった、新しくデータソースを追加してほしい等の詳細なFeedback
が可能です。この構築作業を行わなくてもSnowflake Intelligenceは稼働しますが、Userが行ったFeedbackを保存できなくなるので、構築しておいた方が良さそうです。
use role snowflake_intelligence_admin_rl;
create schema snowflake_intelligence.logs;
grant usage on schema snowflake_intelligence.logs to role
snowflake_intelligence_ro_rl;
create or replace table snowflake_intelligence.logs.feedback (
entity_type varchar not null,
username varchar not null,
agent_name varchar not null,
agent_session_id varchar not null,
context variant not null,
feedback_timestamp datetime not null,
feedback_categories variant,
feedback_message varchar,
message_id varchar,
feedback_sentiment varchar,
user_prompt variant,
executed_queries array,
documents_returned array,
response_start_timestamp datetime,
response_end_timestamp datetime,
response_duration number
);
grant insert on table snowflake_intelligence.logs.feedback to role public;
実際の画面はこちらです。
Cortex Search
こちらのチュートリアル を参考に、CortexSearchを構築しました。
具体的な流れとしては、
- 取得したpdfをStageにアップロード
- Chunk分けを行うFunctionを作成
- 2で作成したFunctionを使って、Chunk情報を格納するTableを作成
- 3で作成したTableを使ってCortex Search Searviceを作成
で行っています。
Cortex Analyst
今回はSnowSightでSemantic Viewを作成しました。GUIでぽちぽち頑張れば、簡単にSemantic Viewを作成することができます。
Snowsightで構築すると、ある程度のディメンショナルモデリングやシノニムの定義等を単一Tableに対してはやってもらえます。
しかし、各Table間のリレーションは自動で張れないので、あくまで自分達でモデリングをある程度やった上でSnowSightによる自動生成を活用するのがいいんだろうなというイメージです。
作成後の画面がこちらです。
Cortex Agent
SnowflakeではAgentをSchemaレベルのオブジェクトとして作成します。先ほど作成したsnowflake_intelligence.agentsスキーマ配下に対して、GUIもしくはCLI(CREATE AGENT文)でAGENTオブジェクトを作成することができます。
Agentの設定内容は以下の通りです。
| 項目 | 説明 |
|---|---|
| About | エージェントの目的と役割を記載するフィールド。どの業務領域を支援し、どのデータソースを参照するかを簡潔に記載し、他の利用者が用途を即座に理解できるようにする。 |
| Instruction | エージェントがユーザーへ回答する際のトーンや方針を記載するフィールド。比較観点、回答の粒度(簡潔/詳細)などを明記し、回答品質と一貫性を担保する。 |
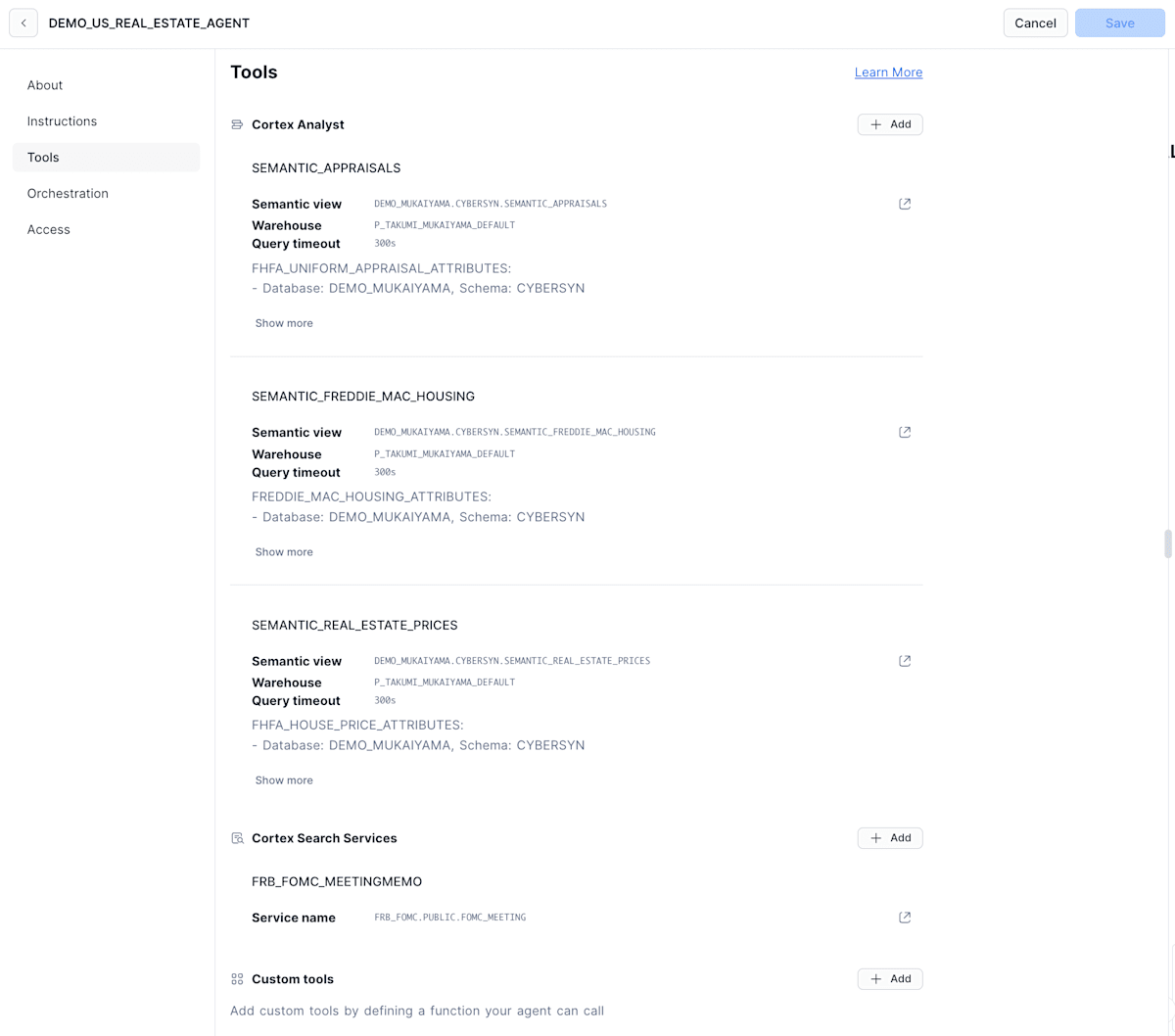
| Tools | エージェントが回答生成時に使用するCortex Analyst(Semantic Models、Semantic Views)、Cortex Searchを設定するフィールド。 |
| Orchestration | 複数ツール(Cortex Analyst, Cortex Search)を使って回答を生成する際の処理順序・条件分岐・統合方法を記載するフィールド。内部処理ルールを明確化し、回答精度向上を図る。 |
| Access | エージェントを利用可能なロールを設定するフィールド。 |
Tool, 指示を含めたAgentの構築例
CLI
CREATE AGENT IDENTIFIER('MY AGENT')
WITH PROFILE='{"display_name": "MY AGENT"}'
COMMENT='Description about agent'
FROM SPECIFICATION $$
{
"models": {
"orchestration": "auto"
},
"instructions": {
"response": "" ,
"sample_questions": [
{"question": "" },
]
},
"tools": [
{"name": "Cortex Search Service Name", "type": "cortex_search"},
{"name": "Semantic View Name", "type": "cortex_analyst_text_to_sql"},
{"name": "Semantic Model Name", "type": "cortex_analyst_text_to_sql"},
],
"tool_resources": {
"cortex search service name": {
"id_column": "FILE_URL",
"name": ".."
},
"Semantic View Name": {
"semantic_view": ".."
},
"Semantic Model Name": {
"semantic_model_file": "@
},
}
}
$$
GUI
About
Display Name(表示名)とDescription(概要)を設定する。
Instructions
レスポンスの指示とサンプル質問を設定する。(必須でない。)

Tools
- Cortex Analyst
- Cortex Search
- Custom Tools
が登録できます!(Snowflake Summitでの宣言通り、CustomToolも使える様になってる!!)
Custom ToolsについてはFunctionとProcedureの両方利用できる。
各種ツール設定時に使用するWarehouseを指定できるっぽい。
なので、Snowflake Intelligenceのコストとしては、
- Snowflake Intelligenceを動かすWarehouse
だけじゃなくて、
- 各種Toolを動かすコスト
も加算されることになりそう。
Orchestration
Orchestrationでは、ModelとPlanning Instructionを指定できます。
Modelとしては、
- Claude Sonnet 4, 3.7, 3.5
- GPT 4.1, o4-mini
- Llama 3.1 405B
が選択できます。
Access
ここでは、Cortex Agentにアクセス可能なRoleを設定できる。
Snowflake Agentを実際に動かしてみる
デモ
デモとして、以下の一連の質問を行いました。
Q1. “Show housing price trends between 2023 and 2025 by geo-id”
Q2. “Choose 5 Biggest City in Biggest City in the us.”
Q3. “Why is it higher trending”
デモの動画はこちらです。
実際にかかったコストを試算する
前提条件
| 項目 | 値 | 補足 |
|---|---|---|
| 質問数 | 3 | Q1〜Q3 |
| Cortex Analyst 呼び出し数 | 6 msg | Q1/Q2 で各 3 msg(SQL 3 回ずつ) |
| Analyst 単価 | 0.067 Cr / msg | 67 Cr / 1 000 msg |
| 仮想 Warehouse | XS・計 3 分 | 1 Cr/h → 0.050 Cr |
| AI_COMPLETE トークン量 | 13 000 token | Plan↔Reflect 4 K×3 + Answer 1 K |
| Cortex Search インデックス | 50 MB (0.05 GB) | 既存サービスを 1 日利用 |
| Search Serving 単価 | 6.3 Cr / GB・月 | 0.05 GB × 1 日/30 ≈ 0.011 Cr |
| 検索クエリ回数 | 1 | クエリ実行自体は追加課金なし |
| クレジット換算レート | 1 Cr ≒ US $3 | Enterprise Edition |
試算結果(モデル別)
| モデル (AI_COMPLETE 単価 Cr/1 M tok) |
AI_COMPLETE | Analyst | Warehouse | Search Serving | 合計 Cr | 合計 US$ |
|---|---|---|---|---|---|---|
| Claude 3.5 / 3.7 / 4 Sonnet (2.55) | 0.033 | 0.402 | 0.050 | 0.011 | 0.496 | $1.488 |
| GPT-4.1 (1.40) | 0.018 | 0.402 | 0.050 | 0.011 | 0.481 | $1.433 |
| o4-mini (0.77) | 0.010 | 0.402 | 0.050 | 0.011 | 0.473 | $1.419 |
| Llama 3.1 405B (3.00) | 0.039 | 0.402 | 0.050 | 0.011 | 0.502 | $1.506 |
Cortex Analystがだいぶ占めていますね。一回あたり大体1.5 US$。
高い気もするし、ビジネスユーザーがDataScientist、Analystを使わずにインサイトを作れるのであれば安い気もする。
今後改善してほしいこと
ものすごい素敵なProductであるSnowflake Intelligenceですが、まだまだ足りない部分があると思っています。
対応しているChartがLineとBarのみ
データを使ってインサイトを得る時に、LineとBarだけだと心許ない。
Scatter、Heatmap、Funnel、Pie Chartあたりはさすがに実装して欲しいなぁ、と思ってます。
今回はアメリカの不動産価格だったので、地図上にHeatmapみたいにで可視化できる機能もついたら最高。
1回の質問に対する実行時間が長め
今回の質問群で、
- Cortex Analystを使って構造化データへクエリ
- Line Chartによる可視化
- Cortex Searchを使ってインサイトを生成
を試しました。
3回質問して、5分弱かかったので質問1回あたりの処理時間は1分40秒くらいです。
Cortex AgentとCortex Analystの両方で実行計画のPlanningもやっているため、体感結構待ちました。
(ビジネスユーザーがたった5分でデータの可視化とインサイトの生成を実現できているので早いんですが….)
個人的には、PlanningはCortex Agentに任せて、ToolとしてのCortex AnalystはPlanningやらなくてもいいんじゃない?って思っています。
まとめ
まだまだ改善の余地があると思うものの、
- 構造化データのための準備
- DB構築
- Text to SQLの実現
- 非構造化データのための準備
- Vector DB構築
- Chunk分け、Embedding
- ハイブリッドサーチ、リランキングの実現
- 定義したToolを丸っと使えるAgent
- 綺麗かつ使いやすいUIを実現するSnowflake Intelligence
をたった数時間で構築できるのは、とんでもないインパクトだなと思いました。
今後どんどん洗練されていくのが楽しみです!!!!
Views: 9

{kind=link}