
はじめに
Snowflake の非構造化データ分析がまた一つ進化しました。2025年に入ってから画像やドキュメントなどの非構造化データ分析への対応が強化されてきた Cortex AI ですが、ついに 音声データ も SQL から直接扱えるようになりました!
今回ご紹介する AI_TRANSCRIBE 関数 は、Snowflake Cortex AISQL の新しい仲間として Public Preview でリリースされました。カスタマーサポートの通話記録、会議の録音、インタビューの音声など、これまで活用するためには一定のハードルがあった音声データを、SQL 一つでテキスト化し、更に他の AISQL 関数と組み合わせて高度な分析ができるようになります。
非構造化データの世界において、画像、ドキュメント、そして音声という3つの主要なデータ形式すべてに対応したことで、データ分析のビジネス活用の可能性が飛躍的に広がった と言えるのではないでしょうか。
本記事では、AI_TRANSCRIBE 関数の基本的な使い方から注意点、そしてビジネス活用まで、実例を交えながら詳しく解説していきます。また、Streamlit in Snowflake を使った音声入力 AI チャットボットのサンプルアプリもご紹介しますので、是非最後までご覧ください!
AI_TRANSCRIBE 関数とは
AI_TRANSCRIBE 関数は、Snowflake Cortex AISQL における音声テキスト変換機能です。これまで音声データの活用には、外部サービスとの連携や 3rd Party のパッケージなどの導入が必要でしたが、AI_TRANSCRIBE 関数を使えば SQL クエリ内で直接音声をテキスト化 できるようになりました。
主な特徴
- SQL ネイティブ: 他の AISQL 関数と同様に、SQL から直接呼び出し可能なのでシンプルに活用できる
- マルチ言語対応: 日本語を含む多数の言語をサポート
- 話者識別機能: 複数の話者を識別してラベル付けすることが可能
- タイムスタンプ付与: 単語レベルまたは話者レベルでのタイムスタンプを付与
- セキュアな処理: Snowflake 内でデータ処理が完結するため、データガバナンスの観点でも安全
Cortex AISQL ファミリーの一員として
AI_TRANSCRIBE は、以下のような既存の Cortex AISQL 関数と組み合わせることで、より強力な分析が可能になります:
- AI_SENTIMENT: テキスト化した音声の感情分析
- AI_CLASSIFY: 音声内容の自動分類
- AI_COMPLETE: 音声内容をプロンプトを指定することで要約や質問応答するなど
- AI_AGG: グループ毎の音声データからのインサイトを得る
- AI_EMBED: 音声データをベクトル化して音声データの曖昧検索を行う
基本的な使い方
AI_TRANSCRIBE 関数の基本的な構文は以下の通りです:
AI_TRANSCRIBE( audio_file> [ , options> ] )
パラメータ
-
audio_file: 音声ファイルを表す FILE 型オブジェクト。
TO_FILE関数を使用してステージングされたファイルへの参照を作成します -
options: オプションの OBJECT 型で、以下のフィールドを指定できます:
-
timestamp_granularity: タイムスタンプの粒度を指定-
"word": 各単語ごとのタイムスタンプを付与 -
"speaker": 話者ごとのタイムスタンプと話者ラベルを付与
-
-
使用例1: シンプルなテキスト変換
最もシンプルな使用方法は、音声ファイルをテキストに変換するケースです:
SELECT AI_TRANSCRIBE(
TO_FILE('@audio_stage', 'customer_call_001.wav')
);
{
"audio_duration": 19.08,
"text": "すみません先日購入した商品について問い合わせがあるんですけれどもよろしいでしょうかこの商品についてパッケージが破損しておりましてこれについて交換していただきたいんですけれども可能でしょうかよろしくお願いいたします"
}
19秒程度の音声ファイルでしたが処理時間は約2秒程度と非常に高速でした。もちろん音声ファイルのサンプリングレートや環境によって処理時間は変わってきますが、分析シーンにおいてストレス無く活用できると思います。
使用例2: 単語レベルのタイムスタンプ付き変換
詳細な分析が必要な場合は、単語レベルでタイムスタンプを付与できます:
SELECT AI_TRANSCRIBE(
TO_FILE('@audio_stage', 'meeting_recording.wav'),
{'timestamp_granularity', 'word'})
);
{
"audio_duration": 19.08,
"segments": [
{
"end": 1.254,
"start": 0.993,
"text": "す"
},
{
"end": 1.274,
"start": 1.254,
"text": "み"
},
{
"end": 1.434,
"start": 1.274,
"text": "ま"
},
{
"end": 1.514,
"start": 1.434,
"text": "せ"
},
{
"end": 2.076,
"start": 1.514,
"text": "ん"
},
...
],
"text": "す み ま せ ん 先 日 購 入 し た 商 品 に つ い て 問 い 合 わ せ が あ る ん で す け れ ど も よ ろ し い で し ょ う か こ の 商 品 に つ い て パ ッ ケ ー ジ が 破 損 し て お り ま し て こ れ に つ い て 交 換 し て い た だ き た い ん で す け れ ど も 可 能 で し ょ う か よ ろ し く お 願 い い た し ま す"
}
使用例3: 話者識別付き変換
会議やインタビューなど、複数の話者が存在する場合は話者識別機能が便利です:
SELECT AI_TRANSCRIBE(
TO_FILE('@audio_stage', 'interview_2025.mp3'),
{'timestamp_granularity', 'speaker'})
);
{
"audio_duration": 16.4,
"segments": [
{
"end": 8.461,
"speaker_label": "SPEAKER_00",
"start": 0.511,
"text": "本日はよろしくお願いします。私の名前は佐藤です。"
},
{
"end": 15.153,
"speaker_label": "SPEAKER_01",
"start": 9.048,
"text": "はい、よろしくお願いします。私の名前は田中です。"
}
],
"text": "本日はよろしくお願いします。私の名前は佐藤です。はい、よろしくお願いします。私の名前は田中です。"
}
対応言語とフォーマット
対応言語
- 日本語
- 英語
- フランス語
- ドイツ語
- スペイン語
- 中国語(標準中国語)
- 広東語
- 韓国語
- アラビア語
- ブルガリア語
- カタルーニャ語
- チェコ語
- オランダ語
- ギリシャ語
- ハンガリー語
- インドネシア語
- イタリア語
- ラトビア語
- ポーランド語
- ポルトガル語
- ルーマニア語
- ロシア語
- セルビア語
- スロベニア語
- スウェーデン語
- タイ語
- トルコ語
- ウクライナ語
皆様が気になる日本語への対応は正式にサポートされております!実際に検証したところ、日本語音声の認識精度も高く、特に違和感無くご利用いただけるのではないかなと思います。
対応音声フォーマット
以下の主要な音声フォーマットがサポートされています:
- MP3: 最も一般的な音声フォーマット
- WAV: 非圧縮の高品質音声
- FLAC: ロスレス圧縮音声
- Ogg: オープンソースフォーマット
- WebM: Web 標準フォーマット
制限事項と注意点
AI_TRANSCRIBE 関数を使用する際の制限事項をまとめました:
技術的制限
| 制限項目 | 詳細 |
|---|---|
| 最大ファイルサイズ | 700MB |
| 最大音声長(タイムスタンプなし) | 120分 |
| 最大音声長(タイムスタンプあり) | 60分 |
| 同時処理数 | アカウントのコンピューティングリソースに依存 |
使用上の注意
- 音声品質の影響: 背景ノイズが多い音声や音質が悪い場合、変換精度が低下する可能性があります
- 専門用語の認識: 業界特有の専門用語や固有名詞は、正確に変換されない場合があります
-
日本語の単語分割: 日本語音声で
timestamp_granularity: 'word'を使用すると、単語ではなく1文字ずつの分割となります - リアルタイム処理: 現時点ではバッチ処理のみ対応で、リアルタイムストリーミング処理は非対応です
リージョン対応状況
AI_TRANSCRIBE は現在以下のリージョンでネイティブに利用可能です:
- AWS US West 2 (Oregon)
- AWS US East 1 (N. Virginia)
- AWS EU Central 1 (Frankfurt)
- Azure East US 2 (Virginia)
他のリージョンをご利用の場合: 上記以外のリージョンでも クロスリージョン推論 機能を使用することで AI_TRANSCRIBE を利用できます。クロスリージョン推論では、サポートされているリージョンのコンピューティングリソースを使用して処理を行うため、若干のレイテンシが発生する可能性がありますが、機能は同様にご利用いただけます。
ビジネス活用シーン
AI_TRANSCRIBE 関数が威力を発揮する代表的なビジネスシーンをご紹介します:
1. カスタマーサービスの品質向上
コールセンターの通話記録を AI_TRANSCRIBE でテキスト化し、そのデータを活用することで様々な分析が可能になります。
- 感情分析の実施: AI_SENTIMENT 関数を用いて、プロフェッショナリズム、問題解決度、待ち時間などの観点から顧客の感情を分析
- 通話内容の自動分類: AI_CLASSIFY 関数で苦情、問い合わせ、称賛などに通話を自動分類
- 話者識別機能の活用: オペレーターと顧客の発言を分離し、それぞれの発言内容を詳細に分析
- リアルタイムフィードバック: 分析結果をダッシュボードで可視化し、サービス品質の即時改善に活用
2. 会議の自動要約とアクションアイテム抽出
経営会議や開発ミーティングの録音を AI_TRANSCRIBE でテキスト化し、業務効率化を実現します。
- 会議録の自動作成: 長時間の会議でも全体のテキストを瞬時に取得
- 要約生成: AI_COMPLETE 関数を用いて、会議のポイントを簡潔にまとめた要約を自動生成
- アクションアイテムの抽出: 決定事項や ToDo を自動的に抽出し、フォローアップを効率化
- 参加者別の発言分析: 話者識別機能を使って、誰がどのような発言をしたかを明確に記録
3. 医療分野での診察記録の自動作成
医師と患者の診察音声を AI_TRANSCRIBE でテキスト化し、医療現場の業務負担を軽減します(個人情報保護対策が必須)。
- 診療記録の自動生成: AI_COMPLETE の構造化出力機能を用いて、主訴、症状、診断、治療計画を構造化された形式で作成
- カルテ入力の効率化: 診察中の会話から必要な情報を自動抽出し、電子カルテへの入力を支援
- 多言語対応: 外国人患者との診察でも、音声をテキスト化して翻訳サービスと連携
- 医療監査への活用: 診療内容の適切性を AI で分析し、医療の質向上に貢献
4. 法務・コンプライアンスの自動監査
契約交渉や法的な会話を AI_TRANSCRIBE で記録し、リスク管理を強化します。
- 交渉内容の完全記録: 契約交渉や法的な議論の全てをテキストとして保存
- コンプライアンスリスクの検出: AI_CLASSIFY 関数で会話内容をリスクレベル別に分類(コンプライアント、低リスク、中リスク、高リスク)
- 証拠保全: 話者識別機能とタイムスタンプを用いて、誰がいつ何を言ったかを正確に記録
- 監査レポートの自動作成: 会話内容から重要なポイントを抽出し、監査用のレポートを自動生成
5. 教育・トレーニング分野での活用
授業や研修の録音を AI_TRANSCRIBE でテキスト化し、学習効果を最大化します。
- 授業内容のアーカイブ化: 講義内容をテキストとして保存し、後から検索・参照可能に
- 字幕付き教材の作成: 単語レベルのタイムスタンプを活用して、動画教材に字幕を追加
- フィードバック分析: トレーニングセッションの内容を分析し、指導法の改善ポイントを特定
- 多言語学習支援: 外国語の授業をテキスト化し、学習者が復習しやすい形で提供
Streamlit in Snowflake で音声入力 AI チャットボット
AI_TRANSCRIBE 関数を活用して、Streamlit in Snowflake で音声入力に対応した AI チャットボットのシンプルなサンプルアプリを作成してみました。ユーザーが音声で質問を投げかけると、それをテキスト化して AI が回答を返すというインタラクティブなアプリケーションです。(追加されたばかりの OpenAI GPT-5も対応させておきました!)
アプリケーションの概要
このアプリケーションは以下の機能を提供します:
- 音声録音機能: Streamlit の機能を使いブラウザから直接音声を録音しステージに保存
- 音声テキスト変換: AI_TRANSCRIBE 関数でテキスト化
- AI による回答生成: AI_COMPLETE 関数で質問に回答
前提条件
このアプリを実装するためには、以下の条件を満たす必要があります:
環境要件
- Python バージョン: 3.11 以上
- 追加パッケージ: 不要 (標準パッケージのみで動作)
- Streamlit in Snowflake: アプリを作成・実行できる環境
リージョンの確認
AI_TRANSCRIBE 関数や AI_COMPLETE 関数が利用可能なリージョンであることを確認してください。対応リージョン以外でもクロスリージョン推論を使用すれば利用可能です。
実装手順
以下の手順でアプリを実装できます:
1. 新規で Streamlit in Snowflake のアプリを作成
Snowsight の左ペインから『Streamlit』をクリックし、『+ Streamlit』ボタンをクリックし SiS アプリを作成します。
2. サンプルコードの貼り付け
作成されたアプリのエディタに、下記のサンプルコードを そのままコピー&ペースト します。コードの修正は不要で、ステージ名なども自動で設定されます。
3. アプリの実行
コードを貼り付けたら、右上の「実行」ボタンをクリックしてアプリを起動します。初回起動時にはステージが自動的に作成されます。
4. アプリの使用
- 音声入力: マイクボタンをクリックして話しかける
- モデル選択: サイドバーから好みの AI モデルを選択
- テキスト入力: 通常のチャット入力も可能
サンプルコード
import streamlit as st
import io
import uuid
import json
from datetime import datetime
from snowflake.snowpark.context import get_active_session
from snowflake.snowpark.functions import ai_complete, to_file
session = get_active_session()
STAGE_NAME = "AUDIO_TRANSCRIBE_STAGE"
st.set_page_config(layout="wide")
st.title("AI音声チャットボット")
st.sidebar.title("⚙️ 設定")
model_options = [
"━━━ 🟢 OpenAI ━━━",
"openai-gpt-oss-120b",
"openai-gpt-oss-20b",
"openai-gpt-5",
"openai-gpt-5-mini",
"openai-gpt-5-nano",
"openai-gpt-5-chat",
"openai-gpt-4.1",
"openai-o4-mini",
"━━━ 🔵 Claude ━━━",
"claude-4-opus",
"claude-4-sonnet",
"claude-3-7-sonnet",
"claude-3-5-sonnet",
"━━━ 🦙 Llama ━━━",
"llama4-maverick",
"llama4-scout",
"llama3.3-70b",
"llama3.2-3b",
"llama3.2-1b",
"llama3.1-405b",
"llama3.1-70b",
"llama3.1-8b",
"llama3-70b",
"llama3-8b",
"━━━ 🟣 Mistral ━━━",
"mistral-large2",
"mistral-large",
"mixtral-8x7b",
"mistral-7b",
"━━━ ❄️ Snowflake ━━━",
"snowflake-arctic",
"snowflake-llama-3.3-70b",
"snowflake-llama-3.1-405b",
"━━━ 🔴 その他 ━━━",
"deepseek-r1",
"reka-core",
"reka-flash",
"jamba-1.5-large",
"jamba-1.5-mini",
"jamba-instruct",
"gemma-7b"
]
default_model = "llama4-maverick"
default_index = model_options.index(default_model) if default_model in model_options else 1
llm_model = st.sidebar.radio(
"AIモデルを選択",
options=model_options,
index=default_index,
format_func=lambda x: x if "━━━" in x else f" • {x}"
)
if "━━━" in llm_model:
llm_model = "llama4-maverick"
@st.cache_resource
def setup_stage():
"""音声ファイル保存用ステージをセットアップ"""
try:
session.sql(f"DESC STAGE {STAGE_NAME}").collect()
except:
session.sql(f"""
CREATE STAGE IF NOT EXISTS {STAGE_NAME}
ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE')
DIRECTORY = (ENABLE = TRUE)
""").collect()
setup_stage()
if 'messages' not in st.session_state:
st.session_state.messages = []
st.session_state.chat_history = ""
def extract_text_from_transcript(transcript_result):
"""AI_TRANSCRIBEの結果からテキストを抽出"""
if isinstance(transcript_result, str) and transcript_result.startswith('{'):
try:
return json.loads(transcript_result).get('text', '')
except:
return transcript_result
return transcript_result
def clean_ai_response(response):
"""AI応答のクリーンアップ(余分な引用符や改行コードを処理)"""
if isinstance(response, str):
response = response.strip('"')
response = response.replace('\\n', '\n')
return response
def generate_ai_response(prompt, model):
"""AI応答を生成"""
df = session.range(1).select(
ai_complete(model=model, prompt=prompt).alias("response")
)
return clean_ai_response(df.collect()[0]['RESPONSE'])
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
st.subheader("音声入力")
audio_value = st.audio_input("マイクボタンをクリックして話してください")
if st.button("📤 音声を送信", disabled=(audio_value is None), use_container_width=True):
if audio_value:
try:
with st.spinner("🎤 音声をアップロード中..."):
audio_filename = f"audio_{datetime.now().strftime('%Y%m%d_%H%M%S')}_{uuid.uuid4().hex[:8]}.wav"
audio_stream = io.BytesIO(audio_value.getvalue())
session.file.put_stream(
audio_stream,
f"@{STAGE_NAME}/{audio_filename}",
auto_compress=False,
overwrite=True
)
with st.spinner("📝 音声を文字起こし中..."):
query = f"""
SELECT AI_TRANSCRIBE(
TO_FILE('@{STAGE_NAME}/{audio_filename}')
) as transcript
"""
result = session.sql(query).collect()
if result and len(result) > 0:
transcribed_text = extract_text_from_transcript(result[0]['TRANSCRIPT'])
if transcribed_text:
st.session_state.messages.append({"role": "user", "content": transcribed_text})
st.session_state.chat_history += f"User: {transcribed_text}\n"
with st.spinner("🤖 AIが応答を生成中..."):
full_prompt = st.session_state.chat_history + "AI: "
response = generate_ai_response(full_prompt, llm_model)
st.session_state.messages.append({"role": "assistant", "content": response})
st.session_state.chat_history += f"AI: {response}\n"
st.rerun()
else:
st.warning("文字起こしに失敗しました。もう一度お試しください。")
except Exception as e:
st.error(f"エラーが発生しました: {str(e)}")
if prompt := st.chat_input("メッセージを入力してください..."):
st.session_state.messages.append({"role": "user", "content": prompt})
st.session_state.chat_history += f"User: {prompt}\n"
with st.chat_message("user"):
st.markdown(prompt)
try:
with st.spinner("🤖 AIが応答を生成中..."):
full_prompt = st.session_state.chat_history + "AI: "
response = generate_ai_response(full_prompt, llm_model)
st.session_state.messages.append({"role": "assistant", "content": response})
st.session_state.chat_history += f"AI: {response}\n"
with st.chat_message("assistant"):
st.markdown(response)
except Exception as e:
st.error(f"エラーが発生しました: {str(e)}")
if st.button("🗑️ チャット履歴をクリア"):
st.session_state.messages = []
st.session_state.chat_history = ""
st.rerun()
アプリケーション画面
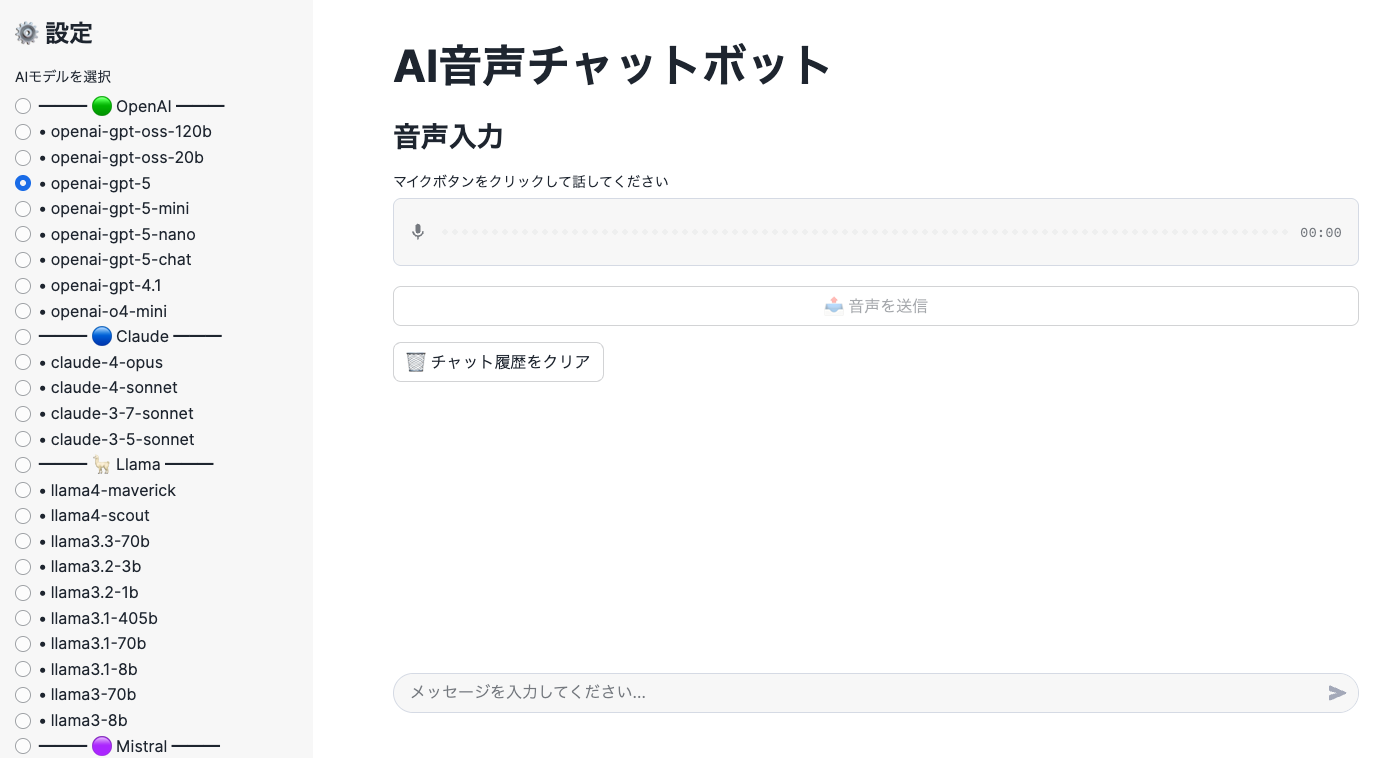

実装のポイント
- シンプルな実装: 追加パッケージのインストール不要で、標準ライブラリのみで実装
- 音声ファイルの管理: ステージ音声データを保存し、AI_TRANSCRIBE で処理
- マルチモーダル対応: 音声入力とテキスト入力の両方に対応
- 豊富なモデル選択: OpenAI GPT-5 を含む最新モデルから選択可能
コストについて
AI_TRANSCRIBE 関数の課金は、他の AISQL 機能と同様にトークン消費に基づいています。音声処理における具体的なコスト構造は以下の通りです:
トークン消費と料金
- 音声1秒あたり50トークン: 言語やタイムスタンプ粒度 (word/speaker) に関わらず一律
- 1時間の音声 = 180,000トークン
- 概算コスト: 100万トークンあたり1.3クレジット、1クレジットを3米ドルと仮定すると、1時間の音声処理は約0.117米ドル (約17円)
例えば、60秒の音声ファイルの場合:
- 60秒 × 50トークン = 3,000 トークン
最新の価格情報については Snowflake Service Consumption Table をご参照ください。
まとめ
AI_TRANSCRIBE 関数は、音声データという新たな非構造化データの扉を開く画期的な機能 です。2025年に入ってから強化されてきた画像、ドキュメントへの対応に加え、音声という3つ目の主要な非構造化データも SQL で扱えるようになったことで、Snowflake は真の意味でマルチモーダルなデータプラットフォームへと進化したと言えます。
主要なメリット
- 統合的なデータ処理: 音声も含めたすべてのデータを Snowflake 内で完結して処理
- 他の AISQL 関数との連携: 感情分析、分類、要約、ベクトル化など、豊富な AI 機能との組み合わせ
- セキュアな環境: データの外部移動が不要で、ガバナンスを維持
- 開発効率の向上: 3rd Party パッケージの導入なしに SQL だけで音声分析パイプラインを構築可能
カスタマーサービス、会議録、医療記録、法務監査など、様々なビジネスシーンで AI_TRANSCRIBE 関数を活用し、これまで活用にハードルがあった音声データから新たなビジネス価値を生み出していただければ幸いです。
宣伝
SNOWFLAKE DISCOVER で登壇しました!
2025/4/24-25に開催されました Snowflake のエンジニア向け大規模ウェビナー『SNOWFLAKE DISCOVER』において『ゼロから始めるSnowflake:モダンなデータ&AIプラットフォームの構築』という一番最初のセッションで登壇しました。Snowflake の概要から最新状況まで可能な限り分かりやすく説明しておりますので是非キャッチアップにご活用いただければ嬉しいです!
以下リンクでご登録いただけるとオンデマンドですぐにご視聴いただくことが可能です。
生成AI Conf 様の Webinar で登壇しました!
『生成AI時代を支えるプラットフォーム』というテーマの Webinar で NVIDIA 様、古巣の AWS 様と共に Snowflake 社員としてデータ*AI をテーマに LTをしました!以下が動画アーカイブとなりますので是非ご視聴いただければ幸いです!
X で Snowflake の What’s new の配信してます
X で Snowflake の What’s new の更新情報を配信しておりますので、是非お気軽にフォローしていただければ嬉しいです。
日本語版
Snowflake の What’s New Bot (日本語版)
English Version
Snowflake What’s New Bot (English Version)
変更履歴
(20250810) 新規投稿
Views: 0

{kind=link}