

こんにちは。白”雪姫”です。
少し前に書いたローカルIPでのS3マウント にて、S3バケットをAWSマネジメントコンソールで作成した時に気になったタブが増えていて、調べてみたものです。
ローカルIPマウントで通常のS3バケット、S3 Express OneZoneディレクトリバケットそれぞれの書き込み速度、読み取り速度の比較です。
Introduction記載の記事の環境になります。
ローカル
- YAMAHA RTX-1210
- VMWare Server 上のUbuntu Linux
AWS側
- Site-to-Site VPN
- Interface Gateway
- S3バケット(通常S3バケット/Express Onzoneディレクトリバケット)
mount-s3を用いて、マウントを行い、約1GBのデータの書き込み、読み込みを行う。
書き込みは、ddコマンド(blcok sizeは1024と1Mとで比較)
読み取りは、ddコマンドとfioコマンドを用いて読み取ります。
読み取りの速度にfioを含めたのは、ランダムアクセスリードの確認を取りたかった為です。
S3 Express OneZoneディレクトリバケットの作り方
Amazon S3から、ディレクトリバケットに行き、バケットの作成にて作成を行えば作成が可能です。
その際に、2枚目の様な画像な感じで設定をAvailability Zonesを選択するように促されます。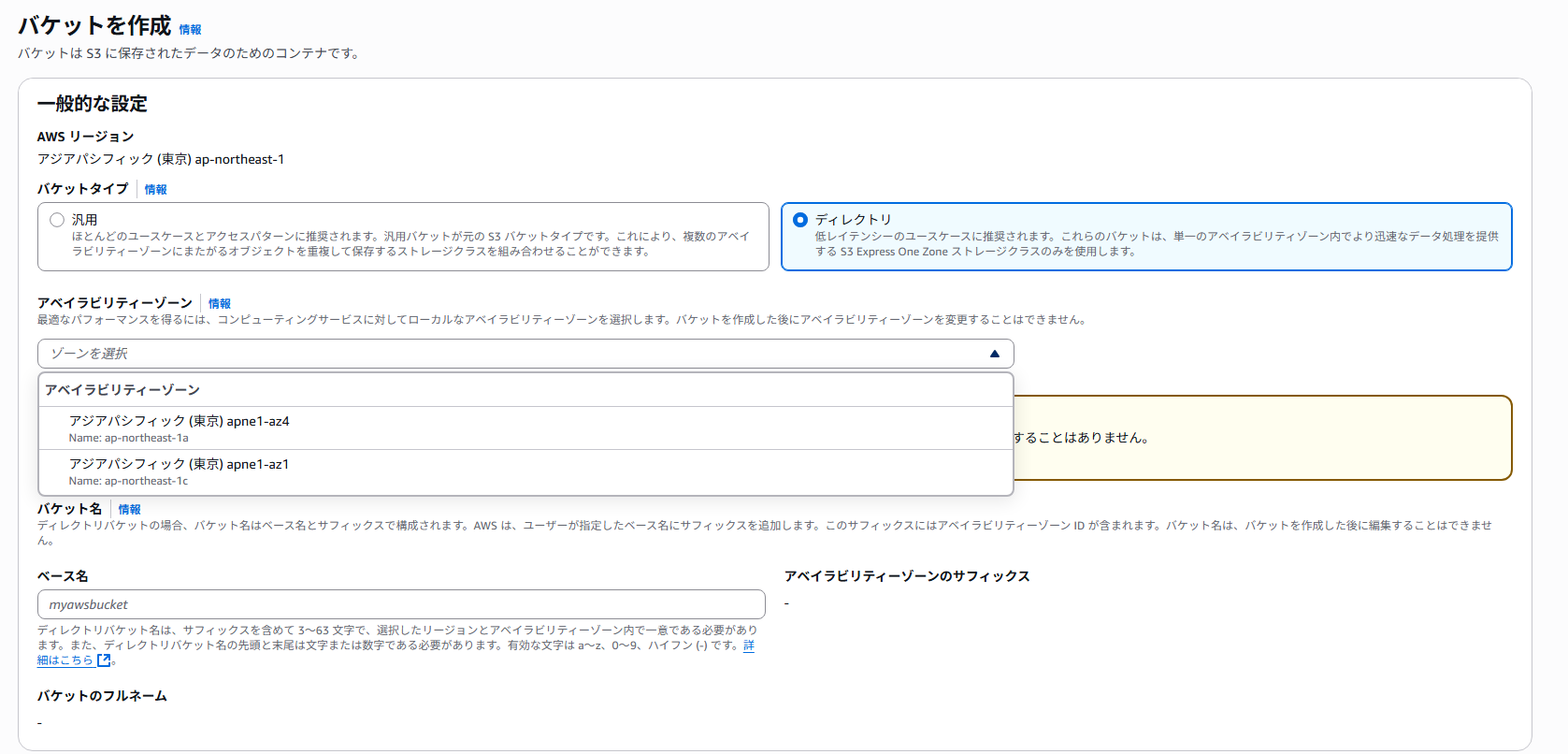
これで1つのZoneになるというわけですね。
なるほど。
マウント方法
以前の記事を参照ください。
マウントするS3のIAMロールに以下の許可を追加しないと権限が不足してしまいますので注意しましょう
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "s3express:*",
"Resource": "*"
}
]
}
書き込みの結果
# block size 1024 byte
dd if=/dev/zero of=/home/y-kalen/s3-mount/test-data/test.data bs=1024 count=1024
1024000+0 records in
1024000+0 records out
1048576000 bytes (1.0 GB, 1000 MiB) copied, 46.3181 s, 22.6 MB/s
# block size 1MB
dd if=/dev/zero of=/home/y-kalen/s3-mount/test.dat bs=1M count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 17.7517 s, 60.5 MB/s
# block size 1024 byte
dd if=/dev/zero of=/home/y-kalen/s3-mount/test-data/test.data bs=1024 count=1024000
1024000+0 records in
1024000+0 records out
1048576000 bytes (1.0 GB, 1000 MiB) copied, 47.8499 s, 21.9 MB/s
# blck size 1MB
dd if=/dev/zero of=/home/y-kalen/s3-mount/test.dat bs=1M count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 15.3328 s, 70.0 MB/s
読み込みの結果
# dd
dd if=/home/y-kalen/s3-mount/test-data/test.data of=/home/y-kalen/test-data.data
2048000+0 records in
2048000+0 records out
1048576000 bytes (1.0 GB, 1000 MiB) copied, 21.086 s, 49.7 MB/s
# fio
fio --time_based --name=benchmark --size=256M --runtime=60 --randrepeat=1 --iodepth=32 --invalidate=1 --verify=0 --verify_fatal=0 --numjobs=8 --rw=randread --blocksize=4k --group_reporting
benchmark: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=psync, iodepth=32
...
fio-3.32
~(中略)~
Run status group 0 (all jobs):
READ: bw=136KiB/s (139kB/s), 136KiB/s-136KiB/s (139kB/s-139kB/s), io=8204KiB (8401kB), run=60253-60253msec
# dd
dd if=test.data of=/home/y-kalen/test-data.data
2048000+0 records in
2048000+0 records out
1048576000 bytes (1.0 GB, 1000 MiB) copied, 18.1868 s, 57.7 MB/s
## fio
fio --time_based --name=test.data --size=256M --runtime=60 --randrepeat=1 --iodepth=32 --invalidate=1 --verify=0 --ve
rify_fatal=0 --numjobs=8 --rw=randread --blocksize=4k --group_reporting
test.data: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=psync, iodepth=32
...
fio-3.32
~(中略)~
Run status group 0 (all jobs):
READ: bw=136KiB/s (139kB/s), 136KiB/s-136KiB/s (139kB/s-139kB/s), io=8172KiB (8368kB), run=60272-60272msec
| S3 | dd(bs=1024) | dd(bs=1M) | dd(Read) | fio |
|---|---|---|---|---|
| 通常バケット | 22.6MB/s | 60.5MB/s | 49.7MB/s | 139KB/s |
| OneZone Express | 21.9MB/s | 70.0MB/s | 57.7MB/s | 139KB/s |
ランダムアクセス時は、8レーン同時読み取りをしているので速度は落ちてるなぁと言う印象に対して、大きい容量の読み取りで考えると約10MB/sの差が出ています。
大容量になりやすいデータ(動画・音楽・Bigdata等など)の保存先として利用して、処理をオンプレミサーバだったり他のサーバに任せるともしかしてかなり良いのでは?
などと思いました。
Views: 0

{kind=link}