
こんにちは!
エクスプラザでLLMアプリケーションエンジニアをやっているunsuです。
私はこの会社に入社した直後、初めて挑戦するAIエージェント機能の開発で5回も大きく設計を変更したことがあります。
この記事は、LLM機能開発の初心者時代、正確な理論なしに奮闘した記録です。今なら違う実装をするかもしれません。でも、この失敗の過程から得た学びを記録として残しておきます。
この記事はこんな方におすすめです
- AIエージェント開発に興味があるけど、まだ手を出せていない。開発の実体験談を聞きたい
- OpenAI Agents SDKって聞いたことあるけど、実際どう動くのか知りたい
- マルチエージェント構成って本当にうまくいくのか知りたい
背景:クライアントの声から始まったプロジェクト
当時、私は生成AI/LLM Applicationエンジニアとして入社して3ヶ月。そんな初心者に突然降ってきた要望でした。
顧客から寄せられた声は、まさに「AIエージェント」の理想形でした:
「記事を選択して『事実確認して修正して』と指示したら、AIが勝手にウェブ検索して、事実確認して、修正案を作ってくれる。そんな機能が欲しい」
当時「AIエージェント」という言葉がトレンドになり始めていて、この要望はその定義通りの、教科書的な理想像でした。
プロダクトオーナーと私は、「作ってみよう!」と決めました。
AIエージェントって何?
AIエージェントとは何か、私は当時、以下のように軽く理解していました。

基本的なLLM 📝
「質問に答えるAI」
- ユーザー:「この文章を要約して」
- AI:「はい、要約すると…」
- 単純な応答生成
AI Agent 🤖
「目標を達成するAI」
- ユーザー:「この記事を事実確認して修正して」
- AIが自律的に:
- ウェブ検索実行
- 事実確認
- 修正案生成
- 結果伝達
Agentは「どうやるか?」を自律的に判断し、自分の能力で複数のステップを経て目標を達成することが基本的なLLMとの違いですね。
要件
今回AIエージェント機能を追加する「Mark」は、簡単な指示と事前に保存しておいた設定でいろんな種類のコンテンツを生成することができるコンテンツ生成AI SaaSプロダクトです。
今回はその生成されたコンテンツを編集するエディターページに追加するAIエージェントの話にフォーカスし、
この記事では特に事例として 「ファクトチェックして、事実通りに編集して」というユースケースに絞って、 それぞれの設計での動作結果をお見せしたいと思います。
技術選定: OpenAI Agents SDKを使ってみよう
OpenAI Agents SDKがリリースされた2025年3月、当時そのSDKを早く使ってみたいと思い、SlackチャットにAgenticに行動をするSlack Botを作った経験があり、そのときは「意外と簡単じゃん」という印象で、こちらを使うことにしました。
また、技術選定時にはまだリリースして1ヶ月も経っていないものの、OpenAI公式だから安定してるはずという思い込みもありました。
OpenAI Agents SDKを構成している概念
では、使い始める前にOpenAI Agents SDKの公式ドキュメントから、理解しておくべき概念を一部みてみましょう。
🤖 Agents(エージェント):指示とツールを持つ基本単位。各エージェントが特定の役割を担当。
🔄 Handoffs(ハンドオフ):エージェント間でタスクを引き継ぐ仕組み。これが後に悪夢の原因に…
🛠️ Tools(ツール):エージェントが実行できるアクション。Web検索、API呼び出しなど。
🎯 Triage Agent(トリアージエージェント):全体を指揮する司令塔。ユーザーの要求を解析して適切なエージェントに振り分ける。
これらの概念は美しく、理論的には完璧でした。
「これなら簡単にAIエージェントが作れる!」と思った私は甘かった… 🍬🍫🍡🍯
1回目の設計:マルチエージェントを試す
最初のアプローチは素直でした。OpenAI Agents SDKのドキュメントを読んで、「これだ!」と思った構成をそのまま実装することにしました。
実装例:
# QnA Agent - 質問応答を担当
qna_agent = Agent(
name="QnA Agent",
instruction="""(プロンプト例):
ユーザーからの質問に対して回答を生成してください。
記事の内容を基に、適切な回答を提供します。
""",
tools=[], # 特別なツールは使用しない
handoff=[] # 他のエージェントへの引き継ぎはなし
)
# Edit Agent - 編集提案を担当
edit_agent = Agent(
name="Edit Agent",
instruction="""(プロンプト例):
事実確認の結果を基に、記事の編集提案を生成してください。
修正が必要な箇所と修正案をJSON形式で返してください。
形式: {"original": "元のテキスト", "suggestion": "修正案", "reason": "理由"}
""",
tools=[],
handoff=[] # 編集完了後は終了
)
# Fact Check Agent - 事実確認を担当
fact_check_agent = Agent(
name="Fact Check Agent",
instruction="""(プロンプト例):
記事内の情報をウェブ検索で事実確認してください。
確認が必要な箇所を特定し、検索結果と照合して正確性を評価します。
事実確認が完了したら、Edit Agentに結果を渡してください。
""",
tools=["web_search"], # ウェブ検索ツールを使用
handoff=[edit_agent] # 編集エージェントへ引き継ぎできる
)
# Triage Agent - 全体の司令塔
triage_agent = Agent(
name="Triage Agent",
instruction="""(プロンプト例):
ユーザーの要求を分析し、適切なエージェントに作業を振り分けてください。
- 質問への回答が必要な場合: QnA Agent
- 事実確認が必要な場合: Fact Check Agent
- 編集が必要な場合: Edit Agent
ユーザーの意図を正確に理解し、最適なエージェントを選択してください。
""",
tools=[],
handoff=[qna_agent, fact_check_agent, edit_agent]
)
# 実際の使用例
response = triage_agent.run(
messages=[
{"role": "user", "content": "この統計データを確認して修正して"}
]
)
期待していた理想的な世界
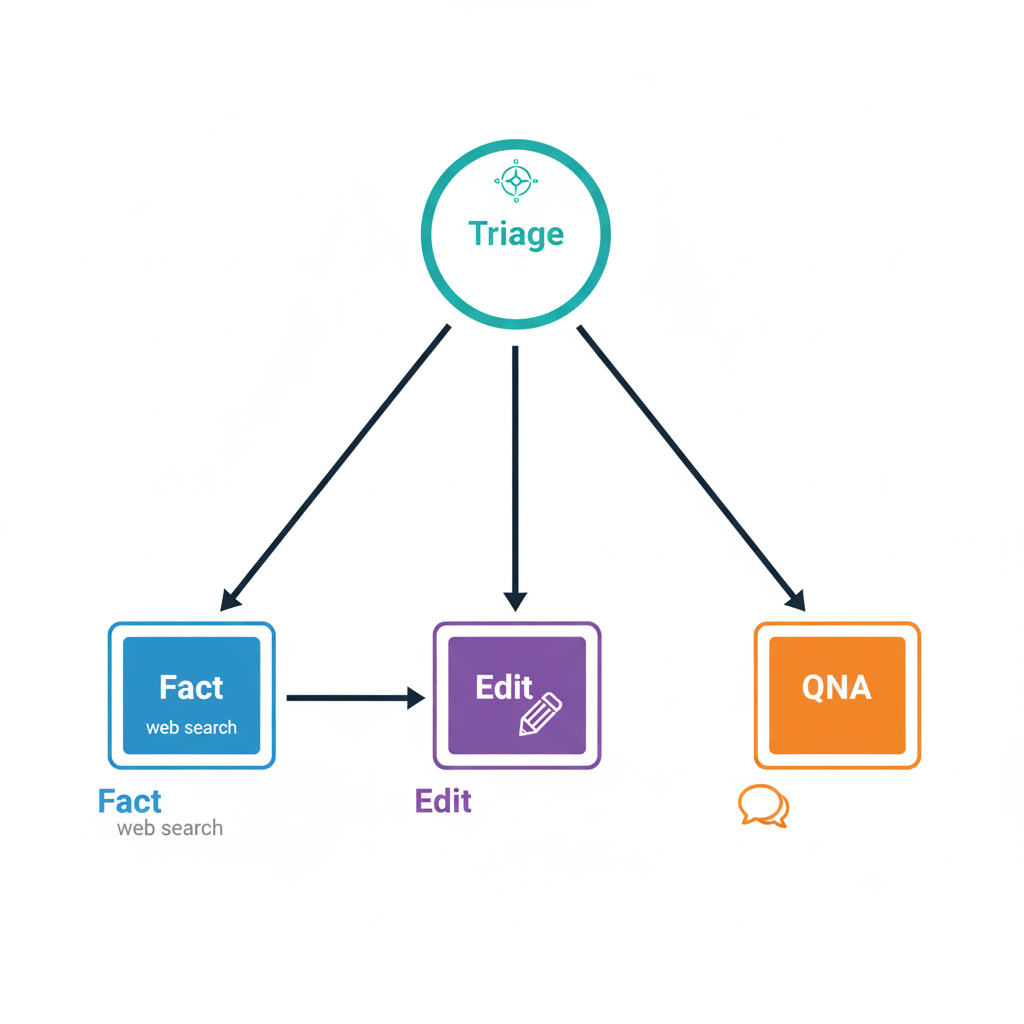
マルチエージェント構成なら、各エージェントが専門分野を持って協調動作するはず。まるでチーム開発のように:
- Triage Agent:プロジェクトマネージャーのように全体を指揮
- Fact Check Agent:事実確認の専門家
- Edit Agent:編集のプロフェッショナル
- QnA Agent:質問応答のスペシャリスト
シンプルで美しい設計。理論的には完璧でした。
実際に起きたこと
入力:「この統計データを確認して修正して」
期待:Triage → Fact Check → Web検索 → Edit Agent → 編集用JSON返却
実際:Triage → QnA Agent「はい、正しいと思います」(検索も編集もせず終了)
10回試したら4~5回くらいしか成功しない。それ以外は、途中で勝手に処理を終了していました。
なぜ失敗したか
エージェント間のハンドオフは、LLMの判断に依存していました。LLMは「最短経路」を選ぶ傾向があり、面倒な作業をスキップしがちでした。
2回目の設計:一回作業後Triageに戻る中央集権型を試す
各エージェントが作業後、必ずTriageに戻して次の判断をさせる設計に変更しました。
# すべてのSub AgentのhandoffをTriageに設定
qna_agent = Agent(
...,
handoff=[triage_agent] # 常にTriageに戻る
)
fact_check_agent = Agent(
...,
tools=["web_search"],
handoff=[triage_agent] # 常にTriageに戻る
)
edit_agent = Agent(
...,
handoff=[triage_agent] # 常にTriageに戻る
)
triage_agent = Agent(
...,
handoff=[qna_agent, fact_check_agent, edit_agent]
)
期待していたフロー
ユーザー → Triage → Sub Agent A → Triage → Sub Agent B → Triage → … → 最終回答
Triageが司令塔となり、各Agentの結果を見て次の判断をする。理論的には確実な制御ができるはず。
実際に起きたこと
単純な「要約して」:
- Triage → QnA Agent → Triage → ユーザー(3回のhandoff)
複合的な「事実確認して修正して」:
- Triage → Fact Check → Triage → Edit → Triage → ユーザー(5回のhandoff)
単純にhandoffが多すぎて遅い 🐌 処理時間が2〜3倍に増加するのでは?
ここはスキップしよう
単純にHandoffが多く発生し、もっといい方法がありそうと思い、早く断念して次の試行に進むことに。
3回目の設計:プランを立てて、その後の実行をそれぞれのAgentに委ねる
最初にプランを立てて、各エージェントに「これに従って」と渡す設計にしました。
sub_agent = Agent(
name="Sub Agent",
instruction="""(プロンプト例):
{sub agentの元々の主な指示}
実行プランを参照し、タスク完了後は計画に従って次のエージェントにHandoffしてください。次のタスクがない場合は、作業を完了して回答を返してください。
プラン: {plan}
""",
handoff=[edit_agent, qna_agent, fact_check_agent, sub_agent_xx, ...]
)
プラン: {plan}部分をコンテキストとして、Handoffを各自サブエージェントに委ねる形ですね。
期待していたフロー
- Triageが全体プランを策定
- Sub Agent Aにプランごと作業を渡す
- Agent Aが作業後、プランを見てAgent Bにhandoff
- 最後のAgentがTriageに結果返却
実際に起きたこと
「プランはこれだよ!」と教えても…
Fact Check Agent: "ウェブ検索完了しました。検索結果は以下の通りです..."
(作業終了)→ Edit AgentにHandoffしない 😭
体感では半分くらいは期待通りに動作。プランの途中で勝手に終了することが多い。
なぜ失敗したか
各エージェントは自分の主タスクを最優先し、「次のエージェントにhandoffする」という指示は後回しにされたのかなと推測しています。
プランを渡しても、LLMは特性上「私の仕事は終わった」と判断したら、次への引き継ぎを怠っていたかもしれないと思いました。
その後ふと思ったのが、シングルエージェントでHandoffを発生させず、Sub-agentたちをToolsとして設定すれば、もしかしたらシングルエージェントが自律的によしなにエージェントたちを読んだ上で終了するんじゃない?ということでした。
# 各専門エージェントを定義
fact_check_agent = Agent(
name="Fact Check Agent",
tools=["web_search"],
instructions="..."
)
edit_agent = Agent(
name="Edit Agent",
instructions="..."
)
qna_agent = Agent(
name="QnA Agent",
instructions="..."
)
# Triageエージェントが他のエージェントをツールとして使用
triage_agent = Agent(
instruction,
tools=[
fact_check_agent.as_tool(
tool_name="FactCheckAgent-as-tool",
tool_description="ウェブ検索で事実確認を実行"
),
edit_agent.as_tool(
tool_name="EditAgent-as-tool",
tool_description="編集案を作成"
),
qna_agent.as_tool(
tool_name="QnaAgent-as-tool",
tool_description="質問に回答"
)
]
)
最初は成功したように見えた
入力:「検索して事実通りに編集して」
結果:「この部分が事実と異なるので、このような編集を提案します...」
ほぼ毎回期待通りの動作が!と思ったら、処理時間が異常に長い。
デバッグログを入れて、どのように動いているかを見てみました。
実際に起きたこと: 制御不可能(?)なTool実行の地獄
[00:00:00] SingleAgent → call tool: FactCheckAgent-as-tool
[00:00:03] SingleAgent → call tool: FactCheckAgent-as-tool(また?)
[00:00:07] SingleAgent → call tool: EditAgent-as-tool(まだ検索中なのに)
[00:00:07] SingleAgent → call tool: EditAgent-as-tool(2回目)
[00:00:11] SingleAgent → call tool: FactCheckAgent-as-tool(もう編集提案したんじゃないの?)
... (計10回以上呼び出し)
制御不能の非同期実行
- ウェブ検索がまだ終わってないのに編集を試みる
- 編集完了後にまたウェブ検索を実行する
- 同じ作業を3〜4回ずつ繰り返す
結局、Tool使用回数の上限(10回)まで実行して、なんとか結果を返していました。
なぜ失敗したか
非同期実行の依存関係を管理できず、LLMは「呼べるツールは全部呼んでおこう」という判断をしていましたかもしれない。もう少しいいコンテキストエンジニアリングを通じてより良い完了判断ができるように指示する工夫も必要だったと思います。
処理時間とAPI呼び出し回数が爆発的に増加。これでは実用的ではありません。
最後の設計: Plan with LLM → Execute with Code
OpenAI Agents SDKを4回試行してきた結果、Handoffの不確実性、非同期実行の混乱、プラン遵守の困難さなど、様々な課題に直面しました。そこで、SDKに頼らない独自設計に踏み切ることを決断しました。
設計思想:LLMとコードの明確な役割分担
LLMに得意なことをさせ、コードで確実に制御する。この原則に基づいて設計を再構築しました。
LLMの役割:
- ユーザー要求の分析と理解
- 実行計画の策定
- 各ステップでの判断(検索クエリ生成、編集案作成など)
コードの役割:
- 実行順序の制御
- 依存関係の管理
- 結果の確実な伝達
実装例
OpenAI Agents SDKのマルチエージェントシステムの概念は参考にしつつ、実装は大幅にシンプル化しました。
以下は、実際のプロダクトコードを設計思想をもとに抽象化して再生成したシンプルなコードの例です。
計画立案フェーズ
async def create_execution_plan(user_message, context):
"""ユーザーの要求から実行計画を作成"""
prompt = f"""
要求: {user_message}
コンテキスト: {context}
必要なステップと順序を決定してください。
"""
planner_response = await llm_client.generate(prompt)
return parse_to_plan(planner_response)
計画立案フェーズでは、LLMがユーザーの要求を分析し、必要なステップを洗い出します。例えば「事実確認して修正して」という要求に対して、「検索→編集」という実行計画を生成します。
実行フェーズ
async def execute_plan(plan, user_message):
"""計画に従って各エージェントを実行"""
results = {}
for step in plan.steps:
previous_result = results.get(step.depends_on, "")
if step.type == "search":
yield "🔍 検索中..."
elif step.type == "edit":
yield "✏️ 編集案を作成中..."
agent = create_agent(step.type, step.task, previous_result)
result = await agent.run()
results[step.id] = result
return results
実行フェーズの最大のポイントは、forループによる確実な順次実行です。各ステップは前のステップの結果をprevious_resultとして確実に受け取り、依存関係が保証されます。
検索品質を保証する仕組み
検索エージェントには、結果の品質を評価して自動的に再検索する仕組みを組み込みました:
async def search_with_quality_check(query, max_retries=4):
"""検索結果の品質を保証"""
for attempt in range(max_retries):
search_results = await web_search(query)
quality_check = await llm_client.evaluate(
f"検索結果: {search_results}\n"
f"これは'{query}'について十分な情報ですか?"
)
if quality_check.is_sufficient:
return search_results
query = quality_check.refined_query
yield f"🔄 より詳細な検索を実行中... (試行 {attempt + 2}/4)"
return search_results
メイン処理とストリーミング
ユーザー体験を向上させるため、処理状況をリアルタイムでストリーミング表示:
async def handle_request(user_message):
plan = await create_execution_plan(user_message, context)
async for update in execute_plan(plan, user_message):
yield update
実際の動作例
入力:「この統計データを確認して修正して」
[画面表示(1行ずつリアルタイムで切り替わるように実装)]
📋 実行計画を作成中...
🔍 検索中...
🔄 より詳細な検索を実行中... (試行 2/4)
✏️ 編集案を作成中...
[最終結果]
以下の編集案を提案します:
- 「株式会社エクスプラザ(CEO: 田中一郎, 本社:神奈川県川崎市)」→「株式会社エクスプラザ(CEO: 高橋一生, 本社:東京都港区)」
- 理由: 会社の公式ホームページの情報をもとに修正しました。(source: https://xxx...)
無事、何回試してもいい成果が出るように改善されました。
なぜこの設計が成功したか
やっと思い通りに動くようになりました。
何をするかはLLMに自律的に考えてもらって、どう実行するかはコードできちんと制御する。
このシンプルな分担がよかったんだと思います。
前のステップの結果が次にちゃんと渡るようになったし、順番もきちんと守って作業を完了できるようになりました。
OpenAI Agents SDKで学んだことは活かしつつ、HandoffなどSDKの内部の挙動に対する深い理解が必要な不安定な仕組みは使わず、自分たちで作り直したのが正解でした。
結局、LLMには考えてもらって、実行はコードで管理する。これに尽きたと思います。
5回の試行錯誤の結果
| 試行 | 体感的な成功度 | 処理時間 | なぜそうだったか |
|---|---|---|---|
| 1 | 半分以下 | 基準 | もっとSDKの内部動作を理解した方が良さそう&Handoffを信用しすぎるな |
| 2 | (もっといい案がありそうと思いスキップ) | 2-3倍 | – |
| 3 | 半分程度 | 1.5倍 | プランだけでは動かない |
| 4 | ほぼ成功 | 3-4倍 | AgentのTool実行は思い通りに動かなかった |
| 5 | 安定動作 | 最適 | LLMとコードの役割分担が鍵 |
今回の試行錯誤で学んだこと3つ
AIエージェント開発にまだ正解はない
OpenAI Agents SDKが公式SDKだからといって、ドキュメント通りに実装すれば終わりではなく、検証を重ねて要件に合う設計を見つけることが重要でした。
LLMとコードの役割分担が鍵
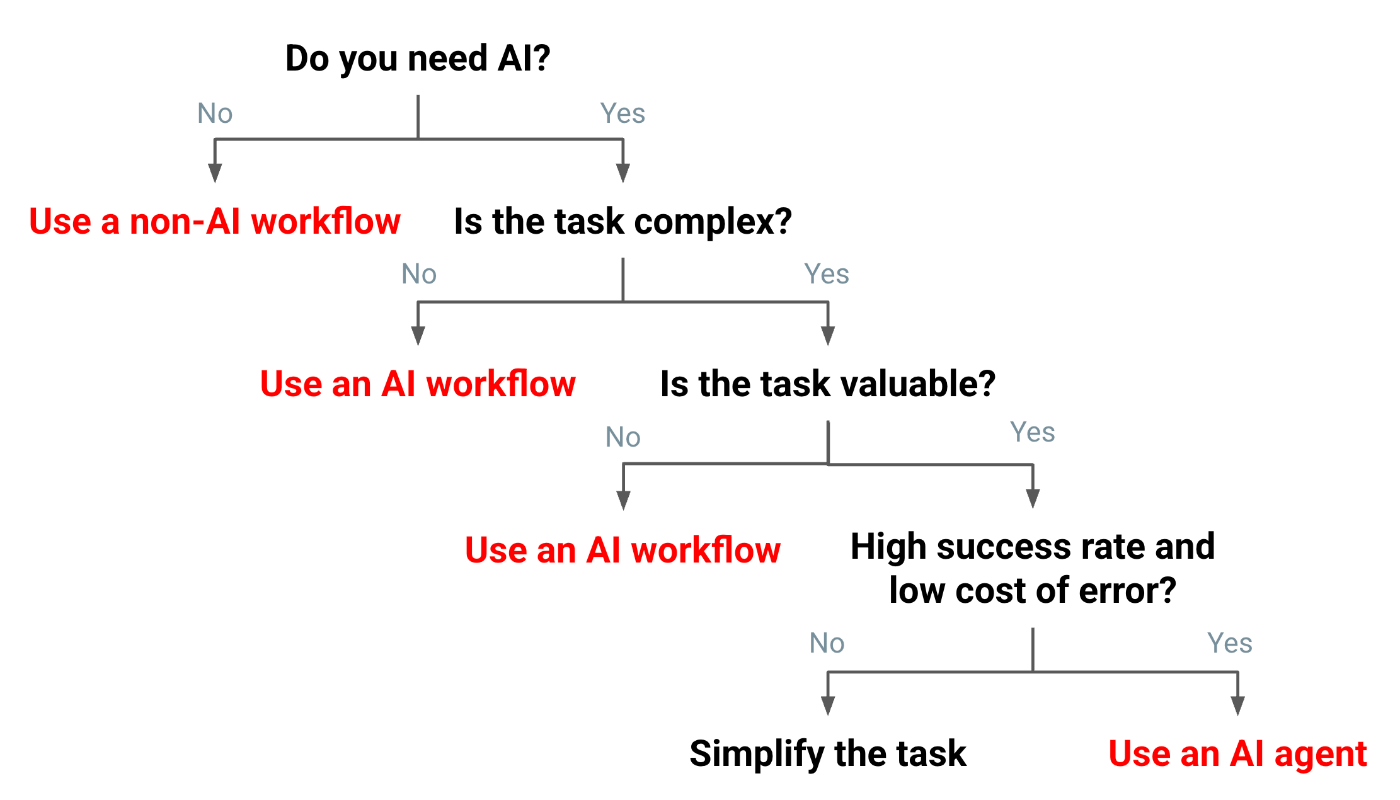
この図を見て、AIエージェントを実装した後でこそ深く共感しました。LLMの得意なこと(判断・計画)とコードの得意なこと(制御・実行)、さらにはエージェントとして開発すべきこと、ワークフローでもいいことを明確に分けることが必要でした。
試行錯誤の価値
試行1〜4でSDKの限界を体感し、最終的に「Plan with LLM, Execute with Code」という独自設計にたどり着きました。5回の試行錯誤は無駄ではなく、システムの本質を理解するための必要なプロセスでした。素早く試すことは大事だなと感じました。
最後に
AI技術の発展が速い今だからこそ、新しい技術をまず試してみることの価値を実感しました。完璧を求めるより、とりあえず素早く手を動かして学ぶことを続けていきたいと思います。
失敗を恐れず、実装して、改善する。それが今のAIエージェント開発の本質かもしれません。
この記事が、これからAIエージェントを開発する人の「失敗」を少しでも有意義なものにできれば幸いです!
最後まで読んでいただき、ありがとうございました。
参考リソース
Views: 0

{kind=link}