

はじめに
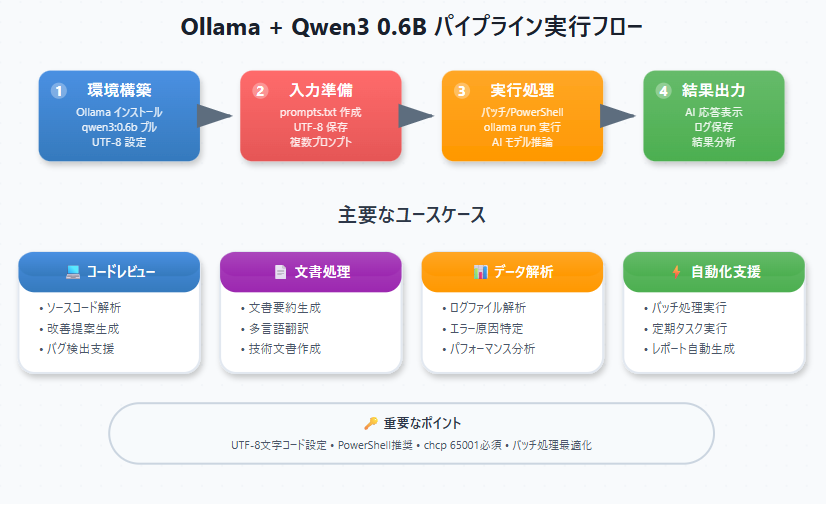
軽量で高性能なローカルLLMの活用が注目を集めています。特にQwen3の0.6Bモデルは、限られたリソースでも実用的な性能を発揮する優秀なモデルです。本記事では、Windows環境のコマンドプロンプト(CMD)を使って、OllamaでQwen3 0.6Bモデルを動かし、効率的なパイプライン処理を実現する方法を備忘録します。
実行例の動画です。処理中の様子やパフォーマンスがわかると思います。
環境構築
筆者の動作確認環境
- Windows 11 (日本語)
- Ollama(最新版)
- PowerShell
- 32GBのRAM (ただしミニPC)
Ollamaのインストール
まず、Ollamaの公式サイトからWindows版をダウンロードしてインストールします。
# インストール確認
ollama --version
Qwen3 0.6Bモデルのダウンロード
# Qwen3 0.6Bモデルのプル
ollama pull qwen3:0.6b
# インストール済みモデルの確認
ollama list
基礎的なOllama Run使用法
単発実行
最もシンプルな使用方法から始めましょう。
# 基本的な質問応答
ollama run qwen3:0.6b "Pythonでリストを作成する方法を教えて"
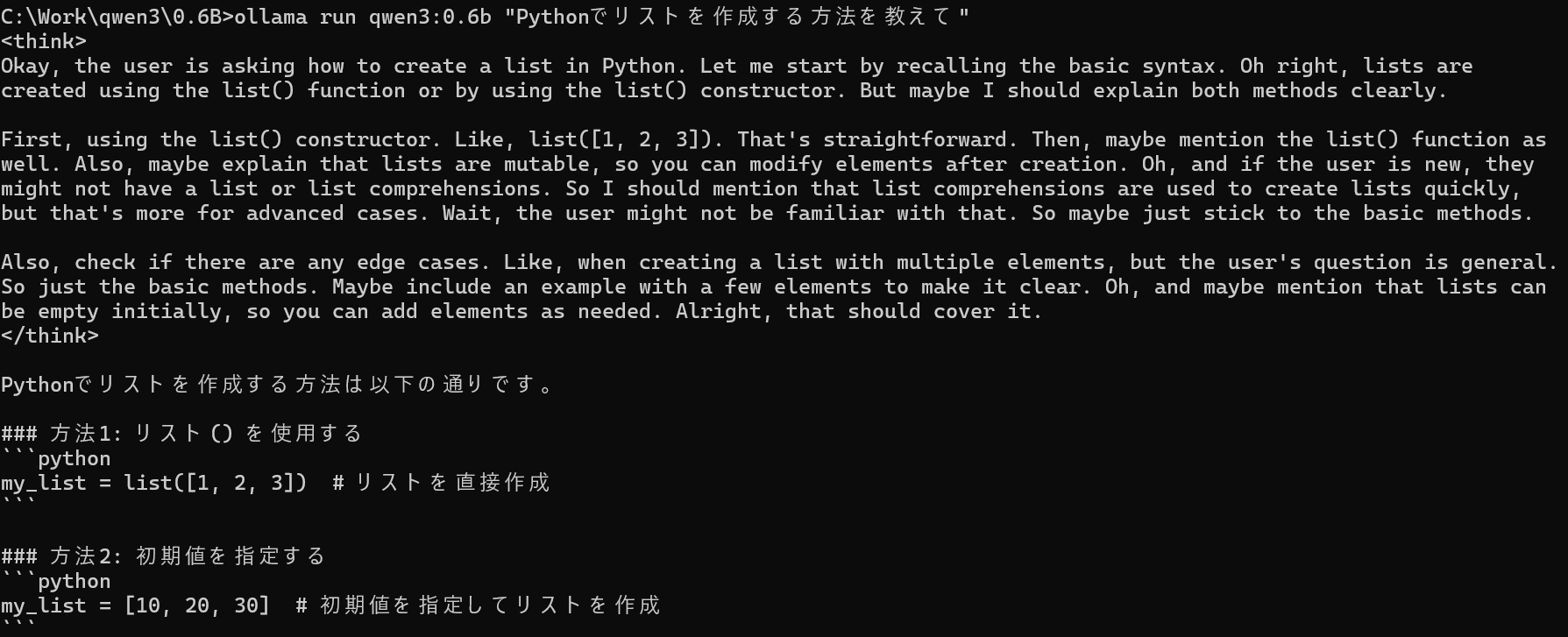
自環境では数秒で出力された。
インタラクティブモード
# 対話的なセッション開始
ollama run qwen3:0.6b

対話モードでは、継続的な会話が可能になります。終了するには/byeと入力します。
パイプライン処理の実装
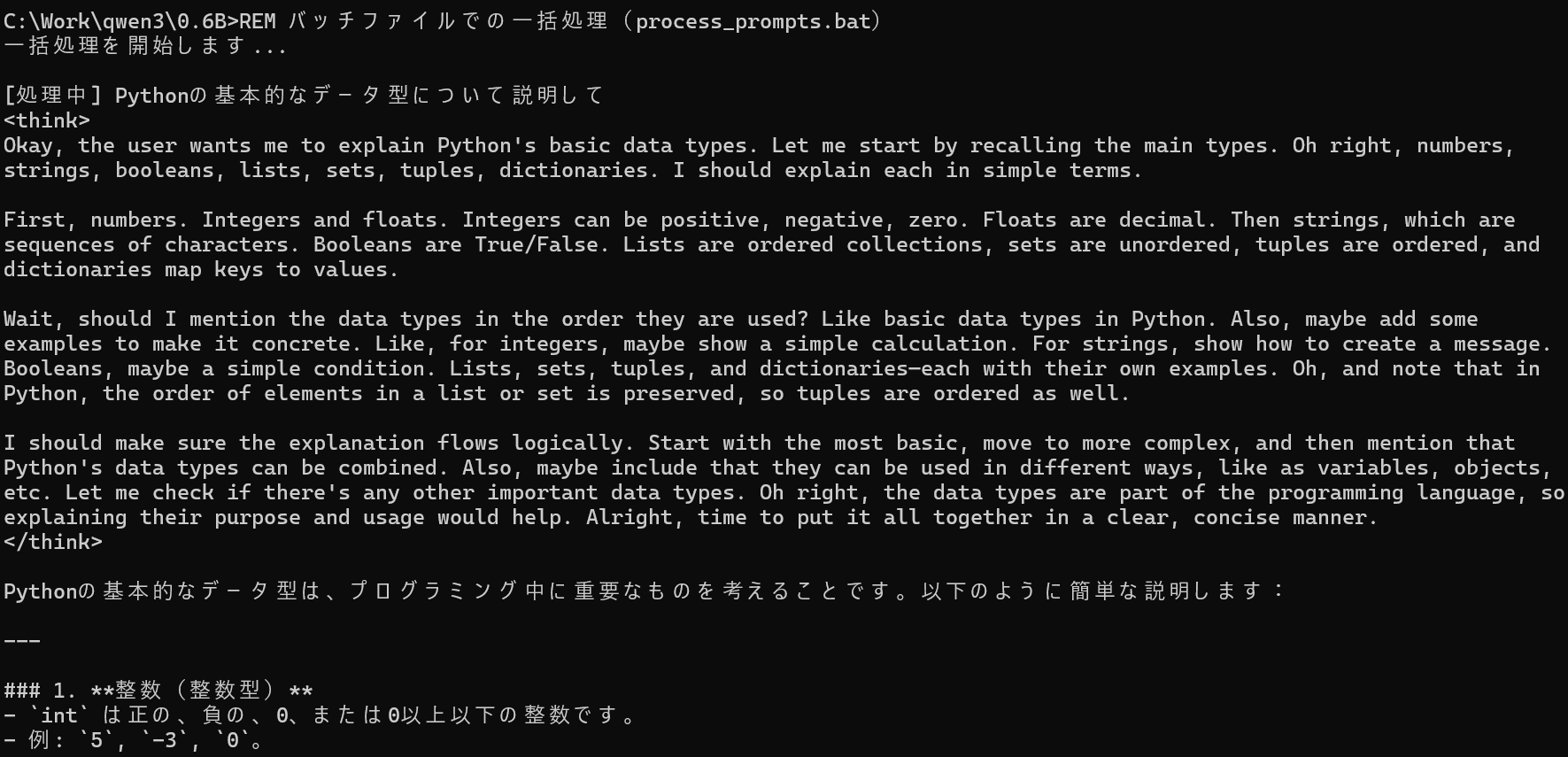
テキストファイルからの一括処理
複数のプロンプトを効率的に処理するパイプラインを構築してみましょう。
REM プロンプトファイルの作成(UTF-8形式で保存)
chcp 65001 >nul
echo Pythonの基本的なデータ型について説明して > prompts.txt
echo 機械学習の概要を簡潔に教えて >> prompts.txt
echo Webスクレイピングの基本手順は? >> prompts.txt
@echo off
chcp 65001 >nul
setlocal enabledelayedexpansion
echo 一括処理を開始します...
echo.
for /f "usebackq delims=" %%i in ("prompts.txt") do (
echo [処理中] %%i
echo %%i | ollama run qwen3:0.6b
echo.
echo ================================
echo.
)
echo 全ての処理が完了しました。
pause
バッチファイルは文字コードUTF-8 BOM付きで保存した。
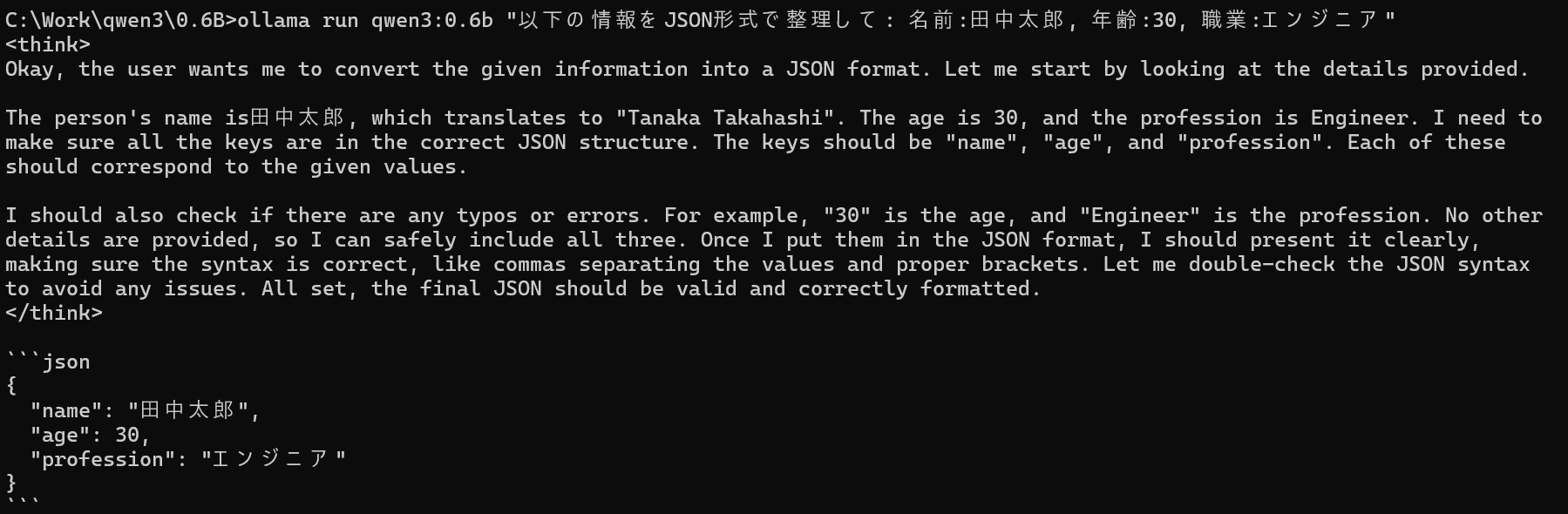
JSON形式での構造化出力
構造化されたデータを処理する場合のパイプライン例:
# JSON形式での質問処理
ollama run qwen3:0.6b "以下の情報をJSON形式で整理して: 名前:田中太郎, 年齢:30, 職業:エンジニア"
パイプライン活用例
ログファイル解析パイプライン
# ログ解析用バッチスクリプト(analyze_logs.bat)
@echo off
echo ログファイル解析を開始します...
for /f "tokens=*" %%a in (error_logs.txt) do (
echo %%a | ollama run qwen3:0.6b "このエラーログを解析して原因と対策を教えて: "
echo.
)
文書要約パイプライン
# 文書要約処理
type document.txt | ollama run qwen3:0.6b "以下の文書を3行で要約してください:"
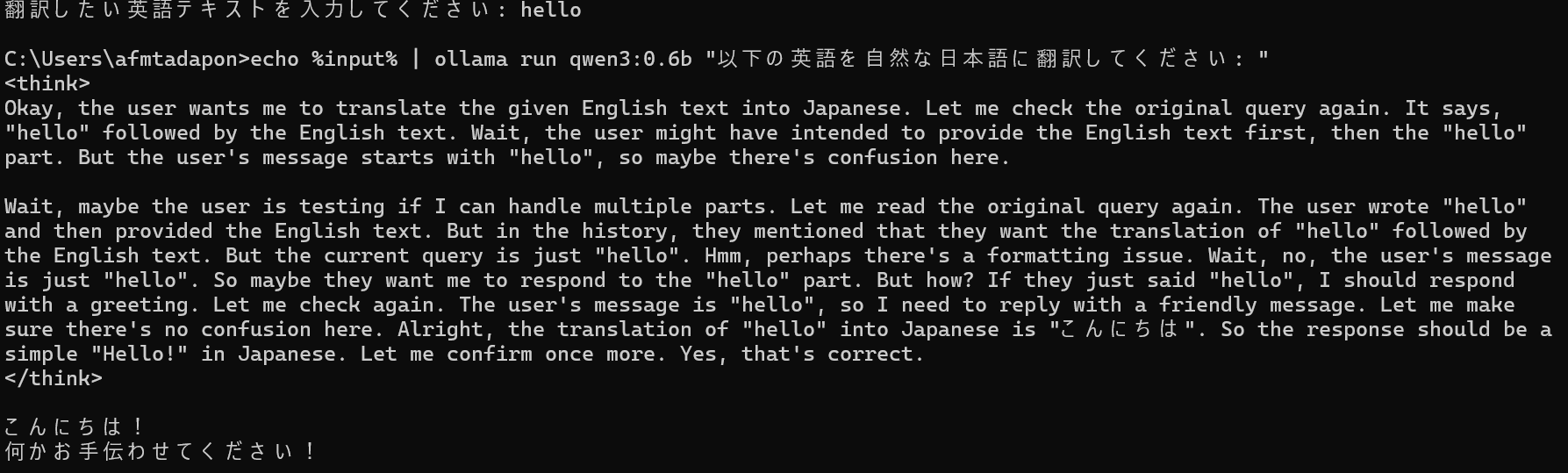
翻訳パイプライン
# 英日翻訳パイプライン
@echo off
set /p input="翻訳したい英語テキストを入力してください: "
echo %input% | ollama run qwen3:0.6b "以下の英語を自然な日本語に翻訳してください: "
コード レビュー支援
# コードレビュー用パイプライン
type sample_code.py | ollama run qwen3:0.6b "以下のPythonコードをレビューして、改善点があれば指摘してください:"
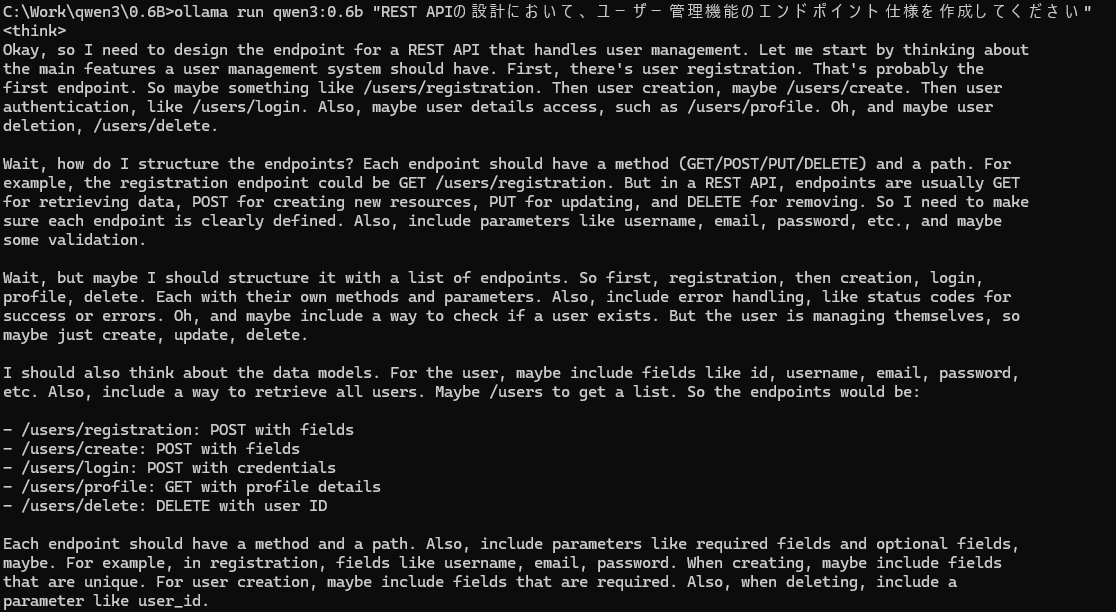
技術文書の生成
# API仕様書生成
ollama run qwen3:0.6b "REST APIの設計において、ユーザー管理機能のエンドポイント仕様を作成してください"
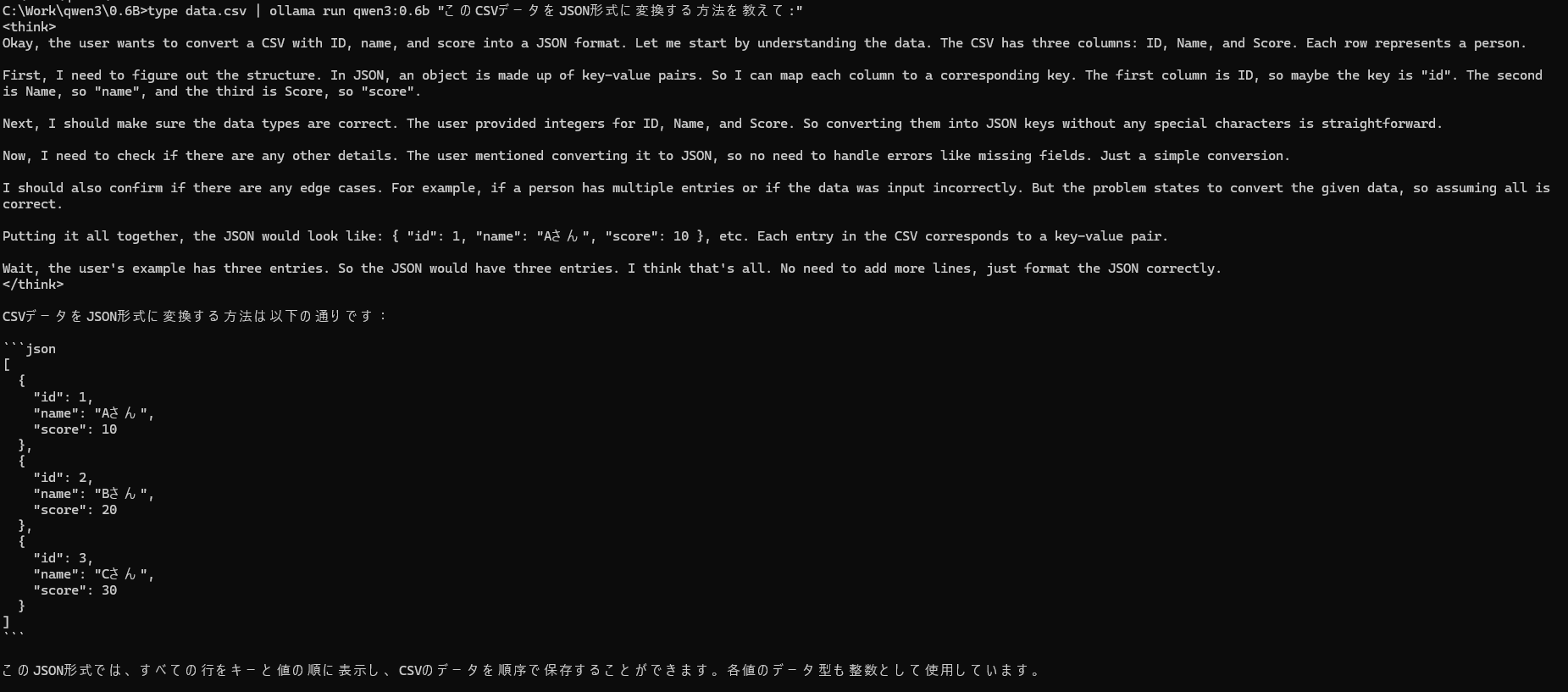
データ変換処理
# CSV to JSON変換支援
type data.csv | ollama run qwen3:0.6b "このCSVデータをJSON形式に変換する方法を教えて:"
まとめ
Ollama RunとQwen3(Qwen2.5)0.5Bモデルを組み合わせることで、Windows環境でも効率的なAIパイプラインを構築できます。軽量でありながら実用的な性能を持つこのモデルは、以下のような場面で特に威力を発揮します:
- 開発支援: コードレビュー、文書生成、デバッグ支援
- データ処理: ログ解析、テキスト変換、要約処理
- 業務効率化: 翻訳、文書整理、情報抽出
ローカル実行可能な軽量LLMの重要性はますます高まるでしょう。本記事で紹介したテクニックを活用して、効率的なAI駆動の自動化パイプラインを構築できるかもしれません。
クリップボードコピーのコマンドとの連携など便利かもしれません・・・
感想: LLMのモデルによって特性や精度、扱える文字列長さに違いがあるため、適したタスクに分割して任せることが十分可能になってきた、という感じです。
参考リンク
Views: 0

{kind=link}