
はじめに
本記事では Kubernetes – NixOS Wiki の環境をベースに、おうち Kubernetes クラスターを構築することをテーマとしています。
本記事の著者は、これまでインフラやネットワークといった領域にそこまで深く踏み込んだことがなく、そのあたりの技術力に少し不満があったため、勉強がてらに元々あった自宅サーバーの環境を刷新しつつ、ついでに NixOS + Kubernetes というロマンの塊のような技術スタックで作る自宅サーバーの簡単なガイドを作ってやろうという目的のもと執筆を行っています。
そのため、本記事の半分は学習目的であり、NixOS やインフラに精通した人物が執筆したものではない点についてご留意ください。
また、本記事は以下の方針に基づき執筆されています。
- NixOS + Kubernetes という技術スタックで、どのように自宅サーバーを構築したかの全体像を把握できること。
- 開発に用いた個別具体的な技術の使い方はほどほどに、その技術のコンセプトの説明や、その技術を使った問題解決の方針の説明を重視すること。
上記の背景から、NixOS とタイトルにあるものの、単にオンプレ環境における Kubernetes の構築の参考として使うことも可能と考えています。
また逆に NixOS とはどういったものかを大まかに解説したり、NixOS と Arch Linux(と Ubuntu)を比較するといった内容も含まれているため、NixOS の一技術記事としてもご活用いただけると思います。
一方で、NixOS と Kubernetes という学習コストの高い技術を同時に扱う都合上、全体で短編小説ほども文量がある技術記事となってしまっております。
すべてを読み通すのは大変だと思いますので、本記事では気になる見出しからご覧いただくことを推奨しています。
本記事では上記の都合上、いたずらに文量を増やさないため、技術の導入方法や具体的な使い方といった、すでに他の技術記事やドキュメントによって解説されている箇所は一部省略し、参考としてリンクを積極的に記載するという方針を採用しています。
そのため結果的に本記事は、NixOS + Kubernetes で自宅サーバーを構築するための Howto は他の記事に譲りつつ、そこで解説されていないが重要だと考える項目を補完することに重きを置くことになりました。
なので本記事は、そうした参考をひっくるめて一つの技術記事として成立しますので、参考に記載したリンク先も合わせてご覧いただけますとよりご理解いただけると思います。
また、私のサーバー環境のすべては dotfiles で管理されています。
解説に関連する実装は dotfiles dir という形でファイルへのリンクを置いていますので、そちらを参考にしていただけますと幸いです。
本記事では以下の前提知識を仮定しています。
- 基本的なプログラミングを行うことができる。
- Linux に関する基本的な知識がある。
- Kubernetes の基本的な用語に関する知識がある。
- TCP/IP に関する基本的な知識がある。
旧自宅サーバー環境
刷新前の自宅サーバーは、Arch Linux で構築された開発サーバーや、Windows PC 内の GPU リソースを利用できる WSL に、MacBook Pro から SSH で接続して開発するという非常にシンプルな構成でした。
その際に Tailscale で VPN 環境を構築して通信を行っていました。
これにより、インターネットに接続できる環境であれば、宅内だけでなく外出先でも MacBook Pro で開発できるようにしていました。
さらに Android や iOS といったモバイル端末を Tailnet に参加させておくことで、モバイル向けの UI を伴う Web アプリケーションの開発時に、モバイル端末から開発サーバーで立ち上がっているアプリケーションへ http で確認することもできます。
また、サーバーの電源を必要なときだけ稼働させておきたい気持ちがあったので、外出の際は Raspberry Pi を常時稼働させ、そこから各サーバーの電源を Wake-on-Lan で起こせるようにすることで、サーバーを使わないときは電源を落とせるようにしていました。
こうして MacBook Pro によってそれなりのスペックのラップトップを持ち運びつつ、どこからでも強いサーバーのリソースを利用できるようになり、開発面においてほぼ不満のないインフラ環境を構築することができました。
実現したいこと
今回の自宅サーバー刷新では、上記の機能に追加して以下のことができるようになることを目標としていました。
- Dropbox や OneDrive のようなストレージサービスの提供
- 手持ちの端末間でパスワード等の機密情報を安全に管理できる仕組みの提供
- クラスターが提供する各アプリケーションに対して、自分だけが名前解決できる独自ドメインを使いつつ、セキュアにアクセスできる
- 稼働するサーバーのログやメトリクスを収集する基盤作成
正直これをやるだけであれば Kubernetes を導入する必要はないのですが、今回は学習目的も兼ねているため、オーバーエンジニアリングは許容して構築を進めていきます。
OS 選定
今回自宅サーバーで利用するディストリビューションとして NixOS を選択しました。
半分趣味の側面もあるのですが、今回は NixOS の再現性と宣言的という性質を最大限活かすためこの技術選定をいたしました。
Nix/NixOS とはなにか
Nix とは、純粋関数型言語である Nix 言語を用いて、開発環境やビルド環境に必要なパッケージを宣言的に管理できるツールです。
例えば Node.js を採用するプロジェクトの開発環境を考えてみましょう。
Node.js のバージョンを揃えるために Volta や nvm といったバージョン管理ツールを使うこともありますし、Docker を使って Node.js の実行環境を用意するケースもあるでしょう。
もしこのバージョン管理を Nix で行う場合、以下のような flake.nix ファイルをプロジェクトに作成することになります。
{
description = "node.js";
inputs = {
nixpkgs.url = "github:nixos/nixpkgs?ref=nixos-unstable";
flake-utils.url = "github:numtide/flake-utils";
};
outputs = { self, nixpkgs, flake-utils }:
flake-utils.lib.eachDefaultSystem (system:
let
packages = nixpkgs.legacyPackages.${system};
in
{
devShells = {
default = packages.mkShell {
buildInputs = with packages; [
nodejs_22
];
shellHook = ''
echo "Node.js version: $(node --version)"
'';
};
};
}
);
}
このファイルが存在するディレクトリで nix develop を実行すれば、Node.js が使えるシェルへと入ることができます(ホストのグローバルなアプリケーションとしてインストールしているわけではなく、このシェルの中のみで Node.js は有効になります)。
もし Node.js のパッケージマネージャーとして pnpm を利用したいのであれば、buildInputs の中に nodePackages.pnpm を追加するだけで OK です(他に利用したいツールがあっても基本的には同様です)。
buildInputs = with packages; [
nodejs_22
nodePackages.pnpm
];
ところで、Nix は Docker のような仮想化技術を用いておらず、パッケージを動作させるために必要な依存関係をローカルにインストールし、それらのリソースを用いてパッケージを動作させます。
上記のようなシンプルな環境であれば良いかもしれませんが、もしさらに複雑なパッケージ管理を必要とするプロジェクトの場合、仮想化なしでマシン間の動作差がない開発環境を用意できるのかという、至極最もな疑問が出てくると思います。
ですが、Nix ではそうした問題は原理上発生しません。
Nix builds packages in isolation from each other. This ensures that they are reproducible and don’t have undeclared dependencies, so if a package works on one machine, it will also work on another.
引用: https://nixos.org、2025年10月3日訪問
Nix はパッケージを互いに隔離して構築します。これにより、パッケージの再現性が保証され、宣言されていない依存関係が存在しないため、あるマシンで動作するパッケージは、別のマシンでも動作します。
Nix は依存関係の衝突や暗黙的な依存関係が発生しないようにパッケージ間で発生する依存関係を裏側で厳密に管理しているため、UNIX 系の OS であれば、ホストの環境に依存しない安定した開発環境を提供することができます。
そして、この Nix の仕組みを OS レベルに適用したものが NixOS になります。
Nix では管理者権限が必要な領域まで操作することはできませんが、NixOS ではユーザーの管理、パーティション、ネットワークやファイアウォールの設定、systemd で動くデーモンの管理などなど、ありとあらゆる設定を宣言的に管理できるようにしたディストリビューションです。
例えば Docker をインストールしたいなぁ……と思ったら、以下の設定を追記するだけで導入が完了します。
{
virtualisation.docker.enable = true;
}
なぜ NixOS なのか
改めてなぜ今回の Kubernetes を用いた自宅サーバー構築で NixOS に目をつけたのかというと、それは NixOS が持つ 再現性 と 宣言的 という 2 つの特徴が今回のケースにマッチすると考えたからです。
今回の環境構築では、合計 3 つのサーバーのセットアップを行うことになります。
1 つ 1 つのサーバーのセットアップを行うのは面倒ですし、また今回 Raspberry Pi をノードに参加させたかったので、CPU アーキテクチャの違いによる動作差も懸念されていました。
では、もしここで NixOS を使うとどうなるのでしょうか。
まず、各サーバーのセットアップが数コマンドで完了します。
NixOS は特性上、1 回動く環境を作ってしまえば、どのマシンに持っていっても基本的には同様に動く環境を簡単に再現できます。
この強力な再現性により、面倒な複数台のサーバーセットアップを爆速で完了することができます。
また、設定がすべて .nix ファイルとして管理されているため、サーバー間で共通の設定を再利用することが可能です。
例えば NixOS における Kubernetes の Worker Node の設定は以下のようになっています。
ここから新しく Worker Node を増やしたいとなった場合、上記の設定をサーバーに import するだけでセットアップがほぼ完了します。
{
imports = [
path/to/node.nix
];
}
将来的にノードを増やすことが考えられたため、ほぼ確実に動くであろうノードの設定を再利用できるのは大きなメリットになると考えました。
そして CPU アーキテクチャについてですが、NixOS では設定項目の中に system というプロパティがあり、ここに aarch64-linux を指定すると、 arm64 に対応した状態で OS をビルドしてくれるので、基本的には CPU アーキテクチャの差異を考える必要はありません(ただし必ずしもすべてではない)。
{
nixosConfigurations = {
yomogi = inputs.nixpkgs.lib.nixosSystem {
system = "aarch64-linux";
specialArgs = {
inherit inputs outputs;
vars = import ./vars;
impurelibs = import ./impurelibs;
};
modules = [
./hosts/yomogi/configuration.nix
];
};
};
}
まとめると、NixOS の再現性と宣言的という特性を活用することで、複数あるサーバーの個別ないし共通の設定を簡単に管理しつつ、素早く安定した環境構築ができると考えたから ということですね。
サーバー構成
自宅にはサーバーが 5 台あり、今回クラスターに参加させるノードはそのうち 3 台になります。
大まかなサーバースペックは以下のとおりです。
(家のサーバーが多くなり、それぞれを区別する必要が出てきたため、ホスト名に各サーバーの呼び名をつけています)
| Machine | Hostname | Role | CPU/GPU | RAM | Storage |
|---|---|---|---|---|---|
| Raspberry Pi 4 | yomogi (蓬) |
Control Plane | ARM Cortex-A72 | 4GB | 64GB(SD カード) |
| Mini PC 1 | tokiwa (常磐) |
Worker | Intel N97 | 16GB | 512GB(M.2 SSD) |
| Mini PC 2 | hanaakari (花明かり) |
Worker | Intel N97 | 16GB | 512GB(M.2 SSD) 1 TB(外付け SSD) |
| Arch Linux Dev Server |
shiosai (潮騒) |
– | Intel Core i5-13400 | 32GB | 1 TB(M.2 SSD) |
| Windows PC(WSL) | fujibakama (藤袴) |
– | Intel Core i5-12600K + NVIDIA GeForce RTX 5070 | 32GB | 1 TB x 2(M.2 SSD) |
蓬サーバー(Raspberry Pi)を Control Plane とし、Mini PC x 2 台にアプリケーションをデプロイしていく方針です。
ただ、Raspberry Pi を単一の Control Plane として運用する方法は基本的におすすめしません(理由へジャンプ)。
また、後に解説しますが、クラスターのストレージの供給として Rook Ceph を利用しており、容量確保のため花明かりサーバー(Mini PC 2)に 1TB の 外付け SSD をマウントしています。
Raspberry Pi には以下の記事に従って NixOS をインストールしました。
ただし上記の通りにインストールを進めてしまうと、NixOS 23.11 が入ってしまうため、最新のイメージファイルを探す必要があります。
以下のビルドから対象のイメージファイルを探してインストールしてください。
基盤構築 – NixOS
今回使用した NixOS のバージョンは 25.05 になります。
NixOS にまつわる大まかなアーキテクチャは以下のとおりです。
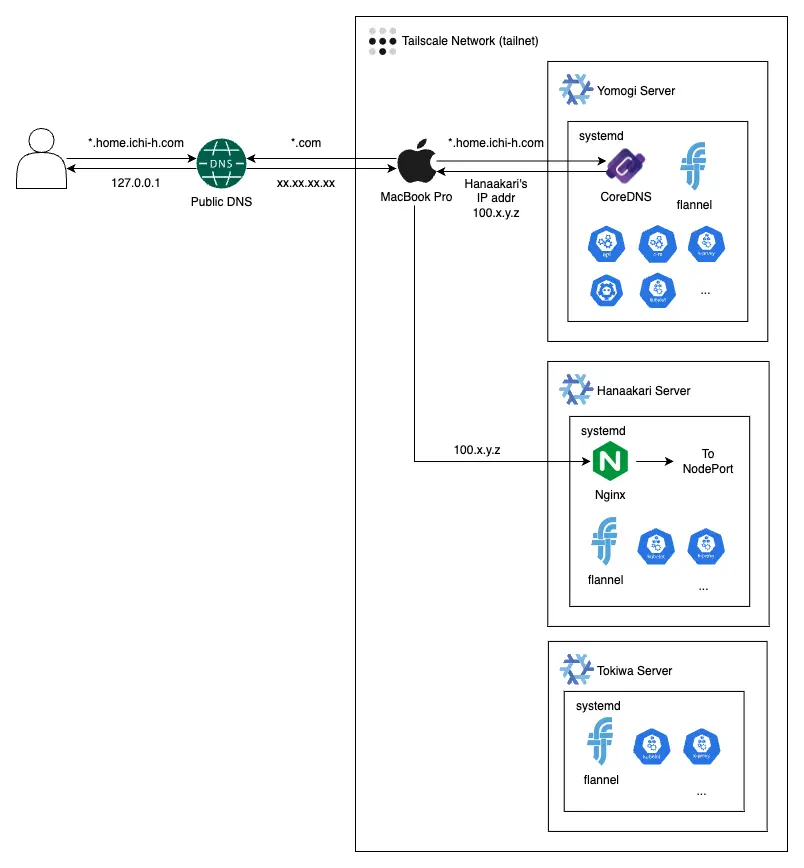
Kubernetes
NixOS では Kubernetes のパッケージが公式から提供されています。
導入方法は下記のリンクをご参照いただければと思います。
NixOS でクラスターを構築する場合、kubeadm 等を用いて構築したときと比べ、一部構成に相違点があるため、簡単に解説させてください。
例えば kubeadm でクラスターを立ち上げた場合、kubelet はホストのサービスとして在中し、apiserver、etcd、control-manager、scheduler といったコンポーネントは Static Pod として立ち上がるのが一般的な構成だと思います。
しかし、NixOS でクラスターを立ち上げる場合、基本的には上記のコンポーネントをすべて systemd のサービスとして管理することになります。
Kubernetes の設定の中に services.kubernetes.roles という項目があり、こちらに master か node、もしくは両方を設定することで立ち上げるサービスを選択することができます。
{
services.kubernetes.roles = ["master" "node"];
}
具体的には以下のものが立ち上がります。
- master
- etcd
- apiserver
- scheduler
- controller manager
- addon manager
- flannel
- proxy
- node
- flannel
- docker
- kubelet
- proxy
services.kubernetes.roles の設定を行った場合、いくつかのサービスが自動的に有効になります。
まず、上記のリストの通り CNI として Flannel が自動的に選択されます。
ホストで Flannel が立ち上がっていたとしても、基本的な仕組みは同様になりますので、詳細は割愛させていただきます。
詳しくは以下の記事が参考になると思います。
また、easyCerts という機能も自動的に ON になります。
これはノード間で通信する際に使用する証明書を自動で発行・更新してくれる非常に便利な機能なのですが、公式の見解としては 「for a production-grade cluster you shouldn’t use easyCerts(本番環境のクラスタでは easyCerts を使用すべきではありません)」 とのことなので注意が必要です(今回の開発では easyCerts を利用しています)。
VPN + Local DNS
各端末間の通信は前環境に引き続き Tailscale を用いて行っています。
Tailnet 内で公開されているマシンと通信する方法として一番簡単なものは、Tailscale から提供される IP アドレス(例: 100.xx.xx.xx)を使うというものだと思います。
しかし、ただの数字の羅列をいくつも覚えるのは人間がするべきことではないので、もっと楽な方法で解決したいところです。
別の方法として、https://login.tailscale.com/admin/dns ページから確認できる Tailnet DNS name と各マシンのホスト名を組み合わせた hostname.xxxx-xxxxx.ts.net というドメインを使って通信する方法もあります。
IP アドレスに比べれば覚えやすく、仮に IP アドレスが変わったとしても変化しない。そしてこのドメインに対して TLS 証明書を発行できるという、状況によっては強力な機能を使うこともできます。
なのですが、できればこれも使いたくないのです……。
というのも、Tailnet DNS name の一部がランダムな文字列になっていたり、またこの名前を変更することも可能ですが、コンソールを確認する限り、現状では任意のドメイン名を使うことができないようなので、使い勝手が少し悪いのです。
一番の理想は、
- 独自ドメインを使って通信でき、
- TLS 証明書を発行しつつ、
- そのドメインを外部の人が踏んでも自宅サーバーに繋がらない
といった具合なのですが、実はこれ全部実現できます。
証明書は Kubernetes の章で紹介するとして、1 番と 3 番については Tailscale の Split DNS という機能を使うことで実現できます。
これは何なのかというと、特定のドメインに対する名前解決を指定した DNS で行うという機能です。
設定方法としては、https://login.tailscale.com/admin/dns から「Nameservers」の項目に進み、「Add nameserver」というセレクターから「Custom…」の項目をクリックすると下記のようなモーダルが表示されます。
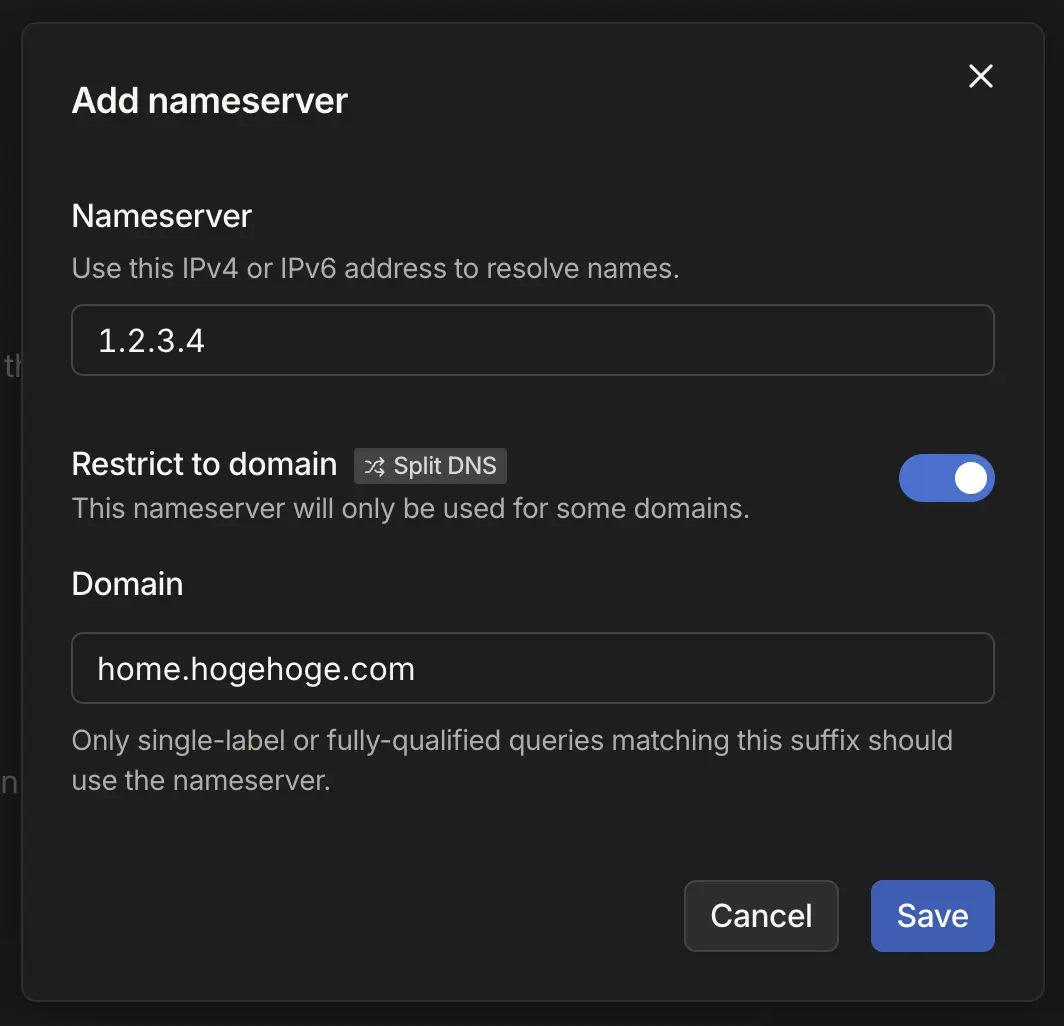
この設定では、home.hogehoge.com というドメインの名前解決には、1.2.3.4 というネームサーバーを使うことになります。
ここに自分が所有しているドメインと、そのドメインの名前解決ができる DNS を用意できれば、Tailnet 内でのみで解決可能なドメイン名を使用することができます。
アーキテクチャ図でこの仕組みを表現した部分は以下になります。
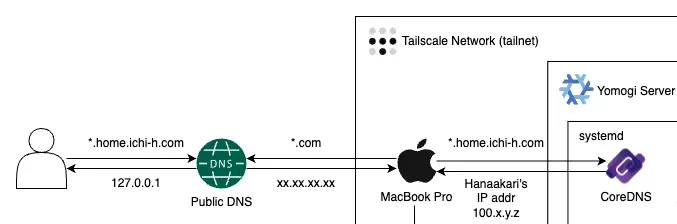
私の環境では home.ichi-h.com というドメインを自宅サーバーに割り当てています。
このドメインに対して Tailnet に参加していない端末からアクセスしようとすると、Public DNS によって 127.0.0.1 へと解決するようになっています。
一方、Tailnet に参加している端末がこのドメインにアクセスしようとすると、Split DNS 機能により、home.ichi-h.com のドメインのみ蓬サーバー(Raspberry Pi)から提供される Local DNS を使用して名前解決を行います(それ以外のドメインは Public DNS を用いて通常通り名前解決を行います)。
今回は CoreDNS を用いて Local DNS を立ち上げました。
下記の設定により、home.ichi-h.com を含むドメインは、すべて花明かりサーバー(Mini PC 2)へと名前解決されます。
{ impurelibs, ... }:
{
services.coredns = {
enable = true;
extraArgs = [
"-dns.port=53"
];
config = ''
.:53 {
log
errors
template IN A home.ichi-h.com {
match "^(.+\.)?home\.ichi-h\.com\.$"
answer "{{ .Name }} 60 IN A ${impurelibs.secrets.ip-address-hanaakari.tailscale}"
fallthrough
}
forward . 1.1.1.1 1.0.0.1
cache 30
health
}'';
};
}
Proxy Server
上記のドメインの解決先となる花明かりサーバー(Mini PC 2)では、Nginx を用いて Kubernetes の Node Port で公開された Traefik(Kubernetes の章にて後述)へリバースプロキシを行っています。
下記では 80 番と 443 番ポートへのトラフィックを 31080 番と 31443 番へポートフォワーディングしています。
events {
worker_connections 1024;
}
stream {
upstream traefik_https {
server localhost:31443;
}
upstream traefik_http {
server localhost:31080;
}
server {
listen 443;
proxy_pass traefik_https;
proxy_protocol off;
}
server {
listen 80;
proxy_pass traefik_http;
}
}
以上の設定により、花明かりサーバーがクラスターへの唯一のエントリーポイントとなり、外部からのアクセスが単一ノードに集約されることになります。
補足: ロードバランシングについて
上記では Node Port へのリバースプロキシを行っていましたが、今回の自宅サーバー構築では、ロードバランサーの導入やそれによる冗長性の確保は行わないという方針を選択しています。
おそらくオンプレ環境では、Service Load Balancer + MetalLB でロードバランシングを行うのが一般的な構成だと思います。
しかし今回は Split DNS を使用したことにより、名前解決の時点で特定のサーバーとの通信が確定してしまいます。
もし Split DNS を使いつつロードバランシングも行う場合、名前解決時にどのサーバーへアクセスするかを決定する等の仕組みが必要ですが、そもそもサーバーの利用者は 1 人なので、現時点でそこまで複雑な仕組みを導入する必要はないだろうと判断しました。
Firewall
NixOS + Kubernetes で環境構築した際にハマりやすい沼の 1 つに Firewall があります。
ここの設定をミスると、「なぜか Control Plane のノード内の Pod から kube-apiserver へのリクエストだけが通らない」などの謎現象が起こります。
試行錯誤した結論としては、私の環境では 10.0.0.0/8 と 192.168.10.0/24 からのリクエストを信頼することで動くようになりました(ただし前者について、一応 Private IP Address といえどかなり広い範囲を開けているので、トラフィックが来うる CIDR に絞って開けることを推奨します)。
{
networking = {
networkmanager.enable = true;
firewall.enable = true;
firewall.extraCommands = ''
iptables -A nixos-fw -s 10.0.0.0/8 -j nixos-fw-accept
iptables -A nixos-fw -s 192.168.10.0/24 -j nixos-fw-accept
'';
};
}
Rook Ceph 関連
サーバースペックを紹介した際に少しお話しましたが、ストレージに Rook Ceph を利用している関係で、設定をいくつか追加する必要があります。
私の環境では、NixOS が提供する Kubernetes のドキュメントや、Rook Ceph が紹介している設定とも少し違う結果になっておりますので、以下の設定は参考程度にお捉えください。
{
boot.kernelModules = [ "ceph" "rbd" ];
services.kubernetes.kubelet.extraOpts = "--root-dir=/var/lib/kubelet";
systemd.services.containerd.serviceConfig = {
LimitNOFILE = "1048576";
};
}
基盤構築 – Kubernetes 編
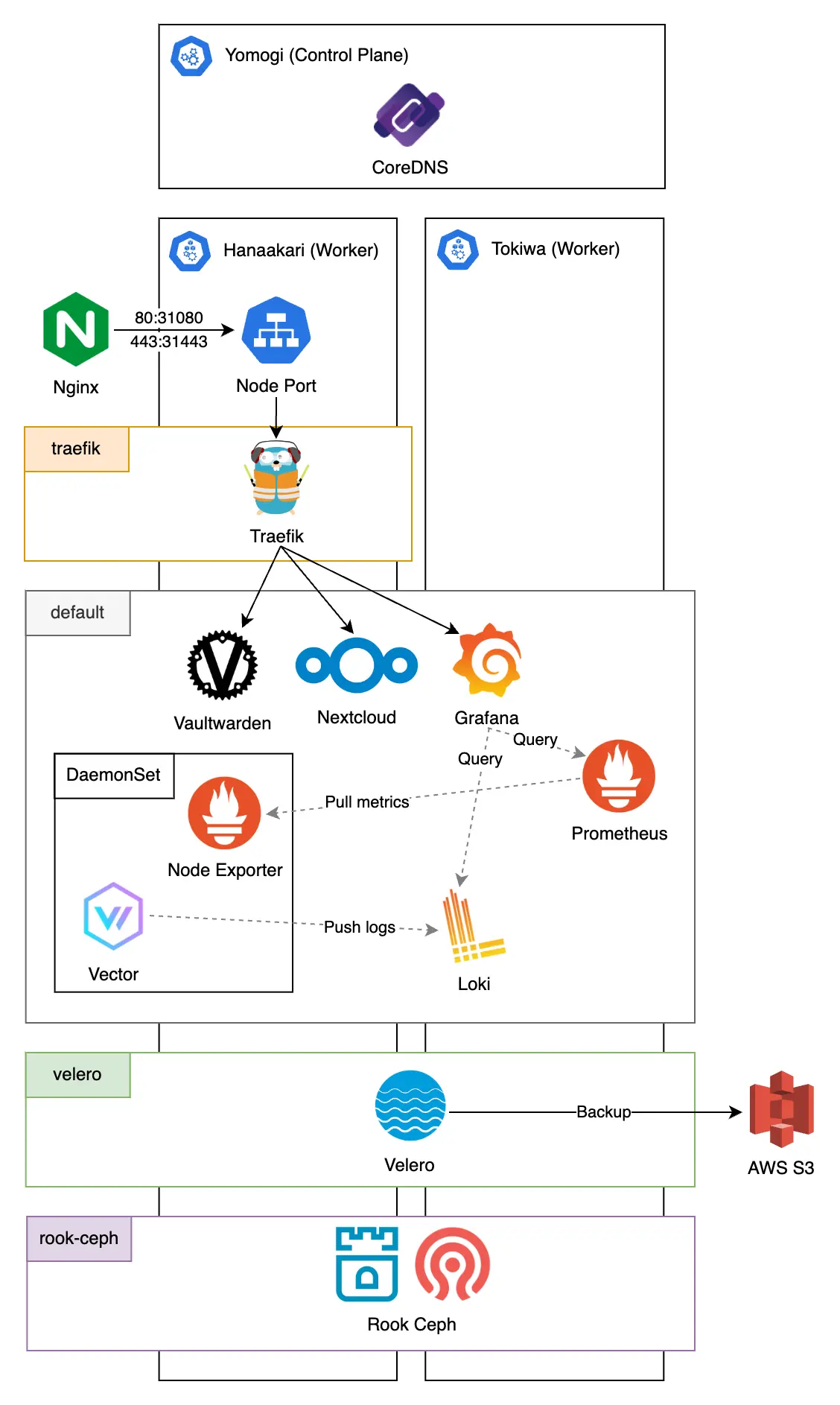
この章では Kubernetes クラスターの基盤を担うアプリケーションについてお話できればと思います。
使用している Kubernetes のバージョンは v1.33.0 です。
またクラスター構築に際して以下のツールを使用しています。
- helm
- helmfile
- helm-secrets
- K9s
アーキテクチャ図は以下のとおりです。
Ingress Controller
Ingress Controller もとい Proxy Server には Traefik を採用しました。
Proxy Server の設定は Nginx が一番慣れているのですが、Traefik は設定が楽という噂を聞いたので試してみることにしました。
Proxy Settings
Traefik を Ingress Controller として使用する場合、最低限以下の設定で動作します。
ports:
web:
nodePort: 31080
websecure:
nodePort: 31443
service:
type: NodePort
nodeSelector:
role: application
proxy: "true"
アプリケーションをルーティングしたい場合は、以下のように Service と Ingress を設定すれば動くようになると思います。
apiVersion: v1
kind: Service
metadata:
name: app-svc
spec:
type: ClusterIP
selector:
app: app
ports:
- name: http
port: 80
targetPort: 80
protocol: TCP
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
traefik.ingress.kubernetes.io/router.tls: "true"
name: app-ing
namespace: default
spec:
rules:
- host: app.localhost
http:
paths:
- backend:
service:
name: app-svc
port:
name: http
path: /
pathType: Prefix
tls:
- hosts:
- app.localhost
これで Traefik がデプロイされているサーバーに対して http://app.localhost:31080 または https://app.localhost:31443 でアクセスできるようになります。
上記の設定の場合、HTTPS 通信時には Traefik から提供される自己署名証明書が用いられます。
Certification
証明書の発行には Let’s Encrypt を用います。
自分しか使わないサーバーなので、自己署名証明書でも問題はないのですが、ブラウザでアクセスする際に警告が出てくるのは鬱陶しいので、ちゃんとした CA から証明書を貰おうと思います。
また証明書発行のチャレンジ方法は DNS-01 challenge で行います。
自宅サーバーで使用するドメインは Claudflare で管理しているため、そちらの DNS を使って証明書を発行することになるのですが、Split DNS でお話した際に、独自ドメインは使いたいが、外部にサーバーを公開したくないという要望がありました。
もしこの要件でサーバーを構築した場合、Let’s Encrypt 側から自宅サーバーにアクセスする経路がないため、HTTP-01 challenge を選択することができません。
一方、DNS-01 challenge で行う場合、チャレンジ時に Let’s Encrypt から与えらるトークンを TXT レコードで DNS に追加する形でドメインの所有権を証明することになります。
この方法であればプライベートなサーバーであっても証明書を発行できるため、今回はこちらで行います。
また Traefik には Lego という ACME が採用されているため、こちらを用いて証明書の自動発行まで設定していきます。
試しに試しまくった結論としては、以下の設定で想定通り動くようになりました。
certificatesResolvers:
cloudflare-resolver:
acme:
email: "{{ .Values.cloudflare.email }}"
storage: /data/acme.json
caServer: https://acme-v02.api.letsencrypt.org/directory
dnsChallenge:
provider: cloudflare
delayBeforeCheck: 10
deployment:
initContainers:
- name: volume-permissions
image: busybox:latest
command:
- sh
- -c
- |
mkdir -p /data
touch /data/acme.json
chown 65532:65532 /data/acme.json
chmod 600 /data/acme.json
chown 65532:65532 /data
chmod 755 /data
volumeMounts:
- name: cloudflare-resolver
mountPath: /data
securityContext:
runAsUser: 0
runAsNonRoot: false
persistence:
enabled: true
name: cloudflare-resolver
storageClass: traefik
path: /data
env:
- name: CF_DNS_API_TOKEN
value: "{{ .Values.cloudflare.dnsApiToken }}"
- name: CF_ZONE_API_TOKEN
value: "{{ .Values.cloudflare.zoneApiToken }}"
また Ingress の annotation も少し変更が必要です。
ホスト名も合わせて以下のように変更すると、取得した証明書を使って HTTPS で通信できるようになります。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
traefik.ingress.kubernetes.io/router.tls: "true"
traefik.ingress.kubernetes.io/router.entrypoints: websecure
traefik.ingress.kubernetes.io/router.tls.certresolver: cloudflare-resolver
name: app-ing
namespace: default
spec:
rules:
- host: app.home.ichi-h.com
http:
paths:
- backend:
service:
name: app-svc
port:
name: http
path: /
pathType: Prefix
tls:
- hosts:
- app.home.ichi-h.com
Traefik を Node Port で公開しているため、このままの設定でアクセスする場合 https://app.home.ichi-h.com:31443 というオリジンを使うことになると思います。
ただ、今回の自宅サーバーでは、このポートに向けてリバースプロキシを行う Nginx をホストで立ち上げているため、実際には https://app.home.ichi-h.com でアクセスすることが可能です。
Logs & Metrics Monitoring
Grafana – Node Exporter Full
今回自宅サーバーを構築するうえでの 1 つのモチベーションが、Kubernetes におけるログ基盤のデファクトスタンダードを調査・実践することでした。
そのため、自宅サーバー構築前からモックアップを作成し検証していたのですが、結論としては以下の構成がおそらく現代における一般的なログ基盤なのではないかなと思います。
- Grafana: ログやメトリクスのモニタリング・通知
- Loki: ログストレージおよびクエリエンジン
- Prometheus: メトリクスコレクタ
- Vector: ログコレクタ
Kubernetes の監視基盤については別途記事を執筆する予定なので、ここでの解説は割愛させていただきます。
Storage
クラスター内でボリュームの永続化が必要になった際、PVC にて要求された PV を供給するために Rook Ceph を用いました。
Rook is an open source cloud-native storage orchestrator, providing the platform, framework, and support for Ceph storage to natively integrate with cloud-native environments.
Ceph is a distributed storage system that provides file, block and object storage and is deployed in large scale production clusters.
引用: https://rook.io/docs/rook/latest/Getting-Started/intro/ 、10 月 7 日訪問
Rook はオープンソースのクラウドネイティブストレージオーケストレーターであり、Ceph ストレージがクラウドネイティブ環境とネイティブに統合するためのプラットフォーム、フレームワーク、サポートを提供します。
Ceph は分散ストレージシステムであり、ファイル、ブロック、オブジェクトストレージを提供し、大規模な本番クラスターに展開されます。
つまり Rook とは、Kubernetes のようなクラウド環境上で Ceph ストレージをうまく扱えるようにしつつ、そのストレージをネイティブのものと統合するためのフレームワークであり、実際に分散ストレージの供給を行っているのは Ceph である、ということですね。
簡単に仕組みを解説いたしますと、Rook Ceph では Operator と呼ばれる仕組みが提供されており、こちらによって CephCluster などの Ceph CRs(Custom Resources) の監視を行っています。
また Ceph CRs を用いることで、Ceph のデーモンがどのように稼働すべきかを宣言的に定義することができます。
この定義を Operator が稼働する Kubernetes クラスターへ反映すると、その内容に基づき Operator がクラスター内に Ceph の Pod 群を配置します。
これにより Kubernetes 上で Ceph を動かすことが可能となり、分散ストレージを提供できるようになる、ということです。
Rook Ceph が提供する Helm Chart では、Operator が rook-ceph、Ceph CRs が rook-ceph-cluster というパッケージで提供されています。
詳細な導入方法については公式のドキュメントが整っているため、基本的にはこちらの手順に従って進めるのが良いと思います。
ただ、NixOS で Rook Ceph を扱う場合、Operator を設定する際に以下を有効にする必要がありますのでご注意ください(設定内容は Values のテンプレートにあった設定例をそのまま拝借しました)。
csi:
csiCephFSPluginVolume:
- name: lib-modules
hostPath:
path: /run/booted-system/kernel-modules/lib/modules/
- name: host-nix
hostPath:
path: /nix
csiCephFSPluginVolumeMount:
- name: host-nix
mountPath: /nix
readOnly: true
csiRBDPluginVolume:
- name: lib-modules
hostPath:
path: /run/booted-system/kernel-modules/lib/modules/
- name: host-nix
hostPath:
path: /nix
csiRBDPluginVolumeMount:
- name: host-nix
mountPath: /nix
readOnly: true
他の技術記事でも言及している方がいらっしゃいましたが、Rook Ceph を安定して動作させるためにはだいぶ手間がかかります。
少なくとも「ドキュメントの通りに進めておわり!」とはいかないと思うので、もし手軽さを求めるのであれば NFS を使ってストレージを供給するのが一番楽だと思います。
一方、NixOS + Kubernetes で環境構築したメリットとして、今回作成した環境をそのままコピーすれば、他のマシンでも再現できる可能性が高いとも考えています。
全く同じ設定にはならないと思いますが、少なくとも 0 から構築するよりは間違いなく早く進められるはずなので、試してみる価値はあると思います。
Backup System
自宅サーバーを運用しているご家庭に雷が落ち、データがすべて消滅する確率は 100% という統計が報告されているため、バックアップ環境を構築することは喫緊の課題と言えます。
今回はクラスターのバックアップツールとして Velero を採用しています。
また、バックアップしたデータを HDD 等で管理したくなかったため、データはすべて AWS S3 へ保存しています(ここだけはクラウドを頼らざるを得ません……)。
Velero は動かすまでかなり苦戦したため、使用した Helm Value を記載しておきます。
snapshotsEnabled: false
deployNodeAgent: true
configuration:
namespace: velero
defaultVolumesToFsBackup: true
backupStorageLocation:
- name: default
provider: aws
bucket: { { .Values.s3.bucket } }
config:
region: { { .Values.s3.region } }
credentials:
useSecret: true
name: cloud-credentials
secretContents:
cloud: |
[default]
aws_access_key_id={{ .Values.s3.accessKeyId }}
aws_secret_access_key={{ .Values.s3.secretAccessKey }}
initContainers:
- name: velero-plugin-for-aws
image: velero/velero-plugin-for-aws:v1.12.2
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /target
name: plugins
dnsPolicy: "None"
dnsConfig:
nameservers:
- 8.8.8.8
- 8.8.4.4
searches:
- velero.svc.cluster.local
- svc.cluster.local
- cluster.local
options:
- name: ndots
value: "5"
nodeAgent:
dnsPolicy: "None"
dnsConfig:
nameservers:
- 8.8.8.8
- 8.8.4.4
searches:
- velero.svc.cluster.local
- svc.cluster.local
- cluster.local
options:
- name: ndots
value: "5"
schedules:
app-backup:
disabled: false
schedule: "0 3 * * 4"
useOwnerReferencesInBackup: false
template:
ttl: 168h
includedNamespaces:
- default
storageLocation: default
また IAM の権限は以下のとおりです。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:DeleteObject",
"s3:PutObject",
"s3:AbortMultipartUpload",
"s3:ListMultipartUploadParts"
],
"Resource": ["arn:aws:s3:::your-bucket-name/*"]
},
{
"Effect": "Allow",
"Action": ["s3:ListBucket", "s3:GetBucketLocation"],
"Resource": ["arn:aws:s3:::your-bucket-name"]
}
]
}
今回デプロイしているアプリケーションの中には機密情報を含むものがあるため、バックアップを作成する際に暗号化が必要になります。
S3 上でも基本的に暗号化が行われていますが、万が一コンソール上で S3 の中身をダウンロードされたり、億が一データとその復号鍵が同時に流出すると詰んでしまうため、サーバー側だけでなく、念には念を入れてクライアント側でも暗号化を行うほうがベターだと思います。
最近のバージョンの Velero では、Kopia というデータ圧縮や暗号化等ができるバックアップツールがデフォルトで使用されます。
Kopia ではエンベロープ暗号化が採用されており、データを暗合化するデータキーと、そのデータキーを暗号化するマスターキーの 2 つが用いて行われます。
Helm で Velero をインストールした場合、これらの設定がなされた状態で使用できるため、そのままバックアップを取れば一応暗号化された状態で保存することができます。
ただ、この方法でインストールした場合、マスターキーとして利用されるパスワードが固定の初期値になっているようなので、変更することを強く推奨します。
変更方法は Base64 でエンコードしたパスワードを以下の Secret Manifest に記入してデプロイするだけで OK です。
apiVersion: v1
data:
repository-password: -strong-password-encoded-in-base64>
kind: Secret
metadata:
name: velero-repo-credentials
namespace: velero
type: Opaque
もちろんこのパスワードも機密情報になりますので、例えば helm-secrets 等を使うことで工夫しましょう。
デプロイしたアプリケーション
Nextcloud
Nextcloud はオープンソースのオンラインストレージサービスです。
端的に言ってしまえば、Dropbox や OneDrive などの OSS 版という理解でほぼあっています。
使っている感想としては、若干動作がもっさりする時があるのが少しネックですが、それ以外に関してはごく普通のストレージサービスなので、特に問題なく使用できています。
私はゼロから Manifest を組んでデプロイしてしまったのですが、実は公式から Helm Chart が出ており、これからデプロイする場合はこちらから立ち上げるのが手っ取り早いと思います。
Nextcloud は権限の設計に少しクセがあるため、Kubernetes にデプロイしようとするとうまくいかないケースがあります。
結論としては、data ディレクトリのアクセス権限と Pod の実行ユーザーに気をつければなんとかなるでの、少し解説いたします。
Nextcloud ではデータを保存するディレクトリとして /var/www/html/data が割かれているのですが、このディレクトリは権限が 770 でないとアプリケーション上で権限エラーが発生し、事実上使用できなくなります。
このディレクトリを Rook Ceph から提供される PV を使ってマウントした際、アクセス権限が狂ってしまったことがあるので、権限エラーが発生した際はまずはこちらを疑ってみましょう。
また上記の /var/www/html/data の所有者は www-data というユーザーになっているため、 Pod の実行ユーザーがこちらになるよう securityContext を以下のようにいじります。
securityContext:
runAsUser: 33
runAsGroup: 33
fsGroup: 33
こちらで権限周りのエラーは撲滅できるようになりましたので、もし権限エラーが発生した場合は上の 2 箇所を確認してみると良いかもしれません。
Vaultwarden
Vaultwarden はオープンソースのパスワードマネージャーになります。
Bitwarden というプロダクトがあるのですが、こちらのソースコードがオープンソースで公開されており、これを Rust で再実装したものが Vaultwarden になります。
そのため Vaultwarden は Bitwaden の API と互換性があり、Bitwaden が提供するデスクトップ/モバイル向けのアプリケーションから Vaultwarden のサーバーに接続することができます。
もともと私自身 Bitwarden ユーザーでして、フリープランでも使用できる範囲が広くそこまで困ってはいなかったのですが、フリープランでは添付ファイルを扱うことができず、特に最近になって機密情報を持つファイルを扱う機会が増えたため、フリープランで運用することができなくなってしまいました。
なので今回の自宅サーバー構築で Vaultwarden をデプロイし、ファイル管理まで行える環境を作ってしまおうというのが導入の経緯になります。
本当にこれは大丈夫なのかと心配になるくらい Bitwarden と全く違いがないので、使用感は非常に良好です。
開発・運用してみての所感
今回の自宅サーバーで行った主な取り組みは以上になります。
ここからは実際にサーバーを構築し、運用してみての所感をいくつかお話できればと思います。
サーバースペック・構成ついて
良かったところ
まず Mini PC についてですが、こちらは想像の十二分に動いてくれています。
動作面は非常に軽快で、RAM も 16GB 中 20% 弱ほどしか使っていない状態なので、まだまだパワーに余裕がありそうです。
正直 Mini PC の性能を舐めていたのですが、GUI を立ち上げて簡単な操作をしたり、VSCode からリモートエクスプローラーでファイルを編集してもサクサク動くので、世の中が注目していた理由がよくわかりました。
悪かったところ
一方 Raspberry Pi についてですが、こちらはだいぶ難がありまして……。
色々と試行錯誤してきましたが、基本的に Raspberry Pi で Kubernetes 運用はおすすめできません。
少なくとも、今回構築した自宅サーバーではスペックが全く足りていないので、どこかの機能を落とすか、そもそも Raspberry Pi をクラスターから外すかしたほうが良さそうです。
まず RAM の観点からお話しますと、私の環境ではメモリが常に 75〜90% ほど使用されています。top コマンドからプロセスごとのメモリ使用量を確認したところ、kube-apiserver で約 15%、ceph-mgr も同様に 15% ほど使用しており、この 2 つだけでメモリの 3 割弱を消費している状態です。
Ceph が想像よりもかなりメモリを食っていたため、この分が通常の Control Plane よりも動作負荷につながっているのかなと予想しています。
次に CPU とディスク I/O です。
Grafana で表示できるダッシュボードのテンプレートに Node Exporter Full というものがあり、その中に Sys Load という指標があります。
CPU 使用率に近い指標なのですが、正確には、一定期間内に CPU が処理しきれなかったタスクをどれだけ抱えているかを示す負荷率 として用いられます。
こちらと CPU 使用率を観測していると、高負荷時に CPU 使用率が 90% ほど、Sys Load が 約 350% というとんでもない数値を観測することがあります。
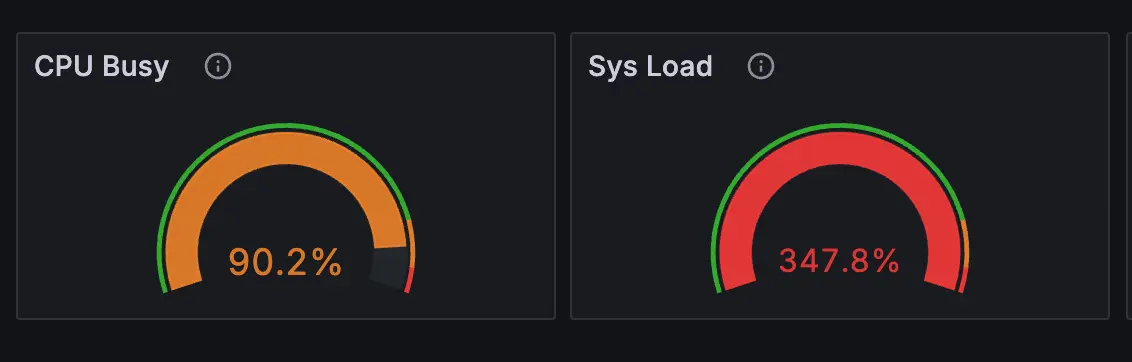
この 2 つが示唆することは、CPU 使用率は高いもののかろうじて余力を残しているが、タスクは全く消化できていないということです。
なぜ CPU を限界まで使い切っていないのにこんなことが起こるのかというと、ほとんどの場合、ディスクやネットワークの I/O で遅延が発生し、プロセスを完了できない状況になっているからです。
試しに高負荷時に vmstat 1 を監視すると、以下のようなログを確認できます。
procs -----------memory---------- ---swap-- -----io---- -system-- -------cpu-------
r b swpd free buff cache si so bi bo in cs us sy id wa st gu
1 2 0 199028 9832 363856 0 0 28476 280 9918 14172 13 15 31 41 0 0
1 4 0 955468 10396 391640 0 0 27524 228 9371 13623 12 29 26 33 0 0
0 8 0 921836 13216 413752 0 0 24280 100 11941 18190 19 26 28 26 0 0
2 1 0 888412 14464 438156 0 0 24660 356 10484 15156 21 21 29 29 0 0
1 9 0 882376 15404 449824 0 0 12488 236 7490 11147 15 26 47 13 0 0
0 12 0 873360 15640 475188 0 0 25044 1152 10304 15452 5 11 1 83 0 0
0 8 0 848916 16020 502596 0 0 27572 196 10693 15462 12 20 1 68 0 0
10 0 0 826488 16972 524028 0 0 22144 280 12741 18488 23 17 13 48 0 0
注目すべきは wa の値です。
これは vmstat 実行時に指定した時間のうち、どのくらい CPU が I/O の完了待ちで処理を止めているかの割合を表す指標です。
上記の 8 秒間のログから wa の値を平均を出すと約 43% になりますので、この 8 秒の間、3.5 秒くらいは I/O 待ちで仕事が止まっているということです。
なぜこんな状況になるのかというと、結論は SD カード です。
ものにも依りますが、基本的に SD カードの書き込みのスピードは約 10 〜 100 MB/s ほどになります。
一方昨今だと M.2 SSD が主流になっていますが、こちらの書き込みはおおよそ 2000 ~ 7000 MB/s 以上 のスピードになることがあります。
なので単純計算でディスク I/O の性能に最大 700 倍ほどの開きがあるわけでして、この分が Sys Load のあり得ない数値の原因となっているわけです。
スペック以外の点として、CPU アーキテクチャが arm64 のため追加の対応が必要になったり、Wake-on-Lan で起動できなかったりと、様々な面で辛いなと思うことがやはり多いです。
彼には彼の得意分野があると思いますので、そうしたところで活躍させてあげるのが良いんじゃないかなと思います。
※ 私の環境だけがおかしい説も考えられるので、もし同様のスペックの Raspberry Pi で快適に Kubernetes を運用している方がいらっしゃいましたらぜひコメントいただけますと幸いです。
NixOS について
良かったところ
何と言ってもOS の再現性と、設定の再利用性の高さです。
特に 2 つの Mini PC の環境構築を行った際に、文字通り数コマンドで同じ環境を立ち上げられたのはさすがに引きました……笑
全く同じハードを使っているというのもありますが、理論をここまで正確に体現できるものなのかと、ある種の感動がありました。
また、意外にも生成 AI からの回答が思ったより正確です。
もちろん嘘をつく頻度は他の言語に比べれば多い印象ですが、ネット検索を使うようプロンプトで指示を出せばそこそこ使える印象です。
NixOS もこうした面で導入のハードルが下がっていると思いますので、ちょっと背伸びするくらいの技術選定を行って良いかもしれません。
悪かったところ(?) – nixpkgs について
これは問題というより私の NixOS 力不足によるところが大きいのですが、今回の開発で NixOS 関連のトラブルに幾度となく遭遇したのですが、その中で、nixpkgs の半ブラックボックス化という問題を感じました。
NixOS でトラブルに遭った際、情報がどこにもないというのは最初からわかっていたことだったので、そこ自体は大きな問題にはなりませんでした。
ただ、何らかのトラブルが発生したときに、そのトラブルは Nix 式上のどの設定項目に依存していているのかが表面からわからないことが多く、また解決方法を試そうとしても、その設定をどこに記述すればよいのか、はたまた自前の設定を Nix 式で表現すればよいのかがわからないという問題に多く遭遇しました。
Nix/NixOS のコンセプトの 1 つに宣言的というものがあります。
これはつまりあるべき状態を記述せよということになりますが、逆を言うと、その状態を実現するための詳細や具体的な手続きは隠蔽されるということです。
その詳細のレベルに起因する問題が発生すると、該当箇所を nixpkgs から実装を探してコードリーディングするという、力技のトラブルシューティングを多くやる必要がありました。
一見 NixOS から完成されたパッケージが提供され、そこを組み合わせるだけで OS を構築できるかと思いきや、その中身で何が起きているかはわからないという点において、実は意外にも、NixOS は Ubuntu のような完成された状態で提供されるディストリビューションと近い問題を抱えているんじゃないかなと思いました。
一方、私が一番長く使っているディストリビューションは Arch Linux なのですが、あちらはまっさらな状態から手続きの積み重ねによって環境を構築するという NixOS とは対極のアプローチを採用するディストリビューションです。
Arch Linux は Nix 式のような形でシステムの全体像を把握する手段が基本的にはないので、そういった概要を把握することは苦手ですが、逆に必ず 1 回は手続きを踏む必要があり、かつそうした手続きをドキュメントとして残す風習があるため、詳細な操作には強い印象があります。
ともかく、上記 2 つは本来良し悪しの問題ではなく、単なるトレードオフの関係なので、どこに価値を置くかによって評価が変わる事柄です。
ただ今回初めて NixOS を使ったということもあり、NixOS 流のトラブルシューティングにまだ慣れておらず、またそこのハードルが高く感じられた点から、こちらを一応のデメリットとして評価させていただければと思います。
1 つ留意すべき点として、今回私は NixOS のパッケージを半ばプリセットのように使用しているという背景があります。
これがもし Nix 式をゴリゴリ書いて環境を作れたならば、ほぼフルスクラッチのような感覚でシステムを構築できるはずなので、逆に Arch Linux と近いような印象を持っていたかもしれません。
このように考えると、再現性の高いパッケージを再利用して恩恵を得ようとするライトユーザーと、システムのすべてを宣言的に構築しようとするヘビーユーザーとの間で、NixOS の捉え方が変わる可能性があるのかもしれません。
悪かったところ – arm64 について
基本的に NixOS では inputs.nixpkgs.lib.nixosSystem の引数として system を指定すれば、その CPU アーキテクチャに合わせて OS をビルドしてくれるのですが、一部 x86_64 にのみ対応する設定が存在しているため、その部分を arm64 向けに修正する必要がありました。
今回は Control Plane で DNS を立ち上げる際に、参照するイメージの URL が x86_64 のものになっているため、そのリンクの修正と、etcd に渡す環境変数を追加する必要がありました。
{
services.kubernetes.addons.dns = {
enable = true;
coredns = {
finalImageTag = "1.10.1";
imageDigest = "sha256:a0ead06651cf580044aeb0a0feba63591858fb2e43ade8c9dea45a6a89ae7e5e";
imageName = "coredns/coredns";
sha256 = "0c4vdbklgjrzi6qc5020dvi8x3mayq4li09rrq2w0hcjdljj0yf9";
};
};
systemd.services.etcd = {
environment = {
ETCD_UNSUPPORTED_ARCH = "arm64";
};
};
}
ハードウェアの差異なので難しいところではあると思うのですが、プロパティで CPU アーキテクチャを指定しているので、うまく解決してほしかったな……という気持ちはほんの少しあります。
Kubernetes について
良かったところ
Kubernetes もクラスターの設定を宣言的に管理するという特性から、環境の再現性はメリットの 1 つだなと感じます。
極端な話、クラスターを 1 回全部爆破してしまっても、コマンドを叩けば同じ状態をほぼ復元できるのは安心感があります(開発時にこの機能に何回か助けられました)。
また、Reconciliation Loopのコンセプトはやはり強力だなと感じます。
Reconciliation Loop とは、端的に言えば、Desired State(望ましい状態)と Current State(現在の状態)に差異がある場合、その差分を継続的に解消するというコンセプトです。
例えば私の環境では常時サーバーを起動する必要がないので、寝ている間は電源を落とし、起きたときにサーバーを起動するのですが、この際クラスターが安定して動作するようになるまで少し時間がかかります。特定のノードがまだ起動中になっていたり、プロセスがまだ Active にならなかったりするからですね。
普通ならノード間の通信時にエラーが起きて稼働が止まりそうなものですが、Kubernetes は放っておいても望ましい状態になるよういい感じに処理を続けてくれるので、そこの手間を考えなくて良いのは非常に楽だなと思いました。
悪かったところ
Kubernetes の開発陣には申し訳ないのですが、公式ドキュメントの中に使い物にならないページがあるのは本当にしんどいです……。
例えば StorageClass について調べていたのですが、そのドキュメントの冒頭に書かれているのは以下の文章です。
StorageClass は、管理者が提供するストレージの「クラス」を記述する方法を提供します。
引用: https://kubernetes.io/ja/docs/concepts/storage/storage-classes/ 、10 月 8 日訪問
いくつかの修飾表現がついていますが、文章の骨格をあぶり出すと実は 「StorageClass とはストレージのクラスです」 というトートロジーが現れます。
またこの先を読み進めていっても書かれているのは技術の詳細のことばかりで、この機能が本質的に何を解決しているのかを読み取ることができませんでした。
技術仕様書としての価値はあるのかもしれませんが、少なくともこれではドキュメントとしてもう一方の機能を果たせていません。
StorageClass に限らず、こういった文章が Kubernetes のドキュメントには大量に存在するのです……(もちろん中には参考になったページもあります)。
ちなみに StorageClass とは、提供する PV の仕様を定義する機能です。
つまり、PVC に対して具体的にどういった PV を Pod に提供するかわからない状況のときに、少なくとも StorageClass で規定した仕様に沿ったストレージを提供することを約束するために作られた機能である ということです。
これが本質です。
技術とは何らかの問題を解決するために存在します。例外はありません。技術には必ず本質、つまり解決できる問題が関係しています。
それなのになぜその問題について明確に語らず、技術を技術の言葉のみで語ろうとするのかが私にはわからないのです。
上記のような解釈を過剰に読み手へ強いる時点で、そのドキュメントはリーダブルではないのです。
Kubernetes の学習コストの高さはその複雑さにもあると思いますが、一番の問題は Kubernetes のコンセプトやその複雑さを本質的に説明できるドキュメントが決定的に足りていないからなのではないかなと感じています。
NixOS + Kubernetes をおすすめできるか
できません(即答)
ただし、ロマンを追い求める『同志』には大変おすすめできます。
まず最大のネックは、アーキテクチャのトリッキーさと、インフラの自由度と開発コストのトレードオフが挙げられると思います。
NixOS の Kubernetes パッケージを紹介した際に、services.kubernetes.roles を設定すると kube-apiserver 等のサービスが自動的に『ホスト』で立ち上がるとお話したと思います。
この設計自体に良し悪しはないので、これが NixOS 流の構築方法なんだなと捉えていますが、こうした構成はおそらく現代において少数だと思うので、何らかの問題が発生したときに情報がネット上になかったり、kubeadm のトラブルシューティングをそのまま活用できないといったトレードオフがあると考えています。
また services.kubernetes.roles を使用した場合、CNI が基本的に Flannel で固定されてしまうのも不自由を感じます。services.kubernetes.flannel.enable = false; を設定すれば Flannel を無効にできると思いますが、後述する nixos-kubernetes-node-join というスクリプトが Flannel に依存しているため、そこの問題を解決する必要がありそうです(自前でスクリプトを組んでしまえば一応解決できそうではあります)。
同様に easyCerts の自動有効化も不自由なポイントになります。
本番環境での利用が非推奨の機能が services.kubernetes.roles を使うだけで有効になるのは、うーん……という感想を持ってしまいます。
また、NixOS 以外のディストリビューションで立ち上げたノードをクラスターに参加させにくい(というよりできない) という問題もあります。
NixOS で構築したクラスターにノードを追加する際に nixos-kubernetes-node-join というコマンドを実行するのですが、こちらは以下のように実装されています。
set -e
exec 1>&2
if [ $# -gt 0 ]; then
echo "Usage: $(basename $0)"
echo ""
echo "No args. Apitoken must be provided on stdin."
echo "To get the apitoken, execute: 'sudo cat /var/lib/kubernetes/secrets/apitoken.secret' on the master node."
exit 1
fi
if [ $(id -u) != 0 ]; then
echo "Run as root please."
exit 1
fi
read -r token
if [ ${#token} != 32 ]; then
echo "Token must be of length 32."
exit 1
fi
install -m 0600 (echo $token) /var/lib/kubernetes/secrets/apitoken.secret
echo "Restarting certmgr..." >&1
systemctl restart certmgr
echo "Waiting for certs to appear..." >&1
while [ ! -f /var/lib/kubernetes/secrets/kubelet.pem ]; do sleep 1; done
echo "Restarting kubelet..." >&1
systemctl restart kubelet
while [ ! -f /var/lib/kubernetes/secrets/kube-proxy-client.pem ]; do sleep 1; done
echo "Restarting kube-proxy..." >&1
systemctl restart kube-proxy
while [ ! -f /var/lib/kubernetes/secrets/flannel-client.pem ]; do sleep 1; done
echo "Restarting flannel..." >&1
systemctl restart flannel
echo "Node joined successfully"
ここを見ると、certmgr、kubelet、kube-proxy、flannel あたりのサービスに依存していることがわかるので、このあたりをホストで立ち上げることができれば、どのディストリビューションであっても技術的にはクラスターに追加できると思います。
ただ、こうしたサービスを手動で立ち上げたいですか? またそこまでしてそのノードを追加しないといけませんか? というお話になるので、あまり現実的な方法ではないと感じます。
(ちなみに、NixOS には nixos-anywhere という、どうしても色々なところで NixOS を使いたくてしょうがない人たちが作った最高の OSS があるので、こちらで NixOS の環境を作ってしまうことで一応解決できます)
ここまでお話して薄々気づいているかもしれませんが、多くの問題は services.kubernetes.roles を使った環境構築に起因しています。
なので services.kubernetes.roles を使わず自前で環境を構築できれば、より自由で堅牢なクラスターを作ることができるといえます。
しかし一方で、これは kubeadm ほどメジャーな技術選定ではなく、ほとんど情報がない中手探りで環境構築を進めていくことが予想されるため、ただでさえ重い実装コストがさらに重くなるというトレードオフが考えられます。
まとめると、services.kubernetes.roles を使うにしても使わないにしても、それぞれに割と無視できないレベルの辛みがあり、また Kubernetes に重点を置くならば、そもそも NixOS を使わずとも kubeadm のようなよりベターな解決方法が考えられるため、基本的に NixOS + Kubernetes による環境構築はおすすめすることができません。
ただ一方で、この技術スタックは個人的にはかなり楽しいものでもあると思っています。
意味不明なエラーはバンバン出るわ、調べても答えは出てこないわ、AI に聞いても変な回答ばっか返ってくるわ……
毎回てんやわんやではあるのですが、おそらくこんなことをやっている人は世界に 1000 人もいないと思うので、こういったロマン全振りでバカなことに全力を注げるタイプの人であれば問答無用で GO です。今すぐやりましょう。
皆さまの実行報告を心待ちにしております。
おまけ: 今後改善したいこと
電源管理
今一番の問題は電源管理のめんどくささですね……。
私の自宅サーバーは常時動かす必要がないため、寝ている間は電気代節約のためサーバーの電源を落としておきたいのですが、電源をダウンする方法が現状サーバーに SSH してコマンドを叩くしかないので、ここは要改善です。
現在サーバーの電源を一括管理するアプリケーションの要求・要件を練っています。もしいけそうであれば OSS で公開する予定です。
services.kubernetes.roles の脱却
上記のとおりです。ロマンを追求したい。
開発サーバーの NixOS 化
本当は元々使っていた Arch Linux の開発サーバーや、Windows 上で動いている WSL のディストリビューションを NixOS に移行できるのが一番の理想です。
もしこちらが実行できれば、これらのサーバーも Kubernetes クラスターに参加できるようになり、DaemonSet で配置される Prometheus Node Exporter からサーバーのメトリクスを取れるようになるので、時間があるときに移行したいところです。
CI/CD の構築
現在 Kubernetes のデプロイはすべて手動で行っており、CI/CD の環境はありません。
クラスターを立ち上げから利用まで乗せることができたものの、また安定した状態にはなっておらず、適当にデプロイをするとどこかがコケるケースがそれなりにあります。
ArgoCD 等を導入したとしても、手動で環境をいじって調節するケースもあるみたいなので、それが普通なのかもしれませんが、まだ高頻度にデプロイを行うわけではないので、自動化したいほど困っているわけではないというのが大きいです。
ただ、自宅サーバーはロマンを追い求めてなんぼの世界だと思うので、そのためだけに導入を検討しております。
また Kubernetes に限らず、実は NixOS にも CD を提供するツールが存在します。
例えば comin は GitOps 型、deploy-rs は CIOps 型の CD ツールです。
このあたりを絡めつつ、NixOS と Kubernetes のデプロイフローを分離して面倒を見れたらなぁ……と画策しています。
他アプリケーションのデプロイ
現状使っているのは Nextcloud と Vaultwarden と Grafana しかありませんが、他にもいくつか導入したいアプリケーションがあります。
特に Miniflux はどこかで間違いなくデプロイすると思います。
他にもバンバンデプロイをして、賑やかなクラスターを運用できればと思います。
Views: 51

{kind=link}