
こんにちは、株式会社カナリーでソフトウェアエンジニアをやっている matsu です。
本記事では、Next.js App Router で TanStack Query を使う場合の Server-side Rendering (SSR) について、処理の流れや仕組みを解説します。
TanStack Query の公式ドキュメント
の補足的な記事と捉えていただければと思います。
用語の定義
文脈によって意味がブレやすい用語がいくつか出てくるため、先に定義を明確にしておきます。
QueryClient
TanStack Query の QueryClient です。キャッシュ管理にて中心的な役割を担います。
dehydrate/hydrate
TanStack Query には、キャッシュを server-side から client-side に受け渡す際に使用する dehydrate 関数 と hydrate 関数 が用意されています (後ほど詳しく説明します)。
これらの関数の機能に従い、本記事では一貫して、
-
dehydrate: server-side にて、
QueryClientからキャッシュを取り出してシリアライズ可能なオブジェクトに変換すること -
hydrate: client-side にて、dehydrate されたキャッシュを
QueryClientに格納すること
という意味で使用します。
ストリーミング
本記事では一貫して Next.js App Router の Streaming を指して使用します。
SSR を実現するための手段
TanStack Query では現状、Next.js で SSR するための手段が2通り用意されています。
prefetchQuery & HydrationBoundary を使った標準的な方法と、@tanstack/react-query-next-experimental を使った実験的な方法です (前者は Next.js 専用というわけではないです)。
いずれの方法を使った場合も、実現方法は違えど、大まかなデータフローは同様です。
キャッシュを管理する QueryClient は、server-side と client-side それぞれで生成されます。server-side の QueryClient は毎回新規に生成される一時的なもので、キャッシュは最終的に client-side の QueryClient でのみ保持されます。
こうしたクライアント中心のキャッシュ管理戦略は、Next.js 標準の fetch とは大きく異なる点ですね。
それでは、以降でそれぞれの使い方や仕組みを深掘りしていきます。
prefetchQuery & HydrationBoundary
使い方
最も基本的な使い方は以下の通りです。await で prefetchQuery の完了を待機し、完了後にコンポーネントを返却します。
app/page.tsx
import { dehydrate, HydrationBoundary } from "@tanstack/react-query";
import { fetchFirstPokemonOptions } from "../../fetch-mock";
import { FirstPokemon } from "../../first-pokemon";
import { getQueryClient } from "../../get-query-client";
export default async function Page() {
const queryClient = getQueryClient();
await queryClient.prefetchQuery(fetchFirstPokemonOptions);
const dehydratedState = dehydrate(queryClient);
return (
HydrationBoundary state={dehydratedState}>
FirstPokemon />
HydrationBoundary>
);
}
first-pokemon.tsx
"use client";
import { useSuspenseQuery } from "@tanstack/react-query";
import { fetchFirstPokemonOptions } from "./fetch-mock";
export const FirstPokemon = () => {
const {
data: { name },
} = useSuspenseQuery(fetchFirstPokemonOptions);
return p>{name}p>;
};
複数のデータフェッチが必要な場合は Promise.all 等を使って並列化すると良いでしょう。
app/page.tsx
import { dehydrate, HydrationBoundary } from "@tanstack/react-query";
import {
fetchFirstPokemonOptions,
fetchSecondPokemonOptions,
} from "../../fetch-mock";
import { FirstPokemon } from "../../first-pokemon";
import { getQueryClient } from "../../get-query-client";
import { SecondPokemon } from "../../second-pokemon";
export default async function Page() {
const queryClient = getQueryClient();
await Promise.all([
queryClient.prefetchQuery(fetchFirstPokemonOptions),
queryClient.prefetchQuery(fetchSecondPokemonOptions),
]);
const dehydratedState = dehydrate(queryClient);
return (
>
h1>Prefetch Awaith1>
HydrationBoundary state={dehydratedState}>
FirstPokemon />
SecondPokemon />
HydrationBoundary>
>
);
}
この時の挙動は以下のようになります (1つ目のデータフェッチが応答に1秒、2つ目が2秒かかる)。
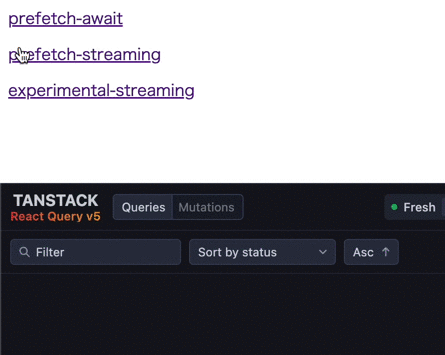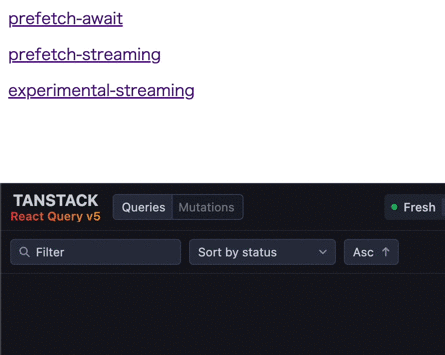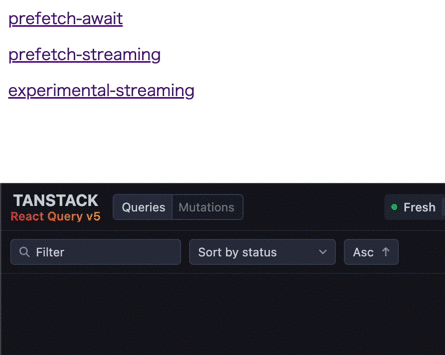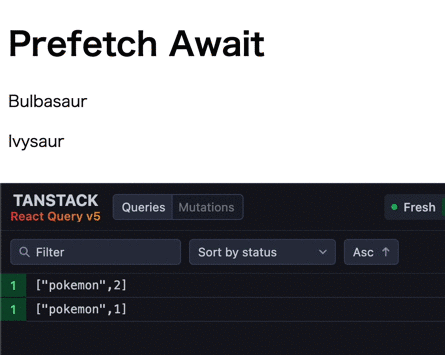
全てのデータフェッチが完了するまで、prefetchQuery を実行したコンポーネントは返却されません。
処理の流れ
この時の処理の流れは以下のようになっています。
prefetchQuery の処理
prefetchQuery は、 queryFn を実行し、結果をキャッシュとして QueryClient に保存する役割を担っています。prefetchQuery の処理を簡略化すると以下のようになります。
packages/query-core/src/queryClient.ts
export class QueryClient {
#queryCache: QueryCache;
fetchQuery(options: FetchQueryOptions) {
const defaultedOptions = this.defaultQueryOptions(options);
const query = this.#queryCache.build(this, defaultedOptions);
return query.fetch(defaultedOptions);
}
prefetchQuery(options: FetchQueryOptions) {
return this.fetchQuery(options);
}
}
参考: packages/query-core/src/queryClient.ts#L372
query.fetch は useQuery 等の中でも利用されているメソッドで、queryFn の実行とキャッシュへの格納はこの中で行われています。prefetchQuery はただの薄いラッパーですね。
なお、話が逸れますが、prefetchQuery は SSR のためだけのメソッドというわけではありません。クライアントサイドでの実行も可能で、例えば、onMouseEnter イベントのハンドラで prefetchQuery を実行する例が公式 doc の中で紹介されています Prefetch in event handlers。
dehydrate の処理
prefetchQuery によってデータがキャッシュに格納されると、続いて dehydrate 関数 によってシリアライズ可能なオブジェクトに変換されます。
dehydrate の処理を簡略化すると以下のようになります。QueryClient からキャッシュを取り出してオブジェクトに変換するだけのシンプルな処理です。
packages/query-core/src/hydration.ts
export function dehydrate(client: QueryClient): DehydratedState {
const queries = client
.getQueryCache()
.getAll()
.flatMap((query) => [dehydrateQuery(query)]);
return { queries };
}
function dehydrateQuery(query: Query): DehydratedQuery {
return {
dehydratedAt: Date.now(),
state: query.state,
queryKey: query.queryKey,
queryHash: query.queryHash,
};
}
参考: packages/query-core/src/hydration.ts#L122
dehydrate の結果は、例えば以下のようになります。
{
"mutations": [],
"queries": [
{
"dehydratedAt": 1753078463192,
"state": {
"data": {
"name": "Bulbasaur"
},
"dataUpdateCount": 1,
"dataUpdatedAt": 1753078462192,
"error": null,
"errorUpdateCount": 0,
"errorUpdatedAt": 0,
"fetchFailureCount": 0,
"fetchFailureReason": null,
"fetchMeta": null,
"isInvalidated": false,
"status": "success",
"fetchStatus": "idle"
},
"queryKey": ["pokemon", 1],
"queryHash": "[\"pokemon\",1]"
},
{
"dehydratedAt": 1753078463192,
"state": {
"data": {
"name": "Ivysaur"
},
"dataUpdateCount": 1,
"dataUpdatedAt": 1753078463191,
"error": null,
"errorUpdateCount": 0,
"errorUpdatedAt": 0,
"fetchFailureCount": 0,
"fetchFailureReason": null,
"fetchMeta": null,
"isInvalidated": false,
"status": "success",
"fetchStatus": "idle"
},
"queryKey": ["pokemon", 2],
"queryHash": "[\"pokemon\",2]"
}
]
}
こちらが HydrationBoundary の state prop に渡され、Nest.js App Router の RSC のお作法に則って HTML に埋め込まれて、client-side へ返却される流れです。
HTML に埋め込まれたキャッシュは以下のようになります (見やすいように改行を入れています)。
script>
self.__next_f.push([
1,
"29:[
[
\"$\",\"h1\",null,{\"children\":\"Prefetch Await\"},\"$2a\",\"$51\",1
],
[
\"$\",\"$L53\",null,
{
\"state\": {
\"mutations\": [],
\"queries\": [
{
\"dehydratedAt\": 1753078463192,
\"state\": {
\"data\": {\"name\": \"Bulbasaur\"},
\"dataUpdateCount\": 1,
\"dataUpdatedAt\": 1753078462192,
\"error\": null,
\"errorUpdateCount\": 0,
\"errorUpdatedAt\": 0,
\"fetchFailureCount\": 0,
\"fetchFailureReason\": null,
\"fetchMeta\": null,
\"isInvalidated\": false,
\"status\": \"success\",
\"fetchStatus\": \"idle\"
},
\"queryKey\": [\"pokemon\", 1],
\"queryHash\": \"[\\\"pokemon\\\",1]\"
},
{
\"dehydratedAt\": 1753078463192,
\"state\": {
\"data\": {\"name\": \"Ivysaur\"},
\"dataUpdateCount\": 1,
\"dataUpdatedAt\": 1753078463191,
\"error\": null,
\"errorUpdateCount\": 0,
\"errorUpdatedAt\": 0,
\"fetchFailureCount\": 0,
\"fetchFailureReason\": null,
\"fetchMeta\": null,
\"isInvalidated\": false,
\"status\": \"success\",
\"fetchStatus\": \"idle\"
},
\"queryKey\": [\"pokemon\", 2],
\"queryHash\": \"[\\\"pokemon\\\",2]\"
}
]
},
\"children\": [
[\"$\",\"$L55\",null,{},\"$2a\",\"$54\",1],
[\"$\",\"$L57\",null,{},\"$2a\",\"$56\",1]
]
},
\"$2a\",\"$52\",1
]
]"
]);
script>
HydrationBoundary の処理
HydrationBoundary は、client-side に渡されてきたキャッシュを hydrate し、QueryClient に詰める役割を担います。
HydrationBoundary の処理を簡略化すると以下のようになります。
packages/react-query/src/HydrationBoundary.tsx
export const HydrationBoundary = ({
children,
state,
}: HydrationBoundaryProps) => {
const client = useQueryClient();
React.useMemo(() => {
if (state) {
const queries = (state as DehydratedState).queries || [];
hydrate(client, { queries });
}
}, [client, state]);
return children as React.ReactElement;
};
参考: packages/react-query/src/HydrationBoundary.tsx#L25
packages/query-core/src/hydration.ts
export function hydrate(client: QueryClient, dehydratedState: unknown): void {
const queryCache = client.getQueryCache();
const queries = (dehydratedState as DehydratedState).queries || [];
queries.forEach(({ queryKey, state, queryHash }) => {
queryCache.build(
client,
{ queryKey, queryHash },
{ ...state, fetchStatus: "idle" },
);
});
}
参考: packages/query-core/src/hydration.ts#L165
なお、実際には、既存のキャッシュが存在した場合の優先度決めや表示タイミング制御なども行われており、優先度決めには dehydrate された時刻 dehydratedAt が使われていたりします。
prefetchQuery & HydrationBoundary (ストリーミングするパターン)
v5.40.0 以降では、dehydrate にて pending 状態の query も含められるようになり、ストリーミングで順次結果を返すことも可能になりました。
使い方
QueryClient 生成時に、pending 状態の query を dehydrate の結果に含めるよう明示しておく必要があります。
get-query-client.ts
const makeQueryClient = () => {
return new QueryClient({
defaultOptions: {
dehydrate: {
shouldDehydrateQuery: (query) =>
defaultShouldDehydrateQuery(query) ||
query.state.status === "pending",
},
queries: {
staleTime: 60 * 1000,
},
},
});
};
prefetchQuery は await 無しで実行し、Streaming SSR のお作法に則ってデータフェッチを実行するコンポーネントを
app/page.tsx
import { dehydrate, HydrationBoundary } from "@tanstack/react-query";
import { Suspense } from "react";
import {
fetchFirstPokemonOptions,
fetchSecondPokemonOptions,
} from "../../fetch-mock";
import { FirstPokemon } from "../../first-pokemon";
import { getQueryClient } from "../../get-query-client";
import { SecondPokemon } from "../../second-pokemon";
export default function Page() {
const queryClient = getQueryClient();
queryClient.prefetchQuery(fetchFirstPokemonOptions);
queryClient.prefetchQuery(fetchSecondPokemonOptions);
const dehydratedState = dehydrate(queryClient);
return (
>
h1>Prefetch Streamingh1>
{}
Suspense fallback={p>Loading...p>}>
HydrationBoundary state={dehydratedState}>
FirstPokemon />
HydrationBoundary>
Suspense>
Suspense fallback={p>Loading...p>}>
HydrationBoundary state={dehydratedState}>
SecondPokemon />
HydrationBoundary>
Suspense>
>
);
}
この時の挙動は以下のようになります (1つ目のデータフェッチが応答に1秒、2つ目が2秒かかる)。
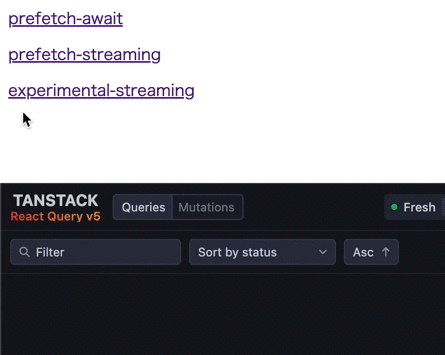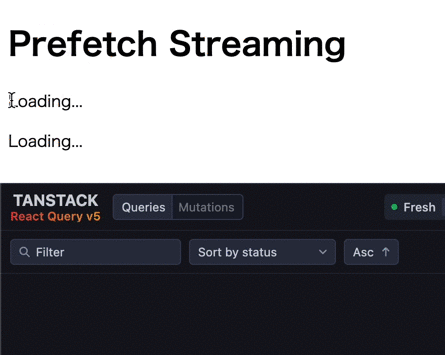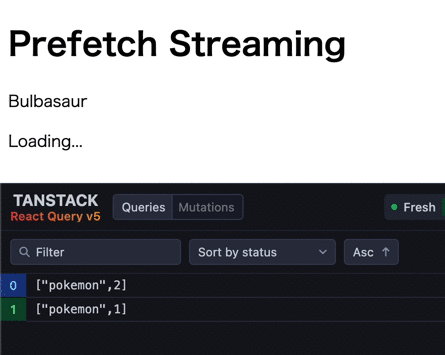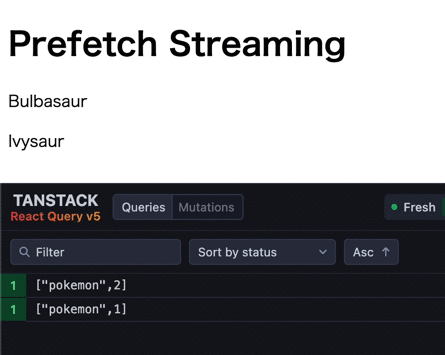
初期表示ではデータフェッチ実行中のコンポーネントがサスペンドされ、fallback が表示されます。その後、データフェッチが完了したコンポーネントから順次サスペンドが解除され、データが表示されます。
処理の流れ
この時の処理の流れは以下のようになっています。
dehydrate と hydrate における Promise の扱い
prefetchQuery で、await していないため、最初に dehydrate が実行されるタイミングでは当然データフェッチの結果は返ってきていません。この時、QueryClient には Promise がセットされており、dehydrate の結果は以下のようになります。
{
"mutations": [],
"queries": [
{
"dehydratedAt": 1753105795949,
"state": {
"dataUpdateCount": 0,
"dataUpdatedAt": 0,
"error": null,
"errorUpdateCount": 0,
"errorUpdatedAt": 0,
"fetchFailureCount": 0,
"fetchFailureReason": null,
"fetchMeta": null,
"isInvalidated": false,
"status": "pending",
"fetchStatus": "fetching"
},
"queryKey": ["pokemon", 1],
"queryHash": "[\"pokemon\",1]",
"promise": [Promise]
},
{
"dehydratedAt": 1753105795949,
"state": {
"dataUpdateCount": 0,
"dataUpdatedAt": 0,
"error": null,
"errorUpdateCount": 0,
"errorUpdatedAt": 0,
"fetchFailureCount": 0,
"fetchFailureReason": null,
"fetchMeta": null,
"isInvalidated": false,
"status": "pending",
"fetchStatus": "fetching"
},
"queryKey": ["pokemon", 2],
"queryHash": "[\"pokemon\",2]",
"promise": [Promise]
}
]
}
こちらが HTML に埋め込まれると以下のようになります (見やすいように改行を入れています)。
script>
self.__next_f.push([
1,
`29:[
[
"$", "h1", null,
{ "children": "Prefetch Streaming" },
"$2a", "$2d", 1
],
[
"$", "$2f", null,
{
"fallback": [ // `
]);
script>
これを見ると
-
fallbackにLoading...が指定されていること -
dataが$undefinedとなっていること -
statusがpending,fetchStatusがfetchingとなっていること
などが分かります。
また、キャッシュの promise フィールドが "$@33" "$@34" となっています。これは RSC のストリーミング (React Flight) で使われる参照記法で、この後 server-side で解決された Promise がここのフィールドに収まるという流れになります。
1つ目のデータフェッチが完了すると、以下の script タグがストリーミングで追加されます。
script>
self.__next_f.push([1,"33:{\"name\":\"Bulbasaur\"}\n"])
script>
キーが 33 となっていますね。これにより "$@33" の promise が実データに置き換えられ、キャッシュデータが正しいものとなります。
(同時に fallback を実際のコンポーネントに置き換えるための script も追加され、それが実行されて初めて描画が完了するのですが、長いので省略しています)
@tanstack/react-query-next-experimental
使い方
@tanstack/react-query-next-experimental のパターンでは、アプリケーション全体を ReactQueryStreamedHydration で囲む必要があります。
providers.tsx
"use client";
import { QueryClientProvider } from "@tanstack/react-query";
import { ReactQueryDevtools } from "@tanstack/react-query-devtools";
import type * as React from "react";
import { getQueryClient } from "./get-query-client";
export const Providers = ({ children }: { children: React.ReactNode }) => {
const queryClient = getQueryClient();
return (
QueryClientProvider client={queryClient}>
ReactQueryStreamedHydration>{children}ReactQueryStreamedHydration>
QueryClientProvider>
);
};
app/layout.tsx
import { Providers } from "./providers";
export default function RootLayout({
children,
}: {
children: React.ReactNode;
}) {
return (
html lang="en">
body>
Providers>{children}Providers>
body>
html>
);
}
SSR に係る記述はこれだけで、あとは各コンポーネントで useSuspenseQuery を利用すればストリーミングが行われます。
app/page.tsx
import { Suspense } from "react";
import { FirstPokemon } from "../../first-pokemon";
import { SecondPokemon } from "../../second-pokemon";
export default function Page() {
return (
>
h1>Experimental Streamingh1>
Suspense fallback={p>Loading...p>}>
FirstPokemon />
Suspense>
Suspense fallback={p>Loading...p>}>
SecondPokemon />
Suspense>
>
);
}
first-pokemon.tsx
"use client";
import { useSuspenseQuery } from "@tanstack/react-query";
import { fetchFirstPokemonOptions } from "./fetch-mock";
export const FirstPokemon = () => {
const {
data: { name },
} = useSuspenseQuery(fetchFirstPokemonOptions);
return p>{name}p>;
};
prefetchQuery & HydrationBoundary の場合は、明示的にキャッシュを dehydrate したり、HydrationBoundary を置いて hydrate したりしていましたが、そのあたりの処理が ReactQueryStreamedHydration によって自動で行われるイメージです。
この時の挙動は以下のようになります (1つ目のデータフェッチが応答に1秒、2つ目が2秒かかる)。
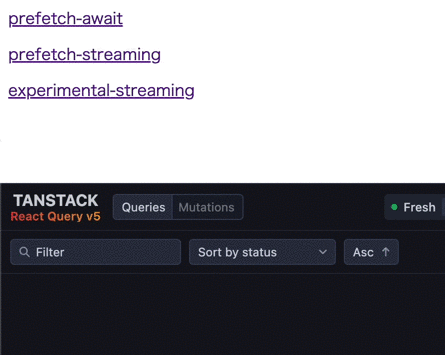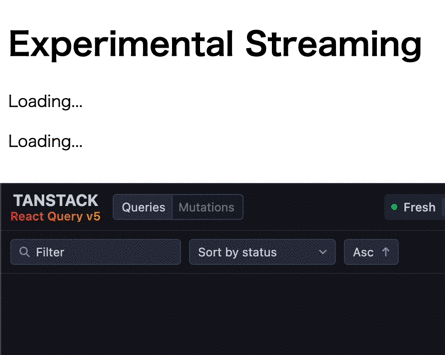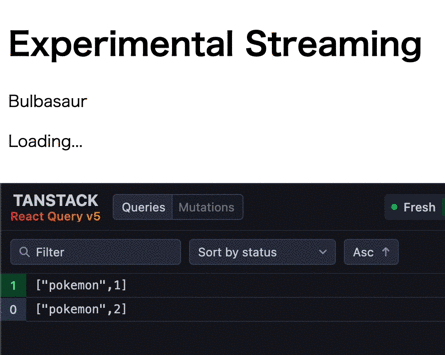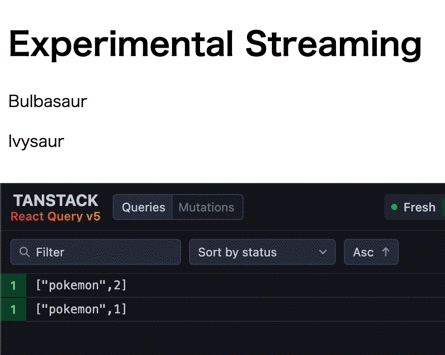
見た目は prefetchQuery & HydrationBoundary のストリーミングと全く同じですね。
(内部的には、キャッシュが作成されるタイミングが微妙に違ってたりします。理由は、両者の処理の流れを見比べていただくと何となく分かるはず。)
処理の流れ
この時の処理の流れは以下のようになっています。データの流れは prefetch & HydrationBoundary でストリーミングした場合とよく似ています。
処理の大部分は、ReactQueryStreamedHydration プロバイダー (とその子である HydrationStreamProvider) で行われます。
以降で、ReactQueryStreamedHydration と HydrationStreamProvider が何をしているのかをもう少し深掘りします。
QueryClient を subscribe してクエリの追加・更新を監視 (server-side)
ReactQueryStreamedHydration は、まず始めに QueryClient のキャッシュを subscribe し、クエリの追加・更新の監視を開始します。
追加・更新があったクエリは、クエリハッシュが配列 trackedKeys に追加されます。
packages/react-query-next-experimental/src/ReactQueryStreamedHydration.tsx
export function ReactQueryStreamedHydration(props) {
const queryClient = useQueryClient(props.queryClient)
const [trackedKeys] = React.useState(() => new Setstring>())
if (isServer) {
queryClient.getQueryCache().subscribe((event) => {
switch (event.type) {
case 'added':
case 'updated':
trackedKeys.add(event.query.queryHash)
}
})
}
}
参考: packages/react-query-next-experimental/src/ReactQueryStreamedHydration.tsx#L37
window オブジェクトに hydrate 処理を登録 (client-side)
データフェッチが開始されコンポーネントがサスペンド状態になったところで、初期の HTML がクライアントに返却されます。
このタイミングで ReactQueryStreamedHydration は、client-side で window の [id].push に hydrate 処理を登録し、ストリーミングデータの受信に備えます。
packages/react-query-next-experimental/src/HydrationStreamProvider.tsx
if (!isServer) {
const win = window as any
if (!win[id]?.initialized) {
const onEntries = (...serializedEntries) => {
const entries = serializedEntries.map((serialized) =>
transformer.deserialize(serialized),
)
for (const hydratedState of entries) {
hydrate(queryClient, hydratedState)
}
}
win[id] = {
initialized: true,
push: onEntries,
}
}
}
参考: packages/react-query-next-experimental/src/HydrationStreamProvider.tsx#L157
今後ストリーミングで届くスクリプトの中で win[id].push の実行が指示されており、それによって登録された hydrate が実行されるという仕組みです。
ちなみに、id は useId でリクエストごとに振られ、一連のリクエストでは同じ id が使われます。
子コンポーネントの useSuspenseQuery が完了した後の処理 (server-side)
子コンポーネントの useSuspenseQuery が完了すると、キャッシュの update イベントが発生し、trackedKeys にクエリハッシュが追加されます。
さらに、Suspense が解決したタイミングで、useServerInsertedHTML の callback が呼び出され、dehydrate 処理が実行されます。
packages/react-query-next-experimental/src/HydrationStreamProvider.tsx
const onFlush={() => {
const dehydratedState = dehydrate(queryClient, {
shouldDehydrateQuery(query) {
return trackedKeys.has(query.queryHash) && shouldDehydrate(query)
},
})
trackedKeys.clear()
return [dehydratedState]
}}
useServerInsertedHTML(() => {
stream.push(...(onFlush.()))
const serializedCacheArgs = stream
.map((entry) => transformer.serialize(entry))
.map((entry) => JSON.stringify(entry))
.join(',')
const html = [
`window[${idJSON}] = window[${idJSON}] || [];`,
`window[${idJSON}].push(${htmlEscapeJsonString(serializedCacheArgs)});`,
]
return (
script dangerouslySetInnerHTML={{ __html: html.join('') }}/>
)
})
参考: packages/react-query-next-experimental/src/HydrationStreamProvider.tsx#L119
useServerInsertedHTML は Next.js が提供する hook で、ストリーミングされる chunk に任意の HTML を挿入できます (CSS-in-JS ライブラリで SSR にてスタイルを注入する際などに使われるようです -> https://nextjs.org/docs/app/guides/css-in-js)。
これを利用して、子コンポーネントの Suspense が解決するたびに tracedKeys に登録されているクエリのキャッシュを dehydrate し、クライアントにストリーミングしているというわけです。
HTML に埋め込まれたキャッシュデータは、例えば以下のようになります (見やすいように改行を入れています) (1つ目のデータがストリーミングされた際のもの)。
script>
window["__RQ_R_15rdb_"] = window["__RQ_R_15rdb_"] || [];
window["__RQ_R_15rdb_"].push({
"mutations": [],
"queries": [
{
"dehydratedAt": 1753290145645,
"state": {
"data": {
"name": "Bulbasaur"
},
"dataUpdateCount": 1,
"dataUpdatedAt": 1753290145642,
"error": null,
"errorUpdateCount": 0,
"errorUpdatedAt": 0,
"fetchFailureCount": 0,
"fetchFailureReason": null,
"fetchMeta": null,
"isInvalidated": false,
"status": "success",
"fetchStatus": "idle"
},
"queryKey": ["pokemon", 1],
"queryHash": "[\"pokemon\",1]"
}
]
});
script>
window オブジェクトに登録した hydrate 処理を実行 (client-side)
初期の HTML を受け取ったタイミングで window[id].push に登録していた hydrate 処理が実行され、QueryClient にキャッシュが格納されることで、結果を表示できるようになります。
以上のように、@tanstack/react-query-next-experimental では、
QueryClientを subscribe してクエリの更新を監視することで、client-side への連携が必要なクエリキャッシュのみを dehydrate できるようにするuseServerInsertedHTMLにより、useSuspenseQueryが完了したタイミングで dehydrate がトリガーされるようにする
といった工夫によって、必要なタイミングで必要なキャッシュのみが client-side へ連携されるようになっているのです。
おわりに
本記事の内容に誤りを見つけた場合は、コメントや X にて気軽にご指摘いただけると助かります。
使い方の項で紹介したサンプルコードは下記に格納しています。必要に応じてご参照ください。
Views: 0

{kind=link}