

はじめに
昨今、ChatGPT が一般的になったことや LLM(大規模言語モデル)の進化が著しいことから、LLM でなんでも解決できると錯覚することもあるかと思います。その中で、LLM に時系列予測させたいという話を伺ったことがあります。確かに LLM は次に来る単語を予測するため、時系列予測の性質を持ち合わせています。
しかしながら、現時点では LLM の数値予測に関しては発展途中のようで、従来の統計手法や機械学習として知られる手法の方がストレートな解決策である可能性があります。大規模言語モデルは主にテキストで事前学習されていますが、数値データにはテキストとは異なる独特の周期性や傾向があるため、LLM での数値予測を困難にしている可能性が指摘されています。
例えば、以下の論文では LLM と従来から広く知られている時系列予測の ARIMA を比較していますが、結果として ARIMA の方がトレンドなどを含む時系列データに対して精度が良かったと報告しています。
An Evaluation of Standard Statistical Models and LLMs on Time Series Forecasting
また、LLM はパラメータ数が数十億規模にも及ぶ巨大モデルであり、その推論には高い計算コストと時間を要するため数値予測には十分過ぎるかもしれません。そのため、数値予測に関しては機械学習手法などを検討する余地はあると思います。
そこで、Microsoft Fabric (以降 Fabric) では Data Science の機能も兼ね備えており、機械学習の検証を素早く始められます。

なぜ Microsoft Fabric での機械学習か?
Fabric は統合データ基盤であるため、大量の蓄積されたデータに対して簡単に機械学習を適用させることが可能です。具体的な Fabric で機械学習を行うメリットは以下です。
-
シームレスなデータ統合とプロセス連携 : Fabric は組織のデータレイク(OneLake)やデータウェアハウスと密接に結びついたプラットフォームです。Fabric 上で実行することで、データの取り込みからモデル訓練・評価・デプロイまでを一貫して同じ環境内で完結できます
-
迅速な計算環境の提供 : 機械学習を実行する環境をゼロから構築することなく、必要に応じて Fabric 上のリソースを利用することで素早く計算を開始できます。
-
エンドツーエンドの ML パイプライン管理 : Fabric はモデル開発だけでなく、トレーニングのメトリクス管理やモデルの登録・デプロイ機能(MLflow 統合)も提供します。作成したモデルは Fabric 上に直接登録できます。
-
自動機械学習ライブラリの対応 : Fabric では、適切な機械学習モデルの選択などを自動で行う AutoML ライブラリの FLAML が利用可能です。これにより、モデルの詳細な知識がなくても効率的に複数モデルの検証を行うことができます。
これらのメリットの中でも、特に注目なのが AutoML ライブラリの FLAML に関してです。
FLAML とは
FLAML (Fast and Lightweight AutoML) は Microsoft Research が開発したオープンソースの自動機械学習ライブラリです。わずかなコードで高品質な機械学習モデルを自動的に生成でき、分類、回帰、時系列予測など幅広いタスクに対応しています。ユーザーは学習アルゴリズムやハイパーパラメータを 1 から選定する必要がなく、FLAML が最適なモデルとパラメータを低い計算コストで見つけ出します。Scikit-Learn ライクなインターフェイス(AutoML.fit, predict メソッド)を備えており、初学者から上級者まで扱いやすい設計です。また、必要に応じてアルゴリズムや評価指標を差し替えることも可能なため、高い拡張性とカスタマイズ性を持っています。
arXiv の論文「FLAML: A Fast and Lightweight AutoML Library」では、FLAML が大規模なオープンソース AutoML ベンチマークで、他のトップ AutoML ライブラリを同等またははるかに少ないリソースで上回る結果を示しています。
FLAML 自体は軽量ですが、大規模データに対する AutoML 処理も Fabric のスケーラブルな計算リソースで高速にこなせます。特に Fabric の Spark 統合により、AutoML の試行を分散並列化することも可能で、大量のパラメータ探索を短時間で実行できます。
容易な操作性によって UI 上で必要な項目(予測したい対象や評価指標など)を選ぶだけで高度なモデル探索を開始できます。技術者でなくとも機械学習モデル開発が可能となり、組織全体で機械学習活用の裾野を広げる効果があります。生成されたノートブックや結果も自動保存されるため、あとからデータサイエンティストが詳細を確認・引き継ぐことも容易です。
ちなみに、マルチ AI エージェントフレームワークとして注目を集めている AutoGen は、もともとはMicrosoft の FLAML プロジェクトの一部として開発されました
検証
実際に Fabric 上で FLAML を利用した AutoML を開始してみます。こちらのサンプルを参考にして、時系列予測を行います。
データのロード
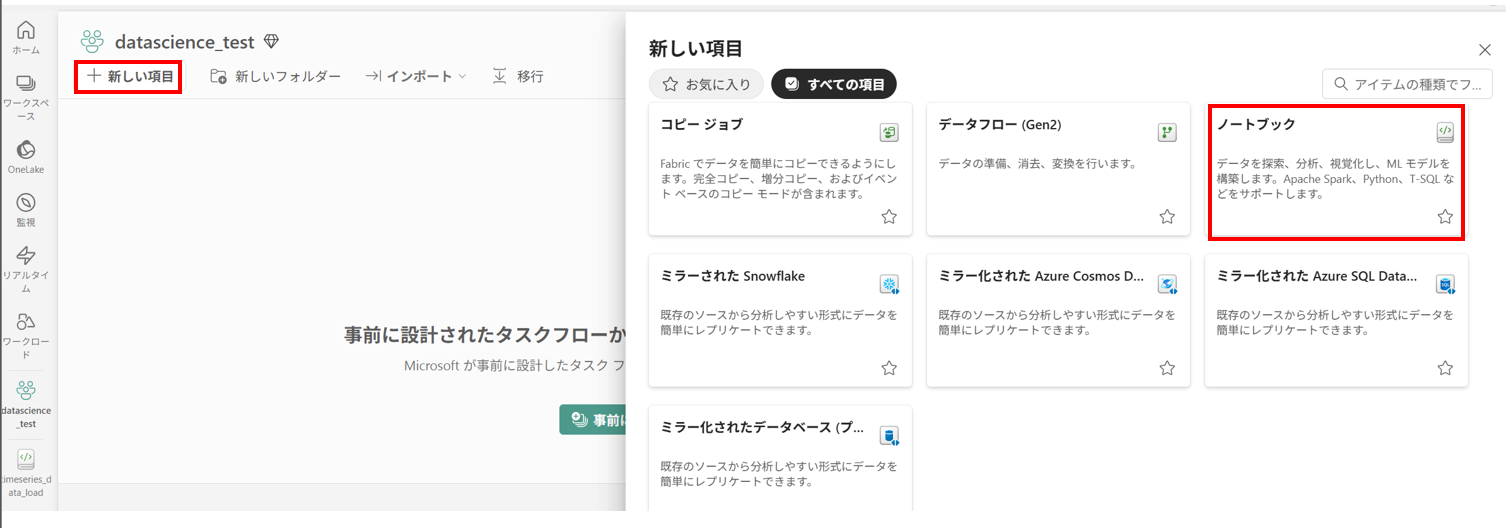
- ノートブックの作成
Fabric 上で [ノートブック] を選択して新しいノートブックを作成します
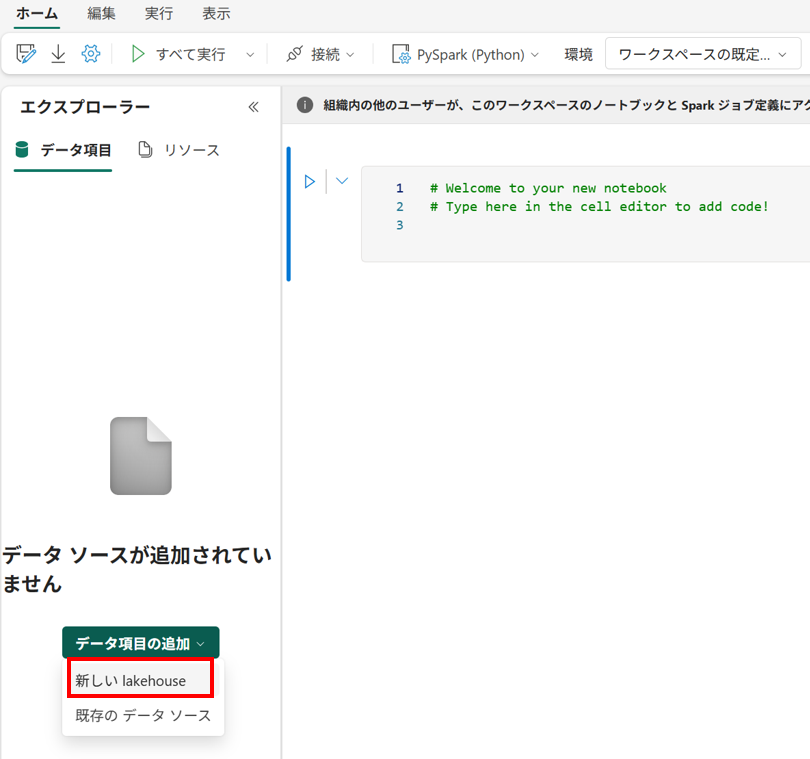
- レイクハウスの連携
[エクスプローラー] から [データ項目の追加] を選択し、AutoML での生成物の保存を行うため、レイクハウスを選択します。
- Python の入力
ノートブックのセルに以下のコードを貼り付け、データのロードを行います。合わせてデータを加工します。ここではニューヨークの電力使用量の時系列データを利用しています。
# Welcome to your new notebook # Type here in the cell editor to add code! import pandas as pd # pd.set_option("display.max_rows", None, "display.max_columns", None) multi_df = pd.read_csv( "https://raw.githubusercontent.com/srivatsan88/YouTubeLI/master/dataset/nyc_energy_consumption.csv" ) # preprocessing data multi_df["timeStamp"] = pd.to_datetime(multi_df["timeStamp"]) multi_df = multi_df.set_index("timeStamp") multi_df = multi_df.resample("D").mean() multi_df["temp"] = multi_df["temp"].fillna(method="ffill") multi_df["precip"] = multi_df["precip"].fillna(method="ffill") multi_df = multi_df[:-2] # last two rows are NaN for 'demand' column so remove them multi_df = multi_df.reset_index() # Using temperature values create categorical values # where 1 denotes daily tempurature is above monthly average and 0 is below. def get_monthly_avg(data): data["month"] = data["timeStamp"].dt.month data = data[["month", "temp"]].groupby("month") data = data.agg({"temp": "mean"}) return data monthly_avg = get_monthly_avg(multi_df).to_dict().get("temp") def above_monthly_avg(date, temp): month = date.month if temp > monthly_avg.get(month): return 1 else: return 0 multi_df["temp_above_monthly_avg"] = multi_df.apply( lambda x: above_monthly_avg(x["timeStamp"], x["temp"]), axis=1 ) del multi_df["month"] # remove temperature column to reduce redundancy display(multi_df)加工したデータをレイクハウスにデルタテーブルとして保存します。
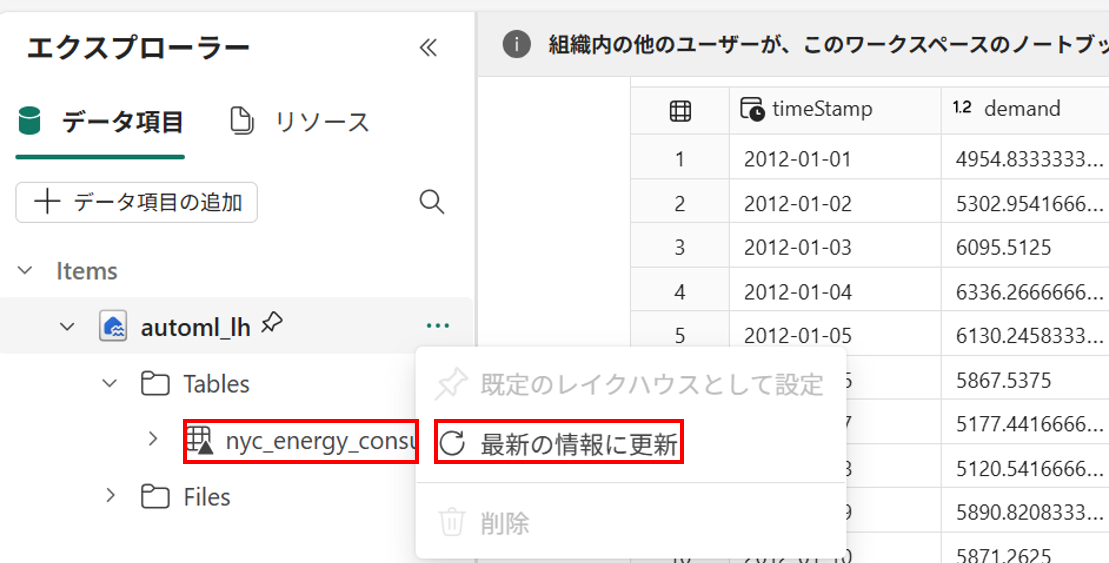
spark_df = spark.createDataFrame(multi_df) spark_df = spark_df.orderBy("timeStamp") spark_df.write.mode("overwrite").format("delta").save(f"Tables/nyc_energy_consumption") print(f"Spark dataframe saved to delta table: nyc_energy_consumption")実行後、レイクハウスで [最新の情報に更新] を選択することで、Tables の配下に [nyc_energy_consumption] が作成されていることを確認できます。
AutoML の実行
- ノートブックの作成
再度、新しいノートブックを作成します。
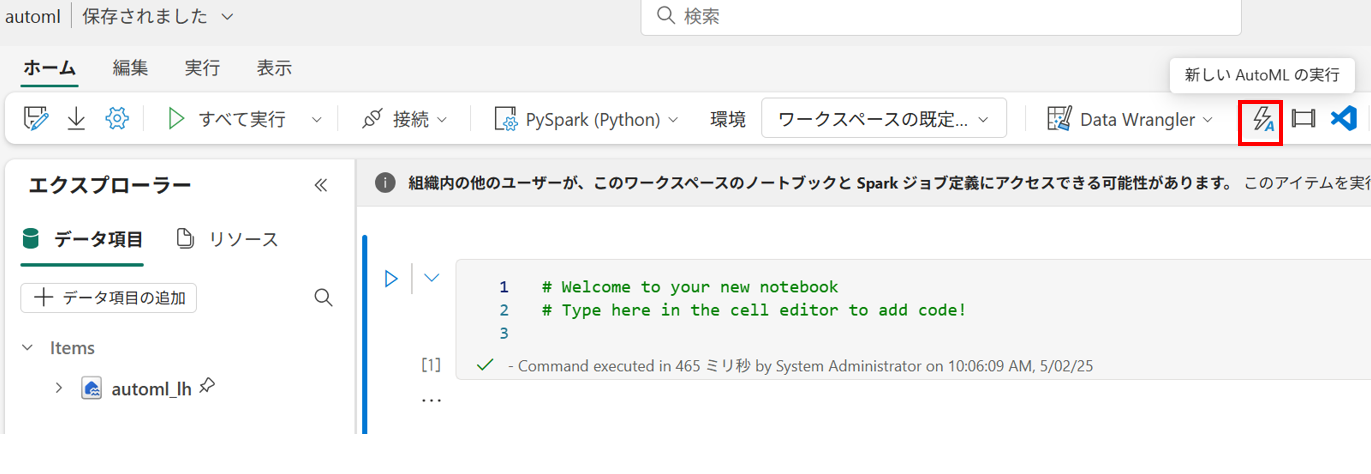
- GUI から AutoML のウィザードを開く
画面上のアイコンから AutoML のウィザードを開きます。
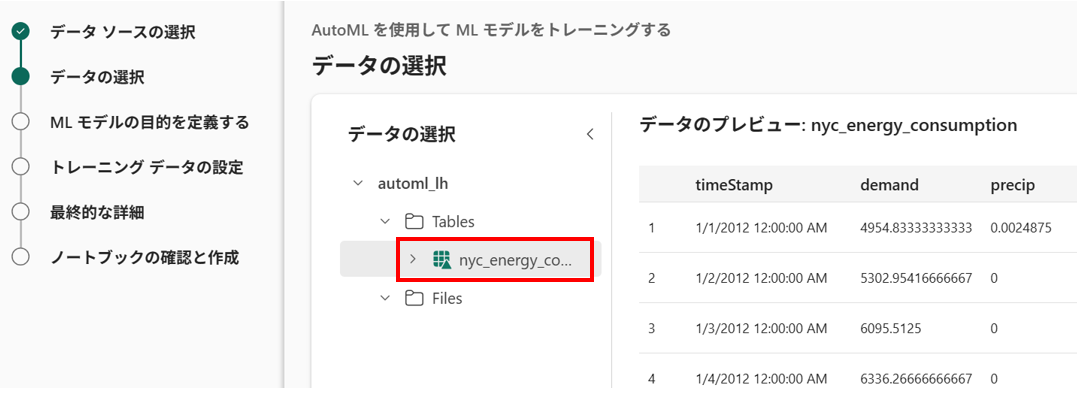
- データの選択
[データソースの選択] で保存したデルタテーブルが存在するレイクハウスを選択し、[データの選択] で [nyc_energy_consumption] を選択します。
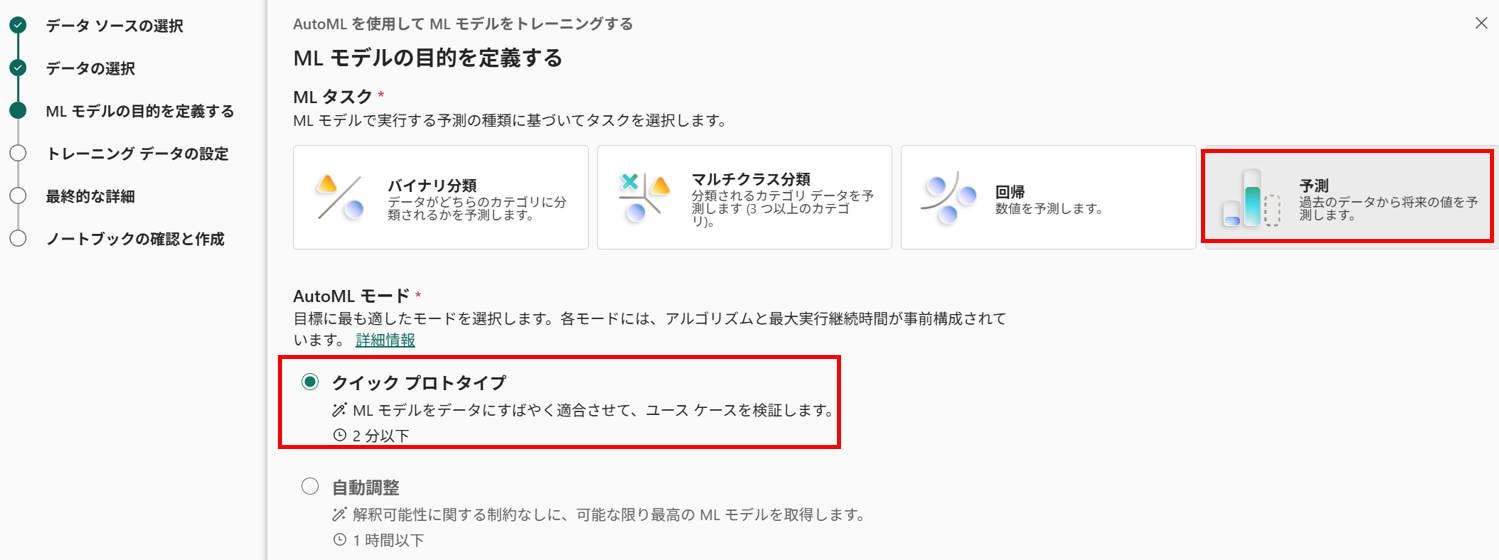
- ML モデルの目的を定義
時系列予測のため、[予測] を選択します。今回は、検証のため [クイックプロトタイプ] を選択します。
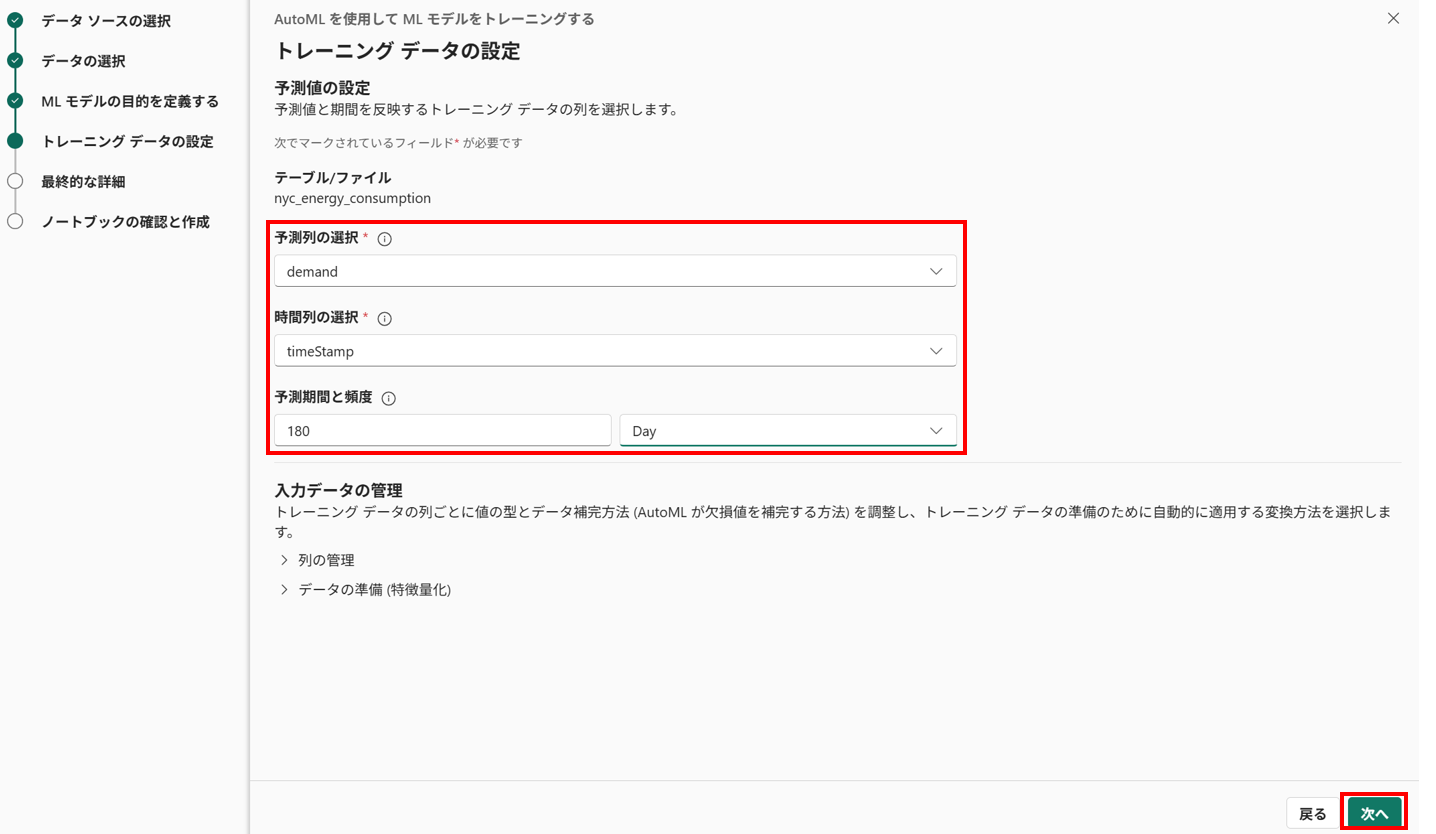
- トレーニングデータの設定
今回は以下のようにトレーニングの設定をしてみます。設定したら [次へ] を選択します。
- 予測列の選択 : demand
- 時系列の選択 : timeStamp
- 予測期間と頻度 : 180, Day
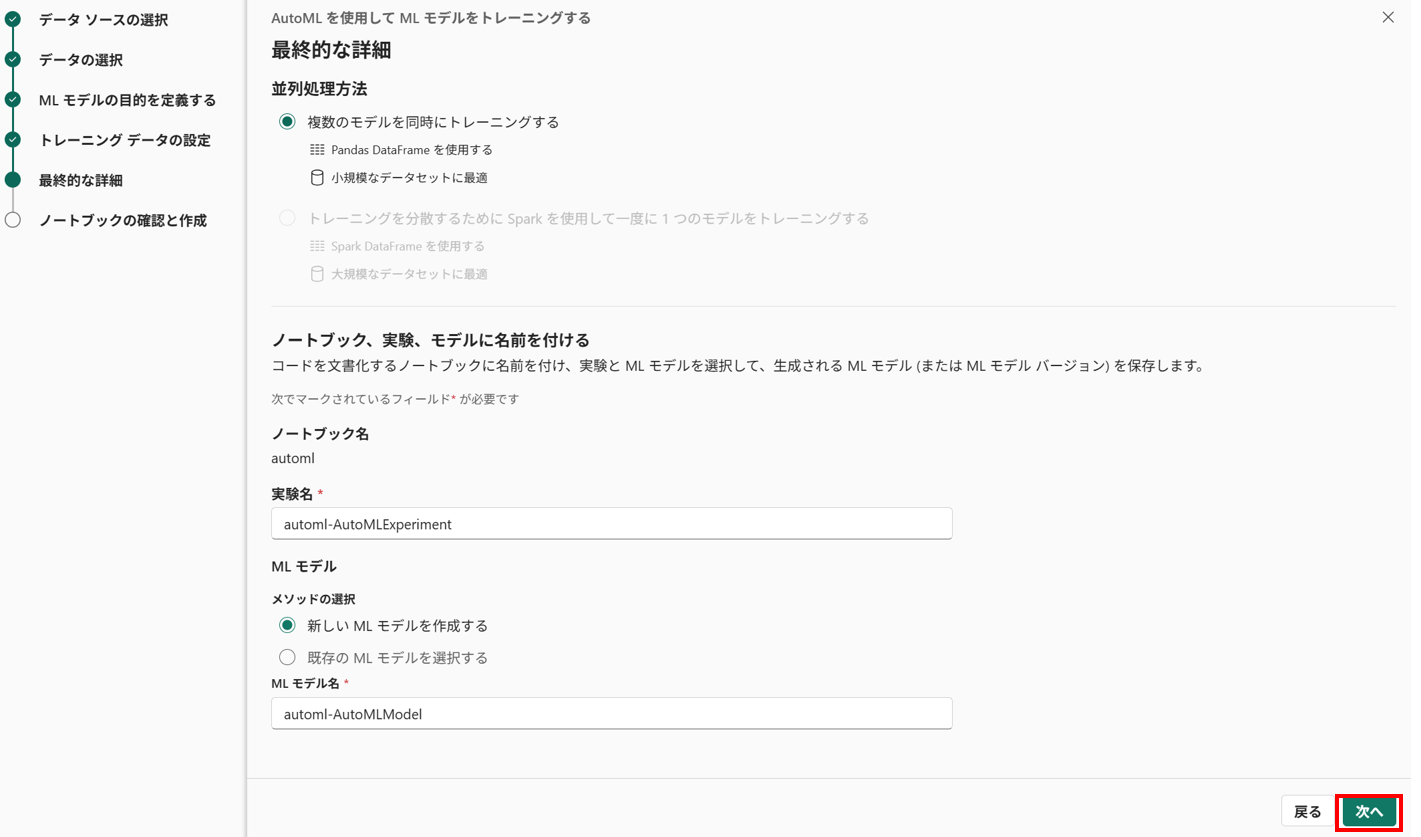
- 名前の設定
名前の変更などを行い [次へ] でプレビューを行います。[作成] を選択すると、ノートブックにコードが自動生成されます。
- コードの変更
生成された python コードの step 2 のセルにおいて、一部を変更しておきます。
79 行目を以下のように変えます。データフレームのインデックスが一致しないことが原因で意図せず補完されてしまうようです。datetime_data = df[datetime_features] ↓ datetime_data = df[datetime_features].reset_index(drop=True)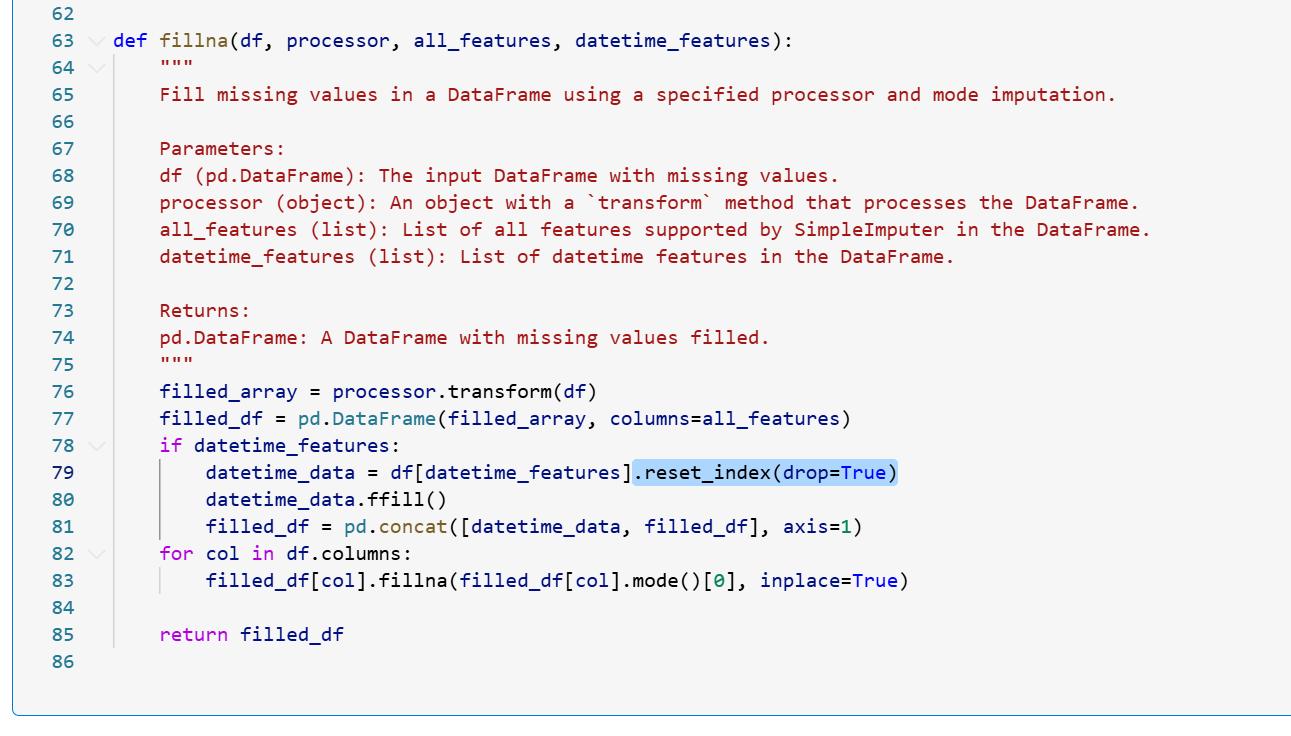
- ノートブックの実行
[すべて実行] で自動生成されたコードを実行し、数分待ちます。
- 結果の可視化
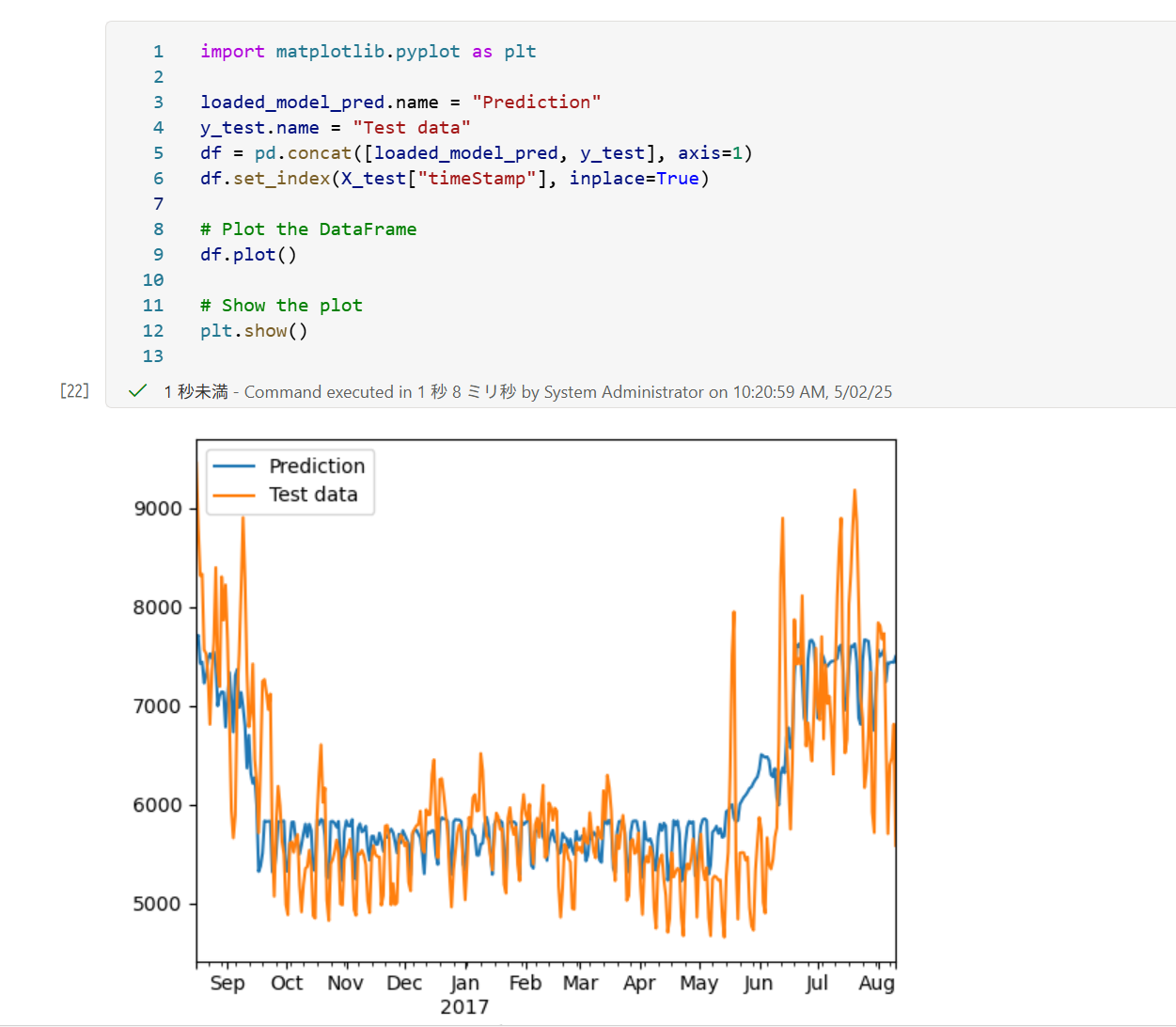
学習が完了し、自動生成されたコードの Step 5 でモデルを利用した予測が行われますので、予測結果をグラフに示してみます。
import matplotlib.pyplot as plt loaded_model_pred.name = "Prediction" y_test.name = "Test data" df = pd.concat([loaded_model_pred, y_test], axis=1) df.set_index(X_test["timeStamp"], inplace=True) # Plot the DataFrame df.plot() # Show the plot plt.show()予測 (Prediction) が、実測値 (Test data) の変動傾向を捉えていることがわかります。特に、7 月から 8 月にかけて実測値が上昇していますが、夏の時期に電力需要が高騰していると考えられ、予測もその季節性に追従できています。
番外編
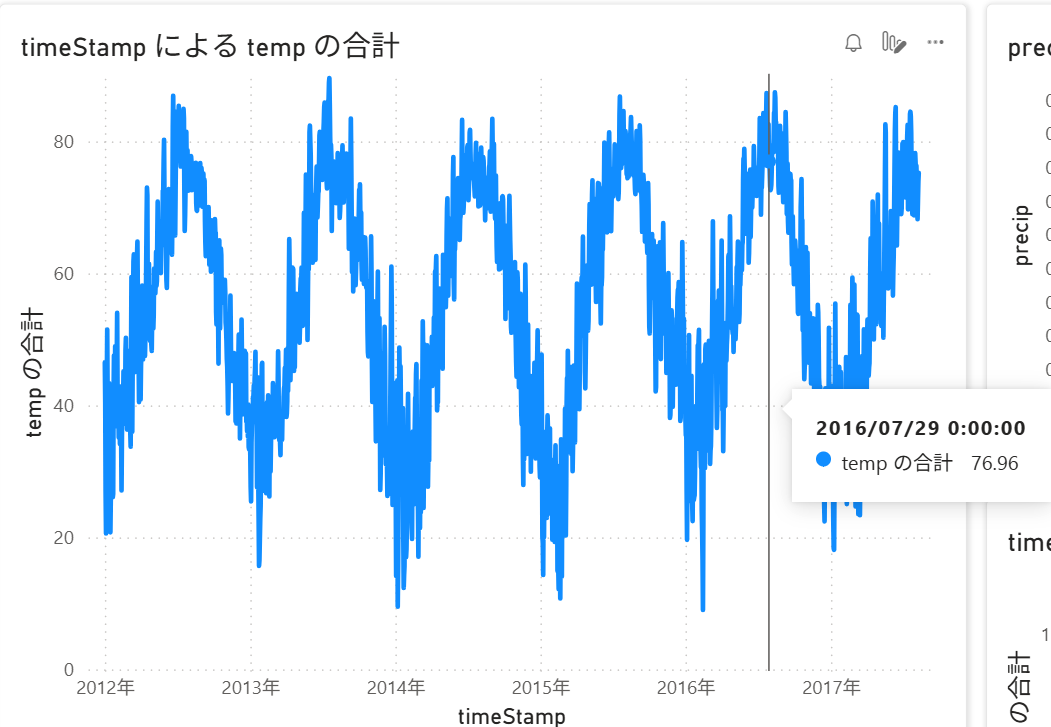
AutoML に利用したデータはレイクハウスにデルタテーブルとして保存してあるので、PowerBI から扱うことも可能です。気温の推移をプロットしてみると、確かに 7 月、8 月頃に上昇していることが確認できました。上記の気温が上昇することで電力需要が高騰することは正しそうです。
まとめ
LLM は時系列予測にも利用できる場合もありますが、現状では ARIMA などの従来からある時系列モデルや機械学習手法の方が精度・効率面で優れている可能性が高いです。Microsoft Fabric はデータの蓄積から機械学習、モデルのデプロイまで一貫して実行できる統合データ基盤であり、AutoML(自動機械学習)もサポートしています。
Fabric と FLAML を活用することで、機械学習の高度な専門知識がなくても高精度な時系列予測が簡単に実現できることを確認しました。データの一元管理や可視化、他サービス連携も容易で、業務での機械学習活用のハードルを大きく下げられると思います。
Views: 2

{kind=link}