
こんにちは、新卒2年目エンジニアの紺谷です。
私はここ1年ほどSaaSプロダクトの運用保守チームで働いています。
普段は顧客や非エンジニアの社員からの問い合わせ対応(プロダクトの仕様の確認やバグ発生時の調査など)や、プロダクトや業務フローを改善していくための開発などをしています。
こういった仕事をやっていくにはプロダクトに使われている技術スタックについての理解はもちろん、プロダクトそのものの使い方や日々刻々と変わっていく仕様を把握したり、その業界特有の複雑なビジネスロジックを理解していくことが欠かせません。
そういったノウハウはドキュメントにまとめ、他のメンバーやこれからチームに入ってくる方々に残していくことが大切なのですが、正直なところ一から文章をまとめるにはなかなか労力がかかります。
メインの情報を箇条書きで書き出してChatGPTに投げて書いてもらうとかでもいいのですが、文書化に必要な情報はSlackやJiraチケット、GitHub/GitLabのリポジトリ上のPR/MR・issue・コード自体、esa(フォルシアで利用しているドキュメント管理ツール)など色々な場所に散らばっていることも多く、それらをまとめるのも大変です。
AIエージェントで解決できないか?
そんな課題を解決するために、Slackに散逸しているテキストや外部情報を集め、構造化されたドキュメントにまとめて出力するようなアプリは作れないかと考えました。
今回はMastraというTypeScriptのAIエージェント系ライブラリを使い、「SlackのスレッドのURLを入力すると、スレッド上のメッセージ履歴やメッセージ内のURLで紐づいた外部情報を取得・文書化し、最終的にMarkdown形式のファイルとして出力する」というところまでを目標としました。
Mastraは、AI機能を搭載したアプリケーションを素早く構築できるTypeScriptフレームワークです。単なるLLMのラッパーではなく、RAGや複雑なAIエージェントの実装が可能で、実用的なAIアプリケーションを体系的に作るための様々なツール群を提供します。
ライブラリとしてNext.jsやNode.js製アプリの中で使うことはもちろん、ブラウザ上でローカルで動作するplaygroundが用意されていてインタラクティブに自分が作ったエージェントの動作を確認できます。
プロジェクトのセットアップ
公式ドキュメントの手順はこちらです。
今回はパッケージマネージャにはpnpm、LLMにはOpenAIのモデルを使います。
以下のコマンドでdocs-creatorという名前でプロジェクトを立ち上げられます。
$ pnpm create mastra@latest docs-creator
コマンドを叩いた後ファイルの配置ディレクトリやデフォルトのLLMプロバイダ(今回はOpenAI)、APIキーを入力するかなどを聞かれるのでEnterを押して進めていきます。
プロジェクトの作成に成功したら、以下のコマンドでplaygroundを立ち上げることが出来ます。ブラウザ上から確認してみましょう。
$ cd docs-creator
$ pnpm run dev
デフォルトでは以下のようなディレクトリ構成になります。
今回は使用しませんがagentsやworkflowなどのディレクトリ内のファイルには、weatherWorkflowやweatherAgentといった変数が定義されており、それらがindex.tsのmastra変数内で指定されることでplayground上から使用可能になっています。
src/mastra/
├── index.ts # Mastraメイン設定
├── agents/ # AIエージェント定義
├── workflow/ # ワークフロー定義
└── tools/ # 外部ツール連携
src/mastra/index.ts
import { Mastra } from '@mastra/core/mastra';
import { PinoLogger } from '@mastra/loggers';
import { LibSQLStore } from '@mastra/libsql';
import { weatherWorkflow } from './workflows/weather-workflow';
import { weatherAgent } from './agents/weather-agent';
export const mastra = new Mastra({
workflows: { weatherWorkflow },
agents: { weatherAgent },
});
Mastra Docs MCP Server の活用
Mastraは公式でMastra Docs MCP ServerというMCP(Model Context Protocol)サーバを提供しています(MCPの概要については後述します)。
これはMastra自体のドキュメントやコードサンプルなど公式が用意したコンテンツを提供しているMCPサーバで、LLMに対して直接ドキュメントを参照させることができるようになっています。
これを設定しておくとMastraそのものの仕様について確認したいとき、ドキュメント上で頑張って調査するようなコストが省けるので、Claude CodeやGithub Copilot (エージェントモード)などのAIコーディングツールやCursorなどのAIコードエディタを利用している方は是非最初に設定してみてください(各環境における設定方法についてはリンク先を参照してください)。
公式ドキュメントに記載されているjson形式の設定のほか、Claude Codeを利用している場合以下のコマンドでMCPサーバを追加することが出来ます。ローカル環境でnpxコマンドが使える必要があることに注意してください。
$ claude mcp add mastra -- npx -y @mastra/mcp-docs-server@latest
Agent の基本的な使い方
それではまず、シンプルなAgentを定義してみましょう。この時点ではAgentは単なるLLMのラッパーで、質問を文字列で渡すと返答を文字列で返してくれるものと考えて構いません。
src/mastra/agents/myAgent.ts
import { Agent } from "@mastra/core/agent";
import { openai } from "@ai-sdk/openai";
export const myAgent = new Agent({
name: "my-agent",
instructions: "あなたは親切なアシスタントです。",
model: openai("gpt-4o-mini"),
});
src/mastra/index.ts
import { Mastra } from "@mastra/core";
import { weatherWorkflow } from "./workflows/weather-workflow";
import { myAgent } from "./agents/myAgent";
export const mastra = new Mastra({
workflows: { weatherWorkflow },
agents: { myAgent },
});
これでplayground画面の”Agents”タブで、作成したAgentに質問を投げることが出来ます。
こういった処理をコード内で行うにはgenerate()メソッドを用います。また、generate()メソッドの中で第2引数にzodスキーマを指定することで、Agentの出力の型を縛ることもできます。
import { z } from "zod";
const response1 = await myAgent.generate([
{ role: "user", content: "元気ですか?" },
]);
console.log(response1.text);
const sampleSchema = z.object({
prefecture: z.string().describe("都道府県名"),
city: z.string().describe("市区町村名"),
yomigana: z.string().describe("よみがな"),
});
const response2 = await myAgent.generate(
[
{
role: "user",
content:
"「長万部」はどの都道府県のどの市区町村にありますか?またなんと読みますか?",
},
],
{ output: sampleSchema }
);
console.log(response2.object);
Agent にツールを使わせる
MCPサーバが提供するツールを使わせる
昨今のAIエージェント界隈では、LLMに外部ツールを使わせる手法としてMCP(Model Context Protocol)が注目を集めています。
MCPは、LLMと様々な外部サービスやツールを連携させるためにAnthropic社が発表した標準的なプロトコルで、LLMの能力を大幅に拡張することができます。
MastraにおいてAgentにMCPサーバが提供するツールを使ってもらうには、まずMCPClientを定義する必要があります。
ここではGitHub公式が出しているMCPサーバを例に使います。
GitHubリモートMCPサーバについてはOAuthとGitHub Personal Access Tokenを使った2つの例が示されていますが、今回は後者の方法で認証を行います。
src/mastra/tools/github.ts
import { MCPClient } from "@mastra/mcp";
export const githubMcp = new MCPClient({
servers: {
"github-mcp": {
url: new URL("https://api.githubcopilot.com/mcp/"),
requestInit: {
headers: {
Authorization: `Bearer ${process.env.GITHUB_PERSONAL_ACCESS_TOKEN || ""}`,
},
},
},
},
});
export const githubMcpTools = await githubMcp.getTools();
export const readOnlyGithubMcpTools = Object.fromEntries(
Object.entries(githubMcpTools).filter(([toolName]) =>
toolName.includes("_get_")
)
);
同様にローカル環境のMCPサーバを使わせることも出来ます。
社内で有志の方が作ってくださったesaの記事を取得・投稿できるNode.js製のMCP サーバを使ってみたいと思います。
src/mastra/tools/esa.ts
import { MCPClient } from "@mastra/mcp";
export const esaMcp = new MCPClient({
servers: {
"esa-mcp": {
command: "node",
args: ["/path/to/directory/esa-mcp-server/build/index.js"],
env: {
ESA_ACCESS_TOKEN: process.env.ESA_ACCESS_TOKEN || "",
},
},
},
});
export const esaMcpTools = await esaMcp.getTools();
export const readOnlyEsaMcpTools = Object.fromEntries(
Object.entries(esaMcpTools).filter(([toolName]) => toolName.includes("get-"))
);
取得したツールを実際にAgentに使わせます。
src/mastra/agents/toolsAgent.ts
import { openai } from "@ai-sdk/openai";
import { Agent } from "@mastra/core";
import { readOnlyEsaMcpTools } from "../tools/esa";
import { readOnlyGithubMcpTools } from "../tools/github";
const instructions = `
あなたは、与えられたツールを使用して、ユーザーの質問に答えるエージェントです。
ツールが使えない際は、その旨をユーザーに伝えてください。
日本語で回答してください。
`;
export const toolsAgent = new Agent({
name: "tools-agent",
model: openai("gpt-4o"),
instructions,
tools: {
...readOnlyEsaMcpTools,
...readOnlyGithubMcpTools,
},
});
src/mastra/index.ts
import { Mastra } from "@mastra/core/mastra";
import { weatherWorkflow } from "./workflows/weather-workflow";
import { myAgent } from "./agents/myAgent";
import { toolsAgent } from "./agents/toolsAgent";
export const mastra = new Mastra({
workflows: { weatherWorkflow },
agents: { myAgent, toolsAgent },
});
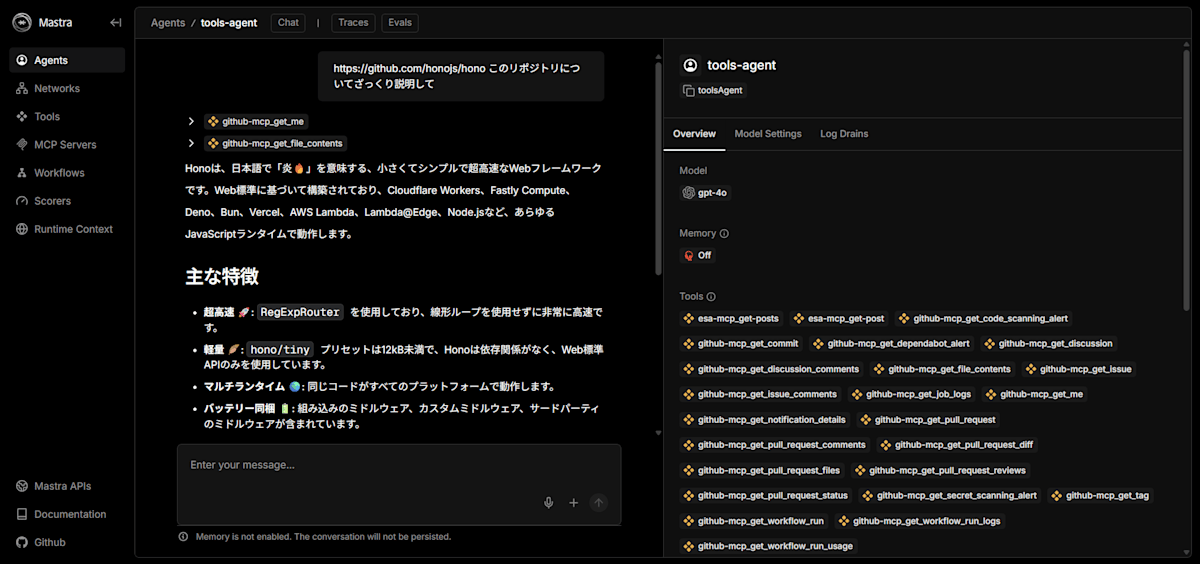
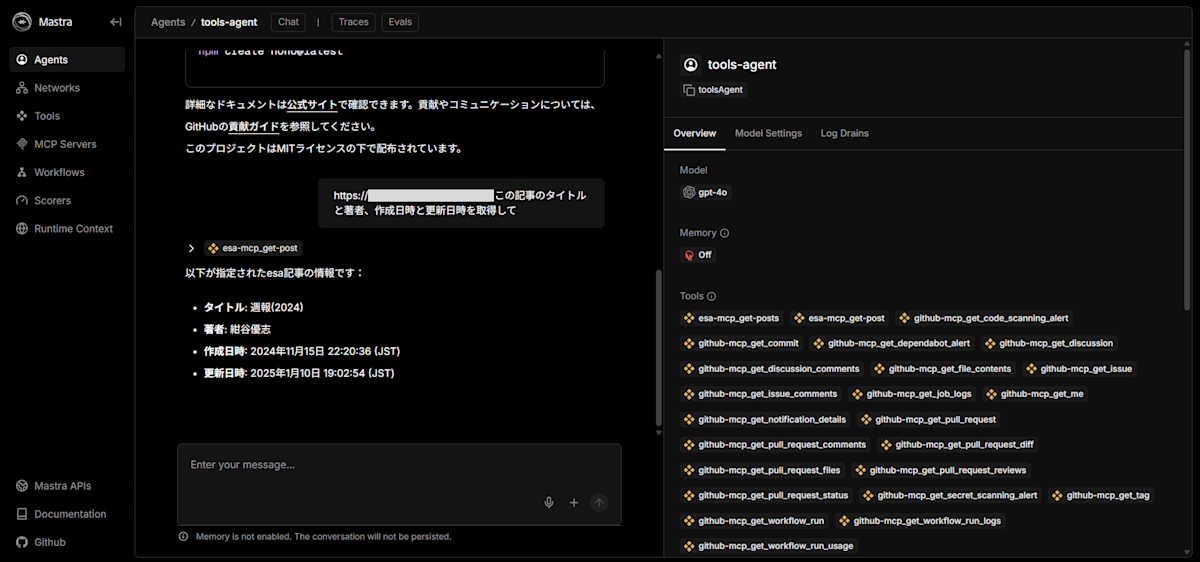
index.tsにtoolsAgentを追記して、playgroundから試してみました。
リポジトリ内の指定したファイル内のソースコードやその概要、私が書いた esa の記事の情報を正しく取得できているようです。
また、画面右側にはAgentが利用可能なツールの一覧が確認できます。
任意の関数をツールとして使わせる
自分で用意した関数をツールとしてAgentに使わせることも出来ます。
本記事の冒頭でSlackの情報を取ってきたいというような話をしたかと思いますがSlackの公式MCPサーバは現在アーカイブされていて利用することは出来ません。
今回はSlackのメッセージのURLを入力引数として受取り、そのメッセージが属するスレッドの内容を全てひとまとめに文字列として返すような関数getSlackThreadMessage()を用意します(記事の本題から反れるため詳細な実装は省略します)。
src/mastra/utils/getSlackThreadMessage.ts
import { WebClient } from "@slack/web-api";
export const getSlackThreadMessage = async (url: string) => {
try {
const urlPattern =
/https:\/\/[\w-]+\.slack\.com\/archives\/([A-Z0-9]+)\/p(\d+)/;
const match = url.match(urlPattern);
const [, channelId, timestamp] = match;
const formattedTimestamp = `${timestamp.slice(0, 10)}.${timestamp.slice(10)}`;
const client = new WebClient(process.env.SLACK_USER_TOKEN);
const threadResult = await client.conversations.replies({
channel: channelId,
ts: formattedTimestamp,
inclusive: true,
});
return threadMessage;
} catch (error) {
throw new Error("メッセージの取得に失敗しました");
}
}
関数をcreateTool()メソッドでラップすることでAgentが利用できるツールとして定義します。
src/mastra/tools/slack.ts
import { createTool } from "@mastra/core";
import z from "zod";
import { getSlackThreadMessage } from "../utils/getSlackThreadMessage";
export const slackTool = createTool({
id: "getSlackThreadMessage",
description: "SlackのスレッドURLからメッセージ内容を取得",
inputSchema: z.object({
url: z.string().describe("SlackスレッドのURL"),
}),
outputSchema: z.string().describe("取得されたSlackメッセージの内容"),
execute: async ({ context }) => {
return await getSlackThreadMessage(context.url);
},
});
後は先程のtoolsAgentにslackToolを指定しましょう。SlackのURLを受け取るとAgentが自律的にslackToolを選択してくれるようになります。
src/mastra/agents/toolsAgent.ts
import { slackTool } from "../tools/slack";
export const toolsAgent = new Agent({
tools: {
...readOnlyEsaMcpTools,
...readOnlyGithubMcpTools,
slackTool
},
});
次は複数のAgentや機能を組み合わせて複雑な処理を動かしていく方法を見ていきましょう。
序盤に述べた「SlackのスレッドのURLからいい感じに情報を取ってきて、最終的にMarkdown形式のドキュメント化」ですが、全体を以下のような単位に分割できると考えました。
- SlackスレッドのURLを受け取り、対象スレッドのメッセージ内容を取得する
-
Agentがスレッドの内容を元に、ドキュメントとして構造や流れ(見出しやそのタイトルなど)を大まかに決定し、文書のテンプレートを出力する
- 任意項目としてユーザーから「こういった内容にしてほしい」という要望を受け取る
- メッセージ内容上には他Slackスレッドやチケット、GitHubなどのURLが含まれていれば、それらの情報も文脈情報としてAgentに取得してもらう
- 文脈情報、文書のテンプレートを用いながらメッセージ内容をAgentに渡し、ドキュメントにまとめさせた上でファイル出力する
ここまでの処理を自動化できれば、散逸した情報からドキュメントを書くという仕事の大部分を自動化できそうな気がしてきました。
各Agentの用意
上記の流れでは役割の違う複数のAgentを使っています。まずはこれらを定義しましょう。
src/mastra/agents/documentAgent.ts
import { Agent } from "@mastra/core/agent";
import { openai } from "@ai-sdk/openai";
import { readOnlyEsaMcpTools } from "../tools/esa";
import { readOnlyGithubMcpTools } from "../tools/github";
import { slackTool } from "../tools/slack";
export const contextExtractionAgent = new Agent({
name: "context-extraction-agent",
model: openai("gpt-4o-mini"),
instructions: `あなたは、与えられたツールを使用して、ユーザーの質問に答えるエージェントです。
ツールが使えない際は、その旨をユーザーに伝えてください。`,
tools: {
...readOnlyEsaMcpTools,
...readOnlyGithubMcpTools,
slackTool,
},
});
export const documentTemplateAgent = new Agent({
name: "document-template-agent",
description: "文書のテンプレートを生成するエージェント",
model: openai("gpt-4o"),
instructions: `あなたは、与えられた文書とユーザーから与えられた指示を元に、これから作成する文書のテンプレートを生成するエージェントです。
**重要な指示:**
- 生成するテンプレートの大見出し(#)とそのタイトル、中見出し(##)とそのタイトルだけ出力してください。
- テンプレートはマークダウン形式で出力してください。
- 与えられた文書の内容を参考にしながら、ユーザーの指示に従ってテンプレートを生成してください。
- 見出しのタイトルは日本語にしてください`,
});
export const documentSummaryAgent = new Agent({
name: "document-summary-agent",
description: "文書の要約を生成するエージェント",
model: openai("gpt-4o"),
instructions: `あなたは、Slackのチャットログをもとに、**事実ベース**の詳細な技術文書を作成するエージェントです。プロンプトには「Slackメッセージ内容」「コンテキスト情報」「テンプレート」が含まれます。コンテキスト情報はSlackメッセージ内に現れるURLのリンク先の情報を取得したものです。指定されたテンプレートに従い、Slackメッセージ内容をまとめてください。Slackメッセージだけで補えない部分を、コンテキスト情報から補完してください。
**重要な指示:**
- テンプレートで指定されたテンプレートに従う。必要に応じて小見出し(###)を追加してもよい
- **ソースコードはできる限り含める** -
コンテキスト情報にソースコードがある場合は、コードブロックで積極的に記載
- **事実のみを記載** - 推測や一般論は避け、具体的な事実(エラー内容、コード変更、設定値など)を記載する
- **技術的詳細を省略しない** - エラーメッセージ、設定ファイル、コマンド例などを具体的に記載
- **時系列を明確に** -
何がいつ起こったか、誰が何をしたかを詳細に記録
**記載すべき内容の例**
- 具体的なエラーメッセージとスタックトレース
- ファイルの変更内容(変更前後の差分)
- 実行されたコマンドとその結果
- 散逸的に散らばっている情報を整理し、構造化する
- Slackメッセージ内容をメインに文書を作成し、コンテキスト情報 中に含まれるテキストも大量に取り入れる
- 根本原因の技術的詳細
出力は必ずマークダウン形式で行ってください。`,
});
Stepを作っていく
Mastraにおいて複雑な処理を組み合わせるには、createStep()メソッドで処理の1単位であるStepを作り、createWorkflow()メソッドで1つ1つのStepをWorkflowというひとつなぎの処理にまとめあげる必要があります。
Stepでは入力変数のスキーマinputSchemaと出力変数のスキーマoutputSchemaをzodで設定する必要があります。最初に全てのStepで使うスキーマを適当なファイルに作成してしまうことにします。
src/mastra/defenition/schema.ts
import { z } from "zod";
export const inputSchema = z.object({
slackUrl: z.string().url(),
userInstructions: z.string().optional(),
});
export const messageSchema = z.object({
message: z.string(),
});
export const contextExtractionSchema = z.object({
message: z.string(),
context: z.string(),
});
export const documentTemplateSchema = z.object({
template: z.string(),
});
export const documentSchema = z.object({
document: z.string(),
});
続いて、先程設定した4段階のStepを定義しましょう。
src/mastra/workflows/documentGenerationWorkflow.ts
import { createStep } from "@mastra/core";
import { z } from "zod";
import { getSlackThreadMessage } from "../utils/getSlackThreadMessage";
import {
contextExtractionAgent,
documentSummaryAgent,
documentTemplateAgent,
} from "../agents/documentAgent";
import {
contextExtractionSchema,
documentSchema,
documentTemplateSchema,
inputSchema,
messageSchema,
} from "../defenition/schema";
const slackMessageRetrievalStep = createStep({
id: "slackMessageRetrieval",
description: "SlackのURLを受け取り、スレッドの内容を全て取得するステップ",
inputSchema: inputSchema,
outputSchema: messageSchema,
execute: async ({ inputData }) => {
const message = await getSlackThreadMessage(inputData.slackUrl);
return { message };
},
});
const contextExtractionStep = createStep({
id: "contextExtraction",
description: "メッセージからURLを抽出し、各URLから情報を取得するステップ",
inputSchema: messageSchema,
outputSchema: contextExtractionSchema,
execute: async ({ inputData }) => {
const { message } = inputData;
const urlPattern = /(https?:\/\/[\w/:%#$&?()~.=+-]+)/g;
const urlList = inputData.message.match(urlPattern) || [];
const contextList = await Promise.all(
urlList.map(async (url) => {
const agentResult = await contextExtractionAgent.generate([
{
role: "user",
content: url,
},
]);
return `
{
"url": "${url}",
"content": "${agentResult.text}"
}
`;
})
);
const context = contextList.join("\n");
return {
message: inputData.message,
context,
};
},
});
export const templateCreationStep = createStep({
id: "templateCreation",
description: "文書のテンプレートを作るステップ",
inputSchema: messageSchema,
outputSchema: documentTemplateSchema,
execute: async ({ inputData, getInitData }) => {
const { userInstructions } = getInitDatatypeof inputSchema>();
const prompt = `
【文書】
${inputData.message}
${userInstructions ? `【ユーザーからの指示】\n${userInstructions}` : ""}
`;
const result = await documentTemplateAgent.generate(
[{ role: "user", content: prompt }],
{ output: documentTemplateSchema }
);
return { template: result.object.template };
},
});
const summarizationStep = createStep({
id: "summarization",
description: "メッセージ内容とコンテキスト情報をもとに文書を要約するステップ",
inputSchema: z.object({
contextExtraction: contextExtractionSchema,
templateCreation: documentTemplateSchema,
}),
outputSchema: documentSchema,
execute: async ({ inputData: { contextExtraction, templateCreation } }) => {
const { message, context } = contextExtraction;
const { template } = templateCreation;
const prompt = `
【Slackメッセージ内容】
${message}
【コンテキスト情報】
${context}
【テンプレート】
${template}
`;
const result = await documentSummaryAgent.generate(
[{ role: "user", content: prompt }],
{ output: documentSchema }
);
const document = result.object.document;
await outputToLogFile(`文書要約`, result.object.document);
return { document: result.object.document };
},
});
createWorkflow で Step を繋げて一連の処理へ
最後に、createWorkflow()メソッドでStepをひとつなぎの処理として連結します。
import { createStep, createWorkflow } from "@mastra/core";
export const documentGenerationWorkflow = createWorkflow({
id: "slack-documentation-workflow-ver2",
inputSchema: inputSchema,
outputSchema: documentSchema,
})
.then(slackMessageRetrievalStep)
.parallel([contextExtractionStep, templateCreationStep])
.then(summarizationStep)
.commit();
ステップを逐次処理する場合はthen()メソッドを繰り返し使用します。
あるステップのoutputSchemaと次のステップのinputSchemaは一致している必要があります。
並列処理を行うときはparallel()を使います。contextExtractionStepとtemplateCreationStepに関しては順番に実行する必要がないことから処理時間短縮のためもあって並列処理としました。そのため、先程のsummarizationStepの入力ではこの 2 つの Step の出力を同時に受け取って処理する形になっています。
また、最後には必ずcommit();を指定してWorkflowの処理の完了を明示する必要があります。
今回は扱いませんでしたが、条件分岐を作成するbranch()やループ処理が使えるdowhile(), dountil(), foreach()といったメソッドも存在します(公式ドキュメント参照)。Agentの成果物の品質が十分高まるまで同じ処理をループしたり、Agentの評価に応じて異なる処理をさせるといった複雑な処理を導入する場合こういったメソッドを使うと便利だと思います。
実行結果
実際にSlackで適当なスレッドを作って実行してみた結果、無事リンク先の情報を参照しながらいい感じにまとまったドキュメントを出力してくれました。
Slackスレッドの内容
[2025/8/10 16:35:55] Yushi Kontani:
claude code上でgithubの情報を取得できるようにする方法が知りたい
issueやPRを作成することもできるのだろうか?
[2025/8/10 16:41:06] Yushi Kontani:
https://github.com/modelcontextprotocol/modelcontextprotocol
どうやらこういうやつを導入すればいけるらしい
[2025/8/10 16:44:01] Yushi Kontani:
github mcp server (https://github.com/github/github-mcp-server) というリポジトリがあった
claudeにMCPサーバというものを使用するように設定すればいいのだろうか
[2025/8/10 16:46:42] Yushi Kontani:
https://github.com/github/github-mcp-server?tab=readme-ov-file#install-in-vs-code
ここにjson形式の設定ファイルのようなものがある
GITHUB_PERSONAL_ACCESS_TOKENというものが必要らしい?
[2025/8/10 16:47:17] Yushi Kontani:
readmeからclaude code cli用のインストール手順を見つけた
この通りにコマンドを叩けばよさそうだ
https://github.com/github/github-mcp-server/blob/main/docs/installation-guides/install-claude.md#claude-code-cli
[2025/8/10 16:53:44] Yushi Kontani:
この説明中にアクセストークンを取得する方法も書いてあったのでちゃんと取得できた
無事claudeにgithub mcp serverを設定することができた
出力されたドキュメント
# GitHub情報取得と操作の設定方法
## GitHub情報取得の概要
Yushi Kontaniは、Claude Code上でGitHubの情報を取得し、issueやPRを作成する方法を模索していました。GitHub MCPサーバを使用することで、これが可能になると考えています。
## 必要なツールとリポジトリ
- [Model Context Protocol (MCP)](https://github.com/modelcontextprotocol/modelcontextprotocol)
- [GitHub MCP Server](https://github.com/github/github-mcp-server)
## MCPサーバの設定
GitHub MCPサーバを使用するためには、VS CodeやClaude Code CLIなどの環境で設定を行う必要があります。以下はVS Codeでの設定例です。
### VS Codeでの設定
- **OAuthを使用する場合**:
```json
{
"servers": {
"github": {
"type": "http",
"url": "https://api.githubcopilot.com/mcp/"
}
}
}
```
- **GitHub Personal Access Token (PAT)を使用する場合**:
```json
{
"servers": {
"github": {
"type": "http",
"url": "https://api.githubcopilot.com/mcp/",
"headers": {
"Authorization": "Bearer ${input:github_mcp_pat}"
}
}
},
"inputs": [
{
"type": "promptString",
"id": "github_mcp_pat",
"description": "GitHub Personal Access Token",
"password": true
}
]
}
```
## GITHUB_PERSONAL_ACCESS_TOKENの取得
GitHubの情報を取得するためには、[GitHub Personal Access Token](https://github.com/settings/personal-access-tokens/new)が必要です。このトークンは、GitHubの設定ページから生成できます。
## Claude Code CLIのインストール手順
Claude Code CLIでGitHub MCPサーバを使用するための手順は以下の通りです。
### 必要条件
- Claude Code CLIがインストールされていること
- Dockerがインストールされ、実行中であること
### インストール手順
1. Dockerを使用してGitHub MCPサーバを追加:
```bash
claude mcp add github -- docker run -i --rm -e GITHUB_PERSONAL_ACCESS_TOKEN ghcr.io/github/github-mcp-server
```
2. 環境変数を設定:
```bash
claude mcp update github -e GITHUB_PERSONAL_ACCESS_TOKEN=your_github_pat
```
3. または、トークンをインラインで指定:
```bash
claude mcp add-json github '{"command": "docker", "args": ["run", "-i", "--rm", "-e", "GITHUB_PERSONAL_ACCESS_TOKEN", "ghcr.io/github/github-mcp-server"], "env": {"GITHUB_PERSONAL_ACCESS_TOKEN": "your_github_pat"}}'
```
## IssueやPRの作成方法
具体的なIssueやPRの作成方法については、GitHub MCPサーバの設定が完了した後、Claude Code CLIを通じて行うことができます。詳細な手順は、GitHub MCPサーバのドキュメントを参照してください。
本記事では、Slackスレッドからのドキュメント作成という目的のもと、AIエージェント構築のためのTypeScriptフレームワークであるMastraについて、その基本的な使い方から複数のエージェントとMCPなどのツールを連携させたワークフローを構築するまでの一連の流れを解説しました。
ある程度思い描いていたものは作れましたし、プロンプトの内容やワークフローの組み方を改善すればもっと精度の高い成果物を出力してもらうこともできるのではないかなと思います。
今後も、AIエージェントの技術で日々の様々な業務を改善していくことに積極的に取り組んでいきたいと考えています。
この記事を書いた人
紺谷 優志
2024 年新卒入社
この間「デザインあ展」を見に行った時に買った「てへんゆのみ」がお気に入りです。
Views: 0

{kind=link}