
Lumina Image 2.0 (略して Lumina2 や LU2) は、Alpha-VLLM から公開された Unified NextDiT アーキテクチャの画像生成モデルです。
この Lumina2 をベースにしたイラスト特化のファインチューンである Neta Lumina が最近公開されたので、Lumina2 のアーキテクチャについて見ていこうと思います。
Lumina 2.0 アーキテクチャ
Stable Diffusion や Flux のような他の画像生成モデルと同様に、Lumina2 は テキストエンコーダー、VAE、デノイザー で構成されています。
| モジュール | タイプ | パラメータ数 |
|---|---|---|
| テキストエンコーダー | Gemma2 2B (base) | 約 2.6 B |
| VAE | Flux.1 VAE | 約 80 M |
| デノイザー | Unified NextDiT (提案アーキテクチャ) | 約 2.6 B |
テキストエンコーダー
まずテキストエンコーダーについて、複数のテキストエンコーダーを採用する SDXL や SD3.5、 Flux.1 と異なり、使用されているテキストエンコーダーは Gemma2 2B の 1 つだけとなっています。
また、Gemma2 はインストラクション版ではなく事前学習版が使用されていますが、これはおそらく前身の Lumina-T2X で採用されいたものをそのまま引き継いだのだと思います。
一方で、学習時のプロンプトテンプレートは以下のようにインストラクションが入っています。
You are an assistant designed to generate high-quality images based on user prompts.
{image_prompt}
詳しい言及がないので推測ですが、おそらく SANA の Complex Human Instruction に影響を受けている気がします。SANA もベース版の Gemma2 を採用しながら、指示応答のようなプレフィックスを付与して学習しています。
Gemma2 が多言語に対応しているのと、学習データに中国語のキャプションも含めていることから、Lumina2 は英語と中国語の両方に対応しています。ファインチューンの Neta Lumina はさらに日本語のキャプションも学習したので、日本語での生成も可能になっています。
Lumina2 も他の多くの画像生成モデルと同様に、テキストエンコーダーの 最後から二番目 の層の出力を埋め込みとして利用しています。実際に公式実装のテキストをエンコードしている部分を見てみると、
とあるように、hidden_states の最後から二番目 ([-2]) を使っていることがわかります。
ライセンスについて
ところで、Gemma2 はもちろん Gemma ライセンス であり、再配布でも Gemma ライセンスが適用されるはずなのですが、Lumina2 が Apache 2.0 で配布されているのは一体…? 関連する事例としては、HiDream は Llama3.1 をテキストエンコーダーを採用していますが、Llama3.1 自体は再配布せずに他の部分を MIT ライセンスとして配布しています。なので、Gemma2 以外 Apache 2.0 ライセンス状態と考えられるか…?
と思いたいのですが、Gemma ライセンスによると、
(e) “Model Derivatives” means all (i) modifications to Gemma, (ii) works based on Gemma, or (iii) any other machine learning model which is created by transfer of patterns of the weights, parameters, operations, or Output of Gemma, to that model in order to cause that model to perform similarly to Gemma, including distillation methods that use intermediate data representations or methods based on the generation of synthetic data Outputs by Gemma for training that model. For clarity, Outputs are not deemed Model Derivatives.
とあり、画像を生成するので「Gemmaと類似の性能を持つように作られたモデル」ではないが、テキストエンコーダーとして使っているので「Gemma をベースとしたモデル」には該当するような気がしなくもなくもない… となると Lumina2 は Gemma ライセンスが適用されるのが妥当になる気もする。
Gemma2 がテキストエンコーダーの SANA は、その部分が Gemma ライセンスであることを明記しているが、全体としては NSCL v2-custom という特殊なライセンスになっている。
なのでかなり微妙なライン… 個人的には Qwen だったらライセンス的に良かったな…
VAE
Flux.1 の VAE をそのまま使っています。
| 項目 | 値 |
|---|---|
| チャンネル数 | 16 |
| 縦横圧縮率 | 1/8 (面積は 1/64) |
Flux.1 は [dev] は非商用ライセンスですが [schnell] が Apache 2.0 ライセンスになっているので、内包されている VAE が緩いライセンスの VAE として使うことができます。
しかし
実際の Lumina-Image 2.0 の vae フォルダーにある config.json を見てみると、
config.json
{
"_class_name": "AutoencoderKL",
"_diffusers_version": "0.33.0.dev0",
"_name_or_path": "black-forest-labs/FLUX.1-dev",
"act_fn": "silu",
...
と、特殊なライセンスになっている [dev] 版の "black-forest-labs/FLUX.1-dev" から取ってきてるようです。まあ中身は一緒なのでこっちは大きな問題はないんじゃないかと思います。
デノイザー
デノイズする部分です。学習目標は Flow Matching で、アーキテクチャは NextDiT から派生した Unified NextDiT です。 NextDit は Lumina Image 2.0 の前身である Lumina-T2X で提案されたアーキテクチャです。
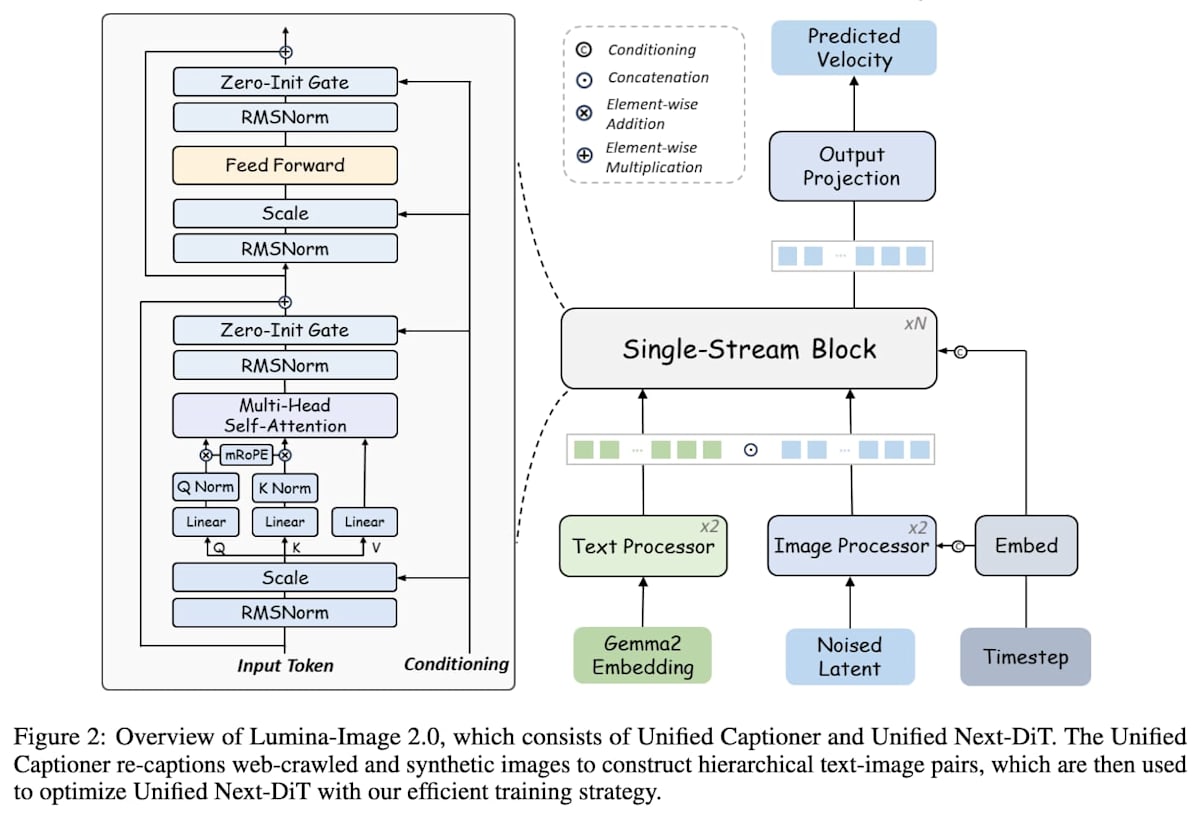
Lumina-Image 2.0: A Unified and Efficient Image Generative Framework の Figure 2 より
素の DiT と比較した際の差異は主に以下の通りです (ただし、Lumina2 以前に導入されたものも含む):
-
AdaRMSNormZero: LayerNorm をほぼ RMSNorm に置き換えた。
shiftはなくなり、scaleとgateのみを使う。特に呼び名がないのでここでは AdaRMSNormZero と呼ぶことにする。(公式実装ではadaLNの表記が出てくるが、実際に LayerNorm を使っているのは最後の 1 層のみ。diffusers の実装 ではほとんどのadaLNではLuminaRMSNormZeroが使われている)。Lumina-T2X で導入。 -
tanh gate: AdaRMSNormZero で使う
gateをtanhに通すようにした (これによってgateが -1~1 の値になって爆発しない)。Lumina-T2X で導入。 - Sandwich Nroamlization: Attention と MLP の前後に RMSNorm を配置。これによりアクティベーションの値が安定する。CogView で提案、Lumina-T2X で導入。
- Multimodal RoPE: 位置エンコーディングは Qwen2-VL と少し似た感じです。Lumina2 で導入。
- Refiner: プロンプトと latents に対して個別に Refiner を通ります。中身はそれぞれ 2 層の Transformer ブロックで、プロンプト側には AdaRMSNormZero は使われていません。
他にもいろいろあるので個人的に気になったものを見ていきます
AdaRMSNormZero, tanh gate, Sandwich Normalization
以下のように使われています:
ここで、dim は 2304 なので常に 1024 が使われます。この 1024 は adaLN の入力となるタイムステップ埋め込みの次元です。
adaLN_modulation を通ると Multi-Head Attention (mha) と MLP (mlp) 用の scale と shift、計 4 つの値が得られます。(このため、出力次元は 4 * dim)
したがって、adaLN_modulation は 1024 次元の入力を受け取り、4 * 2304 = 9216 次元の出力を返すことになります。
AdaRMSNormZero は 一般的な AdaLayerNorm(-Zero) のように、scale は Attention や MLP の前にかけられますが、shift はありません。残差接続で足されるときに gate が掛けられます。このとき、gate や scale がゼロで初期化され、学習初期は恒等関数になります。なので名前に Zero が付いています。
また、gate_msa と gate_mlp は tanh() されているのがわかります。これによって、gate の値が爆発せず -1 から 1 の範囲に収まるので、残差と同じようなスケールで足し合わせることになります。Sandwich Normalization と tanh gate によって各層でのアクティベーションの大きさが安定して学習が安定するらしいです。
これらは Lumina-T2X の NextDiT で導入されました。
NextDiT の norm_final 層について
公式実装には NextDiT に norm_final という名前の RMSNorm がついています。
しかし、この層は一度も使われていません。一方で公式のモデルウェイトや Neta Lumina のウェイトにも含まれているので、そのまま load_state_dict で読みたい場合はそのままにしておくといいと思います。
もしかしたら分散学習などで使われてない層があるとエラーになるかもしれませんが、その時は多分この層のせいなのでよしなにしてください。
SwiGLU
FeedForward では SwiGLU が使われていると思います。公式実装では以下のようになっています。
レイヤー名がややこしいですがやってる処理としては、
x_{\text{SwiGLU}} = \text{Swish}(x_{in} W_1) * x_{in} W_3
\\
x_{out} = x_{\text{SwiGLU}} W_2
になってて、SwiGLU の定義は
\text{SwiGLU}(x, W, V, b, c) = \text{Swish}(x W + b) * (x V + c)
らしいので、バイアスのない SwiGLU だと思います。
これは Lumina-T2I で導入されたようです。
Multimodal RoPE
Lumina2 で導入されました。Qwen2-VL の M-RoPE だと論文中で言ってるんですが、完全に同じことをやってるわけではないです。

Qwen2-VL の M-RoPE についての図
M-RoPE では、(フレームとテキスト, 縦, 横) 3次元の位置インデックスを使います (左上原点)。Qwen2-VL では動画も扱うので、その際の1フレームをテキストの1トークン分の位置と同等に扱っているみたいです。
テキストトークンのインデックスには縦横が存在しないんですが、1次元目と同じ値を使っているので対角線に並べてくイメージに近いと思います(図の右側のイメージ)。しかし、Lumina2 ではこの部分の仕様は採用しておらず、テキストでは1次元目のみを使って2次元目と3次元目はゼロのままにしています。Flux に少し近いです。

Lumina2 の RoPE 位置インデックスのイメージ図
Flux と異なり、画像パッチの 1 次元目はプロンプトの最後の位置インデックス+1を使います。つまり、プロンプトの長さと同じ値であり、また、プロンプトにおける次の単語の位置にあたります。Flux では画像パッチの位置インデックスの一次元目は全てゼロでした。参考:
コンテキストのパディング
今までは CLIP や T5 が多かったので、77 トークンや 256, 512 トークンで決まっているものが多かったですが、Lumina2 ではテキストエンコーダーが Gemma2 になり可変長のプロンプトを扱えるようになったので、プロンプトの長さが固定ではなくなりました。
それによって、学習時や推論時にキャプションの長さが異なるとテンソルのサイズが異なり、バッチ処理をする際に困ることになります。そのため、実際にはパディングを行なってサイズを揃えて、Attention する際にはパディングした部分を無視するようにマスクを設定することで対応することになります。
それでも RoPE の位置インデックスはデータごとに異なってしまうのでループ処理で個別に割り当てることになります。位置インデックスの1次元目だけ取り出すとこんな感じになります。
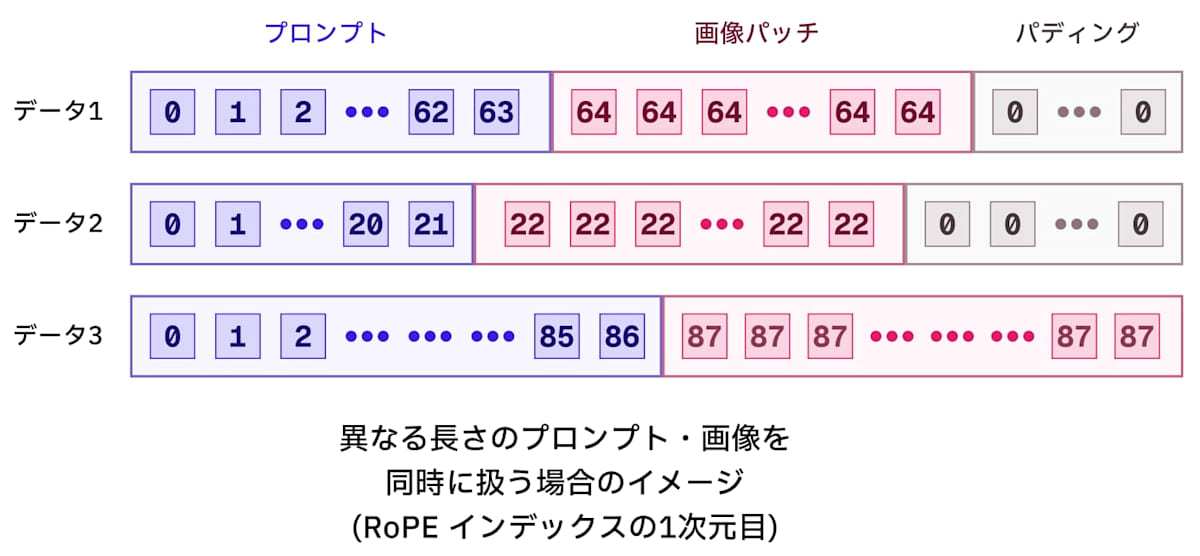
パディングする際の位置インデックスのイメージ
データごとに位置インデックスを計算してパディング付きでスタックしたり、先に一番長くなるシーケンス長を計算して、そのあとでインデックスIDをスライスで入れるなどの方法で解決します。
プロンプトの長さを変えられるなら、画像のサイズも変えられるのでは?と思うかもしれません。実際、可能ですが、VAE のエンコード・デコードやパッチング処理など、画像の2次元的な操作で for ループが発生することになり、特に学習時にはあまり現実的ではないです。異なるサイズのテンソルを扱える NestedTensor もありますが、現状対応している処理が少ないので、結局 for ループが結構発生します。CFG などのシンプルな処理では若干利用できます。
実際に実装してみた ものもありますが、動作はするものの for ループやパディング処理がいっぱい挟まってややこしいことになっています。
なので、学習時はまだ Aspect Ratio Bucketing と仲良くしないといけないようですね。
Refiner
Refiner と聞くと SDXL の Refiner モデルような個別のモデルを連想しますが、ここではそういうのではなく、単にレイヤーです。
本体の Single-Stream Block を通る前に、プロンプトと画像 latent はそれぞれ個別の Refiner を通ります。refiner は Single-Stream Block で使われる Transformer ブロックと同じブロックを 2 層で構成されています。
ただし、プロンプト側の Refiner は AdaRMSNormZero を使わない Transformer で、latent 側の Refiner は AdaRMSNormZero を使う Transformer になっています。AdaRMSNormZero 使う、というのはつまりタイムステップ入力を使うという意味であり、これを使わないプロンプト Refiner はタイムステップに依存しないということでもあります。
そのため、推論時には refine されたプロンプト特徴ははキャッシュすることで、2ステップ目以降で計算を若干省略することができます。
Single-Stream Block
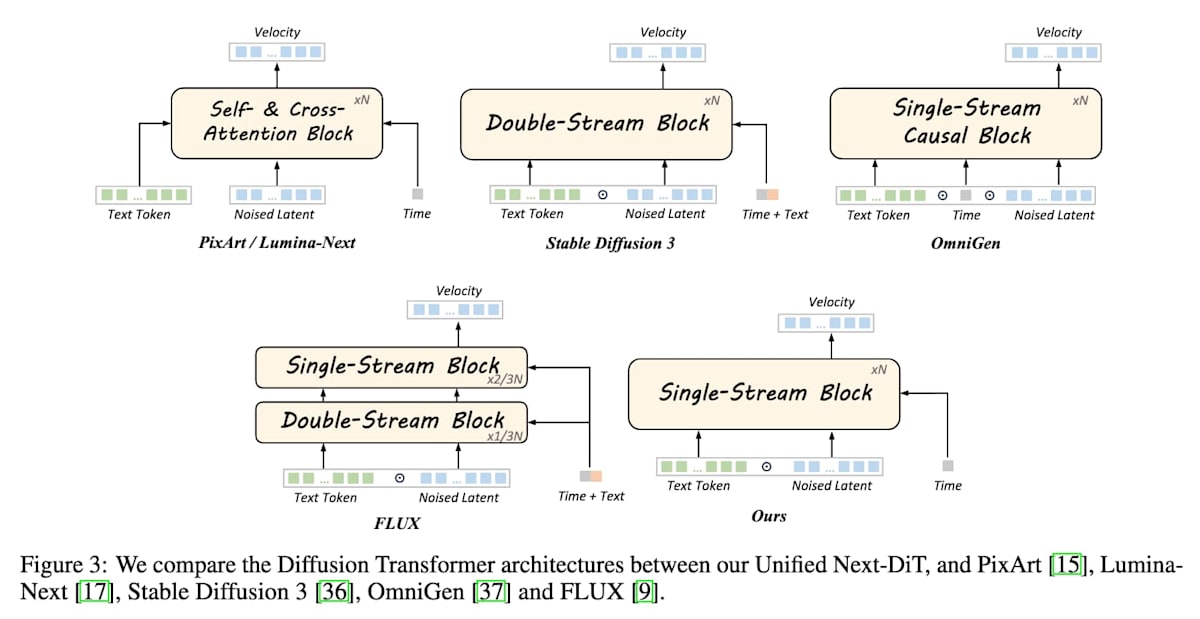
Refiner を通った後はシンプルで、シーケンスでがっちゃんこして Single Stream な DiT を通ります。Flux の Double-Stream Block がない版みたいな感じです。
CFG Renormalization
推論時、画像を生成する際には CFG (Classifier-Free Guidance) するのが一般的ですが、この際に画像の色が飽和したり、バキバキになることがよくあります。
そこで、CFG する際に、CFG しない場合とノルムのスケールを合わせるように正規化する処理を追加することでこれを抑えることができます。要は値がデカすぎないように補正する感じです。イメージとしては大体こんな処理です:
CFG Renorm のイメージ
positive: ポジティブプロンプトでの予測
negative: ネガティブプロンプトでの予測
cfg_scale: CFG スケール
new_velocity = negative + cfg_scale * (positive - negative)
positive_norm = torch.norm(positive, dim=-1, keepdim=True)
new_norm = torch.norm(new_velocity, dim=-1, keepdim=True)
new_velocity = new_velocity * (positive_norm / new_norm)
STIV: Scalable Text and Image Conditioned Video Generation で提案されたそうです。これは Lumina2 以外の SDXL 等でも応用できるかもしれません。試してないのでわかりません。
ちなみに、ComfyUI で使う場合は model を RenormCFG ノードに通すことで使用できます。Neta Lumina の公式ワークフローには含まれていなかったのですが、入れると色の飽和を抑えられるので試してみてください。
タイムステップのサンプリング
- 学習時: Flux と同じ。ただし解像度は 1024×1024 面積固定として扱う
- 推論時: shift 6.0
Lumina2 では学習時のタイムステップのサンプリングに、Flux と同じ処理を行なっています。一方で、推論時は shift のみを行なっています。
この issue コメントによると、
- 学習はタイムステップのサンプリングで対照実験する資源がないので、Flux と同じ設定で行った
- 推論時のサンプリングを学習時に合わせないといけない理論的な理由がない
- 手動で試したところ、shift 6.0 がいい感じだった
らしいです。
Neta Lumina
Neta Lumina は Neta Art から公開された Lumina2 ベースのイラスト生成モデルです。従来の danbooru タグに加えて、自然言語の英語、中国語、日本語での生成に対応しているのがウリです。
学習についての詳細は公式のレポートを参照してください。
量子化してみた
以前 CogView4 を量子化してみたのと雰囲気で Neta Lumina も量子化してみました。
今回は bitsandbytes の NF4 で特に問題が発生しなかったので他は試してません。
モデルサイズは約 10 GB から約 3.7 GB くらいになりました。
| bf16 | テキストエンコーダー&デノイザー NF4 |
|---|---|
 |
 |
あんまり劣化せずに量子化できたので少し意外でした。IllustriousXL 2.0 は量子化するとガビガビになるので、Neta Lumina はまだ学習の余地があるのか、モデル構造的に量子化耐性があるのか、IllustriousXL 2.0 が不安定すぎたのかもしれません。
NF4 量子化すると、1024×1024 解像度の画像を約 10 GB 前後の VRAM で生成できました(オフロードあり)。モデルパラメータの割に VRAM を食うのは、多分 Self Attention でシーケンス長が長くなるからかなと思います。これは全てを Self Attention する DiT 系の宿命ですね。
まとめ、感想
必要なテキストエンコーダーやモジュールの種類が減ってシンプルになったものの、マスクやパディングの扱いが依然としてややこしいです。一度コード書いてしまえば特に苦しくはないですが…
個人的な感想としては、Neta Lumina の LoRA 学習が全くうまくいかなかったので誰か成功させて欲しいです。あと、Gemma みたいな LLM をテキストエンコーダーを使うの、ちょっと挙動が信頼できないからやめた方がいい気がしています。しかもインストラクションモデルじゃなくて事前学習版なので、本当にプロンプトのインストラクションプレフィックスが効いているのかよくわからないし、挙動が信頼できない気がします。最近だと T5Gemma とか、SigLIP2 だったり(CLIPと違ってトークン数の制限がない)、せめて画像に連携しやすい VLM モデルがテキストエンコーダーの方が、下流での調整や応用が効きやすいんじゃないかと思いました。最近の Qwen-Image はまさにテキストエンコーダーが Qwen2.5 VL なので、良い選択だと思いました。
家庭の GPU でファインチューンできるレベルのサイズで、使いやすくて安定してるイラスト生成モデルが欲しいです。
Views: 0

{kind=link}