

前回の記事にて、AIエージェント(LangGraph)を活用した音声ニュース自動生成の取り組みを行いました。その成果をさらに「動画化」する試みとして、GoogleのVeo 2を使った動画生成と、それをLangGraphで生成した音声と組み合わせた動画コンテンツ化をしてみました。
上記の前回記事で詳細は記載していますが、ニュース記事の収集・要約・原稿生成からテキスト音声変換まで、一連の工程をLangGraph上に構築しました。
ニュースのテーマは日替わりで選定可能で、今回は天気や日経平均株価などの日時情報に加えて、政治や論文などの最新ニュースを題材にしています。
また、生成されたニュース原稿は、OpenAI TTS (モデル: tts-1) を使って音声(MP3ファイル)を生成し、DropboxとiPhoneを通して毎朝自動更新・再生するようにしました。
<再掲> mp3ファイルを取得するまでの主な処理の流れ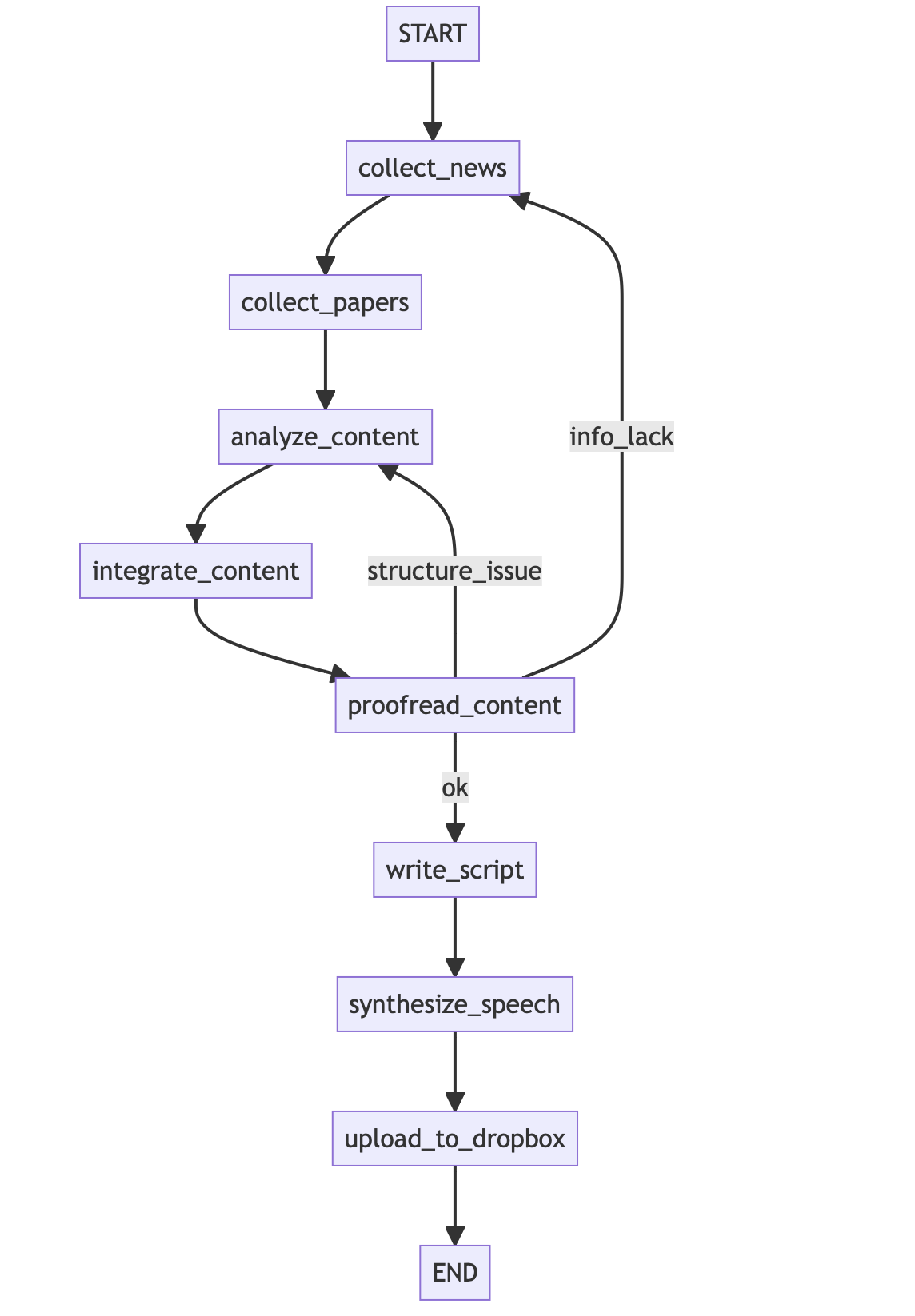
今回は、Google Generative AI (Gemini) SDK を使用して、静止画から動画を生成します。
まずニュース内容に関連するローカル画像ファイルを1枚用意し、サイズが小さい場合は拡大しました。この画像を入力としてVeo 2に動画生成をリクエストします。
SDKの genai.Client を利用し、モデル名 “veo-2.0-generate-001″(Veo 2)に対してプロンプトと先の画像を与えることで、短い動画クリップを生成できます。
内部的にはGoogleの大規模画像生成モデル Imagen 系列と同様に、与えた画像とテキストの文脈に合った映像を生成してくれるイメージです。生成結果の動画クリップは1本あたり数十MBのMP4動画として取得できました。
以下は実際のコードの抜粋です。Google提供のPython SDKを利用しており、あらかじめ環境変数に設定したAPIキー(有効なプロジェクトでVeo利用権限を取得済み)を使ってクライアントを初期化しています。
ローカル画像を読み込んで types.Image オブジェクトに格納し、generate_videosメソッドでモデルにリクエストを送ると、動画生成が開始されます(完了まで数分待機)。
video_gen.py
import io
import sys
import time
from PIL import Image
from pathlib import Path
from google import genai
from google.genai import types
IMG_PATH = Path("img.jpg") # 任意のパスに変更
# ...(画像の読み込みと1280x720リサイズ処理)...
# ...(SDK 用 Image オブジェクトを作成)...
client = genai.Client() # APIキーは自動で読み込まれる
image_obj = types.Image(
image_bytes=img_bytes,
mime_type="image/jpg",
)
operation = client.models.generate_videos(
model="veo-2.0-generate-001",
prompt="ニュースの風景として動画を作成してください", # プロンプト例
image=image_obj,
config=types.GenerateVideosConfig(
aspect_ratio="16:9",
number_of_videos=2, # 動画の作成数
),
)
# ...(生成完了までポーリングで待機し、エラー処理)...
# ...(成功/失敗チェック)...
# 動画保存
stem = IMG_PATH.stem
for i, v in enumerate(videos):
out_path = f"{stem}_{i}.mp4"
client.files.download(file=v.video)
v.video.save(out_path)
print(f"✅ 保存完了 → {out_path}")
なお、画像のサイズやプロンプトによっては失敗したりすることが多かったので、この辺りはドキュメント等を参考に調整が必要かと思います。
Veo 2 が出力する動画クリップは現状最大でも約8秒と短いため、ニュース音声の長さ(今回は約1~2分程度)に合わせて映像を調整する必要があります。ここでは MoviePy ライブラリを使い、動画と音声の長さを合わせ込みました。
具体的には、無音のMP4動画クリップを読み込み、音声MP3の長さに対して次の処理を行います:
この調整後、MoviePyで動画クリップに音声を結合し、音声付きのMP4ファイルとして出力します。
loop_and_mix.py
from moviepy import VideoFileClip, AudioFileClip, vfx
# クリップ読み込み
audio_clip = AudioFileClip("news.mp3")
video_clip = VideoFileClip("video.mp4").without_audio() # 無音の動画クリップを読み込む
audio_duration = audio_clip.duration
video_duration = video_clip.duration
# 音声の長さに映像を合わせる(ループまたはカット)
if video_duration audio_duration:
video_clip = video_clip.with_effects([vfx.Loop(duration=audio_duration)])
else:
video_clip = video_clip.subclip(0, audio_duration)
final_clip = video_clip.with_audio(audio_clip)
final_clip.write_videofile("news_video.mp4", codec="libx264", audio_codec="aac")
また、映像の単調さを避けるために、Veo 2で複数パターンの動画を生成しておき(例: 入力画像やプロンプトを少しずつ変えて複数クリップ取得)、それらを結合して一本の動画にすることも試しました。
ここでは、複数のMP4クリップを連結してから音声を合成し、一本化したMP4を出力できます。複数クリップを繋げることで、同じ映像の繰り返しよりも視覚的な変化を持たせることができました。
concat_and_mix.py
from moviepy import VideoFileClip, concatenate_videoclips, AudioFileClip
clips = [VideoFileClip(p).without_audio() for p in sorted(glob("video_*.mp4"))]
concat = concatenate_videoclips(clips, method="compose") # 連結
audio = AudioFileClip("news.mp3")
# 音声より長ければカット(短ければそのまま)
if concat.duration > audio.duration:
concat = concat.subclip(0, audio.duration)
final = concat.with_audio(audio)
final.write_videofile("morning_news_video.mp4",
codec="libx264", audio_codec="aac")
思った以上に簡単に「ニュース動画らしい」コンテンツが生成できて驚きました。まだ工夫の余地はあるものの、内容の質が良いことや自律的に自動化ができるという点が触ってみて勉強になりました。
改めて、AI Agentは設計が重要だということは前回の記事でも記載しましたが、動画に起こす場合は、画像やプロンプトの違いで映像の雰囲気が大きく左右されることから、依然として人間のクリエイティビティや工夫(プロンプトエンジニアリング)が必要だと感じました。
また、「完全自動生成」によってクリエイティブのハードルは大きく下がる一方で、生成物の著作権や利用範囲に関するリテラシーが今まで以上に重要視されると痛感しました。便利になったからこそ、AIが生成したコンテンツを適切に扱う知識と責任が求められると感じます。私自身もこの辺りの勉強を今一度行ってみようと思います。


















Be the first to comment




