
tl;dr
- OpenAI が GPT-5 を発表したよ
- 書きかけだよ!だんだんと更新しているよ!
- ChatGPT では無料プランを含むほとんどのプランで GPT-5 が使えるよ
- ChatGPT 上のモデル選択がシンプルになって GPT-5 / GPT-5 Thinking / GPT-5 Pro の三つになったよ
- API 経由だと gpt-5 / gpt-5-mini / gpt-5-nano / gpt-5-chat-latest が選べるよ
- Codex CLI / Cursor / Windsurf / GitHub Copilot / Cline / Warp からも使えるよ
- 今回の発表は AGI ができたよ!ではなく、安全性とモデル統合がんばったよ!と受け取ると良いよ
- 個人的には期待値低めで見た方が良いと思うよw
発表動画
Introducing GPT-5
その他公開された YouTube 動画
Introducing GPT-5
GPT-5 はコーディング、数学、ライティング、医療、視覚認識などのタスクにおいて過去最高性能のモデル。あらゆるユーザが利用することができ、Plus プランの方はより多く、Pro プランの方は GPT-5 Pro を利用することができます。GPT-5 Pro はより包括的かつ正確な回答を行なう拡張リーズニングバージョン。
ほとんどの質問に答えられるよう、会話内容や質問の複雑さ、ツールの利用可否などに応じてリーズニングをするか否かを切り替えるリアルタイムルーター方式を採用。「〇〇についてよく考えてください」といったような明示的な指示にも従うことができます。ルーティングの使用制限に達すると、各モデルのミニモデルが残りのクエリを処理します。現状はそういった挙動になっていますが、いずれひとつのモデルに統合することを予定しています。
GPT-5 はベンチマーク性能が向上しただけではなく、実際のユーザの実際の質問において役に立つ回答を返すようになった点が重要で、ハルシネーションの軽減や指示追従性の改善、同調するような応答も軽減。ChatGPT の最も使われる用途であるライティング、コーディング、ヘルスケアにおいて性能を向上。
コーディング
コーディングについても大きく性能向上。複雑なフロントエンドのコード生成や、大規模なリポジトリのデバッグが得意。たったひとつのプロンプトから美しいレスポンジブデザインのウェブサイトや、アプリ、ゲームなど直感的でデザイン性高く作ることができます。初期のテストでは、space やタイポグラフィ、white space など(space / white space の違いがわからん)、デザイン観点での理解力、表現力が洗練されたと評価されています。いくつかサンプルが用意されていて、インタラクティブに動くのでよかったら記事を開いてみてください。
クリエイティブ・ライティング
クリエイティブについても GPT-5 は文章作成のコラボレーターとして役に立ってくれます。ざっくりしたアイデアを文学チックでリズミカルな、心に響く魅力的な文章に変換してくれます。決まりきった韻を踏まないようなフォーマットだとしても、高いレベルで表現を維持することができます。レポートやメールはもちろん、メモの作成や編集など、日常的なタスクに用いることが可能です。文章中に GPT-5 / GPT-4o の比較の表があるらしいが、実際にはなにもないw そのうち修正されるでしょう。
ヘルスケア
医療やヘルスケアにも。ユーザが自身の健康について、きちんと情報を得て自律的に意思決定のできるようサポートします。現実世界のシナリオと医師の定義した評価基準を用いたベンチマークである HealthBench において、これまでのあらゆるモデルと比べて高いスコアを達成。従来のモデルの挙動と比較すると、GPT‑5 はより使い手に寄り添った思考のパートナーとして振る舞い、潜在的な懸念を先回りして指摘しつつも、より役に立つであろう回答を得るための質問を問いかけます。それだけでなく、ユーザーの状況や知識レベル、住んでいる地域に応じて応答を細かく調整できるため、かなり広いシーンにおいて安全かつ信頼性の高い情報を提供するのに役立ちます。いうまでもなく ChatGPT は医療の専門家の代替にはなり得ませんが、それでも検査結果の理解を助けたり、診察時間内に適切な質問を行なったり、治療の方針を検討する際のパートナーとしてご活用ください。
モデルの評価
数学やコーディング、視覚認識、ヘルスケア領域における性能をはじめとして、アカデミックな評価ベンチマークはもちろん、人手評価のベンチマークにおいても評価は高い。アメリカの高校生向け数学競技 AIME 2025 で94.6% (ツール未使用)、コーディングタスクを評価する SWE-bench で74.9%、Aider-Polyglot で88%、マルチモーダルの理解のベンチマーク MMMU で84.2%、医療分野では HealthBench Hard で 46.2%。いずれも最高性能。GPT‑5 Pro の拡張リーズニングによって大学院レベルの高度な専門知識問題のベンチマーク GPQA で 88.4%(ツール未使用)を達成。
ベンチマークの結果の図がたくさん記事にありますが、長くなるので私がよく聞くものかつ重要そうなものだけ下記の details の中で引用します。
ベンチマークの結果
よりロバストで信頼性、役に立つモデルの構築
GPT‑5 はこれまでのモデルに比べて、ハルシネーションが大幅に減少。ChatGPT で実際に行われた対話を模したプロンプトでは、GPT‑4o と比べて事実の誤認が 20% 程度少なく、thinking モードでは OpenAI o3 と比べて約 70% 軽減。特に自由記述の問いに対して、信頼度高くリーズニングできるよう改善。下記の論文の評価ベンチマーク LongFact / FActScore で評価。

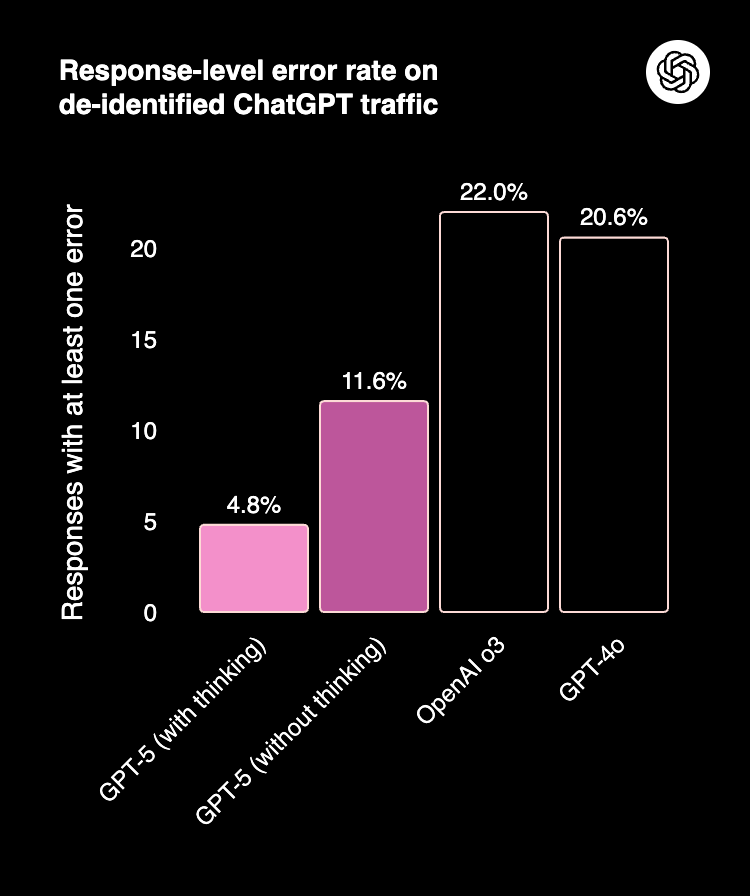
さらに、GPT-5 は自身の状況や能力について正直に伝えるようになりました。具体的には、実行できないタスクや前提条件が不足しているタスク、必要なツールが欠けているなどのタスクにおいて、正確に見定め、限界があるということをユーザに伝えます。下記の指標では OpenAI o3 と比較してかなり抑えられています(低い方が良い)。

安全性
これまでの安全性における学習手法では、ユーザのプロンプトに対して、応答するか拒否するかの二分化されたものしか存在しませんでした。この学習方法はユーザが悪意を持っている時のプロンプトに対しては効果的にはたらくものの、ユーザの意図がわからない時や応答が善悪両方に利用可能な状況においては十分に機能していませんでした。具体的にはウイルス学のような、悪用でき得るが平和的にも利用できるような領域があり、そういった場面で拒否をベースとした学習手法では柔軟性がありません。
そこで GPT-5 では Safety Completions という安全性の学習手法を採用しました。これは、安全の範囲内で可能な限りユーザに役に立つ回答をするよう学習するものです。質問によっては、一部のみの回答に留めたり、抽象度をあげて説明したり、回答拒否の必要な際にはその理由を説明し、安全な代替案を提示するよう学習されています。それにより、相反するような問いへの対応も必要以上に回答拒否せず、仮に意図があいまいだとしても高いロバスト性を示すことができました。
迎合的な表現の軽減と文体の改善
迎合的と仰々しい言葉を使ってしまいましたが、やたらごますりをすることがなくなったという話です。「それは素晴らしいアイデアです!」といったような序文にやたら褒め言葉を入れてくるアレです。GPT-4o と比較してかなり軽減されました。合わせて過剰に絵文字を使うこともなくなりました。これにより、AI と話している感が減り、博士号レベルの知性を備えた友人と会話のように感じられるとのこと。軽度なものは GPT-4o の 18% から 8% 未満に軽減。過度のものは GPT-4o の 14.5% から 6% 未満に軽減。
ChatGPT のカスタマイズ
Custom Instruction への指示追従性が飛躍的に高まりました。合わせてリサーチプレビューとして、四種類のパーソナリティのプリセットが追加。後日追って音声対話モードでも対応を予定。プロンプトを用意せずとも ChatGPT の話し方を切り替えることができます。Cynic / Robot / Listener / Nerd の四つを追加。

生物学的リスクに対するセーフガード
ChatGPT agent と同じように Preparedness Framework のもと、gpt-5-thinking を生物学・化学ドメインにおける High capability として扱うことを決定。現状、生物学的に脅威とされる決定的な根拠はありませんが、予防的なアプローチを取ることを選択。
GPT‑5 Pro
GPT-5 Pro は最も難易度の高いタスクに対応できるモデル。OpenAI o3-pro に代わるモデル。長考しつつパラレルにテストタイムスケーリング、網羅的で質の高い回答を返します。FrontierMath や GPQA といった高難易度のベンチマークでも高性能を叩き出しています。千件を超える実際のリーズニングプロンプトを用いた外部の専門家による評価では、GPT‑5 thinking より GPT‑5 Pro のレスポンスを好む方の割合が 67.8%、重度の誤りも 22% 軽減。医療、科学、数学、コーディングにおいて優れた性能を示しています。
GPT-5 の使い方
ChatGPT のデフォルトモデルは GPT-5 になりました。今後 GPT‑5 が必要に応じてリーズニングし、質問に回答します。また、有料プランであればモデル選択から GPT‑5 Thinking を選んでいただく、あるいは明示的にプロンプトに「よく考えてください」と含めることで、リーズニングを有効化することができます。
誰が使えるか
無料 / Plus / Pro / Team プランのユーザが本日より GPT-5 を使うことができます。Enterprise と Edu プランは一週間後。無料でも使えますが、送信できるメッセージ数が異なります。Pro プランでは GPT-5 を無制限に使うことができ、GPT-5 Pro へのアクセス権も付与されます。無料プランのユーザが GPT-5 の利用制限に達すると、自動的に GPT-5 mini にモデルが切り替わります。GPT-5 mini はリーズニング機能を持つコンパクトで高速かつ高性能なモデルです。
モデルの仕様
API 経由で呼び出す時は gpt-5-2025-08-07。2025 年 8 月 7 日のスナップショット。Context Window は 400k。出力トークンの最大は 128k。ナレッジカットオフは 2024 年 10 月 1 日。リーズニングをサポート。価格は入力 1 Mトークンあたり 1.25 ドル(187.5 円程度)、出力 1 Mトークンあたり 10 ドル(1500 円程度)。キャッシュされた時の入力トークンにかかる料金は 1M トークンあたり 0.125 ドル(18.75 円程度)。テキスト入力と画像入力を受け付け、出力はテキストのみ。Chat Completions API / Responses API / Assistants API / Batch API に対応。ストリーミング出力、Function calling、Structured outputs、ファインチューニング、蒸留、Predicted outputs に対応。ウェブ検索、ファイル検索、画像生成(ツールとしての)、Code interpreter、MCP に対応。レートリミットは一番下に書いてあるので気になる方は見てみてください。
GPT-5 のベストプラクティスや機能、移行ガイドについて
GPT-5 は過去最も知能の高いモデル。コード生成やバグの修正、リファクタリング、指示追従性、ロングコンテキスト、ツールの呼び出しに強み。モデルは gpt-5、gpt-5-mini、gpt-5-nano の三つ。下記のような使い分け。
| モデル | おすすめの使い方 |
|---|---|
| gpt-5 | 複雑なリーズニング、世界中の知識問題、ヘビーな実装、マルチステップを要するエージェンティックタスク |
| gpt-5-mini | 速度、コスト、機能のバランスを保ったリーズニング、チャット |
| gpt-5-nano | 単純な指示や分類などの高いスループットを要するタスク |
モデルがリーズニングをする前にリーズニングに用いるトークン数を制限するリーズニングエフォートパラメータ。これまでのリーズニングモデルでは low / medium / high の三つが用意されていましたが、ここに minimal が追加。TypeScript の例だと下記。reasoning に effort を指定。
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.responses.create({
model: "gpt-5",
input:
"How much gold would it take to coat the Statue of Liberty in a 1mm layer?",
reasoning: {
effort: "minimal",
},
});
console.log(response);
Verbosity(冗長さ)のパラメータも追加。これまでのモデルでは verbosity は medium で指定していたところ、high / medium / low のいずれかとして指定できるようになりました。この値は生成される出力トークンの量を決めるもので、この値を小さくするとレイテンシが減少します。リーズニングと似ていますが、verbosity では回答の質をあげたりさげたりすることができます。
ドキュメントについて詳細に説明をさせたい時、大規模にリファクタリングをしたい時に verbosity を大きくし、簡潔に回答してほしい時、SQL クエリなどの短いコードを生成したい時に verbosity を小さくするようです。
また、カスタムツール機能を追加。
LLM 要約。あとで完全に理解した上で人力で清書する。
カスタムツールでプレーンテキスト入力に対応し、Lark 文法による出力制約も可能。allowed_tools でツールの使用を制限。Responses API で思考連鎖を維持し、リーズニングトークン削減とキャッシュ率向上を実現。o3 からの移行には medium か high、gpt-4.1 からは minimal か low のリーズニング設定を推奨。
GPT-5 システムカード
GPT-5 は、汎用的な質問に答えるスマートで高速なモデル、深く思考するリーズニングモデル、会話の種類や複雑さ、ツールの必要性、あるいは明示的な指示に応じて使用するモデルを決定するリアルタイムルーターを備えた統合システム。
システムカードのラベリングの話。前者の高速、高スループットのモデルを gpt-5-main / gpt-5-main-mini とし、後者の思考モデルを gpt-5-thinking と gpt-5-thinking-mini とラベリングします。API 経由ではそれらの mini / nano バージョンに直接リクエストを投げられるようにしています。ChatGPT 上でパラレルテストタイムコンピュートを用いた gpt-5-thinking へのアクセスも提供、これを gpt-5-thinking-pro と呼んでいます。
GPT-5 のそれぞれのモデルをこれまでのモデルの後継モデルとしてとらえるとわかりやすいようです。
| これまでのモデル | GPT-5 |
|---|---|
| GPT-4o | gpt-5-main |
| GPT-4o-mini | gpt-5-main-mini |
| OpenAI o3 | gpt-5-thinking |
| OpenAI o4-mini | gpt-5-thinking-mini |
| GPT-4.1-nano | gpt-5-thinking-nano |
| OpenAI o3 Pro | gpt-5-thinking-pro |
システムカードで焦点を当てているのは gpt-5-thinking / gpt-5-main。その他のモデルの評価も Appendix に記載。ハルネーションを軽減、指示追従性を改善、同調するような応答も軽減。ChatGPT の最も使われるユースケースであるライティング、コーディング、健康において性能を向上させました。すべての GPT-5 モデルでは、安全性の最新のアプローチである safe-completions を採用。
また、ChatGPT agent と同じように Preparedness Framework のもと、gpt-5-thinking を生物学・化学ドメインにおける High capability として扱うことを決定。現状、生物学的に脅威とされる決定的な根拠はありませんが、予防的なアプローチを取ることを選択。
詳細は PDF ページを参照。
自分用メモ:もし最後に力尽きていなければちゃんと読む
GPT-5 の安全性について
LLM 要約。あとで完全に理解した上で人力で清書する。
OpenAI が GPT-5 で導入した新しい安全訓練手法セーフコンプリーションを発表。従来の拒否ベース訓練は二者択一でありデュアルユース問題に対応困難だったが、セーフコンプリーションは出力の安全性を重視し安全制約下で有用性を最大化。花火点火に関する質問で GPT-5 は詳細指示を拒否しつつ適切な代替案を提供する一方、o3 は完全回答。実験では GPT-5 が o3 より安全かつ有用で、不安全出力の重篤度も低減。この手法は有用性と安全性の両立を実現し今後の安全課題への基盤を構築。
LLM 要約。あとで完全に理解した上で人力で清書する。
OpenAI が2025年8月7日に GPT-5 の安全学習手法として「Safe-Completions」を発表。従来の拒否境界による安全学習に代わり、出力中心の安全学習手法を提案。悪意のあるプロンプトに対して硬拒否するのではなく、安全制約内で可能な限り有用な応答を生成する手法。デュアルユース事例で特に効果的で、完全な拒否と完全な遵守の間で適切な中間応答を生成。安全性を維持しながら有用性を大幅改善し、残存する安全失敗の重大度も軽減することを実証。
GPT-5 のビジネス活用
ビジネス文脈の話。カリフォルニア州立大学、Figma、モルガンスタンレー、ソフトバンク、T-Mobile などの総勢 500 万人以上のユーザが ChatGPT を業務に利用。感想が届いています。
動画ではビジネスにどう使うか。顧客フィードバックの分析からプロトタイピングまでを実演。まとまっていないデータを分析、トレンドやテーマを抽出、チャートとランキングを作成。プロダクトの要件定義書やユーザーストーリーを作成。
開発者向け GPT-5
LLM 要約。あとで完全に理解した上で人力で清書する。
OpenAI が GPT-5 を API プラットフォームで公開。コーディングとエージェンティック タスクに最適化され、SWE-bench Verified で 74.9%、Aider polyglot で 88%を記録。3 つのサイズ gpt-5、gpt-5-mini、gpt-5-nano で提供し、新機能として verbosity パラメータ、minimal リーズニングエフォート、プリアンブルメッセージ、カスタムツールを追加。フロントエンド開発で o3 を 70%上回り、τ2-bench telecom で 96.7%達成。入力 272,000 トークン、出力 128,000 トークンをサポート。料金は gpt-5 が入力 1.25 ドル/1M トークン、出力 10 ドル/1M トークン。
価格
| MODEL | INPUT | CACHED INPUT | OUTPUT |
|---|---|---|---|
| gpt-5 | $1.25 | $0.125 | $10.00 |
| gpt-5-mini | $0.25 | $0.025 | $2.00 |
| gpt-5-nano | $0.05 | $0.005 | $0.40 |
| gpt-5-chat-latest | $1.25 | $0.125 | $10.00 |
| gpt-4.1 | $2.00 | $0.50 | $8.00 |
| gpt-4.1-mini | $0.40 | $0.10 | $1.60 |
| gpt-4.1-nano | $0.10 | $0.025 | $0.40 |
| gpt-4o | $2.50 | $1.25 | $10.00 |
| gpt-4o-mini | $0.15 | $0.075 | $0.60 |
| o3-pro | $20.00 | – | $80.00 |
| o3 | $2.00 | $0.50 | $8.00 |
| o4-mini | $1.10 | $0.275 | $4.40 |
OpenAI Cookbook より
GPT-5 のパラメータとツールの使い方
GPT-5 で使うことのできるパラメータは下記の四つ。
-
Verbosity
-
Free-Form Function Calling
-
Context-Free Grammar (CFG)
-
Minimal Reasoning
LLM 要約。あとで完全に理解した上で人力で清書する。
OpenAI が GPT-5 シリーズの新機能を公開。verbosity パラメータで出力の詳細度を low、medium、high の3段階で制御可能。Free-Form Function Calling により JSON ラップ不要で Python、SQL、shell 環境に直接テキストを送信。Context-Free Grammar により Lark や Regex 構文で出力を厳密に制約し、プログラミング言語やカスタム形式への適合を保証。対応モデルは gpt-5、gpt-5-mini、gpt-5-nano で Responses API と Chat Completions API で利用可能。
GPT-5 のプロンプティングガイド
LLM 要約。あとで完全に理解した上で人力で清書する。
OpenAI の GPT-5 プロンプティングガイドを公開。新しいフラッグシップモデルはエージェンティック AI タスク、コーディング、推論、操縦性で大幅な向上を実現。エージェンティック積極性制御では低い reasoning_effort 設定や明確な基準定義で効率性改善、高い設定で持続性向上を図る。Tool Preamble でユーザー体験向上、Responses API でリーズニングコンテキスト再利用により性能とコスト効率を改善。フロントエンド開発では Next.js や Tailwind CSS を推奨し、ゼロからワンアプリ生成や既存コードベース適応に対応。Cursor の実用例では簡潔性と詳細コードのバランス調整、矛盾する指示の解決で性能向上を達成。新しい verbosity パラメータで回答長制御、minimal reasoning で低遅延を実現。メタプロンプティング機能により自己改善プロンプト生成も可能。
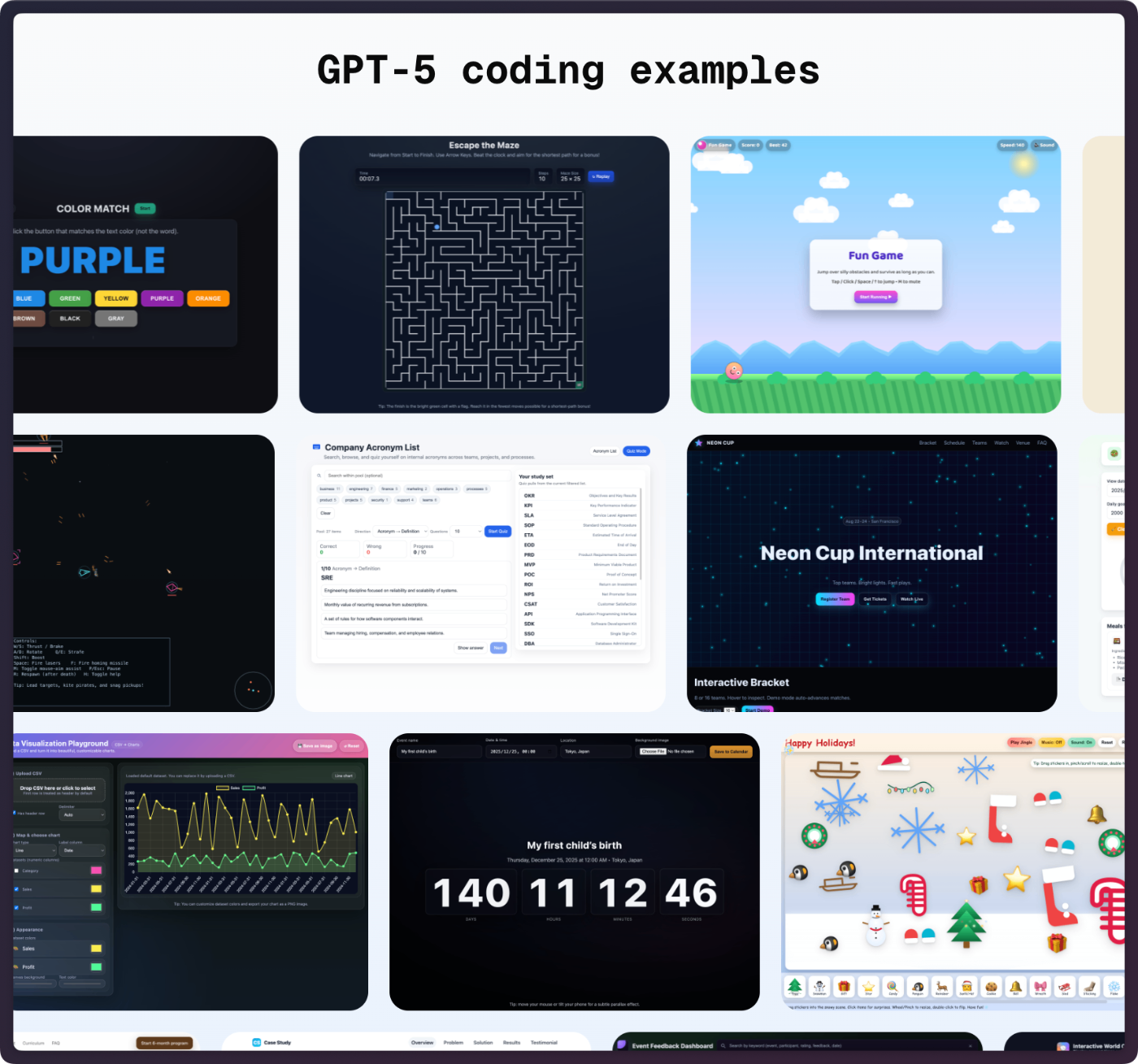
GPT-5 Coding Examples
GPT-5 へのプロンプトによって生成されたデモアプリ集。ウェブサイトやフロントエンドアプリケーション、ゲームアプリケーション、インタラクティブ UI など。上記のリポジトリとデモアプリ集ウェブサイトを公開。同様のプロンプトを用いて自分の環境で作ってみたい場合は、Codex CLI や ChatGPT はもちろんコーディングツールで GPT-5 を指定。README には下記のように Codex CLI で全自動で作成する例が記載されています。
codex --model gpt-5 --full-auto "Build a simple photobooth application with camera access in a single HTML file"
GPT-5 チームの Ask Me Anything
サムアルトマンと GPT-5 チームに質問のできる時間。日本時間で 8 月 9 日(土)の午前 3 時から。GPT-6 について聞かないでねとお断り。
ChatGPT 上で試してみる


もし GPT-5 が現れないよという方はログインし直すか、ブラウザを変えてみると良いかもしれません。私はブラウザを変えてログインすると上記の画面が表示されました。私の手元ではスマホでも GPT-5 が使えるようになりました。
モデルの統合により、選べるモデルはフラグシップモデルの GPT-5 と明示的に考えてほしい時に選ぶ GPT-5 Thinking、研究レベルの知能である GPT-5 Pro の三つだけになりました。
もはやこの手の性能比べに良いプロンプトを持ち合わせていないですが、GPT-4o よりかはかなり自然になったように感じます。

API 経由で試してみる
下記のモデルから選ぶことができました。
- gpt-5
- gpt-5-nano-2025-08-07
- gpt-5-nano
- gpt-5-mini-2025-08-07
- gpt-5-mini
- gpt-5-chat-latest
- gpt-5-2025-08-07
その他対応サービスなど
各社ゼロデイで対応されましたが、私はまだ十分に検証できていません。みなさん使ってみて良い悪い教えてください。
Codex CLI
Codex CLI のデフォルトモデルが GPT-5 に。下記のコマンドでアップデート。UI も一新されています。
Cursor
Cursor の社内チームで 5 人のエンジニアさんが評価、コーディングに効果的と判断。Background Agents を用いた長時間の実行タスクや操作性の高さ、他のモデルが解決できない複雑なバグの解消などにおいて高評価。Cursor の有料プランを契約している方は GPT-5 の無料クレジットが付与されます。GPT-5 が既に使えるようになっていることは手元でも確認できました。
Windsurf
Windsurf にて、GPT-5 が期間限定で無料で使えます。社内の内部評価によると、実コーディングタスクにおいて最高性能。手元でも GPT-5 が使えるようになっていることは確認済み。
GitHub Copilot
リーズニングやコード品質、ユーザー体験が大幅に改善したとのこと。有料の Copilot ユーザに順次展開中。GitHub Copilot Chat、Visual Studio Code の Agent / Ask / Edit モード、GitHub Mobile のチャットモデルの選択から使えます。Copilot Enterprise / Business の管理者は、設定より GPT-5 ポリシーを有効化する必要があるようです。
パッと試すなら GitHub Copilot Chat から。手元でも確認取れました。デフォルトは GPT-4.1 になっていますので、GPT-5 に切り替える際はモデル一覧を開いてください。
Cline
Cline でも。Claude Sonnet 4 の半額程度の価格。
Warp
内部評価によると GPT-5 は技術スタックを跨いだ修正にも優れていたよう。GPT-5 発表の記念に先着五千名まで初月 $5 のプロモコード(通常 $18)を公開。ここには貼りませんが、気になる方は上記のリンクからたどってください。設定から GPT-5 が使えるようになっていることを確認。
おわりに
待ちに待った GPT-5、いかがでしたか。個人的には期待値を高く持っていなかったため、順当な延長線上のアップデートかなという印象を受けました。最高性能という言葉が出てきますが、OpenAI の推しポイントとしては事前に話にあったようにやはりリーズニングモデルの統合であって、リアルタイムルーターシステムという点なのかなと。もうひとつは、安全性について従来の枠組みを脱して、うまく LLM で意図を解釈しながら安全性を保ったという点かな。前者はサムアルトマンは前々から言っていた訳ですし、期待外れという声を見かけますがそれは単に期待値の方向がずれているのかなと思います。
いずれにせよ OpenAI にとっての自信作に間違いはないはずですので、X や記事などでみなさん使い勝手を共有してくださると、良い悪いのユースケースがたくさん出てきて良いのかなと思いますのでぜひ!以上、お読みいただきありがとうございました。
おまけ
※ハルシネーションを含む可能性があります。
Views: 0

{kind=link}