

ソフトウェア
OpenAIはフラッグシップAIモデルとなる「GPT-5」を日本時間の2025年8月8日に発表しました。新しいAIモデルの発表時には、そのAIの性能を示すベンチマーク結果をグラフで視覚化してアピールされるのが常ですが、今回のGPT-5の発表で使われたグラフが明らかに数値と矛盾していたことが判明し、総ツッコミを食らっています。
VIBECHART.NET
https://www.vibechart.net/
たとえば、以下はGPT-5・o3・GPT-4oによるSWE-benchのベンチマーク結果を並べたグラフで、記事作成時点でOpenAIのリリースページで公開されているものです。
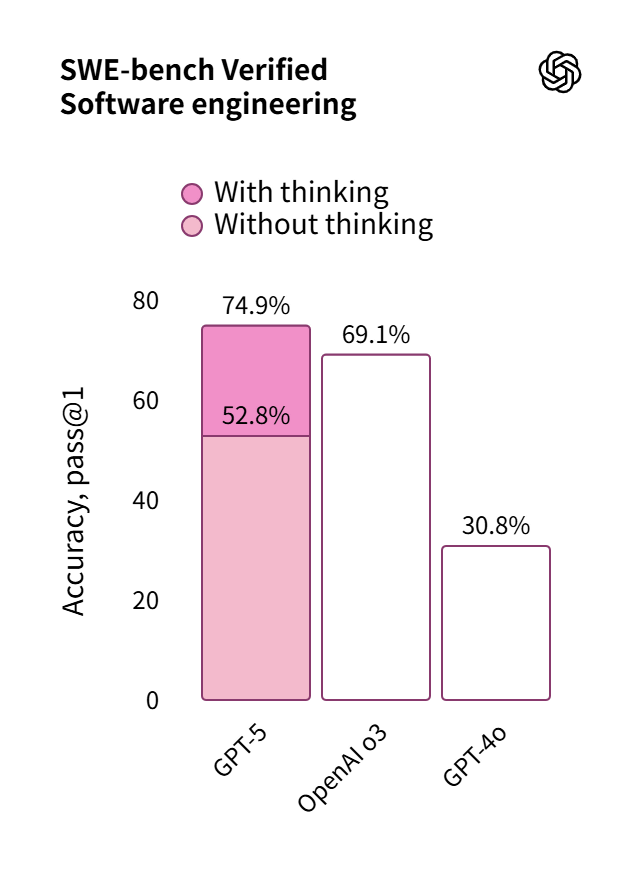
そして発表直後に公開されたベンチマーク結果のグラフがこれ。GPT-5の通常モデル(薄いピンク)が52.8%、推論モデル(濃いピンク)が74.9%という結果に対して、o3が69.1%、GPT-4oが30.8%なのに、なぜか棒グラフでは後者2つの結果が同じ高さで、さらに通常モデルはo3よりも結果が低かったのにもかかわらず、なぜか通常モデルのグラフの方が高くなっています。
GPT-5
The marketing: “It’s like having a team of PhDs in your pocket!”
Also the marketing: This y-axis????♂️❓
#DataViz #ChatGPT
— Tyler Morgan-Wall (@tylermw.com) 2025年8月8日 2:12
さらにGPT-5とo3で実行不可能なタスクに対してどのように応答するかの違いを比較したグラフが以下。モデルが事実でないことを事実のように述べてしまう「欺瞞率」を示しているので、グラフが低ければ低いほど優秀ということになります。正しいグラフはこれ。
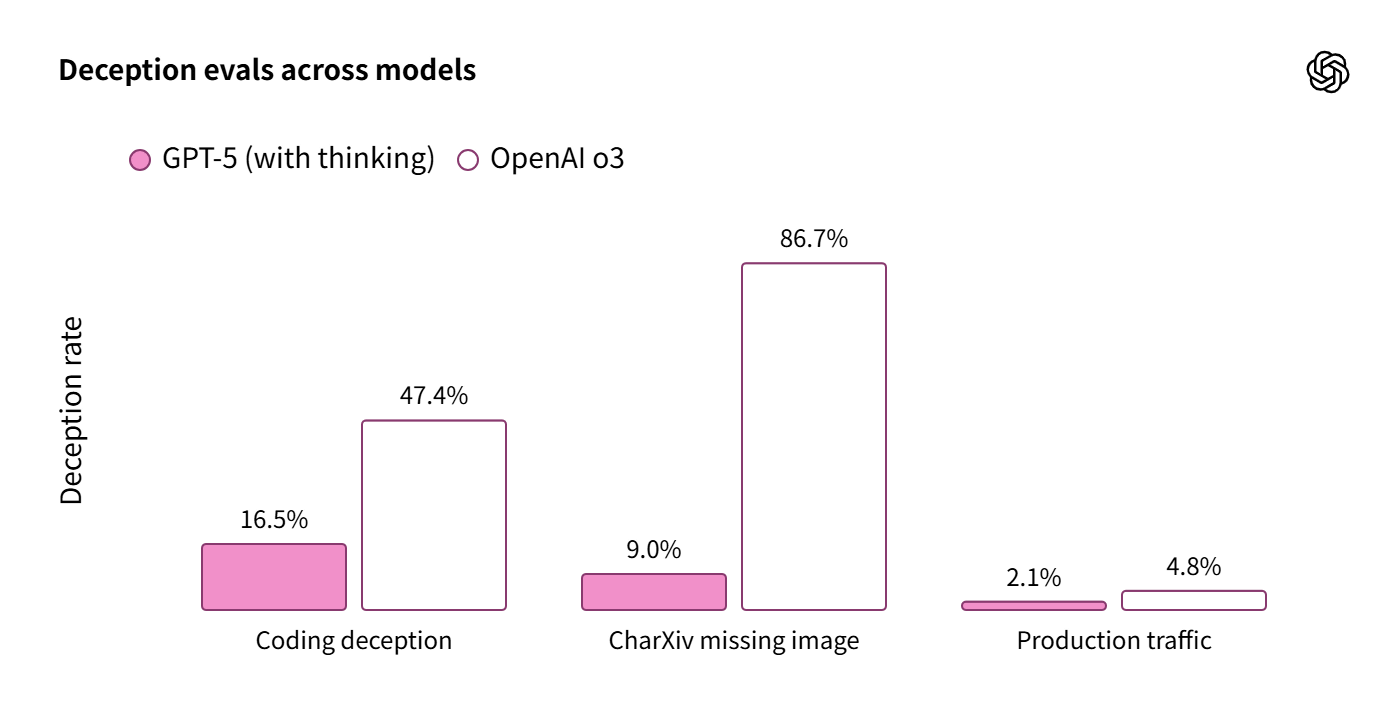
そして、発表直後に公開されたグラフがこれで、OpenAIのGPT-5発表配信でも公開されたもの。明らかにおかしいのが一番左の「Coding deception」で、GPT-5はo3の47.4%よりも低いグラフにもかかわらず、表示されている数字が「50.0%」となっています。
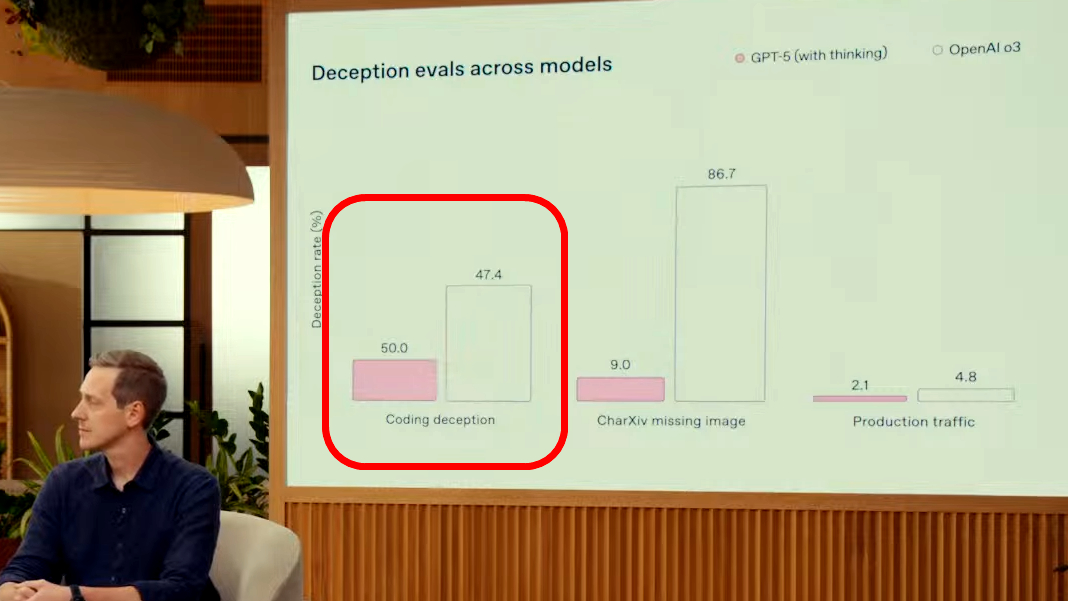
ソーシャルニュースサイトのHacker Newsでは、「なぜあんなにいい加減なのでしょうか?面白くて下手なグラフで拡散したいから?Excel文書のテスト結果を視覚的なグラフに変換するくらいならAIでもできるはずなのに」「OpenAIは間違いなく、ChatGPTに自社のスライドをレビューしてもらうべきでした」「これは単にずさんなだけで、意図的に誤解を招くようなものではないのかもしれません。しかし、数十億ドルもの資金を浪費し、人類のあらゆる活動に革命を起こすと約束している企業が、まともなパワーポイントを作成できないというのは、やはり見栄えが悪いです」などのツッコミコメントがたくさんポストされていました。
この記事のタイトルとURLをコピーする
🧠 編集部の感想:
このニュースは、GPT-5の発表におけるグラフの不具合が大きな話題になったことに驚きました。特に、数値と矛盾したグラフが視覚的に誤解を招いた点が、AI開発企業としての信頼を損ねる要因になったと思います。技術の進歩と企業の透明性が如何に重要か、改めて考えさせられる出来事です。
Views: 0

{kind=link}