
tl;dr
- Google I/O 2025 でたくさんのサービスや機能が発表されたよ
- イベントに合わせて公開されたものはすべてひと通りまとめたよ
- 発表だけでまだ使うことのできないサービスも多いよ(アメリカ限定も多い)
- しばらく追記していくよ
これはなに?
Google I/O 2025 の発表をまとめたもの。開発者向けに限らず、よくばって発表内容をおおよそ網羅した(書きかけのため予定)ので、気になるところだけ読んでください。発表内容が豪勢で、悲しいかな、徹夜をしてしまったので、せっかくなのでみなさんの時短になれば&自分の覚え書きとしてまとめています。少しでも参考になれば幸いです。
こちらに今回の発表に関わる全 27 記事が一覧になっており、それらの中から押さえておくべき記事をかいつまんで簡潔にまとめます。
発表動画(Keynote)について
計約三時間の実況中継。場所はマウンテンビューの Shoreline Amphitheatre、Google I/O 参加のために私は現地に足を運んだことはありませんが、コロナ期以外は例年こちらの会場でやっているようです。X のタイムラインを見ていると現地参加の方をちらほら見かけました。X のタイムラインを観測するに、日本の方々もカリフォルニアにいるかの如く、みなさん夜更かしされていたようです。おつかれさまです。
動画内で触れられたことについてはほぼ本記事でまとめていますが、やはりスマホが自律的に動く様子や帰ってきた Google Glass などはデモを見た方がわかりやすいと思います。ぜひご覧ください。
Google Beam と Google Meet のリアルタイム翻訳について
Google が Project Starline について発表したのは 2021 年の Google I/O。離れていてもそばにいるかのような体験を画面越しに行なう、それが Project Starline でした。今回発表された Google Beam は四年の技術のアプデを開発に取り込んだ AI ファーストのビデオコミュニケーションプラットフォーム。6 台のカメラと AI を用いて、ビデオストリームをマージ、3D ライトフィールドディスプレイでレンダリング。ミリ単位のヘッドトラッキング、60 fps を実現、没入感のある体験を作り出します。HP と提携して、今年の後半に Google Beam デバイスが提供される予定。
また、Google Meet にてリアルタイム音声翻訳ができるように。Google AI Pro / Ultra のサブスク契約をされている方が利用可能。ただし、現状英語とスペイン語間の翻訳のみで、今後数週間で言語の拡充を予定。
Project Astra について
Project Astra は Gemini 2.5 Pro を世界モデルへと拡張、視覚を備え、多言語を使い、感情を認識し、操作のできるユニバーサル AI アシスタントを構築する研究。Project Astra を Gemini アプリに統合、日常的なタスクの実行や管理などを行ないます。
AI Mode について
AI Mode はリーズニングやマルチモーダルを兼ね備えた AI 検索ツール。単なるウェブ検索ではなく、Gemini 2.5 Pro を用いて複数のクエリを同時に実行するクエリファンアウトを用いて、質問やウェブサイトの情報を深く掘り下げます。Deep Search で何百回と検索を実行し、レポーティング、Search Live でカメラを用いたリアルタイム対話ができるよう。ユースケースとしては、Google Pay によるチケット購入や予約などのタスクの実行から、ショッピング体験の向上、検索結果のパーソナライズ、カスタムチャートなど。Google 検索の画面に「AI Mode」が追加されます。登録不要。ただし、現状米国のみ。
Gemini Diffusion について
テキストやコードを高速に生成する拡散言語モデル。ノイズから段階的に出力を洗練する手法を用いて、一度に複数のトークンを生成することで高速化(1479 tps)。LiveCodeBench で 30.9%、BigCodeBench で 45.4%、HumanEval で 89.6%、AIME 2025 で 23.3%。ウェイトリスト登録は下記のリンクから。もしリンクが切れていたら上の記事より辿ってください。
ウェイトリスト登録から数時間後に Gemini Diffusion が使えるようになりました。さすがに拡散言語モデルはレスポンスが速いですね。
Gemini Code Assist について
2 月にプレビュー版を公開していた Gemini Code Assist を正式リリース。VSCode、JetBrains、GitHub 経由で。GitHub 経由だと Install を押して、紐付けたいリポジトリを選ぶだけなのですぐ終わります。
Jules について
Google I/O の直前に公開されていた Gemini 2.5 Pro 搭載の自律型コーディングエージェント Jules。昨日時点ではウェイトリスト登録が必要な方もいたようでしたが、この発表と同時に公開ベータとなり、全世界で使えるようになりました。おそらく今読んでいるあなたも使えるはず。Google Cloud 上の仮想マシン内で閉じ、非同期で作業。テストの作成や機能の実装、バグ修正など。ベータ期間中は無料だが、有料化を予定。
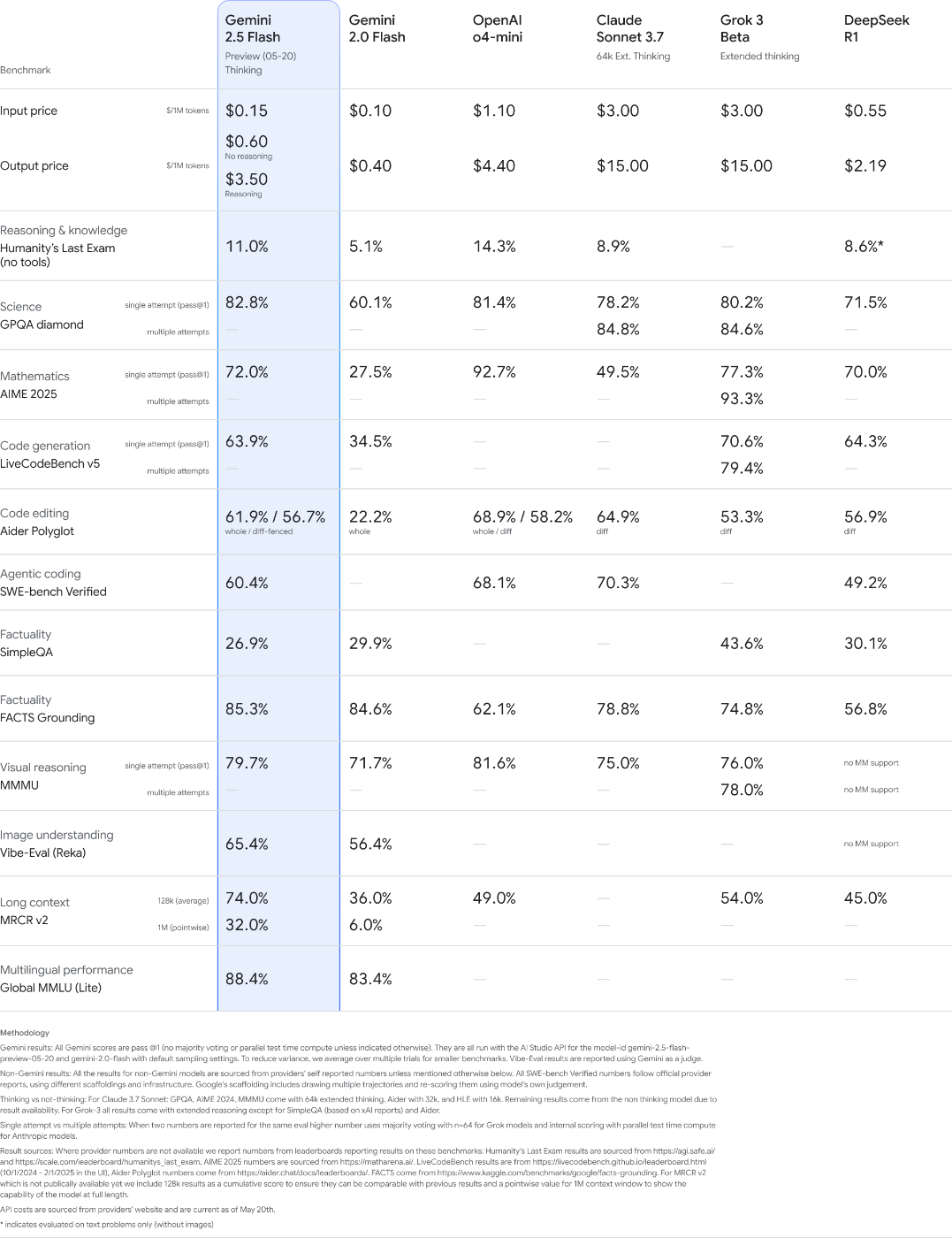
Gemini 2.5 について
みんな大好き Gemini。今回の発表では Gemini 2.5 Pro と Gemini 2.5 Flash のどちらのモデルにも手を加えられました。
Gemini 2.5 Pro では Deep Think という、回答を生成する前に複数の仮説を検討する強化リーズニングモードが試験的に導入。Deep Think を利用した Gemini 2.5 Pro は数学において現状最も難しいベンチマークのひとつである 2025 USAMO で o3 high を差し置いて 2 倍をうわ回るスコアを達成(下記図)、コーディングにおける難易度の高いベンチマーク LiveCodeBench でリード、マルチモーダル性能を測る MMMU で o3 と同等程度のスコアを達成しました。

また、Gemini 2.5 Flash Preview 05-20 が Google AI Studion にて公開。ベンチマーク性能が高いのはもちろん、20-30% のトークン効率化、答えに辿り着くのに必要なトークン数が減りました。
Gemini 2.5 Pro と Gemini 2.5 Flash のいずれのモデルも音声出力に対応。これは次の節にまわします。
最新の LMArena の評価では一位が Gemini-2.5-Pro-Preview-05-06、二位が Gemini-2.5-Flash-Preview-05-20、三位が o3-2025-04-16 です。ベンチマークはベンチマークでしかないものの、英語圏ではどちらも人間の好みにかなり沿っているモデルだと言えるかなと思います。
Gemini の音声出力について
Gemini API はテキスト読み上げに使うことができます。Gemini API がおもしろいのは、指定できる話者はひとりだけではなく、複数人の話者を指定できるところ。スタイルやアクセント、ペース、トーンはすべて自然言語で指示することが可能です。試せてはいないですが、ストリーミングやファイル保存もできるようです。対応言語は 24 言語、声の選択肢は 30 種類。上述のように、対応しているモデルは gemini-2.5-pro-preview-tts と gemini-2.5-flash-preview-tts のふたつ。
公式ドキュメントの Google AI Studio への案内リンクはなぜか機能していなかったため、Google AI Studio の Generate Speech のページから試してみました。もし下記のページが開けなければ、サイドバーより「Generate Media」をクリック、「Gemini speech generation」を開いてください。
声質はいい感じ。ただ、若干ハルシネーション(LLM 単体ではないのでなんと呼ぶかわからないが)によって、テキストをそのまま読み上げてくれないことがあったりするので、ワークフローを組むときはその後の音声を文字起こしして一致しているか評価するなど、少し一手間工夫は必要に思います。その上で、擬似 NotebookLM のように完全自動ポッドキャスト生成なんてことはみなさんなら造作もないですね。
安全性について
Gemini 2.5 Pro の安全性に関するホワイトペーパー。間接的プロンプトインジェクションを仕掛ける場合、悪意あるユーザの指示と通常のユーザの指示を区別できないため、Automated Red-teaming(ART)を実施。単純な攻撃には十分有効ではあるものの、基本的な防御戦略(スポットライティングや自己反省など)は単純な攻撃には有効だが、適応型の攻撃には脆弱であることを発見。対策として、モデルを強固にしたり、入出力のチェックを入れたり、システムレベルのガードレールを組み合わせました。結果として、通常のタスク性能を維持しつつも、攻撃成功率を大幅に低減、Gemini 2.5 を最も安全性の高いモデルとすることができました。
Gemma 3n について
Gemma 3n はモバイル端末向けのオープンウェイトモデル。TPU で 11T を食わせたテキスト、画像、音声、動画のマルチモーダルモデル。入出力はどちらも 32k まで。Gemma 3n E2B と Gemma 3n E4B のふたつのモデルが公開。それぞれパラメータ数は 5B / 8B ではあるが、メモリ使用量は 2GB / 3GB で済むよう。レスポンスは Gemma 3 4B の 1.5 倍。アーキテクチャには MatFormer を採用。手法そのものは 2023 年に公開された下記の論文。未消化なのであとで追記予定。
Google AI Edge と Google AI Studio で利用可。ただし、Hugging Face Hub にあるモデルはテキストと画像のみの入力に限定。
Google AI Studio から動かしてみました。一応動作はするものの、エラーになってレスポンスが返ってこないことが頻繁に発生しました。時間を置いて安定してからもう少し触ってみます。

SynthID Detector について
AI 生成コンテンツにおける透かしの話。SynthID Detector は Google の AI によって生成されたテキスト、画像、音声、動画における透かしを検出。目的は誤情報の阻止。コンテンツをアップロードすると透かしのある部分を特定、検出してくれます。NVIDIA と提携し、一部のサービスに SynthID が埋め込まれている。ウェイトリストの登録は下記のリンクから。入力項目が少ないのですぐに終わります。よろしければ。
Veo 3 と Imagen 4、Flow、Lyria 2 について
Veo 3 は単なる動画生成でなく音声付きの動画を生成してくれます。画像生成モデルの Imagen 4 はクオリティの向上はさながら、文字に対する指示に従うように。これらに Gemini を組み合わせた Flow という AI 映像作成ツールも合わせて発表。カメラコントロールやリファレンス付きの動画生成、アウトペインティング、オブジェクトの追加や削除などの機能も取り入れています。また、Lyria 2 というは音楽制作ツールも公開。これらのすべての出力には透かしがついています。詳しくは SynthID Detector の節を参照。
Flow について
Flow は AI 映像制作ツール。動画生成の Veo 3、画像生成の Imagen、マルチモーダルモデルの Gemini を組み合わせて、自然言語から高品質な物理法則に忠実に従ったリアルな映像を生成できます。自前でアセットを用意するか、あるいは Flow で生成したものをアセットとして使うこともできる。カメラコントロール、シーンの作成、アセット管理、Flow TV など。現在利用できるのは米国のみ。Google AI Pro / Google AI Ultra のサブスクで使えます。
もしアメリカにいらっしゃる方はこちらから。私は日本にいるので残念ながら使えませんでした😭
Flow is not available in your country yet.
代わりに案内されたページはこちら。
Flow で作成された動画がテレビのようにひたすら流れてきます。非現実な動画ばかり流れてくるので見るのはほどほどにしておくことをおすすめします。だんだん頭が痛くなってきます。
AI Agent の構築について
オープンソースのフレームワーク(LangGraph、CrewAI、LlamaIndex、Composio)を用いて、Gemini をベースとした AI エージェントを構築する方法の概要を記した記事。AI エージェント開発に Gemini を推している理由として、リーズニング&プランニングが得意、Function calling、マルチモーダル、コンテキストウィンドウの大きさの四つがあげられています。ちなみに、コンテキストウィンドウは近日 1M から 2M になるよう。これは前々から言っていたと思いますが笑
LiteRT について
LiteRT は以前は TensorFlow Lite と呼ばれていた Google のモバイル端末向けランタイム。モバイル端末で問題になる待機時間、プライバシー、接続の安定性、モデルサイズ、バッテリー消費を解決するために開発されたもの。Android や iOS などのスマホはもちろん、組み込み、マイクロコントローラーなどのクロスプラットフォーム対応。TensorFlow や PyTorch、JAX のモデルを FlatBuffers フォーマット(拡張子は .tflite)に変換したのち推論可能。Java、Kotlin、Swift、Objective-C、C++、Python などに対応。
Google AI Edge について
[追記予定]
Agent 関連のツール、プロトコルについて
Agent Development Kit(ADK)の話。Python ADK v1.0.0 安定版のリリースに加えて、Java ADK v.0.1.0 のリリース。Agent2Agent(A2A)プロトコルが v0.2 に更新。Auth0、Box、Microsoft、SAP、Zoom などの企業との A2A パートナーシップが拡大。
Stitch について
Stitch は自然言語、画像入力から UI デザインとフロントエンドのコードを生成できるツール。Gemini 2.5 Pro のマルチモーダル機能を用いてプロンプトから UI を生成、画像や手書きのスケッチからインターフェースを作成、複数バリエーションを生成、Figma へ貼り付け。
MedGemma について
医療ドメインのマルチモーダルのオープンウェイトモデル。Gemma 3 をベースに 4B の VLM と 27B の LLM の二種類を用意。胸部 X 線他医療ドメインの匿名化されたデータで学習。VLM のイメージエンコーダには SigLIP を採用。Context Length は 128k。ユースケースに応じてファインチューニングあるいはプロンプトエンジニアリング、エージェンティックオーケストレーションなどで出力を調整することが推奨されています。利用には Health AI Developer Foundation の利用規約への同意が必須。Hugging Face Hub 他 Google Cloud Model Garden からも利用できます。
Gemini in Chrome について
Gemini in Chrome は Google Chrome に Gemini が組み込まれたもの。現時点で、インターネット回遊中に今開いているページの情報の解説を頼んだり、要約をしてもらったり。今後、複数タブを横断し、ウェブサイトをナビゲートしてくれるようになるようです。Google AI Pro(月額 $19.99)あるいは Google AI Ultra(月額 $249.99)のサブスク契約している方が対象者ですが、こちらも米国限定です。言語設定が英語になっていないといけないようです。
ブラウザエージェントを用いて人と AI とのインタラクションがどうなるのかについての研究プロジェクトである Project Mariner からスピンオフしたもののよう。こちらはマルチモーダルリーズニングによってウェブのエレメントを解析、解釈し、ユーザの求めるゴールに対してプランニング&実行することを目的としています。
Google AI Ultra について
Google AI Ultra は月額 $249.99 の全部乗せプラン(最初の三ヶ月は半額)。今日発表された Gemini 2.5 Pro の Deep Think や Veo 3、Flow、Project Mariner を始めとして、YouTube Premium やストレージ拡張などもりもりの機能で、Google AI の VIP パスと表現されています。
Flow や Gemini in Chrome を使いたいなら Pro 以上。Project Mariner を使いたいなら Ultra 以上の契約が必要です。ただし、今はまだ米国限定です。

Android XR について
[追記予定]
MCP 対応について
公式ドキュメントの Function calling のページに詳細は書いてありました。
Function calling はモデルを外部ツールや API と接続、通常のテキスト生成をするのではなく、関数を呼び出して実行する機能。OpenAI が初出と認識していますが、Gemini API でももちろん対応。
Model Context Protocol(MCP)についてここで詳しく解説することはいたしませんが、公式ドキュメントの言葉を借りるなら「AI アプリケーションを外部ツールやデータソース、システムに接続するためのオープンスタンダード」です。
MCP サーバーは、Gemini 互換の関数宣言で使用できる JSON スキーマ定義としてツールを公開します。これにより、Gemini モデルで MCP サーバーを直接使用できます。Gemini SDK と mcp SDK でローカル MCP サーバーを使用する方法の例を次に示します。
Python SDK では自動 Function calling 機能も提供され、MCP(Model Context Protocol)との統合も実験的にサポートしている。Gemini 2.0 Flash、1.5 Flash、1.5 Pro で利用可能だが、2.0 Flash-Lite では利用できない。
MCP は、モデルが関数(ツール)、データソース(リソース)、事前定義されたプロンプトなどのコンテキストにアクセスするための共通プロトコルを提供します。MCP サーバーでモデルを使用する場合は、ツール呼び出し機能を使用します。
まとめ
津波のように押し寄せる新しいサービス、デモに圧倒されて、不覚にも寝ることを忘れてしまいました。さすが Google ですね。追記予定となっているところは適宜勉強して埋めていきます。お読みいただきありがとうございました。
Views: 0

{kind=link}