
Googleが主催する『AI エージェント 実践集中コース』に参加して学んだ内容をまとめました。
オンラインを含めると600人超の参加者がしていたとのことです。
Google と Kaggle が提供し世界で 20 万人が登録した「5-Day Gen AI Intensive Course」をわずか 2 日間に凝縮し、これからのソフトウェア開発に求められる AI エージェントの開発スキルと、その基盤となるプロンプト エンジニアリングを実践的に学ぶ短期集中ワークショップです。
効果的なプロンプト設計や AI エージェント開発の基礎から実践までを体験、習得できます。
開催日 :
・Day1:2025 年 6 月 7 日(土)10:00 - 19:00
・Day2:2025 年 6 月 8 日(日)10:00 - 17:00
🟢 Foundational Large Language Models & Text Generation
🟢 Prompt Engineering
🟢 Embeddings & Vector Stores
🟢 Agents
🟢 Agents Companion
🟢 Solving Domain-Specific Problems Using LLMs
🟢 Operationalizing Generative AI on Vertex AI using MLOps
Model & Prompt
- 学習データに近いプロンプトを与えるほどより良い出力が得られる
- modelが変われば強みも変わる
- Flashはcreativity、Proはreasoning
- NotebookLMのモデルでGemini 1.5の方がよりcreativityのある回答をした
- Gemini 2.5だとプロンプトを変えても出力が固定されるという傾向があった
- BeginningとEndにLLMはバイアスを持つので重要なinstructionはここに置く
Parameters

- Q. メールがimportantかnot importantを判定してくださいという指示をする場合、topKは何にすればよい?
- A. 2にする
- topK は、AIが単語を選ぶ際に考慮する選択肢の数を制限するパラメータ
- topK = 2 は**「上位2つの単語だけを候補にしなさい」**という指示になるため。今回で言うとimportantかnot important
- Q. temparatureは?
- A. 0にする
- メールをimportantかnot importantに分類する作業は、創造性が不要なタスク
- temperature = 0 にすることで、AIが「たぶん重要かも」とか「重要っぽい」といった曖昧な表現や、毎回違うニュアンスの回答をすることを防げる
Self-consistency Prompt
複数のreasoning pathsを集計して多数決をとり、1つの出力を得るテクニック
ただし、出力がシンプルでない場合はどうやってsummarizeが難しい
- Q. temparatureは何に設定すれば良い?
- A. close to 1
- reasoning, answerにバリエーションを得るため
Tree of Thought(ToT)

この質問について、3人の異なる専門家が回答していると想像してください。
すべての専門家は、自分の思考の1つのステップを書き留め、
それをグループと共有します。
その後、すべての専門家は次のステップに進みます。以後同様です。
もし専門家の中に、いかなる時点で誤りに気づいた場合は、退場します。
質問は...
Best Practices & Key takesaway
Best Practices
- 具体的かつ明確に指示する (Be Specific and Clear)
- 例を示す (Provide Examples / Few-Shot)
- 「〜するな」ではなく「〜しろ」と伝える (Use Instructions over Constraints)
- 出力フォーマットを試す (Experiment with Output Formats)
- 試行を評価し、記録する (Evaluate & Document Your Attempts)
Key takesaway
- プロンプティングは反復的なプロセスである。
- 完璧なプロンプトは、一度では作れない
- ❌1つの入出力を試してみてうまく行った!→無数の回答を返す。1回の結果で判断しない
- シンプルに始め、必要に応じて複雑にする
- まずは簡単な指示(Zero-Shot)から始め、期待通りの結果が得られなければ、例を追加したり(Few-Shot)、思考のプロセスを指示したり(CoT)と、段階的にプロンプトを複雑にしていく
- 役割、文脈、思考プロセスでモデルを導く
- 実験と記録
- 結果をドキュメンテーションしておくこと!資産化
Googleが提供しているAgentフレームワーク
Agent Development Kit(ADK)とは?
- OSSで提供されているAgent構築フレームワーク
- 素敵な参考記事:
Definition of Agent
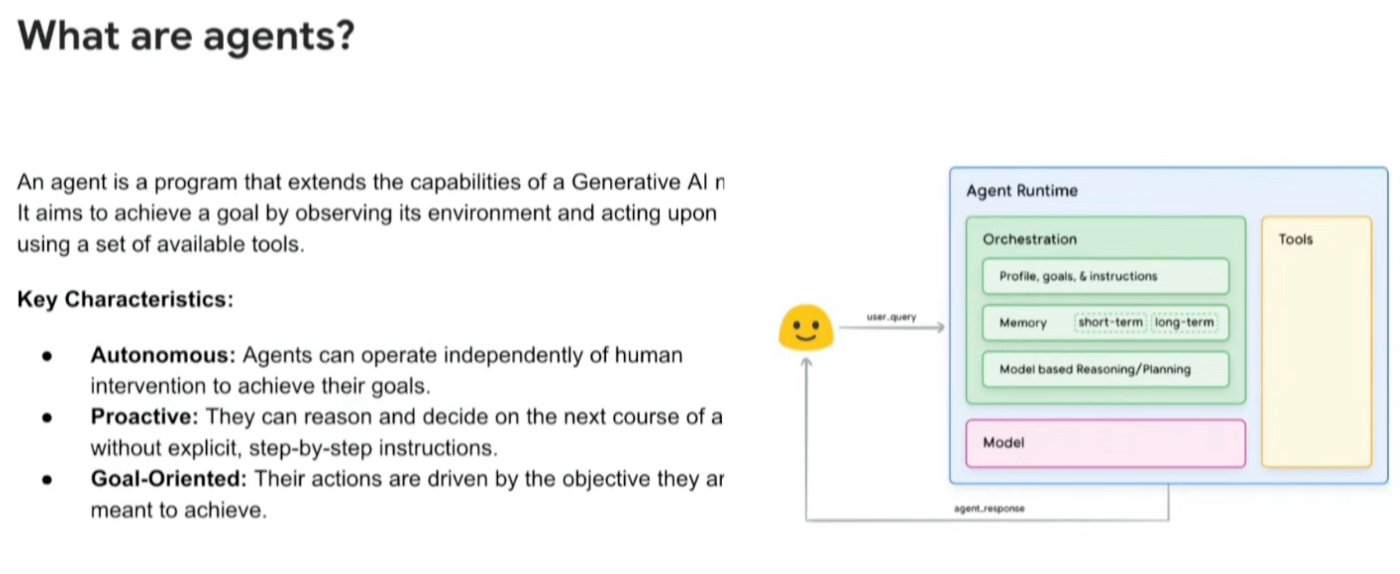
- 人間の介入なしに自律的に動くというのがAgentの重要な定義
- フローチャート的に処理が定義できるようなものはAgentではない(マーケティング上はAgentと謳われているものもある😅)
- semi-autonomousなものはAgentではない
Agent vs. Model
- Model:
- 知識は訓練データ内で利用可能なものに限定される
- ネイティブなツールやネイティブな論理的思考は存在しない(※ユーザーがCoTなどをプロンプトによって指定することで実現する)
- Agent:
- 知識はツールを介して拡張できる
- ネイティブなツールや論理的思考が存在する
Drawbacks of Agent
- 自律的が故に予期しない結果に行き着く可能性がある
- Lower temparetureの場合、自由度が高く誤ったAPIを呼び出しループに陥って目的が達成できない可能性
- Answerに辿り着くまでに大量のtokenを消費する。その上、そのAnswerが間違っている可能性がある
📕 Lab #1: Hands-on Prompt Engineering
Run first prompt
from google import genai
client = genai.Client(api_key=GOOGLE_API_KEY)
response = client.models.generate_content(
model="gemini-2.0-flash",
contents="Explain AI to me like I'm a kid.")
print(response.text)
chat = client.chats.create(model='gemini-2.0-flash', history=[])
response = chat.send_message('Hello! My name is Zlork.')
Temparature
- temperatureは高いと創造性が上がる
- close to 0ほど、出力は固定される
- ユースケースに合わせて設定することが重要
high_temp_config = types.GenerateContentConfig(temperature=2.0)
for _ in range(5):
response = client.models.generate_content(
model='gemini-2.0-flash',
config=high_temp_config,
contents='Pick a random colour... (respond in a single word)')
if response.text:
print(response.text, '-' * 25)
temparature=2.0の時
Magenta
-------------------------
Turquoise
-------------------------
Magenta
-------------------------
Purple
-------------------------
Azure.
-------------------------
temparature=0.0の時
Azure
-------------------------
Azure
-------------------------
Azure
-------------------------
Azure
-------------------------
Azure
-------------------------
Enum Mode
-
response_schemaによって出力のパターンを固定化することができる - 可読性も良いので便利
import enum
class Sentiment(enum.Enum):
POSITIVE = "positive"
NEUTRAL = "neutral"
NEGATIVE = "negative"
response = client.models.generate_content(
model='gemini-2.0-flash',
config=types.GenerateContentConfig(
response_mime_type="text/x.enum",
response_schema=Sentiment
),
contents=zero_shot_prompt)
print(response.text)
Json Mode
-
response_mime_typeにjsonを指定し、response_schemaに想定されるjsonのkeyとvalueのtypeを与えることでjsonモードを実現できる
import typing_extensions as typing
class PizzaOrder(typing.TypedDict):
size: str
ingredients: list[str]
type: str
response = client.models.generate_content(
model='gemini-2.0-flash',
config=types.GenerateContentConfig(
temperature=0.1,
response_mime_type="application/json",
response_schema=PizzaOrder,
),
contents="Can I have a large dessert pizza with apple and chocolate")
print(response.text)
Simple CoT
-
Return the answer directly.をLet's think step by step.に変えただけで正解が導けた - シンプルかつ強力だと思ったので最初に試すのにはいいかも
- ちなみにCoTなしでもモデルによっては正解を導ける(Gemini2.5Pro)ので、CoTを使わなくてもモデル性能で解決できるパターンは多そう
CoTなし
prompt = """When I was 4 years old, my partner was 3 times my age. Now, I
am 20 years old. How old is my partner? Return the answer directly."""
出力
CoTあり
prompt = """When I was 4 years old, my partner was 3 times my age. Now,
I am 20 years old. How old is my partner? Let's think step by step."""
出力
Here's how to solve this problem step-by-step:
Find the age difference: When you were 4, your partner was 3 * 4 = 12 years old.
Calculate the age difference: The age difference between you and your partner is 12 - 4 = 8 years.
Determine the partner's current age: Since the age difference remains constant, your partner is always 8 years older than you. So, now that you are 20, your partner is 20 + 8 = 28 years old.
Therefore, your partner is 28 years old.
Simple ReAct
-
types.GenerateContentConfigにReActの思考フローを定義することで実現 - Labで紹介されたのはinstructionsにコマンドを定義しておく書き方(
model_instructions = """
Solve a question answering task with interleaving Thought, Action, Observation steps. Thought can reason about the current situation,
Observation is understanding relevant information from an Action's output and Action can be one of three types:
(1) entity , which searches the exact entity on Wikipedia and returns the first paragraph if it exists. If not, it
will return some similar entities to search and you can try to search the information from those topics.
(2) keyword , which returns the next sentence containing keyword in the current context. This only does exact matches,
so keep your searches short.
(3) answer , which returns the answer and finishes the task.
"""
example1 = """Question
Musician and satirist Allie Goertz wrote a song about the "The Simpsons" character Milhouse, who Matt Groening named after who?
Thought 1
The question simplifies to "The Simpsons" character Milhouse is named after who. I only need to search Milhouse and find who it is named after.
Action 1
Milhouse
Observation 1
Milhouse Mussolini Van Houten is a recurring character in the Fox animated television series The Simpsons voiced by Pamela Hayden and created by Matt Groening.
# ...
"""
example2 = """..."""
question = """Question
Who was the youngest author listed on the transformers NLP paper?
"""
react_config = types.GenerateContentConfig(
stop_sequences=["\nObservation"],
system_instruction=model_instructions + example1 + example2,
)
react_chat = client.chats.create(
model='gemini-2.0-flash',
config=react_config,
)
resp = react_chat.send_message(question)
print(resp.text)
📕 Lab #2: AI Agent Basics & Function Calling

- sqlite3をimportし、DBからテーブル名を取得したりやSQLクエリを実行する関数を事前に定義しておく。その後関数をfunction callingで呼び出すLabの紹介があった
-
config->toolsの引数に関数のリストを渡すと自律的に関数を実行する - toolsとして呼び出される関数にdocstringで説明を書いておく
- エージェントが関数を呼び出すか否かの判断に使われる
- 他の参加者の方が不要な関数に「毎回必ず呼び出してください」という内容をdocstringに書き込んだところ、毎回呼び出されてしまうということを確認されていました👏💦
def list_tables() -> list[str]:
"""Retrieve the names of all tables in the database."""
db_tools = [list_tables, describe_table, execute_query]
instruction = """You are a helpful chatbot that can interact with an SQL database
for a computer store. You will take the users questions and turn them into SQL
queries using the tools available. Once you have the information you need, you will
answer the user's question using the data returned.
Use list_tables to see what tables are present, describe_table to understand the
schema, and execute_query to issue an SQL SELECT query."""
client = genai.Client(api_key=GOOGLE_API_KEY)
chat = client.chats.create(
model="gemini-2.0-flash",
config=types.GenerateContentConfig(
system_instruction=instruction,
tools=db_tools,
),
)
resp = chat.send_message("What is the cheapest product?")
print(f"\n{resp.text}")
出力
- SQLクエリを自動生成し製品とコストの一覧を見て最安な商品を回答していることが分かる
- DB CALL: execute_query(SELECT ProductName, Price FROM Products ORDER BY Price ASC LIMIT 1;)
- DB CALL: describe_table(Products)
- DB CALL: execute_query(SELECT product_name, price FROM Products ORDER BY price ASC LIMIT 1;)
The cheapest product is the Mouse, which costs $29.99.
A2A
Cost Performance
Agent Evaluation
-
エージェントの評価が重要
- 多数のエージェントを動かしてプロンプト改善→膨大なコストがかかる
- やみくもに改善するのではなく、ゴールに対して良い手法が選べているか
- たとえばカスタマーサポートにエージェントを導入した結果、ユーザー満足度が下がったら意味がない

-
自動評価する仕組みを用意する
- 最終的に評価するのは人だが、人の評価にはコストがかかる上にブレがある
- 最終結果(Final Response)だけではなく、過程(Trajectories)も評価する

-
マルチエージェントシステムの軌跡には複数のエージェントが関与する可能性があるが、ユーザーに返される最終応答は単一であり評価可能
-
マルチエージェントシステムの評価のためには特有の質問も考慮する必要がある。
- エージェントはどの程度うまく連携しているか?
- 正しい計画が作成され、実行されたか?
- タスクに対して適切なエージェントが選択されたか?
- エージェントの追加によってシステム品質と効率は向上するか?
Agentic RAG
- 自律的にquery expansion, multi-step reasoningを行うRAG
- Retrieveをエージェントがよしなにやってくれるため、従来のTraditional RAGの課題(multi-step queryやambiguous query)を解決できる

Q&A
- Agent Granularity
- multi-agentの場合の各agentが担当するタスクについて
- 担当するタスクを細かく設定すれば精度は上がるかもしれない
- しかし、そうするとシステム全体が複雑になるため適切にAgentの粒度は設定した方が良い
What is ADK?
- エージェントを開発するためのOSSフレームワーク
- オーケストレーション層に当たるもの
- 実装がシンプルで学習しやすい
 20250608.png)
20250608.png)
Jules
Jules is an experimental coding agent that helps you fix bugs, add documentation, and build new features. It integrates with GitHub, understands your codebase, and works asynchronously — so you can move on while it handles the task.
📕 Lab #3: Building a Single AI Agent with ADK
※公開は2025/06/08までのようです
google_searchをエージェント内で使用する
ADKが提供するgoogle_searchをimportしてAgentクラスのtoolsに引数として渡す
from google.adk import Agent
from google.adk.tools import google_search
import sys
sys.path.append("..")
from callback_logging import log_query_to_model, log_model_response
root_agent = Agent(
name="google_search_agent",
description="Google検索を使って質問に回答する",
model="gemini-2.0-flash-001",
instruction="あなたは専門の研究者。事実に固執する。",
before_model_callback=log_query_to_model,
after_model_callback=log_model_response,
tools=[google_search]
)
実装したエージェントを呼び出す時
adk run my_google_search_agent

出力形式を指定する
output_schemaで出力形式を指定できる
下記の例は首都をcapitalというkeyに入れて返す例
from pydantic import BaseModel, Field
class CountryCapital(BaseModel):
capital: str = Field(description="A country's capital.")
async def main():
app_name = 'my_agent_app'
user_id_1 = 'user1'
root_agent = Agent(
model=model_name,
name="my_agent",
instruction="Answer questions.",
before_model_callback=log_query_to_model,
after_model_callback=log_model_response,
disallow_transfer_to_parent=True,
disallow_transfer_to_peers=True,
output_schema=CountryCapital,
)
指定する前
** User says: {'parts': [{'text': 'What is the capital of France?'}], 'role': 'user'}
** my_agent: The capital of France is Paris.
指定した後
** User says: {'parts': [{'text': 'What is the capital of France?'}], 'role': 'user'}
** my_agent: {
"capital": "Paris"
}
マルチエージェント
入力された内容の正しさを監査するエージェントを例にマルチエージェントの実装方法を紹介
公式:https://google.github.io/adk-docs/agents/workflow-agents/sequential-agents/#full-example-code-development-pipeline
"""LLM Auditor for verifying & refining LLM-generated answers using the web."""
from google.adk.agents import SequentialAgent
from .sub_agents.critic import critic_agent
from .sub_agents.reviser import reviser_agent
import sys
sys.path.append("..")
from callback_logging import log_query_to_model, log_model_response
llm_auditor = SequentialAgent(
name='llm_auditor',
description=(
'Evaluates LLM-generated answers, verifies actual accuracy using the'
' web, and refines the response to ensure alignment with real-world'
' knowledge.'
),
sub_agents=[critic_agent, reviser_agent],
)
root_agent = llm_auditor
sub agentは通常のAgentクラスを用いて実装する(コードは一部)
critic_agent = Agent(
model='gemini-2.0-flash',
name='critic_agent',
instruction=prompt.CRITIC_PROMPT,
tools=[google_search],
after_model_callback=_render_reference,
)
📕 Lab #4 Building & Evaluating Multi-Agent Systems
※公開は2025/06/08までのようです
マルチエージェントの実践
https://cdn.qwiklabs.com/hc9s%2BOp9Z7JMMXEZLxYoHF%2Bi6Zm1aSaRgjeWOc%2BO7oY%3D
下記は旅行先の提案を行うエージェント
マルチエージェント化はsub_agents引数への指定を行うことで実現できる
attractions_planner = Agent(
name="attractions_planner",
model=model_name,
description="Build a list of attractions to visit in a country.",
instruction="""
- Provide the user options for attractions to visit within their selected country.
""",
before_model_callback=log_query_to_model,
after_model_callback=log_model_response,
)
travel_brainstormer = Agent(
name="travel_brainstormer",
model=model_name,
description="Help a user decide what country to visit.",
instruction="""
Provide a few suggestions of popular countries for travelers.
Help a user identify their primary goals of travel:
adventure, leisure, learning, shopping, or viewing art
Identify countries that would make great destinations
based on their priorities.
""",
before_model_callback=log_query_to_model,
after_model_callback=log_model_response,
)
root_agent = Agent(
name="steering",
model=model_name,
description="Start a user on a travel adventure.",
instruction="""
If they need help deciding, send them to
'travel_brainstormer'.
If they know what country they'd like to visit,
send them to the 'attractions_planner'.
""",
generate_content_config=types.GenerateContentConfig(
temperature=0,
),
sub_agents=[travel_brainstormer, attractions_planner]
)
root_agentにsub_agentsの指定がない場合
steering(root_agent)が即時で返しているのが分かる

root_agentにsub_agentsの指定がある場合
『ユーザーが困っている場合はtravel_brainstormerに渡してください』と言う指示通りに動いていた

エージェントの状態管理
def save_attractions_to_state(
tool_context: ToolContext,
attractions: List[str]
) -> dict[str, str]:
"""Saves the list of attractions to state["attractions"].
Args:
attractions [str]: a list of strings to add to the list of attractions
Returns:
None
"""
existing_attractions = tool_context.state.get("attractions", [])
tool_context.state["attractions"] = existing_attractions + attractions
return {"status": "success"}
attractions_planner = Agent(
name="attractions_planner",
model=model_name,
description="Build a list of attractions to visit in a country.",
instruction="""
- Provide the user options for attractions to visit within their selected country.
- When they reply, use your tool to save their selected attraction
and then provide more possible attractions.
- If they ask to view the list, provide a bulleted list of
{{ attractions? }} and then suggest some more.
""",
before_model_callback=log_query_to_model,
after_model_callback=log_model_response,
tools=[save_attractions_to_state]
)
プロンプトにある下記の部分は動的テンプレートを用いた書き方になっている
{{ attractions? }} の末尾にある?はattractionsというフィールドが状態オブジェクト内に存在しない場合、またはnullやundefinedである場合でもエラーを発生させないようにするために記載している
- If they ask to view the list, provide a bulleted list of
{{ attractions? }} and then suggest some more.
実際の挙動
ユーザーがRyoan-ji Templeが良いねと返すとstateに保存された
エージェントに反復処理させる
通常のAgentクラスではなくLoopAgentクラスを使用する
max_iterationsで最大反復回数を指定可能
from google.adk.agents import LoopAgent
writers_room = LoopAgent(
name="writers_room",
description="Iterates through research and writing to improve a movie plot outline.",
sub_agents=[
researcher,
screenwriter,
critic
],
max_iterations=3,
)
loopから抜けたい場合にexit_loopをtoolとしてあらかじめ指定しておくこともできる
from google.adk.tools import exit_loop
tools=[append_to_state, exit_loop],
If the PLOT_OUTLINE does a good job with these questions, exit the writing loop with your 'exit_loop' tool.
指定した順番でSequentialにエージェントを呼び出す
SequentialAgentクラスを使用する
下記はwriters_room->file_writerの順番で呼び出したい場合の実装方法
from google.adk.agents import SequentialAgent
film_concept_team = SequentialAgent(
name="film_concept_team",
description="Write a film plot outline and save it as a text file.",
sub_agents=[
writers_room,
file_writer
],
)
Views: 2

{kind=link}