

内容は多いため、後でも読むように、ブックマークやストックをお勧めします。
2025年3月31日から4月2日まで、ラスベガスのMGM Grandで開催された Microsoft Fabric Community Conference(FabCon)2025は、データおよびAI分野の専門家にとって非常に重要なイベントとなりました。参加者数は6,200人を超え、前年のラスベガス開催時と比較して50%の増加、ストックホルム開催の2倍の規模となりました。

カンファレンスでは3日間にわたるBreakout Sessionに加え、3月29日〜30日および4月3日にワークショップも開催され、参加者には包括的で実践的な学習機会が提供されました。
FabCon 2025では、220以上のセッションが実施され、Microsoft Fabricの機能紹介をはじめ、Power BIの活用、SQL、AI技術など多岐にわたるトピックがカバーされました。さらに、20のハンズオン・ワークショップでは、分析、データガバナンス、データベース、AI分野において、実践的なスキルを学べる貴重な機会が提供されました。これらのワークショップは、Microsoft Fabricの認定試験の準備にも役立つ内容となっています。
FabConを参加すると、様々なグッズをゲットできますので、ぜひ、皆さんも機会があったら、参加してみてください。
また、ヨーロッパ版のFabConは、2025年9月15日から9月18日までの期間で、Viennaで開催します。
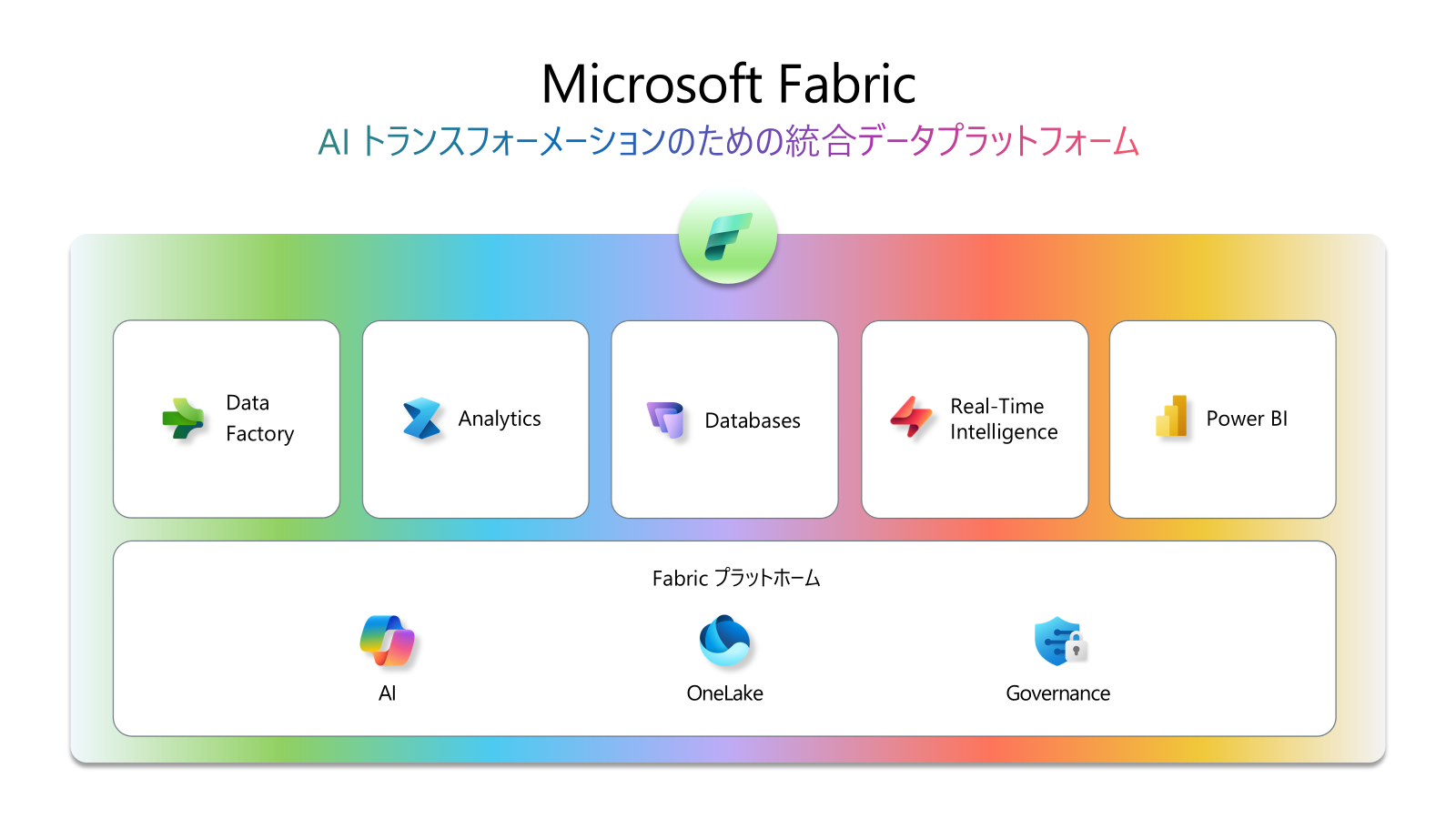
Microsoft Fabric は、次世代のAIトランスフォーメーションを実現するためのエンドツーエンド (E2E) データプラットフォームです。あらゆる種類のデータに対して、ETL、加工、保存、予測、分析、さらにガバナンスとセキュリティ機能を備えています。これらを統一された形式で提供し、Copilot AIも搭載された、オールインワンの一気通貫型の統合データプラットフォームです。OLTP系のDatabaseも含めることになっていますので、データ分析プラットフォームの概念を超えています。
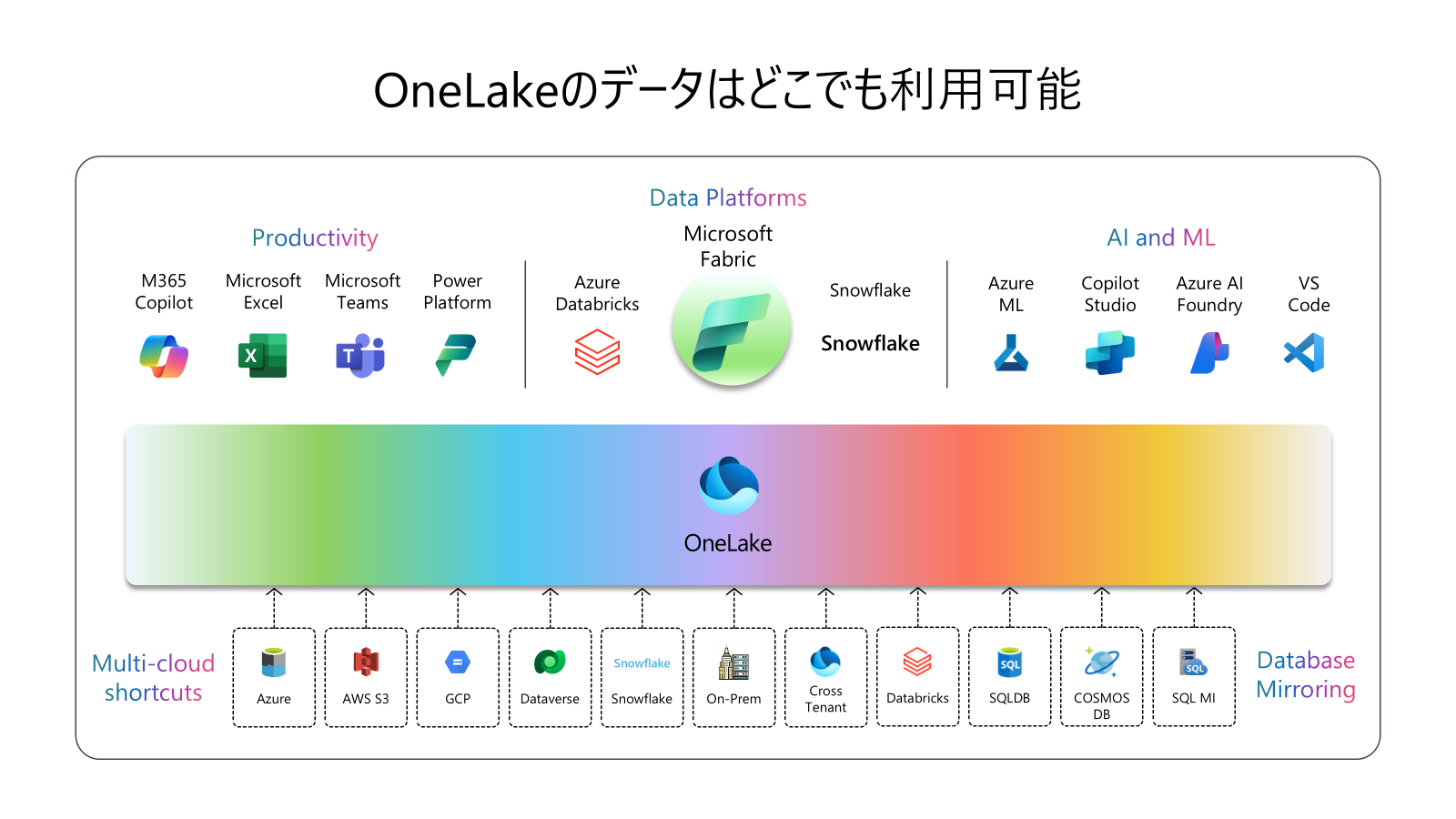
最近、OneLakeに興味をお持ちになるお客様が増えています。
OneLakeはマルチクラウド対応のSaaS型ストレージとも呼ばれており、Microsoft Fabricの一部として提供される、組織全体の分析データを一元管理できる論理データレイクです。
OneLakeは、Microsoft Fabricのテナントに自動的に組み込まれているため、お客様側で追加のインフラ管理を行う必要はありません。M365やPower Platformとの連携はもちろんのこと、DatabricksやSnowflakeなど、他社サービスともオープンフォーマットでスムーズに連携可能です。
さらに、データをOneLakeに物理的にコピーしなくても透過的にアクセスできる「Shortcuts」機能や、データをミラーリングしてニアリアルタイムで同期する「Mirroring」機能も備えています。
そして、2025年5月19日から5月22日には、シアトルでMicrosoft Build 2025が開催されます。本記事では、これら二つのイベントを通して得られるMicrosoft Fabricの最新情報を、皆さまにお届けいたします。
本記事には、すべてのアップデートを網羅しているわけではないため、Power BI や Fabric に関する最新のアップデートを確認するには、下記の5つ方法があります。ご参考ください。そのうちに、MVPお二人のPower BI ReportのURLを紹介させていただきます。

[Microsoft Build 2023]記事:
Microsoft Fabric の概念、それぞれのワークロード、Azure Synapse との違い、ライセンスなどの情報は、下記のURL記事に詳しく記載しておりますので、ぜひ、事前に読んでおくことを強くお勧めします。
https://qiita.com/yangjiayi/items/605d9679e1e35d391a1a
[Microsoft Ignite 2023]記事:
Microsoft Fabric – The unified data platform for the era of AI の GA 記事もあります。下記のURL記事に詳しく記載しておりますので、ぜひ、事前に読んでおくことを強くお勧めします。
https://qiita.com/yangjiayi/items/e264451e5c83c6ac90a7
[Microsoft Build 2024]記事:
Microsoft Build 2024 – Microsoft Fabric What’s new and what’s nextの記事です。下記のURL記事に詳しく記載しておりますので、ぜひ、事前に読んでおくことを強くお勧めします。
https://qiita.com/yangjiayi/items/287bf2d6a2fafee6b3f2
[Microsoft Ignite 2024]記事:
Microsoft Ignite 2024 – Microsoft Fabric What’s new and what’s nextの記事です。下記のURL記事に詳しく記載しておりますので、ぜひ、事前に読んでおくことを強くお勧めします。
https://qiita.com/yangjiayi/items/cb03aa6b8cb79499819a
そのほかに、公式のRoadmapのページもリニュアルされ、ご確認いただけます。
該当記事を投稿する際のステータスなので、パブリックプレビューなどの機能はリージョンのロールアウトの期間もあります。あらかじめにご了承ください。

Platformのアップデートには、AI、OneLake、ガバナンスの内容が含まれています。
プラットフォームアップデート1: サービスプリンシパルのサポートの拡張 (GA)
FabCon Las Vegas 2025では、Microsoft Fabricにおけるサービス プリンシパル (SPN) サポートが大幅に拡張されました。Fabric Data Warehouseでは、SPNによる認証が一般提供され、データウェアハウスのアイテムに対して非対話型で細かいアクセス制御と自動化ワークフローの構築が可能になりました。ノートブックおよびSparkジョブ定義も、FabricジョブスケジューラAPIを通じてSPNのセキュリティ コンテキスト内で実行できるようになり、バッチ処理や定期処理の自動化が容易になりました。Azure Data FactoryのFabric Lakehouse/Data WarehouseコネクタではSPN認証がサポートされ、ユーザーIDを使用せずに安全にデータ取り込みが行えます。さらに、CI/CDデプロイパイプラインではSPN認証が利用可能となり、Deployment Pipelines REST APIを使ったエンドツーエンドの自動展開が実現しました。加えて、Fabric API全般にもSPNサポートが発表され、プログラムによるリソース管理が一層強化されています。
ちなみに、Git プロバイダーとして Azure DevOps を使用する場合の Git API の呼び出しは、まだ開発中であり、今後数か月以内にリリースされる予定です。
プラットフォームアップデート2: Fabric の Terraform プロバイダ (GA)
Microsoft Fabric 用の Terraform プロバイダーは、Fabric ワークスペースや Lakehouse、ノートブック、KQL データベース、ML 実験など多彩なリソースをコード定義できるプラグインです。2024 年 Q3 にパブリック プレビューとしてリリースされ、その後 GA (一般提供) に向けて継続的に機能拡張が行われています。GA 版では、既存プレビュー機能の安定化に加え、Fabric の主要コンポーネント(SQL Database、Eventhouse、KQL データベースなど)をコードで管理可能となりました。Terraform CLI と組み合わせることで、宣言的に Fabric 環境をプロビジョニング・管理でき、CI/CD パイプラインへの組み込みや Service Principal 認証による自動化が可能です。

プラットフォームアップデート3: Fabric Tag (GA)
Microsoft Fabric の Tags 機能は、Fabric アイテム(ワークスペース、Lakehouse、ノートブック、KQL データベース、パイプラインなど)に対して管理者が定義したラベルを付与し、組織内でのカテゴリ分けや検索性を大幅に向上させる仕組みです。2025 年 4 月に一般提供 (GA) され、最大 10,000 種類のタグをテナント単位で定義でき、各アイテムには最大 10 個のタグを割り当て可能です。
プラットフォームアップデート4: Variable Library (パブリックプレビュー)
Microsoft Fabric の Variable Library は、ワークスペース単位で変数を一元管理できる新しいアイテムです。各リリースステージ向けに値のセット (Value Set) を定義でき、パイプラインやノートブックなど複数のアイテムで同じ変数を再利用する「変数のバケツ」として機能します。
Variable Library で定義した変数は、Fabric Data Factory のデータパイプラインだけでなく、ノートブックのデフォルト Lakehouse 設定や、Lakehouse ショートカット、将来的にはあらゆるワークスペース内アイテムで参照可能です。
注意点としては、
- 変数は最大 1,000 個、Value Set も最大 1,000 個まで定義可能です。
- 代替値セット内のセル総数は合計で 10,000 セル以下、アイテム全体は 1 MB 以下に制限されます。
- 現在はプレビュー段階のため、一部 UI 機能や検索反映に遅延がある可能性があります。

プラットフォームアップデート5: User Data Functions (UDF) (パブリックプレビュー)
User Data Functions は、Python 3.11.9 ランタイム上で稼働するサーバレスな関数プラットフォームで、Fabric の各種アイテムや外部アプリケーションから呼び出せるカスタム ロジックをホストします。再利用性の高いビジネス ロジックやデータ処理フローを一元管理し、ノートブックやパイプライン、Power BI レポートからシームレスに利用できる点が最大の特徴です。REST エンドポイント経由で外部システムとも統合でき、Fabric の運用・開発の幅を大きく広げます。
標準で PyPI の公開ライブラリが利用可能で、fabric.functions SDK やブラウザ上のエディタ、VS Code 拡張を通じて編集・デバッグできます。
アイテム所有者のみがコードを変更可能で、User Data Funtions の制限事項ですが、リクエスト合計 4 MB、実行時間 240 秒、レスポンス 30 MB、ログ保持 30 日などがあります。

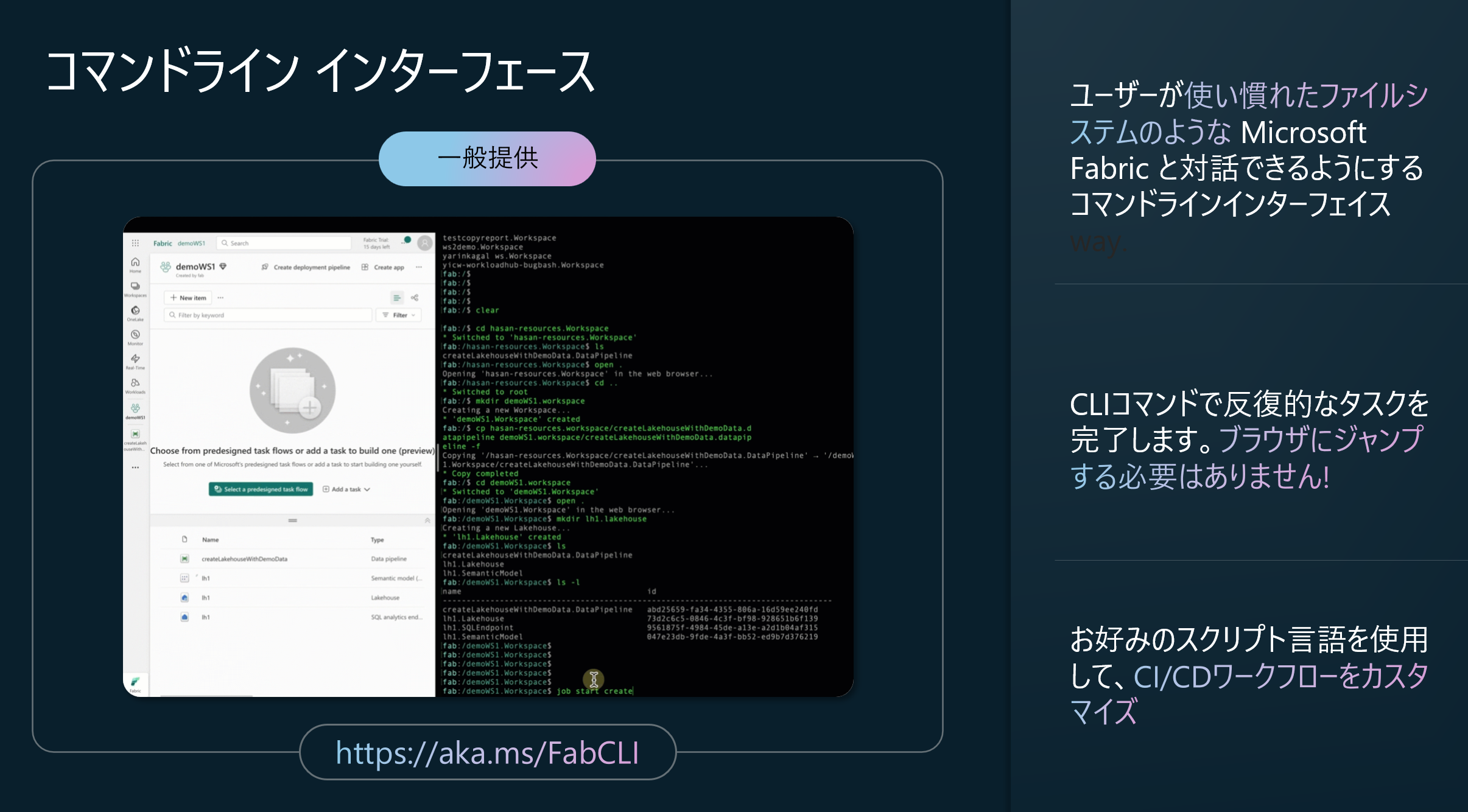
プラットフォームアップデート6: コマンドライン インタフェース CLI (Build 2025: 一般提供)
Fabric CLI は「ファイルシステム風」のコマンド群で Fabric 環境を操作できる開発者向けのツールです。2025年4月22日にプレビュー版が公開され、Fabric ワークスペースの探索・作成・実行・スクリプト自動化がすべてターミナル上で完結します。
ユースケースとしては、開発者なら、ポータルを開かずに CLI だけで新規ワークスペースやリソースを即時プロビジョニングできるようになります。管理者なら、サービス プリンシパル認証でバッチ処理/自動化ジョブを組み込みを作れるようになります。そして、データエンジニアの場合、スクリプトやシェルスクリプト内でパイプライン実行やメタデータ取得を自動化させることも可能です。
プラットフォームアップデート7: Microsoft Fabric と Snowflake 拡張
Fabric の OneLake が Apache Iceberg フォーマットをサポートし、Snowflake と双方向にデータを読み書きできるようになりました。Iceberg/Delta Lake 両フォーマット間の透過的な変換は Apache XTable プロジェクト経由で実現され、Snowflake は OneLake 上のデータを直接参照・更新可能です。
FabCon25では、Arun Ulagaratchagan 氏らが「Fabric と Snowflake の統合拡大」をハイライトしました。従来の提携をさらに推し進め、OneLake 上のデータ連携を更に強化するロードマップが示されました。
そして、2025年1月リリースの Power BI Desktop(v2.139.1576.0)では、新 Snowflake Connector 2.0 をプレビュー提供開始。大容量データセットの読み取り安定性やパフォーマンスが改善され、Power BI Service へのパブリッシュ対応も強化中です。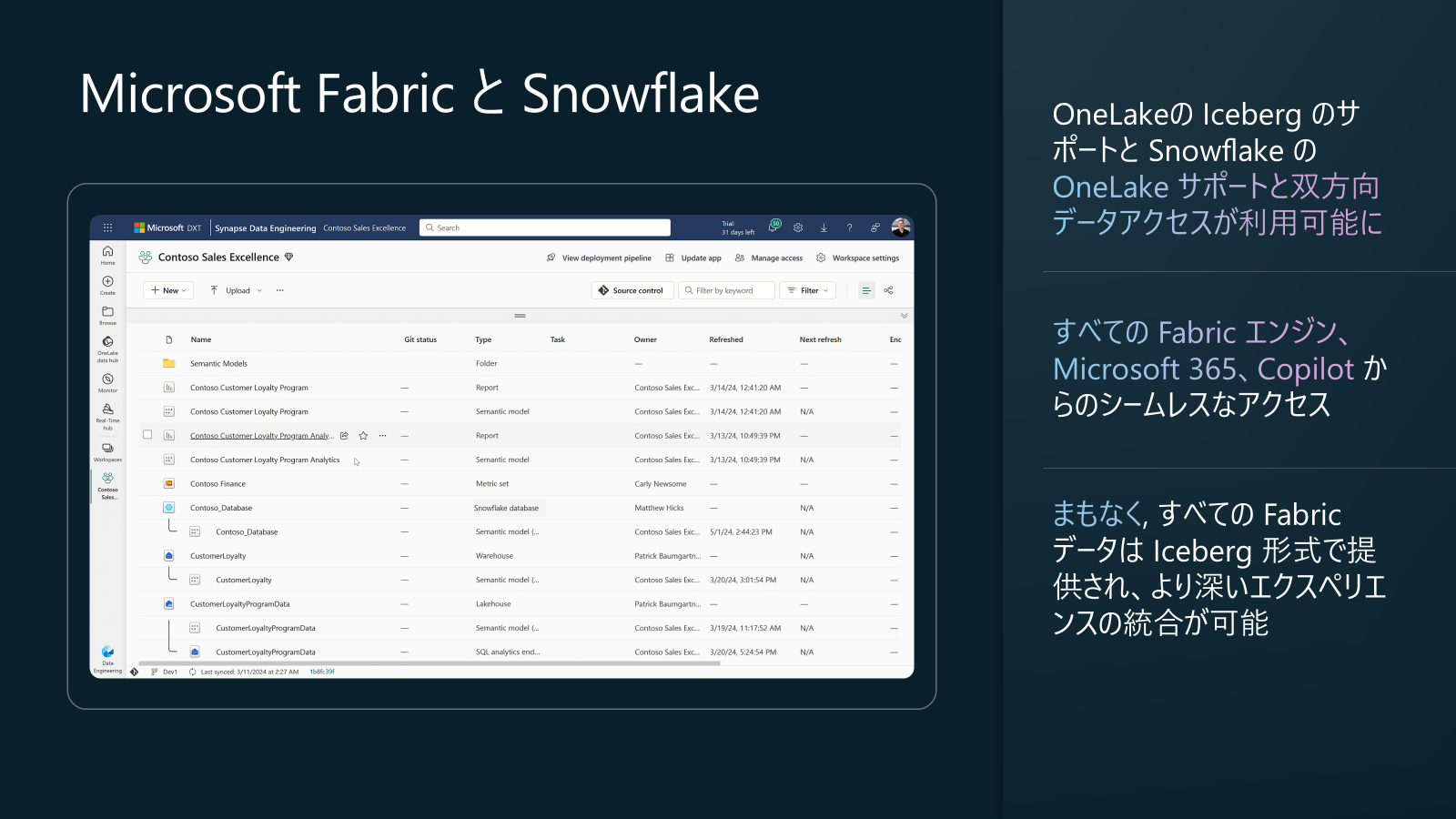
プラットフォームアップデート8: Excel の OneLake Catalog (パブリックプレビュー)
Excel の[データ]タブから直接 OneLake 上のデータ資産を探索・取得できるようになり、ビジネスユーザーは Power BI を使わずともセルフサービス分析が可能になります。つまり、組織の OneLake に格納された Lakehouse、Warehouse、テーブル、ファイルなどを Excel 上で直接検索・プレビュー・インポートできます。現在は Windows 版 Excel のプレビューとして提供されており、将来的な一般提供 (GA) が予定されています。
記事の現時点では、Mac 版 Excel や Web Excel では未対応ですので、要注意です。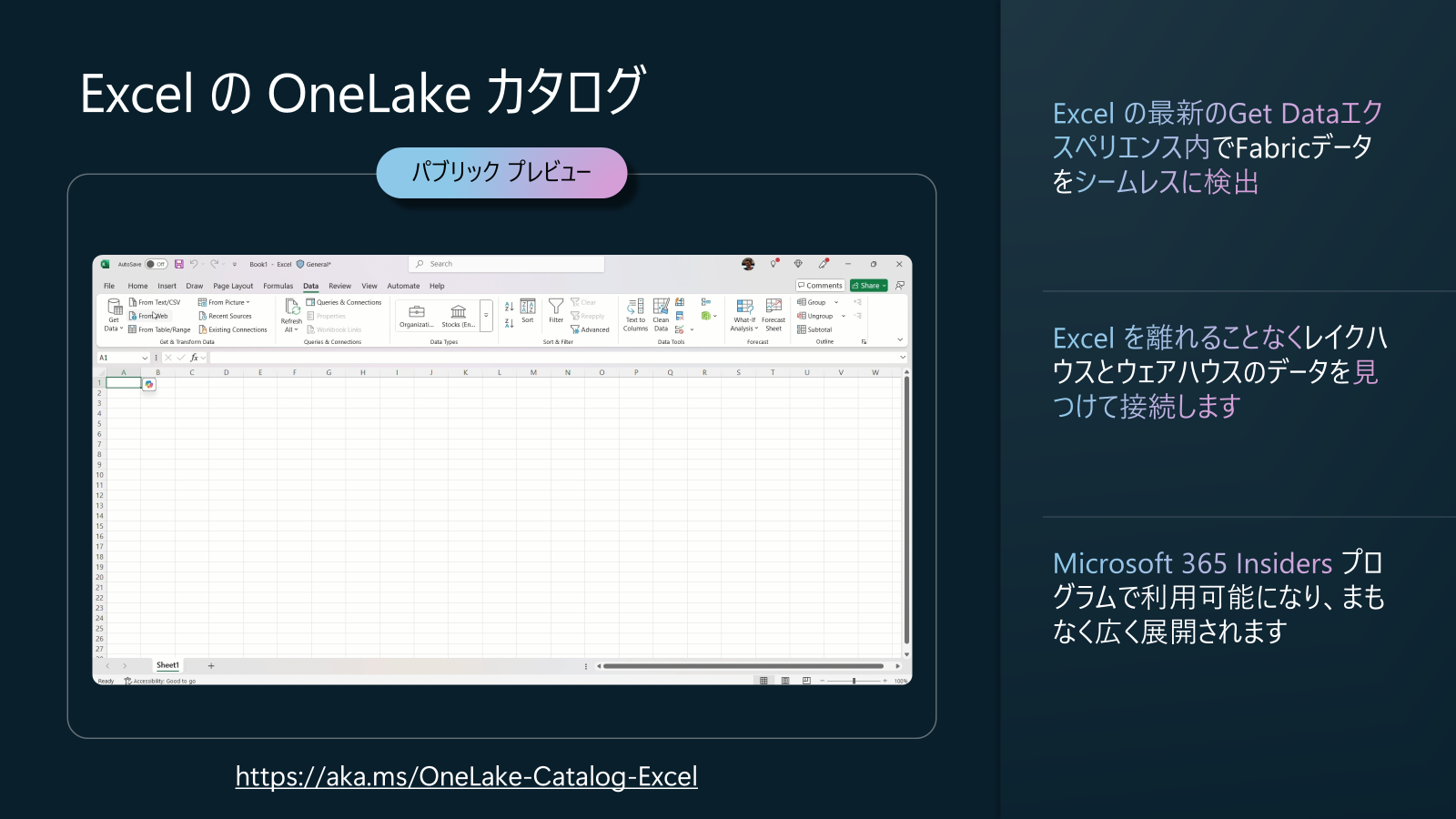
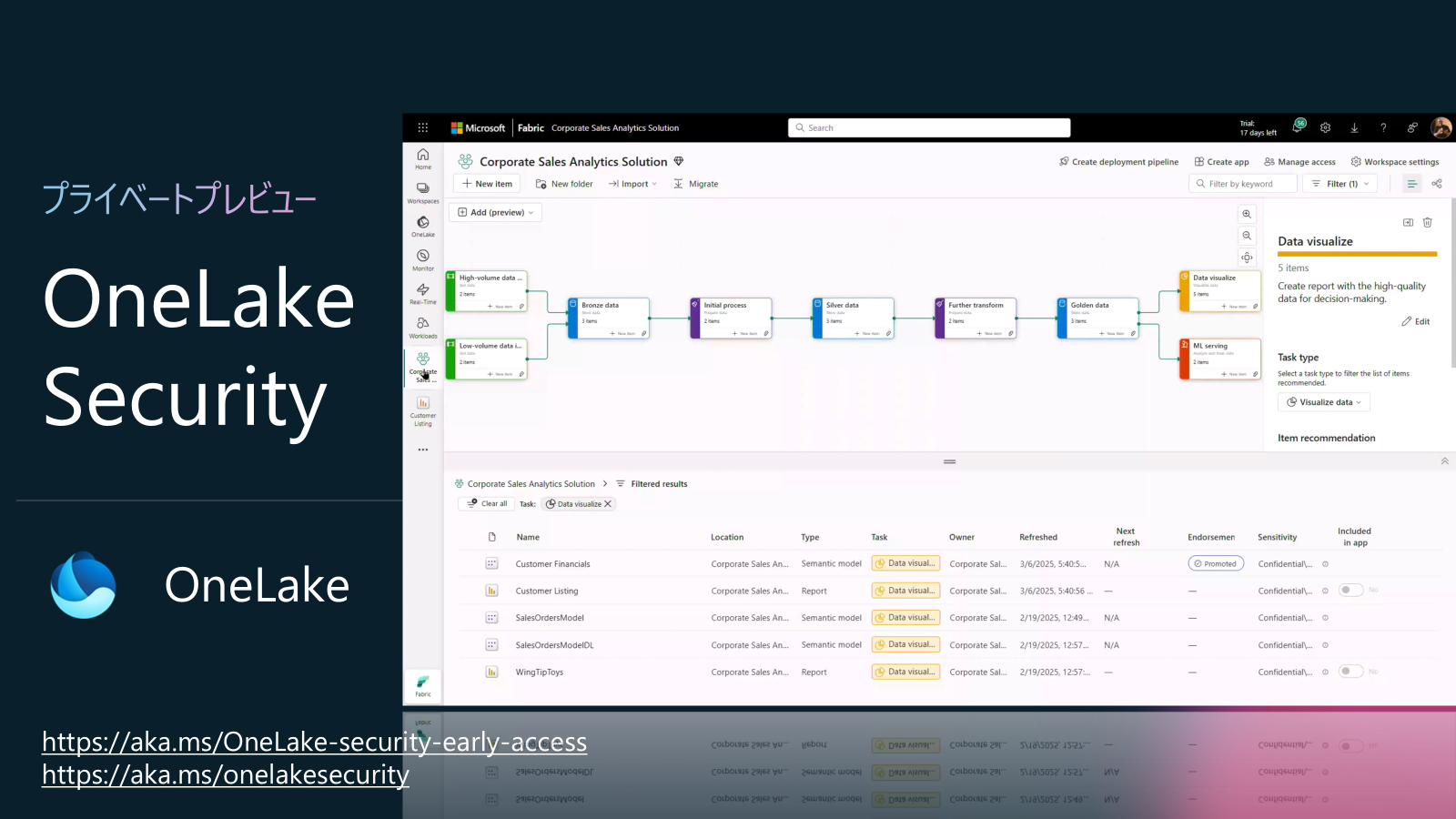
プラットフォームアップデート9: OneLake Security (プライベートプレビュー)
OneLake Security は、ADLS Gen2 を基盤とする階層型データレイク OneLake 上のデータに対し、ワークスペース権限やアイテム権限を継承した多層的なアクセス制御を提供します。
現在、Tableとフォルダのセキュリティのほかに、Column-level securityとRow-level securityも対応できます。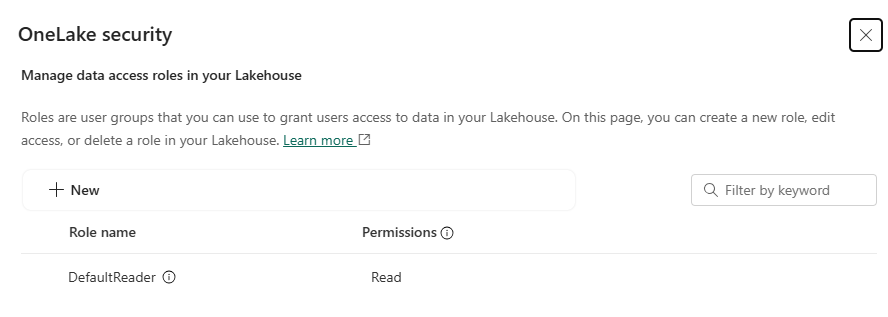
ちなみに、権限管理周りの内容は、DP-700試験も出題対象となり、学習しておいたほうがいいでしょう。
限定プレビューに参加するのは、こちらのURLから申し込んでください。
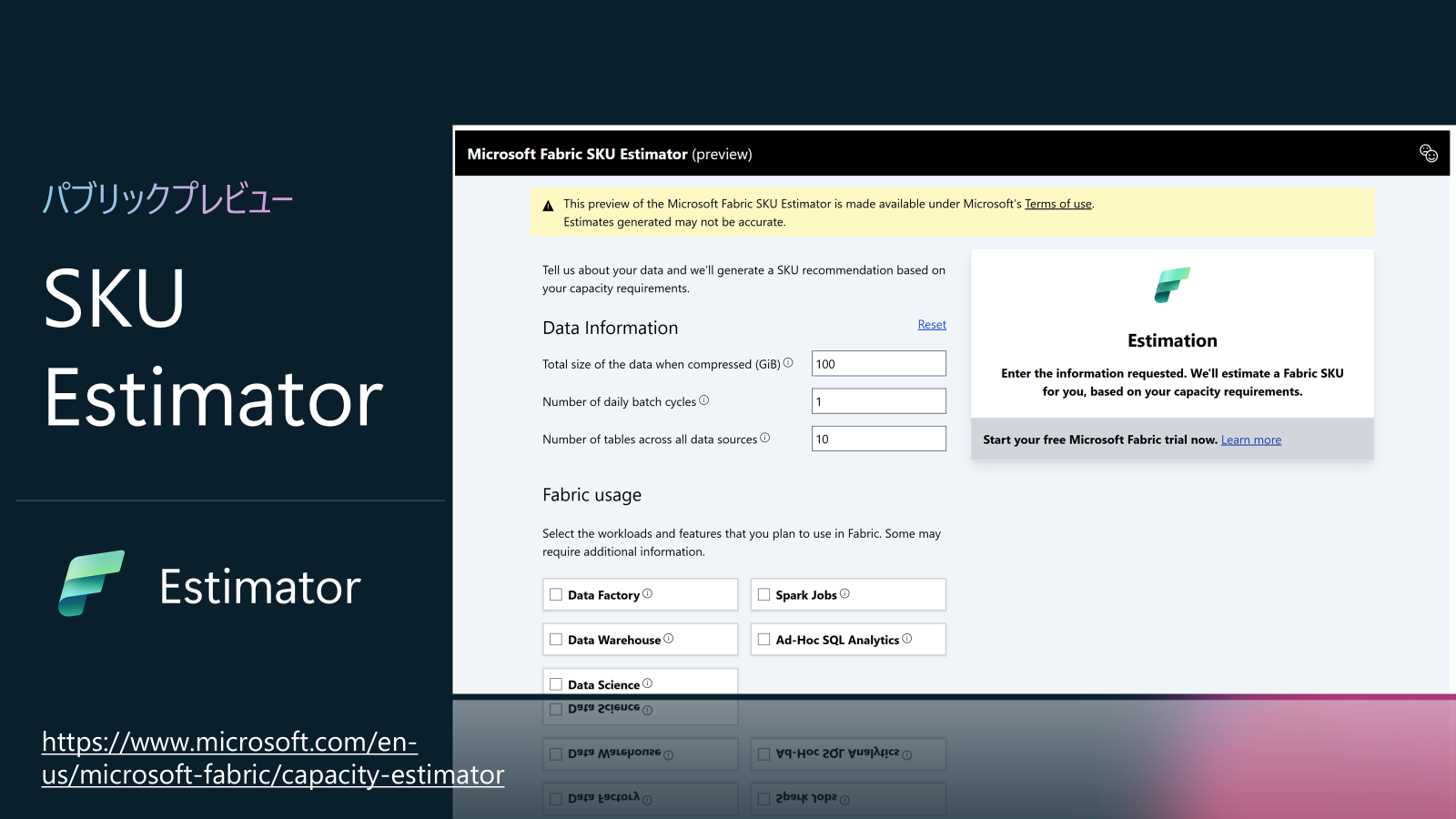
プラットフォームアップデート10: Microsoft Fabric SKU Estimator (パブリックプレビュー)
データサイズ、同時実行クエリ数、レポートユーザー数など、複数の変数をフォームに入力し、SKU推奨の根拠と詳細レポートを取得できます。
Power BI, Spark, Data Warehouse等のワークロード別に最適なSKU構成を示し、ライセンス構成(F64 vs ユーザー単位Proライセンスなど)も考慮します。
ただし、該当ツールは、Copilotの見積計算は含まれていません。
プラットフォームアップデート11: F2 以上の SKU で Copilot と AI エクスペリエンス (2025年4月30日から徐々にロールアウト)
元々AI機能を使うために、F64 SKU が必要でしたが、たくさんのFeedbackから、F64という縛りをなくしたい要望がありました。今回は皆様の要望に応じて、有料のF2以降のSKUでしたら、すべてワークロードのCopilotがご利用可能です。
プラットフォームアップデート12: Shortcut transformations in OneLake (パブリックプレビュー)
Shortcut Transforms は、Fabric ユーザー向けの今後提供予定の機能で、OneLake がサポートするクラウド上のさまざまな場所に保存されたファイル形式(CSV、Parquet、JSON、Text、ORC、Avro、Icebergなど)を構成・変換することが可能になります。Fabric チームは、依存関係の管理や監視エクスペリエンスに加えて、変更検出やデータパイプラインの自動管理も行います。
今後のロードマップには、以下が含まれています。
- ユーザーインターフェイスベースの変換体験
- ノートブックによる変換体験
- 変換処理を実行するためのパブリックAPI
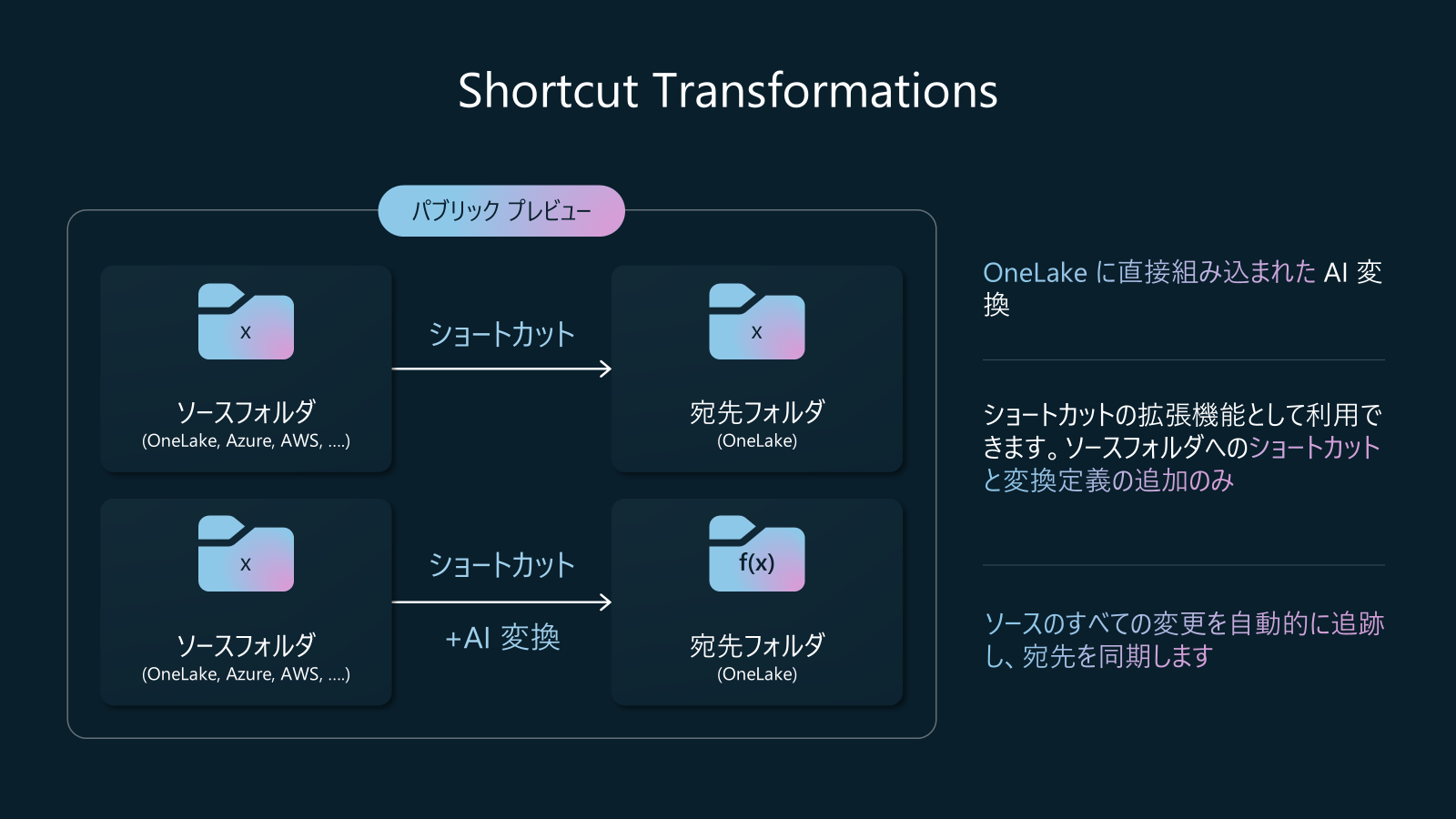
さらに、非構造化テキストファイルやPDFをAIで変換する機能は PuPr ロードマップの一部であり、ノートブックを用いたカスタム変換は将来的なアップデートで提供される予定です。
従来のショートカット機能と同様に OneLake上のデータをリンクできますが、AIによる変換処理を組み合わせることが可能になっています。たとえば、S3にある MP4の音声データをOneLakeにショートカットとして取り込む際、従来のようにそのままMP4ファイルとしてリンクすることもできますが、Shortcut Transformsを使えば、バックグラウンドでAI Functionが動作し、MP4の音声をテキストに変換(文字起こし)し、さらにそのテキストに対して感情分析を行うことができます。最終的には、分析結果が Lakehouseのテーブルとして、構造化されたデータを保存されます。しかも、マウスの数クリックのみで、コーディング不要というノーコードのエクスペリエンスです。
プラットフォームアップデート13: Private Link support at a workspace level (プライベートプレビュー)
テナント レベルのプライベート リンクを使用すると、Fabric への安全な接続が可能になりますが、この機能についてはワークスペース レベルできめ細かいサポートを提供する予定です。組織は、この機能を使用して、テナント全体ではなく特定のワークスペースへの受信トラフィックをセキュリティで保護できるため、運用ワークスペースをセキュリティで保護しながら、開発ワークスペースとテスト ワークスペースにインターネット経由でアクセスできるようになります。このセットアップでは、Azure Private Link と Azure Networking のプライベート エンドポイントを使用して、パブリック エンドポイントを使用する場合は、データ トラフィックが Microsoft のバックボーン ネットワーク経由でプライベートに移動するようにします。ワークスペース レベルの Private Link 機能は、少数のワークロードから開始され、段階的に他のワークロードに拡張されます。Azure Private Link が構成され、パブリック インターネット アクセスが制限されると、その Fabric ワークスペースでサポートされているすべてのシナリオがプライベート リンク経由でルーティングされます。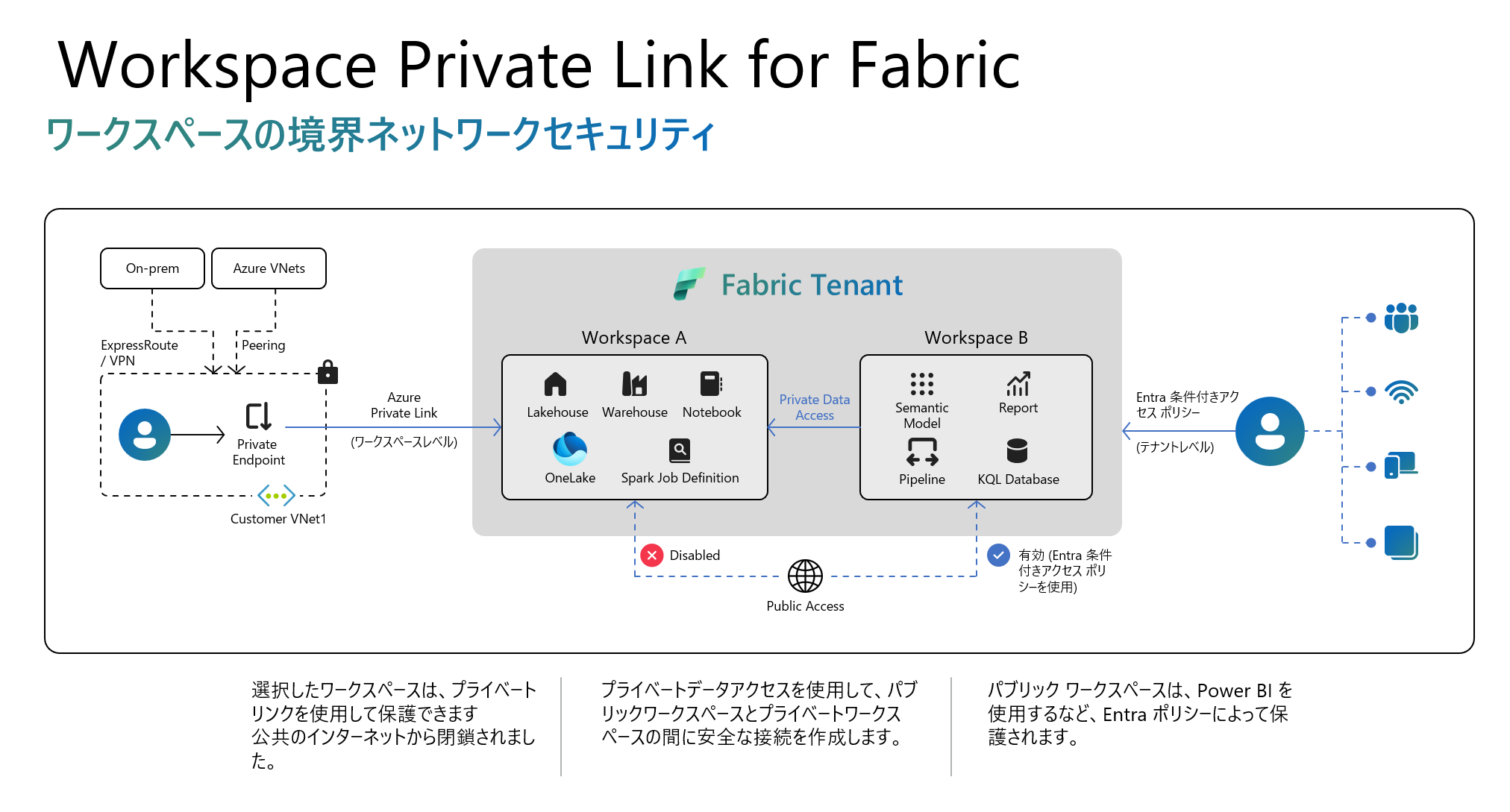
プラットフォームアップデート14: OneLake catalog secure tab (Build 2025: スニークピーク、プライベートプレビューの前段階)
OneLake catalogが、Tab対応になり、データ項目、ユーザー、またはロールごとに、セキュリティポリシーの表示やセキュリティポリシーの作成も可能です。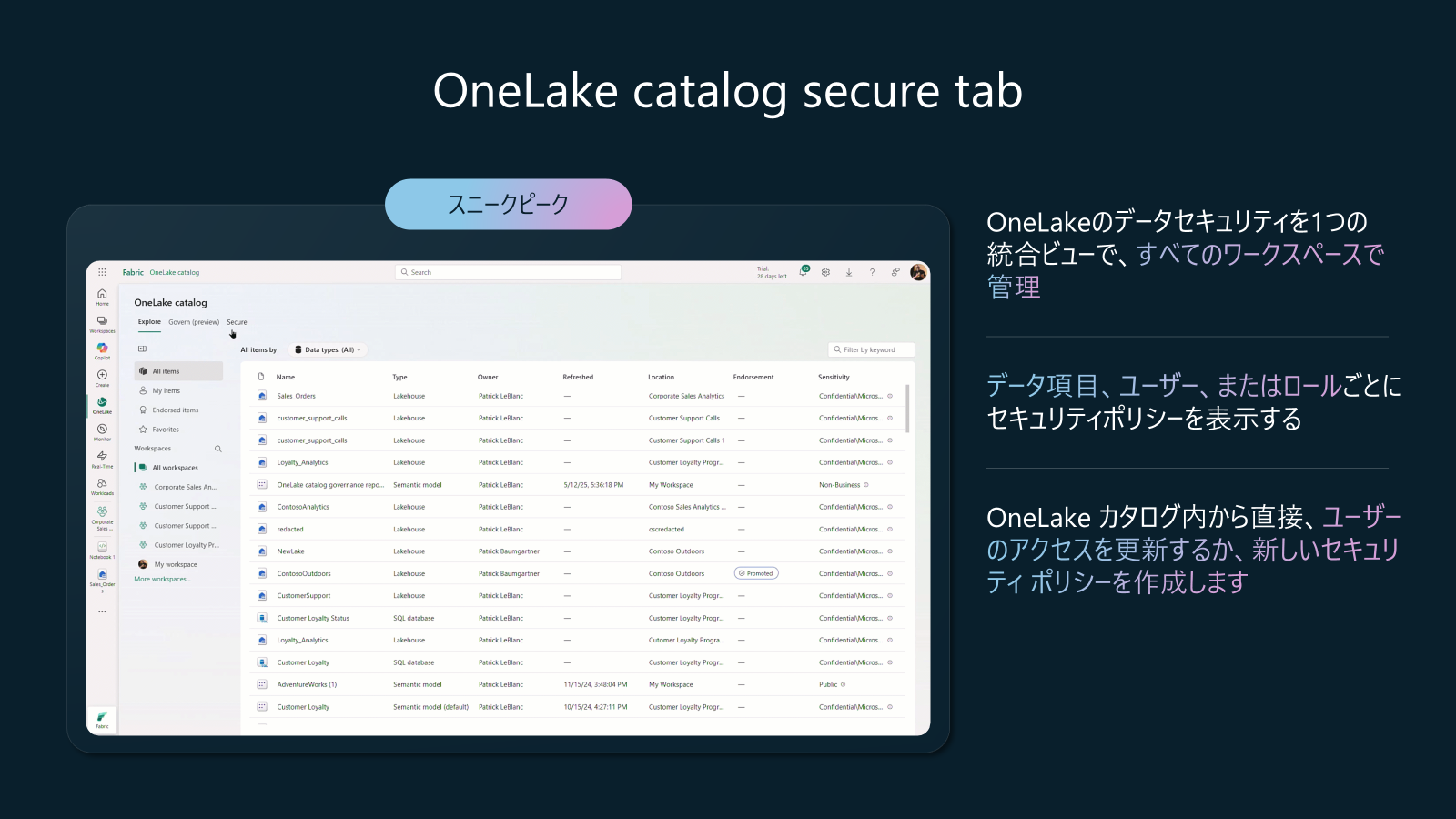

Data Factory in Fabric のアップデートには、パイプライン、コネクタ、データフローの内容が含まれています。
Data Factory in Fabric アップデート1: Azure Key Vault の統合 (プライベートプレビュー)
皆様からのフィードバックに基づき、Fabric Data Factory に Azure Key Vault 統合のサポートを追加できるようになります。また、新しい接続を作成するときや、データ ソース (Azure Storage など) に接続するための必要なシークレットを取得するときに、Azure Key Vault への参照を指定できます。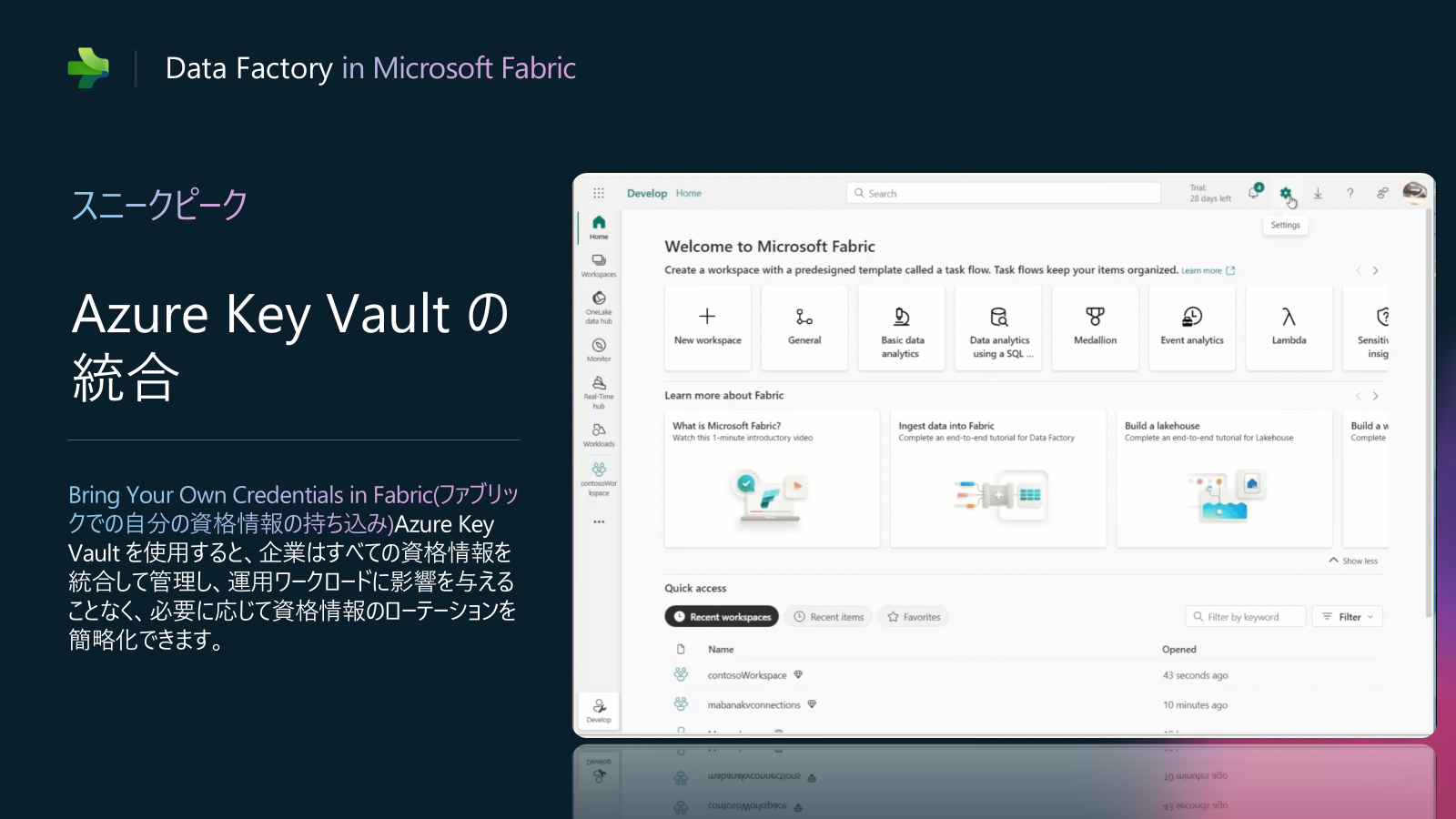
Data Factory in Fabric アップデート2: Using VNET Gateway for Pipelines, Copy Job, and Database Mirroring (パブリックプレビュー)
最も多く寄せられる質問は、Azure VNet またはプライベート ネットワークの背後にあるデータ ソースへの接続です。VNet ゲートウェイを使用すると、これらのデータ ソースに安全に接続できます。パイプライン、コピー ジョブ、データベース ミラーリングに対する VNEt ゲートウェイのサポートを追加しました。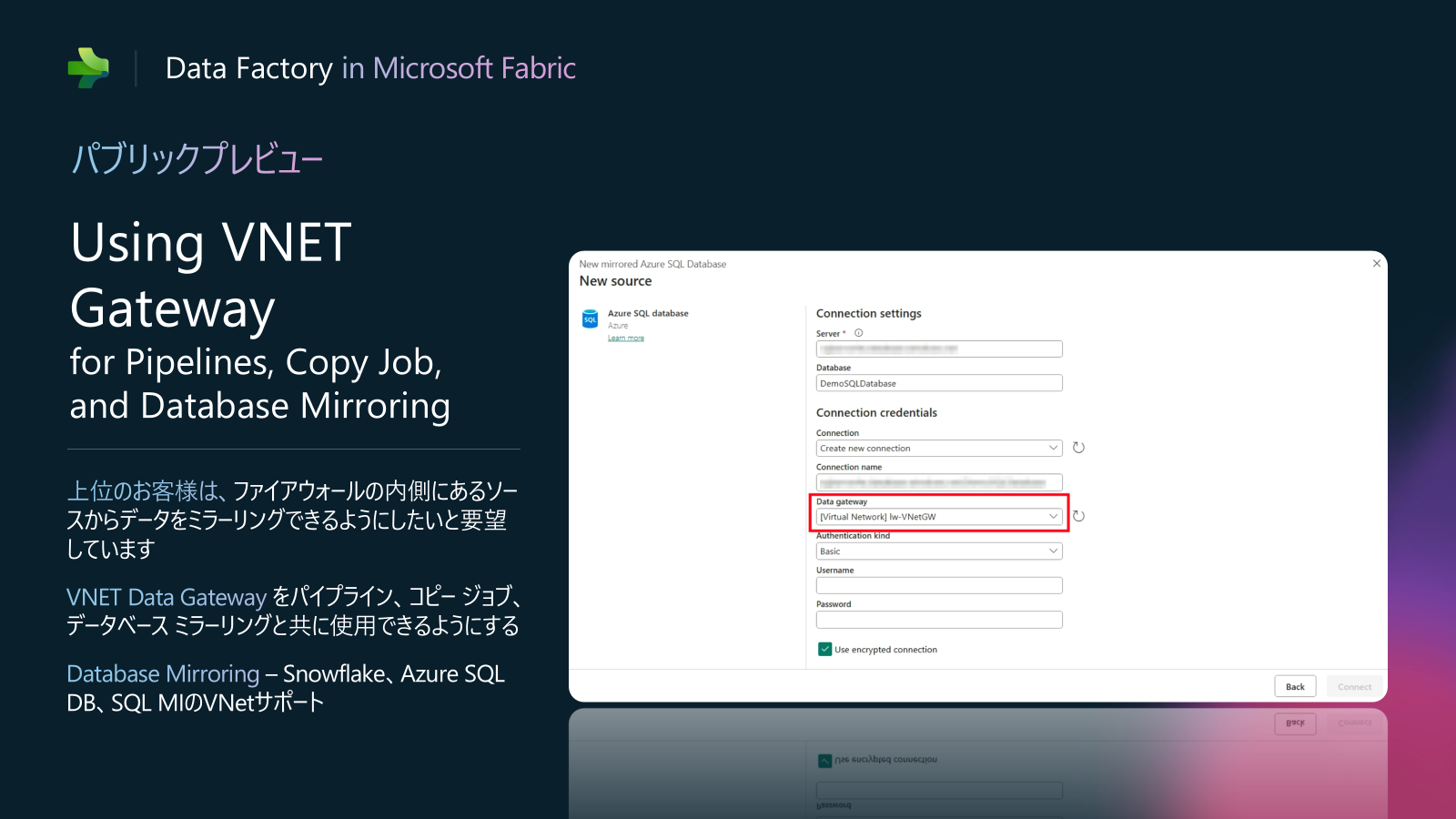
Data Factory in Fabric アップデート3: Copy Job (GA)
Microsoft Fabric の Data Factory における Copy Job は、データの取り込みプロセスを簡素化し、パイプラインの作成なしにデータを任意のソースから任意のデスティネーションへ移動できる機能です。一般提供は、7 月 1 日に提供開始されます。このリリースでは、コピー ジョブ専用の新しい課金メーターも導入されます。これは、データ移動の価格設定方法の透明性と柔軟性を高めるように設計されています。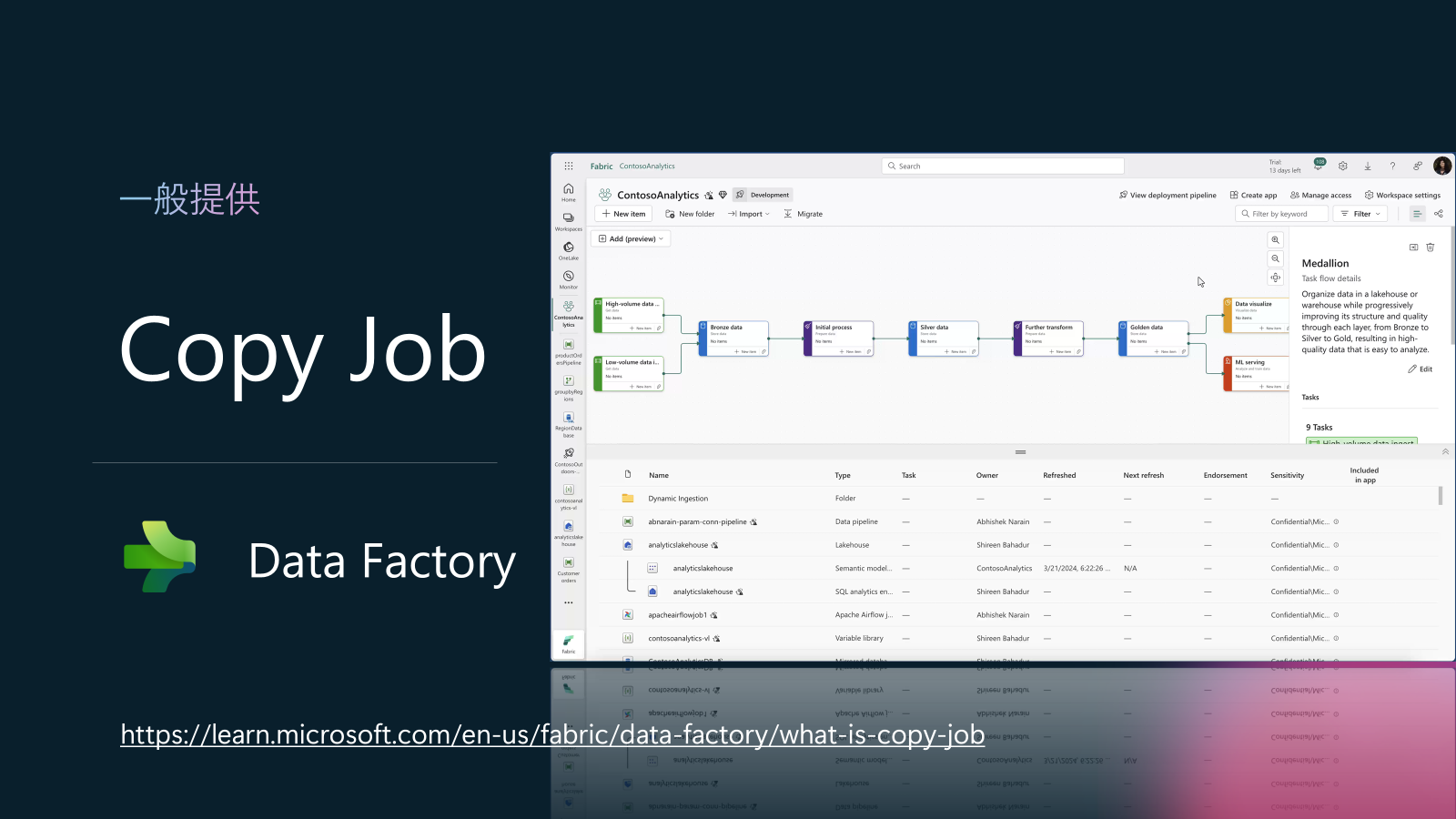
今後は、さらにCopy Jobのコネクタを追加していきます。そして、CI/CDのサポート、Lakehouseの上書きなどの機能をリリースする予定です。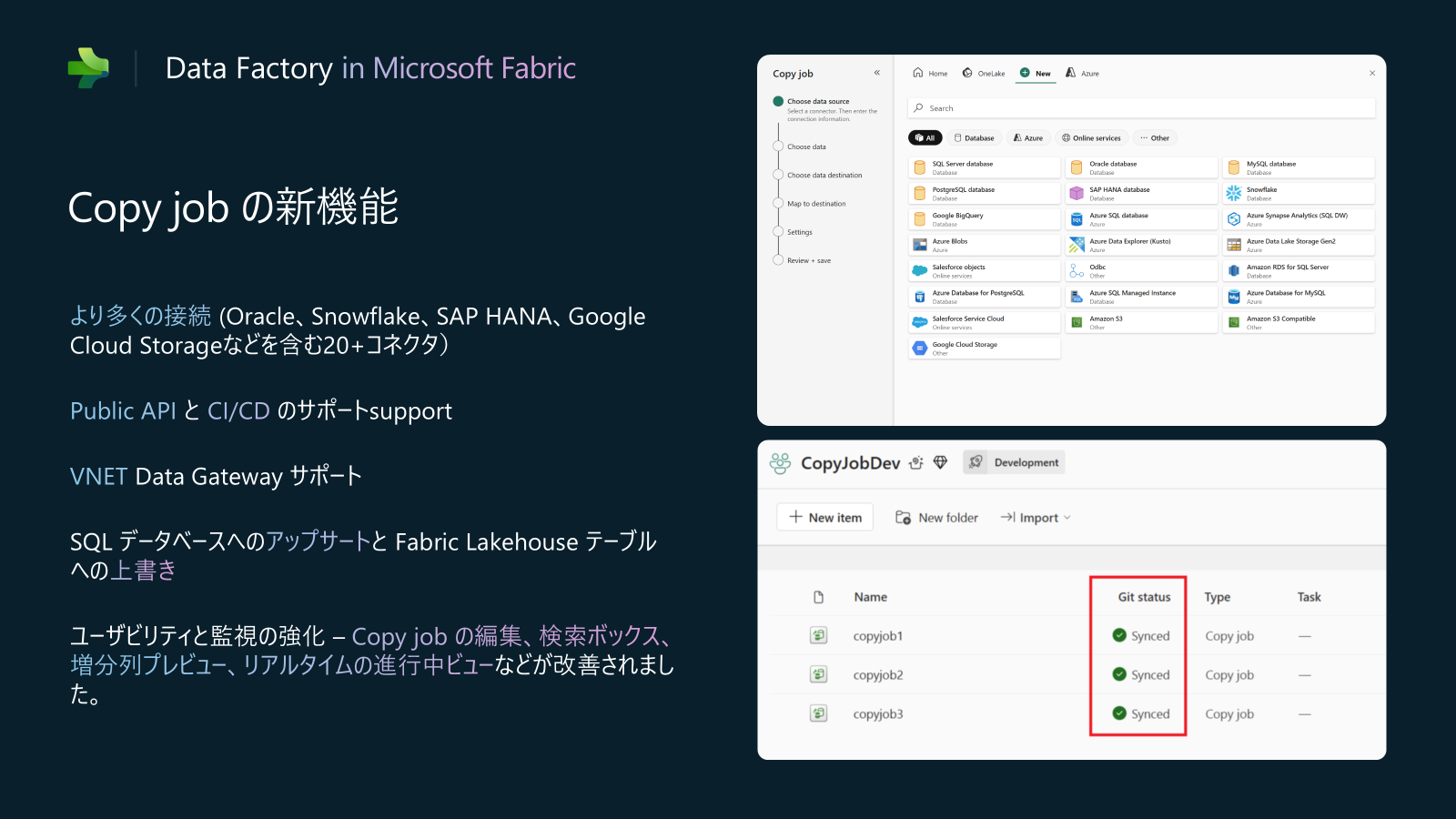
Data Factory in Fabric アップデート4: Apache Airflow job (GA)
Data Factoryはローコードのエクスペリエンスですが、Pro Codeユーザー向けのETLジョブのために、製品チームがApache Airflow jobをリリースします。Microsoft Fabric の Apache Airflow Job は、Python ベースの DAG (Directed Acyclic Graph) を用いてワークフローを構築・管理するためのマネージドサービスです。これは、Azure Data Factory の Workflow Orchestration Manager の次世代版として位置づけられ、インフラの管理を意識することなく、スケーラブルで高可用性なワークフローの実行を可能にします。
Data Factory in Fabric アップデート5: データフローの増分更新 (GA)
Microsoft Fabric の Dataflow Gen2 における インクリメンタル リフレッシュ 機能は、増大するデータ量に対応し、データの更新効率を高めるための強力なツールです。この機能により、データフローは前回の更新以降に変更されたデータのみを取得し、処理時間とリソース消費を削減できます。
Data Factory in Fabric アップデート5: Mirroring for Azure PostgreSQL (パブリックプレビュー)
それは、PostgreSQLのデータがFabric Mirroried Databaseとして同期できる機能です。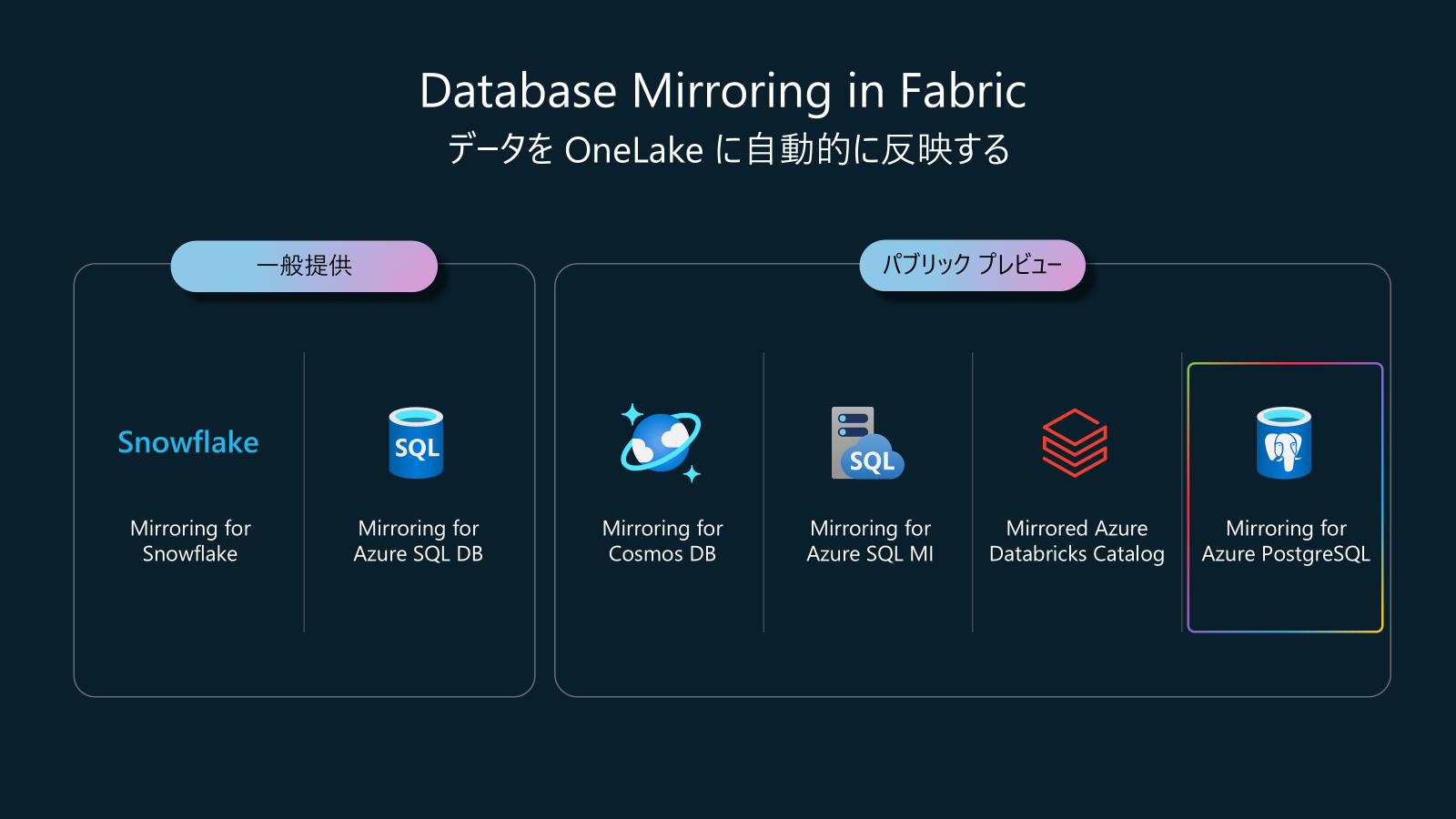
そして、Morring for SQL Serverと、Morring for SQL Server 2025は、パブリックプレビューになっています。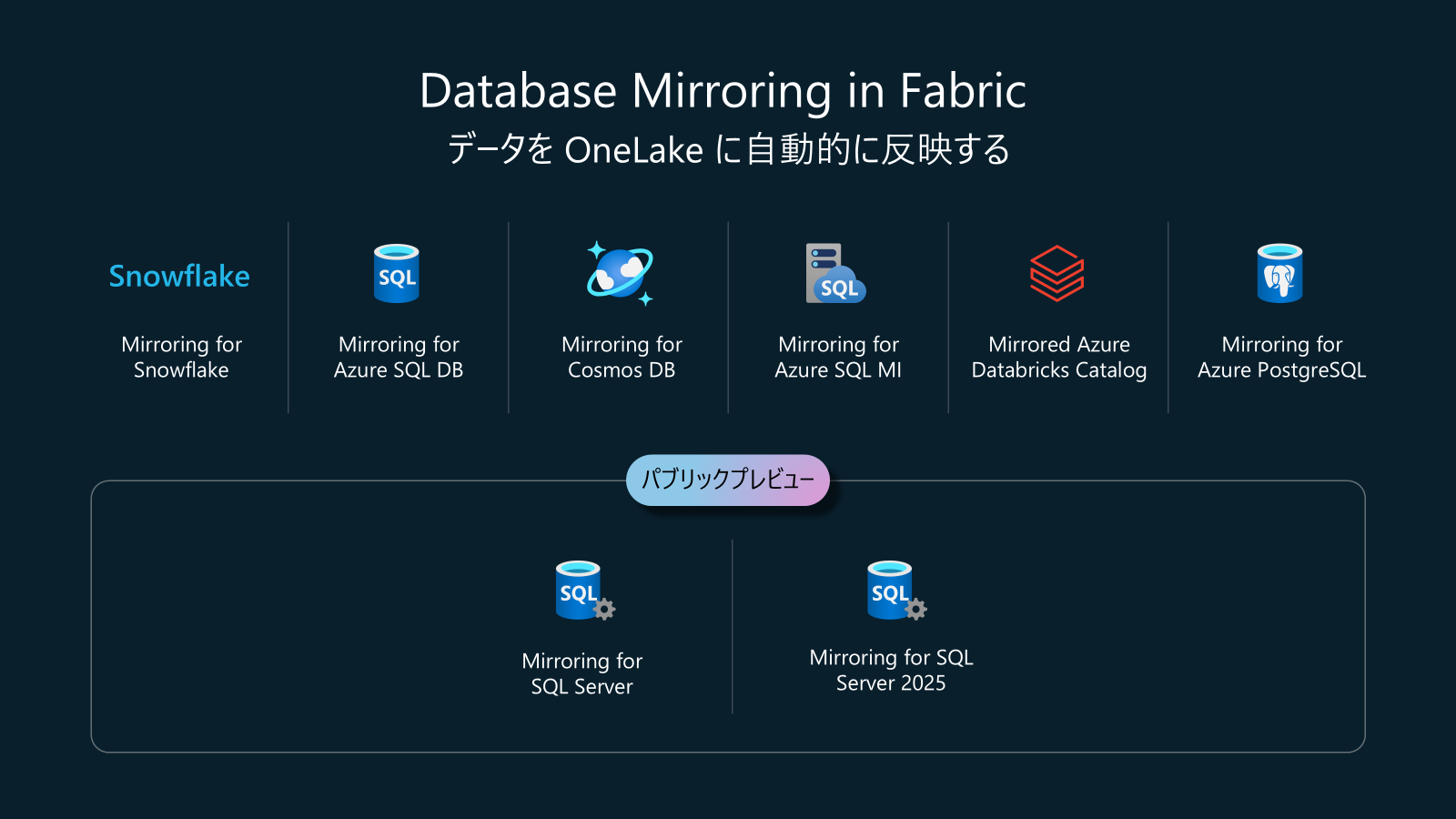
Mirroring for Oralce、Mirroring for BigQueryは現在プライベートプレビューです。
さらに、その先は、Delta Change Feedをサポートするようになり、Mirroried Itemに適用された変更がダウンストリームの増分処理のために、Chage Feedを実装される予定です。こちらの実装で、Mirroried Databaseに加えられた変更を理解し、Medallion アーキテクチャに基づいてダウンストリーム処理のロックを解除できます。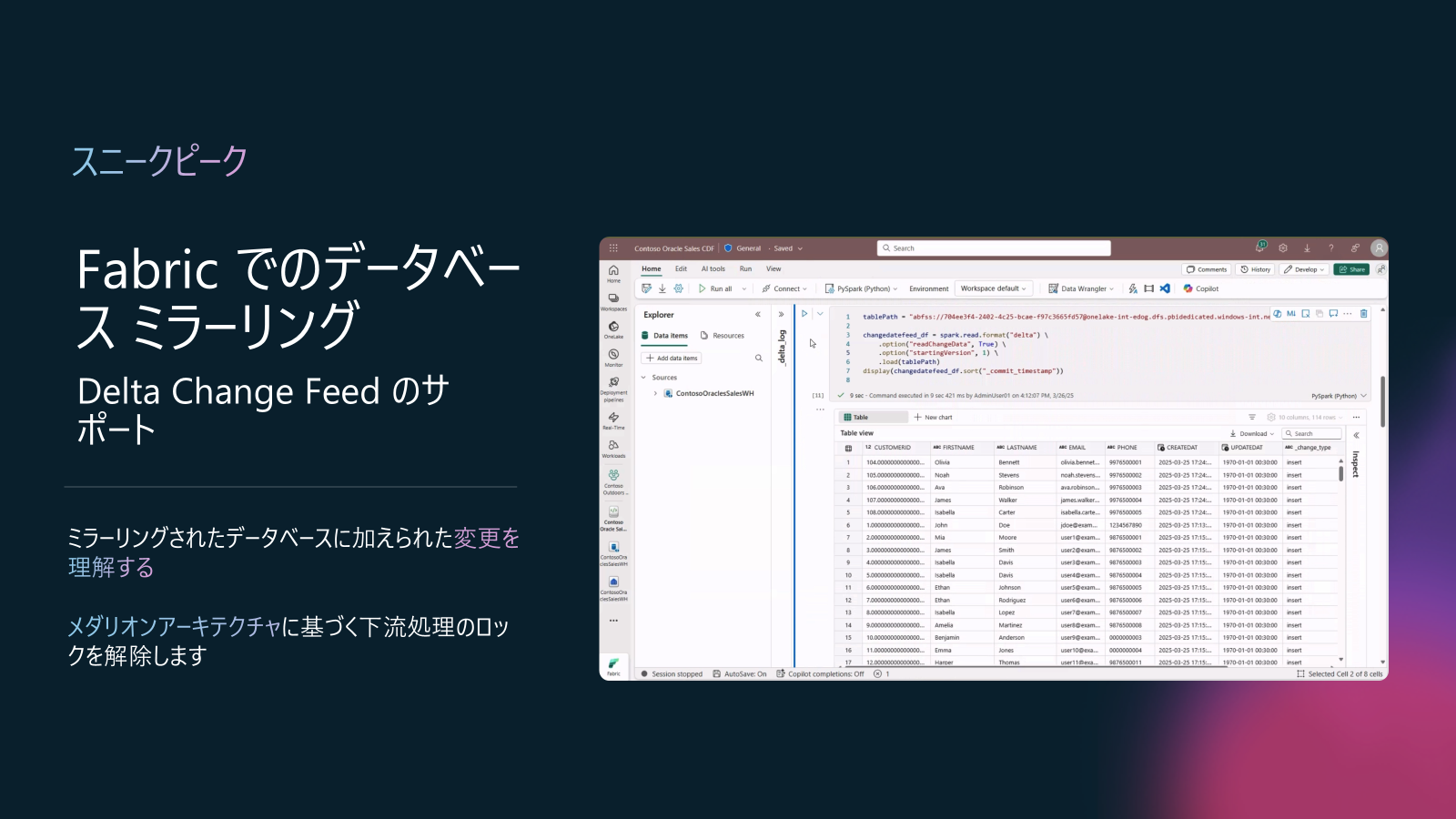
Data Factory in Fabric アップデート6: Open Mirroring (Build 2025: GA)
Open Mirroringは、Fabric Mirroring 機能の拡張であり、データをFabricに取り込む最も簡単な方法の1つであり、OneLakeにデータのコピーを作成して最新の状態に保ちます。ETLは必要ありません。Open Mirroringは、ユーザーやパートナーにAPIを提供し、どこからでもデータをレプリケートできます。データをDelta ParquetまたはCSV形式に変換し、APIまたはUIを使用して、追加の変更とともにデータをOneLakeランディングゾーンにロードするだけです。そこから Microsoft のレプリケーション テクノロジが引き継ぎ、すべてを Delta 形式に変換して、Microsoft Fabric のすべての AI および BI ワークロードに最適化し、対応できるようにします。Open Mirroringを使用すると、拡張性とカスタマイズ性を考慮して設計されているため、誰もが独自のミラーリングソースを作成でき、複雑な変換を必要とせずにMicrosoft Fabricの任意のデータをシームレスに使用できます。

Data Factory in Fabric アップデート7: ファイアウォールの背後にあるソースのミラーリング (パブリックプレビュー)
データベース ミラーリングを使用しているユース ケースについて多くの皆さんと一緒に学習する中で、最も求められていることの 1 つは、Virtual Network またはプライベート ネットワーク内のデータ ソースへの安全な接続のサポートです。オンプレミスデータゲートウェイとVNetデータゲートウェイをデータベースミラーリングとともに使用し、Snowflake、Azure SQL DB、SQL MIに安全に接続することができるようになりました。より多くのデータソースがこれらの新機能を活用できるようになります。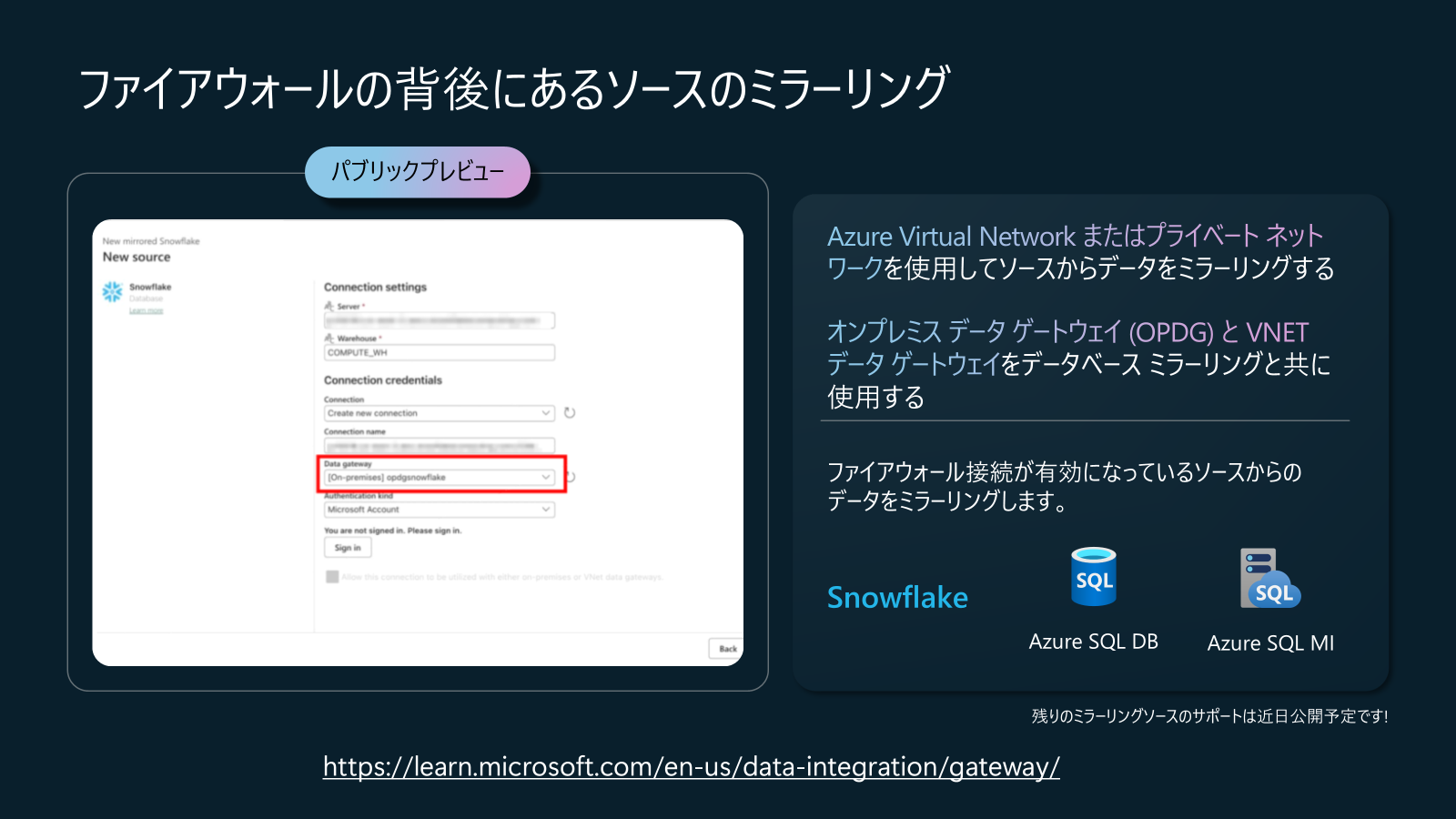
Data Factory in Fabric アップデート8: Copilot for Data Factory (Pipelines + Dataflows) (GA)
Data Factory のすべての Copilot 機能は一般提供されています。そのため、Datafactoryを使用して、Dataflows、Pipelines、およびエラーアシスタントを日々の運用タスクで使用できます。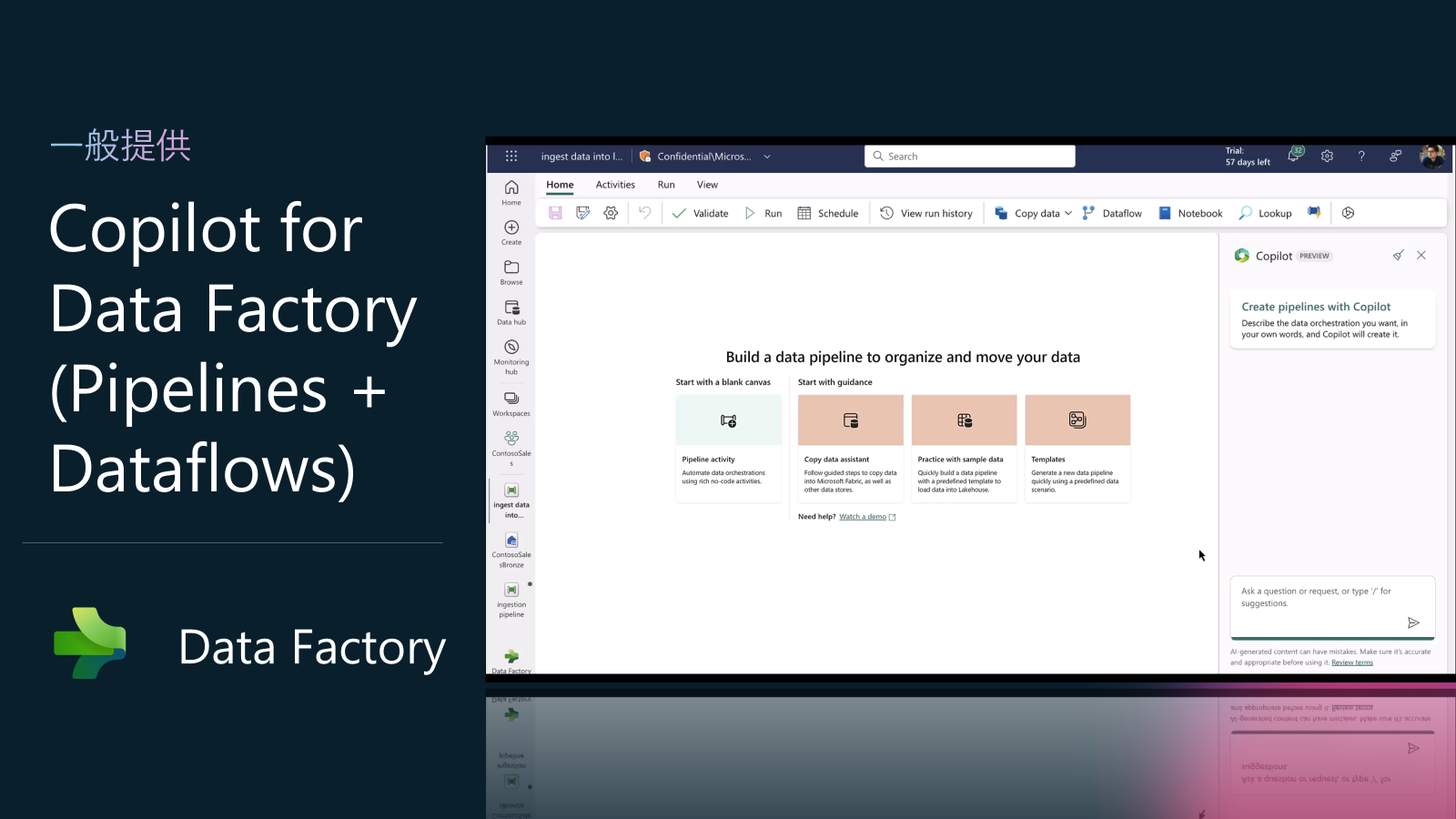
Data Factory in Fabric アップデート9: Dataflow Gen2 SharePoint ファイルへの出力先(CSV) (プライベートプレビュー)
Dataflow Gen2の出力先に、Sharepointを指定できるようになります。Sharepoint上にあるデータに対して、Dataflow Gen2で加工処理を行い、そのままSharepointに書き戻すことが可能になります。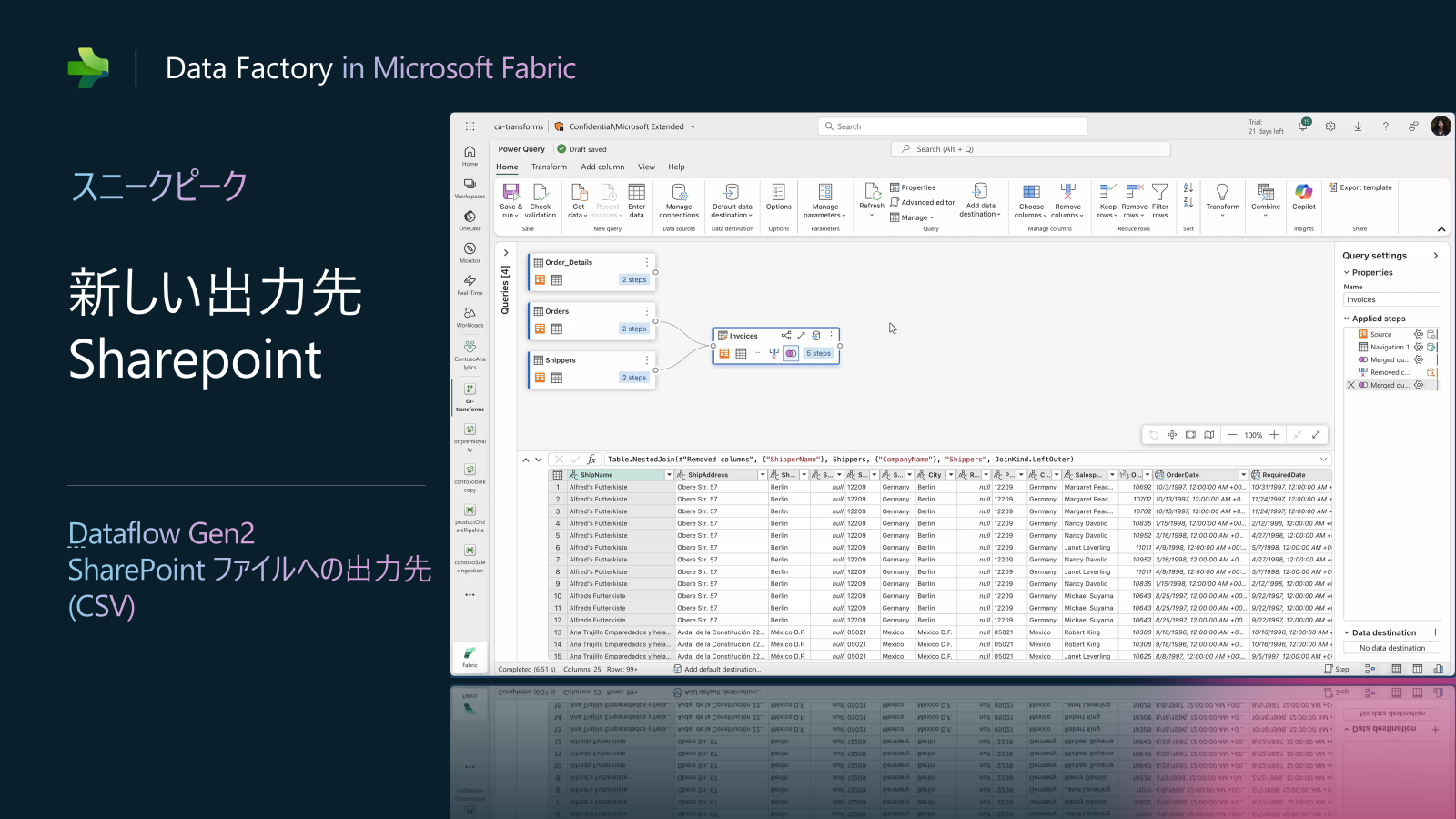

Data Engineering in Fabric アップデート1: Lakehouse マテリアライズドビュー (プライベートプレビュー)
マテリアライズドビューは、Lakehouse のソーステーブルに対する集計クエリを事前実行し、その結果を OneLake 上に Delta テーブルとして格納する機能です。これにより、都度クエリを実行する手間や計算コストを削減し、大規模データセットに対するレポートや分析を高速化できます。つまり、Lakehouse 上で事前集計済みデータを保持し、Direct Lake モードや他ワークロードから高速にアクセスできる点が最大の特徴です。
ブロンズからゴールドへのメダリオンアーキテクチャのデザインを効率化することができるようになり、最も強力な機能の 1 つは、制約を満たさない行を削除するなど、データ品質ルールを定義する機能です。レイクハウス内の通常の差分テーブルのように見え、SQL Analytics エンドポイントと PowerBI ダイレクト レイクを介してクエリを実行できます。自動生成されたマテビュ―管理ダッシュボードもあり、ビルド ステップのエラーをすばやくドリルダウンして表示できます。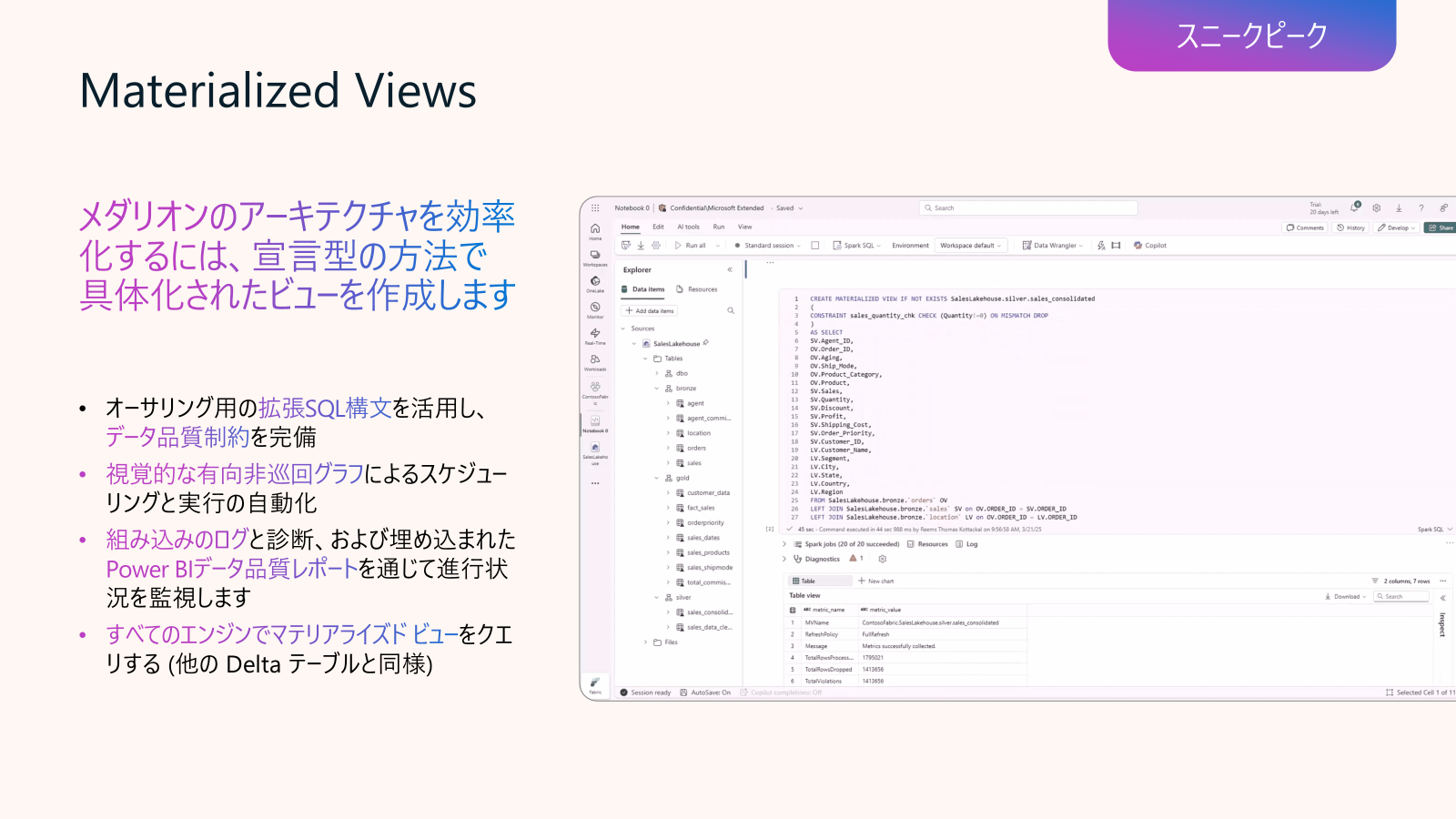
Data Engineering in Fabric アップデート2: Spark RLS/CLS (プライベートプレビュー)
OneLake Security の機能の一部になりますが、Lakehouseのスキーマを有効したうえで、LakehouseのRLSやCLSを設定でき、Sparkも対応しています。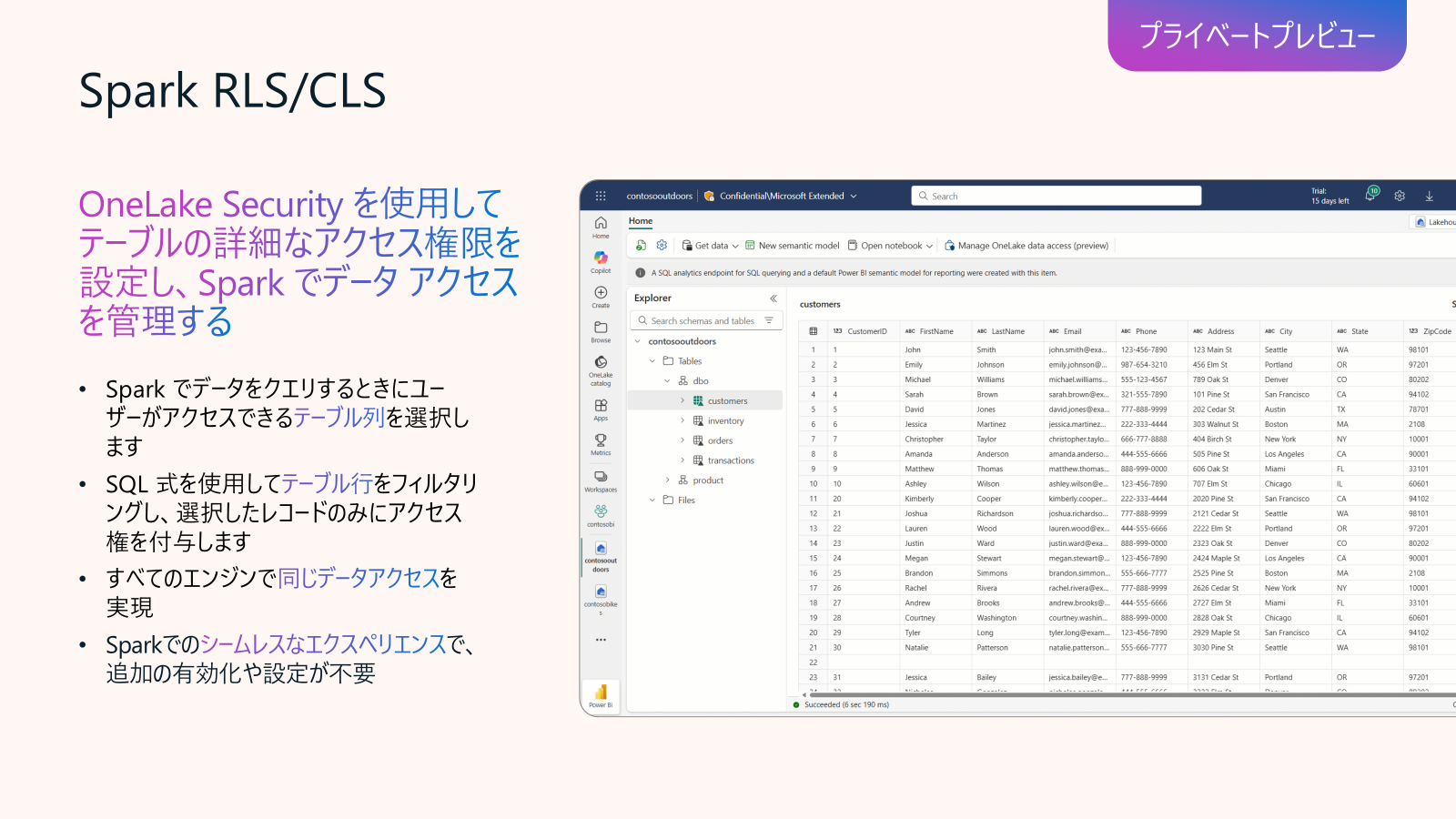
Data Engineering in Fabric アップデート3: Logical Data Modeler (プライベートプレビュー)
Logical Data Modeler は業界標準のデータモデルを視覚的かつコードレスに管理・最適化するソリューションです。インダストリー用のテンプレート最適化やメタデータ駆動のモデル定義をサポートし、ダウンストリームアプリケーション開発におけるセマンティクスを強化します。主に、CDM(Common Data Model)や Kimball 手法に基づく論理モデルテンプレートをドラッグ&ドロップで定義し、組織横断で共通のデータ定義を確立でき、既存の Synapse Dedicated SQL Pool や SQL Server スキーマからの移行を支援するテンプレート最適化機能により、モダナイゼーションを加速します。そして、名前付け規約、データ型、エンティティ間の関係性をモデルに組み込むことで、Power BI レポートや AI ワークロードでのデータ解釈精度を向上させます。ユースケースとしては、データウェアハウスの移行の支援として、SQL Server / Synapse Dedicated SQL Pool から Fabric Data Warehouse への移行時に、論理データモデルを再利用・最適化し、移行作業の生産性と品質を向上させ、セマンティックを組み込んだ論理モデルを基盤に、Power BI レポートや AI エージェントを開発し、一貫性のあるデータの可視化・分析を実現します。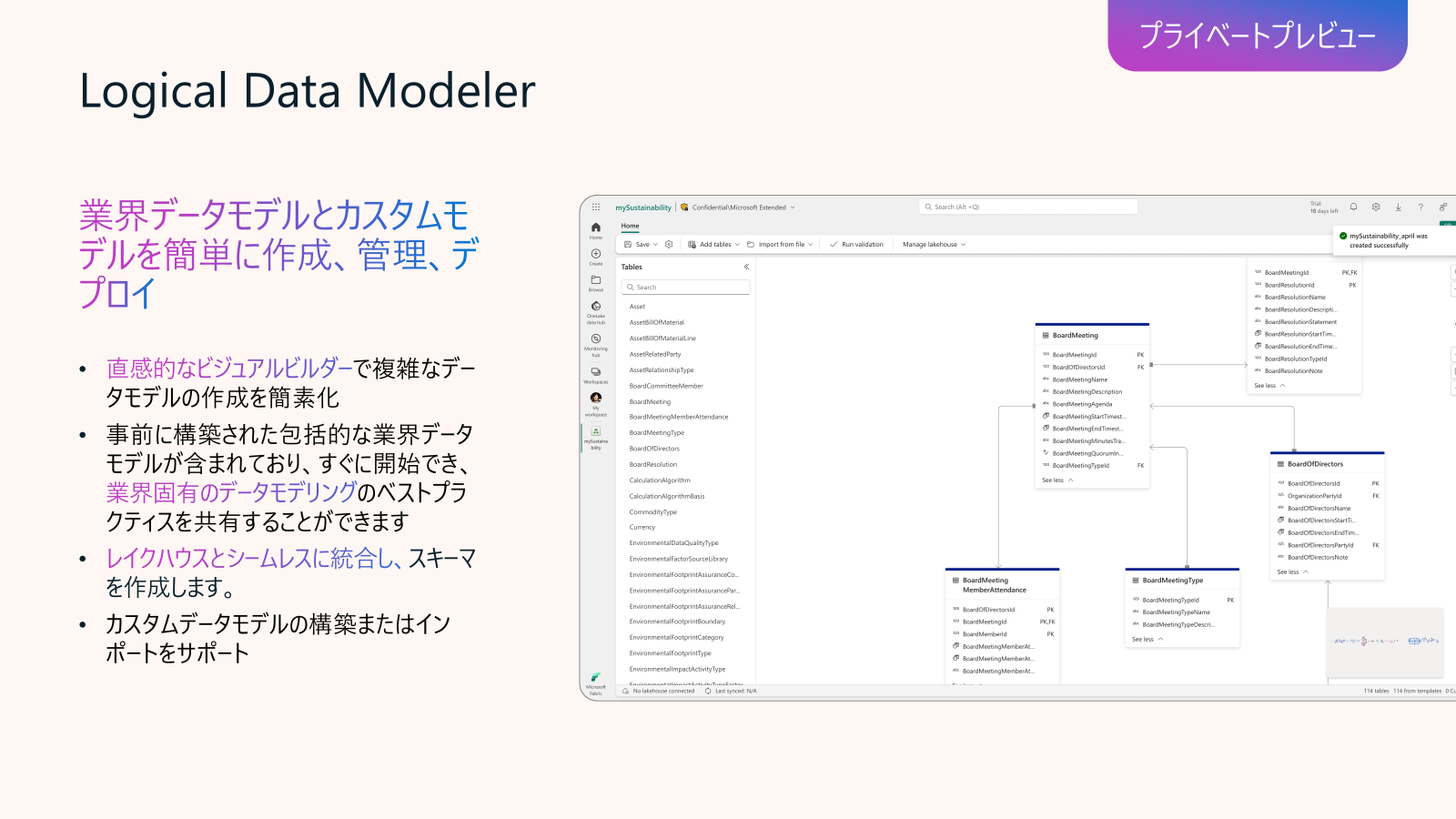
Data Engineering in Fabric アップデート4: Autoscale for Spark (パブリックプレビュー)
こちらのアップデートは主に2点が含まれています。一つは、Spark の自動スケール課金では、柔軟性とコストの最適化を強化するように設計された、Microsoft Fabric の Apache Spark ワークロード用の新しい従量課金制課金モデルが導入されています。このモデルを有効にすると、Spark ジョブは Fabric 容量からコンピューティングを消費しなくなり、代わりに Azure Synapse Spark と同様に、個別に課金される専用のサーバーレス リソースを使用します。もう一つは、自動スケーリングするように、上げ下げの上限と下限を指定できるようになります。
Data Engineering in Fabric アップデート5: Native Execution Engine (GA)
Spark クエリをレイクハウスでネイティブに実行でき、コードの変更やベンダーロックインなしで最大 6 倍高速に実行できます。このリリースでは、最適化とリソースプロファイルが組み込まれており、大規模でより迅速でコスト効率の高いデータエンジニアリングを実現します。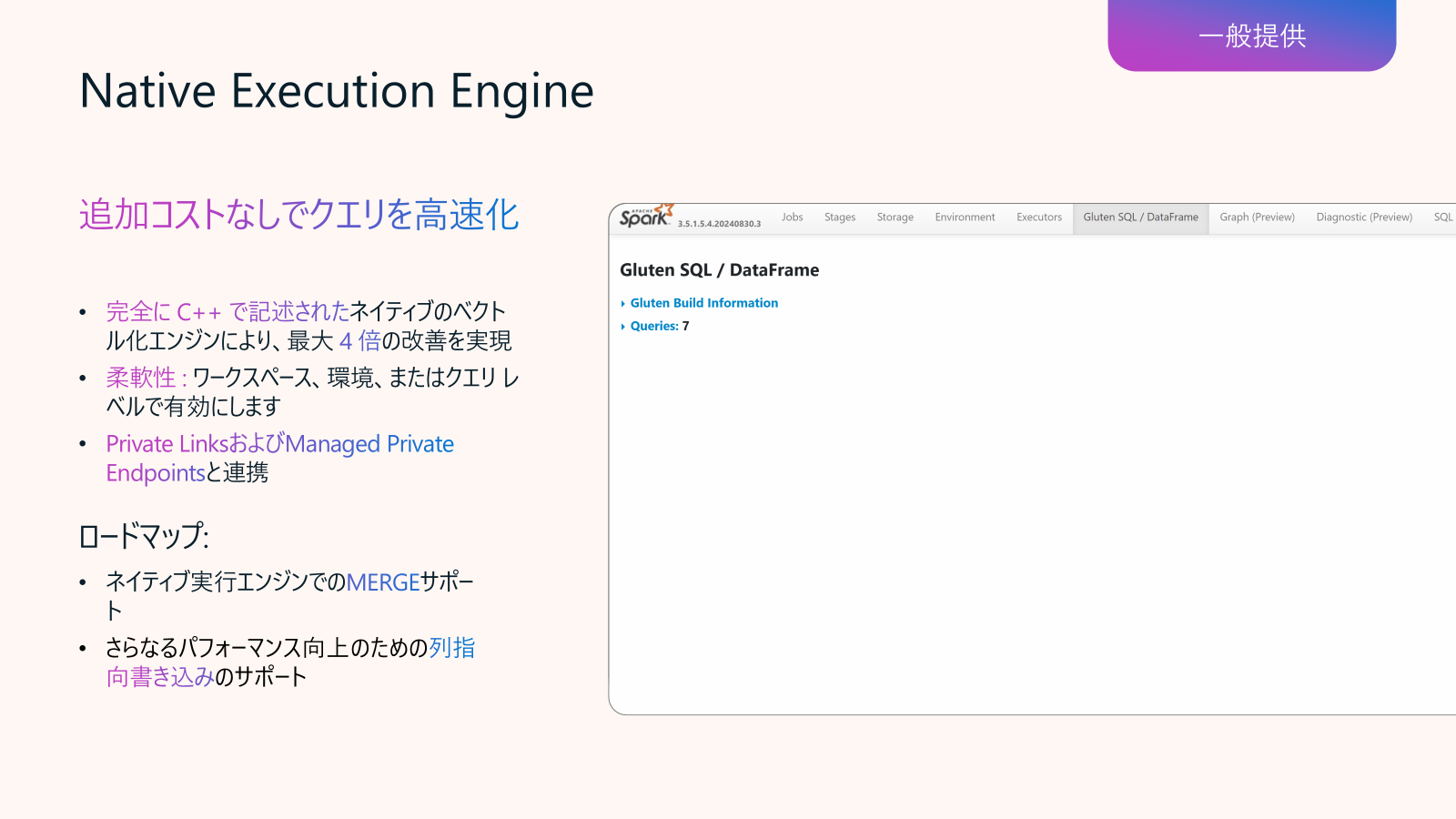

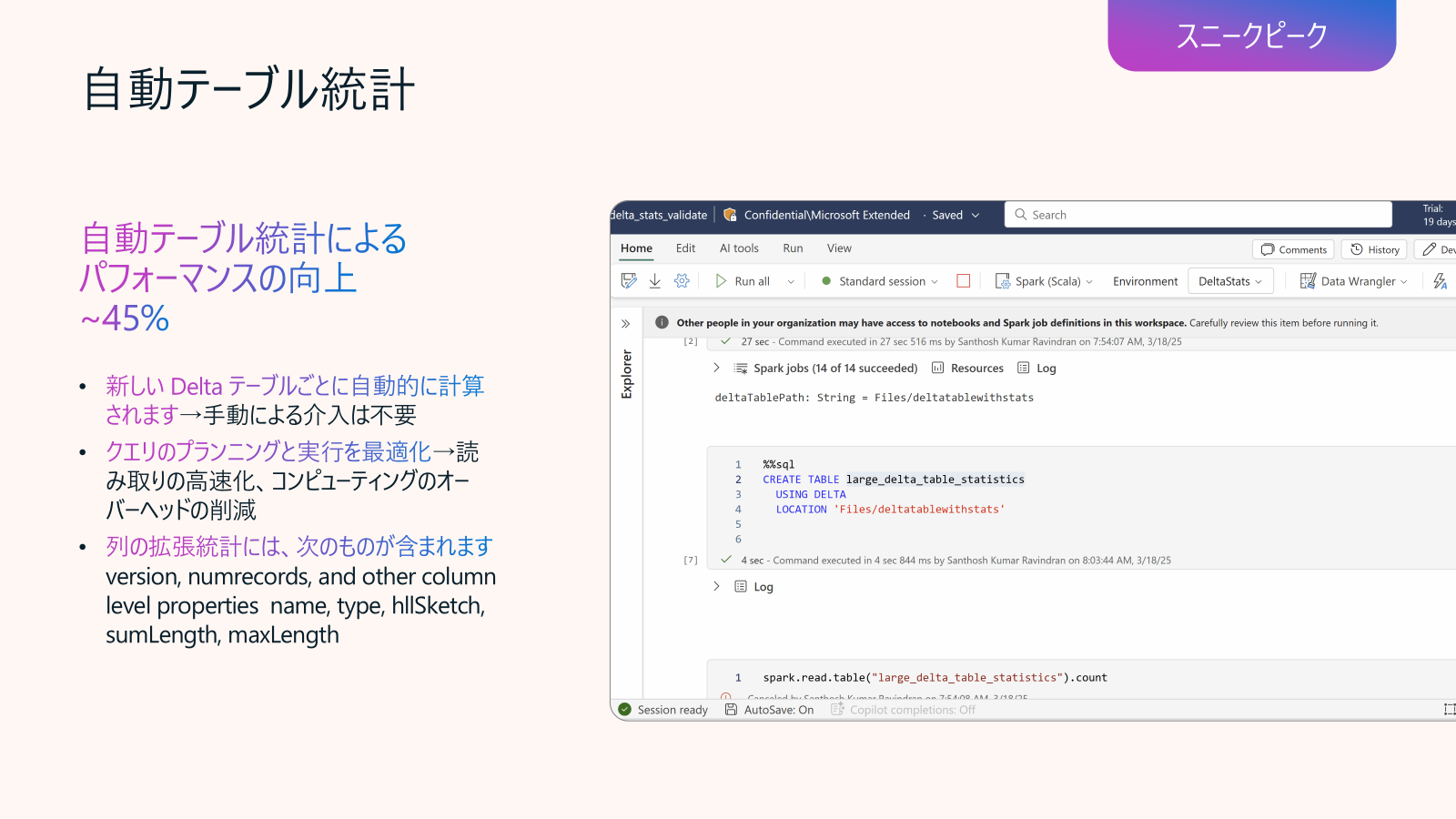
Data Engineering in Fabric アップデート6: Lakehouse 自動テーブル統計 (プライベートプレビュー)
Lakehouse 上の Delta テーブルに対して、Fabric Spark が自動的にテーブル レベルの詳細統計を収集し、クエリ オプティマイザーのコストベース プランナー(CBO)で活用する機能です。これにより、結合戦略やフィルター、集計、パーティション排除などが最適化され、クエリ性能の向上とコンピューティング コストの削減が期待できます。
// 拡張統計収集を有効化/無効化
spark.conf.set("spark.microsoft.delta.stats.collect.extended", "true")
spark.conf.set("spark.microsoft.delta.stats.collect.extended", "false")
// 統計注入(プランナーで利用)を有効化/無効化
spark.conf.set("spark.microsoft.delta.stats.injection.enabled", "true")
spark.conf.set("spark.microsoft.delta.stats.injection.enabled", "false")
Data Engineering in Fabric アップデート7
Spark DW コネクタ (GA)
Spark DW コネクタ(正式名称 “Spark connector for Microsoft Fabric Data Warehouse”)は、Fabric の Spark ランタイムにプリインストールされているコネクタで、Spark ノートブックやジョブから Fabric Data Warehouse(旧 SQL DW)および Lakehouse の SQL Analytics エンドポイントへシームレスにアクセスできる機能を提供します。データサイエンティストやデータエンジニアは、一行のコードで大規模データの読み書きが可能です。
# テーブルの読み込み
df = spark.read.synapsesql("SalesDW.dbo.Orders")
from com.microsoft.spark.fabric.Constants import Constants
df = (
spark.read
.option(Constants.WorkspaceId, "今後、Azure SQL DatabaseにもSparkコネクタも利用可能になります。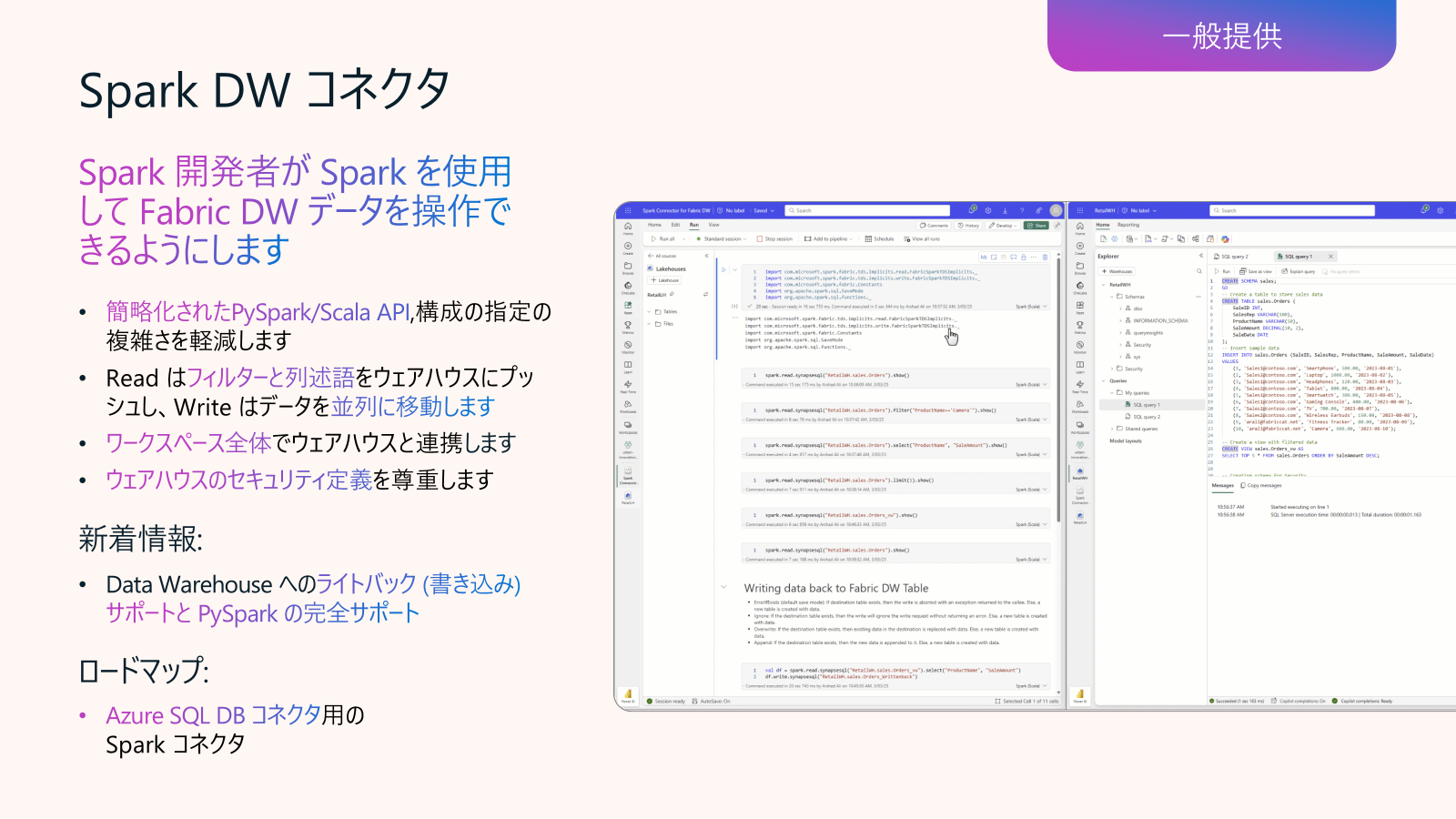
Data Engineering in Fabric アップデート8: Esri – ArcGIS GeoAnalytics Support (パブリックプレビュー)
Esri と Microsoft が提携し、ArcGIS GeoAnalytics for Microsoft Fabric という Spark ネイティブの空間分析ライブラリが提供されています。Fabric Runtime 1.3 上で動作するこのライブラリを利用すると、ノートブックや Spark ジョブ定義内で Esri の 180 以上の空間関数・ツールを呼び出し、空間データの取り込み・変換・集計・可視化が可能になります。現在は パブリック プレビュー 段階で、追加ライセンス不要で利用できます。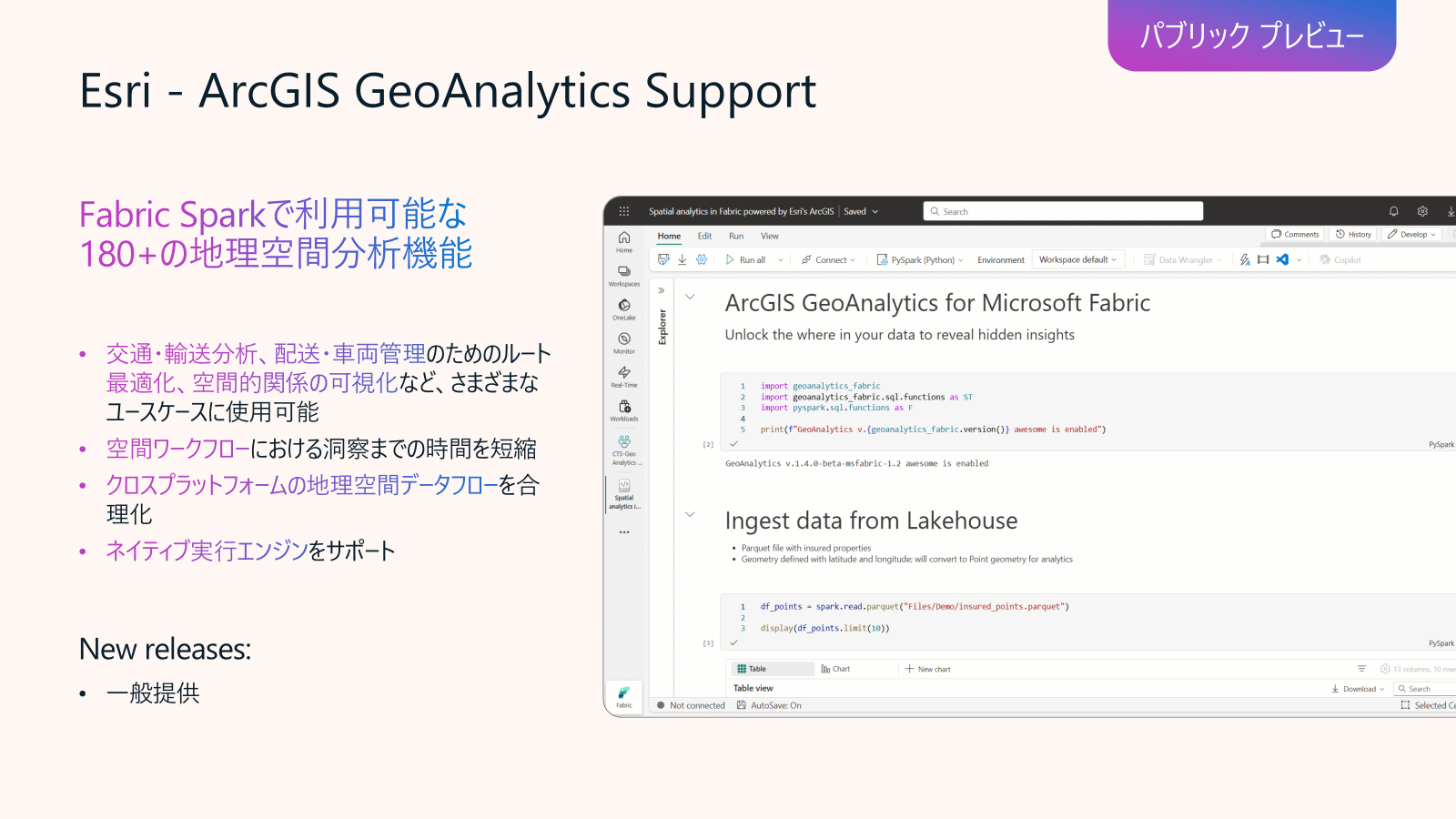
Data Engineering in Fabric アップデート9: NotebookとUser Data Functions の統合 (パブリックプレビュー)
Notebookでも、notebookutilsで、あらかじめに定義したUser Data Funtions (UDF) を確認でき、そして実行できます。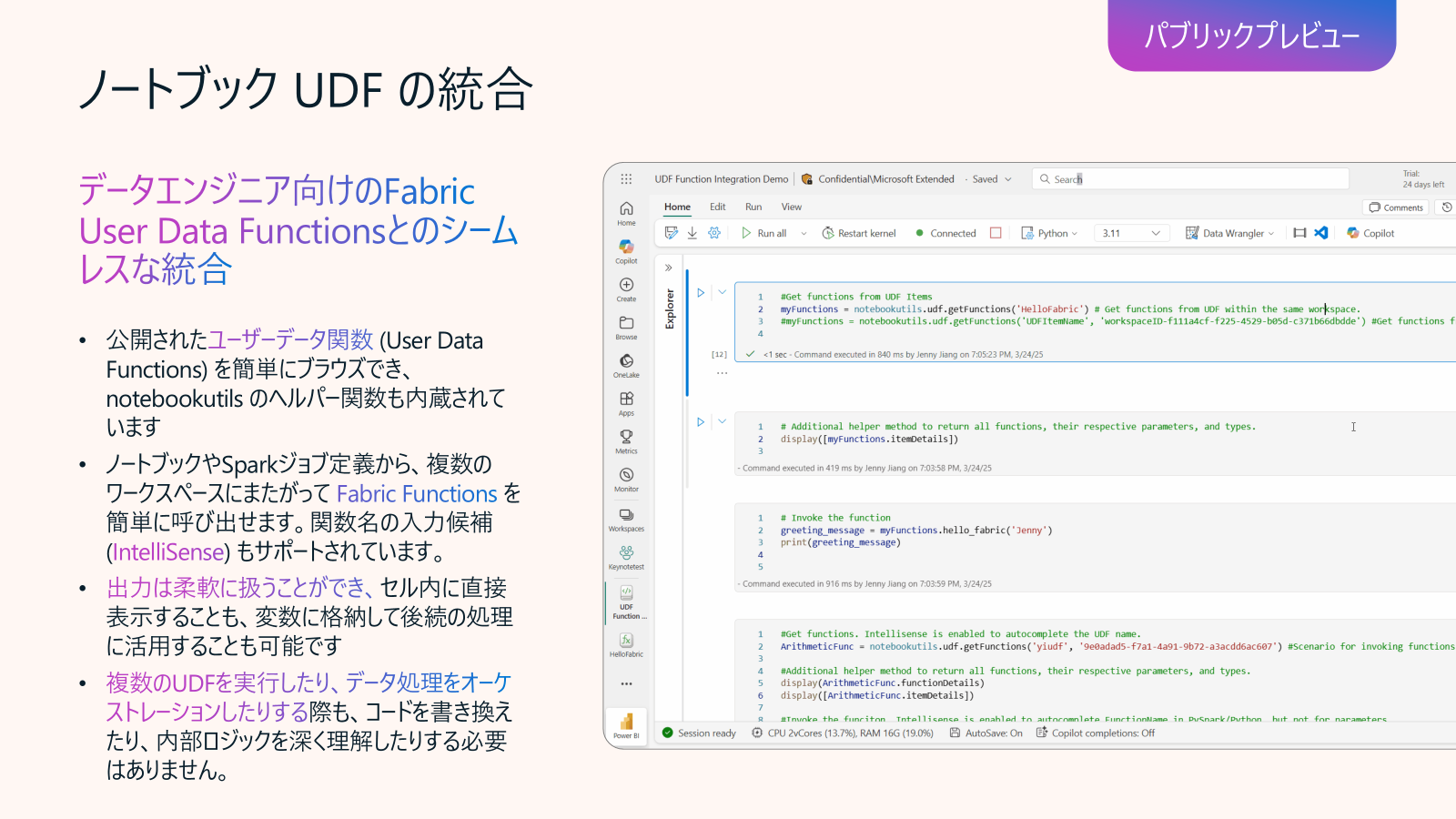
Data Engineering in Fabric アップデート10: ネットワークセキュリティ- Outbound アクセス保護 (プライベートプレビュー)
Workspace プライベートリンクの一部ですが、明示的に承認されたデータエンドポイントのみに限定し、オープンなインターネットエグレスは行わないアプローチです。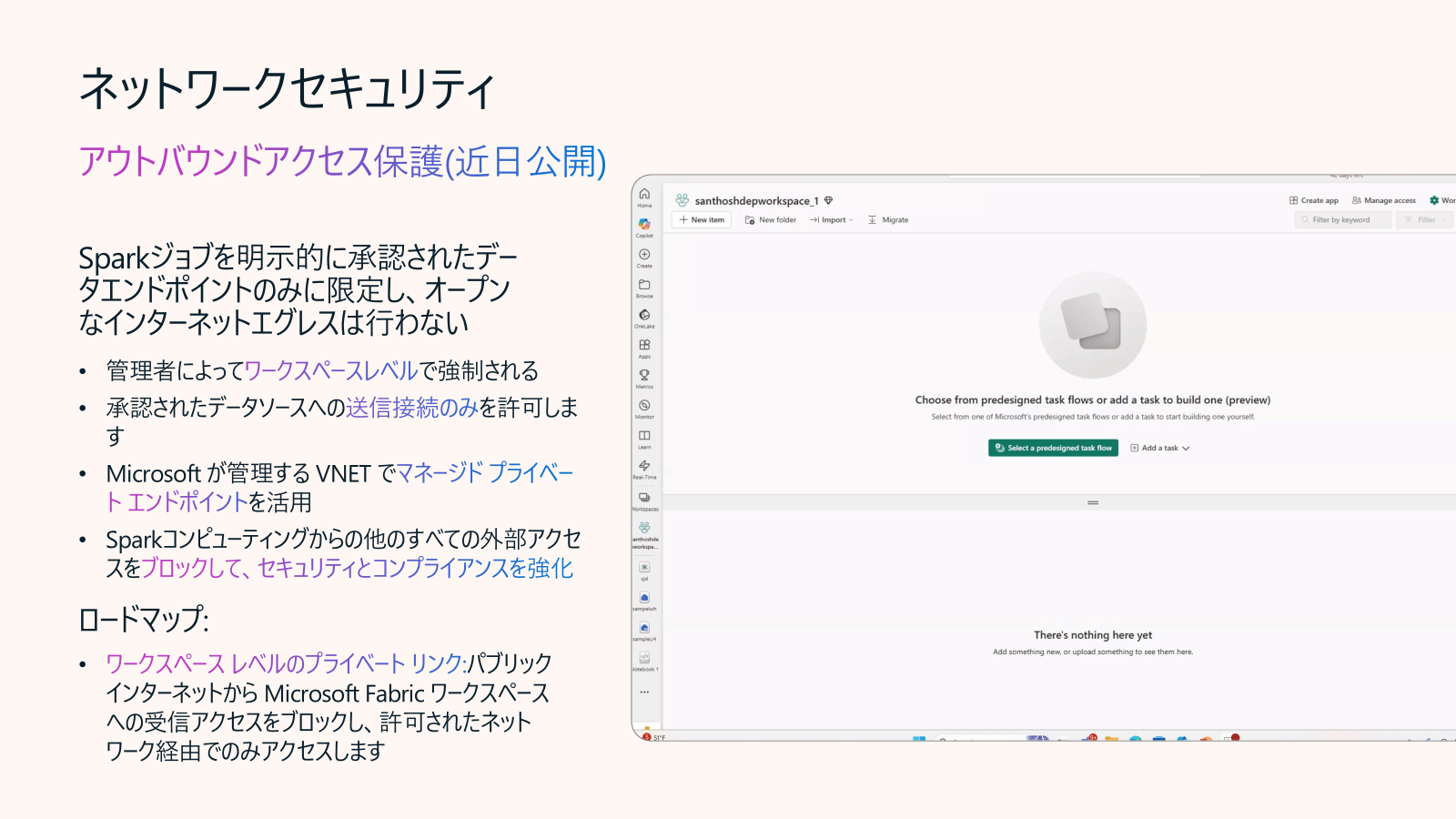

Data Warehouse in Fabric アップデート1: 結果セットのキャッシュ (パブリックプレビュー)
クエリ結果セットキャッシュは、クエリ結果をユーザーデータベース内に自動的にキャッシュし、再利用によって再計算を不要にすることで、クエリ応答性を飛躍的に向上させる機能です。キャッシュの有効化はデータベース単位・セッション単位で制御可能で、キャッシュヒット時は並列スロットを消費せず、コンカレンシー制限にもカウントされません。また、1 TB / DB の上限や、非決定論的関数 / UDF / RLS テーブルなど一部クエリはキャッシュ対象外となる制限も明示されています。
この仕組みは、自動キャッシュ保存になっています。最初にクエリを実行すると、その結果をユーザーデータベース内にキャッシュとして永続化します。以降同一クエリが実行されると、再計算せずにキャッシュ結果を直接返却します。そのおかげで、コスト節約にもつながります。キャッシュヒット時は計算リソース(Concurrency Slots)を消費せず、リソース使用量とコストを削減できます。
こちらの機能は、重複実行、繰り返し実行のクエリに有効です。
ALTER DATABASE YourDatabase> SET RESULT_SET_CACHING { ON | OFF };
SET RESULT_SET_CACHING { ON | OFF };

Data Warehouse in Fabric アップデート2: コールドクエリのパフォーマンスの向上 (GA)
コールドクエリは、初期実行するクエリのことです。Fabric DWは、データを書き込むために、OneLakeに、Parquetファイルを書き出します。そして、そのParquetの書き出しは、トランスコーディングというプロセスがあります。今までは、同期トランスコーディングでしたが、非同期トランスコーディングを変更になりました。そして、非同期でありながら、トランスコーディングプロセスが複数の行グループで並行に行います。その結果、I/O操作の待ち時間が短縮され、トランスコーディングでバックエンドノードの使用可能なすべてのCPUコアも利用できるように、パフォーマンス改善のアプローチとなります。
Data Warehouse in Fabric アップデート3: Proactive Statistics Refresh (パブリックプレビュー)、Incremental Statistics Refresh (パブリックプレビュー)
Proactive Statistics Refresh は、データの更新タイミングやクエリ実行パターンをリアルタイムに監視し、変更があったテーブル統計を自動的に再構築する機能です。
Incremental Statistics Refresh は、パーティション化テーブルの統計情報をパーティション単位で更新し、全体再構築のコストを大幅に削減する機能です。SQL Server 2014 以降の Auto Create Incremental Statistics と同様に、各パーティションの更新量を把握し、必要な統計だけを部分的に更新する仕組みを採用しています。
Data Warehouse in Fabric アップデート4: Custom SQL Pool (プライベートプレビュー)
Azure Synapse Analyticsを利用している方は、Dedicated SQL pool workload managementという機能があります。
ロールごとにグループ分けの定義でしたが、Fabric Data Warehouseのカスタム SQL プールでは、ユーザーが管理するワークロードの分離境界と、バースト可能な容量制限を制御する機能が提供されます。考え方は非常に似ています。SQL Endpointの接続文字列で、Appで定義したうえ、該当機能を利用します。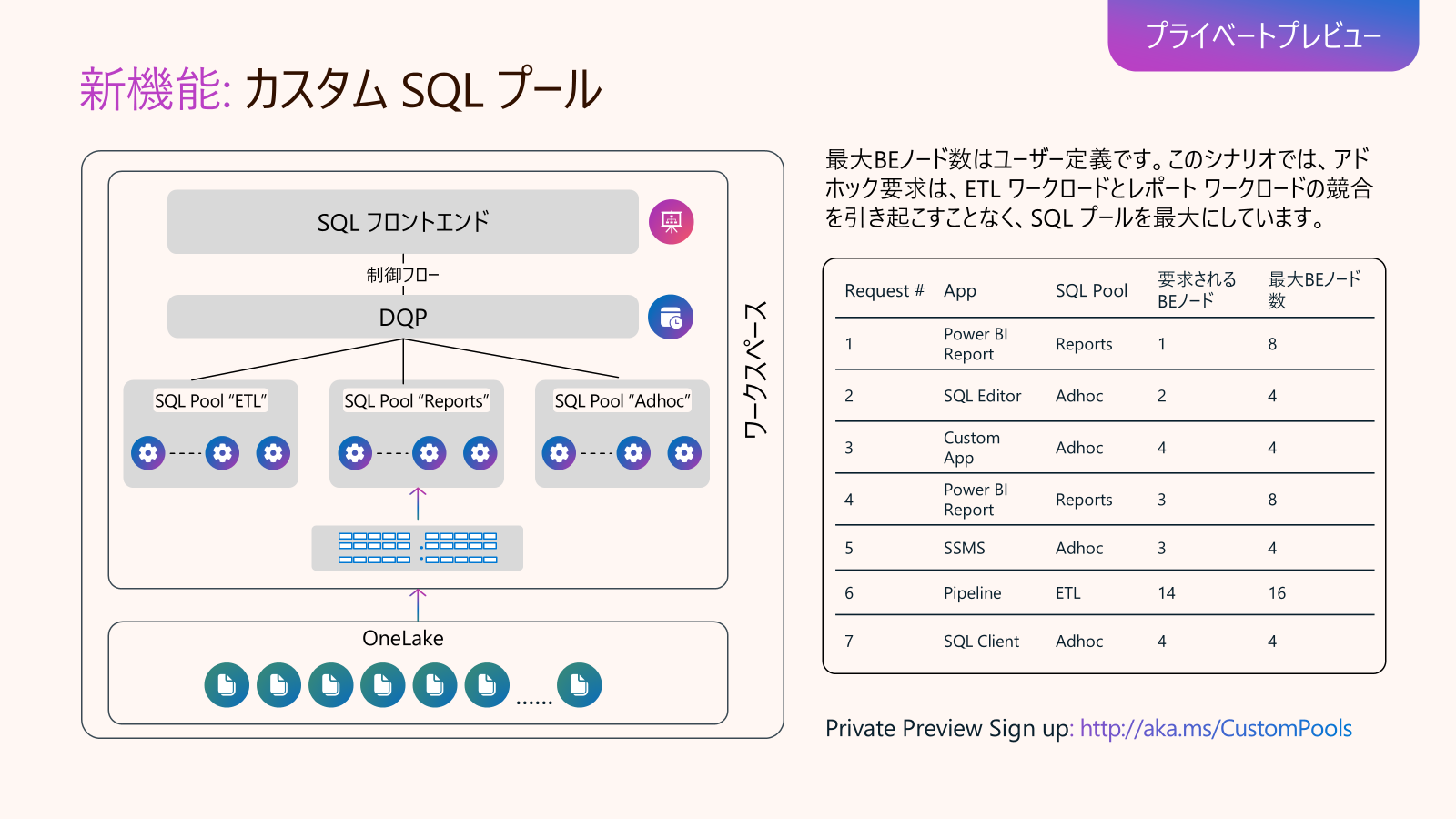

今後は、正規表現も対応できるようになります。
Data Warehouse in Fabric アップデート5: Data Clustering (プライベートプレビュー)
データ クラスタリングは、ユーザーが取り込み時にデータを同じ場所に配置するための列を指定し、読み取り時にファイルのスキップを実行できるようにすることで、読み取りパフォーマンスを高速化します。つまり、なるべくDelta Parquetのファイルのスキャン範囲を減らし、同じ場所に配置する仕組みです。
下記のように、WITHの後のCLUSTER BYに、指定するカラム単位で、近場の配置場所に格納していきます。
CREATE TABLE testtbl1 (
col1 bigint,
col2 bigint,
col3 date)
WITH (CLUSTER BY (col1, col2))
Data Warehouse in Fabric アップデート6: Warehouse Snapshots (パブリックプレビュー)
Warehouse Snapshots はプレビュー機能として提供され、ユーザーは任意の時点のデータウェアハウスを読取り専用のスナップショットとして最大30日間保持・参照できるため、リアルタイム更新中でも一貫性のある分析環境を簡単に提供できます。ユーザーは同じ接続文字列を使って過去のバージョンをシームレスにアクセス可能で、更新中の本番環境へ影響を与えずに安定した分析が行えるアプローチです。
ユースケースとしては、例えば、リアルタイム更新中の Data Warehouse データを、スナップショット時点の状態でロックダウンし、分析ユーザーに提供できるため、レポートの結果ずれを防ぎます。また、過去のスナップショットを利用して、異なる時点でのデータ比較やトラブル発生時の迅速なリカバリ(同一リージョン内)に活用可能ですし、テスト、検証環境でも役立ちます。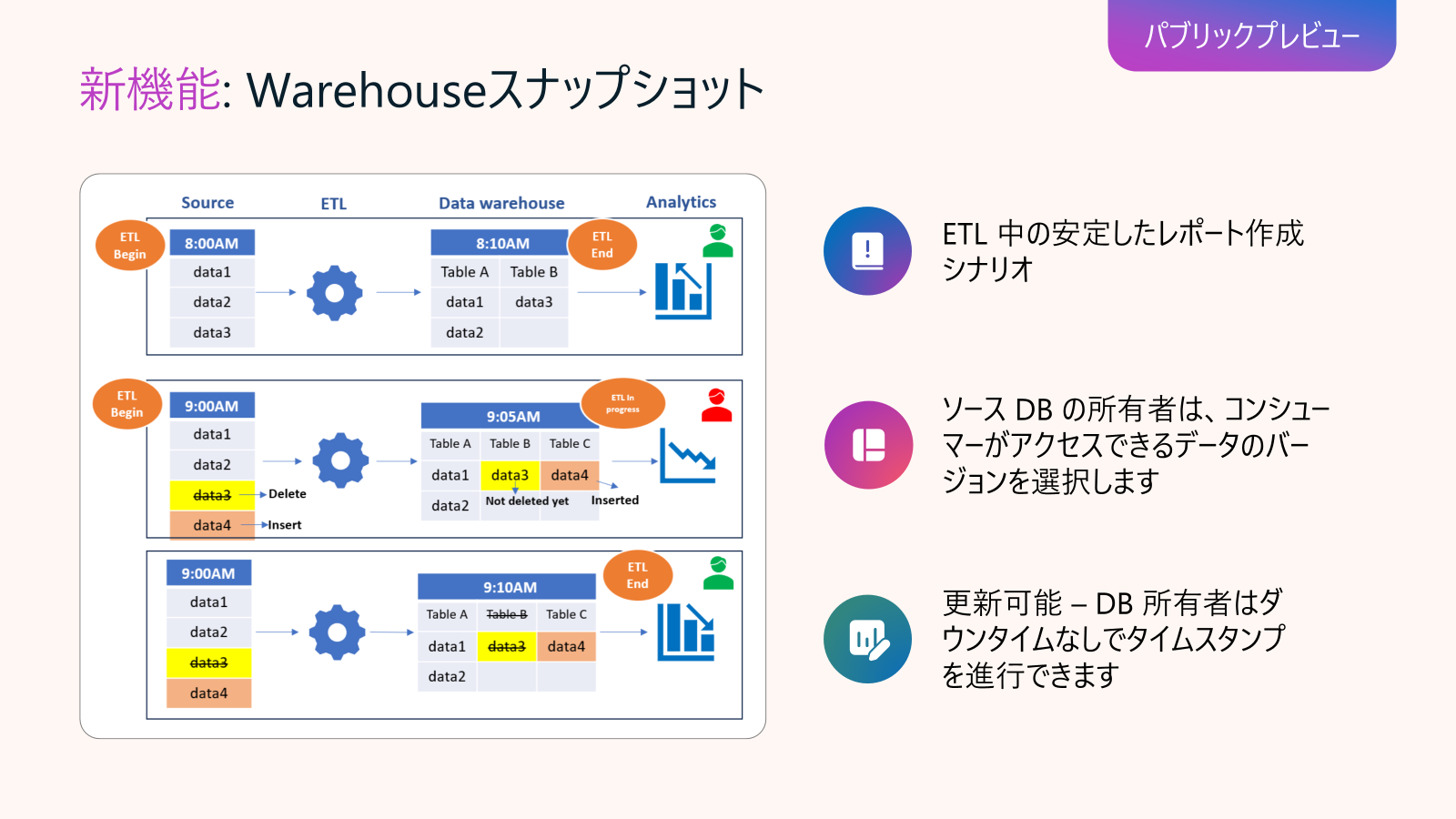
Data Warehouse in Fabric アップデート7: SQL audit logs (パブリックプレビュー)
この機能は、データベース イベントを記録して監査ログに書き込む SQL 監査ログ機能の一般提供を追跡し、これにより、お客様は sys.fngetauditfilev2 を使用して監査ファイルをクエリしたり、OneLake から .xel ファイルにアクセスして監査とコンプライアンスを行うことができます。
Data Warehouse in Fabric アップデート8: Code Migration Assistant (パブリックプレビュー)
SQL Server、Synapse 専用 SQL プール、およびその他のウェアハウスの Fabric Data Warehouse への移行を加速するように設計されており、ユーザーはソース データベースからコードとデータを移行し、ソース スキーマとコードを Fabric Data Warehouse に自動的に変換し、データ移行を支援し、AI を活用した支援を提供できます。具体的には、DACPAC ファイルを使って既存オブジェクトのメタデータ(テーブル、ビュー、関数、ストアドプロシージャ、セキュリティオブジェクトなど)を取り込み、AI(Copilot)を活用して T-SQL の互換性問題を検出・修正提案し、移行不能なスクリプトを対話的にアップデートできます。移行元のデータソースに対して、アセスメントも行ってくれます。例えば、移行対象のオブジェクトが Fabric Data Warehouse の T-SQL Surface Area と互換性がない場合、Code Migration Assistant が自動で問題を検出し、型変換や構文修正を AI が提案します。今後、Synapse Spark や Lakehouse へのコード移行拡大や、Copilot 以外の AI モデルサポートも検討中とされています。

Data Science in Fabric アップデート1: Real-Time Endpoints for Machine Learning Models (パブリックプレビュー)
Fabricは、PREDICTによるバッチスコアリングの既存の機能に加えて、データサイエンティストが、自動的に構成される安全でスケーラブルなオンラインエンドポイントを使用して、登録された任意のMLモデルからリアルタイムの予測を提供できるようにします。これらのエンドポイントは、他の Fabric エンジンまたは外部アプリから呼び出すことができるため、ユーザーはモデルをデプロイして、幅広く信頼性の高い消費を実現できます。
こちらの機能を使うと、低レイテンシーかつスケーラブルなリアルタイム推論が可能になり、外部アプリケーションや他の Fabric コンポーネントから REST API 経由で予測結果を取り込みやすくなります。バックエンドには自動スケーリング機能が備わり、認証・認可はキー/トークンベースの方式を選択できるほか、従来は Azure Machine Learning とのハイブリッド構成が必要だったケースが Fabric 単独で完結するようになります。
Data Science in Fabric アップデート2-1: CI/CD for Fabric Data Agent (パブリックプレビュー)
Fabric データ エージェントの CI/CD を有効にします。CIプロセスに統合された自動テストにより、デプロイ前にデータエージェントの設定に対するすべての変更が検証され、エラーを早期に発見し、信頼性の高い更新のみが本番環境に到達するようにするなど、CI/CDパイプラインを適切に実装すると、大きなメリットが得られます。構造化されたデプロイ プロセスでは、開発ワークスペースから、運用環境をミラーリングするテスト ワークスペースを経て、最終的に運用環境に移行し、ワークスペース固有の構成を自動的に適用します。この迅速で信頼性の高いイテレーションにより、運用エラーが減少するだけでなく、ユーザーからのフィードバックや進化するビジネスニーズに対応して改善や修正を迅速に進めることができ、最終的にはエンドユーザーエクスペリエンスの向上につながります。
Data Science in Fabric アップデート2-2: Data Agent Large Schema Support (パブリックプレビュー)
運用データウェアハウス、レイクハウス、セマンティック モデル、SQL DB には、数百から数万のテーブル、ビュー、関数、メジャーが含まれています。ユーザーがセマンティックモデル、レイクハウス、データウェアハウスにデータエージェントを活用するのを妨げるのを防ぐには、本番環境のデータベースシステムをサポートすることが重要です。このドキュメントでは、データ エージェントのシナリオ全体で運用規模のデータベース システムとセマンティック モデルをサポートするための要件について説明します。 – UX を有効にして、ユーザーが大規模なスキーマをデータ エージェントに読み込み、オブジェクトを簡単かつ効率的に選択できるようにする。- エージェント レベルのサポートを追加して、LLM が正しいデータ ソースを選択するときに大規模なスキーマにスケーリングできるようにします。ツール レベルのサポートを追加して、LLM を入力として大規模なスキーマにスケーリングし、信頼性の高い応答を生成できるようにします。
Data Science in Fabric アップデート2-3: Data Agent Support for Views and Functions (パブリックプレビュー)
データ エージェントは SQL Analytics エンドポイントを介してのみ T-SQL テーブルをサポートしますが、運用 SQL システムは、複雑な操作を実行し、データをコンシューマーの特定のユース ケースにスコープするために、ビューと関数に大きく依存します。データ エージェントは、これらのビューと関数を活用して、より複雑なクエリを生成できます。
Data Science in Fabric アップデート2-4: Data Agent to Support Mirrored Databases (パブリックプレビュー)
Data Agent でミラーリングされた SQL DB をサポートすることで、技術系ユーザーと非技術系ユーザーの間のギャップが埋められ、より効率的に共同作業を行い、正確でタイムリーなデータに基づいて情報に基づいた意思決定を行うことができます。また、この統合により、企業は既存の SQL DB への投資を最大限に活用しながら、Microsoft Fabric のデータ エージェントの高度な機能を活用することができます。
Data Science in Fabric アップデート2-5: Data Agent SDK (パブリックプレビュー)
Fabric Notebookを使って、Data Agentのエンドポイントを連携します。
Data Science in Fabric アップデート3: AI Functions for LLM-Powered Text Enrichment and Transformation (パブリックプレビュー)
FabricのAI機能により、ノートブックのユーザーは、テキストの要約、翻訳、分類、感情分析、文法修正などのタスクをシームレスに実行でき、一般的なエンリッチメントのための簡素化されたAPIを提供し、ユーザーがより少ないコード行でそれらをより簡単に適用できるようにします。これらの関数は、最初は pandas DataFrames 上で利用でき、最終的には Spark、SQL、および Fabric 全体の他のプログラミング サーフェスを介して利用できるようになります。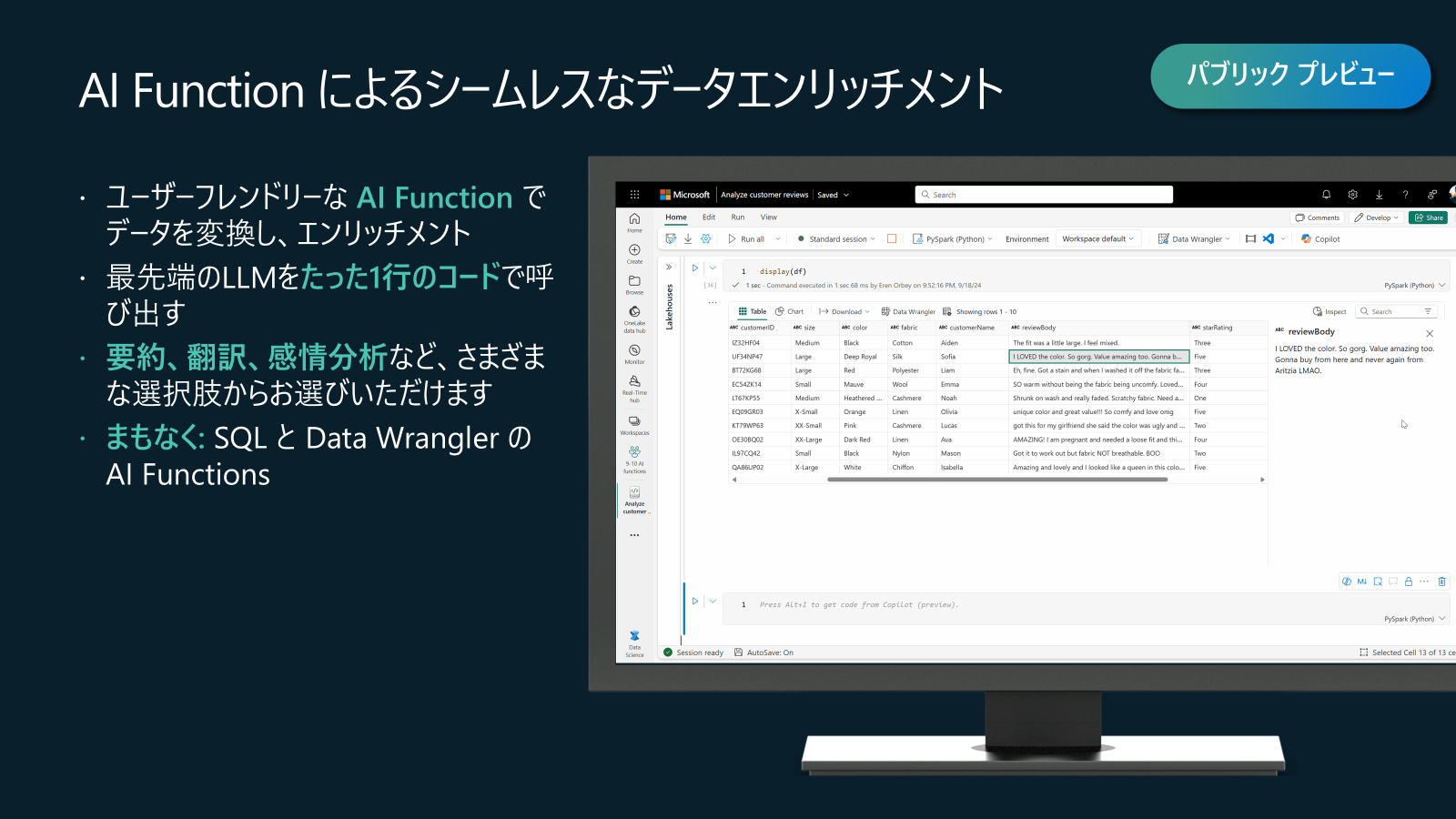
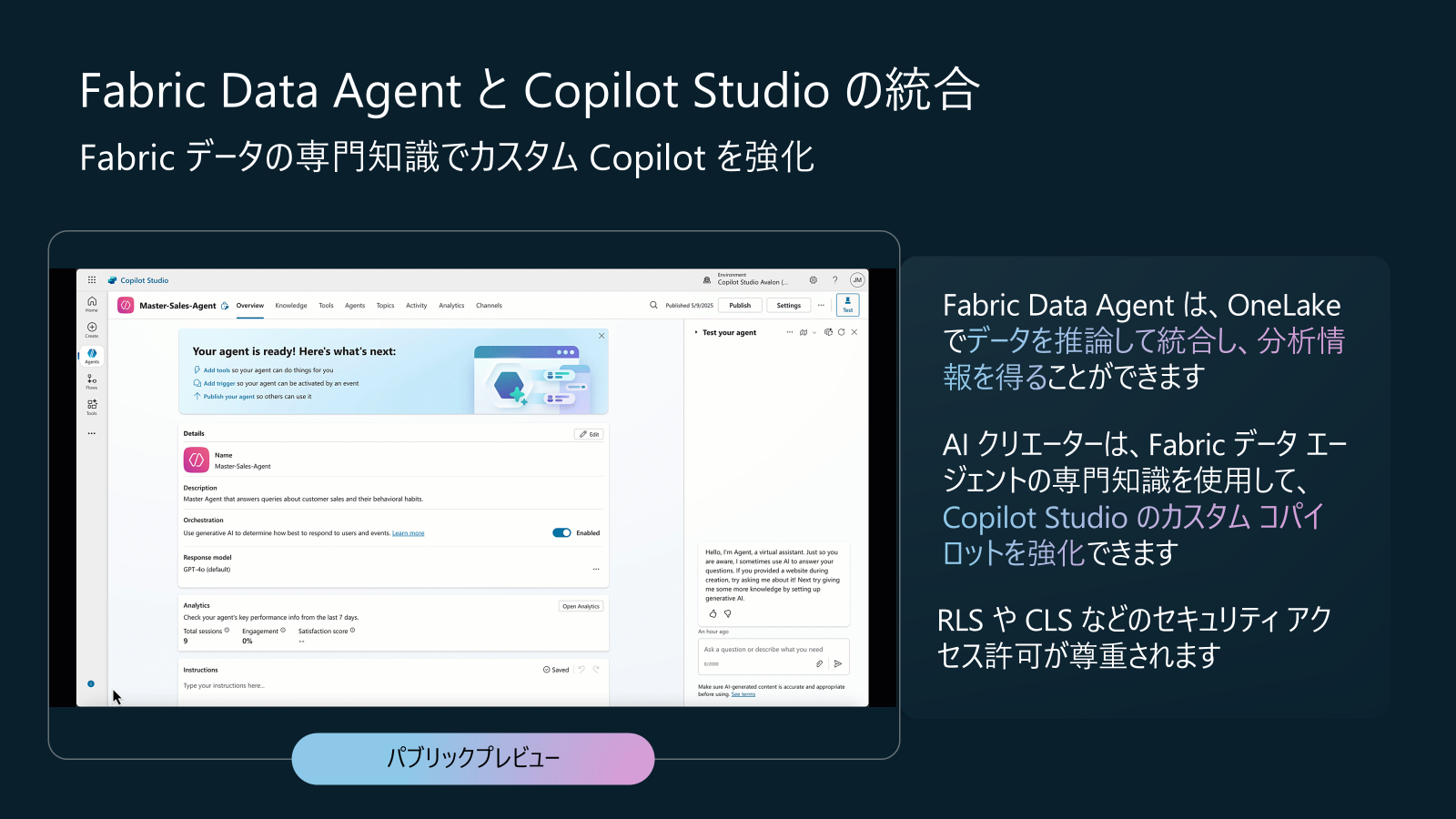
Data Science in Fabric アップデート4: Fabric Data Agent と Copilot Studio の統合 (Build 2025: パブリックプレビュー)
Fabric Data Agentを Copilot Studio カスタムエージェントに組み込むことで、Copilot Studio の多彩なマルチエージェントワークフローから OneLake 内のデータへ自然言語でアクセスし、インサイト取得やアクション実行が可能になります。エージェント間のタスク委譲(マルチエージェントオーケストレーション)にも対応し、Teams や Microsoft 365 Copilot などのチャネルに展開して、組織横断でデータ駆動の AI アシスタント体験を実現します。

Database in Fabric アップデート1: SQL Server 2025 CTP2.0 (パブリックプレビュー)
SQL Server 2025 では、Cosmos DB と同じ基になるコード、つまり、DiskANN と呼ばれるリアルタイムの変更をサポートするスケーラブルな近似最近傍検索アルゴリズムのスイートを使用します。どちらのデータベースもREG(Retrieval Augmented Generation)もサポートしていると述べ、SQL Server 2025は、アプリケーション開発用のLangChain、Semantic Kernel、Entity Framework Coreなどの一般的なAIフレームワークとのシームレスな統合をサポートすると付け加えました。
Microsoft Fabricとの連携といえば、Mirroringになります。Synapse Link for SQL Server 2025は存在せず、Mirroring for SQL Server 2025に置き換えます。
SQL Server は Fabric の Worklaodではないものの、Mirroring for SQL Server 2025があります。それは、CDCを使ったMirroringの仕組みではなく、CES (Change Event Streaming) を使ったMirroringになります。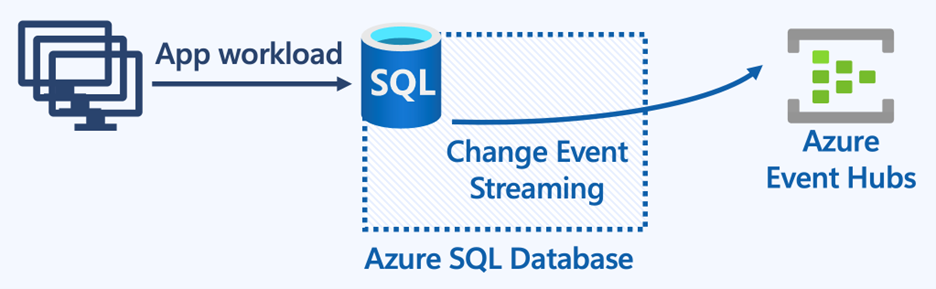
今後は、CTP2.1などのをリリースする予定です。

Azureなら、VMテンプレートですぐにDeveloper Editonをデプロイできます。
SQL Server 2025 Preview downloadは下記のURLからインストーラーを経由で、ISOファイルを落とせます。
Database in Fabric アップデート2: Cosmos DB in Fabric (Build 2025: パブリックプレビュー)
DatabaseのWorkloadに、新たにCosmos DBが追加されました。従来のSQL Databaseに加え、NoSQL対応のCosmos DBもサポートされるようになり、今後さらに機能拡張が進む予定です。
このCosmos DBの最大の特徴は、Fabricの一部として提供されるSaaS版であることです。これまでAzure Cosmos DBのデータをFabricに取り込むには、「Mirroring for Cosmos DB」を利用していましたが、新たに提供される「Cosmos DB in Fabric」では、SQL Database in Fabricと同様に、OneLakeにデータがParquetファイル形式で自動的に同期されます。そのため、追加の設定やツールなしで、Cosmos DBのデータを簡単に分析や活用ができるようになります。
また、Fabricのキャパシティユニット(Fabric CU)を利用してリソース管理やスケーリングも可能です。
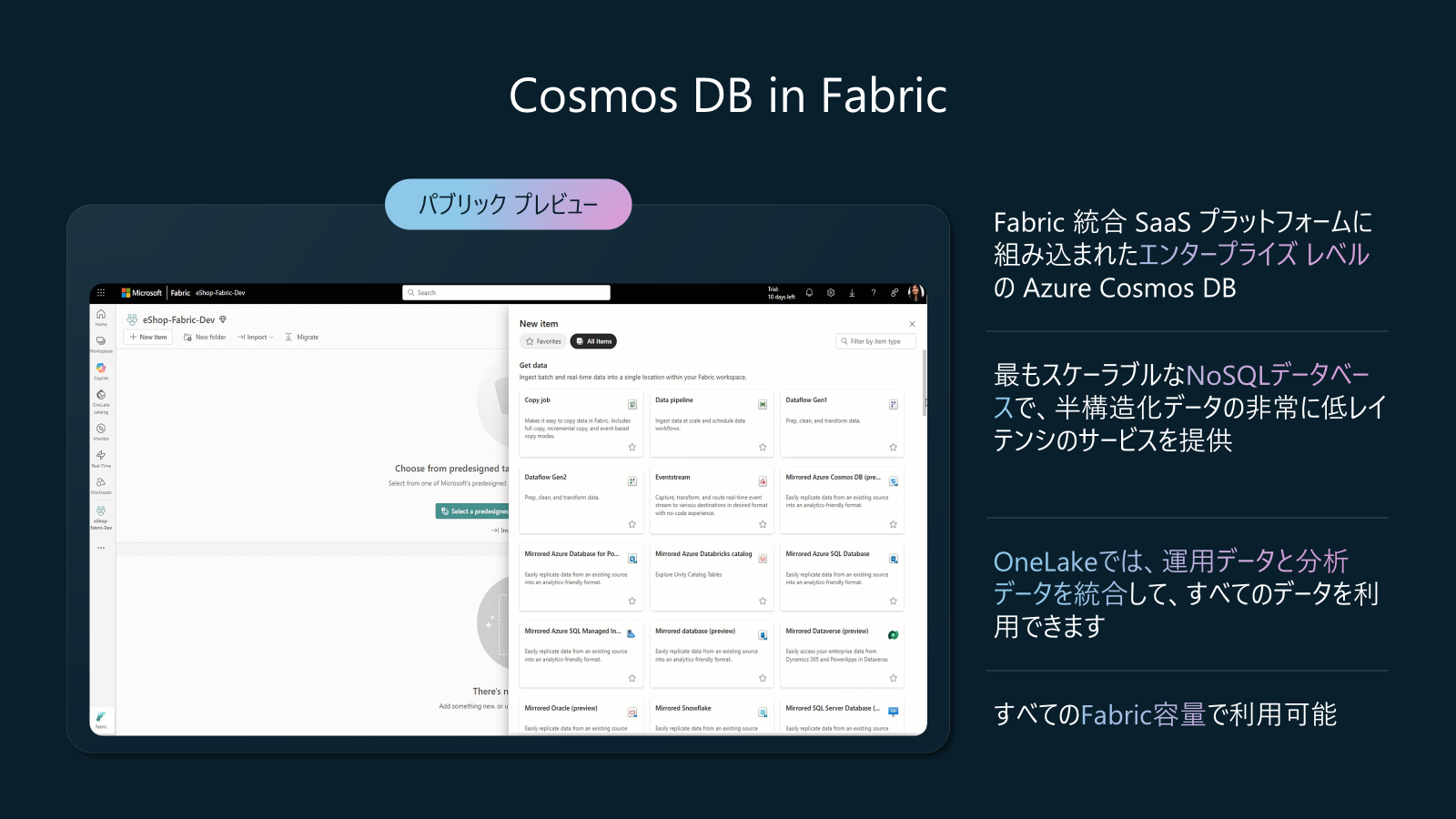
現在、SQL Database in Fabric及び、Cosmos DB in Fabric、両方ともパブリックプレビューです。
Database in Fabric アップデート3: SQL Database in Fabric (パブリックプレビュー)
QL Database in Microsoft Fabric は、Azure SQL Database のエンジンをベースにしたトランザクショナル(OLTP)データベースで、Fabric 上で運用データの格納・管理から分析シナリオへのシームレスな展開までを一貫してサポートします。Fabric ワークスペース内に作成すると、データは自動的に OneLake に Parquet 形式でレプリケートされ、Spark、ノートブック、Power BI、Copilot などのサービスでリアルタイム活用が可能になります。エンタープライズクラスのスケーラビリティやインテリジェントパフォーマンス機能はデフォルトで有効化され、従来の Azure SQL Database と同様の T-SQL および TDS 接続が利用できる点が大きな特徴です。
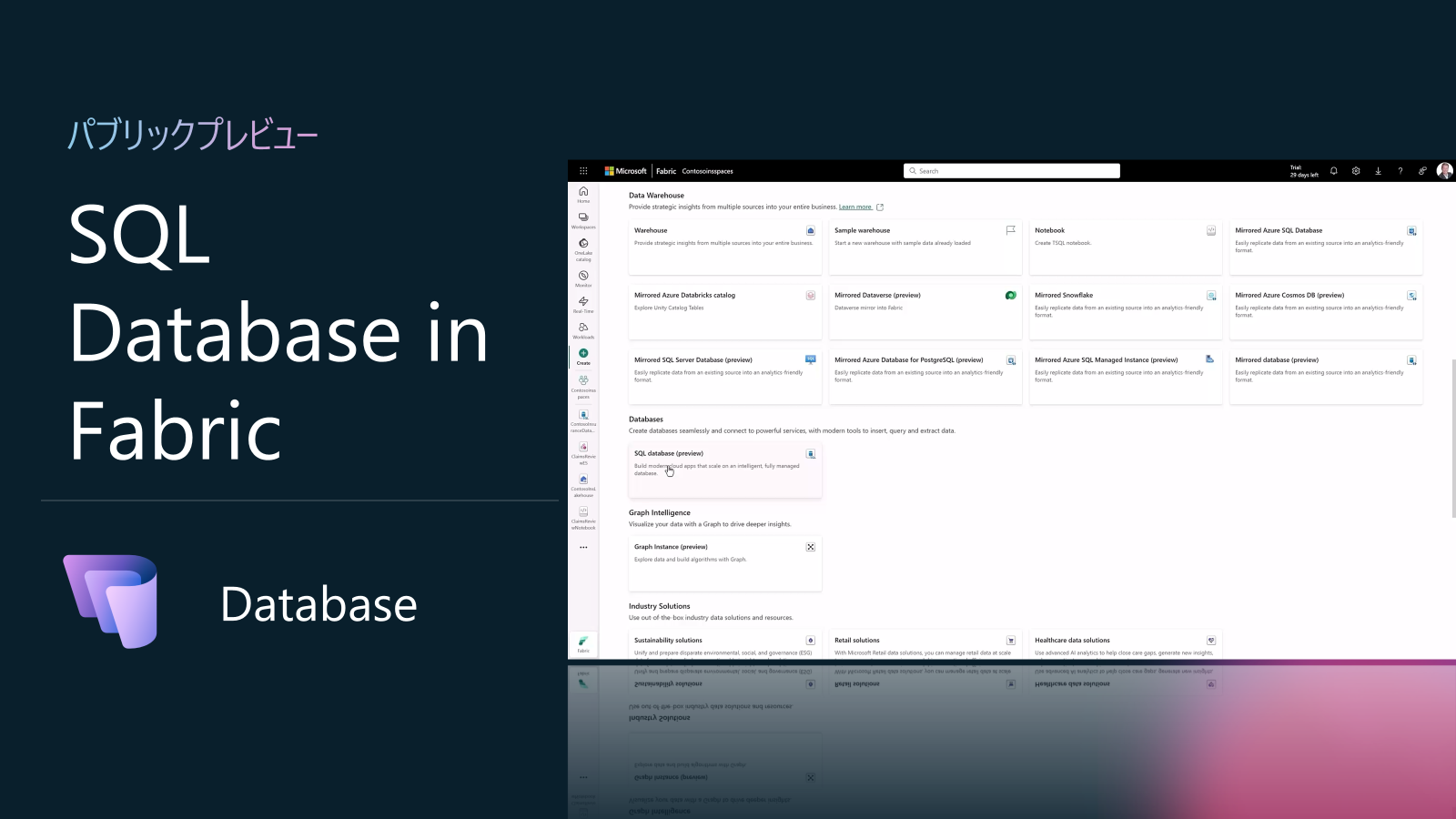
今後のロードマップは下記をご参考ください。


Microsoft Fabric の Real-Time Intelligence は、イベント駆動型シナリオやストリーミングデータ、ログデータをエンドツーエンドで取り扱う統合ソリューションです。データの取り込み(Eventstreams)、スケーラブルなストア(Eventhouse)、リアルタイムなアラート/アクション(Activator)、そして可視化(Real-Time Dashboards)や管理コンソール(Real-Time Hub)までをワンストップで提供し、データの“動き”に即応したインサイト取得と自動化を実現します。
Real-Time Intelligence in Fabric アップデート1: Digital twin builder (パブリックプレビュー)
Digital twin builder は、Fabric のリアルタイム分析基盤上で、ローカード/ノーコードの操作だけで「資産」や「プロセス」といった実世界の概念をオントロジー(用語体系)としてモデル化し、OneLake に格納された各種データソースとマッピングしてデジタルツインを構築・管理・可視化できるプレビュー機能です。
Fabric のスケーラビリティと統一セキュリティモデルを活用し、KQL や Spark、Power BI、Real-Time Dashboards などさまざまな Fabric ワークロードとシームレスに連携できます。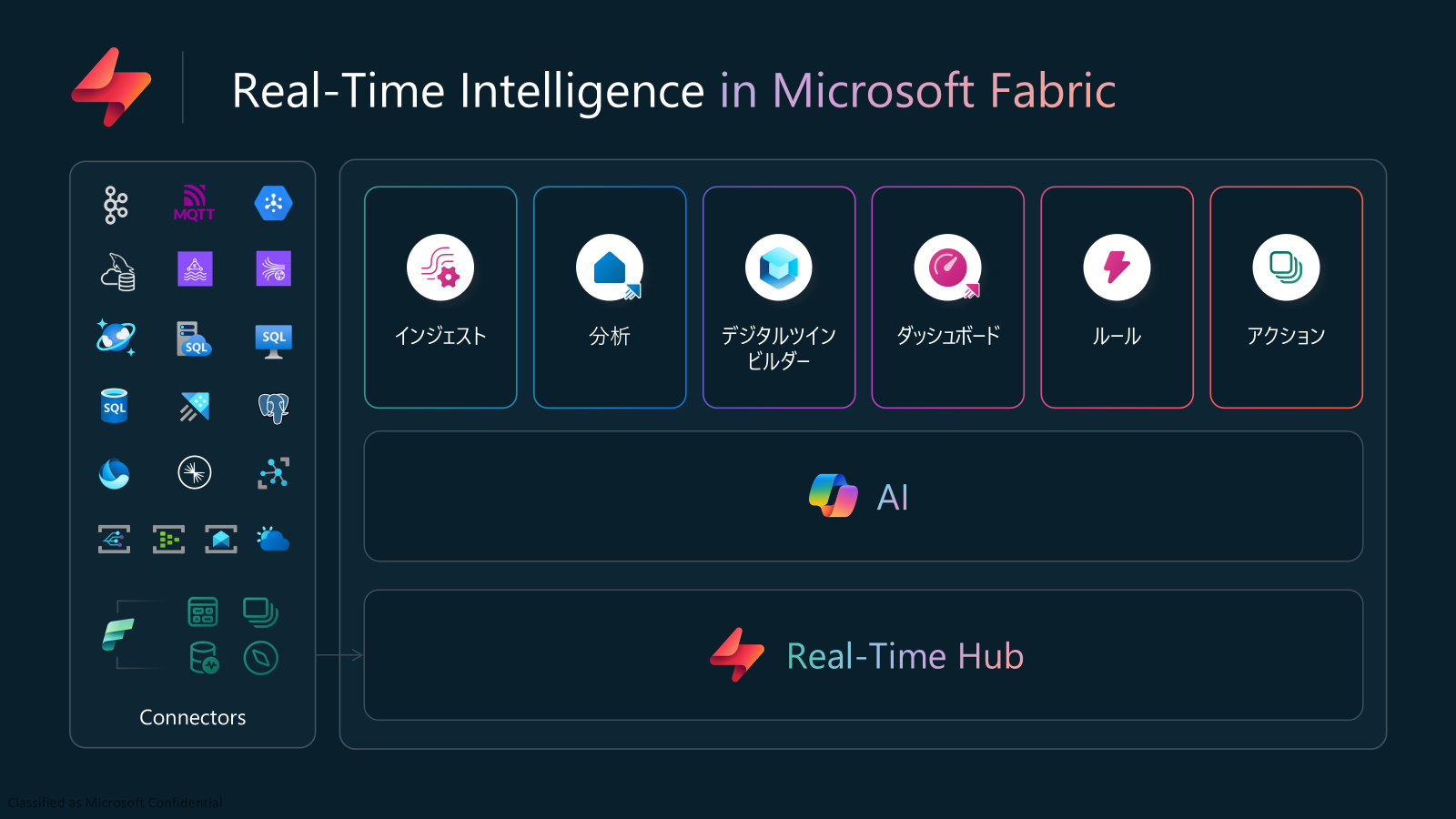
モデル化されたオントロジーは OneLake に Delta テーブルとして保存され、Spark ジョブや SQL Analytics、Power BI、Real-Time Dashboards から直接クエリが可能です。
Real-Time Intelligence in Fabric アップデート2: APIs, CI/CD & ALM (GA)
Eventstream REST API と、Eventstream CI/CD が一般提供になりました。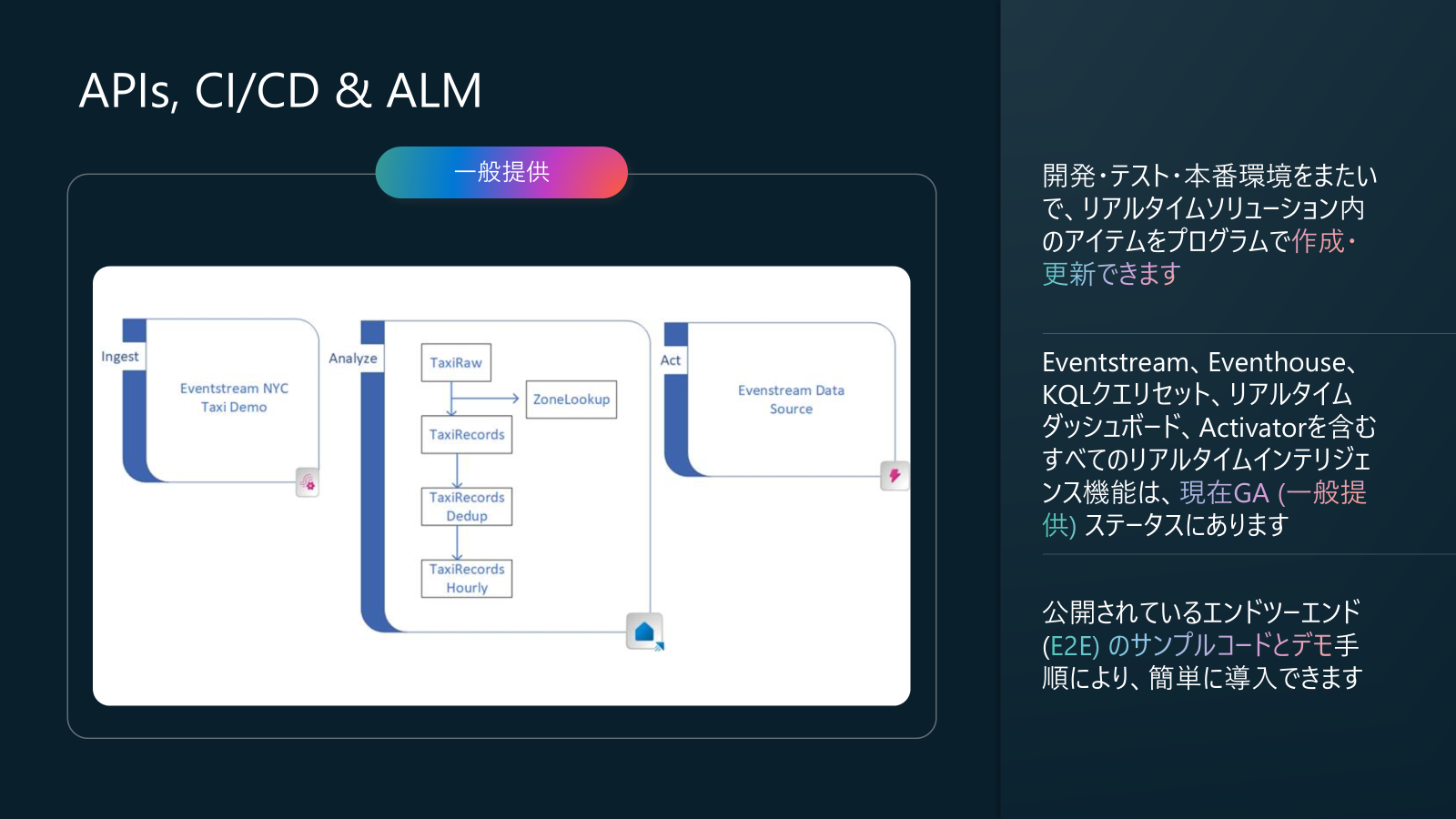
Real-Time Intelligence in Fabric アップデート3: Eventstream Managed Private Endpoint 接続 (まもなく GA)、Eventstream workspace level private link と共に、(パブリックプレビュー)
Azure EH および IoT Hub ソースのマネージド プライベート エンドポイントとの Eventstream 統合です。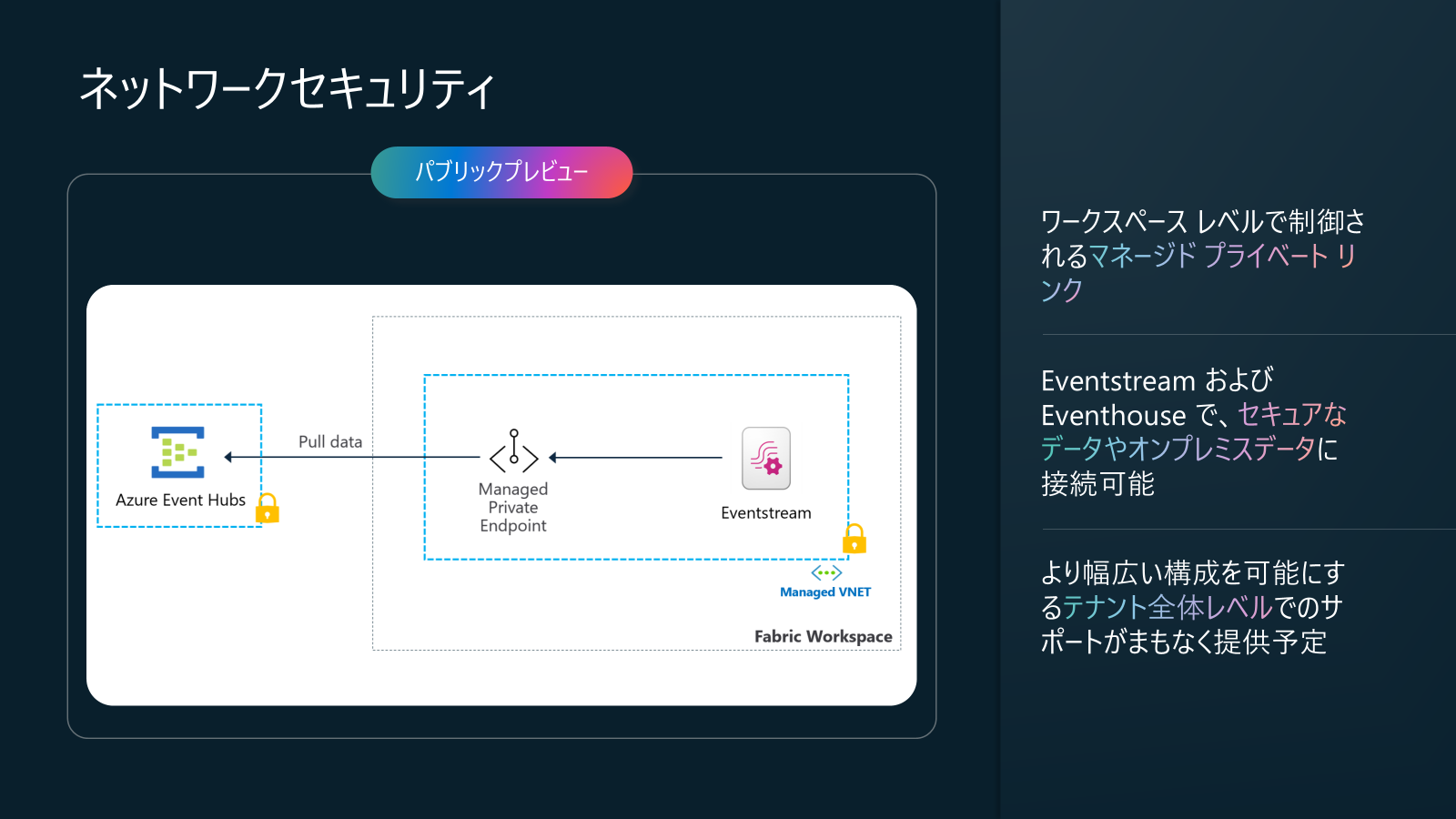
Real-Time Intelligence in Fabric アップデート4: Synapse Data Explorer Migration tool (パブリックプレビュー)
この機能を使用すると、1 つの Synapse Data Explorer クラスターから Fabric のイベントハウスにすべてのデータを移行できます。 このプロセスは、ソース クラスターのすべてのデータベースを移行先のイベントハウスに移行し、ソース クラスターのクエリとインジェスト エンドポイント URI をイベントハウスに移動します。 そのため、ソース クラスターと eventhouse エンドポイントの両方でイベントハウスを参照し、既存のインジェストとクエリが引き続き機能するようにすることができます。
Real-Time Intelligence in Fabric アップデート5: オペレーションエージェント (スニークピーク、プライベートプレビューの前段階)
こちらの機能は、ユーザーが自分の自然言語で、Copilot Studioのように、自分でAI Agentを作成できるようになります。オペレーションエージェントに「見る・判断する・通知する・行動する」力を教え込むことで、業務を自動化し、24時間体制での運用を実現できます。オペレーションチームはルーティンタスクから解放され、より戦略的で価値の高い業務に専念できるようになります。
興味がある会社は、私までご連絡ください。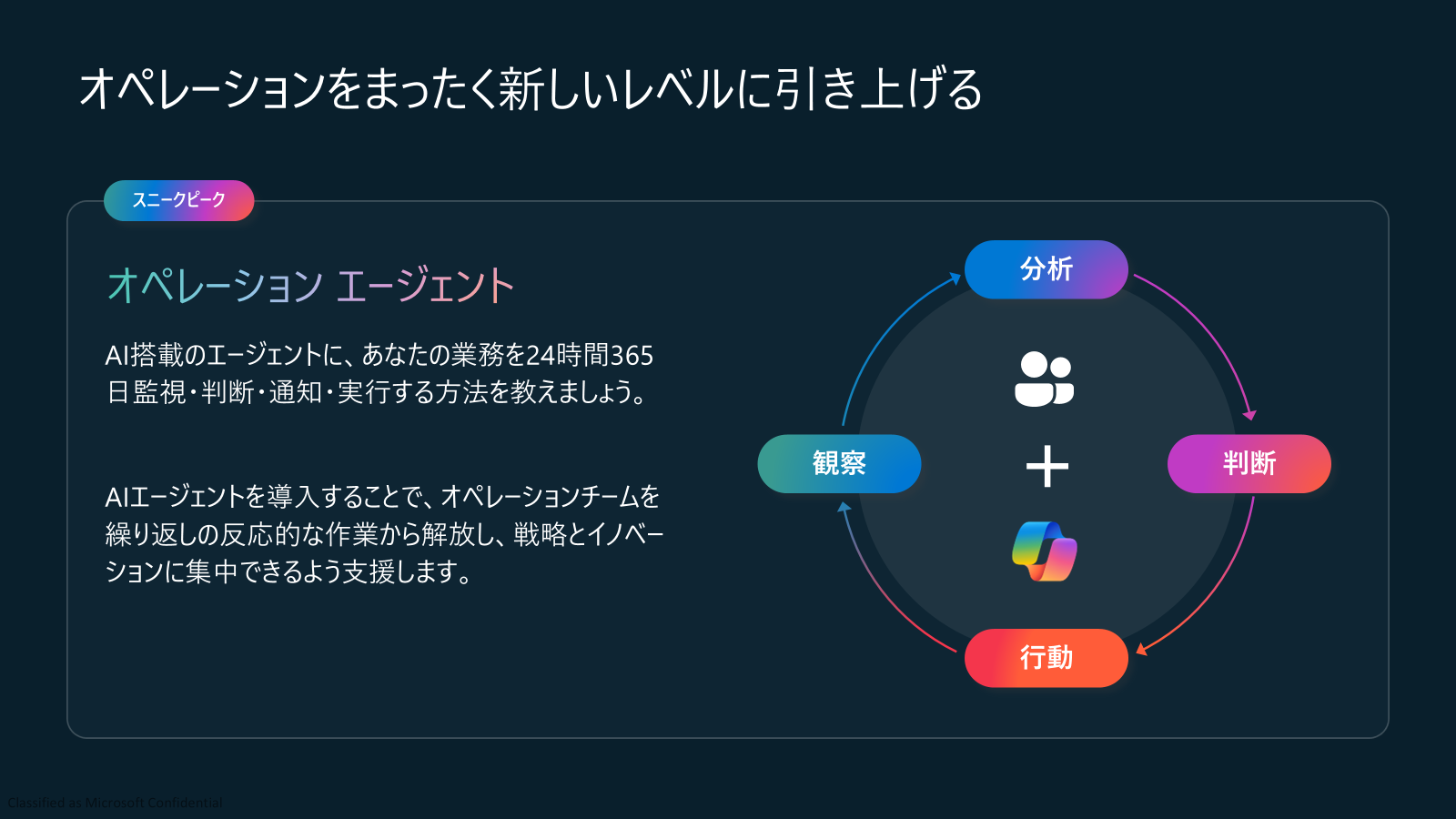

Power BI アップデート1: Direct Lake と Web での複合モデルのインポート (プライベートプレビュー)
この機能により、Direct Lake テーブルとインポート テーブルの両方を含むセマンティック モデルを作成できるため、これらのストレージ モードに柔軟性を持たせることができます。このタイプの複合セマンティックモデルは、Web 編集エクスペリエンスで直接作成および編集できます。Power BI Desktop 版ではなくて、Fabric ポータル上で、Webモデリング可能です。
Power BIのWebモデリングにおいて、インポートモデル専用の強力な新機能が導入されました。特に注目すべきは、ブラウザーから直接最新のPower Queryエディターを利用できるようになったことです。これにより、データの変換や多様なデータソースからのテーブル追加、Mクエリの編集など、これまでPower BI Desktopを使用しなければ行えなかった作業を、すべてWeb上で実行できます。
さらに、モデルのデータやスキーマの更新、データソース設定の管理、過去のモデルバージョンをオンラインで完全に復元することも可能になりました。また、ローカリゼーション(多言語対応)、アクセシビリティ、厳格モードを通じたセキュリティサポートも強化され、エンタープライズユーザーが直感的かつコンプライアンスを遵守した環境で作業できるよう改善されています。
今回のアップデートは、従来のデスクトップツールの必要性をなくし、WebブラウザーからのみのユーザーやMacユーザーにもデータモデリング機能を提供します。これにより、ブラウザーだけでPower BIモデルの保守、拡張、共同作業が行えるようになり、データモデリングのワークフローがこれまで以上に容易になります。
なお、GAに向けて、Webモデリングではインポートモデルのみがサポートされる予定です。
また、Power Query Online(PQO)を使用して、よく利用されるほとんどのデータコネクタからデータの追加や変換を行うことができますが、一部の例外(カスタムコネクタ、SAP HANAなどのキューブ型データソース、Direct Lake、Direct Query、複合モデルなど)は、現時点ではサポート対象外となります。
なお、Direct LakeおよびDirect Queryについては、今後のリリースでPQOのサポートが追加される予定です。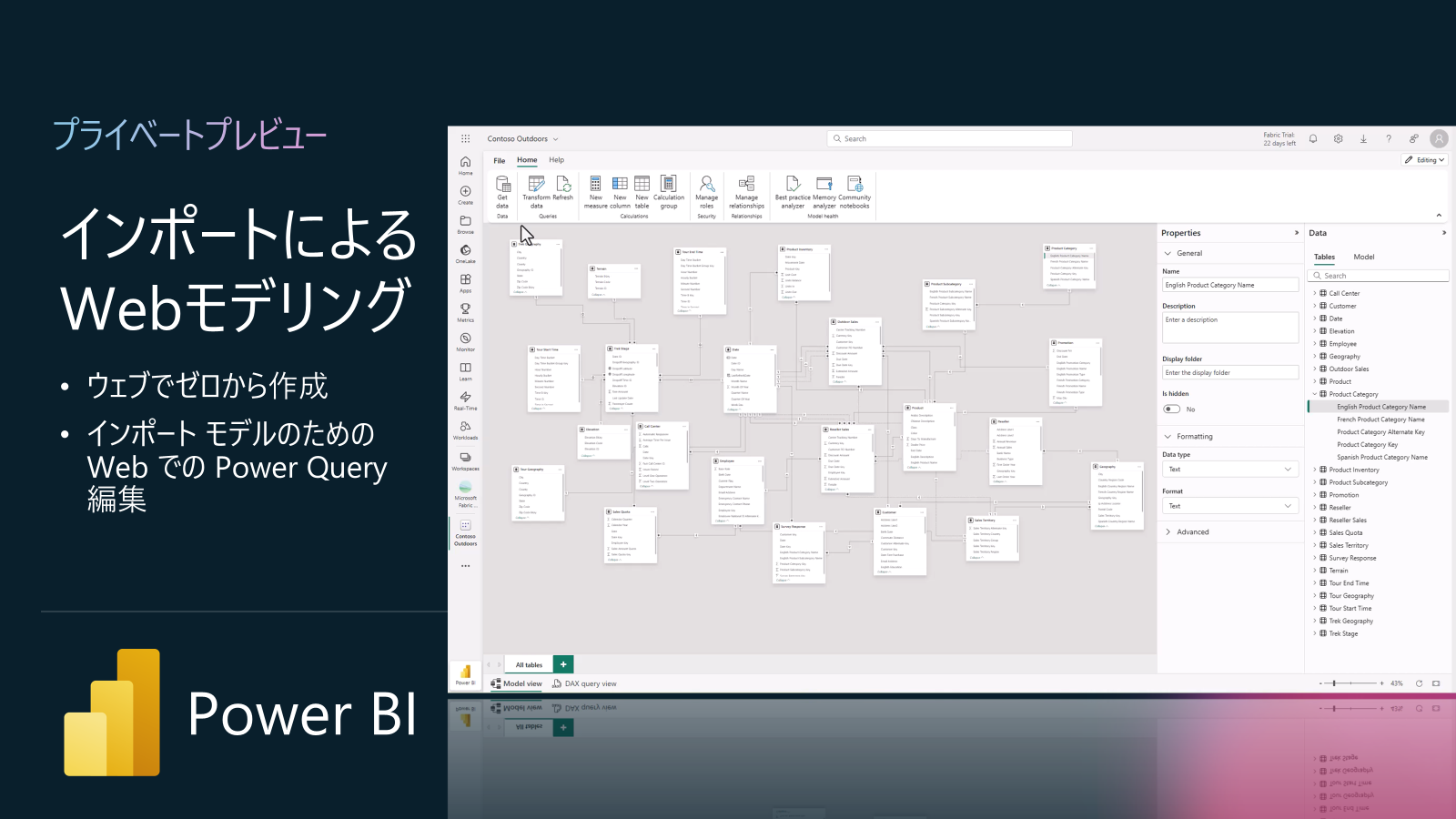
Power BI アップデート2: TMDL View (パブリックプレビュー)
TMDL ビューは、Power BI Desktop 内の表形式モデル定義言語 (TMDL) を使用した “コードとしてのセマンティック モデリング” エクスペリエンスを提供します。これにより、ユーザーは最新のコードエディターでセマンティックモデルオブジェクトの変更をスクリプト化、変更、および適用できるため、ユーザーの効率が大幅に向上します。今後のアップデートでは、モデルの翻訳、ドキュメンテーション、一括操作など、時間のかかるタスクを処理するためにCopilotが統合される予定です。
そして、今後、TMDL ビューの機能強化を行います。例えば、プレビューオプションがあります。
または、TMDL の継承オプションも用意していて、メタデータを再利用できるようになります。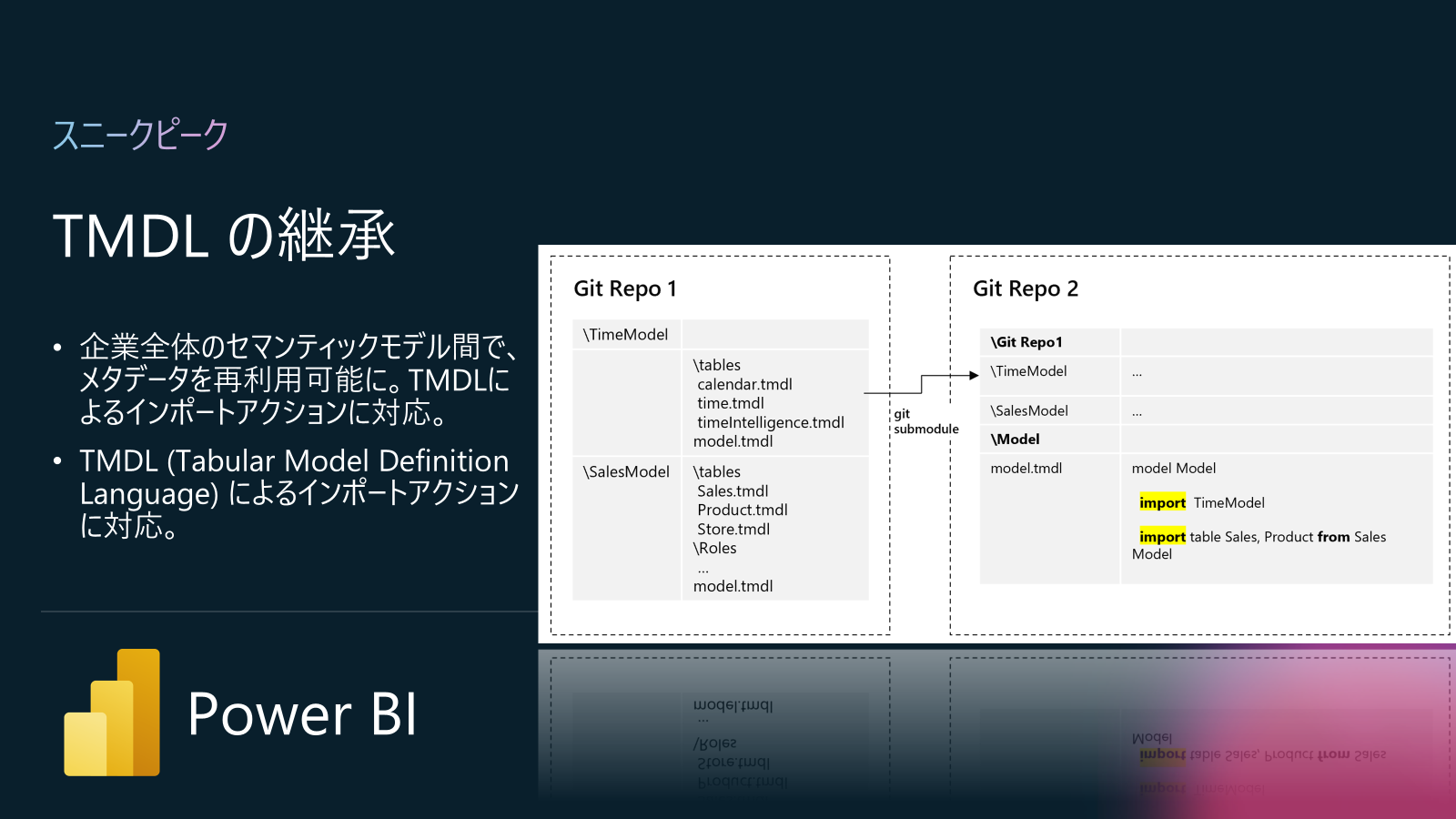
Power BI アップデート3: Power BI Desktop での Direct Lake セマンティック モデルの作成 (パブリックプレビュー)
Power BI Desktop 上で Direct Lake ストレージモード のセマンティックモデルを新規に作成・編集できます。Direct Lake モデルは、OneLake 上の Delta テーブルをそのままライブ接続することで、インポート不要かつ大容量データへの高速分析を可能です。ただし、現時点では、ライブ接続すると、レポートのページが表示されなくなります。そのため、Dual モニタの方は、二つPower BI Desktop アプリを開いて、一つはReportの編集用と、もう一つは、ライブ接続の編集用で操作します。
現在のOneLakeのDirect Lakeでサポートされている機能についてですが、
- ユーザーエクスペリエンスの観点から、データカタログを通じて様々なソースタイプをサポートし、OneLakeと統合したセマンティックモデル(インポート)を提供します。
- Fabricユーザーは、Power BI Desktopを使って、Direct Lake on OneLakeのセマンティックモデルを作成できます。
- Fabricユーザーは、Web上で直接、Direct Lake on OneLakeのセマンティックモデルを作成することもできます。
- Direct Lake on OneLakeのセマンティックモデルでは、複数のワークスペースにまたがる複数の成果物(アーティファクト)から、複数のOneLakeデータソースを利用可能です。
- OneLakeのDirect Lakeでは、DirectQueryへのフォールバック(切り替え)は許可されません。
- OneLakeのDirect Lakeでは、混合ストレージモード(インポート、DirectQuery、デュアルなど)の利用は許可されません。
今後の改善予定として
- Fabricユーザーは、Dataflows Gen2を統合データソースとして活用し、Direct Lake on OneLakeのセマンティックモデルを作成できるようになります。
- Fabricユーザーは、SQLエンドポイント上のDirect Lakeモデルを、OneLake上のDirect Lakeへと移行できるようになる予定です。
Power BI アップデート4: Annotations PowerPoint 注釈 (パブリックプレビュー)
Power BI の PowerPoint アドインに「注釈」機能がプレビューとして追加され、スライドに埋め込んだ Power BI ビジュアル上の特定データポイントに直接テキストを紐づけられるようになりました。これにより、会議やプレゼンテーション時にデータの背景説明やハイライトを一層明確に伝えられます 。
Power BI アップデート5: Org Apps (preview) for Pro licenses (パブリックプレビュー)
本機能は「組織向けにカスタマイズしたアプリを複数作成・配信できる」新アイテムで、従来の Power BI アプリ体験を拡張しますが、現状は Premium/Fabric 容量ワークスペース限定のプレビューです。Pro ライセンス ワークスペースへの展開は「まもなく」リリース予定で、その詳細が間もなく公開される予定です。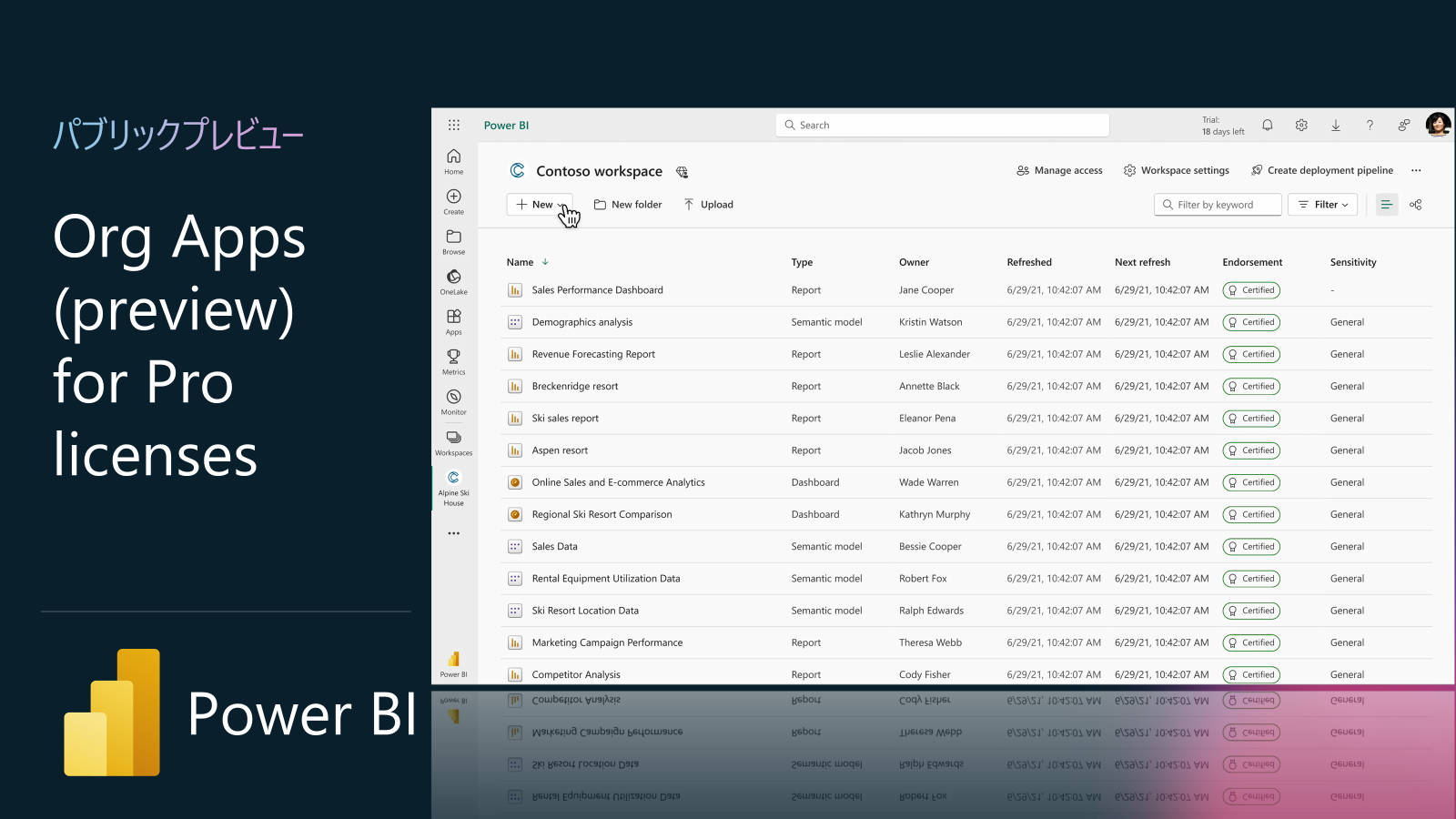
Power BI アップデート6: Copilot in Power BI (Build 2025: パブリックプレビュー)
Power BIには、セマンティックモデル、インサイト、ビジュアルは今までのコンセプトですが、そのほかに、チャットというコンセプトが追加され、含めるようになります。
Copilot は自然言語でデータに質問できる対話型 AI アシスタントで、ビジネスユーザーはレポートを開かずとも「今月の売上推移は?」「主要な成長要因を要約して」などと尋ね、即座にインサイトや可視化結果を得られます。2025年5月の Power BI 更新で、フルスクリーンのスタンドアロン Copilot 体験がプレビュー公開され、Microsoft Purview と連携したガバナンス機能、自動 AI 前処理による精度向上、Power BI サービス/Desktop/モバイルでのシームレス利用など、多岐にわたる強化が加わりました。
スタンドアロン Copilot: 左ナビゲーションから全画面で起動できる新 UI。背景にある任意のデータセットやセマンティックモデルを横断的に検索・分析できます。左側のメニューバーのところに、「Copilot」ボタンがあり、それをクリックすると、Reportを開かずに、Report内のデータ (セマンティックモデル) と会話できるようになります。
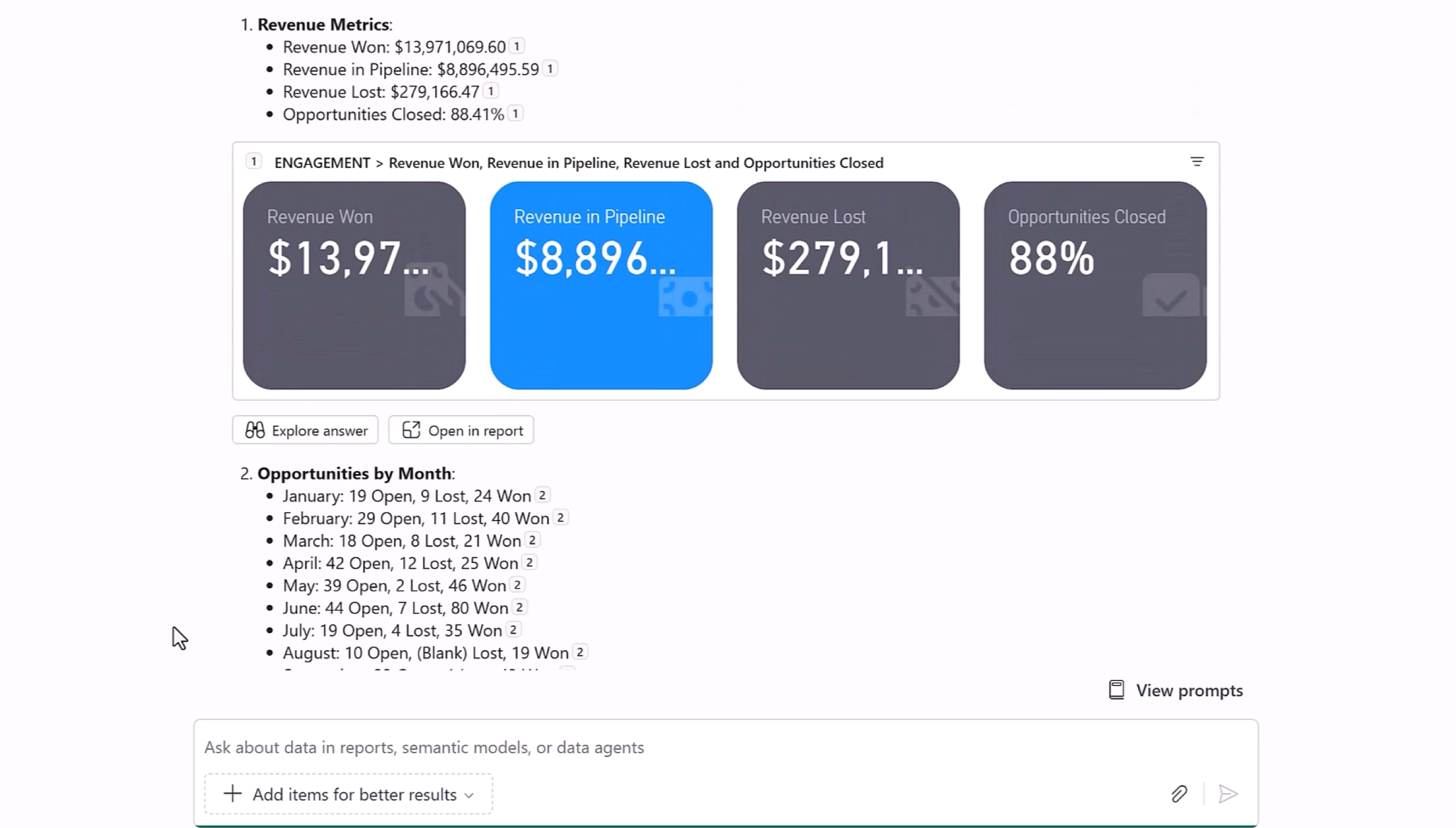
Pane 版 Copilot: 従来からあるチャットペインをレポート内に表示し、そのコンテキストに応じた回答やビジュアル作成を行います。
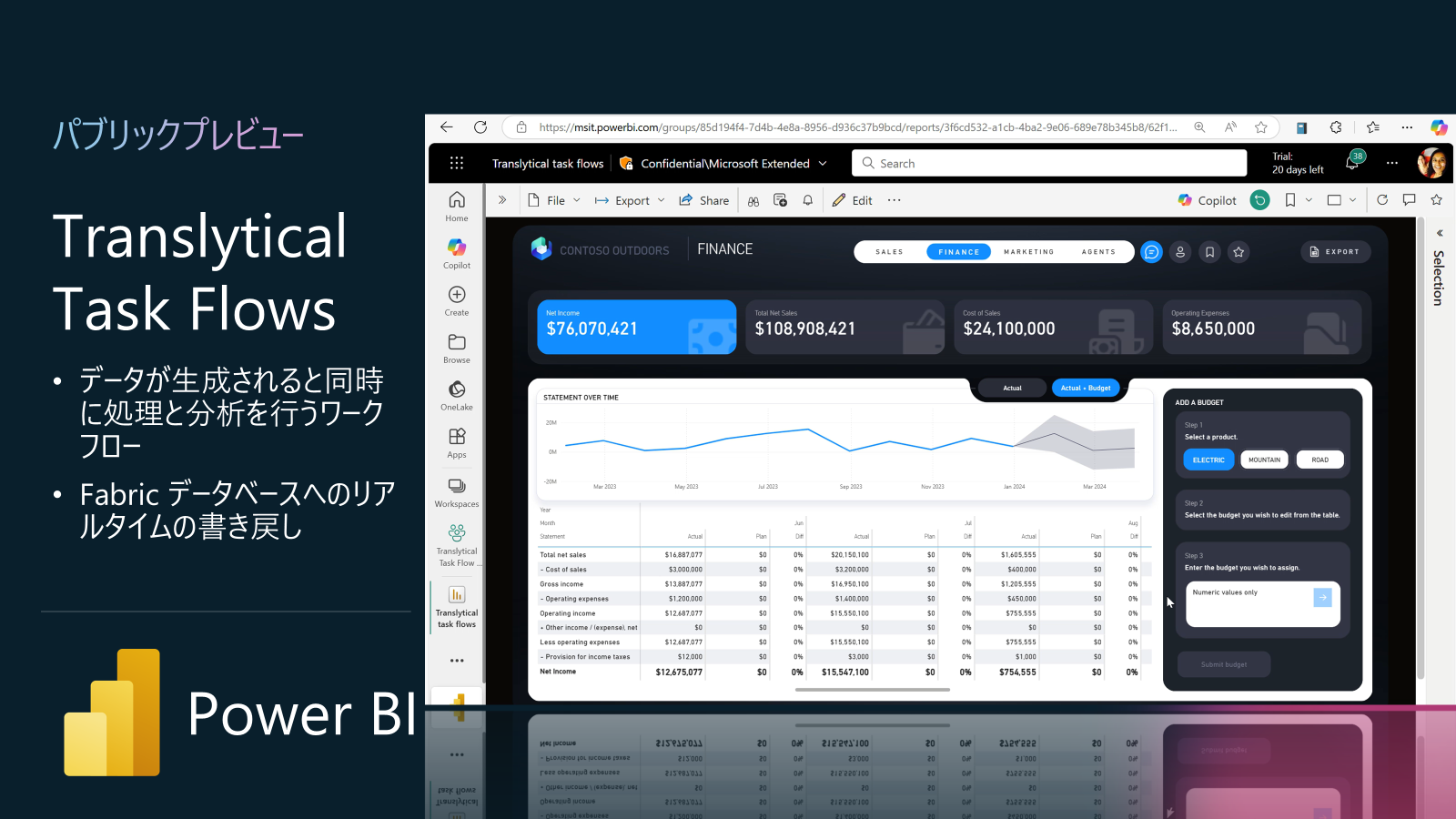
Power BI アップデート7: Translytical Task Flow (Build 2025: パブリックプレビュー)
トランスアナリシス アプリを使用すると、ユーザーはPower BIレポート内からユーザーデータ関数(UDF:User Data Function)を直接呼び出すことができます。
このデータ関数(UDF)には任意のコードを記述することが可能で、レポート内のメジャーやスライサーなどの値、およびFabric上でホストされているデータベースから取得したデータをパラメーターとして受け取ることができます。
データ関数を容易に使用できるようにするため、ワークスペースからデータ関数を取得し、レポートのデータをそのパラメーターに結びつけ、レポート内で選択したデータ関数をユーザーが簡単に呼び出せるようにする仕組みが導入されます。この機能の成功は、作成時と利用時の両方におけるユーザーの利用状況によって判断されます。
Power BIのボタン操作によりユーザーデータ関数(UDF)が呼び出されると、ダッシュボードを閲覧するユーザーが、その背後にあるデータソースと直接インタラクティブにやり取りできるようになります。これにより、より強力で動的なアプリケーションの作成が可能になります。
具体的には、ユーザーデータ関数(UDF)は次の役割を果たします。
- ユーザーが入力したパラメーターを解析し、有効性を確認します。
- データベースに対する操作(データ更新、挿入、削除など)を定義し実行します。
- エラー発生時にはそれを処理し、ユーザーに適切なエラー通知を行います。
この統合機能は、以下のようなユースケースを想定しています。
- ユーザーがPower BIレポートから、データベースに対してクエリ以外の操作(更新や登録処理など)を直接実行できる。
- Power BIから呼び出されるユーザーデータ関数(UDF)は、処理の結果を示すステータス情報のみを返す必要がある(大量データを返す用途ではない)。
使用の前提条件の1つですが、Direct Query モードのレポートであることです。それと、Power BI Desktopで、「テキスト スライサー ビジュアル」を有効にすることです。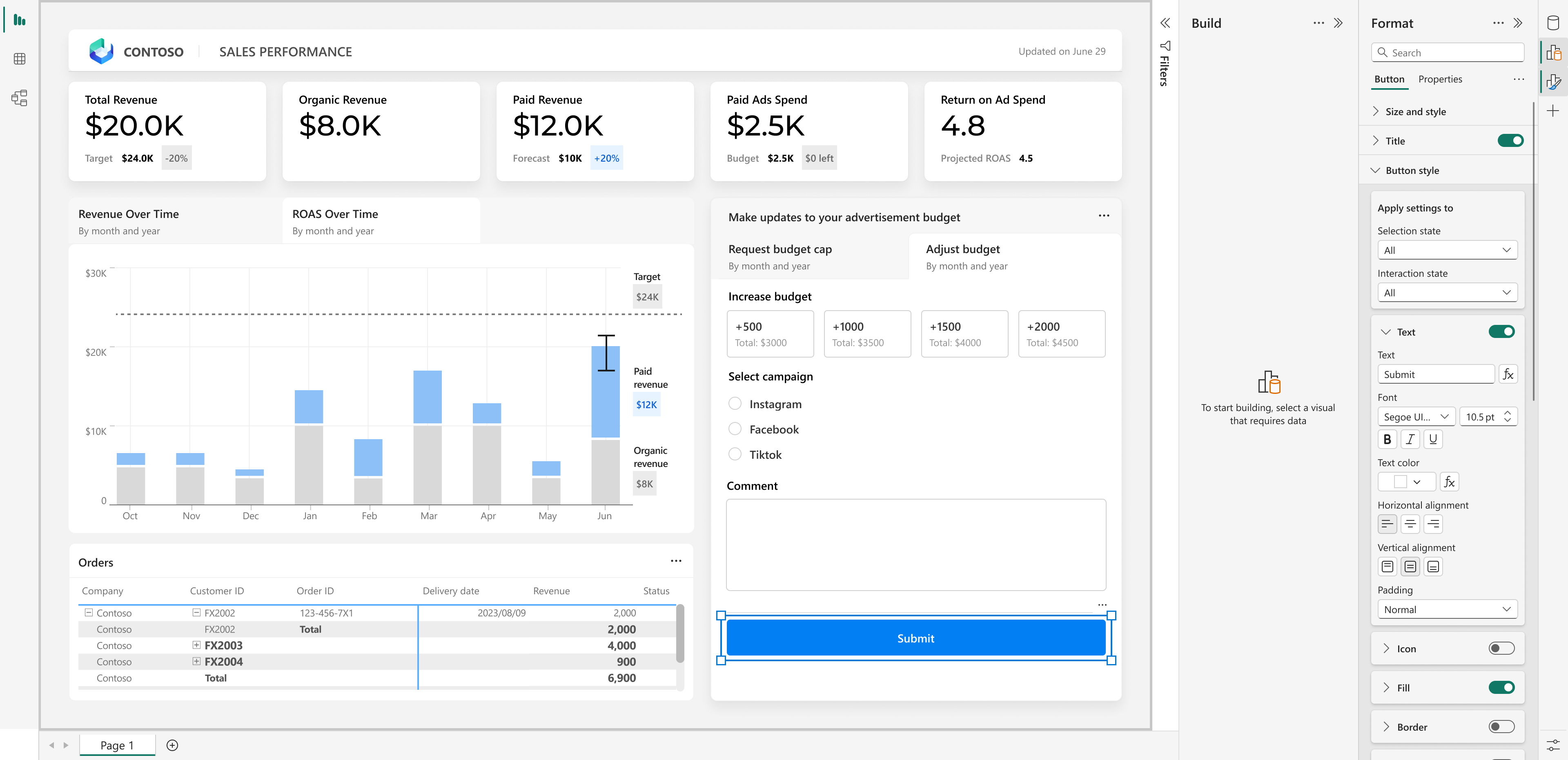
Power BI アップデート8: Copilot Tooling (プライベートプレビュー)
Power BI における Copilot Tooling(AI 連携用のデータ準備ツール)機能で、主に「Prep data for AI」と呼ばれるデータ準備機能で、モデル作成者が Copilot に最適化したコンテキストを提供するための3つの新ツール(AI データスキーマ、Verified answers、AI instructions)を備え、Power BI Desktop とサービスで利用できるようになっています。
Power BI では、Copilot との自然言語対話を高精度化するために、Semantic モデル上で以下の3つのツールを提供しています。
- AI データスキーマ:Copilot が着目すべきテーブル・フィールド・リレーションを専用スキーマとして定義し、AI にモデル構造を明示的に伝えます。
- Verified answers:レポートの特定ビジュアルを「確定回答」として紐づけ、ユーザーの質問に対してその可視化結果を返すように設定できます。
- AI instructions:モデルやビジネスロジックの背景情報をテキストで注釈し、Copilot の応答品質を向上させるためのガイダンスを提供します。

注意してほしいのは、Copilot Tooling機能は セマンティックモデルを介して動作するため、Import / DirectQuery / Composite モデルで利用可能ですが、Direct Lake モードでは一部制限があります。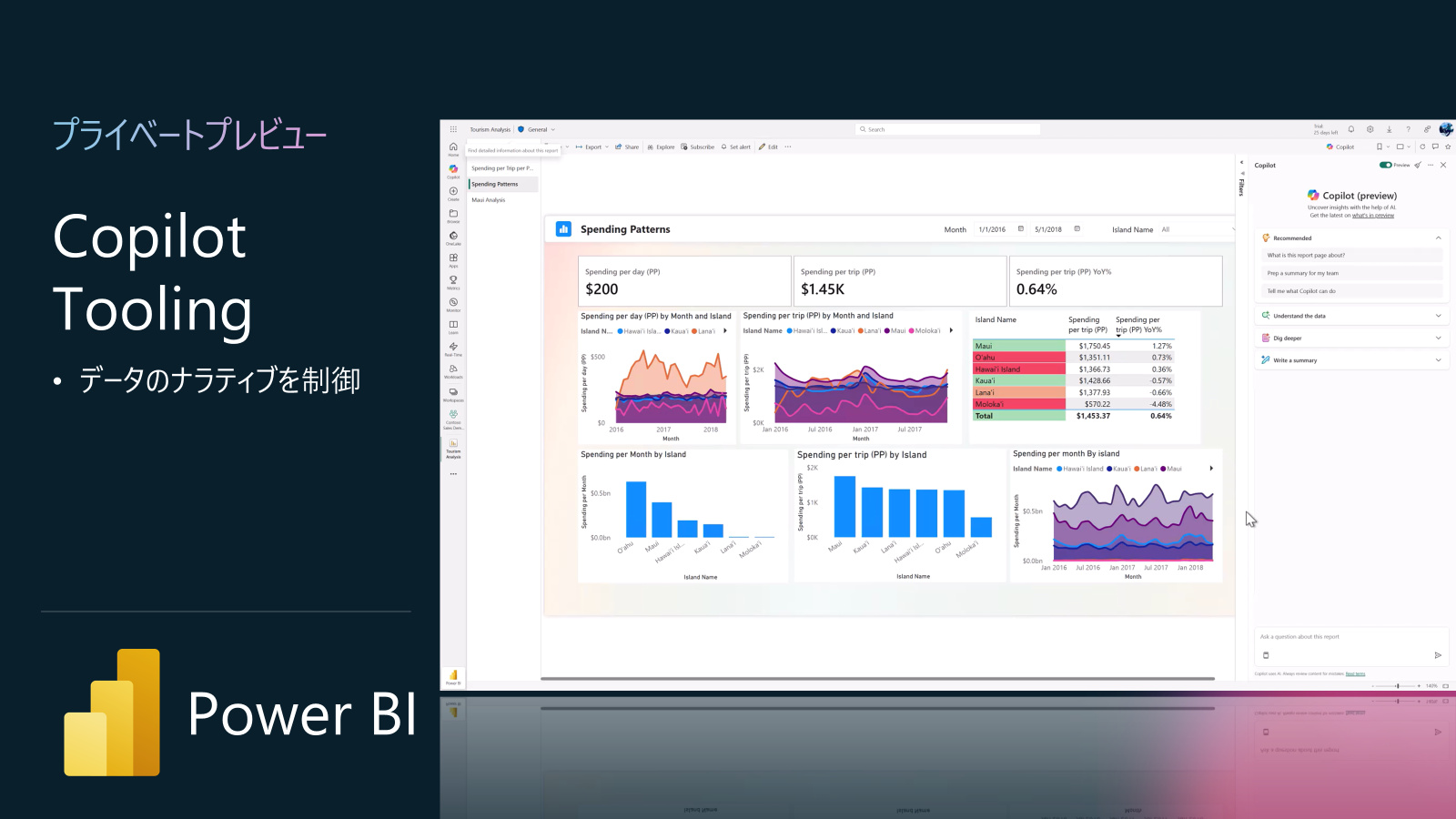

ISV 向けの Workload Development Kit(ワークロード開発キット)がパブリック プレビューとして公開され、REST API/OneLake 経由で各 Fabric サービスを統合できるようになりました。
Partner Workloads アップデート1: Partner Workload status
多くの ISV パートナー(SAS、Esri、Informatica、Teradata、Neo4j、Profisee など)がプライベート プレビューで独自ワークロードを提供開始し、そのうち Osmos、Profisee、PowerBI.tips のワークロードは一般提供 (GA) されています。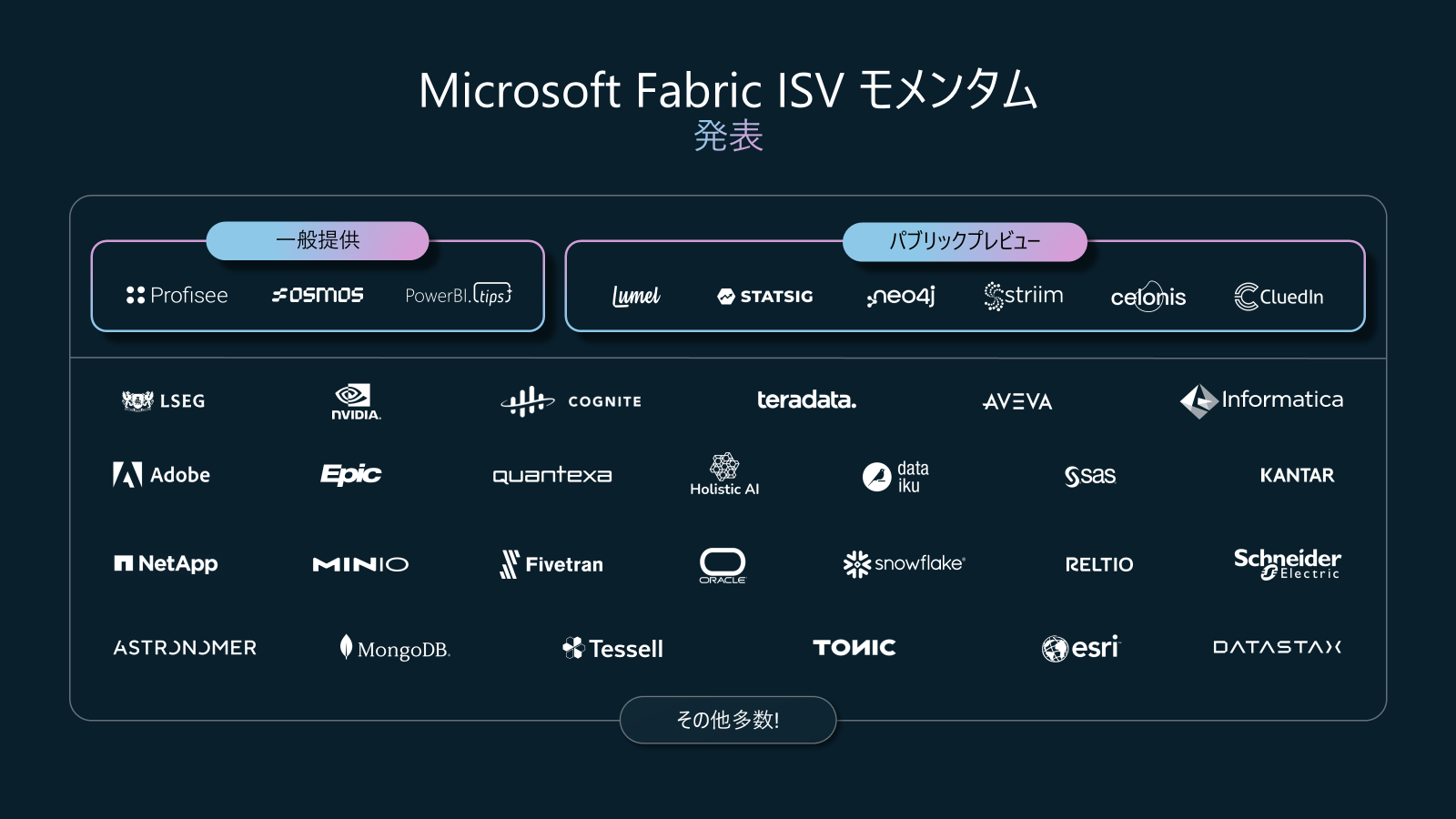

Fabric RTI Workshopにご興味がある場合は、個人ではなく、企業単位でのお申し込み(最大15名まで)が可能です。参加をご希望の方は、私のLinkedInまたはMicrosoft担当営業まで、お気軽にご連絡ください。
当 Community では、Azure Data Platformの勉強会は毎月に開催しています。ぜひ、Communityもアクセスしてみてください。そして、SQL Server 2025 新機能などのイベントも開催しております。
Views: 0

{kind=link}