万博ガンダム用の「グラスフェザー装備」がROBOT魂でも発進!ソーラーパネルにはクリアパーツ採用、新規装備の「ビーム溶接ガン」も付属
Source link
Views: 0

万博ガンダム用の「グラスフェザー装備」がROBOT魂でも発進!ソーラーパネルにはクリアパーツ採用、新規装備の「ビーム溶接ガン」も付属
Source link
Views: 0


第54回日本漫画家協会賞の受賞作品が本日4月14日に発表され、コミック部門の大賞に園田ゆり「ツレ猫 マルルとハチ」、カーツーン部門の大賞に山口マサル「10人の博士の昼休み」、萬画部門の大賞に坂月さかな「星旅少年」が輝いた。
Source link
Views: 0


最近『ゼロから作るDeep Learning 2』で自然言語処理の勉強をしていて、備忘を兼ねてword2vecについてまとめてみました!
この記事では、word2vecの仕組みを「本当にゼロから」実装しながら学んだことを、できるだけ丁寧に・分かりやすく紹介するので良かったら見てみてください!!
自然言語の単語を機械が理解するためには、数値に変換する必要があります。よくあるのが one-hotベクトル ですが、これは単語同士の意味的な距離を表現できません。
# ↓ こんな感じ
[0, 1, 0, 0, 0] # you
[1, 0, 0, 0, 0] # shark
[0, 0, 1, 0, 0] # love
# → you・sharkは(代)名詞という意味で近いが、ベクトル空間だけでは表現できない!
そこで登場したのが 分散表現(Distributed Representation) です。
意味的に近い単語はベクトル空間でも近くなるように学習する仕組みで、その代表格が word2vec になります。
以下のように、one-hotでは you も shark も love もベクトル上は全く等距離なのに対し、分散表現では「意味的に近い」単語が近い位置にマッピングされます。
# One-hotベクトルの例(次元: 5)
you → [0, 0, 1, 0, 0]
shark → [0, 1, 0, 0, 0]
love → [1, 0, 0, 0, 0]
# 分散表現(学習済みベクトル)
you → [0.21, -0.45, 0.87]
shark → [0.19, -0.44, 0.90] # youとは似た者同士
love → [0.80, 0.10, -0.60]
このように、分散表現では、you と shark のような比較的意味が近い(文脈が似る)ことが空間上で表現できるのです。
word2vecは主に2つのモデルがあります。
どちらも入力層・中間層・出力層の3層構造で、重み行列がそのまま単語のベクトル表現(分散表現)になるのがポイントです。
ちなみに、単純なCBOW, Skip-gramでは計算コストが高すぎるという弱点があるため、以下のような処理を間に挟んで実行するのがスタンダードらしいです。
CBOW(Continuous Bag of Words)モデルは、「前後の文脈」から「中央の単語」を予測するアーキテクチャです。
例:I like sharks. You ? sharks. He like sharks. She like sharks. Right?
(※小さなコーパスでの説明になるため、文法等は無視してください。。)
→「You」「sharks」から「?」を求めるイメージ
ここでは、レイヤー構造をクラス化した SimpleCBOW の実装を紹介しつつ、コードの意味を詳しく解説します。
では、実際のコードを見ていきましょう。
以下コードがSimpleCBOWの全体像になります。
※なお、MatMulレイヤやSoftmaxWithLossレイヤはすでに用意済みとします。
※以下コードはこちらを引用させていただきました。
import sys
sys.path.append('..')
import numpy as np
from common.layers import MatMul, SoftmaxWithLoss
class SimpleCBOW:
def __init__(self, vocab_size, hidden_size):
V, H = vocab_size, hidden_size
# 重みの初期化
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(H, V).astype('f')
# レイヤの生成
self.in_layer0 = MatMul(W_in)
self.in_layer1 = MatMul(W_in)
self.out_layer = MatMul(W_out)
self.loss_layer = SoftmaxWithLoss()
# すべての重みと勾配をリストにまとめる
layers = [self.in_layer0, self.in_layer1, self.out_layer]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
# メンバ変数に単語の分散表現を設定
self.word_vecs = W_in
def forward(self, contexts, target):
h0 = self.in_layer0.forward(contexts[:, 0])
h1 = self.in_layer1.forward(contexts[:, 1])
h_avg = (h0 + h1) * 0.5
score = self.out_layer.forward(h_avg)
loss = self.loss_layer.forward(score, target)
return loss
def backward(self, dout=1):
ds = self.loss_layer.backward(dout)
da = self.out_layer.backward(ds)
da *= 0.5
self.in_layer1.backward(da)
self.in_layer0.backward(da)
return None
このモデルでは次のような処理を行います:
__init__ メソッドここでは、語彙数(V)と中間層の次元数(H)を受け取り、各レイヤの初期化と重み・勾配の初期値がまとめられた容器を作成します。
V, H = vocab_size, hidden_size
V:語彙数
H:中間層の次元数
なお、Hが大きいほど単語の意味をより豊かに表現できるのですが、その分計算コストが大きくなってしまうため、その塩梅が大切です。
# 重みの初期化
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(H, V).astype('f')
ここでは、 入出力の重み行列(語彙ID → ベクトル変換用) を初期化しています。W_inは[V, H]型の行列に、W_outは[H, V]型の行列の各データにランダムな数値を挿入しています。
なお、0.01はランダム値のスケールを小さくして初期学習を安定させる目的で行なっています。
加えて、.astype('f')は32ビットのフロート型(float32)に変換することでメモリを節約しています。
# レイヤの生成
self.in_layer0 = MatMul(W_in)
self.in_layer1 = MatMul(W_in)
self.out_layer = MatMul(W_out)
self.loss_layer = SoftmaxWithLoss()
ここでは、word2vecの使われる各レイヤを初期化しています。MatMulレイヤでは、入力値に対して重みとの内積を出力します。
# すべての重みと勾配をリストにまとめる
layers = [self.in_layer0, self.in_layer1, self.out_layer]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
②〜③で生成した重みやレイヤをリストでまとめています。
# メンバ変数に単語の分散表現を設定
self.word_vecs = W_in
メンバ変数に単語の分散表現を設定しています。
これがCBOWから求めたい分散表現(= 単語間の関係性)になります。
forward メソッド(順伝播)大まかなには以下の様な処理を行なってます。
W_in でベクトル化(h0, h1)h_avg を作成W_out をかけてスコアを出すh0 = self.in_layer0.forward(contexts[:, 0])
h1 = self.in_layer1.forward(contexts[:, 1])
in_layer0とin_layer1レイヤでは 文脈(context)の単語ベクトルを生成 しています。
なお、in_leyerが2つ定義されているのは、今回contextが2つあるためです。
イメージとしては以下になります。
「I eat bread.」 → context:[ I, bread ] target:[ eat ]
→ contextが2つあるから、in_layerが2つ定義している
h_avg = (h0 + h1) * 0.5
score = self.out_layer.forward(h_avg)
out_layerでは、 平均した単語ベクトルからスコアを出力 しています。
具体的には、in_layer0とin_layer1で求められた単語ベクトルの和から平均を取って、重みW_outとの内積(= スコア)を出力します。
loss = self.loss_layer.forward(score, target)
return loss
②で求めた出力値からSoftmaxWithLossレイヤを通して、損失を求めます。
言い換えると、 モデルがどれだけ間違った推論をしたか を求めます。
backward メソッド(逆伝播)大まかなには以下の様な処理を行なってます。
ds = self.loss_layer.backward(dout)
ここでは、softmax関数及び損失関数から、 スコアに対する損失の勾配 を求めています。
da = self.out_layer.backward(ds)
①で求めた勾配から以下の勾配を求めています。
W_outの勾配h_avgの勾配例えば、W_outの場合、W_outをどう調整すれば損失が減るかを計算しているイメージです。(= 勾配)
da *= 0.5
self.in_layer1.backward(da)
self.in_layer0.backward(da)
入力層の順伝播では各単語ベクトルの和の平均を求めました。
そのため、元に戻すために0.5をかけています。
あとは、入力層の勾配を求めて終わりです。
こちらはCBOWの逆で、1つの単語からその周囲の文脈を予測する形式です。
例:I like sharks. ?0 like ?1. He like sharks. She like sharks. Right?
(※小さなコーパスでの説明になるため、文法等は無視してください。。)
→「like」から「?0」「?1」を求めるイメージ
ここまで実装してきて気づくのは、実は 分散表現(単語ベクトル)の正体は、モデルが学習した重み行列W_in(あるいはW_out)そのもの だということです!
特にCBOWモデルでは、入力層にある W_in が「各単語に対応する単語ベクトル」を保持していて、これこそがまさに単語の意味をベクトルで表した 分散表現 の本体なのです。
学習が進むにつれて、意味的に似た単語(IとYouなど)は似たベクトルになっていき、この W_in を使えば「単語間の距離=意味的な近さ」を評価できるようになります。
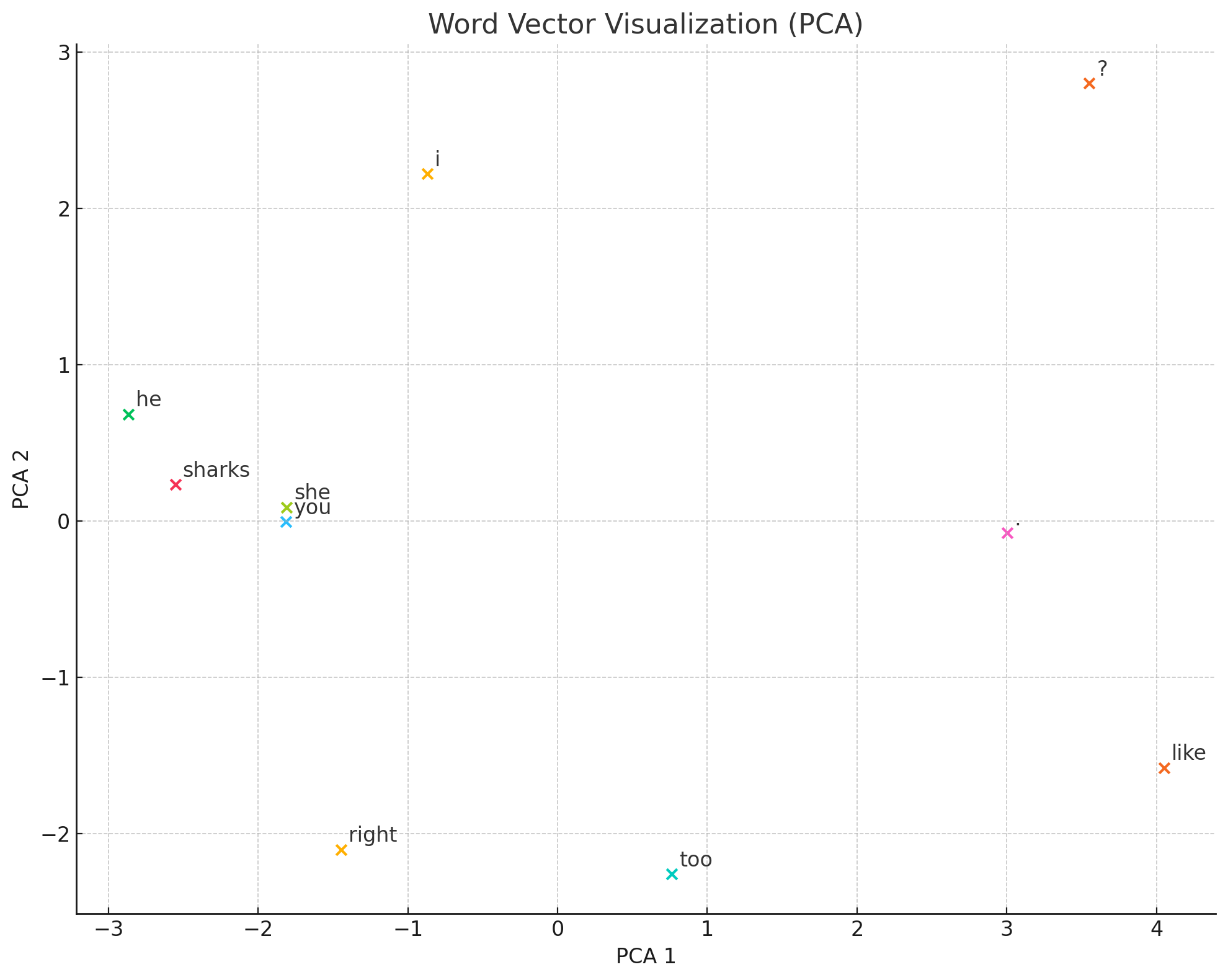
i [-0.32524088 -0.18620428 2.0526676 0.3084023 -1.9294733 ]
like [ 1.4720454 -1.3610317 -2.4738932 -1.3957747 1.3359051]
sharks [-2.00644 1.4744333 1.6221061 2.2876415 -0.26866663]
. [ 0.63513064 -1.5589677 -0.13443974 -0.09589648 2.234503 ]
you [-1.2287176 1.314618 0.59635144 1.1488862 -1.315046 ]
too [-0.4152239 1.1136645 -1.7693648 0.1781921 0.8826593]
he [-1.589313 1.5803062 1.4276375 1.5701383 -2.035321 ]
she [-1.2137684 1.2662815 0.6632496 1.1201724 -1.3627746]
right [-1.5883118 1.8926656 -1.109615 1.4353355 -0.14227109]
? [ 1.8778818 -1.7863336 2.1310813 -1.9476782 1.1779776]
実際に求めた分散表現になります。
似たような単語(i, you, he, she)で見比べてみると・・・
i [-0.32524088 -0.18620428 2.0526676 0.3084023 -1.9294733 ]
you [-1.2287176 1.314618 0.59635144 1.1488862 -1.315046 ]
he [-1.589313 1.5803062 1.4276375 1.5701383 -2.035321 ]
she [-1.2137684 1.2662815 0.6632496 1.1201724 -1.3627746]
ある程度似通った値になっているかと思います。
ですが、意味合い的に全く似ていない単語(i, like, too)で見比べてみると・・・
i [-0.32524088 -0.18620428 2.0526676 0.3084023 -1.9294733 ]
like [ 1.4720454 -1.3610317 -2.4738932 -1.3957747 1.3359051]
too [-0.4152239 1.1136645 -1.7693648 0.1781921 0.8826593]
先ほどよりはまとまりが無いように思います。
今回はコーパスが非常に小さい(単語数:20個程度)ため推論結果が少しバラバラになってしまいましたが、何万何十万のコーパスの場合はもう少し精度が上がると思います。
求めた分散表現から次元圧縮などを経て、プロットしたグラフが以下になります。
↓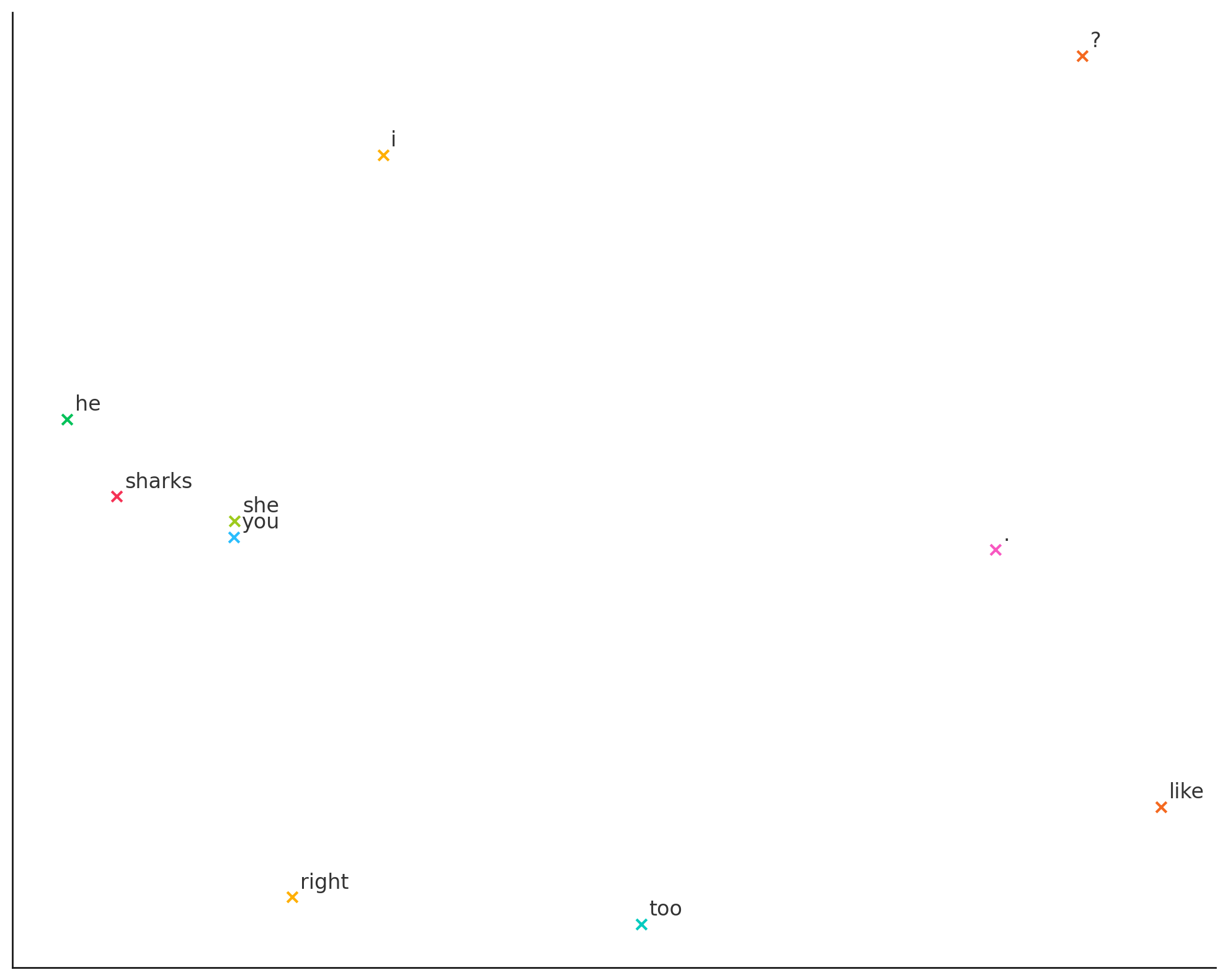
右側がごちゃってますが、やはり似た単語は同じところでプロットされているかと思います。
なお、学習が終わったあとは、各単語のベクトル表現(分散表現)からコサイン類似度を計算することで、意味的に近い単語ほど高い類似度を示すことが分かります。
`you` に近い単語TOP5
she 0.9992
he 0.9825
sharks 0.8619
right 0.7098
i 0.5796
`he` に近い単語TOP5
she 0.9885
you 0.9825
sharks 0.8613
i 0.7157
right 0.5707
つまり、コサイン類似度で評価すると、 高いスコアが出る=意味的に関係のある単語ほどベクトル空間内で近い位置にプロットされる = 似た者同士! と判断できます。
以上のことから、単語の意味が各分散表現に宿っているといえるのではないでしょうか。
有名な king - man + woman ≒ queen みたいなベクトル演算も、上記理由から行えるのです!
今回は、CBOWを中心としたWord2Vecの仕組みについて解説しました。
Negative Sampling や Embedding などの改良手法もありますが、今回はひとまずここまでとしたいと思います。
普段使っているLLMが、入力された文章をどのように解析しているのか、少しブラックボックスのように感じていましたが、Word2Vecを学ぶことでその裏側の仕組みが少し見えてきた気がします。
また、Word2Vecが「単語間の関係性」を学習するのに対し、Doc2Vecのように「文節間の関係性」を対象に学習する手法もあることを知ることができました。
今後は、RNN や Attention機構 など、より発展的なトピックについても学びながら、記事としてまとめていきたいと思います。
最後まで読んでくださり、ありがとうございました!
もし記事が参考になったら、「いいね」してもらえるとすごく励みになります!
また、内容に誤りや気になる点があれば、遠慮なくご指摘していただけると嬉しいです!
他にもいろいろな記事を投稿しているので、もしよかったら見てみてください!
Word2Vecを理解するにあたって、以下の資料を参考にさせていただきました。
先人たちの知見に感謝です!
Views: 0

4月15日(火)、中世風の世界が舞台のマルチプレイ対応アクションゲーム『Ad Mortem』のゲームプレイ映像が公開された。記事執筆時点ではSteamストアページが公開中で、年内にクラウドファンディングを実施する予定であることが告知されている。
公開された映像では、苛酷な世界で斧や剣で戦う戦士たちの姿が見られる。大戦中に武器同士が触れると弾きが発生し、体勢が崩れるような場面もある。また、近接武器だけではなく、銃器が登場するシーンも確認できる。
本作は、最大4人で協力してダンジョンに挑むCoopモードと、5対5、10対10の対戦モードが収録されるアクションゲームだ。Steamストアページによると、一人称視点と三人称視点を切り替えることが可能である。
本作の舞台は穢れた世界「Contrara」。プレイヤーは古き神々の死によって生まれた“Vessel(器)”と呼ばれる存在で、死ぬことも許されずこの世界に縛られている。「Palisadean」と「the Hantrii」の敵対する派閥が分かれており、プレイヤーはどちらかの陣営に所属し、ほかのVesselと対戦することができる。
(画像は『Ad Mortem』のSteamストアページより)
協力プレイモードでは、プレイヤー同士で協力しながらダンジョンを進むことができる。PvPモードでは、同等のスキルレベルのプレイヤー同士でマッチメイキングが行われ、対戦が可能。先述した5対5のモードと、10対10のふたつのモードがある。
また、「Duelyard」と呼ばれる訓練場では思う存分戦闘訓練に明け暮れることもできるようだ。さらに、本作にはキャラクターを聞かざるコスメアイテムなども存在する。
We are excited to finally share Ad Mortem gameplay, Check out our gameplay trailer and wishlist us on Steam!https://t.co/Qx5i2aUOxE#indiegame #gamedev #gameplay
— AD MORTEM (@PlayAdMortem) April 14, 2025
Head On Studiosの手がける『Ad Mortem』はSteamストアページが公開中だ。
本ページはアフィリエイトプログラムによる収益を得ている場合がございます
Views: 0


ロボット工学が進歩するにつれて、業界は多くの種類のグラント作業を自動化するために、より多くのロボットを着実に採用しています。 2023年には540,000を超える新しい産業ロボットが世界中に設置され、総産業ロボットの数を400万人以上にしました。 IFR。
産業用ロボットは通常、繰り返しのタスクに優れていますが、正確なタスクを実行し、繊細な素材を処理し、変化する条件に合わせて調整するのが難しいと感じています。たとえば、レストランのキッチンのロボットは、役立つ以上のものになります。そのため、多くの産業プロセスがまだマニュアルです。
韓国のスタートアップ rlwrld この問題は、大規模な言語モデルと従来のロボットソフトウェアを組み合わせることにより、ロボット工学専用に構築された基本的なAIモデルで解決することを目指しています。同社は、このモデルにより、ロボットが迅速でアジャイルな動きをし、ある程度の「論理的推論」も実行できるようになると述べています。
RLWRLDの創設者兼CEOであるJung-Hee Ryuは、TechCrunchとの独占インタビューで、「RLWRLDの基礎モデルを使用して、多くの手動作業を必要とするプロセスを完全に自動化し、作業環境をより効率的にすることで完全に自動化できます」と述べています。
スタートアップは現在、シード資金で210億KRW(約1480万ドル)でステルスから出ています。このラウンドは、ベンチャーキャピタル会社がハッシュし、ミラエアセットベンチャーインベストメントとグローバルブレインも投資しました。
特に、RLWRLDは、日本のANAグループ、PKSHA、Mitsui Chemical、Shimadzu、Kddiの大きな戦略的投資家の長いリストを集めています。韓国からのLGエレクトロニクスとSKテレコム。インドからのアンバー製造。
RLWRLDは、SEED資金は、戦略的投資家との概念実証プロジェクトに資金を提供するために使用されると述べました。 GPUなどの安全なコンピューティングインフラストラクチャ、ロボットを購入し、デバイスを購入して、広範なデータを収集します。そして、研究の才能を雇います。また、スタートアップは新しいお金を使用して、5フィンガーを含む高度な手の動きを開発します。これは、テスラ、図AI、1Xなどの競合他社によってまだ実証されていない機能です、とRyuは言いました。

Ryu氏は、RLWRLDが戦略的投資家と協力して、異なる自動化の方法を探求していると述べました 人間中心のワークフロー AIモデルを使用します。彼らは一緒に、今年後半に予定されているヒューマノイドベースの自律行動のデモを準備している、とRyuは言った。さらに、同社は、産業、共同、自律的なモバイルロボットやヒューマノイドなど、さまざまな種類のロボットをサポートできるプラットフォームの開発に取り組んでいます。
2024年に設立されたRLWRLDは、RYUの3回目のスタートアップです。彼の2番目のスタートアップ、 Olaworksは、2012年にIntelに買収されましたそして最終的に、コンピュータービジョン部門内のIntelの韓国R&Dセンターになりました。そして2015年に彼は設立しました スタートアップアクセラレータ、Future Playそれはディープハイテク企業に焦点を当てています。
何が彼に新しい会社を再び始めるように促したのかと尋ねられたとき、Ryuは、AIのスタートアップが米国、ヨーロッパ、中国の数がどれほど速く増加しているかに気づいたのに対し、韓国と日本の同等のAIのスタートアップは比較的存在していなかったと述べた。
彼は、韓国と日本の30人以上のAI教授と、データやGPUなどのインフラストラクチャの不足など、ベンチャーを立ち上げるために彼らを落胆させた障害と利用可能な機会について、30人以上のAI教授と話をしました。
「私は、LLMSの技術的に飽和した分野よりもロボット財団モデル(RFM)に優先順位を付けることが戦略的に有益であると判断し、韓国と日本の製造における顕著な世界的な強さを活用しています」と彼は言いました。
その後すぐに、彼はKaist、SNU、Postechを含む韓国のトップランクの機関の6人の教授を、RLWRLDを立ち上げました。
RLWRLDは、この問題に取り組むだけではありません。のようなスタートアップ SKILD AI そして 物理的知性 テスラのような大企業と同様に、ロボット工学の同様の基礎モデルを構築しています。 Google DeepMindそして nvidia。
しかし、Ryuは、ロボット工学の基礎モデルを開発するために必要なAIおよびロボット工学の専門家と、高度な自由度(DOF)を持つヒューマノイドロボットを開発するために必要なAIおよびロボット工学の専門家がすでにあるため、彼のスタートアップは良いスタートを切っていると考えています。
“さらに、 [such companies] 通常、2本指のグリッパーなどの低Dofロボットに依存します。 RLWRLDはすでに高度なリファレンスロボットを確保しているため、優れたパフォーマンスの結果を期待しています」と彼は言いました。
Ryuはまた、戦略的な投資家のおかげで、RLWRLDは近くにある製造サイトから貴重なデータをすばやく収集できると述べました。 2024年、 レポート 日本と韓国が世界的な製造生産の9.2%を集合的に占めていることを示しました。
RLWRLDは、今年には、概念実証(POC)プロジェクトと戦略的パートナーとのコラボレーションデモを通じて、早くも収益を上げることを目指しています。
スタートアップの長期的な目標は、家事を支援するために国内環境で使用できる工場、物流センター、小売店、さらにはロボットにも対応することです。それまでの間、優先事項は、産業をターゲットにしていることです。なぜなら、彼らは最も支払いをしており、自動化に対する強い需要を持っているからです。
スタートアップには13人の従業員がいます。
Views: 0
Cygamesは本日(2025年4月14日),同社が6月17日に世界同時リリースを予定している「Shadowverse: Worlds Beyond」(iOS / Android / PC)のテーマソングに,シンガーソングライターのキタニタツヤさんが書き下ろした新曲「あなたのことをおしえて」を起用したことを発表した。
 |
また,同曲を使用した新CM映像がゲーム公式YouTubeチャンネルで公開されたほか,キタニさんからのコメントも届いているので掲載しよう。


 |
ゲームの企画・開発・運営事業を展開する株式会社 Cygames(本社:東京都渋谷区、代表取締役社長:渡邊耕一)は、6月17日(火)に世界同時リリースを予定している新作タイトル『Shadowverse: Worlds Beyond(以下、シャドウバース ワールズビヨンド)』のテーマソングに、人気アーティスト・キタニタツヤ氏が書き下ろした新曲「あなたのことをおしえて」の起用が決定したことをお知らせします。また、この度楽曲を使用した15秒の新CM映像を『シャドウバースワールズビヨンド』公式YouTubeチャンネルで公開しました。
キタニタツヤ氏から、楽曲に込められた思いなどのコメントも頂いています。
▼【Shadowverse: Worlds Beyond】テーマソングCM
https://youtu.be/E0X95VNTXvE
■テーマソングに、キタニタツヤ書き下ろしの新曲「あなたのことをおしえて」決定!
|
次世代スマホカードゲーム『シャドウバース ワールズビヨンド』のテーマソングに、キタニタツヤ氏が書き下ろした新曲「あなたのことをおしえて」の起用が決定しました。
本作は、対戦型デジタルTCG『シャドウバース』の新作タイトルとして2025年6月17日(火)にリリース開始予定です。テーマソングとなる「あなたのことをおしえて」は、ゲーム内でプレイヤーを迎える重要な楽曲として位置づけられており、キタニタツヤ氏特有の疾走感溢れるサウンドが、一新される“シャドウバース”の世界を彩ります。
本作では「超進化」や「エクストラPP」といった新要素や、作成したアバターを動かしてオンライン空間上で他ユーザーとカードバトルを楽しめる「シャドバパーク」など、進化したゲームプレイが楽しめます。
キタニタツヤ氏による楽曲と共に、ぜひ新たな『シャドウバース』の世界をお楽しみください。
■キタニタツヤ氏から、楽曲に込めた思いなどコメント到着!
大きな力に翻弄されながらも少しずつそれに抗い、悲しかったこと、苦しかったことを糧に、胸の奥に抱えた理想で現実をささやかにでも上書きしていく。
そんな小さな革命が私たちの日常の中にはたくさんあって、ドライツェーンの姿はその象徴のように映りました。「あなたのことをおしえて」はその革命を鼓舞するものであるようにと作った歌です。
『Shadowverse』という歴史あるゲームのテーマソングを担当させていただけて光栄です。
ぜひゲームとともに、この楽曲も長く聞いていただけると幸いです。
 |
Views: 0

電動キックボードのシェアリングサービスを展開するLimeが、日本国内で初めてジオフェンシング技術を活用し、首都高速道路への誤進入を防止する新たな安全対策を導入。渋谷・新宿・池袋などの料金所周辺で実運用を開始し、ビーコンによる駐車マナー向上策も進行中。
Source link
Views: 0
21時ライブ配信】 – PC Watch")

MINISFORUMから16コアのRyzen 9 7945HX3Dをオンボード搭載しながら、実売で9万円台をMini-ITXマザーボード「BD790i X3D」が登場。
7945HX3Dは人気のゲーミングCPU“Ryzen 7 7950X3D”のモバイル版といった仕様で、7950X3D同様に16基のZen 4コアとゲームに効く3D V-Cacheを組み合わせています。そして7950X3Dは今でも12万円近くする高級モデル。つまりBD790i X3Dってめちゃ買い得では!?
というわけでゲーマー、クリエイター、ロマン派、そして純粋にパフォーマンスを求めるみなさんのために、劉デスクがBD790i X3Dの検証レポートをお届けします。
さらに、Lian Liのケース「A3-mATX-WD」と組み合わせた強力な自作ゲーミングPCも披露。超素敵なマシンが簡単&リーズナブルにつくれちゃうんです。
劉尭(PC Watchデスク)
佐々木修司(PADプロデューサー)
16コアRyzen X3D搭載のマザーボードが9万円台!「MINISFORUM BD790i X3D」で強力ミニゲーミングPCを作る
【公式チャンネル “PAD”チャンネル登録のお願い】
PC Watch、AKIBA PC Hotline!が共同でお届けするPCハードウェアと関連情報の専門YouTubeチャンネルです。完成品PC、自作PC、パーツ、周辺機器などを専門媒体ならではの視点で掘り下げます。コンテンツは今後も続々と追加予定。チャンネル登録をお願いします!
Views: 0
inmobilexion(インモビ)は、動画・ニュース・サイト紹介を中心に、信頼性の高い情報をわかりやすくお届けする情報プラットフォームです。 「in-mobile」×造語の"〜xion"から生まれたインモビは、厳選・接続・導線など多様な意味を内包しながら、次世代の情報体験を提案します。
Contact us: [email protected]
© インモビ by inmobilexion.com