

本日夕方にスタートした、Nintendo Switch 2の予約抽選販売。応募しようとアクセスが集中しているようで、エラーが頻発し、予約申込みが完了できない状況が続いている。始まってから1時間以上も格闘し、まだ申込みが行えていない記者の状況を紹介しよう。
Source link
Views: 0

本日夕方にスタートした、Nintendo Switch 2の予約抽選販売。応募しようとアクセスが集中しているようで、エラーが頻発し、予約申込みが完了できない状況が続いている。始まってから1時間以上も格闘し、まだ申込みが行えていない記者の状況を紹介しよう。
Source link
Views: 0


要約
Storybookがバージョン8以降から進化が凄まじい!
@storybook/experimental-nextjs-viteで、Next.JS環境でStorybookブラウザが爆速で立ち上がる!
既存のVitestと統合されてテストのしやすさレベルアップ!testファイル内の普通のテストと一緒にテスト実行されるやん!
ブラウザ上からもコンポーネントテストできるようになってて便利だしモダンでかっこいい!
はじめに
こんにちは!イノベーション開発チームのmiyaken85です!
弊社が運営するITトレンドのフロントエンドでは、コンポーネント管理ツールとしてStoryb…
Source link
Views: 0
私は「最小限の」サービスワーカーのアイデアが好きです。 サービスワーカー かなり複雑になる可能性があり、彼らの力は正直に私を少し緊張させます。彼らはブラウザとネットワークの間の仲介者であり、私はそれを本当に繰り返すことを想像できます。他のテクノロジーにはできないことは役に立たないので、それらを使用することを思いとどまらせないでください。
だから私は「最小限の」部分が好きです。それが非常にはっきりとしていることを理解したいです!コードが少ないほど良いです。
Tantekは最近それについて投稿しました、最小限のアイデアで:
個人サイトには、サイトの任意のページからインストールされているサービスワーカー(および「オフライン」HTMLページ)があり、オフラインページのキャッシュだけで、将来のリクエストでリクエストページが利用可能であるかどうかを確認します。 (たとえば、インターネットアーカイブ)またはサイトの静的ミラー(通常、別のドメイン)。
それは明らかに有用なようです。しかし、ページのアーカイブにリンクすることについての少しは、私には散らばっているようです。ユーザーがページを表示できない理由がオフラインであるためである場合、インターネットアーカイブに送信するページも機能しません。しかし、私はキャッシングと少なくとも何かをしようとすることについてのビットが好きです。
ジェレミー・キースはこれについて考えていました 2018年にも戻って:
ロジックは次のように機能します:
- HTMLページのリクエストがある場合は、ネットワークから取得し、コピーをキャッシュに保存します(ただし、ネットワークリクエストが失敗した場合は、代わりにキャッシュを調べてみてください)。
- 他のファイルについては、最初にキャッシュ内のコピーを探しますが、その間、ネットワークから新鮮なバージョンを取得してキャッシュを更新します(そして、キャッシュに既存のバージョンがない場合は、ネットワークからファイルを取得してキャッシュにコピーを保存します)。
実装は実際です ほんの数行のコード。 a それのバリエーション Tantekのアイデアも処理し、他の場所でアーカイブにリンクすることを行うことができるカスタムオフラインページを実装します。
さらにいくつかのリンクを残します。 Lofiという用語を聞いたことがありますか? 「lo-fi」はきれいなので、私はそれの短縮の最大のファンではありません 確立された音楽用語 言うまでもなく、「低忠実度」はあらゆる種類のコンテキストで役立ちます。しかし、最近Web Techでは、「ローカルファースト」を指します。
「ローカルファースト」は、クライアントとサーバー間のデータ交換を容易にする「同期エンジン」を介して、各クライアントの埋め込みデータベースにシフトして書き込み、書き込みをしていると考えています。 FigmaやLinearなどのアプリケーションがこのアプローチを開拓しましたが、ますます簡単になります。
ローカルファースト開発に関するいくつかのメモ、カイル・マシューズ
私はそのアイデアを正直に掘り下げ、それをテクノロジー(およびテクノロジーを作る企業)が一歩踏み出す場所として見ています 本当に このスタイルの機能を簡単にします。このようにはすでにたくさんのものが機能しています。私は自分の携帯電話のメモアプリを思い浮かべます。これらのメモは常に利用可能です。私がオンラインであろうとオフラインであろうと、それは(気にしないようです)。私がオンラインであれば、彼らはクラウドと同期しますので、他のデバイスやバックアップには最新のものがありますが、そうでない場合はそうです。そのように機能するので、それはより良いです!そして、私はそれができてうれしいですが、ウェブ上の多くのものはそうではありません(Codepenはそうではありません)。しかし、私はそのように機能するものを構築し、登るのに大きな山ではないようにしたいと思います。
それ ええ、私たちは後で/ネットワークアクセスがあるときはいつでも同期します 非常に自明であり、問題の一部です。テクノロジーは「最後の書き込み勝利」のような簡単な/愚かな選択をすることができますが、それはユーザーが我慢しない危険なデータロス領域になる傾向があります。代わりに、データをインテリジェントにマージする必要があり、それは簡単ではありません。 Dropboxはこれを扱う数十億ドルの会社であり、確かに彼らは常にそれを完璧に持っているわけではありません。主要な解決策の1つはCRDTの概念です。これは、控えめに言っても印象的なアイデアですが、私たちのほとんどが穏やかに戻るほど複雑です。だから私は単にあなたを残します CRDTSの穏やかな紹介。
Views: 0

私たちの生活では、嘘や不正を行う瞬間が少なくありません。
仕事でミスを隠すため、面倒な作業を断るため、あるいは日常的で何気ない嘘をつくこともあるかもしれません。
「嘘も方便」という言葉があるように、嘘をついた方が適切な場面もありうるでしょう。
そのためこれまで心理学では、人は状況に応じて嘘を使い分けており、一貫してずっと不正を続ける人は少ないと考えられていました。
例えば、貧乏な学生時代だったらお金の入った財布を拾ったときネコババしてしまうかもしれませんが、経済的に余裕のある社会人になったらちゃんと警察に届けるだろうと予想できます。
しかし、ドイツのマックス・プランク犯罪・安全と法研究所(MPI-CSL)のイザベル・ティールマン(Isabel Thielmann)博士らが行った新たな研究によると、嘘をつく行動(不正)は一時的な状況で変化するものではなく、強い一貫性を持って繰り返されることが示されたのです。
これはつまり、学生時代に拾った財布をネコババするような人は、会社の役員になってもネコババする可能性が高いということを示唆しています。
研究の詳細は、学術ジャーナル「Psychological Science」に2023年3月に発表されました。
目次
まず、この研究が何を明らかにしたのかを見ていきましょう。
多くの人が考えるように、嘘をつく行動は状況依存的です。つまり、嘘をつくことで得られる利益がある場合、その行動を選択するのは自然なことに思えます。
例えば、正直に答えると不利になりそうな質問を面接でされた場合、「あえて嘘をつく」のはごく当たり前の選択に思えます。

実際心理実験でもその傾向は示されており、人はバレる心配がなく、自身の利益になるなら嘘をつくし、バレそうだったり、大した利益にならないなら嘘は避ける傾向があるとされてきました。
これはつまり、貧乏な学生だったら少額の報酬のために嘘をつくかもしれないが、立場のある社会人だったら少額の報酬目当てに嘘はつかないだろうということです。
しかし、嘘というのはその時の状況依存ではなく、その人の性根(性格特性)に依存するのはないかという考え方も存在します。
ただこれまでの心理研究は、実験の条件がバラバラで、実験サンプルも小さく、この疑問を明確にできていませんでした。
そこで今回の研究チームは、同じ人物に対して実験条件(例えば、インセンティブの種類、匿名性、報酬構造など)を厳密に統一して、数年単位の実験を実施しました。
この研究では、1,279名のドイツ在住者に対して「マインドゲーム」「コイン投げ」「くじ引きタスク」の3つの実験課題を使用して、嘘をつく行動の一貫性が測定されました。それぞれの課題には、異なるタイプの報酬が設定されており、嘘をつくことが金銭や面倒な作業を避けるなどの利益に繋がっています。
マインドゲーム:
参加者は1から8の番号の中から1つ選び、その後、画面に表示されたターゲット番号と一致するかを報告します。正直に答えても、嘘をついても「一致した」と答えれば報酬(2ユーロ)が得られます。
コイン投げタスク:
この課題では、参加者に「100個の英単語に含まれる『y』の数を数える」という非常に面倒な作業を与えます。ただし、コインを投げてその結果が指定された面(表か裏)と一致した場合やらなくてもいいよ、と伝えられます。つまり、嘘をつくことで面倒な作業を回避できるのです。(この実験では単に報酬のお金が出されるだけのパターンも実施されています)
くじ引きタスク:
参加者にはランダムで1つの月が選ばれ、その月が自分の母親の誕生月と一致するかを尋ねられます。正直に答えても嘘をついても「一致した」と言えば、5ユーロがもらえます。

今回の研究で重要なのは、この実験が時間を置いて繰り返し行われた点です。
この研究では、最初の「マインドゲーム」の後、約5週間後に「コイン投げタスク」が行われ、さらにその3年以上後に「くじ引きタスク」が実施されているのです。(追加実験では参加者数は数百人規模に減っています)
そしてこのように、時間を空けて同じ参加者に複数回実験を行った結果、非常に興味深い事実が見えてきたのです。
実験を行った結果、嘘をつく行動は一貫して維持されることが確認されました。
つまり嘘で利益を得た人たちは、その後どれだけ期間を空けても、一貫して嘘をつく選択を繰り返したのです。
この実験では特に嘘をつくことに罰則を与えていません。そのため人によっては、罰則がないならそりゃ利益になるなら嘘をつくのは当たり前だろうと考えるかもしれません。
しかし、こうした実験デザインも研究者たちの意図している部分です。
実は今回の研究では、性格特性についても詳しく調べられています。すると誠実性(正直さや倫理感)が高い人は、どんな状況でも嘘を避ける傾向が強く、誠実性が低い人々は、金銭的利益や面倒な作業を避けるために嘘をつきやすい傾向が見られたのです。
つまり、今回のような嘘を簡単につける状況で、しかも嘘をつけば利益が得られる状況でも、誠実性の高い人は一貫して嘘を避けていたのです。

一方で、誠実性が低い人達は、どれだけ期間を空けても、一貫して嘘をつく選択を繰り返しました。
この研究の結果は、嘘をつく行動が人によって一貫しているという事実を示した点が重要なポイントです。
つまりその人の状況や考え方が変化する期間を置いても、この行動パターンが繰り返されるということは、不正に対して十分な罰則などの介入がない限り、その人の行動は基本的に変わることがないということを示しています。
これは、企業や社会での不正行為を防ぐための取り組みがどれほど重要かを理解する手がかりにもなります。
大した利益にもならないことで立場ある人が嘘や不正をしているとしたら、それはその人の若い頃からの性格によるものかもしれません。
そのため、不正をする傾向が強い人々には、早期の介入や教育が必要であることが分かります。
特に、企業や学校などでの不正行為を減らすためには、単に罰を与えるのではなく、誠実性を高める教育や、倫理観を養うための社会的な取り組みが効果的であると考えられます。
不正を働くような人は、どんな立場や状況になってもそれを繰り返す可能性があります。そのことを心に留めておきましょう。
参考文献
Once a Liar, always a Liar?
https://www.mpg.de/24406277/0328-stra-once-a-liar-always-a-liar-151860-x
元論文
Cheat, cheat, repeat: On the consistency of dishonest behavior in structurally comparable situations.
https://psycnet.apa.org/doi/10.1037/pspp0000540
ライター
相川 葵: 工学出身のライター。歴史やSF作品と絡めた科学の話が好き。イメージしやすい科学の解説をしていくことを目指す。
編集者
ナゾロジー 編集部
Views: 0


AmazonにてASUSのゲーミングPCが特別価格で販売されている。期間は4月17日23時59分まで。
対象商品には、動画編集などにも適した、インテルCorei5-14400Fプロセッサー/GeForce RTX 4060搭載のゲーミングデスクトップPC「ROG Strix G13CHR」と、AMD Ryzen 9 7940HSプロセッサー/GeForce RTX 4060搭載のゲーミングノートPC「ROG Flow X13 GV302XV」がラインナップされている。
なお、購入する際は、セール価格で販売されているかどうかを確認してから購入してほしい。
OS:Windows 11 Home 64bit(日本語版)
CPU:インテル Core i5-14400F プロセッサー
GPU:NVIDIA GeForce RTX 4060
メモリ:32GB DDR5-5600
ストレージ:1TB(PCI Express 4.0 x4接続 NVMe/M.2)
OS:Windows 11 Home 64bit(日本語版)
CPU:AMD Ryzen 9 7940HS 8コア/16スレッド+Radeon グラフィックス
GPU:NVIDIA GeForce RTX 4060 Laptop GPU
メモリ:16GB LPDDR5-6400
ストレージ:1TB(SSD)
Views: 0


「ちりめんじゃこ」に潜む”あいつら”を好きなだけ探せるゲーム。「手」と「ピンセット」を切り替えながら、大量の「ちりめんじゃこ」のなかから、そうではないものを見つけていく
Source link
Views: 0


『デビル メイ クライ 5(Devil May Cry 5)』のSteam同時接続数が記事執筆時点での直近24時間で6,809人まで伸びています。
本作は、2019年3月にリリースされたスタイリッシュアクションゲームシリーズ最新作。2022年10月時点では、全世界売上が600万本を突破しています。
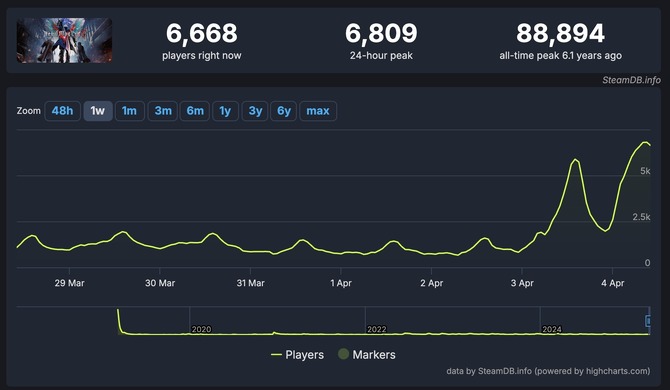
最高同時接続数は、SteamDBによると6.1年前の88,894人となっていますが、ここ一ヶ月は、同時接続数は多くても2,500人前後、直近1週間でみると1,500人前後となっていました。しかし、4月3日23時に急激に増加し、5,889人に。4月4日18時には、6,809人となっています。
Netflixでは、4月3日からアニメ「Devil May Cry」を配信。またSteamでは、最大75%オフの『デビル メイ クライ』FRANCHISE SALEを開催中。これらの影響により、同時接続人数が大幅に増加したようです。

『デビル メイ クライ 5』は、PC(Steam)/PS4/Xbox One向けに、『デビル メイ クライ 5 スペシャルエディション』が、PS5/Xbox Series X|S向けに発売中です。


Views: 0


アンケートではまず「推し活」をしているユーザーに対し、どのジャンルを応援しているかを調査。上位5項目は以下の通りです。
・アーティスト/ミュージシャン
・アイドル(国内・海外問わず)
・キャラクター・アニメ/漫画
・俳優/女優
・スポーツ選手/チーム
「推し活をしている方へ。推し疲れしてしまった経験はありますか?」という質問に対し、「ある 33%」「ない 67%」という結果に。
約3分の1のファンが推し疲れを経験していることが明らかになりました。
・推し活にお金がかかりすぎた
・自分の生活や仕事が忙しくなった
・推し活に時間がかかりすぎた
・情報や供給についていけなくなった
・SNSのファン同士のトラブルやマウント合戦
推し疲れは特に経済的負担と時間的制約が大きな要因となっているよう。
近年のグッズ展開の多様化やイベント・配信の増加が、ファンの負担増につながっている可能性も考えられます。
「推し疲れした後、推し活はどうなりましたか?」という質問への回答順位は以下の通りでした。
・推し活のペースを落とした
・別の趣味を見つけた
・少し休んでまた再開した
・推し活をやめた
・他の推しに乗り換えた
完全に離れるのではなく、ペースダウンや一時休止という形で対応する人が多い結果に。
「少し休んでまた再開した」と回答した方に「推し疲れから立ち直る、一番のきっかけは何でしたか?」と質問した結果は以下の通りでした。
・時間を置いた
・推しへの愛を再確認した
・推し活以外の趣味を楽しんだ
・ファン仲間と話をした
・推しの新しい供給があった
適度な距離感の確保や客観的な視点を持つことが、健全な推し活の継続につながるようです。
現代のファン文化における「推し疲れ」の実態が明らかになった今回の調査。
自分のペースを大切にしながら、無理なく楽しく推し活を続けるヒントが詰まった貴重なデータとなりました!
調査方法:「QR/バーコードリーダー・アイコニット」アプリ内アンケート
実施時期:2025年1月7日
有効回答者数:21,883人
※アンケート結果の出典元:「アイコニット・リサーチ」調べ
Views: 0

Rustは「安全な言語」として知られています。特にメモリ安全性の面では優れた言語設計が施されていますが、それだけですべての問題が解決するわけではありません。コンパイラは多くのバグを捕捉してくれますが検出できない落とし穴も存在します。
上記の記事にRustで安全なコードを書く際によく遭遇する落とし穴と、それらを避けるためのベストプラクティスが非常によくまとまっていました。いくつか紹介します。
Rustのコンパイラは優秀ですが、以下のような問題は検出できません:
unwrapやexpectの使用による意図しないパニックbuild.rsスクリプトそれでは、よくある落とし穴とその対策を見ていきましょう。
整数のオーバーフローはよくある問題です。次のコードを見てみましょう:
// 良くない例:オーバーフローの可能性がある
fn calculate_total(price: u32, quantity: u32) -> u32 {
price * quantity // 大きな数値の場合、オーバーフローする可能性あり!
}
この例では、priceとquantityが大きな値の場合、結果がオーバーフローする可能性があります。デバッグモードではパニックしますが、リリースモードではラップアラウンドします(値が最大値を超えると0から再度カウントを始める)。
// 良い例:チェック付き算術演算
fn calculate_total(price: u32, quantity: u32) -> Resultu32, ArithmeticError> {
price.checked_mul(quantity)
.ok_or(ArithmeticError::Overflow)
}
checked_mulなどのメソッドを使うと、オーバーフローが発生した場合にNoneを返してくれるので、適切にエラー処理ができます。
また、Cargo.tomlに以下を追加しておくとリリースビルドでもオーバーフローチェックが有効になるそうです。覚えておきたいですね:
[profile.release]
overflow-checks = true
asを安易に使わない数値型の変換にはよくasキーワードが使われますが、これは安全でない場合があります:
let x: i32 = 1000;
let y: i8 = x as i8; // 値が範囲外なので切り捨てられる!
この例では、i32からi8への変換で値が切り捨てられ、予期しない結果になります。
Rustには3つの主要な数値変換方法があります:
asキーワード:便利だが安全でない(値が切り捨てられる可能性あり)From::from():データ損失のない変換のみ許可(拡大変換に最適)TryFrom:変換が失敗する可能性がある場合にResultを返す// 良い例:TryFromを使った安全な変換
use std::convert::TryFrom;
let x: i32 = 1000;
let y = i8::try_from(x).map_err(|_| "値が大きすぎます")?;
この方法なら、変換が失敗した場合にエラー処理ができます。
数値が特定の条件を満たす必要がある場合、単純なプリミティブ型ではなく、境界つき型を使いましょう。
// 良くない例:無制限の数値型
struct Product {
price: f64, // マイナスの可能性あり!
quantity: i32, // マイナスの可能性あり!
}
// 良い例:境界つき型
#[derive(Debug, Clone, Copy)]
struct NonNegativePrice(f64);
impl NonNegativePrice {
pub fn new(value: f64) -> ResultSelf, PriceError> {
if value 0.0 || !value.is_finite() {
return Err(PriceError::Invalid);
}
Ok(NonNegativePrice(value))
}
}
struct Product {
price: NonNegativePrice,
quantity: std::num::NonZeroU32, // 0以外の正の整数のみ
}
この方法では、不正な値を持つオブジェクトが作れなくなります。
getメソッドを使う配列やベクトルへの直接のインデックスアクセスは危険です:
let arr = [1, 2, 3];
let elem = arr[3]; // 範囲外アクセスでパニック!
getメソッドでオプション値を返すlet arr = [1, 2, 3];
if let Some(elem) = arr.get(3) {
println!("4番目の要素: {}", elem);
} else {
println!("4番目の要素はありません");
}
split_atよりsplit_at_checkedを使うスライスを分割する際も同様に注意が必要です:
let arr = [1, 2, 3];
let (left, right) = arr.split_at(4); // 範囲外でパニック!
let arr = [1, 2, 3];
match arr.split_at_checked(3) {
Some((left, right)) => println!("分割成功: {:?} と {:?}", left, right),
None => println!("インデックスが範囲外です")
}
文字列などのプリミティブ型をそのまま使うと、バリデーションが困難になります:
// 良くない例:制限のないString型
fn authenticate_user(username: String) {
// ユーザー名が空かも?特殊文字が含まれているかも?
}
#[derive(Debug, Clone, PartialEq, Eq, Hash)]
struct Username(String);
impl Username {
pub fn new(name: &str) -> ResultSelf, UsernameError> {
if name.is_empty() {
return Err(UsernameError::Empty);
}
if name.len() > 30 {
return Err(UsernameError::TooLong);
}
if !name.chars().all(|c| c.is_alphanumeric() || c == '_') {
return Err(UsernameError::InvalidCharacters);
}
Ok(Username(name.to_string()))
}
pub fn as_str(&self) -> &str {
&self.0
}
}
fn authenticate_user(username: Username) {
// ユーザー名は常に有効!
}
この方法なら、関数に渡される時点で値が有効であることが保証されます。
フィールドの組み合わせによっては無効な状態が生じることがあります:
// 良くない例:不正な組み合わせが可能
struct Configuration {
port: u16,
host: String,
ssl_enabled: bool,
ssl_cert: OptionString>, // ssl_enabled=trueなのに証明書がNoneという状態が可能
}
// 良い例:型で状態を強制
enum ConnectionSecurity {
Insecure,
Ssl { cert_path: String }, // 証明書なしのSSLは表現できない
}
struct Configuration {
port: u16,
host: String,
security: ConnectionSecurity,
}
この方法では、「SSL有効だが証明書がない」という無効な状態を表現できなくなります。
Defaultの実装は慎重に何も考えずにDefaultを実装すると問題が生じることがあります:
// 良くない例:不適切なデフォルト値
#[derive(Default)]
struct ServerConfig {
port: u16, // 0になる(有効なポートではない)
max_connections: usize, // 0になる
timeout_seconds: u64, // 0になる
}
// 良い例:明示的な初期化
struct ServerConfig {
port: Port,
max_connections: std::num::NonZeroUsize,
timeout: std::time::Duration,
}
impl ServerConfig {
pub fn new(port: Port) -> Self {
Self {
port,
max_connections: NonZeroUsize::new(100).unwrap(),
timeout: Duration::from_secs(30),
}
}
}
Debug実装時は機密情報に注意Debugトレイトを自動導出すると、機密情報が漏洩する恐れがあります:
// 良くない例:機密情報が表示される
#[derive(Debug)]
struct User {
username: String,
password: String, // デバッグ出力で見えてしまう!
}
Debugを手動実装する#[derive(Debug)]
struct User {
username: String,
password: Password,
}
struct Password(String);
impl std::fmt::Debug for Password {
fn fmt(&self, f: &mut std::fmt::Formatter'_>) -> std::fmt::Result {
f.write_str("[REDACTED]")
}
}
これにより、デバッグ出力時にパスワードが「[REDACTED]」と表示されるようになります。
また、次のような実装もあります:
impl std::fmt::Debug for DatabaseURI {
fn fmt(&self, f: &mut std::fmt::Formatter'_>) -> std::fmt::Result {
// 構造体を分解して、フィールドが追加された場合にコンパイルエラーになるようにする
let DatabaseURI { scheme, user, password: _, host, database, } = self;
write!(f, "{scheme}://{user}:[REDACTED]@{host}/{database}")?;
Ok(())
}
}
serdeのSerializeとDeserializeを自動導出すると、思わぬ問題が生じることがあります:
// 良くない例:チェックなしのシリアライズ
#[derive(Serialize, Deserialize)]
struct UserCredentials {
#[serde(default)] // デシリアライズ時に空文字を受け入れる
username: String,
#[serde(default)]
password: String, // シリアライズ時に平文で出力される
}
#[derive(Deserialize)]
#[serde(try_from = "String")]
pub struct Password(String);
impl TryFromString> for Password {
type Error = PasswordError;
fn try_from(value: String) -> ResultSelf, Self::Error> {
if value.len() 8 {
return Err(PasswordError::TooShort);
}
Ok(Password(value))
}
}
この方法では、デシリアライズ時に自動的に検証が行われます。
機密データを比較する際は、実行時間の差から情報が漏れる可能性があります:
// 良くない例:単純な比較
fn verify_password(stored: &[u8], provided: &[u8]) -> bool {
stored == provided // タイミング攻撃に弱い
}
// 良い例:定数時間比較
use subtle::{ConstantTimeEq, Choice};
fn verify_password(stored: &[u8], provided: &[u8]) -> bool {
stored.ct_eq(provided).unwrap_u8() == 1
}
無制限の入力を受け付けると、DoS攻撃の原因になります:
// 良くない例:サイズ制限なし
fn process_request(data: &[u8]) -> Result(), Error> {
let decoded = decode_data(data)?; // 巨大なデータでメモリを使い果たす可能性
// 処理
Ok(())
}
// 良い例:明示的なサイズ制限
const MAX_REQUEST_SIZE: usize = 1024 * 1024; // 1MiB
fn process_request(data: &[u8]) -> Result(), Error> {
if data.len() > MAX_REQUEST_SIZE {
return Err(Error::RequestTooLarge);
}
let decoded = decode_data(data)?;
// 処理
Ok(())
}
Path::joinの挙動に注意パスを結合する際のPath::joinメソッドには注意が必要です:
use std::path::Path;
fn main() {
let path = Path::new("/usr").join("/local/bin");
println!("{path:?}"); // "/local/bin" と出力される
}
第2引数が絶対パスの場合、第1引数は無視されます。 これは意図しない動作につながる可能性があります。
自分のコードだけでなく、依存ライブラリのunsafeコードも脆弱性の原因になります。
cargo-geigerで依存関係をチェックcargo install cargo-geiger
cargo geiger
このツールを使うと、プロジェクトの依存関係に含まれるunsafe関数の数を確認できます。
Rustのlintツール「Clippy」を使うと、前述の多くの問題をコンパイル時に検出できます:
// 数値演算関連
#![deny(arithmetic_overflow)]
#![deny(clippy::checked_conversions)]
#![deny(clippy::cast_possible_truncation)]
// unwrap関連
#![deny(clippy::unwrap_used)]
#![deny(clippy::expect_used)]
// 配列インデックス関連
#![deny(clippy::indexing_slicing)]
// その他
#![deny(clippy::join_absolute_paths)]
#![deny(clippy::serde_api_misuse)]
覚えておきたいのが:
cargo check はこれらの問題を報告しません
cargo run は実行時にパニックするか失敗します一方
cargo clippy はコンパイル時にすべての問題を検出します!Rustは安全な言語として設計されていますが、コンパイラだけでは検出できない問題も多くあります。実践的な対策も紹介されており大変参考になりました。
Views: 0
inmobilexion(インモビ)は、動画・ニュース・サイト紹介を中心に、信頼性の高い情報をわかりやすくお届けする情報プラットフォームです。 「in-mobile」×造語の"〜xion"から生まれたインモビは、厳選・接続・導線など多様な意味を内包しながら、次世代の情報体験を提案します。
Contact us: [email protected]
© インモビ by inmobilexion.com


 筆圧に合わせた濃淡が出しやすく、繊細な表現が可能なタッチ筆ペン「BuTouch」が人気。
筆圧に合わせた濃淡が出しやすく、繊細な表現が可能なタッチ筆ペン「BuTouch」が人気。