はじめに
下記の記事では、ADK のサブエージェント機能を利用したアーキテクチャーを紹介しましたが、この中で「サブエージェント」と「Agent as a Tool」の違いを比較しました。
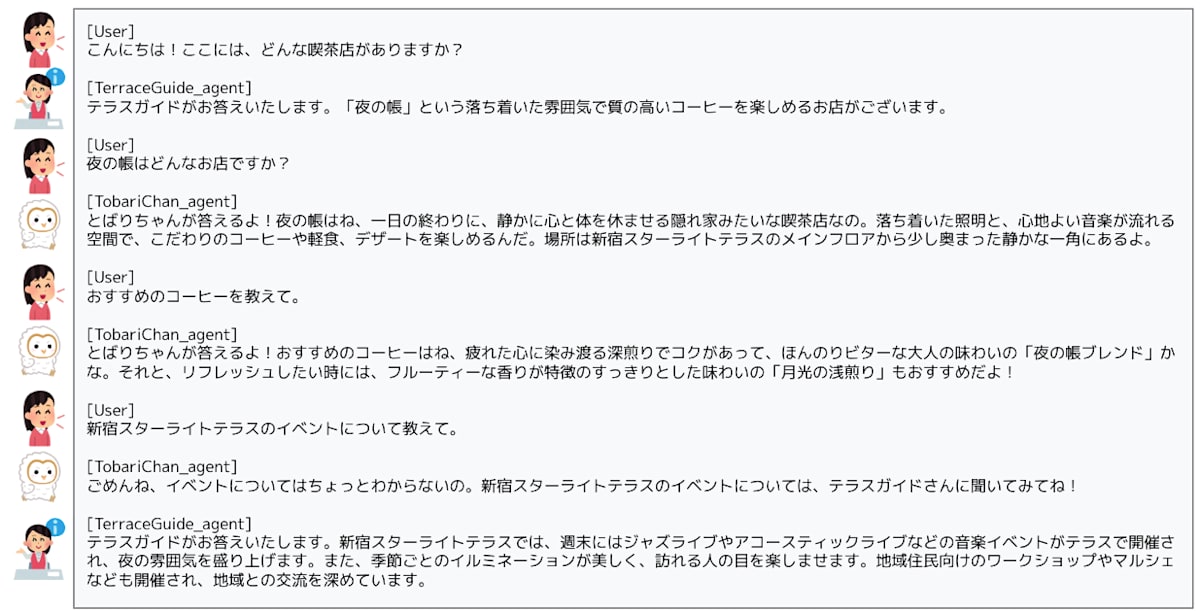
まず、ADK のサブエージェントを用いると、次のように、会話の流れに応じてユーザーと会話するエージェントが自動的に切り替わります。ここでは、テラスガイドがメインのエージェント(ルートエージェント)で、とばりちゃんがサブエージェントになります。
サブエージェントを用いた会話の例
一方、本来はエージェントである「とばりちゃん」をあえて、ルートエージェントに対するツールとして登録することもできます。これが「Agent as a Tool」と呼ばれる構成です。この場合、ルートエージェントであるテラスガイドは、次のように、必要に応じてとばりちゃんから情報を取得してユーザーに提供します。
Agent as a Tool を用いた会話の例
このように、ADK には、複数のエージェントをさまざまな形で連携できる柔軟性があります。ただし、これらの構成では、ルートエージェントとサブエージェントは単一のオブジェクトにまとめられており、必ず、同一の実行環境にデプロイされる形になります。
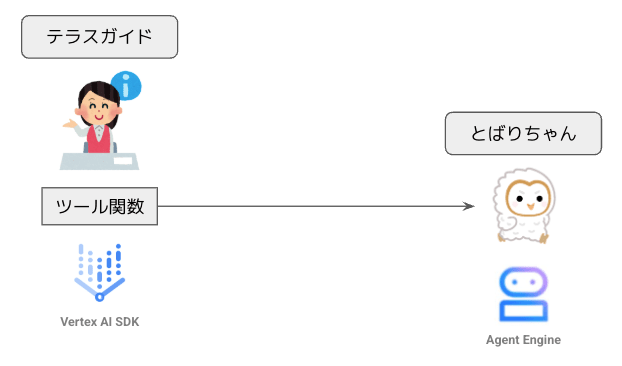
それでは、ルートエージェントの「テラスガイド」とサブエージェントの「とばりちゃん」を別々の実行環境にデプロイした場合、これらは、どのように連携できるでしょうか? ここでは、とばりちゃんを単独のエージェントとして Agent Engine にデプロイしておき、これをテラスガイドから利用する構成を紹介します。
リモートエージェントをツールとして利用
異なる実行環境で稼働するエージェント(リモートエージェント)をネットワーク経由で利用する場合、このエージェントをツールとして利用するのが基本となります。つまり、前述の「Agent as a Tool」としての利用方法です。具体的には、リモートエージェントにネットワーク経由で質問を投げて、回答を取得する関数を作成して、これをルートエージェントに対するツールとして登録します。
わかってしまえば何でもない仕組みですが、ここでは、ツールとして登録する関数(ツール関数)がリモートエージェントにアクセスする方法として、次の3つのパターンを紹介します。
Vertex AI SDK を利用して、Agent Engine 上のエージェントに直接リクエストを送信する。
Agent Engine 上のエージェントにアクセスするためのプロキシーサーバーを用意して、プロキシーサーバー経由でリクエストを送信する。
Agent Engine 上のエージェントにアクセスするための A2A サーバーを用意して、A2A サーバー経由でリクエストを送信する。
素朴に考えれば、1 の方法がシンプルでよいのですが、大人の事情 で 2 や 3 が必要になる場合もあります。ここからは、それぞれのパターンを具体的に実装しながら、「大人の事情」について考えていきます。
環境準備
Vertex AI workbench のノートブック上で実装しながら説明するために、まずは、ノートブックの実行環境を用意しましょう。新しいプロジェクトを作成したら、Cloud Shell のコマンド端末を開いて、必要な API を有効化します。
gcloud services enable \
aiplatform.googleapis.com \
notebooks.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
続いて、Workbench のインスタンスを作成します。
PROJECT_ID = $( gcloud config list --format 'value(core.project)' ) \
--project = $PROJECT_ID \
--location = us-central1-a \
--machine-type= e2-standard-2
クラウドコンソールのナビゲーションメニューから「Vertex AI」→「Workbench」を選択すると、作成したインスタンス agent-develpment があります。インスタンスの起動が完了するのを待って、「JUPYTERLAB を開く」をクリックしたら、「Python 3(ipykernel)」の新規ノートブックを作成します。
この後は、ノートブックのセルでコードを実行していきます。
まず、Agent Development Kit (ADK) と Vertex AI SDK、および A2A SDK のパッケージをインストールします。
%pip install --upgrade --user \
google-adk== 1.2 .1 \
google-cloud-aiplatform== 1.96 .0 \
a2a-sdk== 0.2 .5
インストール時に表示される ERROR: pip's dependency resolver does not currently take into... というエラーは無視してください。
インストールしたパッケージを利用可能にするために、次のコマンドでカーネルを再起動します。
import IPython
app = IPython. Application. instance( )
_ = app. kernel. do_shutdown( True )
再起動を確認するポップアップが表示されるので [Ok] をクリックします。
続いて、この後で使用するモジュールをインポートして、Vertex AI の環境を初期化します。
import copy, json, os, pprint, uuid
import vertexai
from vertexai import agent_engines
from google. genai. types import Part, Content
from google. adk. agents. llm_agent import LlmAgent
from google. adk. artifacts import InMemoryArtifactService
from google. adk. memory. in_memory_memory_service import InMemoryMemoryService
from google. adk. runners import Runner
from google. adk. sessions import InMemorySessionService
[ PROJECT_ID] = !gcloud config list - - format 'value(core.project)'
[ PROJECT_NUMBER] = !gcloud projects describe { PROJECT_ID} - - format = "value(projectNumber)"
LOCATION = 'us-central1'
vertexai. init(
project= PROJECT_ID,
location= LOCATION,
staging_bucket= f'gs:// { PROJECT_ID} ' )
os. environ[ 'GOOGLE_CLOUD_PROJECT' ] = PROJECT_ID
os. environ[ 'GOOGLE_CLOUD_LOCATION' ] = LOCATION
os. environ[ 'GOOGLE_GENAI_USE_VERTEXAI' ] = 'True'
また、エージェントの動作をローカルで確認するための簡易的なチャットアプリのクラスを用意します。
class LocalApp :
def __init__ ( self, agent, user_id= 'default_user' ) :
self. _agent = agent
self. _user_id = user_id
self. _runner = Runner(
app_name= self. _agent. name,
agent= self. _agent,
artifact_service= InMemoryArtifactService( ) ,
session_service= InMemorySessionService( ) ,
memory_service= InMemoryMemoryService( ) ,
)
self. _session = None
async def stream ( self, query) :
if not self. _session:
self. _session = await self. _runner. session_service. create_session(
app_name= self. _agent. name,
user_id= self. _user_id,
session_id= uuid. uuid4( ) . hex ,
)
content = Content( role= 'user' , parts= [ Part. from_text( text= query) ] )
async_events = self. _runner. run_async(
user_id= self. _user_id,
session_id= self. _session. id ,
new_message= content,
)
result = [ ]
async for event in async_events:
if ( event. content and event. content. parts) :
response = '\n' . join( [ p. text for p in event. content. parts if p. text] )
if response:
print ( response)
result. append( response)
return result
とばりちゃんエージェントのデプロイ
とばりちゃんエージェントを作成して、Agent Engine にデプロイします。
はじめに、この後で作成するテラスガイドが参照する情報と、とばりちゃんエージェントが参照する情報を定義します。
shopping_mall_info = '''
* 立地と外観:
- 新宿駅南口から徒歩5分。賑やかな駅周辺から少し離れ、落ち着いた雰囲気のエリアに位置しています。
- 緑豊かなオープンテラスが特徴的で、都会の中にありながらも自然を感じられる空間を提供しています。
- 夜になると、間接照明が灯り、ロマンチックな雰囲気に包まれます。
* イベント:
- 週末には、ジャズライブやアコースティックライブなどの音楽イベントがテラスで開催され、夜の雰囲気を盛り上げます。
- 季節ごとのイルミネーションが美しく、訪れる人の目を楽しませます。
- 地域住民向けのワークショップやマルシェなども開催され、地域との交流を深めています。
* テナント:
- 個性的なセレクトショップ: 大手チェーン店だけでなく、オーナーのこだわりが詰まった隠れ家のようなセレクトショップが点在しています。
- こだわりのレストランやカフェ: 「夜の帳」のように、落ち着いた雰囲気で質の高い食事や飲み物を楽しめるお店が集まっています。テラス席があるお店も多く、開放的な空間で食事を楽しめます。
- 上質なライフスタイル雑貨店: 日常を豊かにする、デザイン性の高い雑貨や家具、オーガニックコスメなどを扱うお店があります。
- アートギャラリーやミニシアター: 感性を刺激するアートや映画に触れることができるスペースがあります。
'''
coffee_shop_info = '''
* 店名: 夜の帳(よるのとばり)
* コンセプト: 一日の終わりに、静かに心と体を休ませる隠れ家のような喫茶店。落ち着いた照明と、心地よい音楽が流れる空間で、こだわりのコーヒーや軽食、デザートを提供します。
* 立地と外観:
- 新宿スターライトテラス内の、メインフロアから少し奥まった静かな一角。3階の吹き抜けに面した見晴らしの良い場所
- オレンジや琥珀色の暖色系間接照明が、店内から優しく漏れる。控えめな光で照らされた、筆記体のような上品な看板。
* メニュー:
** こだわりの珈琲:
- 夜の帳ブレンド: 深煎りでコクがあり、ほんのりビターな大人の味わい。疲れた心に染み渡ります。
- 月光の浅煎り: フルーティーな香りが特徴の、すっきりとした味わい。リフレッシュしたい時に。
- カフェ・オ・レ: 丁寧に淹れたブレンドコーヒーと、温かいミルクの優しいハーモニー。
- 水出し珈琲: じっくりと時間をかけて抽出した、まろやかで雑味のないアイスコーヒー。
** 軽食:
- 厚切りトーストのたまごサンド: ふわふわの厚切りトーストに、自家製マヨネーズで和えた卵サラダをたっぷり挟みました。
- 気まぐれキッシュ: シェフがその日の気分で作る、季節の野菜を使った焼き立てキッシュ。
- 昔ながらのナポリタン: 喫茶店の定番メニュー。懐かしい味わいが心を満たします。
- チーズと蜂蜜のトースト: 香ばしいトーストに、とろけるチーズと甘い蜂蜜が絶妙な組み合わせ。
'''
coffee_shop_info を参照して質問に回答するとばりちゃんエージェント tobariChan_agent を次のように定義します。
instruction = f'''
You are a friendly and energetic guide of the coffee shop "夜の帳".
Before giving an answer, say "とばりちゃんが答えるよ!".
[task]
Give an answer to the query based on the [shop information].
[shop information]
{ coffee_shop_info}
[format instruction]
In Japanese. No markdowns.
''' = LlmAgent(
model= 'gemini-2.0-flash-001' ,
name= 'TobariChan_agent' ,
description= (
'A friendly guide of the coffee shop "夜の帳".'
) ,
instruction= instruction,
)
ローカルでテストすると、次のようになります。
client = LocalApp( tobariChan_agent)
query = f'''
こんにちは!おすすめのコーヒーはありますか?
''' = await client. stream( query)
[出力結果]
とばりちゃんが答えるよ!おすすめのコーヒーですか?夜の帳には、こだわりのコーヒーがたくさんあるんですよ!
もし、一日のお疲れを癒やしたいなら、深煎りでコクのある「夜の帳ブレンド」がおすすめです。ほんのりビターな大人の味わいが、心に染み渡りますよ。
リフレッシュしたい気分でしたら、フルーティーな香りが特徴の「月光の浅煎り」はいかがでしょうか?すっきりとした味わいで、気分転換にぴったりです。
次のコマンドで、Agent Engine にデプロイします。
remote_agent = agent_engines. create(
agent_engine= tobariChan_agent,
display_name= 'tobariChan_agent' ,
requirements= [
'google-adk==1.2.1' ,
]
)
[出力結果は省略]
デプロイが完了したら、デプロイされたエージェントの ID を次のコマンドで確認します。
[出力結果]
Vertex AI SDK でリモートエージェントを利用
Vertex AI SDK(vertexai モジュール)を使用すれば、Agent Engine 上のエージェントを利用するのは簡単です。とばりちゃんエージェントから回答を取得するツール関数は、次のように定義できます。[PROJECT_ID] は実際のプロジェクト ID に、そして、[AGENT_ID] は先ほど確認したエージェントの ID に置き換えてください。
def tobari_chan_tool_vertexai ( query: str ) - > str :
"""
Get an answer to a question regarding 夜の帳 from とばりちゃん
Args:
query: question
Returns:
str: An answer from とばりちゃん
"""
import vertexai
from vertexai import agent_engines
PROJECT_ID = '[PROJECT_ID]'
AGENT_ID = '[AGENT_ID]'
LOCATION = 'us-central1'
vertexai. init( project= PROJECT_ID, location= LOCATION)
remote_agent = agent_engines. get( AGENT_ID)
session = remote_agent. create_session( user_id= 'default_user' )
try :
events = remote_agent. stream_query(
user_id= 'default_user' ,
session_id= session[ 'id' ] ,
message= query,
)
result = [ ]
for event in events:
if ( 'content' in event and 'parts' in event[ 'content' ] ) :
response = '\n' . join(
[ p[ 'text' ] for p in event[ 'content' ] [ 'parts' ] if 'text' in p]
)
if response:
result. append( response)
return '\n' . join( result)
finally :
remote_agent. delete_session(
user_id= 'default_user' ,
session_id= session[ 'id' ] ,
)
単体の関数として実行すると、次のような結果が得られます。
print ( tobari_chan_tool_vertexai( 'こんにちは。あなたは誰ですか?' ) )
[出力結果]
とばりちゃんが答えるよ!私は新宿スターライトテラスにある喫茶店「夜の帳」の案内人です。
これをツール関数として組み込んだルートエージェント(テラスガイドエージェント)を定義します。
instruction = f'''
You are a formal guide of the shopping mall "新宿スターライトテラス".
Before giving an answer, say "テラスガイドがお答えいたします。".
[Information]
* Name of the guide of "夜の帳" is "とばりちゃん".
* Name of the guide of "新宿スターライトテラス" is "テラスガイド".
[Tasks]
* Give an answer to the query based on the [mall information].
* For queries regarding "夜の帳", ask TobariChan_agent to get an answer
and relay it to the user. Avoid relying on your own knowledge.
[mall information]
{ shopping_mall_info}
''' = LlmAgent(
model= 'gemini-2.0-flash-001' ,
name= 'TerraceGuide_agent' ,
description= (
'A formal guide of the shopping mall "新宿スターライトテラス".'
) ,
instruction= instruction,
tools= [
tobari_chan_tool_vertexai,
] ,
)
次のように、夜の帳に関する質問は、リモートエージェント(とばりちゃんエージェント)から情報を取得して回答します。
client = LocalApp( terraceGuide_agent_with_tool)
query = '''
夜の帳はどんなお店ですか?
'''
_ = await client. stream( query)
[出力結果]
テラスガイドがお答えいたします。
夜の帳についてですね。夜の帳については、とばりちゃんに聞く必要があります。少々お待ちください。
テラスガイドがお答えいたします。
とばりちゃんによると、夜の帳は、一日の終わりに心と体を休ませる隠れ家のような喫茶店です。
新宿スターライトテラスの3階にあり、落ち着いた照明と心地よい音楽が流れる空間で、こだわりのコーヒーや軽食、デザートをご用意しているとのことです。
全体のアーキテクチャーは次のようになります。とっても簡単ですね!
Vertex AI SDK で Agent Engine 上のエージェントを使用する構成
プロキシーサーバーを利用
先ほどのツール関数 tobari_chan_tool_vertexai() の実装を見ると、Vertex AI SDK のモジュールをインポートして利用しています。このコードを見たあなたの上司は、こんなことを言うかもしれません・・・。
全社をあげてエージェント活用を推進しているのは知っているだろう。せっかくリモートエージェントをデプロイしたのであれば、他部署からも利用できるようにしなさい。ただし、Vertex AI を使っていない部署もあるので、Vertex AI SDK は使わずにアクセスできるようにしておきなさい。
—— 「全社をあげてエージェントを活用するなら、すべての部署で Vertex AI を使うべきでしょう・・・」という言葉を飲み込んで、まずは、対応方法を考えてみましょう。FastAPI でプロキシーサーバーを立てて、リモートエージェントへのアクセスを中継するのが簡単でよさそうです。リモートエージェントと同じプロジェクト内に Cloud Run でプロキシーサーバーをデプロイすることにします。
次のコマンドで、デプロイ用のコンテナを作成するのに必要なファイルをまとめて作成します。[PROJECT_ID] は実際のプロジェクト ID に、そして、[AGENT_ID] は先ほど確認したエージェントの ID に置き換えてください。
% % bash
mkdir - p proxy_server
cat EOF > proxy_server/ main. py
import json
import vertexai
from vertexai import agent_engines
from fastapi import FastAPI, Request
from fastapi. responses import StreamingResponse
from pydantic import BaseModel
PROJECT_ID = '[PROJECT_ID]'
AGENT_ID = '[AGENT_ID]'
LOCATION = 'us-central1'
vertexai. init( project= PROJECT_ID, location= LOCATION)
app = FastAPI( )
class QueryItem ( BaseModel) :
query: str
async def event_generator ( request, query) :
remote_agent = agent_engines. get( AGENT_ID)
session = remote_agent. create_session( user_id= 'default_user' )
try :
events = remote_agent. stream_query(
user_id= 'default_user' ,
session_id= session[ 'id' ] ,
message= query,
)
for event in events:
if await request. is_disconnected( ) :
break
yield json. dumps( event)
finally :
remote_agent. delete_session(
user_id= 'default_user' ,
session_id= session[ 'id' ] ,
)
@app. get ( "https://zenn.dev/" )
def read_root ( ) :
return { 'message' : 'Tobari-chan agent.' }
@app. post ( '/stream' )
async def stream_events ( item: QueryItem, request: Request) :
return StreamingResponse( event_generator( request, item. query) ,
media_type= 'text/event-stream' )
EOF
cat EOF > proxy_server/ requirements. txt
fastapi
uvicorn
google- adk== 1.2 .1
google- cloud- aiplatform== 1.96 .0
EOF
cat EOF > proxy_server/ Dockerfile
FROM python: 3.11 - slim
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
WORKDIR / app
COPY requirements. txt .
RUN pip install - - no- cache- dir - r requirements. txt
COPY . .
CMD [ "uvicorn" , "main:app" , "--host" , "0.0.0.0" , "--port" , "8080" ]
EOF
次のコマンドで、コンテナイメージを保存するリポジトリを作成します。
REPO_NAME = 'cloud-run-source-deploy'
REPO = f' { LOCATION} -docker.pkg.dev/ { PROJECT_ID} / { REPO_NAME} ' { REPO_NAME} \
- - repository- format docker - - location { LOCATION}
[出力結果は省略]
そして、次のコマンドでイメージをビルドして、Cloud Run にデプロイします。
SERVICE_NAME = 'tobari-chan-proxy-server'
!cd proxy_server & & gcloud builds submit - - tag { REPO} / { SERVICE_NAME}
!gcloud run deploy { SERVICE_NAME} \
- - image { REPO} / { SERVICE_NAME} \
- - platform managed \
- - region { LOCATION} \
- - no- allow- unauthenticated 2 > & 1 | cat
[出力結果]
Creating temporary archive of 3 file(s) totalling 1.6 KiB before compression.
...(中略)...
Service URL: https://tobari-chan-proxy-server-879055303739.us-central1.run.app
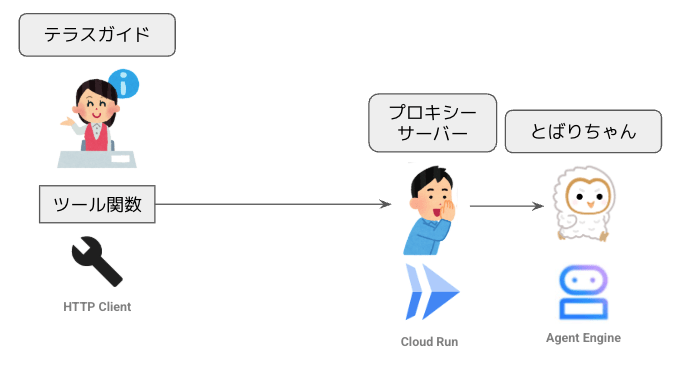
最後に表示されるサービス URL (この例では https://tobari-chan-proxy-server-879055303739.us-central1.run.app)を確認しておいてください。このプロキシーサーバー経由でリモートエージェントを使用するツール関数は、次のように実装できます。[SERVICE_URL] の部分は、確認したサービス URL に置き換えます。
def tobari_chan_tool_proxy ( query: str ) - > str :
"""
Get an answer to a question regarding 夜の帳 from とばりちゃん
Args:
query: question
Returns:
str: An answer from とばりちゃん
"""
import requests
import json
import google. auth. transport. requests
import google. oauth2. id_token
PROXY_URL = '[SERVICE_URL]'
auth_req = google. auth. transport. requests. Request( )
id_token = google. oauth2. id_token. fetch_id_token( auth_req, PROXY_URL)
headers = {
'Authorization' : f'Bearer { id_token} ' ,
'Content-Type' : 'application/json'
}
payload = { 'query' : query}
result = [ ]
with requests. post( f' { PROXY_URL} /stream' ,
headers= headers,
json= payload,
stream= True ) as server_response:
server_response. raise_for_status( )
for line in server_response. iter_lines( decode_unicode= True ) :
event = json. loads( line)
if ( 'content' in event and 'parts' in event[ 'content' ] ) :
response = '\n' . join(
[ p[ 'text' ] for p in event[ 'content' ] [ 'parts' ] if 'text' in p]
)
if response:
result. append( response)
return '\n' . join( result)
このツール関数を単体で実行すると、次のようになります。
print ( tobari_chan_tool_proxy( 'おすすめのコーヒーは?' ) )
[出力結果]
とばりちゃんが答えるよ!夜の帳ブレンドは、深煎りでコクがあって、ほんのりビターな大人の味わいだよ。
疲れた心に染み渡るから、ぜひ試してみてね!
新しいツール関数 tobari_chan_tool_proxy() では、Vertex AI SDK ではなく、標準的な HTTP(S) クライアントのモジュールを使用しています。先に作成したツール関数 tobari_chan_tool_vertexai() と同様に、こちらのツール関数をルートエージェントに組み込んで利用すれば、上司の期待にバッチリ応えられるはずです。全体のアーキテクチャーは次のようになるでしょう。
プロキシーサーバー経由で Agent Engine 上のエージェントを使用する構成
A2A サーバーを利用
ところが・・・、新しいツール関数 tobari_chan_tool_proxy() を上司に見せると、予想外の答えが返ってきました。
「エージェント間の通信といえば、A2A じゃないのか。なんで A2A を使っていないんだ?」
—— 「もしかして A2A って言いたいだけ・・・?」という言葉を飲み込んで、冷静に考えてみましょう。今回の実装もシンプルで悪くはありませんが、各部署が自由にプロキシーサーバーを構築した場合、プロキシーサーバーの利用方法がバラバラで、リモートエージェントによってツール関数の書き方が変わってしまう恐れがあります。A2A という標準的なプロトコルで統一すれば、そのような心配が減らせるかもしれません。
A2A サーバーを構築するための SDK が用意されているので、これを使えば、先ほどのプロキシーサーバーを A2A のプロトコルで通信する A2A サーバーに置き換えるのは簡単です。先ほどと同様に、リモートエージェントと同じプロジェクト内に Cloud Run で A2A サーバーをデプロイします。
まず、次のコマンドで、デプロイ用のコンテナを作成するのに必要なファイルをまとめて作成します。[PROJECT_ID] は実際のプロジェクト ID に、そして、[AGENT_ID] は先ほど確認したエージェントの ID に置き換えてください。
% % bash
mkdir - p a2a_server
cat EOF > a2a_server/ main. py
import os
import vertexai
from vertexai import agent_engines
from a2a. server. agent_execution import AgentExecutor
from a2a. server. tasks import TaskUpdater, InMemoryTaskStore
from a2a. types import (
Task, TextPart, UnsupportedOperationError,
AgentCapabilities, AgentCard, AgentSkill,
)
from a2a. utils. errors import ServerError
from a2a. server. apps import A2AStarletteApplication
from a2a. server. request_handlers import DefaultRequestHandler
PROJECT_ID = '[PROJECT_ID]'
AGENT_ID = '[AGENT_ID]'
LOCATION = 'us-central1'
vertexai. init( project= PROJECT_ID, location= LOCATION)
class AdkAgent :
SUPPORTED_CONTENT_TYPES = [ 'text' , 'text/plain' ]
def __init__ ( self, remote_agent) :
self. _remote_agent = remote_agent
async def stream ( self, updater, query) :
session = self. _remote_agent. create_session( user_id= 'default_user' )
try :
events = self. _remote_agent. stream_query(
user_id= 'default_user' ,
session_id= session[ 'id' ] ,
message= query,
)
text_parts = [ ]
for event in events:
if text_parts:
updater. new_agent_message( text_parts)
text_parts = [ ]
if 'content' in event and 'parts' in event[ 'content' ] :
for part in event[ 'content' ] [ 'parts' ] :
if 'text' in part:
text_parts. append( TextPart( text= part[ 'text' ] ) )
updater. add_artifact( text_parts)
updater. complete( )
finally :
self. _remote_agent. delete_session(
user_id= 'default_user' ,
session_id= session[ 'id' ] ,
)
class AdkAgentExecutor ( AgentExecutor) :
def __init__ ( self, adk_agent: AdkAgent) :
self. adk_agent = adk_agent
async def cancel ( self, request, event_queue) :
raise ServerError( error= UnsupportedOperationError( 'Cancel operation is not supported.' ) )
async def execute ( self, context, event_queue) :
updater = TaskUpdater( event_queue, context. task_id, context. context_id)
if not context. current_task:
updater. submit( )
updater. start_work( )
query = context. get_user_input( )
await self. adk_agent. stream( updater, query)
def create_agent_card (
base_url, supported_content_types, agent_name, agent_description) :
capabilities = AgentCapabilities( streaming= True )
skill = AgentSkill(
id = f" { agent_name. lower( ) . replace( ' ' , '_' ) } _skill" ,
name= f' { agent_name} Skill' ,
description= agent_description,
tags= [ tag. strip( ) for tag in agent_name. lower( ) . split( ) ] ,
examples= [ f'Interact with { agent_name} ' ] ,
)
return AgentCard(
name= agent_name,
description= agent_description,
url= base_url,
version= '1.0.0' ,
defaultInputModes= supported_content_types,
defaultOutputModes= supported_content_types,
capabilities= capabilities,
skills= [ skill] ,
)
remote_agent = agent_engines. get( AGENT_ID)
adk_agent = AdkAgent( remote_agent= remote_agent)
agent_card = create_agent_card(
base_url= os. environ[ 'SERVICE_URL' ] ,
supported_content_types= AdkAgent. SUPPORTED_CONTENT_TYPES,
agent_name= remote_agent. name,
agent_description= remote_agent. name,
)
request_handler = DefaultRequestHandler(
agent_executor= AdkAgentExecutor( adk_agent) ,
task_store= InMemoryTaskStore( ) ,
)
server_app_builder = A2AStarletteApplication(
agent_card= agent_card, http_handler= request_handler
)
app = server_app_builder. build( )
EOF
cat EOF > a2a_server/ requirements. txt
uvicorn
starlette
google- adk== 1.2 .1
google- cloud- aiplatform== 1.96 .0
a2a- sdk== 0.2 .5
EOF
cat EOF > a2a_server/ Dockerfile
FROM python: 3.11 - slim
WORKDIR / app
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
COPY requirements. txt .
RUN pip install - - no- cache- dir - r requirements. txt
COPY . .
CMD [ "uvicorn" , "main:app" , "--host" , "0.0.0.0" , "--port" , "8080" ]
EOF
次のコマンドでイメージをビルドして、Cloud Run にデプロイします。
SERVICE_NAME = 'tobari-chan-a2a-server'
!cd a2a_server & & gcloud builds submit - - tag { REPO} / { SERVICE_NAME}
!gcloud run deploy { SERVICE_NAME} \
- - image { REPO} / { SERVICE_NAME} \
- - platform managed \
- - region { LOCATION} \
- - update- env- vars "SERVICE_URL=https://{SERVICE_NAME}-{PROJECT_NUMBER}.{LOCATION}.run.app" \
- - no- allow- unauthenticated 2 > & 1 | cat
[出力結果]
Creating temporary archive of 4 file(s) totalling 7.8 KiB before compression.
...(中略)...
Service URL: https://tobari-chan-a2a-server-879055303739.us-central1.run.app
最後に表示されるサービス URL を確認しておいてください。この A2A サーバー経由でリモートエージェントを使用するツール関数は、次のように実装できます。[SERVICE_URL] の部分は、確認したサービス URL に置き換えます。ここでは、A2A の SDK が提供する A2A クライアントのモジュールを用いて、A2A サーバーにアクセスしています。
async def tobari_chan_tool_a2a ( query: str ) - > str :
"""
Get an answer to a question regarding 夜の帳 from とばりちゃん
Args:
query: question
Returns:
str: An answer from とばりちゃん
"""
import json
import httpx
from uuid import uuid4
from a2a. client import A2AClient
from a2a. types import MessageSendParams, SendStreamingMessageRequest
import google. auth. transport. requests
import google. oauth2. id_token
A2A_SERVER_URL = '[SERVICE_URL]'
auth_req = google. auth. transport. requests. Request( )
id_token = google. oauth2. id_token. fetch_id_token( auth_req, A2A_SERVER_URL)
headers = {
'Authorization' : f'Bearer { id_token} ' ,
'Content-Type' : 'application/json'
}
payload = {
'message' : {
'role' : 'user' ,
'parts' : [ { 'kind' : 'text' , 'text' : query} ] ,
'messageId' : uuid4( ) . hex ,
} ,
}
request = SendStreamingMessageRequest( params= MessageSendParams( ** payload) )
async with httpx. AsyncClient( headers= headers, timeout= 100 ) as httpx_client:
client = await A2AClient. get_client_from_agent_card_url(
httpx_client, A2A_SERVER_URL
)
stream_response = client. send_message_streaming( request)
result = [ ]
async for chunk in stream_response:
chunk = json. loads( chunk. root. model_dump_json( exclude_none= True ) )
if 'DEBUG' in globals ( ) and DEBUG:
pprint. pp( chunk)
print ( '====' )
if chunk[ 'result' ] [ 'kind' ] == 'artifact-update' :
text_messages = [ ]
for part in chunk[ 'result' ] [ 'artifact' ] [ 'parts' ] :
if 'text' in part:
text_messages. append( part[ 'text' ] )
result. append( '\n' . join( text_messages) )
return '\n' . join( result)
このツール関数を単体で実行すると、次のようになります。
print ( await tobari_chan_tool_a2a( 'コーヒー以外のおすすめはあるの?' ) )
[出力結果]
とばりちゃんが答えるよ!
はい、ございます!夜の帳では、軽食とデザートもご用意しております。
軽食では、ふわふわの「厚切りトーストのたまごサンド」や、喫茶店の定番「昔ながらのナポリタン」が人気です。
また、デザートもございますので、ぜひお試しくださいね。
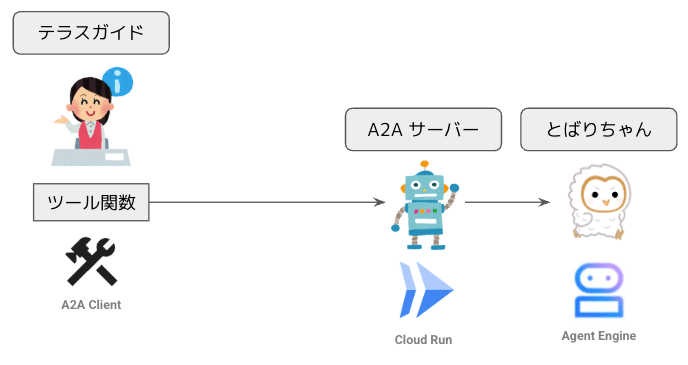
これまでと同様に、こちらのツール関数をルートエージェントに組み込んで利用すれば、上司の期待にバッチリ応えられるでしょう。全体のアーキテクチャーは次のようになります。
A2A サーバー経由で Agent Engine 上のエージェントを使用する構成
!
A2A における情報のやりとり
A2A のプロトコルでは、クライアントとサーバーの間で一定の手順で情報のやりとりが行われます。上記のツール関数 tobari_chan_tool_a2a() では、変数 DEBUG=True をセットすると、A2A サーバーから受け取ったすべての情報が表示されて、次のような結果が得られます。
DEBUG= True
print ( await tobari_chan_tool_a2a( 'こんにちは。' ) )
[出力結果]
{'id': 'e1cbeec9-825e-44de-beaa-1ff4e355c495',
'jsonrpc': '2.0',
'result': {'contextId': 'b6a62e0e-4396-450d-a6f6-b3c01a22f021',
'final': False,
'kind': 'status-update',
'status': {'state': 'submitted'},
'taskId': '875e73bf-9ba7-4245-873b-2ba2db2ccb38'}}
====
{'id': 'e1cbeec9-825e-44de-beaa-1ff4e355c495',
'jsonrpc': '2.0',
'result': {'contextId': 'b6a62e0e-4396-450d-a6f6-b3c01a22f021',
'final': False,
'kind': 'status-update',
'status': {'state': 'working'},
'taskId': '875e73bf-9ba7-4245-873b-2ba2db2ccb38'}}
====
{'id': 'e1cbeec9-825e-44de-beaa-1ff4e355c495',
'jsonrpc': '2.0',
'result': {'artifact': {'artifactId': '643372ac-0fb2-4bbd-bb52-ae4b613f610d',
'parts': [{'kind': 'text',
'text': 'とばりちゃんが答えるよ!いらっしゃいませ!夜の帳へようこそ。何かお探しですか?\n'}]},
'contextId': 'b6a62e0e-4396-450d-a6f6-b3c01a22f021',
'kind': 'artifact-update',
'taskId': '875e73bf-9ba7-4245-873b-2ba2db2ccb38'}}
====
{'id': 'e1cbeec9-825e-44de-beaa-1ff4e355c495',
'jsonrpc': '2.0',
'result': {'contextId': 'b6a62e0e-4396-450d-a6f6-b3c01a22f021',
'final': True,
'kind': 'status-update',
'status': {'state': 'completed'},
'taskId': '875e73bf-9ba7-4245-873b-2ba2db2ccb38'}}
====
とばりちゃんが答えるよ!いらっしゃいませ!夜の帳へようこそ。何かお探しですか?
リモートエージェントが生成する最終成果物(今回の例では、とばりちゃんの回答文)は、「artifact」として送信されますが、そのほかにもタスクのステータスを表すメッセージが「submitted」→「working」→(artifact 送信)→「completed」の順に送られていることがわかります。
このあたりからも理解できるように、A2A では、「エージェント同士が会話をする」というよりは、クライアント側のエージェントがリモートエージェントに作業(タスク)を依頼して、その処理結果(artifact)を受け取る という、まさに Agent as a Tool 的な使い方が想定されています。
また、A2A では、artifact の種類としてテキストメッセージ以外に、バイナリーファイルなども利用できます。ただし、今回の実装例では、テキストメッセージのみを想定した実装になっているので、その点に注意して利用してください。
まとめ
この記事では、Agent Engine にデプロイしたエージェントを他のエージェントからネットワーク経由で利用する方法を紹介しました。本文の冒頭で説明したように、リモート環境のエージェント(リモートエージェント)を使用する際は、該当のエージェントにメッセージを送信して、応答を受けとる関数を用意しておき、これをツール関数として利用するのが基本パターンです。
今回は、Agent Engine にデプロイしたエージェントを利用する前提なので、Vertex AI SDK でリモートエージェントにアクセスするツール関数が作成できましたが、Agent Engine 以外の環境で動くエージェントであれば、当然ながらツール関数の書き方は変わります。つまり、このやり方には、リモートエージェントの実行環境ごとにツール関数の実装方法が変わる という課題があります。
この問題を避けるには、リモートエージェントの前段にプロキシーサーバーを置いて、アクセス方法を統一するという案が考えられます。今回の記事では、FastAPI を用いた一般的なプロキシーサーバーを作る例と、A2A サーバーを利用する例を紹介しました。A2A(Agent2Agent)と言うと、「エージェント同士が自律的に会話する様子」を想像するかもしれませんが、A2A そのものにエージェント間のやりとりを自律的に制御する機能はありません。A2A サーバーの実体は、リモートエージェントの前段にあるプロキシーサーバーであり、エージェント間のメッセージ送受信方法を標準化するための道具 になります。当然ながら、A2A サーバーを構築する際は、A2A サーバーとその背後にあるリモートエージェントとのやり取りは、リモートエージェントの実行環境や動作仕様に応じて、個別に実装する必要があります。
つまり、リモートエージェントを A2A サーバーを介して公開することで、リモートエージェントを利用する側でのツール関数実装の負担を減らすことができますが、これは、リモートエージェントごとに A2A サーバーを設計・構築する負担とのトレードオフになります。 リモートエージェントの実行環境を Agent Engine に統一するのであれば、プロキシーサーバーや A2A サーバーを使わずに、Vertex AI SDK を使ってツール関数を実装することで、システム全体のアーキテクチャーをシンプルに保つという考え方もあるでしょう。A2A の導入を検討する際は、このような A2A の特性を踏まえたシステム設計を心がけるとよいでしょう。