本日、2025年7月17日、パブリッシャーのLimited Run Gamesがアクションゲーム『オレっ!トンバ Special Edition』のダウンロード版を8月1日に配信すると発表しました。対応プラットフォームはPC(Steam)、Nintendo Switch、PS5、PS4で、価格は2980円(税込)です。
ゲーム概要
『オレっ!トンバ Special Edition』は、1997年に初代PlayStation向けにリリースされた『オレっ!トンバ』のリマスター版で、多くの新要素が追加されています。ゲームは横スクロールアクションが基本ながらも、3D空間を感じさせる2.5次元スタイルを採用しています。プレイヤーは主人公の少年トンバを操作し、強力な魔法を使う魔ブタたちが支配する大陸で冒険します。
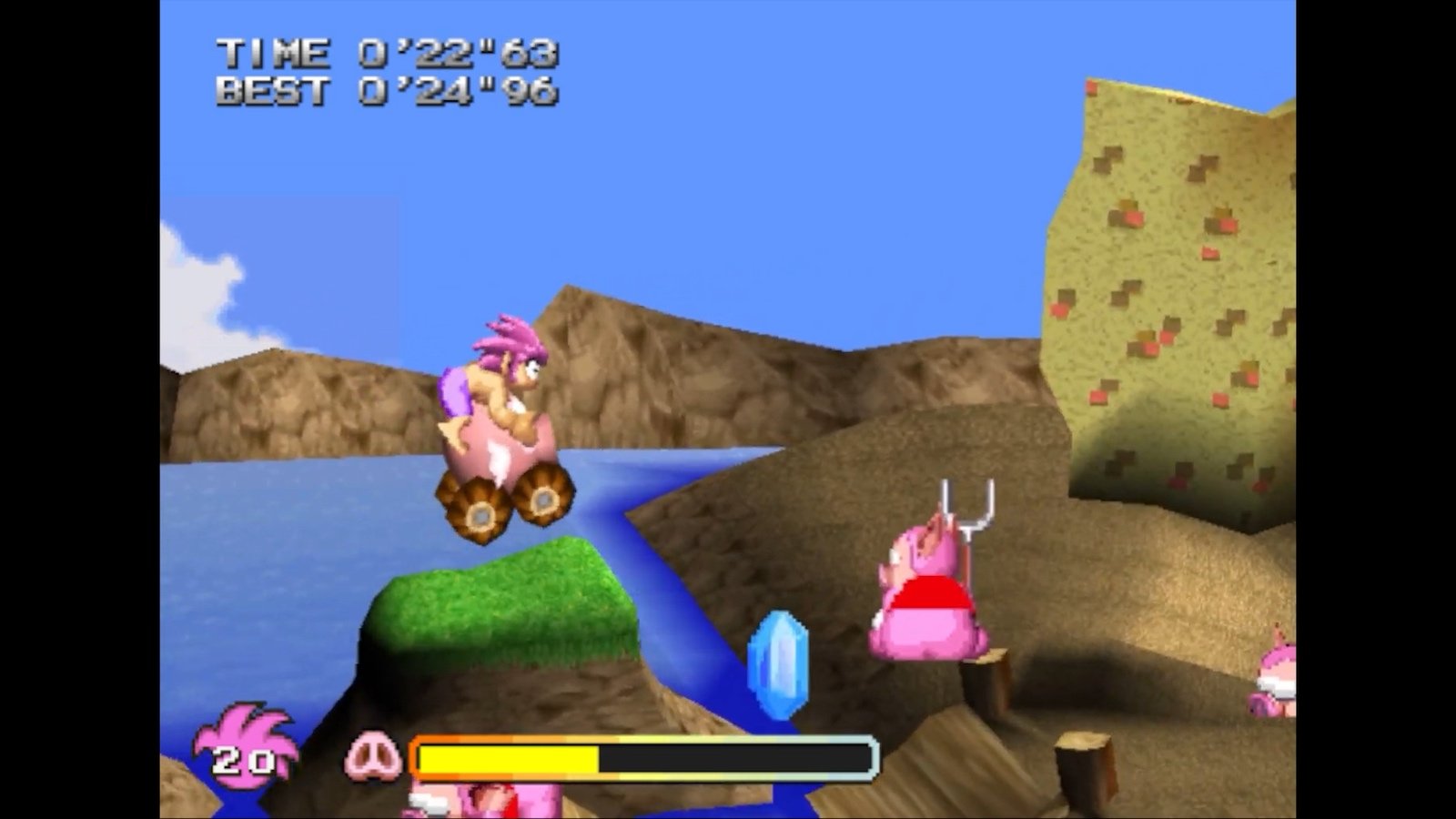
物語の中で、トンバはジィちゃんから受け継いだ腕輪を盗まれ、魔ブタたちを追いかけて多彩なステージをクリアしていきます。プレイヤーはトンバを操作して、奥行きのある世界で様々なお宝を探しながら、個性的なキャラクターたちと共に冒険を楽しむことができます。

追加機能と特典
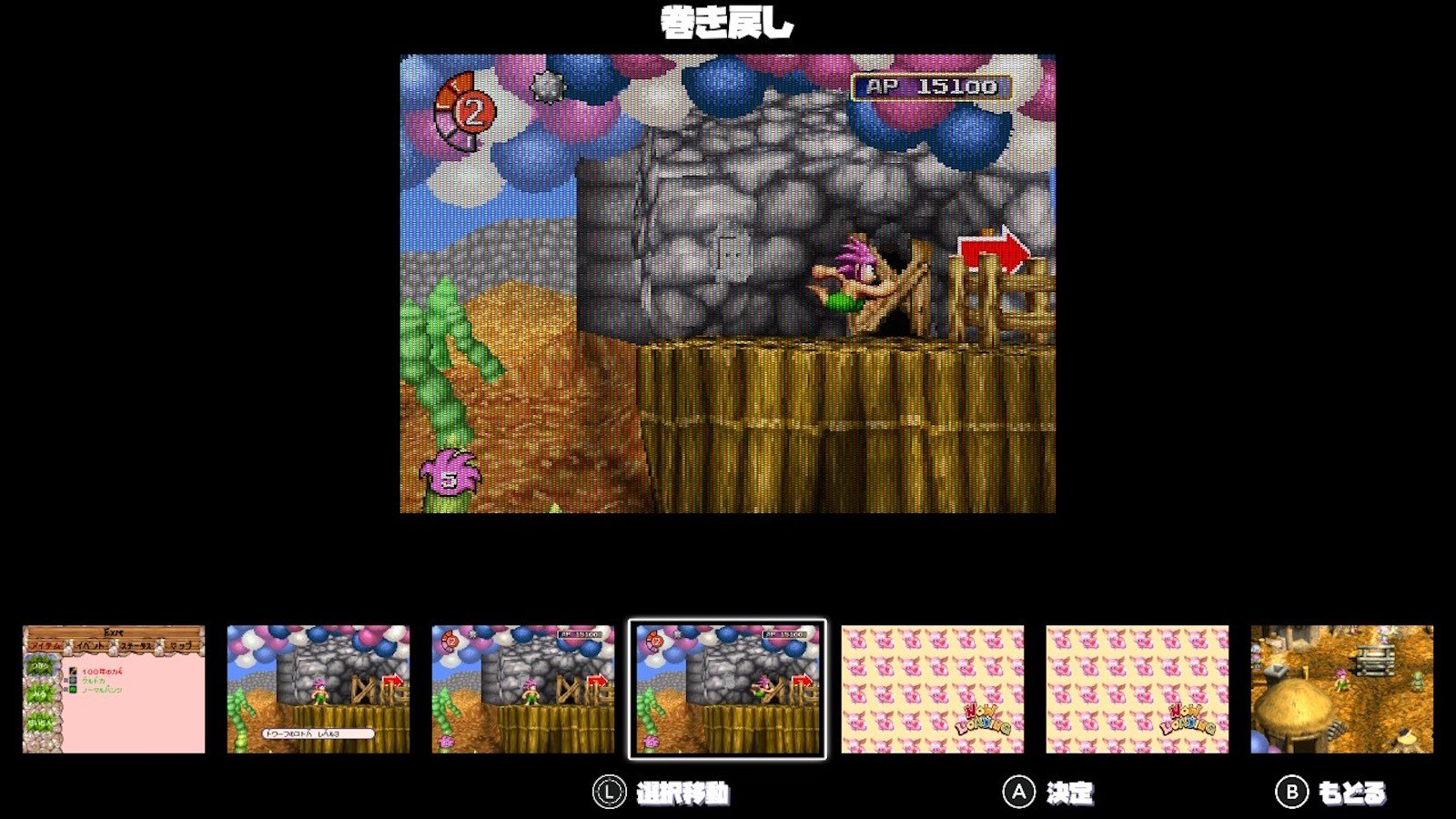
リマスター版には、いつでもセーブできる機能や巻き戻し機能が加わっています。また、「ミュージアム」では、オリジナル版発売当時のPR素材や取扱説明書、さらには開発資料や高解像度のアートワークなども閲覧可能です。
音楽はオリジナル版の作曲に関わった藤田晴美氏が手がけており、リマスター版でも新たに収録されています。また、元カプコンのクリエイターで本作の監督を務めた藤原得郎氏のインタビュー映像も収録され、貴重な裏話が楽しめる内容となっています。
リリース予定
『オレっ!トンバ Special Edition』のダウンロード版は8月1日から配信され、PC版はすでに配信中ですが、日本語版の提供状況については別途リリースが予定されています。また、Nintendo SwitchおよびPS5向けのパッケージ版は9月4日に発売予定です。
詳細は、販売元のSUPERDELUXE GAMESの公式サイトで確認できます。
この新作リマスター版により、懐かしの名作が新たな魅力を持って現れることに期待が高まります。
🧠 編集部より:
補足説明と豆知識
『オレっ!トンバ Special Edition』販売について
パブリッシャーのLimited Run Gamesは、アクションゲーム『オレっ!トンバ Special Edition』のダウンロード版を8月1日に配信することを発表しました。このゲームはPC(Steam)、Nintendo Switch、PS5、PS4に対応しており、価格は2980円(税込)です。
ゲームの背景
『オレっ!トンバ』は、1997年に初代PlayStation向けにウーピーキャンプによって開発され、アニメーションスタイルとユニークなキャラクターで人気を博しました。リマスター版では、オリジナルの魅力を保ちながら新要素も追加されています。それにより、懐かしさだけでなく、現代のプレイヤーにも楽しめる内容となっています。
ゲームの特徴
本作は2.5次元のアクションゲームで、横スクロールアクションとRPG要素が交じり合っています。主人公トンバは、悪名高い魔ブタたちに立ち向かう冒険を繰り広げます。今回のリマスター版には、いつでもセーブできる機能や巻き戻し機能が搭載されており、新たに「ミュージアム」モードも追加され、貴重な開発資料なども楽しむことができます。
音楽とクリエイター
音楽はオリジナル版に関与した藤田晴美氏によって手がけられ、その魅力を引き立てています。また、監督の藤原得郎氏のインタビュー映像も収録されており、開発秘話に触れることができる貴重なコンテンツです。
購入情報
- Steam版: こちらから購入できます。
- パッケージ版: Nintendo Switch/PS5向けのパッケージ版は、9月4日に発売予定です。詳細はSUPERDELUXE GAMESの公式サイトをチェックしてください。
豆知識
『オレっ!トンバ』は、リリース当時からも,非常に独自のビジュアルスタイルやユニークなストーリー展開で高く評価されており、今でも多くのファンがいます。また、日本のゲーム開発業界において多くの影響を与えた作品としても知られています。
発売日が近づく中、再びReturn of Tonbaを楽しみにしている方々も多いでしょう。新たなファンもオリジナル版を振り返りながら、楽しむことができる機会が増えそうです。
-
キーワード: リマスター
オレっ!トンバ Special Edition をAmazonで探す
※以下、出典元
▶ 元記事を読む
Views: 0