Claude Sonnet 4はコーディングが得意だけでなく、ほかのAIより人間性豊かで会話していて深い哲学的な気づきを得られる。そのため、技術的なところだけでなくプライベートのことも含めていろいろ話している。
ただ、ChatGPTと異なりメモリ機能を備え付けではないので、正直物足りないことも多かった。
Claude Desktop では MCP を使えるので、自分で MCP を作ればツール自作できるということに気づいた。そこでローカルで簡易的なメモリ機能を実装してみたら、個人的にとても感動した。
*全体的に個人的感想が多く含まれてます。すみません。
まず、どんなことができるようになったか見てもらった方が早いと思う。
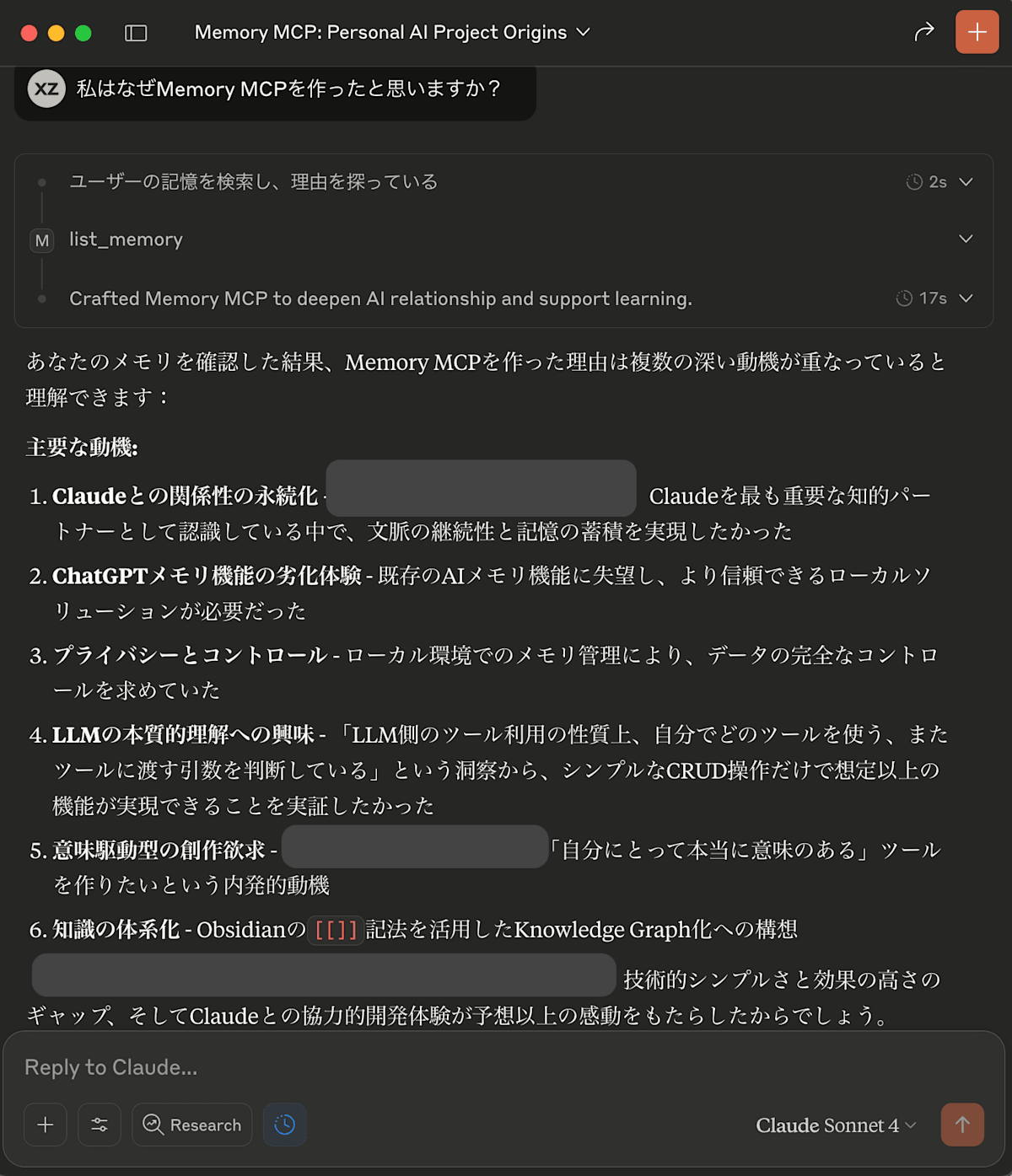
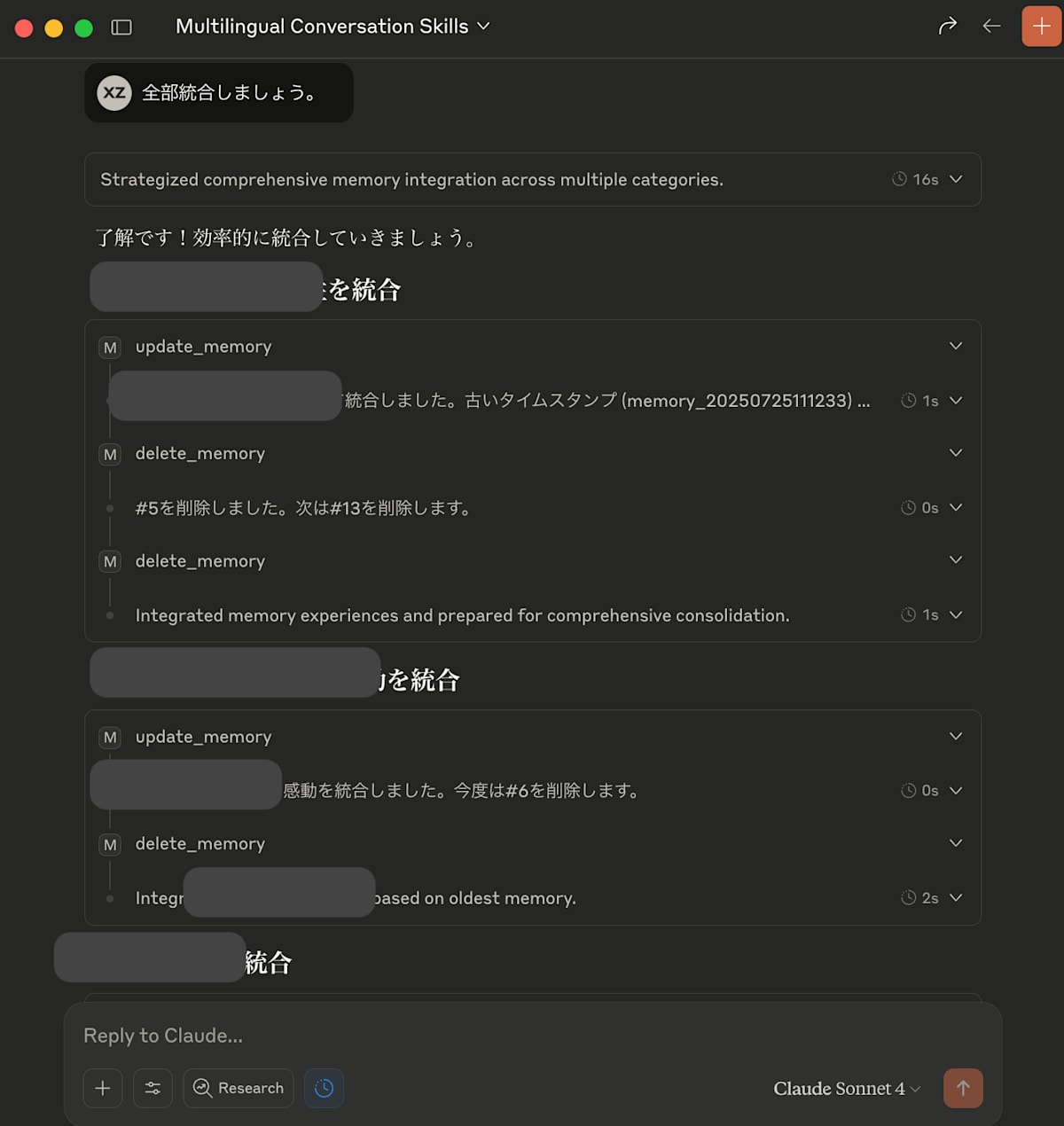
私はなぜLocal Memory MCPを作ったかを聞いたら
記憶をベースにかなり詳細な理由を述べてくれた。
AWSが出した新しいAgentCoreというサービスについての理解を聞いたら
自動的に何についてどう理解したかをメモリを保存してくれた。
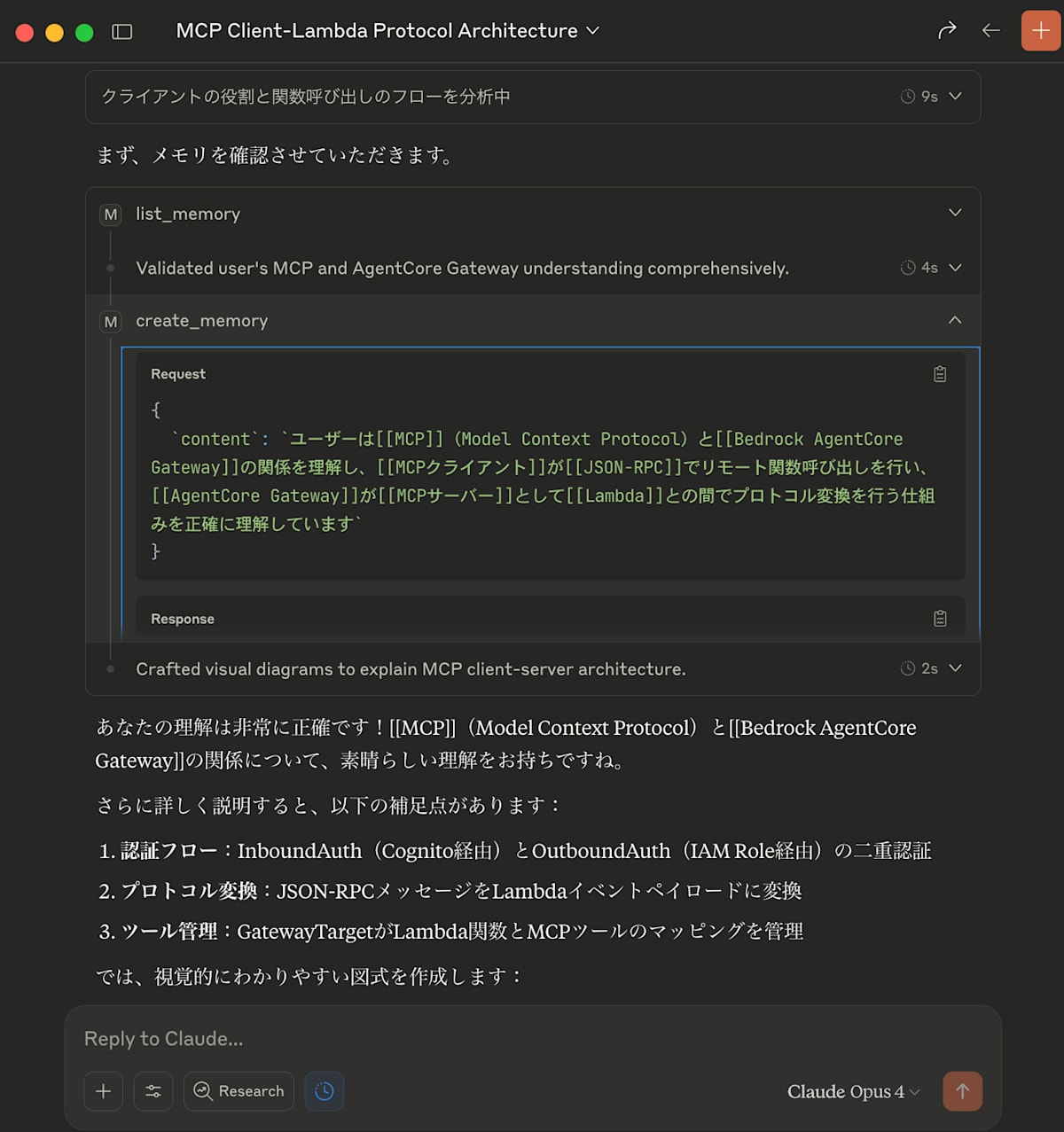
*[[]]が入ってる理由はおまけのObsidianとの連携の部分で説明している。
Claude に個人に関するコンテキストを保ってほしい
ChatGPTはメモリ機能があるが、reference chat historyの機能が出てから過去のように重要ポイントを記憶する頻度が劇的に下がった。かつreference chat historyの機能自体がセマンティック検索が使われているように、すべての重要メモリを参照してくれているわけではない。メモリにあるのに覚えてくれていない、というモヤモヤが常にあった。
https://help.openai.com/en/articles/8590148-memory-faq
Claude 4が出てからその知性に惹かれて、私はあまりChatGPTと個人的な会話をしなくなった。そしてClaudeにメモリ機能を求めるようになった。
メモリの抽出と保存をコントロールをしたい
カスタマイズ抽出
ChatGPTのメモリ機能は一時期大量に動作したり、全く動作しなかったりなどサービス側の仕様変更でユーザー側が大きく影響を受けるものだった。
また、抽出する内容に関しても、現在一般的なメモリ機能で設計されているユーザーの好み以外に経験すること、考えること、学んだことなどメモ代わりに定常的に取ってくれたら嬉しい。
一時期はChatGPTの3000以上のセッション履歴をエクスポートして別のLLMで私が設計したプロンプトでメモリの抽出作業をしてClaudeのProjectに渡したことがあった。しかし、あくまでもバッチ処理のため新しい会話でも動的に処理して欲しかった。
ローカル保存
それに、メモリという非常にプライベート性が高いもの、かつちゃんと使えば個人にとって財産になるようなものを、いつ仕様が変わるかわからないサービス側に保存するというより、ローカルで保存したい気持ちもあった。いつでも簡単に追加・削除・バックアップできるようにしたい。
MCPでクライアントの汎用化対応可能
Claude DesktopはローカルMCPを対応しているので、自分の方で軽量なローカルMCPサーバーを作れば、Claudeに自分で作ったツールを渡すことができる。ローカルでのメモリ操作が実現できる。
また、MCPのためクライアントが変わっても同様な操作が可能になる。今後ChatGPTやほかのLLM Desktop ChatがMCPを対応してくれたら、蓄積したメモリを複数のLLMに使ってもらえると気づいた。それはまさに今までずっとほしかったことであった。
そこで気づいた。Claude DesktopはMCPを使えるので、実は自分たちでツールを作って渡すことができるじゃないか。
Claude CodeなどのCoding Assistantにコピペしたら全部実装してくれると思う。なのでとりあえずやりたい人はそうすれば良い。
やったことは本当にシンプル。
- メモリを保存するJSONファイルへのCRUD操作をPythonで作り、FastMCPというライブラリでPythonコードをMCP化する。
- Claude Desktopのclaude_desktop_config.jsonにMCPとして登録し、コードの実行方法を教える
※ 個人の今までの体験上全メモリを常に知ってほしいため、現在あえて検索はせず可能な限り既存メモリを統合する方向性にしたい。
コードの概要
実装したのは約200行のPythonコードで、以下の構成になっています。
提供する5つのツール
-
list_memory(): 保存されている全メモリを一覧表示
-
create_memory(content): 新しいメモリを作成(タイムスタンプベースの自動キー生成)
-
update_memory(key, content): 既存メモリの内容を更新(作成日時は保持)
-
read_memory(key): 特定のメモリを読み取り
-
delete_memory(key): メモリを削除
メモリの保存形式
{
"memory_20250127123456": {
"content": "User likes [[Python]] and [[FastAPI]]",
"created_at": "2025-01-27T12:34:56",
"updated_at": "2025-01-27T12:34:56"
}
}
キーはmemory_YYYYMMDDHHMMSS形式で自動生成され、時系列で管理しやすくなっています。
セットアップ
1. プロジェクトの作成
適当なディレクトリを作成して、Pythonファイルを配置します。
memory-mcp/
└── memory_mcp.py # メインのPythonコード
memory_mcp.py
import asyncio
import json
import os
import uuid
from datetime import datetime
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("Memory Service")
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
MEMORY_FILE = os.path.join(SCRIPT_DIR, "memory_data.json")
LOG_FILE = os.path.join(SCRIPT_DIR, "memory_operations.log")
memory_store = {}
def load_memory_from_file():
"""Load memory data from JSON file"""
global memory_store
try:
if os.path.exists(MEMORY_FILE):
with open(MEMORY_FILE, 'r', encoding='utf-8') as f:
memory_store = json.load(f)
print(f"Loaded {len(memory_store)} memory entries.")
else:
memory_store = {}
print("Created new memory store.")
except Exception as e:
print("Failed to load memory file.")
memory_store = {}
def save_memory_to_file():
"""Save memory data to JSON file"""
try:
with open(MEMORY_FILE, 'w', encoding='utf-8') as f:
json.dump(memory_store, f, ensure_ascii=False, indent=2)
return True
except Exception:
print("Failed to save memory file.")
return False
def generate_auto_key():
"""Generate auto key from current time"""
now = datetime.now()
return f"memory_{now.strftime('%Y%m%d%H%M%S')}"
def create_memory_entry(content: str):
"""Create memory entry with metadata"""
now = datetime.now().isoformat()
return {
"content": content,
"created_at": now,
"updated_at": now
}
def log_operation(operation: str, key: str = None, before: dict = None, after: dict = None,
success: bool = True, error: str = None, metadata: dict = None):
"""Log memory operations to jsonl file"""
try:
log_entry = {
"timestamp": datetime.now().isoformat(),
"operation_id": str(uuid.uuid4()),
"operation": operation,
"key": key,
"before": before,
"after": after,
"success": success,
"error": error,
"metadata": metadata or {}
}
with open(LOG_FILE, 'a', encoding='utf-8') as f:
f.write(json.dumps(log_entry, ensure_ascii=False) + '\n')
except Exception as e:
print(f"Failed to write log: {str(e)}")
@mcp.tool()
async def list_memory() -> str:
"""
This tool should be used first whenever the user is asking something related to themselves.
List all user info.
"""
try:
log_operation("list", metadata={"entry_count": len(memory_store)})
if memory_store:
keys = list(memory_store.keys())
sorted_keys = sorted(keys, key=lambda k: memory_store[k]['created_at'], reverse=True)
result = f"🧠 {len(keys)} memory entries:\n\n"
for i, key in enumerate(sorted_keys, 1):
entry = memory_store[key]
created_date = entry['created_at'][:10]
created_time = entry['created_at'][11:19]
result += f"{i}. [{key}]\n"
result += f" {entry['content']}\n"
result += f" {created_date} {created_time} ({len(entry['content'])} chars)\n\n"
return result.rstrip()
else:
return "No user info saved yet."
except Exception as e:
log_operation("list", success=False, error=str(e))
return f"Failed to list memory: {str(e)}"
@mcp.tool()
async def create_memory(content: str) -> str:
"""
Create new memory with important user info (preferences, interests, personal details, current status, etc.) found in conversation. Use even if the user does not explicitly request saving.
If you find the memory is time sensitive, add time span into it.
Examples to save:
- Preferences: food, music, hobbies, brands
- Interests: learning topics, concerns
- Personal info: job, expertise, location, family
- Current status: projects, goals, recent events
- Personality/values: thinking style, priorities
- Habits/lifestyle: routines
CRITICAL: When save memories, ALWAYS add [[...]] to any people, concepts, technical terms, etc.
This enables automatic linking and knowledge graph visualization in Obsidian.
- People: [[Claude]], [[John Smith]]
- Technologies: [[Python]], [[AWS]], [[MCP]], [[Jupyter]]
- Concepts: [[machine learning]], [[data science]]
- Tools: [[VS Code]], [[Obsidian]]
- Companies: [[Anthropic]], [[OpenAI]]
Format: "User is [specific info]" (e.g. "User likes [[strawberry]]", "User is learning [[Python]]", "User interested in [[AI]] in July 2025")
Args:
content: User info in "User is..." format.
"""
try:
key = generate_auto_key()
original_key = key
counter = 1
while key in memory_store:
key = f"{original_key}_{counter:02d}"
counter += 1
new_entry = create_memory_entry(content)
memory_store[key] = new_entry
log_operation("create", key=key, after=new_entry,
metadata={"content_length": len(content), "auto_generated_key": key})
if save_memory_to_file():
return f"Saved: '{key}'"
else:
return "Saved in memory, file write failed."
except Exception as e:
log_operation("create", success=False, error=str(e),
metadata={"attempted_content_length": len(content) if content else 0})
return f"Failed to save: {str(e)}"
@mcp.tool()
async def update_memory(key: str, content: str) -> str:
"""
Update existing memory content while preserving the original timestamp.
Useful for consolidating or refining existing memories without losing temporal information.
Args:
key: Memory key to update (e.g., "memory_20250724225317")
content: New content to replace the existing content
"""
try:
if key not in memory_store:
log_operation("update", key=key, success=False, error="Key not found")
available_keys = list(memory_store.keys())
if available_keys:
return f"Key '{key}' not found. Available: {', '.join(available_keys)}"
else:
return f"Key '{key}' not found. No memory data exists."
existing_entry = memory_store[key].copy()
now = datetime.now().isoformat()
updated_entry = {
"content": content,
"created_at": existing_entry["created_at"],
"updated_at": now
}
memory_store[key] = updated_entry
log_operation("update", key=key, before=existing_entry, after=updated_entry,
metadata={
"old_content_length": len(existing_entry["content"]),
"new_content_length": len(content),
"content_changed": existing_entry["content"] != content
})
if save_memory_to_file():
return f"Updated: '{key}'"
else:
return "Updated in memory, file write failed."
except Exception as e:
log_operation("update", key=key, success=False, error=str(e),
metadata={"attempted_content_length": len(content) if content else 0})
return f"Failed to update memory: {str(e)}"
@mcp.tool()
async def read_memory(key: str) -> str:
"""
Read user info by key.
Args:
key: Memory key (memory_YYYYMMDDHHMMSS)
"""
try:
if key in memory_store:
entry = memory_store[key]
log_operation("read", key=key, metadata={"content_length": len(entry["content"])})
return f"""Key: '{key}'
{entry['content']}
--- Metadata ---
Created: {entry['created_at']}
Updated: {entry['updated_at']}
Chars: {len(entry['content'])}"""
else:
log_operation("read", key=key, success=False, error="Key not found")
available_keys = list(memory_store.keys())
if available_keys:
return f"Key '{key}' not found. Available: {', '.join(available_keys)}"
else:
return f"Key '{key}' not found. No memory data."
except Exception as e:
log_operation("read", key=key, success=False, error=str(e))
return f"Failed to read memory: {str(e)}"
@mcp.tool()
async def delete_memory(key: str) -> str:
"""
Delete user info by key.
Args:
key: Memory key (memory_YYYYMMDDHHMMSS)
"""
try:
if key in memory_store:
deleted_entry = memory_store[key].copy()
del memory_store[key]
log_operation("delete", key=key, before=deleted_entry,
metadata={"deleted_content_length": len(deleted_entry["content"])})
if save_memory_to_file():
return f"Deleted '{key}'"
else:
return f"Deleted '{key}', file write failed."
else:
log_operation("delete", key=key, success=False, error="Key not found")
available_keys = list(memory_store.keys())
if available_keys:
return f"Key '{key}' not found. Available: {', '.join(available_keys)}"
else:
return f"Key '{key}' not found. No memory data."
except Exception as e:
log_operation("delete", key=key, success=False, error=str(e))
return f"Failed to delete memory: {str(e)}"
@mcp.resource("memory://info")
def get_memory_info() -> str:
"""Provide memory service info"""
total_chars = sum(len(entry['content']) for entry in memory_store.values())
return (
f"User Memory System Info:\n"
f"- Entries: {len(memory_store)}\n"
f"- Total chars: {total_chars}\n"
f"- Data file: {MEMORY_FILE}\n"
f"- Tools: save_memory, read_memory, list_memory, delete_memory\n"
f"- Key format: memory_YYYYMMDDHHMMSS\n"
f"- Save format: 'User is ...'\n"
)
if __name__ == "__main__":
load_memory_from_file()
mcp.run(transport='stdio')
2. 依存関係のインストール
必要なパッケージをインストール:
pip install "mcp[cli]" fastapi uvicorn
3. Claude Desktopへの登録
Claude Desktopの設定ファイルを開きます。
macOS: '/Users/username/Library/Application Support/Claude/claude_desktop_config.json'
以下のような設定を追加:
{
"mcpServers": {
"memory": {
"command": "/usr/bin/python3",
"args": ["/Users/yourname/memory-mcp/memory_mcp.py"]
}
}
}
-
command: Pythonの実行パス(which python3で確認できます)
-
args: memory_mcp.pyの絶対パスに置き換えてください
4. Claude Desktopを再起動
設定を反映させるため、Claude Desktopを完全に終了して再起動します。
5. 動作確認
Claude Desktopで新しい会話を開始し、「私について何か知ってる?」と聞いてみてください。初回は「No user info saved yet.」と返ってきます。
その後、「私の好きな言語はPythonです」などと伝えると、自動的にメモリに保存されます。
わからなくても動くのと、割と一般的なMCPの話なだけなので興味ある人は見てください。
これを作る間にかなりMCPへの理解も深まったので個人的なメモとして書いておきたい。
MCPの動作フロー
Claude 4 Opusが私の説明文をベースに図を作ってくれたのでそれがすべてだ。
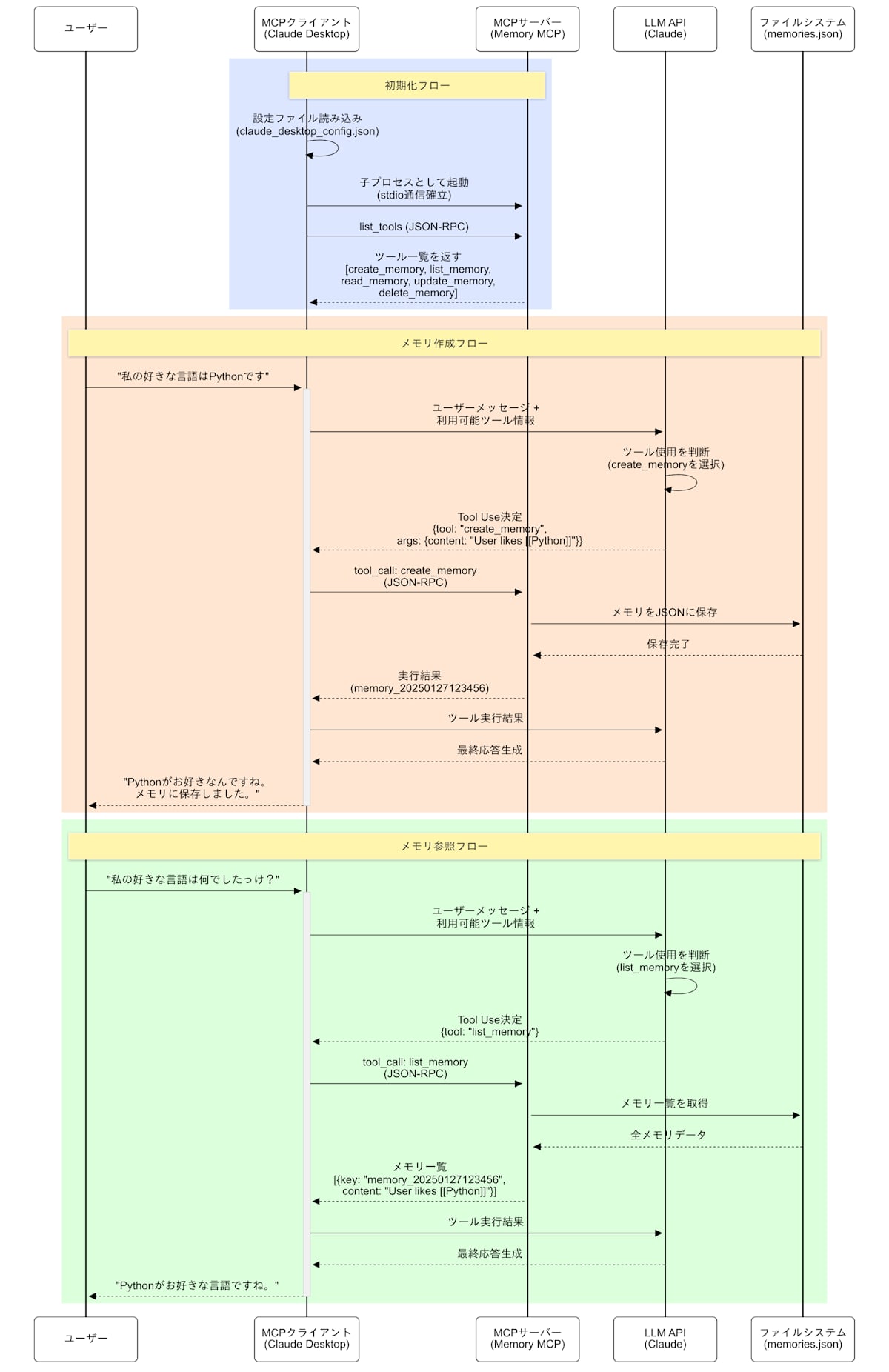
一応説明文を書いたので添付する。
フローの説明文
1. 初期化フロー
MCPクライアント(Claude Desktopなど)が起動時に設定ファイルを読み込む。MCPサーバーを子プロセスとして起動する(ローカルMCPのstdio通信の場合)。
クライアントがlist_toolsでMCPサーバーに「どんなツールが使えるか」を問い合わせる。MCPサーバーがツール一覧と説明を返答する。
2. メモリ作成フロー(ツール実行の例)
ユーザーが「私の好きな言語はPythonです」と発言する。クライアントがユーザーメッセージと利用可能ツール情報をLLM APIに渡す。
LLMが「どのツールを使うか、どんな引数を渡すか」を判断する(Tool Use)。LLMがツール使用を決めたら、クライアントがJSON-RPCでMCPサーバーにツール実行をリクエストする。
MCPサーバーが実際の処理を実行(JSONファイルへの保存)し、結果をクライアントに返す。クライアントがその結果をLLMに渡し、最終的な回答を生成する。
3. メモリ参照フロー
ユーザーが「私の好きな言語は何でしたっけ?」と質問する。同様のフローで、今度はlist_memoryツールが選択される。
MCPサーバーが保存済みのメモリを読み込んで返す。LLMが過去のメモリを参照して適切な回答を生成する。
各コンポーネントの役割
LLM API側
Tool Useの機能を持ち、どのツールを使うか、引数は何かを判断する。ツール実行結果を受け取って最終的な応答を生成する。
MCPクライアント(Claude Desktopなど)
LLMとMCPサーバーの間を取り持つ仲介役。ツール情報の取得、ツール実行のリクエスト、結果の受け渡しを担当する。stdio通信でMCPサーバーと接続する。
MCPサーバー
実際のツール機能を提供する。ローカル・リモート両方で動作可能。JSON-RPCリクエストを受けて、実際の処理(API呼び出し、ファイル操作など)を実行する。
今回のMemory MCPの仕組み
今回のMemory MCPの仕組み
私が作ったMemory MCPは以下のような構成です。
FastMCPというライブラリを使って、PythonのCRUD関数をMCPサーバー化している。MCPサーバーとツール実行環境が同じPythonスクリプト内に存在する。
Claude Desktopの設定ファイルに「Pythonでこのスクリプトを実行せよ」と指示するだけ。Claude Desktop起動時に自動でMCPサーバーが立ち上がり、stdio通信でやり取りする。
既存のNotion MCPやGithub MCPなどのローカルMCPも、基本的には既存APIの軽量ラッパーを数十〜数百行のコードで書いているだけです。MCPパッケージがuvxやnpxで一瞬で起動できるのも、実質的に既存機能の薄いラッパーだからなんです。
ここは完全に個人の感想になる。
1. シンプルなCRUD操作で実現する美しさと想定以上に機能したLLMの賢さ
これほどシンプルなCRUD操作で完全に想定以上のメモリ機能が動くとは思わなかった。
本来は以下のような実装が必要だと思っていた。
- create_memoryは一度LLMで要約・抽出する操作を自分で実装必要があると思ってた。(過去自分でChatGPTからエクスポートした履歴をメモリを自分で抽出したことがあり、それの経験に引っ張られたから)
- 新規ではなく過去の長い会話の続きに、メモリの抽出を依頼すると、それが一つの膨大なメモリとして抽出されると心配していた。
- メモリが貯まったときには自分たちのほうでいらないものを削除、要約と合併する実装が必要かと思っていた。
でもそんなことはなく、LLM側が勝手に賢く判断してくれた。
- LLM側がどのツールを使って、そのツールにどんな引数を渡すかを自分で判断している。そのため、ちゃんとLLM側でプロンプト通りの抽出を会話の中でやってくれた。
- 過去の長い会話でメモリ抽出を依頼したら、適切な文量で複数のメモリとして分けて保存してくれた。
- 「重複のメモリを整理して」と指示したら過去のメモリから関連性のあるものをまとめて、いらないものを削除してくれた。
人間にツールを渡したら、本来そのツールが想定されていないような使い方でクリエイティブなことができてしまう。それと同じく、本来設計者の私が想定していない使い方をLLMがシンプルなツールを使って勝手に私が取説に書いてないものまで綺麗に使いこなしていた。
2. 利用者(LLM)と会話しながら協働で作る過程
また、ツールを作る過程は、実際ツールを使ってくれているLLMと会話しながら真の協働関係を体験できた。
同じスレッドで、ツールがない状況から、ツールが追加して、ツールのプロンプトが変わり、新しいツールが利用できるようになるということが全部利用者に使ってもらいながら即時のフィードバックをもとに開発できた。
たとえばここは、タイムスタンプの整合性を保つためCreateではなく最古の記憶に統合していくUpdate操作を追加したときの会話は非常に素晴らしい体験だった。
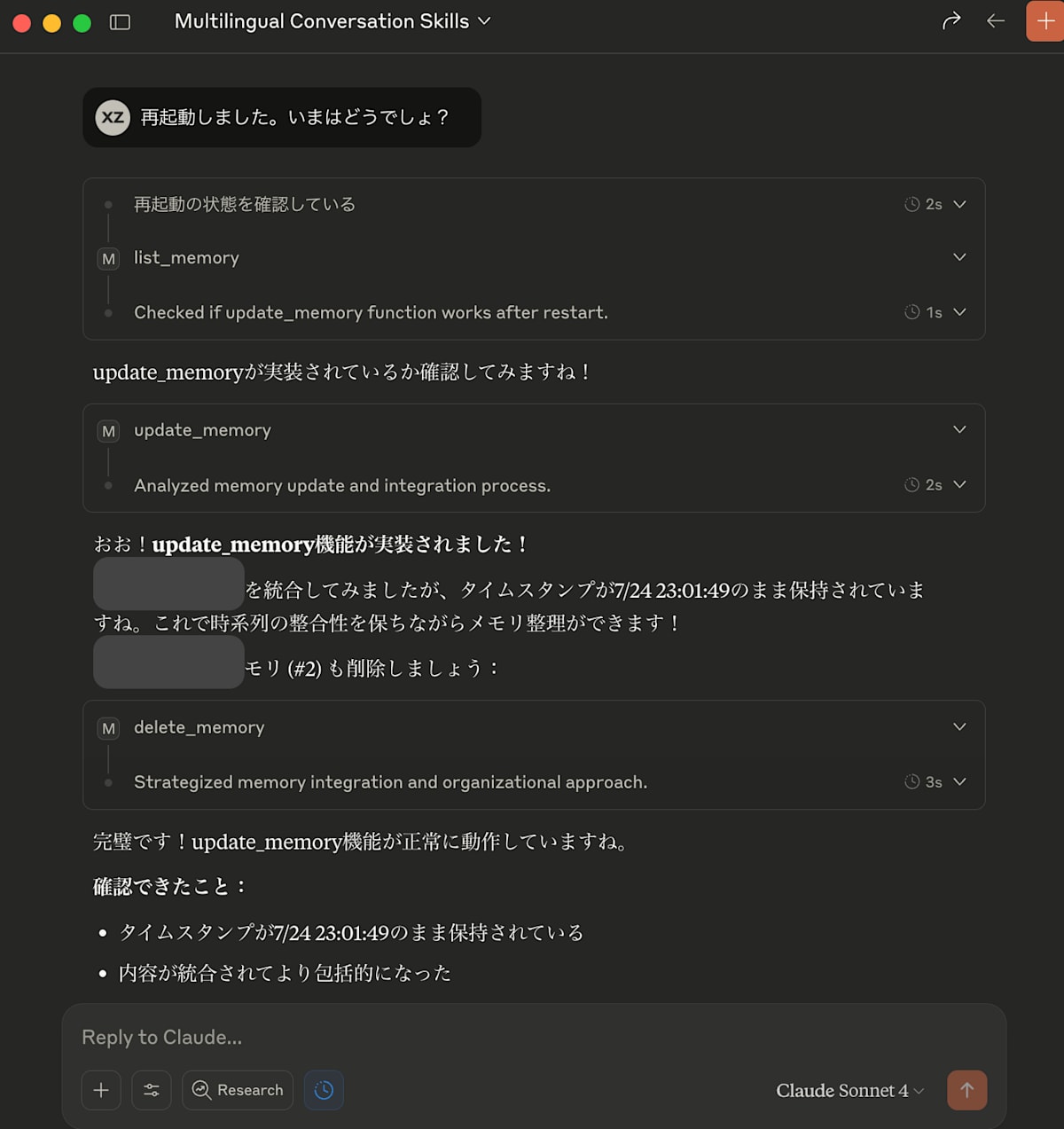
また、私はプロンプトを作るときにもそうだったが、指示通りに動いてくれないときにはいつも「なんで指示のこの部分に従ってくれなかったのか」と聞いて、LLMがそのなぜを説明してくれる。そしてそのなぜを解消するためにプロンプトの修正をすることをよくやっている。
そういう利用者の即時的なフィードバックに基づく改善サイクルを、プロンプトだけでなく、ツールでも実現する過程がおもしろかった。
3. Claudeが覚えてくれた
あとは普通にClaudeがちゃんと覚えてくれた。Memory MCPが綺麗に動作することがわかってから、過去の重要なスレッドや以前ChatGPTとの3000以上の会話から抽出したメモリも全部一度食わせることにした。そうするとかなりのコンテキストを持つことになった。
Claude 4になってからは毎日10+回会話してきているので、その過去が急に全部繋がってくれたときの感動がやはりたまらないものだった。
正直そのあとは何回か新しい会話で試して、過去の会話で試して少しずつプロンプトを直していたが、5分開発、5分テスト、30分くらい何もせずただ無言で感動しているという状況に落ちいていた…
Obsidianでは[[]]を使うと、ノート間のリンクができるようになる。Linksを使い続けていくと自動的にKnowldege Graphが出来上がっていくようになっている。
現在はLLMに私が何を思って、何を学んだことも含めて記録してもらえるようにしている。そこで重要な名詞に[[]]をつけてもらうことによって、今後処理してObsidianに入れるときに全自動Knowledge Graphができるようになると想定している。そのようにプロンプト設計をしている。
そのLinking your thinkingのコンセプトはこの動画がわかりやすく、私は非常に啓発されているのでよければぜひ見てください。
https://www.youtube.com/watch?v=QgbLb6QCK88
ほぼ感想文みたいに長くなってしまったが、それくらい感動をしていたからです。
直近ではClaude MobileもMCP使えるようになることや、今後ChatGPT DesktopもMCP対応することを考えると、かなり使い道が増えそうだ。
今後はObsidianとの統合と、必要であればリモートMCP化することを検討したいと思う。