
1.どんなことをしたのか?
個人の勉強がてら、行政組織のデータを使って、下記のようなサイト(以下、まちきずき)を作ってます。
-
PC
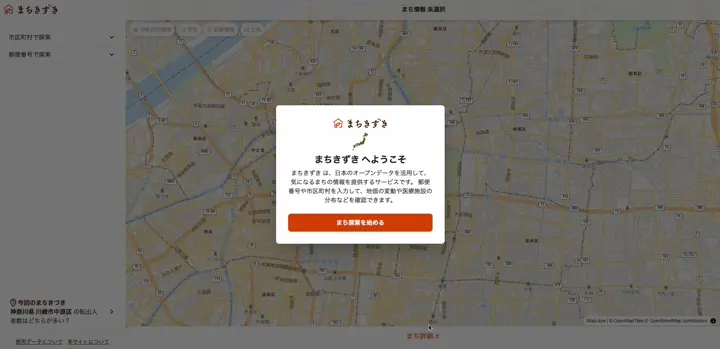
-
モバイル

技術的には、SSG(静的サイトジェネレーター)の Astro を使って、Cloudflare Pages でホスティングしており、DuckDB-Wasm を使ってブラウザ内で Parquet 形式のデータを検索できるようにしています。
ブラウザ内に OPFS でデータを保存しているので、OPFS Explorer の Chrome 拡張を使うと、保存されているデータファイルを確認することもできます。
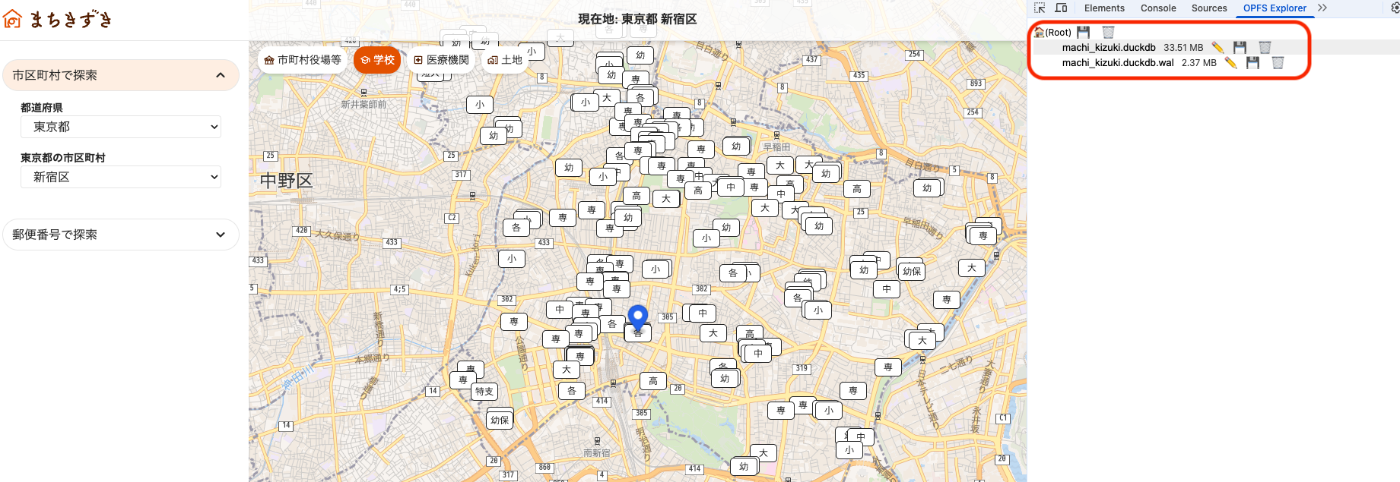
使用データは、ここにも書いているのですが、以下のようなデータを使っています。
2.検証背景&開発動機
voluntas さんの記事を参考に、S3 のログ検索用に DuckDB-Wasm を触る機会があり、「ログ以外でも DuckDB-Wasm を使えるところがあるんじゃないかなあ?」と考えていたところ、「Cloudflare Pages と DuckDB-Wasm を組み合わせれば、オープンデータを使って、サーバーサイドの処理を持たない SSG を用いたサイトを作れるんじゃないかな?」と思いついたのがきっかけです。
個人で開発することもあり、サイトの維持費が無料の範囲内で、あまり固い言葉を使わず、今まで訪れたことのある市区町村やニュースで話題になる市区町村のデータを旅行するような感覚でゆるく眺められるサイトを目指して開発してみました。
なお、政府が運営しているサイトだと、下記のようなサイトがあります。データの正確性や網羅性という観点だと公式のサイトを紹介しておいた方がよさそうなので、紹介がてらリンクを貼っておきます。
3.採用技術
まちきずきで採用している主な技術要素は以下の通りです。
- フロントエンド(静的サイト生成で運用): Astro + SolidJS
- 地図描画: MapLibre GL JS
- 住所検索: MapTiler
- データベース: DuckDB(ブラウザ内に OPFS で保存)
- データベース操作: DuckDB-Wasm
- ホスティング: Cloudflare Pages
- 圧縮データ形式: Parquet, FlatGeobuf
これらの技術を以下のような流れで組み合わせて、サイトを公開しています。
- 外部サービス
- データ整形(Build)処理
- CI/CD
- フロントエンド(Astro + SolidJS)
上記のような技術要素で開発を行う際、技術的な制約や課題感は、最低限下記のような内容がありそうということを認識したうえで開発に着手しました。
Cloudflare Pages の制限
- ファイル数の上限が 20,000
- 1 ファイルのファイルサイズが 25MiB まで
DuckDB-Wasm の制限
- DuckDB-Wasm の使用メモリサイズは 4GB まで
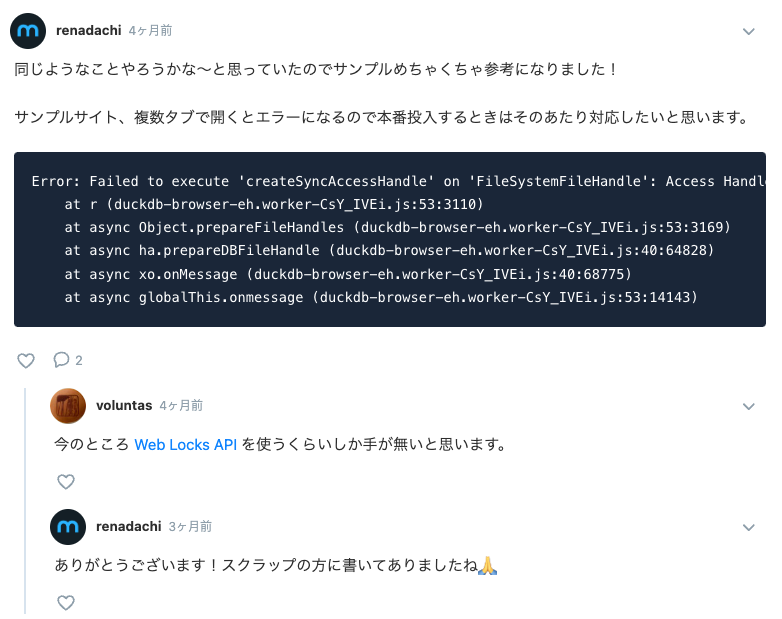
- 複数タブによる同時アクセスは、タブの切り替えに対応するなら何かしらの排他制御が必要(現時点では、まちきずきも複数タブでの操作は対応していないです)
OPFS (Origin Private File System)の制限
- OPFS は、DevTools ではまだサポートされていないので、 OPFS Explorer の Chrome 拡張を利用する必要がある。
- OPFS Explorer からダウンロードできる機能もあるので、センシティブなデータは OPFS に保存してはいけない
行政組織が提供している SHP (Shape ファイル)形式の課題
よりオープンな国土数値情報となるための提案(pdf)
- SHP 形式は、複数ファイルに分割されていたり、容量制限がある
- 行政組織が提供している SHP 形式の利用は課題が大きく、Web サービスで取り扱うなら下記のような GeoJSON 形式を利用する方がよさそう
{
"type": "FeatureCollection",
"name": "P05-22_13",
"crs": { "type": "name", "properties": { "name": "urn:ogc:def:crs:EPSG::6668" } },
"features": [
(snip)
{
"type": "Feature",
"properties": {
"P05_001": "13101",
"P05_002": "1",
"P05_003": "千代田区役所",
"P05_004": "千代田区九段南1-2-1"
},
"geometry": {
"type": "Point",
"coordinates": [
139.753637732192686,
35.694002940266962
]
}
},
(snip)
]
}
上記のような制限や課題感を踏まえたうえで、まちきずきのサイト開発を行ったときにどのような学びを得られたかを以下にまとめてみます。
4.各フローごとの学び
外部サービスについて
行政組織のデータを利用する際、まずどのようなキーで複数のデータを紐づけるかという点で悩みました。
国土数値情報ダウンロードサイトなどでは、2 桁の都道府県コードと 3 桁の市区町村コードを組み合わせた 5 桁のコードが中心だったのですが、データによっては、6 桁のチェックディジット付きのデータもあり、データの紐づけに悩みました。
また、郵便番号のデータは毎月微妙に更新されていたりするので、定期的にデータを更新する仕組みを作る必要があったり、郵便番号だけでは市区町村を特定できないケースがあったりというのは個人的にはよい学びでした。
医療機関のデータは、開発初期には国土数値情報のダウンロードサイトの GeoJSON を使っていたのですが、厚労省の公表データは、病院の URL が掲載されていたり(※)したので、こちらを使う方が情報サイトらしくなりそうだと思い、こちらのデータを DuckDB で整形して使うことにしました。
※URL にメールアドレスなどが入ってきたり、http 以外の文字列も入ってきたり、大文字になったりするので注意する必要はあります…
GitHub Actions(ビルド&デプロイ)について
前項の通り、行政組織のデータをそのまま使うと、データの紐づけがうまくいかないことがあったり、フォーマットが異なっていたりするので、データを取得してから、Parquet 形式や FlatGeobuf 形式に変換するスクリプトを作成し、GitHub Actions のワークフローで実行するようにしました。
DuckDB でのクエリ実行などは他のブログなどが参考になると思うので割愛しますが、例えば、xlsx ファイルや csv ファイル、他のスクリプトで生成した parquet ファイルのデータを使う際は、下記のような一時テーブルを作成したりしていました。DuckDB を使うことで、read_xlsxやread_csv_autoを使って、複数のデータソースを組み合わせて、SQL でデータを整形できるのは便利だなと感じました。
await conn.run(`
CREATE TABLE tmp_municipalities AS (
WITH all_municipalities AS (
SELECT
A as "団体コード",
B AS "都道府県名",
C AS "市区町村名",
D AS "都道府県名_kana",
E AS "市区町村名_kana"
FROM read_xlsx('自治体団体コードのxlsxファイルパス', sheet="R6.1.1現在の団体", range="A2:E1795", all_varchar=true, header=false)
UNION
SELECT
A as "団体コード",
B AS "都道府県名",
C AS "市区町村名",
D AS "都道府県名_kana",
E AS "市区町村名_kana"
FROM read_xlsx('自治体団体コードのxlsxファイルパス', sheet="R6.1.1政令指定都市", range="A2:E192", all_varchar=true, header=false)
)
SELECT
"団体コード" AS jis_code,
"都道府県名" AS prefecture,
"市区町村名" AS city,
"市区町村名_kana" AS city_kana
FROM
all_municipalities
ORDER BY
jis_code
);
CREATE TABLE tmp_municipalities_area AS (
SELECT
*
FROM
read_csv_auto('自治体面積情報のcsvファイルパス',
header = true,
all_varchar = true
)
);
`);
また、GeoJSON 形式のデータを Parquet 形式に変換する際にも、spatial の拡張機能をインストールしておけば、ST_Read で GeoJSON のファイルを読み込んで、緯度経度情報を抽出できたりします。
await conn.run(`
INSTALL spatial;
LOAD spatial;
SELECT
P05_001 AS jis_code,
P05_002 AS municipal_facility_code,
P05_003 AS municipal_facility_name,
P05_004 AS municipal_facility_address,
ST_X(geom) AS longitude,
ST_Y(geom) AS latitude
FROM
ST_Read('${geojsonFiles[0]}');
`);
ただ、DuckDB-Wasm のビルド時の注意点として、DuckDB-Wasm のバイナリファイルが 1 ファイルあたり 30MB を超えてくるため、バイナリファイルをビルド成果物に同梱させるのはCloudflare Pages の 25MB のファイルサイズ制限に引っかかることがわかりました。
$ ls -lh node_modules/@duckdb/duckdb-wasm/dist |rg wasm
-rw-r--r--@ 1 xxxxx staff 32M Sep 12 01:52 duckdb-coi.wasm
-rw-r--r--@ 1 xxxxx staff 32M Sep 12 01:52 duckdb-eh.wasm
-rw-r--r--@ 1 xxxxx staff 37M Sep 12 01:52 duckdb-mvp.wasm
そのため、DuckDB-Wasm の利用は、公式ドキュメントで案内されている CDN 版を利用することにしました。
ここでの考慮点としては、ConsoleLogger の設定がデフォルトのままだと DuckDB へのクエリが info ログとして出力されてしまうため、
const logger = new duckdb.ConsoleLogger(duckdb.LogLevel.WARNING);
のように、LogLevel を WARNING 以上に設定して、コンソールへの出力を制御したりしています。
フロントエンドの実装について
SSG を使ったサイトということで、まずインフラとして Cloudflare Pages と Astro を選択したのですが、アプリケーションのロジックを担うフレームワークとして、個人的に興味があった SolidJS を選択しました。
SolidJS を使うことで状態管理ライブラリを追加で導入せずに状態管理ができたり、ほぼ React で書いていたときと同じような JSX ライクな記法でコンポーネントを作成できたりするのが便利だなと感じました。
SolidJS の UI コンポーネントライブラリは色々あったのですが、下記のスクラップや、他のSolidJSのUIコンポーネントライブラリのスター数や直近のコミット状況を考慮して、Kobalte を採用しました。
コンポーネントの配置もどうしようと悩んでいたのですが、同僚にFeature-Sliced Design(以下、FSD) というフロントエンドアーキテクチャを教えてもらったところだったので、キャッチアップがてら FSD のルールを参考にコンポーネントの配置を行いました。
ただ、SSG として Astro を使っていることもあり、pages ディレクトリだけは FSD のルールを外して、Astro のルーティングとして利用するようにし、pages 以降の処理を app ディレクトリのコンポーネントで受けて、widgets 以下のコンポーネントに処理を渡すようにしました。
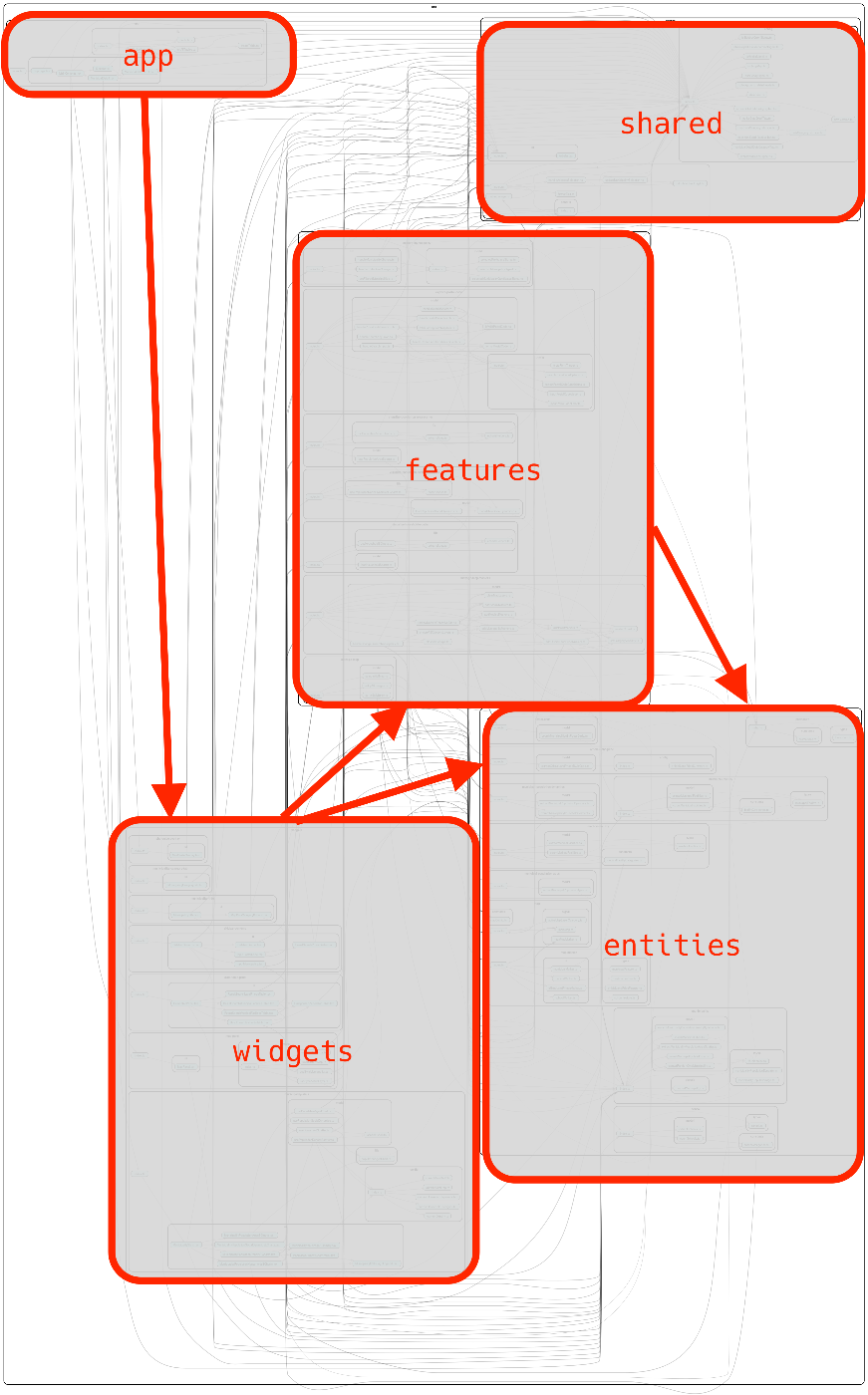
上記のように、開発中のコンポーネントをdependency-cruiserで可視化しながら、FSD のルールに沿っているかを確認しながら開発を行っているのですが、ざっくりと app->widgets->features->entities (shared はどこのレイヤーからも利用される)の順番で依存関係が構築されていることがわかるのではないかと思います。
ちなみに、FSD のリンターもあったりするので、最初からこの構成で始めるともっときれいな依存関係になるのかもしれません。
なお、注意点のところに書いた DuckDB-Wasm の排他制御については、現状対応しておらず、複数タブで開くと下記のエラーが発生しており、複数タブについての対応はまだ行っていません。今のところ、個人と家族で会話するときのネタぐらいしか使っていないので、あまり問題にはなっていないのですが、業務利用するのであれば対応する必要がありそうです。
Error: Failed to execute ‘createSyncAccessHandle’ on ‘FileSystemFileHandle’: Access Handles cannot be created if there is another open Access Handle or Writable stream associated with the same file
地図描画について
著者は業務でも個人開発でも GIS プログラミングの経験はなかったので、このあたりは色々調べながら実装を行いました。
地図描画ライブラリには、 最初は RESAS でも使われていたり、ブログなどの情報が多く見られる Leaflet を使おうとしたのですが、下記のブログとドキュメントを眺めていて、MapLibre GL JS を使ってみることにしました。
特に、MapLibre GL JS の flyTo メソッドを使うと、地図の移動がアニメーション付きで行えるため、市区町村の移動が旅行しているような感覚が味わえるのが良いなと感じました。
地図のタイル情報については、個人開発ということもあり、業務で使う機会が少なそうな Google Maps 以外の地図情報がどのような情報量になるのかが気になったので、OpenStreetMap のタイル情報を使ってみることにしました。MapLibre GL JS を用いた Map の初期設定については、下記のような感じで行っています。
export const MAP_DEFAULT_CONFIG = {
map_container_id: "map-container",
marker_color: "#2563eb",
map_center: { lat: 34.6873, lng: 135.5259 },
map_zoom: 13,
map_pitch: 0,
map_min_zoom: 4,
map_max_tile_cache_size: 200 * 1024 * 1024,
map_max_tile_cache_zoom_levels: 14,
} as const;
const map = new maplibregl.Map({
container: MAP_DEFAULT_CONFIG.map_container_id,
style: "https://tile.openstreetmap.jp/styles/osm-bright-ja/style.json",
center: [
MAP_DEFAULT_CONFIG.map_center.lng,
MAP_DEFAULT_CONFIG.map_center.lat,
],
zoom: MAP_DEFAULT_CONFIG.map_zoom,
pitch: MAP_DEFAULT_CONFIG.map_pitch,
minZoom: MAP_DEFAULT_CONFIG.map_min_zoom,
maxTileCacheSize: MAP_DEFAULT_CONFIG.map_max_tile_cache_size,
maxTileCacheZoomLevels: MAP_DEFAULT_CONFIG.map_max_tile_cache_zoom_levels,
});
ちなみに、まちきずきの初期状態のマーカーは大阪城にしているのですが、これは特に意味はなく、単に著者が大阪出身&在住だからです。
5.AI コーディングエージェントとの併走について
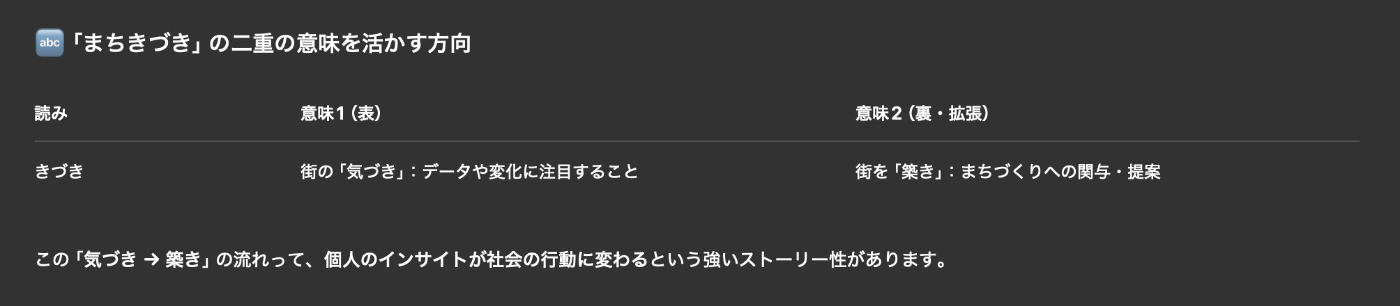
サイト名で、「まちきずき」と名付けたのは、ChatGPT と壁打ちしていく中で偶然出てきたアイディアが由来です。
ChatGPT から、まちの変化に気づいたり、まちを築くきっかけにするみたいな案はどう?というエモいアイディアを提案してきたので、それをサイト名に採用しました。
著者はフロントエンドの知見が乏しかったため、AI エージェントを使って、開発のアドバイスをもらいながら開発を行いました。
使い分けとしては、Codex CLI が出る以前は以下のような感じで使い分けを行っていました。
- GitHub Copilot: コードの行数を特定した補完や、リファクタリング
- Devin: バグ調査や、具体的な修正方法がわかっているときに利用
- Codex: 寝る前や食事前のちょっとした時間に、リファクタリング候補のタスク化を行ってもらう
開発途中、Claude Code を使ってみたいなと思っていた時期もありましたが、個人で複数の AI サービスに課金をするのも難しかったので、結局 GitHub Copilot を中心に、Devin と Codex を併用しながら開発を行いました。
ただ、Devin は最初の方でサンプル実装を行ってくれたり、バグ調査を行ってくれたりしたのですが、結局チャットで追加指示を行うことで、クレジットを消費することが多くなり、費用がかかるので最近はあまり使わなくなりました。今は、個人で課金している ChatGPT Plus のプランを活用した Codex CLI が一番使いやすいと感じており、新規機能の実装やリファクタリングを行う際に利用しています。
なお、ロゴやサイト全体の配色については、AI サービスと何度か壁打ちを行ったのですが、思い描くイメージを明文化できず、結局イメージに合うものができませんでした。
そこで、デザイナーの妻に相談したら、最終的にロゴとサイト全体のイメージ配色を考えてくれたりしたので、本当に妻に感謝です。
6.まとめ
上記のようなまちきずきの開発を通して、AI コーディングエージェントを使ったとしても、自分が身につけている知識以上のことは指示できないので、人間も学び続ける姿勢が重要ということを改めて感じました。特にデザインまわりは全然思ったような指示が出せず、無駄に各種AIコーディングエージェントのクレジットを消費することが多かったと思います。
上記以外にも色々設定を行っていたりするのですが、画面実装における UI/UX の改善点や、可視化してみたいデータの追加など、まだ改善したい点は多いので、大きくは変更しなさそうな部分を中心に、現時点での学びの内容をまとめてみました。
自治体ごとにページを分割していたり、配信する FGB ファイルや Parquet ファイル数を考えても、Cloudflare Pages のファイル数制限にはまだ余裕があるので、もう少しデータを増やしながら、サイトの改善を行っていきたいと思います。
Views: 0

{kind=link}