

DR(ディザスタリカバリ)の略で、日本語だと災害復旧を意味します。
災害発生時にシステムやデータを迅速に復旧・復元し、事業の中断を最小限に抑えるための技術的アプローチのことをDRと言います。
なんとなくふわっとしたイメージは付くと思いますが、そもそもどういった事象を災害と呼ぶのでしょう?![]()
災害というと、自然災害が一般的かなと思っていますが、
AWSでは、次の3つのカテゴリに災害を分類し、復旧計画を検討し、実践することをDRと呼んでいます。
- 1. 地震や洪水などの自然災害
- 2. 停電やネットワーク接続などの技術的な障害
- 3. 不注意による設定ミス、不正な/外部のアクセスや変更などの人為的行動
3.に関して細かくすると以下のようになり、アプリケーションの不具合なども含まれます。
- 人的災害(マルウェア・ランサムウェア感染、テロ、ストライキなど)
- 作業ミスによるデータロスト、全損・一部損
- データの誤削除
- データ間の整合性の不一致
- パフォーマンスの低下
- ビジネスロジックの不具合
- 不正アクセスによるトラブル
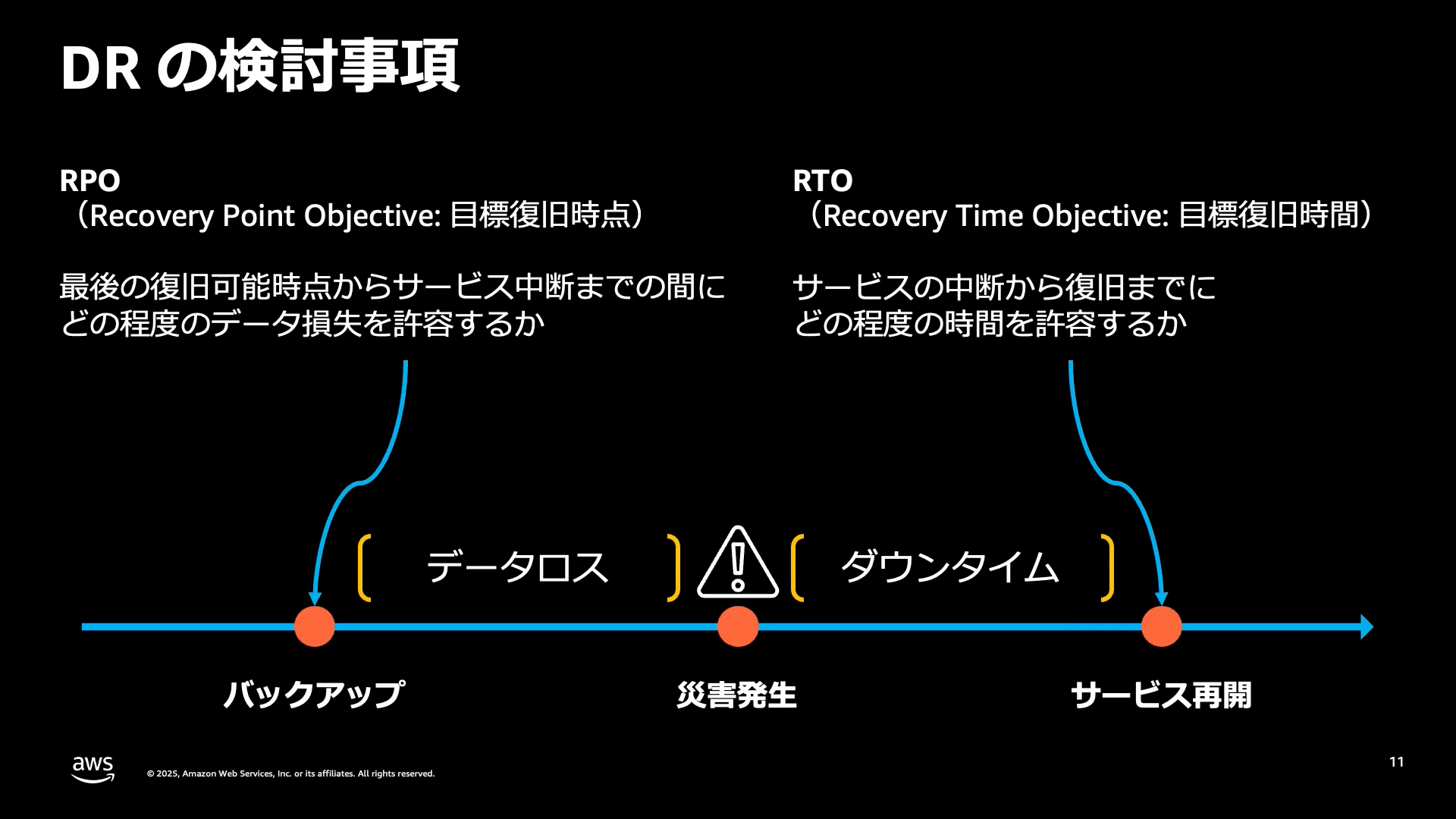
DRを検討する上で、何も指標がないと評価が出来ないかと思います。
以下の3つがDRの指標になります。
-
1. RPO(Recovery Point Objective:目標復旧時点)
- 災害からの復旧時に
どの時点のデータに戻っていればよいかの指標 - 現在からの時間差分が短ければ短いだけデータ損失は少なくなります
- 災害からの復旧時に
-
2. RTO(Recovery Time Objective:目標復旧時間)
- 災害によるサービスダウンから復旧までの
最大許容時間 - 復旧にかかる時間が短ければ短いだけサービス停止によるユーザ影響を減らすことが出来ます
- 災害によるサービスダウンから復旧までの
-
3. RLO(Recovery Level Objective:目標復旧レベル):
-
どの程度まで復旧させるか - 100%は
完全に復旧したことを表します
-
また、それぞれの指標に影響する要素は以下のようになります。
| 要素 | RTO | RPO | RLO |
|---|---|---|---|
| リストアやDR環境へのフェイルオーバー方法 | 〇 | 〇 | |
| 意思決定フロー | 〇 | 〇 | |
| 実装およびランニングコスト | 〇 | 〇 | 〇 |
| バックアップ取得間隔 | 〇 | 〇 | |
| バックアップ取得と転送方法 | 〇 | 〇 | |
| フェイルオーバーの優先度 | 〇 |
フェイルオーバーとは、稼働中のシステムで問題が生じてシステムやサーバーが停止してしまった際に、自動的に待機システムに切り替える仕組みのことを言います
RPO、RTOは短いほうが良いし、RLOは100%であるほうが良い、とは何となくわかりました。
では、どのように指標を決めて、どのように計画を立てて、どのように実施すれば良いのでしょうか?![]()
1. 何に備えるのかを決める
まず、冒頭に記載した通りDRは3つのカテゴリに分類されます。
おそらく、余程リソースが潤沢でない限り時間やコストの面からこれら全てに対応するというのは、現実的ではないはずでしょう。
なので、プロジェクト毎に災害の定義が必要となってきます。
何をもって災害とするかによって対策と費用が変わので、そこがふわっとしたままだとコストの試算も難しくなるためです。
例:自然災害はめったに起こらないはずなので、発生頻度が高そうな「3. 不注意による設定ミス、不正な/外部のアクセスや変更などの人為的行動」に注力しよう、など
ただ、これはあくまで初期段階の定義になるはずです。
アーキテクチャが決まってくるとコスト計算が可能になるはずですが、そのコストがお客様の要望とマッチしない場合、災害の発生確率や頻度とコストを天秤にかけて災害の定義を見直すことが必要になります。
見直しは運用が始まってからも継続的に実施することが理想です(とはいえ、そこにコストをかけるのが現実は難しかったりする)
2. 各指標の目標値を決める
何に備えるのかを決めたところで、次にRTO、RPO、RLOを決めていきます。
これらの目標値は机上で全てを決めるのではなく、構築しテストをしながら少しずつ調整するのが理想です。
なるべく早く・損失がない復旧をしたいからといって、根拠の無い目標値を設定してしまうと後で困ったことになります。
また、目標値を決める上で技術的な部分だけに目が行きがちですが以下のように、復旧には多くの要素が絡んできます。
これらのコストを踏まえて総合的にRTO、RPO、RLOを決めていく必要があります。
- DR発生の検知
- DR発動の意思決定
- 社内・社外への連絡
- 担当者のアサイン
- 技術的な復旧タスクの実施
- 復旧確認
- 社内・社外への連絡
DRと可用性との違い
DRに関連する言葉として、みなさん一度は聞いたことのある可用性があります。
どちらも回復力に関連する指標ではあるのですが、
- DRは、
ワークロード全体に重点を置く - 可用性は、
ワークロードのコンポーネントの障害、ネットワークの問題、ソフトウェアのバグ、負荷の急増など、小規模なスケールの一般的な中断に重点を置く- 例えば、ワークロードの一部分であるS3は可用性が99.99%ですね

- 例えば、ワークロードの一部分であるS3は可用性が99.99%ですね
という違いがあります。
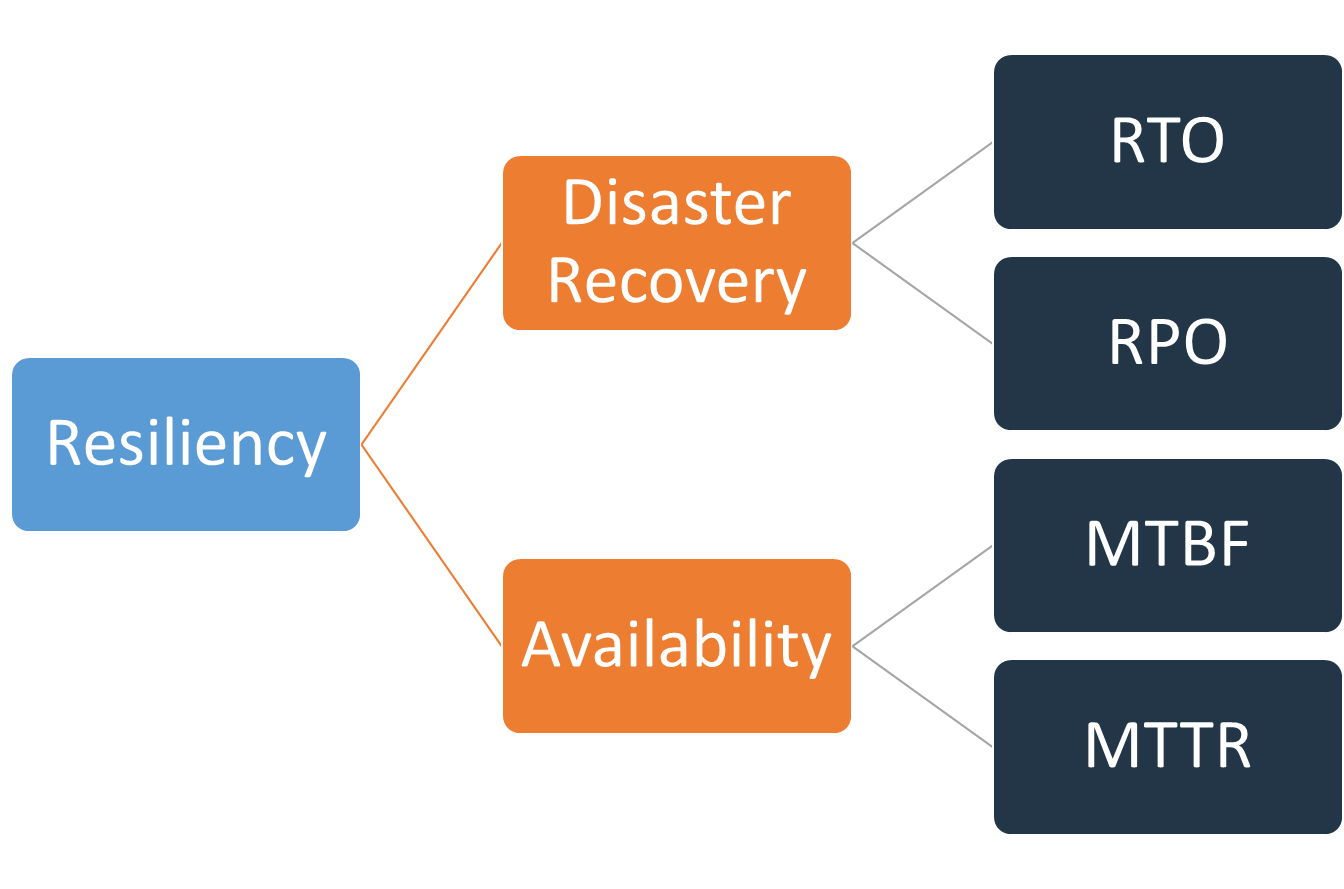
可用性は、平均故障間隔 (MTBF) と平均復旧時間 (MTTR) を使用して計算されます

3. DRのアプローチを選択する
目標値を決めたところで、具体的にどのようにDRを行うか決めていきます。
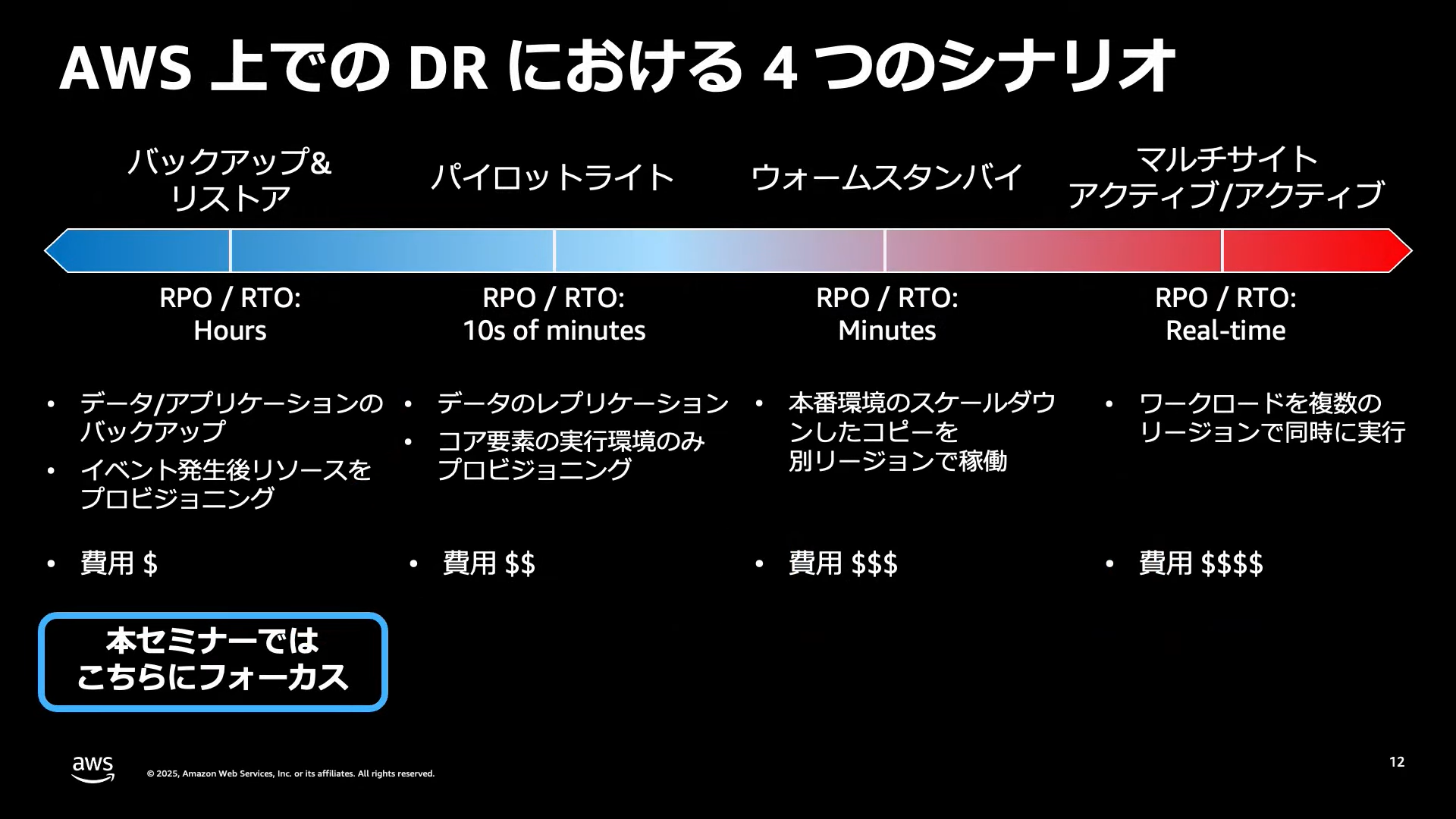
AWSでは、以下の4つのアプローチが紹介されています。
- バックアップ&リストア
- パイロットライト
- ウォームスタンバイ
- マルチサイトアクティブ/アクティブ
バックアップ&リストア
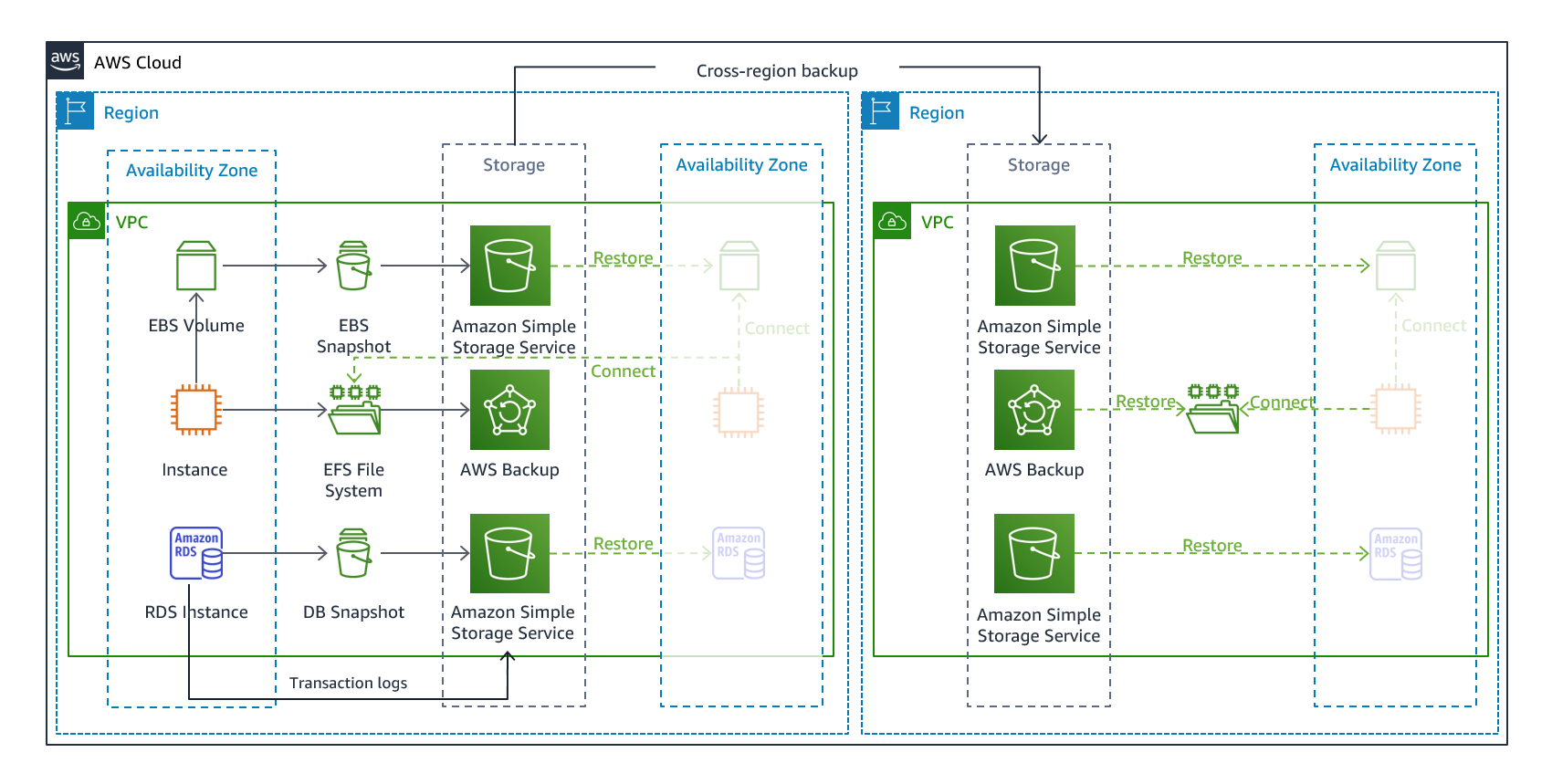
データの損失や破損を軽減するアプローチです。
データをDR先にレプリケートすることでリージョンの災害を軽減したり、単一のアベイラビリティーゾーンにデプロイされたワークロードの冗長性の欠如を軽減したりするために使用できます。
このアプローチでは、データのバックアップを主目的とするため、アプリケーションはDR先リージョンには作りません。
なので、インフラストラクチャ、設定、アプリケーションは別途、DR先リージョンに再デプロイする必要があります。
再デプロイには、CDKなどのIaC(infrastructure as code)を使用することが推奨されます。
手動での復旧だと、ワークロードを復元するのが複雑になり、復旧時間が長くなり、RTOを超える可能性があるためです。
パイロットライト
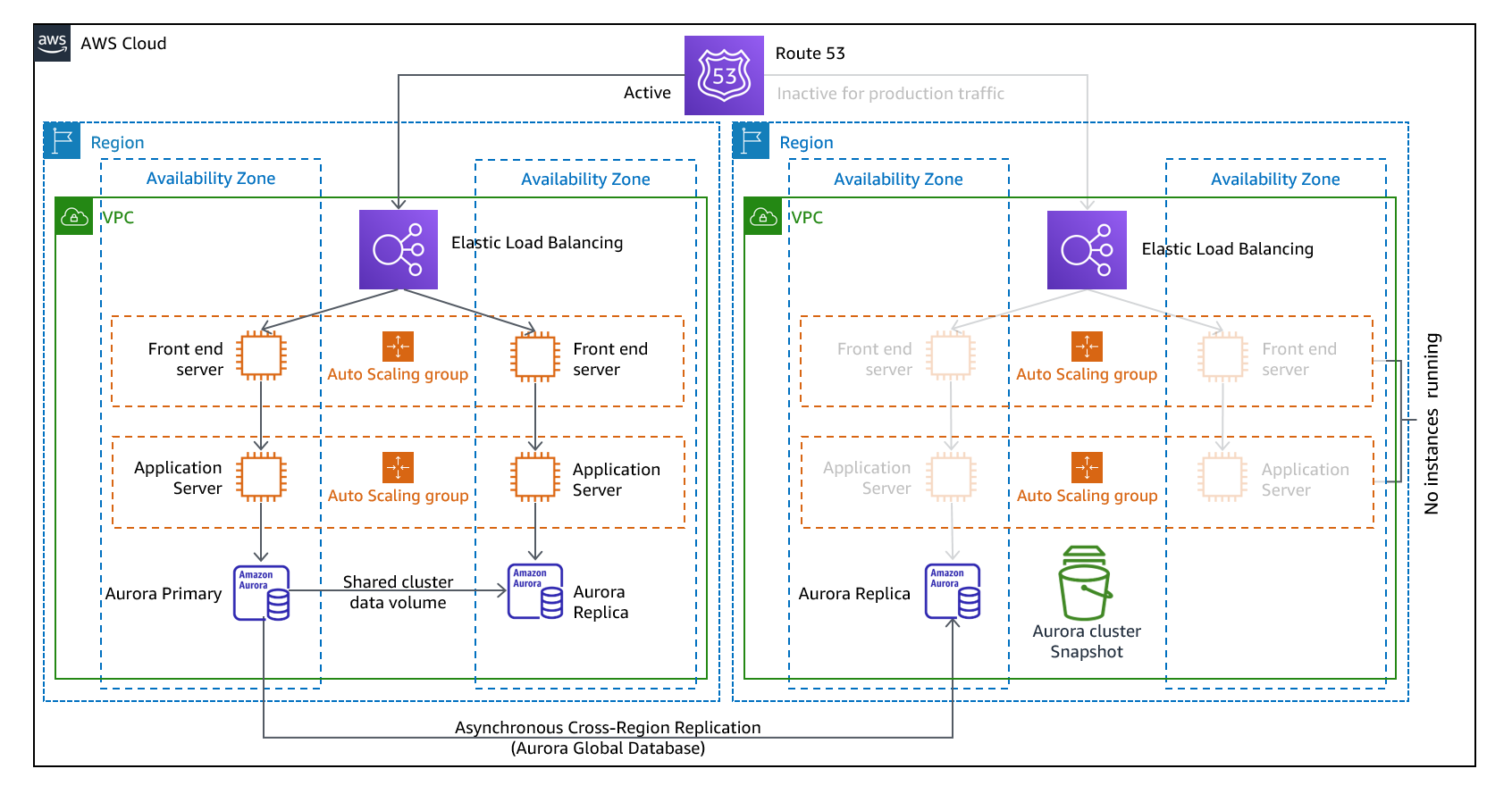
DR先リージョンで、本番稼働環境と同じリソースを構築して停止状態にしておき、DR時に稼働状態にするアプローチです。
ELBなど停止できないリソースは稼働中で構築しておきます。
AWS利用料金は発生しますが、バックアップ&リストアと比較するとRTOが短くなります。
また、データベースは常に稼働させ、プライマリDBと同期させておくことでRTOが更に短くなります。
インフラストラクチャーとアプリケーションの変更を両方のリージョンに同時にデプロイする必要があります。
なので、CI/CDでパイプラインを構築してデプロイを簡素化することが推奨されます。
ウォームスタンバイ
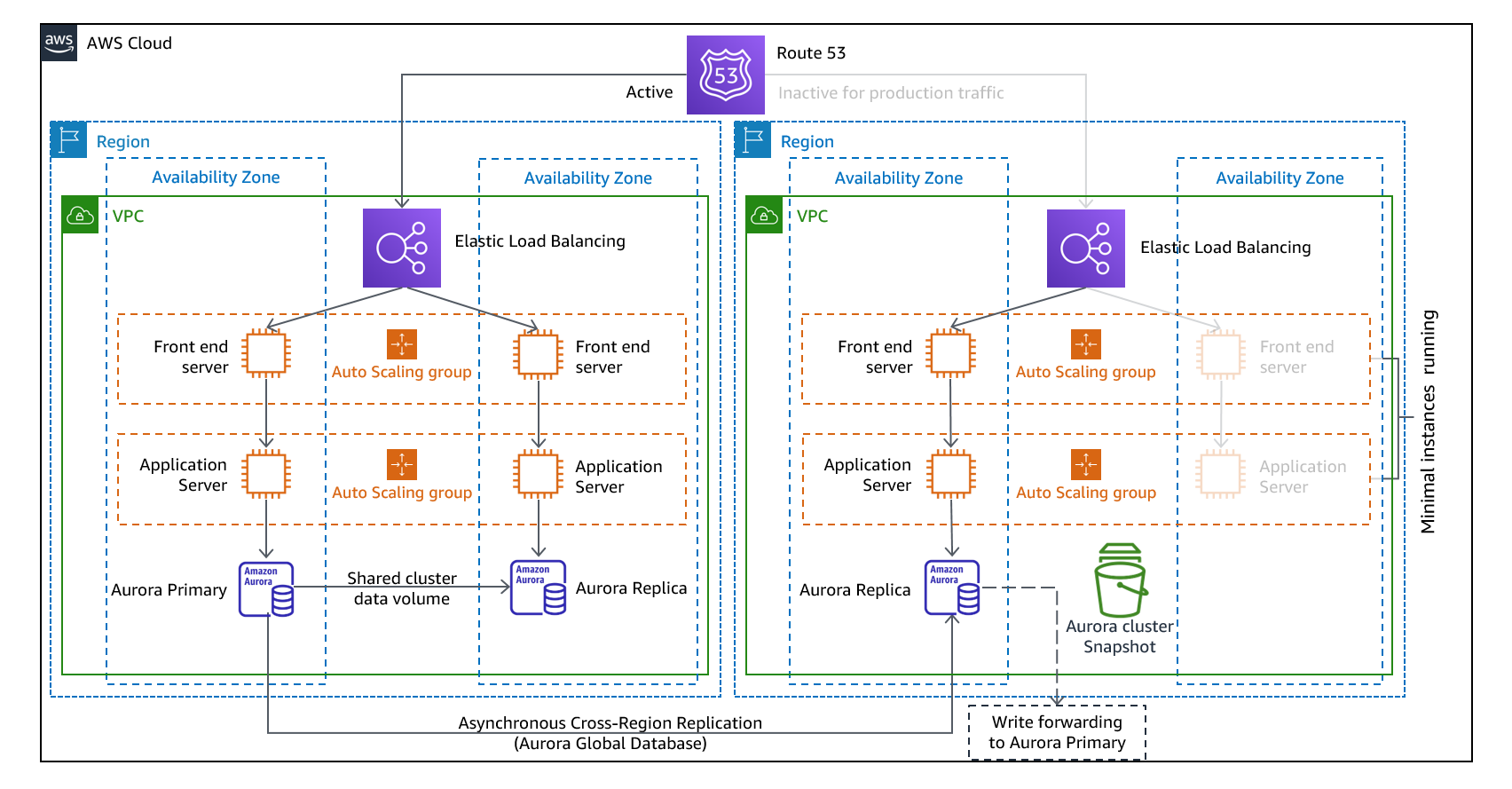
DR先リージョンで、本番稼働環境と同じ構成を縮小した状態で稼働しておくアプローチです。
DR時には、本番環境と同等のスペックや台数に戻して運用します。
DBやファイルなどのデータは継続的にレプリケーションしておきます。
AWSリソースが常に稼働している状態なので、RTOはパイロットライトに比べ短くなりますが、AWS利用料金は高くなります。
パイロットライトでは基本的にリソースを停止しているためテストが難しかったのですが、
ウォームスタンバイではテストを簡単かつ継続的なテストを実施し、災害から回復する能力に対する信頼を高めることができます。
マルチサイトアクティブ/アクティブ
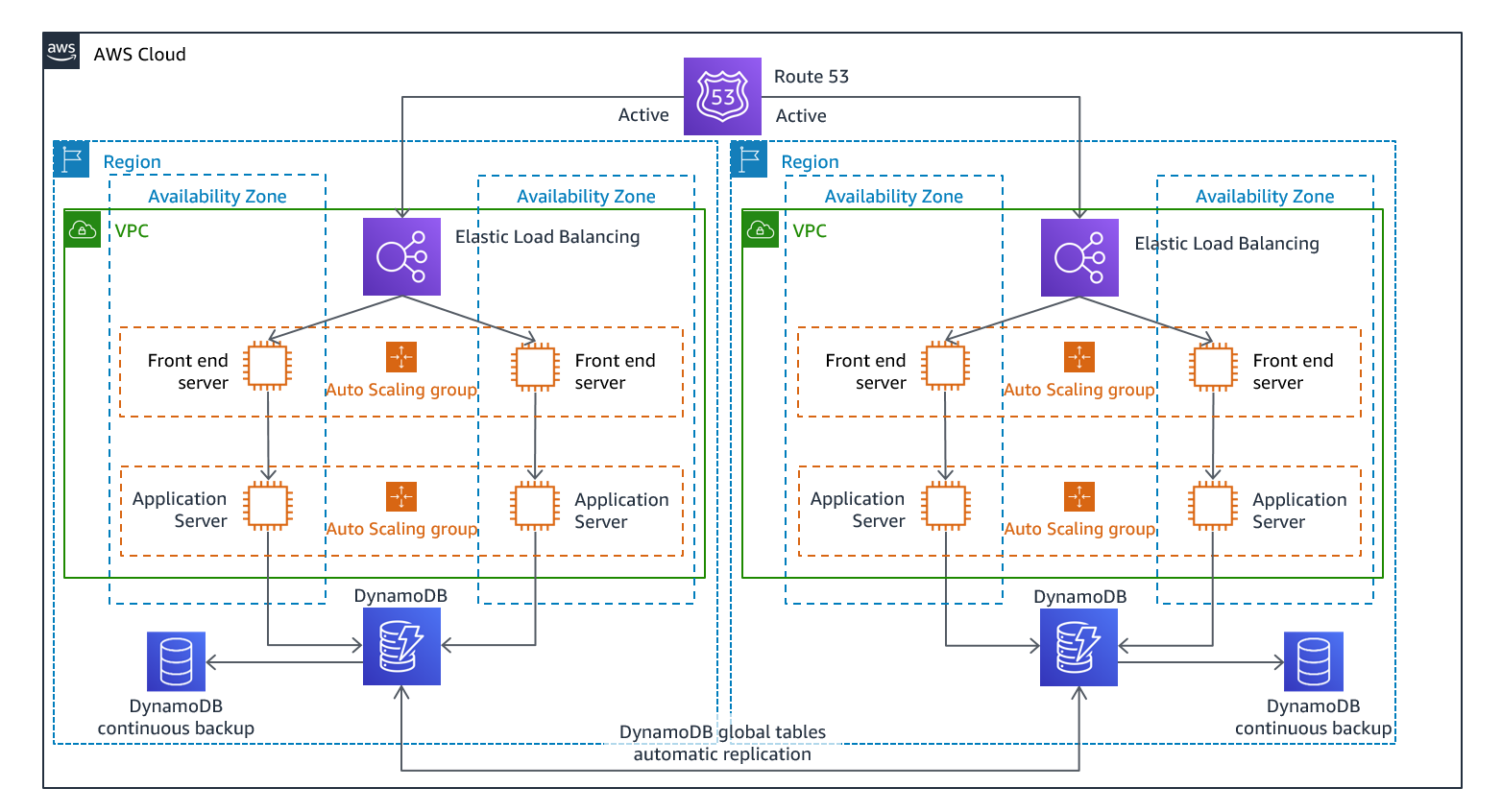
複数のリージョンで同時に本番環境を稼働し、1つのリージョンが仮にダウンしてもサービスへの停止をほぼ0に出来るアプローチです。
複数のAWSリージョンで、ワークロードが稼働するので、RTOは最も短いですが、AWS利用料金は最も高くなります。
アプローチの1つにウォームスタンバイが出てきましたが、ホットスタンバイ、コールドスタンバイという言葉もあるかと思います。
AWSのアプローチでいうと、
- ホットスタンバイがマルチサイトアクティブ/アクティブ
- コールドスタンバイがパイロットライト
と言えます。
4. DRの検出方法とフローを定める
DRのアプローチを決めましたが、DRをどのように検出し、どのようなフローで復旧を行っていくかを決める必要があります。
AWSだとヘルスダッシュボードやEventBridgeなどで検知することになるかと思います。
また、復旧に関してもまずはリージョン内で復旧できるか確認したほうが良いと思います。
単一のAWSサービスに一時的な障害が発生しているだけの可能性もあるため、リージョン内での復旧が不可能だと判断されたらDRを行うほうが良さそうです
フローとしては以下のような流れになるかと思います。※あくまで一例
- システムダウンの自動検知
- 原因の調査
- リージョン内での復旧を実施 ※検知からxx時間はリージョン内での復旧を試みる
- xx時間経過後、復旧の目処が立たないならばDR実施を決定
- 社内・社外関係各所にDR実施の連絡
- DR復旧作業の開始 ※可能な限り自動化する
- DR復旧作業の完了
- ワークロードの動作(手動・自動)確認
- 社内・社外関係各所に DR復旧の連絡
- DR先での運用
- フェイルバック実施と時期の判断
- 社内・社外関係各所にフェイルバックの連絡
- フェイルバック実施
- フェイルバック完了
- ワークロードの動作(手動・自動)確認
- 社内・社外関係各所にフェイルバック完了の連絡
フェイルバックとは、システムに障害が発生し、バックアップシステムに切り替えた後、元のシステム(本番システム)に戻すことを言います
オンプレとクラウドでのDRの違い
オンプレと比べ、AWSなどのクラウドサービスを使っている場合は、DRは比較的導入がしやすいはずです。
5. DRの体制を整える
検出方法とフローを定めたら、実際にDRをどのような体制で行うか決めていきます。
以下のようなステークホルダーが関係してくるかと思います。
- クライアント:サービス提供元
- システム開発ベンダー:ワークロードを開発した会社
- 別ベンダー:同じワークロードを開発した協力会社
- 運用チーム:ワークロードの監視・運用を行う会社
- インフラチーム:インフラ構築を行った会社
そして、DRを行う上では以下の役割が必要になりそうです。
- DR発動責任者
- DR実施責任者
- DR復旧作業チーム
- DR連絡窓口
6. DRを構築する
さて、ここまで色々考えてきましたが、実際にDRが出来るようにインフラの構築などを行っていきます。
アプローチによってどのような実現方法があるかは、別途記事を書きたいと思っているので、今回は詳細な説明を省きます![]()
7. DRをテストする
構築が完了しましたが、これで終わりではありません。
本当に災害が発生した場合に、ちゃんと復旧できるかをテストしないといけません。(本番一発勝負は怖いですよね![]() )
)
テストでは
- ワークロードがDR先リージョンで稼働していること
- ワークロードで稼働しているアプリケーションが正常に動作していること
- インフラやアプリケーションの設定が正しいこと
などを確認します。
CI/CDでの自動テストなど可能な範囲で自動化することにより、定期的なテストが可能になるはずです
また、テストをするにしてもどうやって障害を発生させるかですが、AWSでは障害を意図的に発生させることが出来るFault Injection Simulatorというサービスがあります。
8. DRを評価・見直しする
DRが出来るように計画から構築、テストまで行い、災害発生時に復旧することも確認出来ました。
これで完璧ですね…とはいきません ![]()
なぜなら、以下のように状況は変わっていくからです。
- 試算より予想以上にコストがかかってしまい、マルチサイトアクティブ/アクティブが難しくなった
- システムが増えたため、DR対象も増えた
- アーキテクチャの変更により、DRに変更が必要になった
- 人員の減少などにより、現在の体制維持が難しくなった
- 新しいサービスが出てきて、よりよいDR構成にしたほうがよくなった
適宜、現在のDR対応で問題ないか、評価・見直しをしていくようにしましょう。
コントロールプレーン API 呼び出しがかなりの割合で失敗する、サービスのインフラストラクチャ、リソース、API にかなりの割合で影響する、全面的な電源障害または重大なネットワーク障害に至るなど、ある問題がお客様に広範かつ重大な影響を及ぼした場合、AWS では問題の解決後にPost-Event Summary (PES) を公開することを約束しています。Post-Event Summary は最低 5 年間公開され、問題の影響範囲、問題の原因となった要因、特定されたリスクに対処するために取られた措置が記載されます。
AWS Post-Event Summaryというサイトで、大規模な障害については公開されているようです。
これを見る限り、特定のサービス障害が特定のリージョン内で発生し、1日前後中断したことがあるようです。
東京リージョンに限定すると、過去2回ほど6時間程度のEC2・EBS・DirectConnet障害が発生したようです。
(未来がどうなるかはわからないですが)このとことから、マルチサイトアクティブ/アクティブのような即時復旧できる場合を除いて、必ずしもDRで復旧させるのが正解ではなく、リージョン障害が復旧するのを待つという選択肢もありそうです![]()
今回は、DRとは何か? について記事を書きました。
技術的な部分だけでは解決しない問題もあったりするため、様々な知識や経験が必要になると思いますが重要な内容ではあるので、もっと知識を付けていきたいです![]()
Views: 0

{kind=link}