

こんにちは、yu_Matsuです!
先月は生成AI界隈で大きな発表が多く、頭がパンクしそうになる日々が続きましたが、皆様はいかがでしたでしょうか。
今回なその中でも Strands Agents と Claude Code のキャッチアップを兼ねて、社内情報検索Slack botのアップデートの検証を行ったため、その体験記を記事にしました。
Strands Agents は、2025年5月16日に発表されたばかりの AWS公式のAIエージェントのSDK になります。エージェントのSDKといえば、LangChain/LangGraph や MastraAI などがよく利用されていますが、遂にAWSからも提供されることとなりました!
特徴として、「わずか数行のコードで AI エージェントを構築・実行するモデル駆動型アプローチを採用したオープンソース SDK」と謳われている通り、本当に簡単にAIエージェントを実装することが出来ます。
以下は公式ドキュメントのQuickStartから拝借した、最小単位のコード例になります。たったこれだけでAIエージェントが実現出来てしまうのは驚きです!
from strands import Agent
# Create an agent with default settings
agent = Agent()
# Ask the agent a question
agent("Tell me about agentic AI")
もちろん、ツールの利用やマルチエージェントも対応しており、従来と比べるとより直感的に実装できるようになっていますので、AIエージェントの敷居がまた一段下がったのではないでしょうか。
この記事のもう一つのトピックである Claude Code ですが、こちらは先月の Anthropic社の開発者向けイベントである Claude with Code で正式リリースが発表されたエージェント型コーディングツールになります。
ベータ版ではCLIからの利用のみでしたが、正式リリースに伴い、VSCodeなどのIDE上での利用も可能になりました。
以下のコマンドでインストールすることができ、
npm install -g @anthropic-ai/claude-code
Claude Codeを起動したいプロジェクトのディレクトリに移動し、以下のコマンドを実行することで起動できます
初回起動後は認証が必要になりますので、詳しくは下記のドキュメントをご参考ください。
セットアップが完了すると、以下のようなメッセージが表示されます。Claude Codeへの指示は下の入力欄に入力して実行する感じになります。

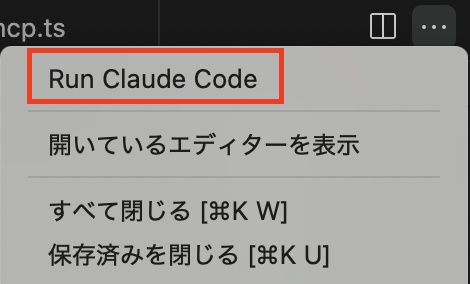
VSCodeの例になりますが、エディタ右上の3点リーダーを押下すると「Run Claude Code」が現れるようになっており、CLIからではなくここからでも起動できるようになっています。
本題に入る前に、まずは既存のSlack botのコードのサンプルを以下に掲載します。
Slack boltを利用して実装した簡単なSlack botであり、裏側ではKnowledge bases for Amazon Bedrock(以降「Knowledge bases」) の Retriever を利用した RAG 搭載のLLMチェーンが動いています。
メッセージがストリーミングで表示されるようにしているため、少し途中の処理が複雑になっていますがご了承ください。
app.py
import os
import asyncio
import logging
from typing import Dict, List
from dotenv import load_dotenv
# slack bolt周り
from slack_bolt import App
from slack_bolt.adapter.socket_mode.async_handler import AsyncSocketModeHandler
from slack_bolt.async_app import AsyncApp
# langchain周り
from langchain_aws import ChatBedrockConverse
from langchain_aws import AmazonKnowledgeBasesRetriever
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# Load environment variables from .env file
load_dotenv()
# 環境変数の設定
SLACK_BOT_TOKEN = os.environ["SLACK_BOT_TOKEN"]
SLACK_APP_TOKEN = os.environ["SLACK_APP_TOKEN"]
AWS_REGION = os.environ.get("AWS_REGION", "us-east-1")
KNOWLEDGE_BASE_ID = os.environ["KNOWLEDGE_BASE_ID"] # Amazon Knowledge Base ID
# ロギング設定
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# 非同期Slackアプリの初期化
app = AsyncApp(token=SLACK_BOT_TOKEN)
# Amazon Knowledge Baseリトリーバーの設定
retriever = AmazonKnowledgeBasesRetriever(
knowledge_base_id=KNOWLEDGE_BASE_ID,
retrieval_config={
"vectorSearchConfiguration": {
"numberOfResults": 4 # 検索結果の数
}
},
region_name=AWS_REGION
)
# BedrockのAIモデルの初期化
bedrock_model = ChatBedrockConverse(
model_id="us.anthropic.claude-3-7-sonnet-20250219-v1:0",
region_name=AWS_REGION
)
# ドキュメントをフォーマットする関数
def format_docs(docs):
"""取得したドキュメントを文字列に整形"""
return "\n\n".join(doc.page_content for doc in docs)
# プロンプトテンプレート
prompt = ChatPromptTemplate.from_template("""
あなたは専門的なアシスタントです。与えられたコンテキストに基づいて質問に答えてください。
コンテキスト:
{context}
質問: {question}
回答は日本語で行ってください。
""")
# RAGのLLMチェーン
chain = (
{
"context": retriever | format_docs,
"question": RunnablePassthrough()
}
| prompt
| bedrock_model
| StrOutputParser()
)
# メンションされたときの処理
@app.event("app_mention")
async def handle_mention(event, say):
"""Botがメンションされたときの処理"""
user_id = event["user"]
channel_id = event["channel"]
text = event["text"]
# の部分を削除してメッセージのみを取得
message_text = text.split(">", 1)[1].strip() if ">" in text else text
try:
# スレッドで初期メッセージ送信(タイピング中の表示代わり)
response = await say(
text="考え中...",
thread_ts=event["ts"]
)
message_ts = response["ts"]
# ストリーミング処理用の状態管理
full_response = ""
update_interval = 1.0 # 更新間隔(秒)
last_update = 0
# RAGチェーンを非同期ストリーミングで実行
async for chunk in rag_chain.astream(message_text):
# 新しいチャンクを追加(文字列として処理)
if isinstance(chunk, str):
full_response += chunk
else:
full_response += str(chunk)
# 一定間隔でSlackメッセージを更新
current_time = asyncio.get_event_loop().time()
if current_time - last_update >= update_interval and full_response.strip():
await app.client.chat_update(
channel=channel_id,
ts=message_ts,
text=full_response
)
last_update = current_time
# 最終的な完全な応答を更新
if full_response.strip():
await app.client.chat_update(
channel=channel_id,
ts=message_ts,
text=full_response
)
else:
await app.client.chat_update(
channel=channel_id,
ts=message_ts,
text="応答を生成できませんでした。"
)
except Exception as e:
logger.error(f"エラーが発生しました: {e}")
await say(f"エラーが発生しました: {str(e)}")
# メイン関数
async def main():
# AsyncSocketModeHandlerの初期化
handler = AsyncSocketModeHandler(app, SLACK_APP_TOKEN)
# アプリの起動
await handler.start_async()
# スクリプトとして実行された場合
if __name__ == "__main__":
asyncio.run(main())
RAGのデータソースとなるドキュメントは、サンプルとして「広報東京都2025年5月号」のPDF版を利用しました。
動作イメージは以下のような感じです。(Slack botの設定等は本題から逸れるため省略します。)
Slack bot(今回は「テスト用ボット」という名前)にメンション付きでメッセージを送ると、スレッドが作成されて会話が開始します。

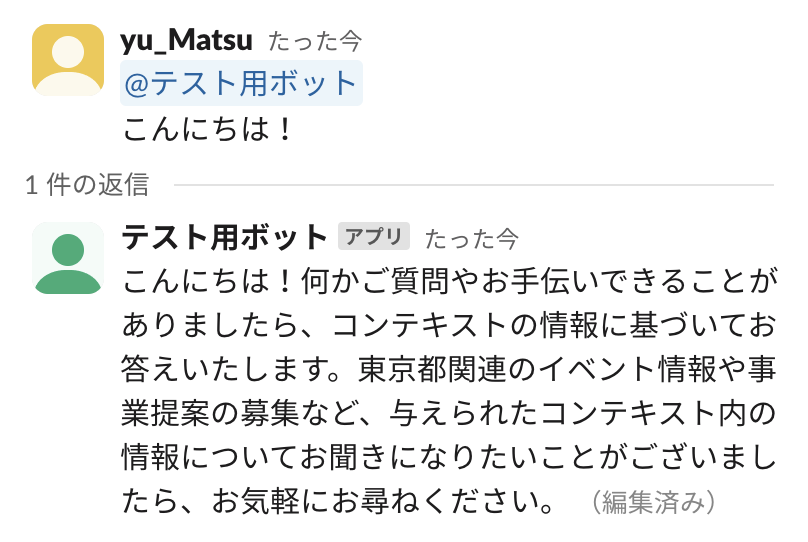
上記PDFの内容に関して答えてくれるかどうか試してみます。『「夢のみち」道路愛護ポスターコンクール』というコンクールの応募締め切りについて聞いてみます。

正解は「6月27日」ですが、問題なく回答しています。

以降で、このSlack botのコードをStrands Agentsで書き換えつつ、MCPサーバーも利用できるようにしていきます!
早速 Claude Code と共に進めていきたいのですが、まずはお互いにStrands Agentsに慣れたいと思います。
Strands Agentsの説明でも触れた通り、非常に簡単なプログラムでAIエージェントを実装できます。以下のような test.py というベースラインのプログラム(ほぼQuickStartのもの)を作成し、機能を付け加えてみたいと思います。
test.py
import boto3
from strands import Agent
from strands.models import BedrockModel
# Create a BedrockModel
bedrock_model = BedrockModel(
model_id="us.anthropic.claude-3-7-sonnet-20250219-v1:0",
region_name='us-east-1',
temperature=1.0,
)
agent = Agent(model=bedrock_model)
if __name__ == "__main__":
result = agent("こんにちは!")
print(result.message)
Strands Agents で RAG を実装したい
今回の目的は RAG 搭載の Slack bot ですので、まずはRAGの利用方法に関して Claude Code に聞いてみます。
Claude Codeへの指示
Amazon BedrockのSDKである Strands Agents を利用して、簡単なAIエージェントをtest.pyというファイルに実装しました。
これに Knowledge bases for Amazon Bedrock の Retriever を利用したRAG機能を追加したいと思います。
Strands Agents は最新のSDKになりますので、必要に応じてWebで検索を行いながら test.py を改修して下さい
早速 Claude Code がタスクを実行し始めました。

複雑なタスクであれば、Claude Code はまずブレークダウンを行い、 TODO リストを作成してからタスクに取り掛かっているように見えます。人間と同じような動きができていて、すごいなぁと感心していました。
また、Web検索を行う場合は、その検索キーワードとともに検索実行中であることも表示されています。
どうやら Strands Agents の公式ドキュメントにたどり着いたようです。
さらに検索してもいいかどうかを聞かれたので、「1. Yes」を選択しました。(ちなみに、これ以降Strands Agentsのドキュメントは承認なしで検索してもよければ「2.」を選択します。)

見守っていると、Strands Agentsのドキュメントの調査が完了し、次のステップに移りました。どうやらboto3のRetrieverの調査をしているようです。

一通り調査が完了して、調査内容に基づいてtest.pyを修正してくれたようです。
VSCode上で Claude Code を実行している場合は、2枚目の画像のように修正前と修正後の差分を表示してくれます。


結果を見てみると、カスタムツールでRAGを実現しているように見受けられます。確かに、Strands Agents では @tool デコレータを利用することでエージェントが利用するツールを自分で定義できます。
しかし、少しドキュメントを漁ってみると、実は Strands Agents では「retrieve」という Retriever のツールが提供されていることがわかりました。strands-agents-toolsというパッケージから利用可能です。
ですので、Claude Codeの変更を「No」で棄却し、追加で2枚目画像のような指示をしてみました。調査の手助けとなるように、retrieveツールのGitHubのURLを合わせて渡しています。


調査の結果、retrieveツールを利用した実装にたどり着いてくれたようです。
先ほどと同様に変更差分が表示されるので、問題がなければ「Yes」を選択すると、変更が反映されます。

修正された test.py が以下になります。
test.py
import os
import sys
import logging
from typing import Optional
from strands import Agent
from strands.models.bedrock import BedrockModel
from strands_tools import retrieve
from dotenv import load_dotenv
load_dotenv()
# Enables Strands debug log level
logger = logging.getLogger("strands")
# Knowledge Base ID (環境変数から取得)
KNOWLEDGE_BASE_ID = os.getenv("KNOWLEDGE_BASE_ID", "YOUR_KNOWLEDGE_BASE_ID")
# Create a BedrockModel
bedrock_model = BedrockModel(
model_id="us.anthropic.claude-3-7-sonnet-20250219-v1:0",
region_name='us-east-1'
)
# Create agent with retrieve tool for RAG
agent = Agent(
model=bedrock_model,
tools=[retrieve]
)
if __name__ == "__main__":
print("RAG対応Slackボットテスト開始")
print(f"Knowledge Base ID: {KNOWLEDGE_BASE_ID}")
print("-" * 50)
# Test basic interaction
result = agent("こんにちは!")
print("基本応答:")
print(result.message)
print("-" * 50)
# Test RAG functionality with retrieve tool
rag_query = "「夢のみち」路愛護ポスターコンクール の応募締切日を教えてください。"
rag_result = agent(rag_query)
print("RAG応答:")
print(rag_result.message)
実際に上記コードを実行してみた結果が以下になります。問題なくドキュメントの情報を回答できている事が分かるかと思います。

このように、Strands Agents で Knowledge bases での RAG を実現する場合、ナレッジベースIDを環境変数に設定さえしておけば、 エージェントの定義で tools=[retrieve] を追加するだけで良いので、かなり便利です。
Tips: retrieveツールに関して、上記のような利用する場合は、検索結果の採用数や、スコアの閾値といったパラメータを設定することが出来ないことに注意して下さい。
スコアの閾値に関しては環境変数にMIN_SCOREを設定すれば良いみたいですが、検索結果の採用数は環境変数で設定できないため、工夫が必要になりそうです。
MCPサーバーも利用できるようにしたい
すでに既存のSlack botをStrands Agentsに置き換えるには十分なのですが、せっかくなのでMCPサーバーも利用できるようにしたいです。引き続きtest.pyを利用して、Claude Code と共に検証したいと思います。
Claude Codeに以下のような指示を投げてみました。
Claude Codeへの指示
test.pyに関して、Strands AgentsでRAGの実装まで完了しましたが、これに加えMCPサーバーも利用出来るようにしたいです。
利用するMCPサーバーはStandard I/Oタイプの想定で、コマンド(command)と引数(args)は環境変数等で指定できるようにして下さい。
同様にTODOリストを作成してタスクを実行し始めました。

Strands AgentsのMCPツール利用のドキュメントに自力でたどり着いたので、「Yes」を選択します。

過程は省略しますが、何度か Claude Code に追加の指示を出した後、test.pyの修正が完了しました。(Claude Codeだけではうまく対応できなかった箇所は人手で修正しています。)

test.py(ところどころ人手で修正しています)
import os
import sys
import logging
from typing import Optional
from strands import Agent
from strands.models.bedrock import BedrockModel
from strands.tools.mcp import MCPClient
from strands_tools import retrieve
from mcp.client.stdio import stdio_client, StdioServerParameters
from dotenv import load_dotenv
load_dotenv()
# Enables Strands debug log level
logger = logging.getLogger("strands")
# Configuration
KNOWLEDGE_BASE_ID = os.getenv("KNOWLEDGE_BASE_ID", "YOUR_KNOWLEDGE_BASE_ID")
MCP_SERVER_COMMAND = os.getenv("MCP_SERVER_COMMAND", "uvx")
MCP_SERVER_ARGS = os.getenv("MCP_SERVER_ARGS", "awslabs.aws-documentation-mcp-server@latest")
# Knowledge Base ID (環境変数から取得)
logger.info(f"Knowledge Base ID: {KNOWLEDGE_BASE_ID}")
logger.info(f"MCP Server: {MCP_SERVER_COMMAND} {MCP_SERVER_ARGS}")
def create_mcp_client():
# MCP client setup
try:
mcp_client = MCPClient(lambda: stdio_client(
StdioServerParameters(
command=MCP_SERVER_COMMAND,
args=MCP_SERVER_ARGS.split(",")
)
))
return mcp_client
except Exception as e:
logger.warning(f"Failed to connect to MCP server: {e}")
logger.info("Continuing with RAG tools only")
def main():
# Create a BedrockModel
bedrock_model = BedrockModel(
model_id="us.anthropic.claude-3-7-sonnet-20250219-v1:0",
region_name='us-east-1'
)
with create_mcp_client() as mcp_client:
# Base Tools
tools = [retrieve]
# Add MCP tools if available
try:
mcp_tools = mcp_client.list_tools_sync()
tools.extend(mcp_tools)
logger.info(f"Added {len(mcp_tools)} MCP tools")
except Exception as e:
logger.warning(f"Failed to list MCP tools: {e}")
logger.info("Continuing with RAG tools only")
# Create agent with RAG and MCP tools
agent = Agent(
model=bedrock_model,
tools=tools,
)
print("RAG対応Slackボットテスト開始")
print(f"Knowledge Base ID: {KNOWLEDGE_BASE_ID}")
print("-" * 50)
# Test basic interaction
result = agent("サクラメントの天気はどうですか?")
print("MCPサーバー応答:")
print(result.message)
print("-" * 50)
# Test RAG functionality with retrieve tool
rag_query = "「夢のみち」路愛護ポスターコンクール の応募締切日を教えてください。"
rag_result = agent(rag_query)
print("RAG応答:")
print(rag_result.message)
Strands Agents では、MCPクライアントを以下のように定義しています。今回はStandard I/Oタイプでの接続なのでstdio_clientを利用していますが、例えばStreamable HTTPでの接続の場合はstreamablehttp_clientを利用します。
mcp_client = MCPClient(lambda: stdio_client(
# commandとargsは環境変数から読み込む
StdioServerParameters(
command=MCP_SERVER_COMMAND,
args=MCP_SERVER_ARGS.split(",")
)
))
そして、エージェント作成の際には以下のように with文でMCPサーバーとのコネクションを張り、list_tools_syncでサーバーからツールを取得します。今回はすでに retrieve ツールがあるので、取得したツールを tools に追加する形になっています。
with create_mcp_client() as mcp_client:
tools = [retrieve]
mcp_tools = mcp_client.list_tools_sync()
tools.extend(mcp_tools)
agent = Agent(
model=bedrock_model,
tools=tools,
)
ちなみに、今回利用するMCPサーバーは、MCPの公式ドキュメントのQuickStartで実装したもので、アメリカの気象予報や警報情報を調べるツール群になります。詳しくは以下をご覧ください。
それでは test.py を実行して動作確認をしてみます。
まず最初にMCPサーバーの方の動作確認ですが、問題なくサクラメントの天気予報を回答してくれています。

次にRAGの動作確認ですが、こちらも問題なさそうですね!

これで、Strands Agents の基本的な使い方に関して Claude Code と共に把握する事ができました!
Tips: MCPサーバーの利用にあたるコード修正に関して、Claude Codeが作成したコードを後から人手で直していますが、この後も同じファイルを Claude Code に操作させる場合は、一度修正したコードを Claude Code に理解させておくと、後続の処理の精度が体感上がったように感じたのでおすすめです。
Claude Codeへの指示例
test.pyをこちらで修正したので、その内容について理解しておいて下さい。必要があればweb検索を行っても構いません
それではいよいよSlack botをアップデートしたいと思います。
元々のlangchainで実装したコードである app.py と、前節で作成したStrands Agentsのサンプルコードである test.py があるため、これらをマージするようなイメージで Claude Code に指示を出します。
Claude Codeへの指示
app.pyでSlack boltとLangChainを利用してRAG搭載のSlack botを実装しています。
先ほどまでtest.pyで実装してきたような Strands Agents を利用したRAG搭載かつMCPサーバを利用できるAIエージェントを搭載したslack botにアップグレードしたいです。
Slack boltによるSlack botの実装部分は基本的に踏襲しつつも、中身のエージェントはtest.pyで実装したものに置き換えるイメージです。
app.pyとtest.pyを比較しつつ、strands_app.pyというファイルでコードを作成してみて下さい。
Tips: 実はこのタイミングで Claude Code で以下のようなエラーが発生していました。これは、Anthropic APIのクレジットが切れたことが原因です。便利だからといって何も考えずに利用していると、結構お金が飛んでいきますので、ご利用は計画的に…

MAXプランであれば、$100/月からという中々なお値段になりますが、Claude Codeが使い放題なので、よく利用する場合は検討の価値があります。
app.pyのコードを読み込んで理解し、タスクを進めてくれています。

一度コードが出来上がったのですが、レビューしてみると、MCPサーバーとのコネクション周り(with文)とストリーミング処理の実装が怪しかったので、参考になりそうなドキュメントを与えて再作成を依頼しました。
すると、一度の指摘のみで想定している動作をするコードを作成してくれました!
正直何往復かやり取りする覚悟でいたので、驚きです!

作成されたコードが以下になります。
strands_app.py
import os
import asyncio
import logging
from typing import Dict, List, Optional
from dotenv import load_dotenv
# slack bolt周り
from slack_bolt import App
from slack_bolt.adapter.socket_mode.async_handler import AsyncSocketModeHandler
from slack_bolt.async_app import AsyncApp
# Strands Agents周り
from strands import Agent
from strands.models.bedrock import BedrockModel
from strands.models.anthropic import AnthropicModel
from strands.tools.mcp import MCPClient
from strands_tools import retrieve
from mcp.client.stdio import stdio_client, StdioServerParameters
# Load environment variables from .env file
load_dotenv()
# 環境変数の設定
SLACK_BOT_TOKEN = os.environ["SLACK_BOT_TOKEN"]
SLACK_APP_TOKEN = os.environ["SLACK_APP_TOKEN"] # Socket Modeに必要
AWS_REGION = os.environ.get("AWS_REGION", "us-east-1")
KNOWLEDGE_BASE_ID = os.environ["KNOWLEDGE_BASE_ID"] # Amazon Knowledge Base ID
MCP_SERVER_COMMAND = os.getenv("MCP_SERVER_COMMAND", "uvx")
MCP_SERVER_ARGS = os.getenv("MCP_SERVER_ARGS", "awslabs.aws-documentation-mcp-server@latest")
ANTHROPOC_API_KEY = os.environ.get("ANTHROPIC_API_KEY", "YOUR_ANTHROPIC_API_KEY")
# ロギング設定
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# Slackアプリの初期化
app = AsyncApp(token=SLACK_BOT_TOKEN)
def create_mcp_client():
"""MCPクライアントを作成"""
try:
mcp_client = MCPClient(lambda: stdio_client(
StdioServerParameters(
command=MCP_SERVER_COMMAND,
args=MCP_SERVER_ARGS.split(",")
)
))
return mcp_client
except Exception as e:
logger.warning(f"Failed to connect to MCP server: {e}")
return None
async def process_message_with_strands_streaming(text: str, channel_id: str, message_ts: str):
"""
Strands Agentでメッセージを処理(ストリーミング対応)
MCPクライアントのwith句制約を考慮した実装
"""
# BedrockModel作成
bedrock_model = BedrockModel(
model_id="us.anthropic.claude-3-7-sonnet-20250219-v1:0",
region_name=AWS_REGION
)
# ベースツール(RAG)
tools = [retrieve]
# MCPクライアントを作成
mcp_client = create_mcp_client()
if mcp_client:
# MCPクライアントを介してMCPサーバーに接続し、処理を実行
try:
with mcp_client:
# MCPツールを取得
try:
mcp_tools = mcp_client.list_tools_sync()
tools.extend(mcp_tools)
logger.info(f"Added {len(mcp_tools)} MCP tools")
except Exception as e:
logger.warning(f"Failed to get MCP tools: {e}")
# エージェント作成
agent = Agent(
# model=bedrock_model,
model=anthropic_model,
tools=tools
)
# ストリーミング処理
full_response = ""
update_interval = 1.0 # 更新間隔(秒)
last_update = 0
try:
# Strands Agentsの非同期ストリーミング
async for event in agent.stream_async(text):
if "data" in event:
# データイベントを追加
chunk = event["data"]
full_response += chunk
# 一定間隔でSlackメッセージを更新
current_time = asyncio.get_event_loop().time()
if current_time - last_update >= update_interval and full_response.strip():
await app.client.chat_update(
channel=channel_id,
ts=message_ts,
text=full_response
)
last_update = current_time
elif "current_tool_use" in event:
# ツール使用イベントの表示
tool_name = event["current_tool_use"].get("name", "Unknown")
tool_status = f"\n🔧 Using tool: {tool_name}..."
await app.client.chat_update(
channel=channel_id,
ts=message_ts,
text=full_response + tool_status
)
# 最終応答を更新
if full_response.strip():
await app.client.chat_update(
channel=channel_id,
ts=message_ts,
text=full_response
)
else:
await app.client.chat_update(
channel=channel_id,
ts=message_ts,
text="応答を生成できませんでした。"
)
return full_response
except Exception as e:
logger.error(f"Streaming error: {e}")
error_msg = f"ストリーミング処理中にエラーが発生しました: {str(e)}"
await app.client.chat_update(
channel=channel_id,
ts=message_ts,
text=error_msg
)
return error_msg
except Exception as e:
logger.error(f"MCP connection error: {e}")
# MCPなしで処理続行
pass
# MCPサーバーが利用できない場合はRAGのみで処理
try:
agent = Agent(
model=bedrock_model,
tools=[retrieve]
)
full_response = ""
update_interval = 1.0
last_update = 0
async for event in agent.stream_async(text):
if "data" in event:
chunk = event["data"]
full_response += chunk
current_time = asyncio.get_event_loop().time()
if current_time - last_update >= update_interval and full_response.strip():
await app.client.chat_update(
channel=channel_id,
ts=message_ts,
text=full_response
)
last_update = current_time
if full_response.strip():
await app.client.chat_update(
channel=channel_id,
ts=message_ts,
text=full_response
)
else:
await app.client.chat_update(
channel=channel_id,
ts=message_ts,
text="応答を生成できませんでした。"
)
return full_response
except Exception as e:
logger.error(f"Agent processing error: {e}")
error_msg = f"処理中にエラーが発生しました: {str(e)}"
await app.client.chat_update(
channel=channel_id,
ts=message_ts,
text=error_msg
)
return error_msg
# メンションされたときの処理
@app.event("app_mention")
async def handle_mention(event, say):
"""Botがメンションされたときの処理"""
user_id = event["user"]
channel_id = event["channel"]
text = event["text"]
# の部分を削除してメッセージのみを取得
message_text = text.split(">", 1)[1].strip() if ">" in text else text
try:
# スレッドで初期メッセージ送信
response = await say(
text="考え中...",
thread_ts=event["ts"]
)
message_ts = response["ts"]
# Strands Agentでストリーミング処理
final_response = await process_message_with_strands_streaming(
message_text, channel_id, message_ts
)
except Exception as e:
logger.error(f"メンション処理エラー: {e}")
await say(f"エラーが発生しました: {str(e)}")
# メイン関数
async def main():
"""アプリケーションのメイン関数"""
logger.info("🚀 Starting Strands Agents Slack Bot...")
logger.info(f"📚 Knowledge Base ID: {KNOWLEDGE_BASE_ID}")
logger.info(f"🔌 MCP Server: {MCP_SERVER_COMMAND} {MCP_SERVER_ARGS}")
logger.info(f"🌍 AWS Region: {AWS_REGION}")
# AsyncSocketModeHandlerの初期化
handler = AsyncSocketModeHandler(app, SLACK_APP_TOKEN)
# アプリの起動
await handler.start_async()
# スクリプトとして実行された場合
if __name__ == "__main__":
asyncio.run(main())
それでは、Slack botを起動して実際に動作確認してみます。
コマンドラインを見る限り、起動自体は成功していますので、第一段階は突破です!

Slack上でbotにメッセージを送ってみます。
とりあえず簡単な挨拶に対する返事は返ってきているのと、どのような機能を持っているかについての説明を見る限りは、正常にツールを読み込めていそうです。

まずは、MCPサーバーの方の確認をします。先ほどと同様に、サクラメントの天気予報について聞いてみます。
ちなみにですが、ストリーミング表示もちゃんと出来ています。下画像はツール実行途中の出力になります。

サクラメントの天気予報が返ってきました!

最後に、RAGの方の確認になります。今度は違う質問をしてみます。
旧芝離宮恩賜庭園で開催される「旧芝離宮夜会」の開催期間を聞いてみます。

正解は以下なのですが、開催期間に加え、他の付加情報に関しても誤りなく回答できていることが分かります!

これで一通り動作確認は完了です!
無事にSlack botをアップデートすることが出来ました!!🎉
Tips: 今回はモデルに Claude 3.7 を利用していますが、もちろん Claude Sonnet 4 を利用することも可能です。
model_id="us.anthropic.claude-sonnet-4-20250514-v1:0"
しかし、筆者が試した時点では BedrockModel 経由での呼び出しだとレスポンスが全然返ってこないという事象が発生していました。
もしそうなった場合は、以下のように直接Anthropicのモデルを呼び出してみて下さい。 ただし、事前にAnthropicのAPIキーを払い出しておく必要があることに注意して下さい。
from strands.models.anthropic import AnthropicModel
anthropic_model = AnthropicModel(
client_args={
"api_key": ANTHROPOC_API_KEY,
},
# **model_config
max_tokens=1028,
model_id="claude-sonnet-4-20250514",
params={
"temperature": 1.0,
}
)
今回は、社内情報検索Slack botのアップデートの Strands Agents によるアップデート検証を、Claude Code を利用して実施した体験の記事でした。
Strands Agentsは、とにかく手軽にエージェントを実装できるようになったのが驚きでした。AIエージェントへの入門時はもちろん、PoCなどで手早く動くものを作りたい時にも便利なのではと思います。もちろん、LangChain や Mastra AIといった他のフレームワークとは実装したいものの特性や状況によって使い分けになるかと思いますが、AWSの公式からSDKが提供されたというのはかなり大きいと思います。今後の展開に期待
Claude Code は実際に使ってみてその便利さと性能の高さに感動しました。こちらが出した指示を、人間と同じようにタスクに分解してを整理してくれますし、複雑なタスクでも、詳細に、段階に分けて指示すればかなり高精度なコードを生成してくれていました。Maxプランにしてこれからもガンガン使っていきたいです!
本記事はこれで以上になります。ご高覧ありがとうございました!!
Views: 2

{kind=link}