
はじめに
こんにちは!ナウキャストのデータエンジニアのけびんです。
ナウキャストでは一部のバッチジョブの実行やデータの保存にAWSを利用しています。その中でも、古くから運用しているAWSアカウントでは、特に2024年までのコスト増加が課題となっていました。
様々な施策を通じて、2025年にはアカウント全体での月額コストを 約30% 削減することができ、その中でもS3単体での削減が最も大きな成果を上げました。本ブログでは、S3に焦点を当て、実際にどのようにコスト削減を行ったのか、その設定やアーキテクチャをご紹介します。
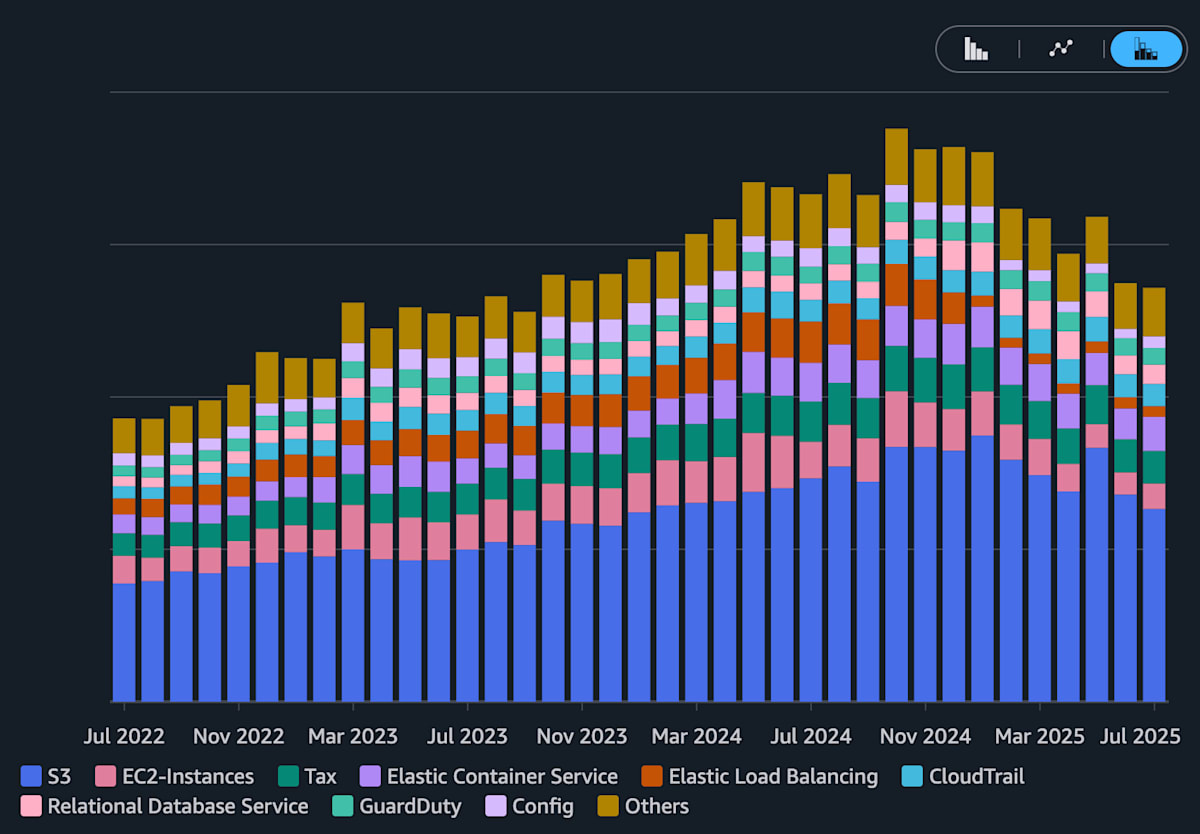
Cost Explorer で確認した対象のAWSアカウント全体のサービスごとのコスト。
特にS3が2024年まで増加し、その後削減されている様子が確認できる。
ナウキャストのビジネスモデルとS3の役割
本記事の技術的な詳細を理解するうえで、背景としてナウキャストがどのようなビジネス課題を解決しているかをご紹介します。
ナウキャストは 「データの商社」 として、パートナーであるデータホルダーからPOSデータやクレジットカードデータなどの多様なビッグデータを受け取り、それらを社内のデータ基盤で適切に集計・加工したうえで、顧客に提供するビジネスを展開しています。
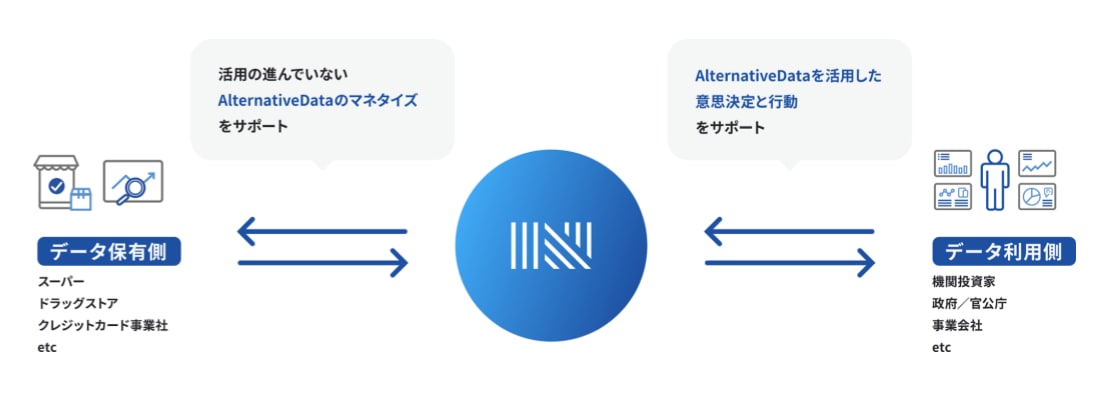
このプロセスにおいて、 S3 は大量のデータ管理や保存を支える基盤としての役割を果たしています。しかし、S3はアカウント全体のコストの 約半分 と大きな割合を占めており、ストレージコストは重要なテーマとなっています。
はじめにお見せしたグラフが示す通り、2024年にはS3のコストが増加の一途をたどり、対応が必要でした。本記事ではこの課題をどう解決したのか、そのアプローチを紹介していきます。大まかな流れは以下の通りです。
- 事前準備として、S3の課金体系と現状のコストを正確に把握する
- ストレージコストが現状一番大きいと判明したため、適宜データの削除を進める
- データの削除はステークホルダーとの調整で時間がかかることが多いため、「削減量は大きいが時間がかかるもの」と「削減量は小さいがすぐにできるもの」を並行して行うことでコスト削減が進んでいる様子を示せるようにバランスを取った
事前準備
実際にコスト削減に手をつける前にコストの現状を正しく認識することは非常に重要です。むやみやたらにコスト削減の作業をしても効果が薄い可能性も高いため、適切にコストの現状を理解し、削減効果が高いところから優先度をつけてやることにしました。
S3 の課金体系の把握
まずはそもそもS3のコストの仕組みについて正確に把握することが大事です。どのコストを削減するかによって、行うべき削減施策も大きく異なるからです。
S3の標準バケットであれば基本的に以下の3種類のコストが発生します。
-
ストレージ課金:保存したデータ量に比例して発生するコスト
- 例:東京リージョンだと基本的に毎月$25/TB
-
データ転送課金:データを転送する際に発生するコスト
- 例:S3(APN1) → S3(Others) :$90/TB
- 例:S3(APN1) → Internet :$114/TB
-
リクエスト数課金:APIを利用した回数に比例して発生するコスト
- 例:PUT, COPY, POST, LIST : $4.7 / 100万リクエスト
- 例:GET, SELECT など: $0.37 / 100万リクエスト
- 例:DELETE, CANCEL : 無料
Cost Explorer での現状確認
コストの仕組みがわかった上で、実際に発生しているコストを確認しましょう。AWS では Cost Explorer という機能があるのでこれを使うことで簡単にコストを可視化することができます。おすすめの可視化の仕方をいくつか紹介します。
- 全てのコストを、 Service で Group by する
- はじめに、で貼った画像はまさにこのパターン
- S3が支配的であり、またS3のコストが増えていることがわかる
- Service を S3 に絞り、 Usage type で Group by する
- S3 の中では、 ストレージ課金 が一番大きいことがわかる
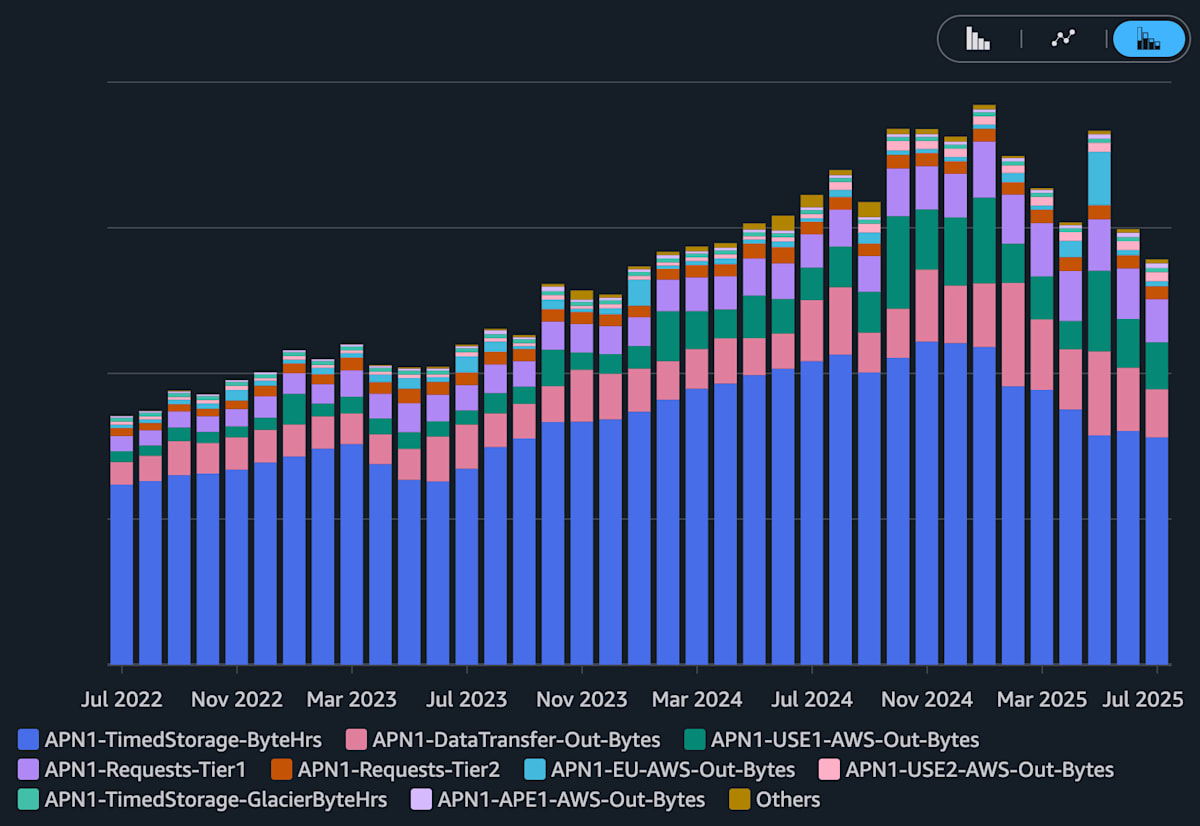
- S3 の中では、 ストレージ課金 が一番大きいことがわかる
- Service を S3 に絞り、 Resource で Group by する
- 直近14日分しか見られないが、バケットごとにより詳細なレベルでコストを確認できる
これらの作業により、ストレージ課金が高いバケットから優先して中身を確認し不要なものを削除しようというアプローチが可能になります。
S3 Storage Lens での現状確認
Storage Lens を使うことで AWS アカウント全体で、どのバケットのどのような種類のデータ量が多いのか、というのを簡単に把握できます。
- Total storage
- 不完全なマルチパートアップロード、オブジェクトメタデータ、削除マーカーを含む、合計ストレージ容量
- Noncurrent version bytes
- 現在のバージョンではないストレージ容量
- Incomplete multipart upload bytes
- 不完全なマルチパートアップロードストレージ容量
この辺りの主要なメトリクスは14日間分しかデータは見られませんが無料で確認することができるので便利です。
無料枠でS3のストレージ料金の現状整理が可能なのはありがたいですね。

ドキュメント https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/userguide/storage_lens.html より
また有料にはなりますが “Transition lifecycle rule count” など他のメトリクスを利用することも可能です。S3利用状況をより深く見ておくべき場合には活用を検討すると良いでしょう。
コスト削減①:明らかに不要なデータを削除する
S3 の Storage Lens を使って状況を見てみると、いろいろなデータが存在することがわかります。
今回のAWSアカウントの場合、意外と以下のストレージ量があり、これらの多くは削除して良いものでした。
- Noncurrent version bytes
- Versioning しているバケットの古いバージョンのオブジェクトのデータ量
- Incomplete multipart upload bytes
- 大きいデータのアップロードの際には multipart upload が行われるが、これが途中で失敗した場合などのファイルがそのまま残っていることがあり、そのデータ量
これらのデータを削減するために、適切に S3 Lifecycle Policy を設定していきました。 Terraform で設定する場合には以下のように記述すれば良いです。
resource "aws_s3_bucket_lifecycle_configuration" "s3_test" {
bucket = aws_s3_bucket.s3_test.id
rule {
id = "retain_versions_for_7_days"
noncurrent_version_expiration {
noncurrent_days = "7"
}
filter {
prefix = ""
}
status = "Enabled"
}
rule {
id = "retain_multipart_uploads_for_1_days"
status = "Enabled"
filter {}
abort_incomplete_multipart_upload {
days_after_initiation = 1
}
}
}
コスト削減②:実は不要なデータを削除する
「コスト削減方法①」であきらかに不要なデータが削除できましたが、まだまだデータはたくさんS3に保存されています。大量にデータがあると実はもう使われておらず不要なものもあったりするでしょう。そのようなデータを特定し、対処することでコスト削減につながります。
不要なデータの特定:S3 Access Logs と Athena
まず実は不要なデータを特定する必要があります。関係者にいちいち聞いていくと大変です。そこで S3 Access Logs を出力するように設定し、そのログから使われていないデータを特定するというアプローチをとりました。
S3 Access Logs は他のログと同様設定以降のログしか保存されないので、まず最初に設定しておくことが重要です。 Cost Explorer や S3 Storage Lens でコスト削減対象の候補となったバケットについては早めに設定しておきました。
ログを取得したいバケットで S3 Access Logs を有効化する他、ログを保存するバケットのバケットポリシーも変更する必要があるので注意してください。
またさらにこの特定の作業をやりやすくするために、出力された S3 Access Logs に対して Athena Table の設定もしておくと便利です。これにより Athena で S3 の利用状況の分析が簡単にできるようになり、アクセスされていないデータの特定をしやすくなります。
S3 Access Logs の設定には意外と罠があったりします。また Athena のテーブルは Partition Projection 間で設定すると、ログ分析のパフォーマンスが上がりコスト効率も良くなります。この辺りのトピックについては詳細を別途記事にまとめる予定です。
対処方法
アクセスされていないデータを特定したら、ステークホルダーと合意を取り、実際にデータの削除をしました。
場合によっては削除は心配なケースもあるかと思います。そのようなケースでは Glacier など料金が安いストレージクラスへ変更をすることを検討してもよいかもしれません。これらの対処方法も Lifecycle Policy で対応するのが楽です。
コスト削減③:S3のアーキテクチャを見直す
コストの確認のところでも明らかであったように、2024年前半ごろまでS3のストレージ料金はひたすら増加していました。これはナウキャストにおけるS3の使い方が原因でした。
最初に話したようにナウキャストはデータの商社のようなビジネスをしており、加工したデータ顧客に提供しています。提供方法は、ナウキャストのAWSアカウントにS3バケットを用意し、顧客のAWSアカウントからのクロスアカウントアクセスの許可をすることで、顧客にデータを pull してもらえるようにするというものです。この際にS3バケットは顧客ごとに作成していました(社内ではこれを gate bucket と呼んでいます)。

つまり顧客が増えるごとに gate bucket の数は増え、またその中に同じデータがコピーされてしまうという構造になっていました。
顧客ごとに設定するためある意味シンプルであり、また歴史的な事情でこのような構成になっていました。
このデータを重複して持つ構成を変更しないとビジネスの成長とともにストレージコストが増えてしまう現状が変わらないため、 shared bucket という共通のバケットを作ることにしました。多くの顧客は全く同一のデータを購読しているため、単一のS3バケットを用意し、そこに複数の顧客からアクセスが可能になるような構成にしました。
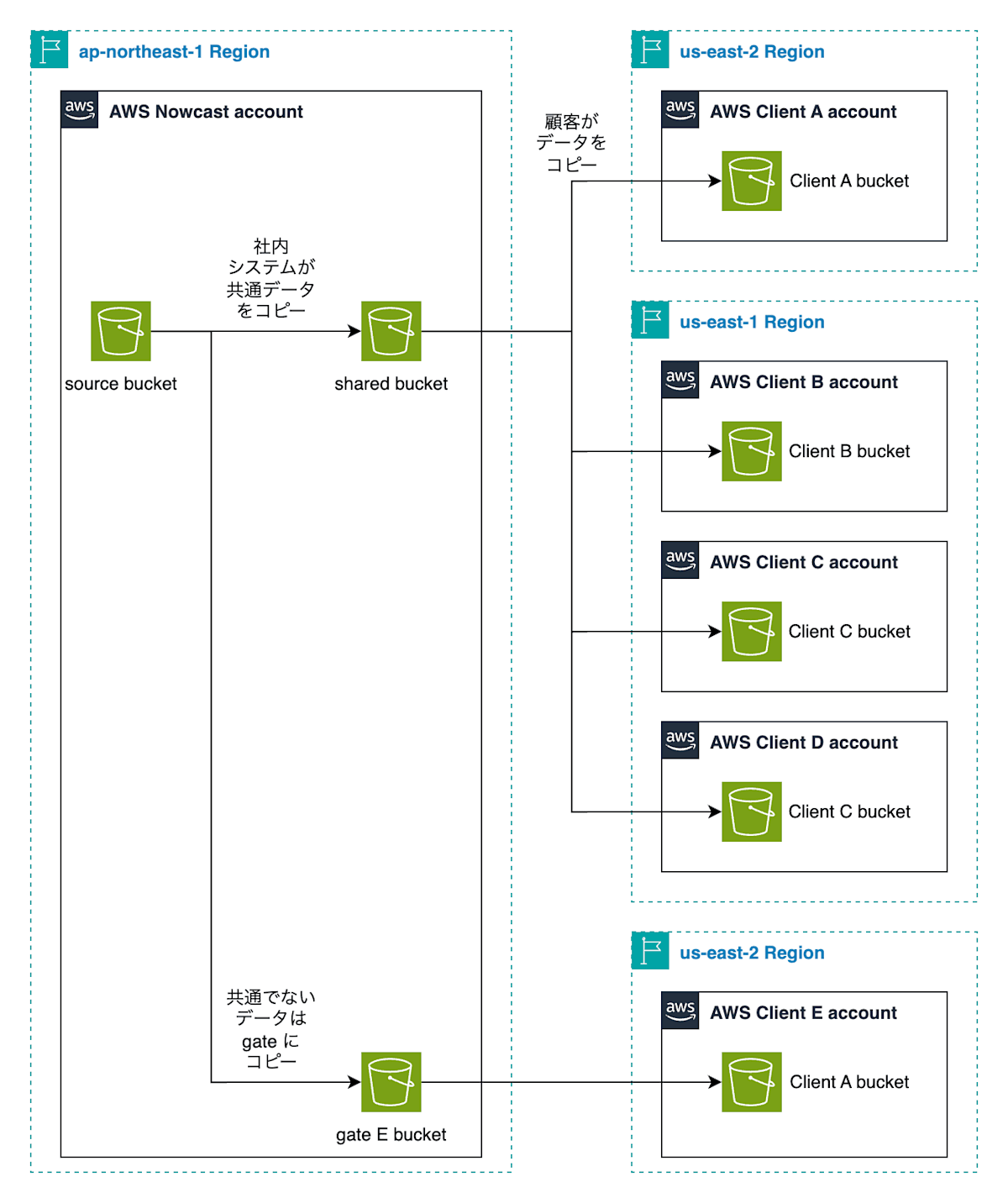
このようにデータ伝送に関する S3 のアーキテクチャを見直し、 S3 で重複して保持しているデータを削除することが可能になり、2025年に入ってから gate bucket と呼んでいる顧客個別のバケットからデータを実際に削除しました。
その結果として S3 のコストの大幅な削減につながっています。
まとめ
ナウキャストでS3のコスト削減のために行った設定やアーキテクチャの設計を紹介してきました。ポイントは
- Cost Explorer や Storage Lens によるコストの現状把握
- S3 Access Logs によるデータの利用状況の把握と、データの削除
- S3 のアーキテクチャを工夫することで不要なデータの削除
で、これらの結果としてS3の月額コストを約30%削減することができました。
今回は主に S3 のストレージ容量削減が主眼に置かれた内容でした。
気づいている方もいるかもしれませんが、その次にデータ転送のコストもそれなりに高くなっています。こちらについては現在対策を打っているところで、結果が出たらまた紹介します!
Views: 0

{kind=link}