

AI技術の発展はすさまじく、毎月のように新しいAIモデルが生まれては会話の自然さや計算能力などのスコアがアップデートされています。しかし、AIセキュリティツールを構築するエンジニアのディーン・バレンタイン氏は「最近のAIモデルの進歩は、ほとんどでたらめなのではないか」と指摘し、AIを取り巻く問題点について語っています。
On Recent AI Model Progress – ZeroPath Blog
https://zeropath.com/blog/on-recent-ai-model-progress
バレンタイン氏は2024年に会社を設立し、最新のAIモデルを活用して、セキュリティ分野の脆弱(ぜいじゃく)性を見つけるテストをする専門職である「ペンテスター」の大部分を置き換えるツールを作成するプロジェクトを開始しました。バレンタイン氏によると、会社を設立して間もない頃にAnthropicがリリースしたClaude 3.5 Sonnetの高い能力もあり、初期の社内ベンチマークの結果はすぐに飽和状態になり始め、バレンタイン氏らのセキュリティツールは基本的なミスを減らしただけでなく脆弱性の説明と重大度の見積もりの質も向上したように見えたことに驚いたそうです。
ClaudeはAIモデルを3.6、3.7と更新していき、バレンタイン氏らのセキュリティツールも新しいモデルを導入していきました。しかし、より高いパフォーマンスと発表されていた新しいモデルを導入しても、旧モデルを導入していた頃と比べて、内部ベンチマークにも新しいバグを見つける能力にも大きな違いをもたらさなかったそうです。そのため、バレンタイン氏は「実際のところ、ClaudeのAIモデルは新しいものになっても大してパフォーマンスが向上していないのではないか」と指摘しました。その上で、バレンタイン氏は「AI業界には『正しい尺度』が存在しないことが問題です。業界がモデルの知的能力について測定する方法を思いつかないのなら、企業経営や公共政策の策定といった業務にAIが及ぼす影響を評価する指標を、一体どうやって開発するつもりなのでしょうか」と語っています。
バレンタイン氏によると、新しいAIモデルが発表される際に参照されるベンチマークは、統一された規格のあるものではなく、「そのAIモデルを評価するためのベンチマーク」になっている可能性があるそうです。統一的な基準としてのベンチマークは、AIの論文理解&再現能力を評価するOpenAIの「PaperBench」や、AIのサイバー犯罪能力を測定するGoogleのベンチマークなどが開発されています。しかし、基準としてのベンチマークが存在すると、AIを開発する際に実際の利便性を上げるのではなく、既存のベンチマークをクリアするための努力が行われる傾向にあるとバレンタイン氏は指摘しました。イギリスの経済学者が提唱した、『尺度が目標になると、それは良い尺度ではなくなる』というグッドハートの法則というものがあり、現在のAI業界は、AIの能力を評価したいことが先行してグッドハートの法則に陥っているとバレンタイン氏は警告しています。
AIモデルが爆速で賢くなっているのでテスト方法が追いついていない – GIGAZINE

また、既存のベンチマークが正しい評価を下しているかという問題もあります。ブルガリアのテクノロジー研究所に所属するイボ・ペトロフ氏らが2025年3月に発表した論文では、数学ベンチマークで高いスコアを達成していた言語モデルを利用して、2025年アメリカ数学オリンピックの問題に取り組ませたところ、テストしたすべてのモデルが大幅に苦戦して平均で5%未満という低いスコアを記録したことを報告しました。これは、従来のベンチマークは最終的な数値の答えのみに基づいてモデルを評価していましたが、実際の数学タスクには厳密な推論と証明生成が不可欠であり、数学的推論に基づいたベンチマークでは言語モデルは依然として能力が欠けているためです。ここでは、モデルがベンチマークスコアを向上させるのは「多くの答えをトレーニングで覚えた」ということでしかなく、出題されたばかりの数学オリンピックの問題のように、知らない問題を推論で解決することはできない可能性が示唆されています。
一方で、AIの機能向上を正しくつかむことができる指標としてバレンタイン氏が挙げたのは、AIモデルにポケモンのゲームをプレイさせる「ClaudePlaysPokemon」です。ゲームをプレイするには、基本的な操作を把握することに加え、つい先ほど学んだ内容を時々思い出すなど、多くの人間特有の能力を統合する必要があります。そのため、Claude 3.7 Sonnetのような高度なAIモデルでもかなりゆっくりゲームをプレイしていますが、どのようにタスクをうまく処理しているか確認できるため、基準が不透明なベンチマークを信頼するよりノイズが少ないとバレンタイン氏は述べています。
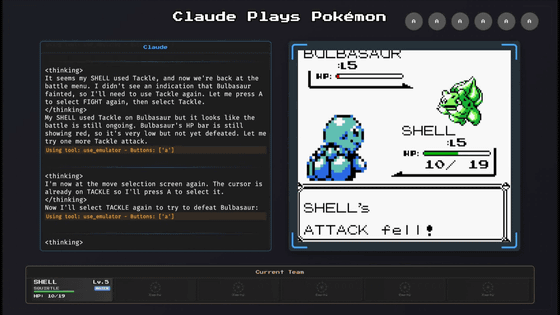
バレンタイン氏は「AIは、すぐに私たちが住む社会の心臓部になるでしょう。それらが互いに構成し、相互作用しながら作り出す社会的、政治的構造は、私たちの周りで目にするすべてのものを定義します。私たちはできる限り、それらを高潔なものにすることが重要です」と語りました。
この記事のタイトルとURLをコピーする
・関連記事
Googleが「AIのサイバー犯罪能力」を測定するベンチマークを開発 – GIGAZINE
OpenAIがAIの論文理解&再現能力を評価するベンチマーク「PaperBench」を発表、人間とAIのどちらが研究開発力が高いのか? – GIGAZINE
推論モデルは「思考内容」を出力しているけど実際の思考内容とはズレていることが判明、Anthropicが自社のClaude 3.7 SonnetやDeepSeek-R1で検証 – GIGAZINE
Views: 0

{kind=link}