
注意
決してクラッキングなどの犯罪行為に悪用しないでください。
例えバグを見つけても本番環境で確かめることはせず、然るべき手順に従って報告してください。
社内で使う場合、情報漏えいには十分気をつけてください。
私は ZOMIA という暗号専門の研究機関と、早稲田大学の暗号プロトコル修士課程に所属しています。
ZOMIA での研究の一環として Cline と Claude Code を組み合わせたセキュリティ診断ツールを開発し、
- 攻撃シナリオ設計
- 攻撃を再現する PoC テストコード生成
- 脆弱性報告レポート作成
までを 半自動化 しました。
目的は、形式検証やプロ監査でも見逃される複雑なロジックバグを発見し、ソフトウェアをハッカーから守ることです。
本記事では、この セキュリティ特化型エージェント開発のノウハウと学び を共有します。
読者は「AI を実務に活用したいエンジニア」を想定しています。
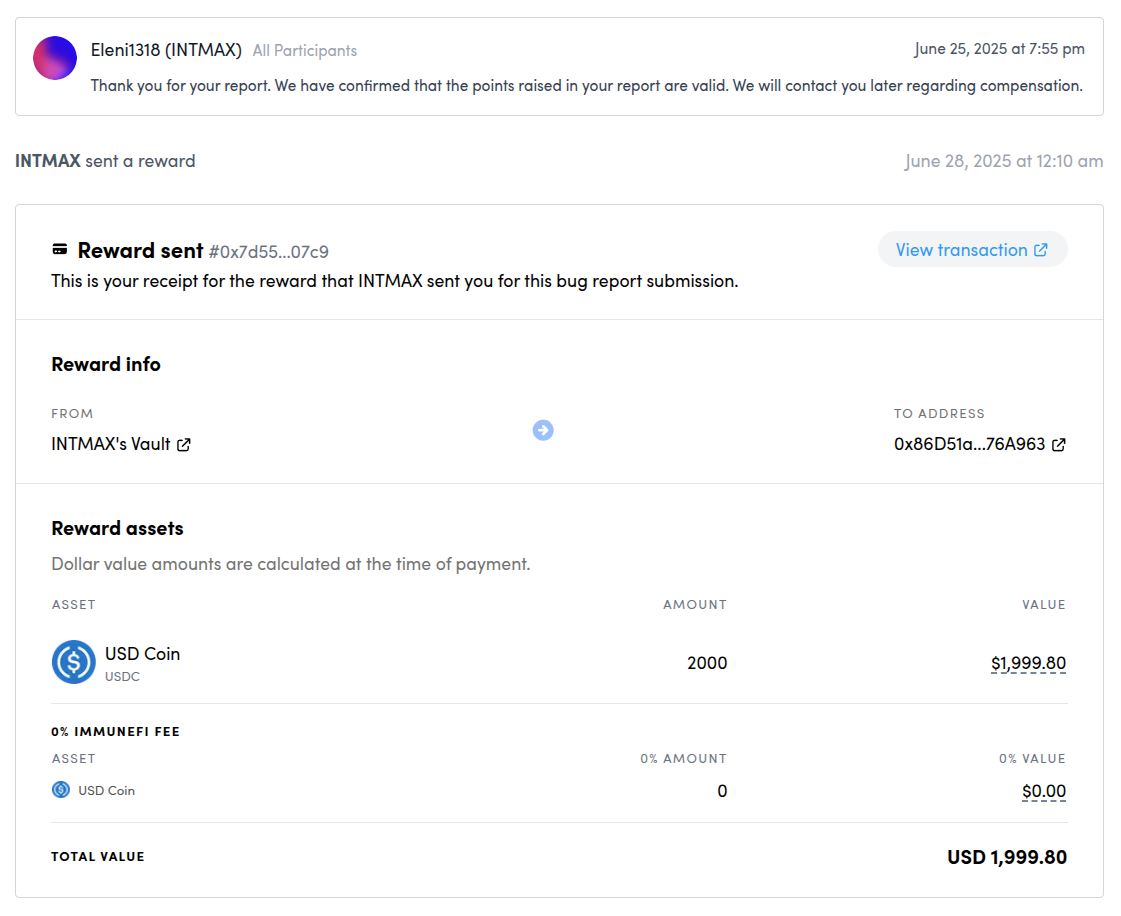
経緯 — バグバウンティで $2,000 を獲得
セキュリティ診断ツールの有用性を確かめるべく、Immunefi のバグバウンティ に参加しました。
1 週間で 10 プロジェクトを調査し、ついに intmax2-zkp にロジックバグを発見。報奨金 $2,000 を得ました 🎉
プロジェクトCEOからも評価されている通り、形式検証やプロ監査やホワイトハットにも見逃されたバグを発見できました👏
サービスの目標とコンセプト
本サービスのゴールは 与えられたソースコード群からバグを見つける こと。
必要な工程は次の 4 つです。
| # | 工程 | 補足 |
|---|---|---|
| 1 | 脆弱箇所の発見 | 静的解析+コードリーディング |
| 2 | 攻撃シナリオ設計 | アプリ固有ロジックを理解 |
| 3 | 攻撃 PoC(E2E テスト)生成 | 失敗 PoC は削除 |
| 4 | バグレポート作成 | フォーマットに沿い Markdown で出力 |
肝は 1・2 の質をいかに上げるか。
単純なコーディングルール違反は既に監査で潰されているため、アプリケーション特有のロジックバグ を掘り当てる必要があります。
関連研究のAuditGPTやSymGPTはコーディング規約違反検出が主ターゲットですが、当プロジェクトは “その一歩先” を狙うものです。
目標を達成するために、我々は「攻撃者の思考」をトレースするように訓練するように心がけました。
これにより、AIの性能向上とともに未知の攻撃を自律的に発見可能になると考えています。
今回の成果でそれが一部実証されました。
最初からLangChainで実装しようとするな
初期段階ではLangChainを使ったワークフローを自前で組んでいました。しかしこれは失敗でした。
LangChainを用いてGitHubのURLを入れるだけで診断してくれるという手軽なインタフェースを作りました。

アーキテクチャは以下の通りで、Slitherなどの静的解析ツールやRAGを駆使してAIがセキュリティ診断を行うワークフローを構築しています。
LangChainを使ったAI Agentワークフロー
とても洗練されたアーキテクチャに見えますが、この技術選定には問題がありました。
大前提として、我々はセキュリティの専門家であり、AIエージェントの専門家ではありません。
最初からまあまあ上手くいくだろうという希望的観測しか持っておらず、AIエージェント開発はトライアンドエラーを繰り返すことで精度を高めていくしかないことに気付けていませんでした。
実際には、エージェントワークフロー、コンテキストデータ、プロンプトなどのプラクティスが固まるまでは手動で微調整を何回も繰り返す必要があり、LangChainでそれをやると毎回の修正工数が肥大します。
詰まるところ、AIエージェント開発は思ったよりはるかに複雑で、プロンプトエンジニアリング、ワークフロー設計、API使用制限に対する対処など、エンジニアリングの課題が多すぎるのです。
それで本来のAIの精度が出ないのはもったいないと思い、課題を限定するために、エージェントワークフローには既存のCline + Claude Codeを運用する方針に切り替えました。
これらはワークフローをプロンプト経由で指示することもできますし、RAGやMCPも簡単に設定できる柔軟さがあります。
まずは巨人の肩に乗り、方法が固まったらLangChainで改めて自動化しようと結論付けました。
Claude Code だけでは攻撃シナリオが弱い
次に、Claude Codeだけで自動化できないかと思い、攻撃シナリオ設計から報告書作成まで行うプロンプトを与えて実行させてみました。
実際のプロンプト
## 導入メッセージ(最初に送る)
**🎯 目的**
あなたには、このリポジトリのスマートコントラクトを「攻撃者視点」でエンドツーエンド監査してもらいます。
私が順番に質問を出すので、**必ず理由を考えたうえで行動し、その理由を短く説明してください**。
成果物に AI・RAG・LLM などの語を絶対に含めないでください。
不明点があれば必ず質問してください。準備ができたら **「準備完了」** とだけ返答してください。
---
### 質問 1 — ドメイン知識の読み込み
**Step 1**
以下 3 つのディレクトリにある *すべての JSON ファイル* を取得し、インデックスを作成してください。
* `.audit/rag/attacks/`
* `.audit/rag/audits/`
* `.audit/rag/practices/`
取得したファイル名を一覧表示し、インデックス化が終わったら **「Step 1 完了」** と返してください。
---
### 質問 2 — アプリケーション文脈の理解
**Step 2**
`.audit/application_context.md` と `.audit/scopes.md` を解析し、以下を箇条書きでまとめてください。
1. ビジネスロジック
2. 信頼前提
3. 役割 / アクセス権限
4. クリティカルアセット
5. 外部連携
まとめを提示したら、**「Step 2 完了」** と返してください。
---
### 質問 3 — 静的解析の実行
**Step 3**
`python .audit/tools/scan_executor.py .` を実行し、`contracts/` 配下を解析してください。
各検出結果について
「ファイル : 行番号 | 重大度 | ツール名 | 簡潔な説明」
の形式で列挙し、**生ログはそのまま保存** してください。
一覧を提示したら **「Step 3 完了」** と返してください。
---
### 質問 4 — 手動コードレビュー
**Step 4**
`contracts/` のコードを手動で精読し、Step 3 と突き合わせて *疑わしい箇所* を洗い出してください。
それぞれについて
「ファイル : 行番号 | 懸念点の要約 | 想定される攻撃アイデア」
を列挙してください。
重点は *コア機能ロジック* と *高インパクト経路* です。
終わったら **「Step 4 完了」** と返してください。
### 質問 5 - 動的解析の実行
静的解析とはべつに、動的解析を実施してください。各external関数に対してfuzz testを実施し、おかしな挙動がないか分析してください。
---
### 質問 5 — エクスプロイトシナリオの構築
Ultrathink:
**Step 5**
今までの各疑点ごとに、.audit/application_context.mdを見ながら次の形式で **少なくとも 1 件** の具体的シナリオを作成してください。
1. 前提条件
2. 攻撃手順(行動 → 得られる権限)
3. 最終的な影響
4. スコープ内である理由(`.audit/scopes.md` との照合結果)
攻撃者ならどういう攻撃をするかを想像しながら、キルチェーンやアタックグラフを構築しながら攻撃シナリオを作成すること。
完成したら **「Step 5 完了」** と返してください。
---
### 質問 6 — エクスプロイトテストの生成と実行
**Step 6**
リポジトリのテストフレームワークを自動検出し、**各シナリオにつき 1 ファイル** の PoC テストを `test/security/` に追加してください(既存スタイルを踏襲)。
すべてのテストを実行し、脆弱性が再現できた PoC だけを残してください。
脆弱性が再現できたときにテストが成功するようにしてください。
テスト結果のサマリを提示したら **「Step 6 完了」** と返してください。
## DO - 正しいテスト方法:
1. External関数のみテスト - 攻撃者が実際に呼び出せる関数
2. 現実的なmsg.sender - 攻撃者のアドレスを使用
3. 実際のユーザー行動 - 正当なapprovalパターン
## DON'T - 間違ったテスト方法:
1. Internal関数の直接テスト - 攻撃者は呼び出せない
2. 任意のsender指定 - 攻撃者にはこの能力はない
3. ライブラリの技術的詳細 - 実際の攻撃とは無関係
4. 理論的可能性のみ - 実用性を無視
5. フィッシング、オラクル、外部コントラクトなどの外部要因に依存するテスト
---
### 質問 6.5 — バリデーションゲート確認
**Step 6.5**
次の 4 条件を **チェックリスト形式** で示し、すべて ✔ が付いていることを確認してください。
* PoC が再現に成功
* シナリオが完全にスコープ内(.audit/scopes.mdのOut of Scopeをもとに照合)
* 誤検知なし
* 不成立シナリオとそのテストは削除済み
確認後 **「Step 6.5 完了」** と返してください。
---
### 質問 7 — 監査レポートの作成
**Step 7**
Step 6.5 を通過した各エクスプロイトについて、`.audit/report_templete.md` のフォーマットに従って Markdown レポートを `.audit/reports/` に作成してください。
すべての項目を埋めてください。
PoCには、そのコードとcontractsのコードがあれば独立で実行できるテストコードを記述して。テストコマンドは入れなくて良いです。
完了したら **「Step 7 完了」** と返してください。
---
### 最終確認
**Step 8(最終)**
以下の成果物がそろっているか確認し、チェックリストを提示してください。
1. `test/security/` 内の PoC テストファイル(すべて通過)
2. 静的解析ログ
3. `.audit/reports/` 内の脆弱性レポート
4. コミット外の内部思考ログ
すべて OK なら **「監査完了」** と返してください。
ここでは.audit/rag/にありったけの知識を詰め込んでいます。特に有用だったのはImmuneFiなどで過去に報告されたバグレポートの一覧です。
しかしこれは部分的に失敗でした。Claude Codeはあくまでコーディングに特化しているため、攻撃シナリオ設計で躓きました。Claude Codeが提案した攻撃シナリオに的外れなものが多かったのです。
バグバウンティは、攻撃のスコープが事前に定義されています。ソーシャルハッキングや、外部ツール起因のバグなどは当然対象外だからです。
しかし最悪なことに、Claude Codeはスコープ外の攻撃をでっち上げてきます。これは重大なハルシネーションでした。
なぜこれが起こるのか試行錯誤して分かりました。主な原因はClaude Codeがコンテキストをすぐに忘れてしまうことにありました。
あらかじめアプリケーションに関するドメイン知識や攻撃スコープの定義を与えていても、コードを探索しているうちに忘れてしまい、コードの「なんとなく怪しい部分」につられてしまっていることが分かりました。
この原因を決定付けたのはChat GPTのo3を使っているときでした。
試しにClaude Codeが提案した攻撃シナリオを「この攻撃は今回のバグバウンティに妥当なのか」をチェックしてみたところ、しっかりと攻撃スコープ内外の見分けをして、妥当かどうか判別してくれました。
GPTはo1くらいからデフォルトでエージェントになりましたが、質問をするとまずWeb検索して必要なコンテキストを整理していることが挙動から分かります。
これは、必要な情報を回答前に必ず再整理しているのです。なので、GPTはコンテキストを与えるほど賢くなります。しかしClineやClaude Codeはその逆で、コンテキストを多く与えすぎると整理しきれずに、ニワトリのようにすぐ忘れてしまうのです。
なのですべて単一のエージェントに頼るのではなく、下の流れのうち1と2を行うエージェントと3と4を行うエージェントに分けました。
- ソースコードをもとに脆弱箇所の発見
- 攻撃シナリオの設計
- 攻撃の再現PoC (簡単なE2Eテスト)
- バグレポートの作成
各エージェントには膨大なデータの代わりに要点だけが記述されたマークダウンファイルをコンテキストとして与えることにしました。
また、ハルシネーションを最大限防ぐために、2と4のあとにGPT o3に妥当性を判定させてフィードバックをし、何回かやり直させるようにしました。
解決策 — 役割分担 & ダブルチェック
最終的に、次の 三位一体アーキテクチャ に落ち着きました。
- Cline — 脆弱箇所抽出 & 攻撃シナリオ生成
- Claude Code — PoC 作成・テスト実行・レポート整形
- GPT-o3 — 上流で指示 / 下流で妥当性チェック(ハルシネ潰し)
実際のスクショ
-
Cline が攻撃シナリオ生成:

-
Claude Code が PoC コードを書く様子:

-
Claude Code がレポートを書く様子:

※ プロンプト全文と RAG 知識ベースは悪用防止のため非公開です。
得られた知見
| 気づき | 詳細 |
|---|---|
| エージェントは分業が吉 | モデルあたりのコンテキストをできるだけ小さく |
| 妥当性評価を別モデルに | ハルシネーション検知とフィードバックループが機能 |
| 攻撃者視点で訓練 | 「守る側」よりロジックバグ探索に効く |
| LangChain は“自動化フェーズ”向け | 試行錯誤段階では UI で操作できる Cline がラク |
残る課題
- 攻撃シナリオ網羅性 — さらなる RAG 拡充 & ファインチューニング中
- 複雑環境での PoC — テスト環境が整備されていないと生成に失敗
さいごに
LangChain 開発期を含め 約 1 か月、Cline + Claude Code 切替後は 1 週間 で実バグ発見まで至りました。
今回のセキュリティ特化型AIエージェント開発が上手く行った大きな要因は、我々がセキュリティ専門チームだったことがあります。
チューニングを行う我々自身に攻撃や防御に対する心構えが既にあったおかげでモデルの異変にいち早く気付き、仮説をもって改善に取り組むことができました。
さらなる精度向上に向け、ご意見・アイデアを大募集中です!
セキュリティ診断を依頼したい企業・プロジェクトオーナーの方 も、ぜひお気軽にご連絡ください。
Views: 0

{kind=link}