






MCP初心者だった私ですが、MCPの理解を深めるのも兼ねて、TROCCOのMCPを作りながら遊んでみました。今のMCPがどんなものかの理解も含めてなので備忘録がてらのものも色々書いておきますが、TROCCOのMCPだけが気になる方は前半だけ読んでみてください。
- MCPって何?と思っている人
- TROCCOでMCPを使ってみたい
- 今回のMCPはエンジニアの中根さんの作ったもの(gtnao/troccomcp)を参考に作ったので、そちらも見てみていただけると。
- 私はアプリケーション開発の経験がない&TypeScript初心者なので、怪しいところがあるかもしれません。あったらこっそり教えてくださいw
作成したMCPサーバはこちら。
GitHub Copilot Agentで動くように作っています。使える機能は以下の5つです。
- list_users: ユーザー一覧の取得
- list_pipeline_definitions: ワークフロー一覧の取得
- get_pipeline_definition_detail: ワークフロー詳細の取得
- get_datamart_definition_detail: データマート定義詳細の取得
- update_datamart_definition_description: データマート定義のメモの更新
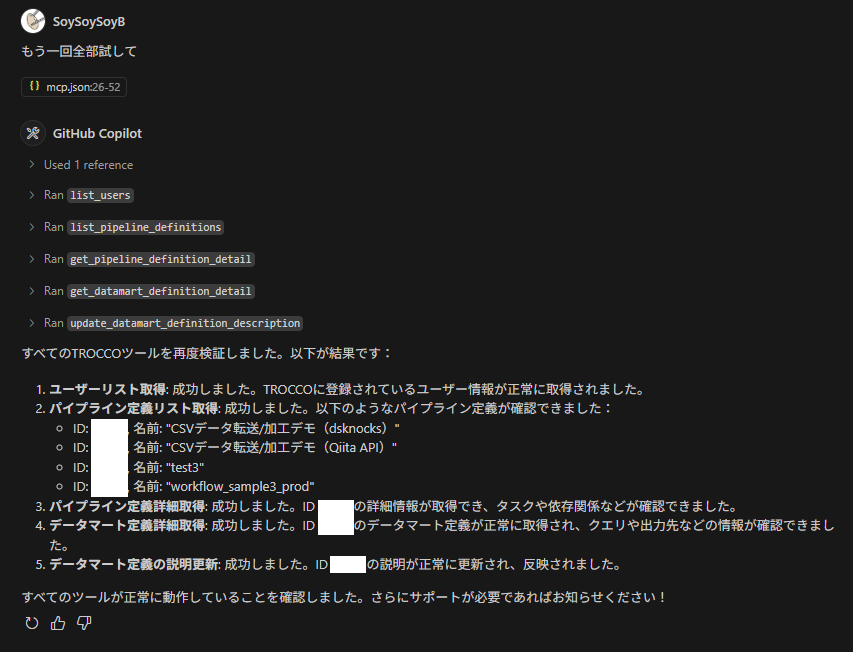
データマート定義の設定内容をもとに、その処理内容の概要をメモに書き込んでくれています。
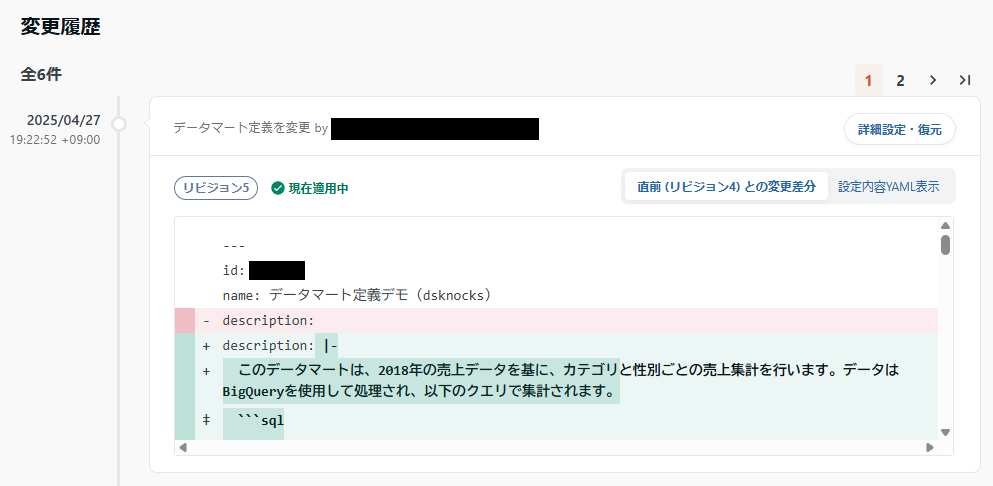
別途SlackのMCPと組み合わせると、最終ログインが古いユーザーを一覧にしてSlackで確認するようメンションしてくれるようなこともできます。
ファイル操作のMCPと組み合わせると、ワークフローでの処理内容を解説するMarkdown形式のドキュメントをまとめてくれたりします。

これはめちゃくちゃ夢が広がりますね!
以下の設定をすると、playwright、filesystem、SlackとTROCCOのMCPが設定できます。
.vscode/mcp.json
{
"inputs": [
{
"type": "promptString",
"id": "slack_bot_token",
"description": "Slack Bot Token",
"password": true
},
{
"type": "promptString",
"id": "trocco_api_key",
"description": "TROCCO API Key",
"password": true
}
],
"servers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest"
]
},
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"${workspaceFolder}"
]
},
"slack": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-slack"
],
"env": {
"SLACK_BOT_TOKEN": "${input:slack_bot_token}"
},
"envFile": "${workspaceFolder}/.env"
},
"trocco": {
"command": "node",
"args": [
"/build/index.js"
],
"env": {
"TROCCO_API_KEY": "${input:trocco_api_key}"
}
}
}
}
詳細は以下のドキュメントを熟読してください。
とりあえず使いたいだけの人は以上です!ここから備忘録がてら書いておきます。
おおもととして公開されているのはGitHubの以下のオーナーのです。ここに各言語のSDKとサーバが公開されています。私の作ったもの(中根さんが作っていたもの)もこのSDKをベースにしているので、サクッと作れるようになっています。
色々なサーバ
serversのリポジトリで公開されているサーバの一覧があります。
リンクとして表示されているものとしては、modelcontextprotocolのオーナーとして公開しているものが20、サービス提供者から公式に公開されているものが112、コミュニティでOSSとして公開されているものが283です。
オーナーとして公開されているものだと、Filesystem、Git、GitHub、Google Drive、Slackあたりが使いやすそうです。公式のものはたくさんありますが、BoxやNotionあたりが使いやすいでしょうか。
なお、playwrightやOneDrive、dbtといったものも掲載されていなかったので、サービス提供者から公開されているものも結構漏れているのではと思います。次々作成されているので、仕方ないですね。
クラウドプラットフォームでは、AWSやAzureがあり、Google CloudはMCP Toolbox for Databasesというものを公開していました。
API経由で連携していくだけあってセキュリティ面は気になるので、なるべくサービス提供者自体が公開しているものを使うようにしましょう。あるいは大したコード量にもならないので、ちゃんとコードを読んでフォークして使うなどした方が良さそう。
MCP Toolbox for Databasesはどうか
サードパーティーのBigQuery MCPがちょっと気になるので、公式のものは使えないだろうかということで気になりました。BigQueryに関するQuickstartが公開されているので見てみます。
以下のようにツールを定義していくらしいです。もう少し探索してくれるようなイメージだったのですが、そうでもない?と思いつつINFORMATION_SCHEMA叩かせるようにすれば使えるのかもしれないですね。
tools.yaml
sources:
my-bigquery-source:
kind: bigquery
project: YOUR_PROJECT_ID
tools:
search-hotels-by-name:
kind: bigquery-sql
source: my-bigquery-source
description: Search for hotels based on name.
parameters:
- name: name
type: string
description: The name of the hotel.
statement: SELECT * FROM `YOUR_DATASET_NAME.hotels` WHERE LOWER(name) LIKE LOWER(CONCAT('%', @name, '%'));
search-hotels-by-location:
kind: bigquery-sql
source: my-bigquery-source
description: Search for hotels based on location.
parameters:
- name: location
type: string
description: The location of the hotel.
statement: SELECT * FROM `YOUR_DATASET_NAME.hotels` WHERE LOWER(location) LIKE LOWER(CONCAT('%', @location, '%'));
book-hotel:
kind: bigquery-sql
source: my-bigquery-source
description: >-
Book a hotel by its ID. If the hotel is successfully booked, returns a NULL, raises an error if not.
parameters:
- name: hotel_id
type: integer
description: The ID of the hotel to book.
statement: UPDATE `YOUR_DATASET_NAME.hotels` SET booked = TRUE WHERE id = @hotel_id;
update-hotel:
kind: bigquery-sql
source: my-bigquery-source
description: >-
Update a hotel's check-in and check-out dates by its ID. Returns a message indicating whether the hotel was successfully updated or not.
parameters:
- name: checkin_date
type: string
description: The new check-in date of the hotel.
- name: checkout_date
type: string
description: The new check-out date of the hotel.
- name: hotel_id
type: integer
description: The ID of the hotel to update.
statement: >-
UPDATE `YOUR_DATASET_NAME.hotels` SET checkin_date = PARSE_DATE('%Y-%m-%d', @checkin_date), checkout_date = PARSE_DATE('%Y-%m-%d', @checkout_date) WHERE id = @hotel_id;
cancel-hotel:
kind: bigquery-sql
source: my-bigquery-source
description: Cancel a hotel by its ID.
parameters:
- name: hotel_id
type: integer
description: The ID of the hotel to cancel.
statement: UPDATE `YOUR_DATASET_NAME.hotels` SET booked = FALSE WHERE id = @hotel_id;
雑感
今回作ってみて大分理解が深まりましたが、エディタのエージェントを通して使う場合は、
- 指定したパッケージを手元に持ってくる(npm / pip etc.)/ローカルのソースコードを指定する
- ソースコードを実行して、サーバとして機能させる
- サーバ側で実行できるものはツールとして一覧化されている
- エージェントは手元で動いているサーバの特定のツールに指定された形式でリクエストを送る
- エージェントのリクエストに応じて事前に定義された形でAPIに処理を連携する
みたいな感じです。以前の記事(Snowflake Data for BreakfastのSlack – Cortex Agents連携を試してみる)であったSlackのSocket Modeと似たような感じだと思いました。
エージェント側で指示内容の遂行やレスポンスの解釈ができるから夢のような機能になっているわけですが、中身としてはただのAPIのラッパーにすぎないよね、という印象です。
あとはその結果をどうファイルレベルで永続化させるか、文脈情報を適切に持たせて最適化するか、権限をどう整理していくか(gitコマンドは使わせない/そもそもDockerに閉じ込めてしまうなど)みたいなところが勘所なのだと体感としても理解しました。
Windows環境でやると、C:...ではなくc:...とやってファイルが見つかりませんとか言ってくるのはどうにかしてほしい。
ということで、雑にMCPについてまとめてみました。JavaScript(Google Apps Script)とPythonしか使ったことがなかったので、TypeScriptの使い方の勉強にもなり大変有意義な経験でした。
TROCCOでも色々活用の余地がありそうなので、引き続き上手く使って(できれば提供して)いければと思います!




{kind=link}