
0. はじめに
Rethはその名のとおりRustで実装されたEthereumのExecution Clientである。
プロジェクトをリードするParadigm が宣言している通りいくつか特徴があるが、競合となるGethと比較した時に強調できるのは以下の3点である。
- Modularity
- Performance
- Client Diversity
1と2は密接に関係しているだけでなく、3の課題解決に繋がっていると言っても過言ではない。
この記事はGethのアーキテクチャと比較しながら主にModularityとPerformanceについて深掘り、最後の章でこれらがいかにClient Diversityに繋がるかを解説する
本稿はReth読むスレをこれら3点に注目して編集したものである。
1. Modularity
まずModularityについて解説する。
Rethの主要な機能はCrateによってコンポーネント化されており、独立したライブラリと使用できる。これによって例えば #P2P のスタンドアロンネットワークを立ち上げたり、ノードのデータベースに直接接続したりできる。
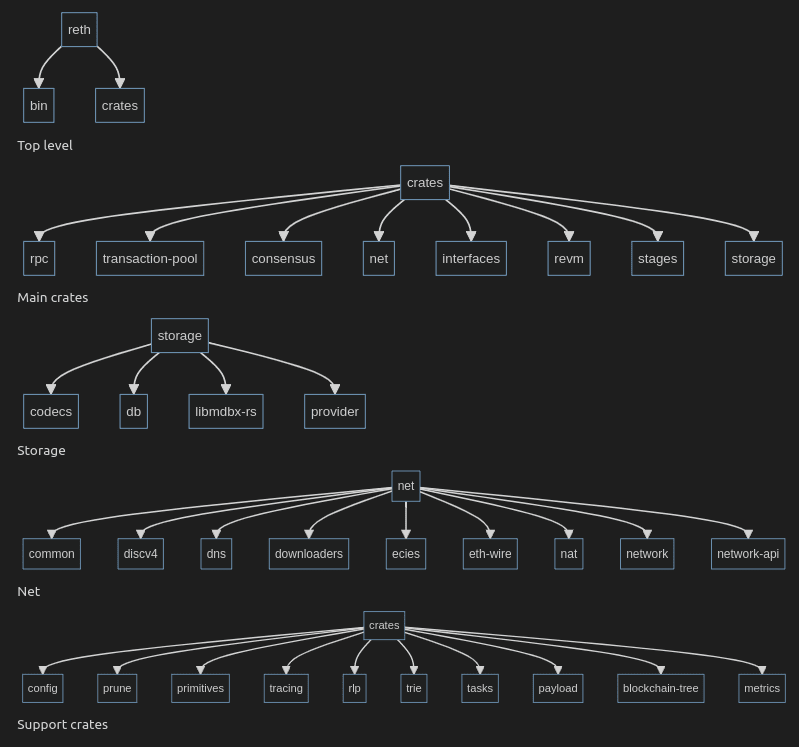
特に #Geth との大きな違いはstages cratesに実装されているstaged syncにある。このシステムはPerformance向上のコアとなる。
2. Performance
以下の表は、RethとGethの同期速度とストレージフットプリントに関する主要なデータポイントをDeep Researchを元にまとめたもの
| クライアント | 初期同期時間(メインネットフルノード) | 初期同期時間(メインネットアーカイブノード) | 週次DB成長率(アーカイブノード) |
|---|---|---|---|
| Reth | 約50時間 | 約50~53時間 | 約50 GB/週 |
| Geth | 1ヶ月以上 | 1ヶ月以上 / 約15時間(スナップショット同期) | 約560 GB/週 |
なんでDB成長率が違うんだ?
ソースはこちら
両者の推奨スペックはこのとおり
| 項目 | Geth(Full Node) | Geth(Archive Node) | Reth(Full Node) | Reth(Archive Node) |
|---|---|---|---|---|
| Disk | 最低 1〜2TB SSD(NVMe推奨) | 最低 4TB SSD(高耐久、NVMe推奨) | 最低 1.8TB(TLC NVMe 推奨) | 最低 2.8TB(TLC NVMe 推奨) |
| Memory | 16GB~ | 32GB~ | 8GB~ | 16GB~ |
| CPU | 4コア以上(推奨 6〜8コア) | 8コア以上(並列化処理向け) | コア数よりクロック重視 | コア数よりクロック重視 |
| Bandwidth | 25Mbps+ | 同上 | 24Mbps+ |
こっからは特徴のひとつである同期時のパフォーマンスに注目して解説する
Staged sync
Rethの二つ目の特徴であるPerformanceに大きく寄与するのがこのStaged syncだ。
この設計は以下の Erigon のアーキテクチャを踏襲したものである。
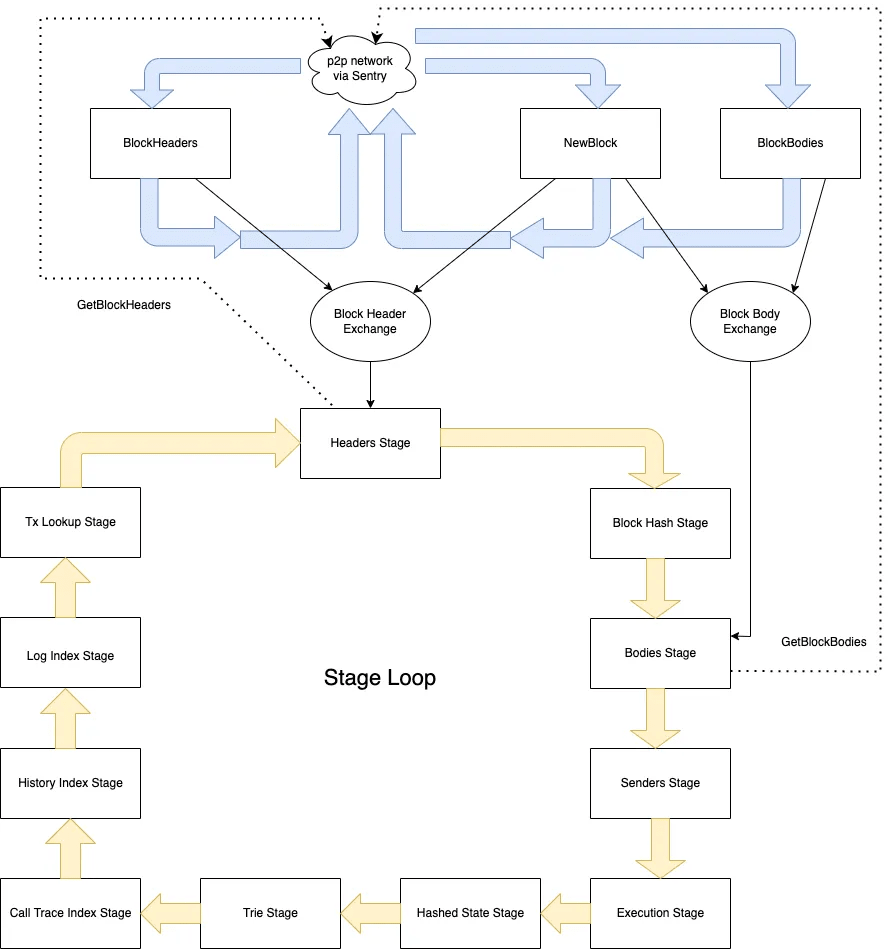
このstaged sync自体もModularityを体現していると言える。
各ステージはノードの同期プロセスをセグメント化したものである。
各ステージはヘッダーのダウンロードやトランザクションの実行などが明確に定義された1つのタスクを担当し、その結果をデータベースに永続化する。必要な変更に応じて前方や後方ステージにロールバックする。
ここでGethのFull Syncとに対して以下のように比較してみよう。
| 特徴 | Geth (Full Sync) | Reth (Staged Sync) |
|---|---|---|
| 同期方法 | 最初のブロックから最新ブロックまで順に取得し、ブロックのトランザクションを順に実行しながらステートを構築する(逐次同期) | 各段階ごとに同期し、効率的にデータベースを構築する(バッチ同期) |
| データ構造 | 逐次的にブロックを処理し、ブロックごとにステートの更新を行う | 各データを並列で取得し、段階ごとに処理を完了していく |
| 同期速度 | 比較的遅い。最新のブロックに追いつくまでに時間がかかる。 | 高速。非同期で各段階のデータを取得・処理するため、データベースのビルドが迅速 |
| データサイズ | ステートデータを順次保存するため、データベースの肥大化が早い | 各段階で不要なデータを破棄可能なため、データベースサイズを最適化しやすい |
| 再同期 | 再同期が発生した場合、再度ブロックを順次取得・検証する必要がある | 各段階ごとに分割されているため、一部の段階だけ再同期することが可能 |
このように同期時間やリソース効率の観点からStaged syncはFull Syncよりも効率的と言える。(Snap SyncやFast Syncと比較してどのくらい効率的なのか知りたい)
開発者としては各ステージを独立して開発・テストできるので保守性が高いなと思った。
また、各ステージを個別に最適化することでディスクI/Oやメモリの効率も上がりそうだ
また、各ステージの完了時に進捗がチェックポイントとして保存されるため、同期中にクライアントがクラッシュしたり、Reorgが発生したりしても最初からやり直すことなく、最後の完了したステージから再開できる。
要約するとstaged syncによってGethに比べて以下のような優位性を発揮している
- 同期速度
- ストレージ効率
- RPCスループット
- メンテナンス性
staged syncでは以下のようなフローで各stageが進行していく。これをパイプラインと呼ぶ。
Rethのパイプラインは11のstageからなる。これらは以下のように3つのフェーズに大別できる。(各フェーズは筆者が勝手に呼んでいるもの)
ダウンロードフェーズ
- Header Stage
- Body Stage
実行フェーズ
- Sender Recovery Stage
- Execution Stage
- Account Hashing Stage
- Storage Hashing Stage
- Merkle Execute Stage
インデックスフェーズ
- Transaction Lookup Stage
- Index Storage History Stage
- Index Account History Stage
- Finish Stage
インデックスフェーズは同期や実行に直接関係ないが、クライアントの利便性やRPCの高速化の観点から重要な機能を提供する。Rethの固有の機能であるExecution Extensionはここで作成したインデックスを流用していると思われる。
全てのステージについて簡易的なスニペットを交えて順番に概説する。
crates/stages/stages/src/stages/headers.rs
まずブロックヘッダーを同期するステージ
ブロックヘッダーをダウンロードし、その整合性を検証したのちデータベースに書き込む
fn execute(&mut self, provider: &Provider, input: ExecInput) -> ResultExecOutput, StageError> {
let current_checkpoint = input.checkpoint();
if self.sync_gap.as_ref().ok_or(StageError::MissingSyncGap)?.is_closed() {
self.is_etl_ready = false;
return Ok(ExecOutput::done(current_checkpoint))
}
if !self.is_etl_ready {
return Err(StageError::MissingDownloadBuffer)
}
self.is_etl_ready = false;
let to_be_processed = self.hash_collector.len() as u64;
let last_header_number = self.write_headers(provider)?;
self.hash_collector.clear();
self.header_collector.clear();
Ok(ExecOutput {
checkpoint: StageCheckpoint::new(last_header_number).with_headers_stage_checkpoint(
HeadersCheckpoint {
block_range: CheckpointBlockRange {
from: input.checkpoint().block_number,
to: last_header_number,
},
progress: EntitiesCheckpoint {
processed: input.checkpoint().block_number + to_be_processed,
total: last_header_number,
},
},
),
done: true,
})
}
まず引数のproviderはデータベースへのアクセスを提供するハンドラだ
| 引数 | 役割 |
|---|---|
| provider | DBへの書き込みを抽象化したハンドラ |
| input | パイプラインから渡される現在のステージチェックポイント |
checkpoint はパイプラインにおける進捗を同期したり、それらの情報を次のstageに引き継ぐために使われる。各ステージの最初と最後でチェックポイントの取得と更新が行われる。
let current_checkpoint = input.checkpoint();
...省略
Ok(ExecOutput {
checkpoint: StageCheckpoint::new(last_header_number).with_headers_stage_checkpoint(
HeadersCheckpoint {
block_range: CheckpointBlockRange {
from: input.checkpoint().block_number,
to: last_header_number,
},
progress: EntitiesCheckpoint {
processed: input.checkpoint().block_number + to_be_processed,
total: last_header_number,
},
},
),
まずDBに書き込む前に同期する必要があるかチェックする。その必要がなければスキップする。また、ETLが準備できていなければエラーを返す
if self.sync_gap.as_ref().ok_or(StageError::MissingSyncGap)?.is_closed() {
self.is_etl_ready = false;
return Ok(ExecOutput::done(current_checkpoint))
}
if !self.is_etl_ready {
return Err(StageError::MissingDownloadBuffer)
}
ここでETL (Extract, Transform, Load)とはデータエンジニアリングやDBシステムの用語であり以下のような処理を指す。ETL処理はバッチ処理と相性が良く、大量データを効率的に処理するパイプライン構成でよく用いられる。
| フェーズ | 処理の例 |
|---|---|
| E (Extract) | ヘッダーやトランザクションなどをネットワークから取得 |
| T (Transform) | 番号順にソート/必要な形式に変換 |
| L (Load) | ソート済みデータを高速にDB(MDBXなど)へ書き込み |
省略したがexecuteの前でpoll_execute_ready()というメソッドが呼ばれており、ここではネットワークからヘッダを逆順にダウンロードし、昇順にソートしている。(逆順なのはヘッダが親と繋がって途切れにくいから?)
use reth_etl::Collector;
self.hash_collector.insert(block_number, hash);
self.header_collector.insert(block_number, header);
ソートされたデータはディスクに一時的に保管される(バッファリング)
つまりこのメソッドはExtractとTransform担当している。
そして次にexecute()でディスク上のETLバッファからMDBX DBへ書き込む(Load)という二段構えになっている。
let last_header_number = self.write_headers(provider)?;
self.hash_collector.clear();
self.header_collector.clear();
このようにしてヘッダを取得→ソート→バッチ挿入というETL処理が行われる。
この構成によりダウンロードとDB書き込みを疎結合させ、「ある程度たまってから一括書き込み」というバファリング戦略を取ることでランダムI/Oが減り、効率化される。
RethではHeadersだけでなくTransactions,Receipts,LogsなどでもETLを活用している。
2. Body Stage
crates/stages/stages/src/stages/bodies.rsHeaderStageの完了後、BodyStage が開始される。
- 新しいブロックヘッダーに対応するブロックボディをダウンロード
fn execute(&mut self, provider: &Provider, input: ExecInput) -> ResultExecOutput, StageError> {
if input.target_reached() {
return Ok(ExecOutput::done(input.checkpoint()))
}
let (from_block, to_block) = input.next_block_range().into_inner();
self.ensure_consistency(provider, None)?;
let buffer = self.buffer.take().ok_or(StageError::MissingDownloadBuffer)?;
let highest_block = buffer.last().map(|r| r.block_number()).unwrap_or(from_block);
provider.append_block_bodies(
buffer
.into_iter()
.map(|response| (response.block_number(), response.into_body()))
.collect(),
StorageLocation::StaticFiles,
)?;
let done = highest_block == to_block;
Ok(ExecOutput {
checkpoint: StageCheckpoint::new(highest_block)
.with_entities_stage_checkpoint(stage_checkpoint(provider)?),
done,
})
}
ブロックボディはstarting_block から target_block まで順次ダウンロードされる
各ブロックボディは事前検証を行い、問題がなければデータベースに保存される。
if input.target_reached() {
return Ok(ExecOutput::done(input.checkpoint()))
}
let (from_block, to_block) = input.next_block_range().into_inner();
self.ensure_consistency(provider, None)?;
...
provider.append_block_bodies(
buffer
.into_iter()
.map(|response| (response.block_number(), response.into_body()))
.collect(),
StorageLocation::StaticFiles,
)?;
DBに保存していたヘッダーと違い、ブロックボディはStaticFilesに保存される。
そこでensure_consistency における事前検証ではDBとStaticFilesの同期状態を保証する。もし差異があればステージの進行を取り消して、データベースや静的ファイルを過去の整合した状態に戻す。
このようなステージ進行を中断し、そのステージの状態だけを巻き戻す操作は各ステージに用意されており、unwind メソッドとして定義されている。これによりreorgや今回のようなデータの不整合、ステージ進行中のクラッシュに対応できるようになっている。
ここまでがダウンロードフェーズ。次に実行フェーズについて解説する。
3. SenderRecoveryStage
crates/stages/stages/src/stages/sender_recovery.rs
このステージではトランザクションの送信者(署名者)情報を復元する
- ECDSA署名から送信者アドレスを復元
- 復元した送信者情報をデータベースに保存
fn execute(&mut self, provider: &Provider, input: ExecInput) -> ResultExecOutput, StageError> {
..省略
let batch = tx_range
.clone()
.step_by(BATCH_SIZE)
.map(|start| start..std::cmp::min(start + BATCH_SIZE as u64, tx_range.end))
.collect::VecRangeu64>>>();
let tx_batch_sender = setup_range_recovery(provider);
for range in batch {
recover_range(range, provider, tx_batch_sender.clone(), &mut senders_cursor)?;
}
Ok(ExecOutput {
checkpoint: StageCheckpoint::new(end_block)
.with_entities_stage_checkpoint(stage_checkpoint(provider)?),
done: is_final_range,
})
}
対象となるトランザクションをBATH_SIZE(1024)ずつに分割してバッチ処理される
let batch = tx_range
.clone()
.step_by(BATCH_SIZE)
.map(|start| start..std::cmp::min(start + BATCH_SIZE as u64, tx_range.end))
.collect::VecRangeu64>>>();
バッチごとにrecover_rangeを実行する。
for range in batch {
recover_range(range, provider, tx_batch_sender.clone(), &mut senders_cursor)?;
}
このrecover_range()は、トランザクションの署名から送信者(sender)アドレスを復元し、TransactionSenders テーブルに格納する処理を行う。このバッチ処理はRayonで並列化していた。
送信者アドレスの復元は以下の2step
- トランザクションの(v,r,s)public_keyを復元
- keccak256(public_key)を取って20バイトのAddressに変換
この結果は次のExecution stageで使う
4. ExecutionStage
crates/stages/stages/src/stages/execution.rs
お待ちかね。トランザクションを実行しステートを更新する
- トランザクションの実行
- アカウントバランスやステートの更新
- 実行結果をデータベースに反映
fn execute(&mut self, provider: &Provider, input: ExecInput) -> ResultExecOutput, StageError> {
...省略
let block = provider
.recovered_block(block_number.into(), TransactionVariant::NoHash)?
.ok_or_else(|| ProviderError::HeaderNotFound(block_number.into()))?;
fetch_block_duration += fetch_block_start.elapsed();
cumulative_gas += block.header().gas_used();
...省略
let result = self.metrics.metered_one(&block, |input| {
executor.execute_one(input).map_err(|error| StageError::Block {
block: Box::new(block.block_with_parent()),
error: BlockErrorKind::Execution(error),
})
})?;
if let Err(err) = self.consensus.validate_block_post_execution(&block, &result) {
return Err(StageError::Block {
block: Box::new(block.block_with_parent()),
error: BlockErrorKind::Validation(err),
})
}
results.push(result);
...(省略)
let done = stage_progress == max_block;
Ok(ExecOutput {
checkpoint: StageCheckpoint::new(stage_progress)
.with_execution_stage_checkpoint(stage_checkpoint),
done,
})
}
まず{Header,Body,Senders}からなる構造体を受け取る
let block = provider
.recovered_block(block_number.into(), TransactionVariant::NoHash)?
.ok_or_else(|| ProviderError::HeaderNotFound(block_number.into()))?;
そしてEVM上でTxを実行する。
let result = self.metrics.metered_one(&block, |input| {
executor.execute_one(input).map_err(...)
})?;
次にgas_usedやstate_rootなどがblock headerと一致するか検証する。
if let Err(err) = self.consensus.validate_block_post_execution(&block, &result) {
return Err(StageError::Block {
block: Box::new(block.block_with_parent()),
error: BlockErrorKind::Validation(err),
})
}
results.push(result);
EVMでの処理は、EVM crateについて解説したこちらを参照してほしい。
RethではREVMを使っているが、こちらの詳しい実装は確認できていない。zkELと関連付けて確認しておきたい。
5. AccountHashingStage
crates/stages/stages/src/stages/hashing_account.rs
アカウントのハッシュを計算する。これによりステートツリーの構築(7. MerkleExecuteStage)に必要なアカウントデータのハッシュが生成される。Ethereumのステートは Merkle Patricia Trie に格納されており、この木のキーが「ハッシュ化されたアドレス」で構成される。
fn execute(&mut self, provider: &Provider, input: ExecInput) -> ResultExecOutput, StageError> {
..省略
for chunk in &accounts_cursor.walk(None)?.chunks(WORKER_CHUNK_SIZE) {
let (tx, rx) = mpsc::channel();
channels.push(rx);
let chunk = chunk.collect::ResultVec_>, _>>()?;
rayon::spawn(move || {
for (address, account) in chunk {
let address = address.key().unwrap();
let _ = tx.send((RawKey::new(keccak256(address)), account));
}
});
if !channels.is_empty() && channels.len() % MAXIMUM_CHANNELS == 0 {
collect(&mut channels, &mut collector)?;
}
}
collect(&mut channels, &mut collector)?;
let mut hashed_account_cursor =
tx.cursor_write::RawTabletables::HashedAccounts>>()?;
let total_hashes = collector.len();
let interval = (total_hashes / 10).max(1);
for (index, item) in collector.iter()?.enumerate() {
if index > 0 && index % interval == 0 {
info!(
target: "sync::stages::hashing_account",
progress = %format!("{:.2}%", (index as f64 / total_hashes as f64) * 100.0),
"Inserting hashes"
);
}
let (key, value) = item?;
hashed_account_cursor
.append(RawKey::B256>::from_vec(key), &RawValue::Account>::from_vec(value))?;
}
} else {
let lists = provider.changed_accounts_with_range(from_block..=to_block)?;
let accounts = provider.basic_accounts(lists)?;
provider.insert_account_for_hashing(accounts)?;
}
..省略
Ok(ExecOutput { checkpoint, done: true })
}
アドレスをkeccakでハッシュしETL collectorに集める。
hashingは並列化されているのがわかる。
for chunk in &accounts_cursor.walk(None)?.chunks(WORKER_CHUNK_SIZE) {
let (tx, rx) = mpsc::channel();
channels.push(rx);
let chunk = chunk.collect::ResultVec_>, _>>()?;
rayon::spawn(move || {
for (address, account) in chunk {
let address = address.key().unwrap();
let _ = tx.send((RawKey::new(keccak256(address)), account));
}
});
そして変更があったアカウントのみ更新する
let lists = provider.changed_accounts_with_range(from_block..=to_block)?;
let accounts = provider.basic_accounts(lists)?;
provider.insert_account_for_hashing(accounts)?;
6. StorageHashingStage
crates/stages/stages/src/stages/hashing_storage.rs
スマートコントラクトのストレージスロットに対してハッシュを計算する。
基本プロセスはAccountHashingStageと同じ
fn execute(&mut self, provider: &Provider, input: ExecInput) -> ResultExecOutput, StageError> {
...省略
for chunk in &storage_cursor.walk(None)?.chunks(WORKER_CHUNK_SIZE) {
let (tx, rx) = mpsc::channel();
channels.push(rx);
let chunk = chunk.collect::ResultVec_>, _>>()?;
rayon::spawn(move || {
for (address, slot) in chunk {
let mut addr_key = Vec::with_capacity(64);
addr_key.put_slice(keccak256(address).as_slice());
addr_key.put_slice(keccak256(slot.key).as_slice());
let _ = tx.send((addr_key, CompactU256::from(slot.value)));
}
});
if !channels.is_empty() && channels.len() % MAXIMUM_CHANNELS == 0 {
collect(&mut channels, &mut collector)?;
}
}
collect(&mut channels, &mut collector)?;
let total_hashes = collector.len();
let interval = (total_hashes / 10).max(1);
let mut cursor = tx.cursor_dup_write::tables::HashedStorages>()?;
for (index, item) in collector.iter()?.enumerate() {
if index > 0 && index % interval == 0 {
info!(
target: "sync::stages::hashing_storage",
progress = %format!("{:.2}%", (index as f64 / total_hashes as f64) * 100.0),
"Inserting hashes"
);
}
let (addr_key, value) = item?;
cursor.append_dup(
B256::from_slice(&addr_key[..32]),
StorageEntry {
key: B256::from_slice(&addr_key[32..]),
value: CompactU256::decompress_owned(value)?.into(),
},
)?;
}
} else {
let lists = provider.changed_storages_with_range(from_block..=to_block)?;
let storages = provider.plain_state_storages(lists)?;
provider.insert_storage_for_hashing(storages)?;
}
...省略
Ok(ExecOutput { checkpoint, done: true })
}
アドレスとスロットキーをkeccak256ハッシュしている。
for chunk in &storage_cursor.walk(None)?.chunks(WORKER_CHUNK_SIZE) {
rayon::spawn(move || {
for (address, slot) in chunk {
addr_key = keccak256(address) || keccak256(slot.key);
send(addr_key, slot.value);
}
});
}
7. MerkleExecuteStage
crates/stages/stages/src/stages/merkle.rs
AccountHashingStageおよびStorageHashingStageの結果を元にMerkle Patricia Trieの構築を行い、state rootを更新する。
ここで実行フェーズの中核に当たるstage6~8を整理しよう。私の理解だと各stageとその処理内容は以下のように対応している。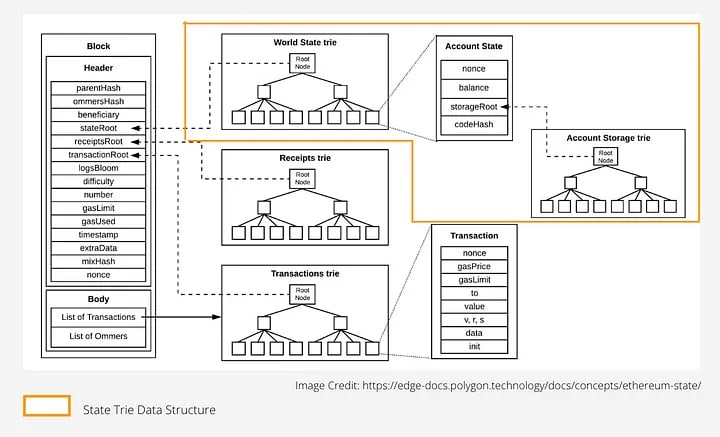
| ステージ名 | 内容 |
|---|---|
| AccountHashingStage | World State Trie のノードのキー構築(keccak256(address)) |
| StorageHashingStage | Account Storage Trie のノードのキー構築(keccak256(address,slot)) |
| MerkleExecuteStage | state rootの更新 |
具体的なプログラムについてだが、通常は前のstateの差分に対してのみstate treeを構築(差分更新モード)しているが、5000ブロックごとに全体を再構築(全構築モード)していることがわかった。
pub const MERKLE_STAGE_DEFAULT_CLEAN_THRESHOLD: u64 = 5_000;
このステージはかなり長いのでここでは前者についてのみ解説する。以下のexecuteメソッドのスニペットはそのために編集・省略したものなので注意してほしい。
fn execute(&mut self, provider: &Provider, input: ExecInput) -> ResultExecOutput, StageError> {
if input.target_reached() {
return Ok(ExecOutput::done(input.checkpoint()));
}
let range = input.next_block_range();
let (from_block, to_block) = range.clone().into_inner();
let current_block_number = input.checkpoint().block_number;
let target_block = provider
.header_by_number(to_block)?
.ok_or_else(|| ProviderError::HeaderNotFound(to_block.into()))?;
let target_block_root = target_block.state_root();
if to_block - from_block threshold && from_block != 1 {
debug!(target: "sync::stages::merkle::exec", current = ?current_block_number, target = ?to_block, "Updating trie");
let (root, updates) = StateRoot::incremental_root_with_updates(provider.tx_ref(), range)
.map_err(|e| {
error!(target: "sync::stages::merkle", %e, ?current_block_number, ?to_block, "Incremental state root failed!");
StageError::Fatal(Box::new(e))
})?;
provider.write_trie_updates(&updates)?;
let total_hashed_entries = (provider.count_entries::tables::HashedAccounts>()?
+ provider.count_entries::tables::HashedStorages>()?) as u64;
}
staterootを更新し、更新されたノードをDBに反映させる。
let (root, updates) = StateRoot::incremental_root_with_updates(provider.tx_ref(), range)
.map_err(|e| {
error!(target: "sync::stages::merkle", %e, ?current_block_number, ?to_block, "Incremental state root failed!");
StageError::Fatal(Box::new(e))
})?;
provider.write_trie_updates(&updates)?;
上記のスニペットでは省略したが計算されたルートが期待値と一致するか検証し、不一致の場合はエラーを返す部分も存在する。
fn validate_state_rootH: BlockHeader + Sealable + Debug>(
got: B256,
expected: SealedHeaderH>,
target_block: BlockNumber,
) -> Result(), StageError>
同様に状態ツリー構築の進捗を保存し中断時の再開を可能にする機能も存在した
fn get_execution_checkpoint(&self, provider: &impl StageCheckpointReader) -> ResultOptionMerkleCheckpoint>, StageError>
fn save_execution_checkpoint(&self, provider: &impl StageCheckpointWriter, checkpoint: OptionMerkleCheckpoint>) -> Result(), StageError>
8. TransactionLookupStage
crates/stages/stages/src/stages/tx_lookup.rs
ここからはインデックスフェーズについて解説する。RethのDBレイアウトはこのようになっているので適宜参照してほしい。
まずトランザクションのインデックスを作成し効率的な検索を可能にする。これによりトランザクションのハッシュやブロック位置でのクエリが高速化される。
fn execute(
&mut self,
provider: &Provider,
mut input: ExecInput,
) -> ResultExecOutput, StageError> {
...省略
let mut hash_collector: CollectorTxHash, TxNumber> =
Collector::new(self.etl_config.file_size, self.etl_config.dir.clone());
loop {
let (tx_range, block_range, is_final_range) =
input.next_block_range_with_transaction_threshold(provider, self.chunk_size)?;
let end_block = *block_range.end();
for (key, value) in provider.transaction_hashes_by_range(tx_range)? {
hash_collector.insert(key, value)?;
}
input.checkpoint = Some(
StageCheckpoint::new(end_block)
.with_entities_stage_checkpoint(stage_checkpoint(provider)?),
);
if is_final_range {
let append_only =
provider.count_entries::tables::TransactionHashNumbers>()?.is_zero();
let mut txhash_cursor = provider
.tx_ref()
.cursor_write::tables::RawTabletables::TransactionHashNumbers>>()?;
let total_hashes = hash_collector.len();
let interval = (total_hashes / 10).max(1);
for (index, hash_to_number) in hash_collector.iter()?.enumerate() {
let (hash, number) = hash_to_number?;
if index > 0 && index % interval == 0 {
info!(
target: "sync::stages::transaction_lookup",
?append_only,
progress = %format!("{:.2}%", (index as f64 / total_hashes as f64) * 100.0),
"Inserting hashes"
);
}
let key = RawKey::TxHash>::from_vec(hash);
if append_only {
txhash_cursor.append(key, &RawValue::TxNumber>::from_vec(number))?
} else {
txhash_cursor.insert(key, &RawValue::TxNumber>::from_vec(number))?
}
}
trace!(target: "sync::stages::transaction_lookup",
total_hashes,
"Transaction hashes inserted"
);
break;
}
}
Ok(ExecOutput {
checkpoint: StageCheckpoint::new(input.target())
.with_entities_stage_checkpoint(stage_checkpoint(provider)?),
done: true,
})
}
指定範囲の(Tx hash,Tx Number)を取得する。
for (key, value) in provider.transaction_hashes_by_range(tx_range)? {
hash_collector.insert(key, value)?;
}
TransactionHashNumbersテーブルにTxHash-Tx Numberを保存する
let append_only = provider.count_entries::tables::TransactionHashNumbers>()?.is_zero();
...
for (index, hash_to_number) in hash_collector.iter()?.enumerate() {
...
if append_only {
txhash_cursor.append(key, &value)?;
} else {
txhash_cursor.insert(key, &value)?;
}
}
10. IndexStorageHistoryStage
crates/stages/stages/src/stages/index_storage_history.rs
コントラクトストレージの履歴を追跡するインデックスを作成する。これにより、過去のステートをクエリできるようになる。
fn execute(
&mut self,
provider: &Provider,
mut input: ExecInput,
) -> ResultExecOutput, StageError> {
...
info!(target: "sync::stages::index_storage_history::exec", ?first_sync, "Collecting indices");
let collector =
collect_history_indices::_, tables::StorageChangeSets, tables::StoragesHistory, _>(
provider,
BlockNumberAddress::range(range.clone()),
|AddressStorageKey((address, storage_key)), highest_block_number| {
StorageShardedKey::new(address, storage_key, highest_block_number)
},
|(key, value)| (key.block_number(), AddressStorageKey((key.address(), value.key))),
&self.etl_config,
)?;
info!(target: "sync::stages::index_storage_history::exec", "Loading indices into database");
load_history_indices::_, tables::StoragesHistory, _>(
provider,
collector,
first_sync,
|AddressStorageKey((address, storage_key)), highest_block_number| {
StorageShardedKey::new(address, storage_key, highest_block_number)
},
StorageShardedKey::decode_owned,
|key| AddressStorageKey((key.address, key.sharded_key.key)),
)?;
Ok(ExecOutput { checkpoint: StageCheckpoint::new(*range.end()), done: true })
}
対象範囲において(address, slot)ごとにどのブロックで変更されたかを集計する。結果はETL Collectorに保存する。
let collector = collect_history_indices::...>(
provider,
BlockNumberAddress::range(range.clone()),
...
)?;
収集した (address, slot) → Vec
load_history_indices::_, tables::StoragesHistory, _>(
provider,
collector,
first_sync,
...
)?;
ここでは詳細に触れないがAccountsHistoryとStorageHistoryではインデックスをブロック範囲で分割して保存するためのシャーディング戦略が取られていた。
11. IndexAccountHistoryStage
crates/stages/stages/src/stages/index_account_history.rs
アカウントの履歴を記録するインデックスを作成する。アカウントの残高、ノンス、コードなどの変化を追跡する
fn execute(
&mut self,
provider: &Provider,
mut input: ExecInput,
) -> ResultExecOutput, StageError> {
...
info!(target: "sync::stages::index_account_history::exec", ?first_sync, "Collecting indices");
let collector =
collect_history_indices::_, tables::AccountChangeSets, tables::AccountsHistory, _>(
provider,
range.clone(),
ShardedKey::new,
|(index, value)| (index, value.address),
&self.etl_config,
)?;
info!(target: "sync::stages::index_account_history::exec", "Loading indices into database");
load_history_indices::_, tables::AccountsHistory, _>(
provider,
collector,
first_sync,
ShardedKey::new,
ShardedKey::Address>::decode_owned,
|key| key.key,
)?;
Ok(ExecOutput { checkpoint: StageCheckpoint::new(*range.end()), done: true })
}
IndexStorageHistoryStageと同様の手法でaddress → Vec
ステージ9~11をまとめると以下のようになる。
| ステージ名 | Key | Value | Table |
|---|---|---|---|
| TransactionLookupStage | TxHash | TxNumber | TransactionHashNumbers |
| IndexStorageHistoryStage | (address, slot) | block_numbers | StoragesHistory |
| IndexAccountHistoryStage | address | block_numbers | AccountsHistory |
11. FinishStage
crates/stages/stages/src/stages/finish.rs
最後のステージではすべての処理が正しく完了したことを検証する。このステージが完了すると、ノードの状態がチェーンの最新状態と同期される。
fn execute(
&mut self,
_provider: &Provider,
input: ExecInput,
) -> ResultExecOutput, StageError> {
Ok(ExecOutput { checkpoint: StageCheckpoint::new(input.target()), done: true })
}
この章ではStaged Syncを構成する12のstageからなるパイプラインについて解説した
stateの更新だけでなくインデックスを形成したり、UnwindしたりとデータベースのI/Oが頻発しておりパフォーマンスの観点ではここにボトルネックがありそうだ。
次の章ではRethが採用している組み込み型 #Key-value-store である #libmbdx について見ていく
libmdbx
前提として #Geth や #Bitcoin-Core では #key-value-store として #Level-DB が使われている。LevelDBはGoogleが開発したオープンソースのKVSライブラリであり、Gethはブロックヘッダー、トランザクション、レシート、ステートデータなど、ブロックチェーンの様々なデータをLevelDBに保存している。近年ではLevelDBに代わる、より新しい高性能なKey-Valueストアとして #Pabble なるものが評価されているらしい。
一方でRethではlibmdbxというマイナーな組み込み型KVSを使っている。
libmdxの起源は2015年に遡り、広く利用されているLightning Memory-Mapped Database (LMDB) からのフォークとして開発された。軽量でありながら高性能であるという特徴がある。LMDB自体は #Nostr などの分散アプリケーションでも使われているようだが、libmdbxを採用している著名なサービスはあまり見当たらなかった。 #Flutter 向けのNoSQLデータベースである #Isar で使われてるらしい
基本設計
#libmdx はハイパフォーマンスな組み込み型KVSであるLMDBを踏襲しつつ、並行処理の最適化と堅牢性を高めている。以下の基本設計についてはLMDBから受け継いだものだ。
| 項目 | 概要 |
|---|---|
| Memory map | ファイルをメモリ空間に直接マップして高速にアクセスする方式 |
| MVCC (Multi-version Concurrency Controll) | 読み取りと書き込みが衝突しないようにバージョンを分離して管理する方式 |
| Copy on Write | 変更時に元データを複製してから書き込みを行う方式(不変性の維持) |
| Append Only B+tree | ノードの更新をせず、新しいノードを末尾に追記することでB+木を構築・維持する方式 |
| No WAL(Write-Ahead Logging) | 書き込み前のログを取らずに、データ構造そのものに直接整合性を持たせる設計 |
libmdxを理解することはLMDBを理解することと心得たのでLMDBについての詳細はこちらに譲る。ここから先はlibmdxの特徴をLLMで要約させたものを列挙する。
データ整合性
- MVCCとCoWを通じてACIDを保証
- WALなしでもシステムクラッシュ後のデータ整合性を保証する(クラッシュからのデータ整合性保証)
- LMDBで発見された多くのバグを修正し、macOSやWindowsそれぞれに応じた耐久性保証を提供
メモリ管理
- 独自の内部キャッシュを持たず、OSのページキャッシュと仮想メモリ管理機能を最大限に活用
- データベースファイルサイズを動的に調整し、コミット時にフリーページの結合と未使用領域の切り詰め(コンパクティフィケーション)を継続的に行う
- LIFOガベージコレクションポリシーにより、古くなったページを効率的に再利用し、長時間トランザクションによるページ枯渇問題を管理する
I/O
- Memory mapped I/OとB+ツリーにより、検索・挿入・更新・削除がO(log N)
- Readは待機不要で並行アクセス可能、Writeは単一ミューテックスで厳密に直列化され、高いスループットを実現
- WALを使用しないため、書き込み時のログオーバーヘッドが少なく、LIFO(Last-In, First-Out)ガベージコレクションがディスクキャッシュ効率を高める
他にも自動でデータベースのサイズを調整する機能や不要なスペースを削減する機能が追加されている。
Ethereumクライアントのような極めて高いパフォーマンスと信頼性が求められる環境で広く採用されている理由が理解できた。ちなみに #MithrilDB という次期バージョンも現在開発中らしい。
Level DBとLMDBの比較
Gethで使われるLevel DBとRethのlibmdxについてアーキテクチャやパフォーマンスを比較した。
| 機能 | LevelDB | libmdbx |
|---|---|---|
| アーキテクチャ | LSM ツリー | B+ ツリー |
| データ構造 | MemTable、SSTable (レベル化) | B+ ツリー |
| 書き込みパフォーマンス (一般) | 高速 (追加専用) | 良好 (メモリマッピングで改善) |
| 読み取りパフォーマンス (一般) | 良好 (シーケンシャル)、中程度 (ランダム) | 非常に高速 (ポイントルックアップ)、良好 (範囲スキャン) |
| 並行性制御 | 単一ライターロック、並行リーダー | MVCC (複数リーダー、単一ライター) |
| データ永続性 (メカニズム) | WAL (先行書き込みログ) | コピーオンライト、同期モード |
| スペース効率 | 中程度 (圧縮で改善) | 良好 |
| WAL (デフォルト) | 有効 | 無効 |
| 一般的なユースケース (アーキテクチャに基づく) | 書き込み負荷の高いアプリケーション | 読み取り負荷の高いアプリケーション |
- 青:読み込み操作
- 緑:同期書き込み(ディスクに永続的に書き込まれるまで、操作が完了したと見なされないモード)
- 赤:遅延書き込み(データベースへの変更がディスクに即座に書き込まれることを待たずに、操作が完了したと見なされるモード)
読み取りパフォーマンスに関してはLevelDBと比較して大幅に高速であることを示している
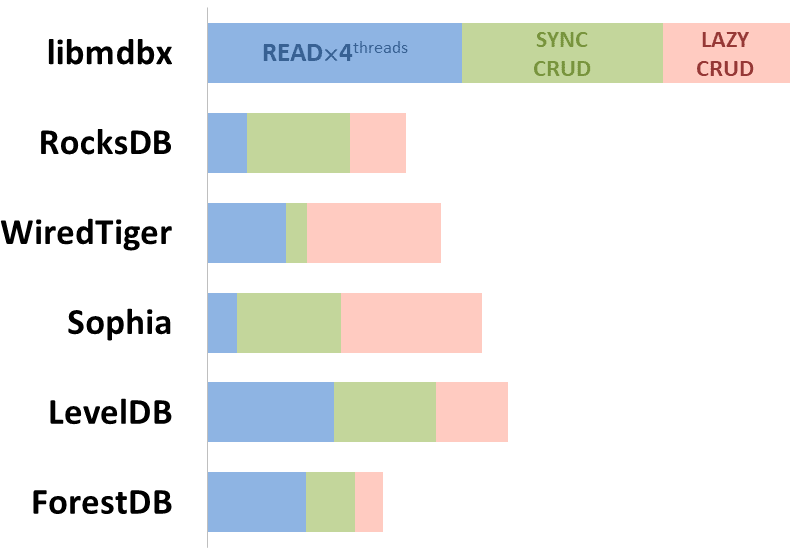
書き込みパフォーマンスに関しては場合による。LMDBは大きな値の書き込みでは高速になる。LevelDBは特にランダム書き込みや小さな更新を含むシナリオでは、LMDBよりも優れたパフォーマンスを発揮する。
つまりLMDB(libmdx)は読み取りに関してはGethのLevel DBよりも高速であることが保証されている。書き込みについては賛否両論あるようで、そのような議論はQiitaでも言及されていた。
3. Client Diversity
ここまでRethのModularityとPerformanceの密接な関係について解説してきた。
これら二つの特徴に比べるとClient Diversityは重要なのだろうか?
むしろClient Diversityこそが最も重要だと言えるし、Rethのミッションはここにあるだろう。
Ethereumが分散型で検閲耐性のある堅牢なネットワークであり続けるために不可欠だ。アーキテクチャ的には単一障害点のリスクを軽減し、ネットワーク耐性を高める。
エコシステム全体としては競争とイノベーションの促進、特定チームへの依存性(集中化)の排除に繋がる。
現在のELは #Geth と #Nethermind の2大クライアントが全体の80%近くを占めている。CLについてはTekuの寡占状態と言える。
*ここでは各クライアントのシェアが

from:https://clientdiversity.org/#why
Gethのようにすでに長い時間をかけて信頼を得たクライアントのシェアを無理に奪う必要はないが、別のクライアントらがシェアを拡大(多様化)させるにはどうすれば良いのだろう?
例えばプロバイダーらの開発環境に適応しやすい言語やOSをサポートしていることが考えられる。実際、多くのクライアントがその意図を汲んでか言語の多様性を発揮している
しかし、言語が違うだけでシェアを伸ばせるわけではないことは自明だ。
次に考えられるのはそのクライアントのパフォーマンスと堅牢性だ。
ここまで解説してきたようにRethは少なくともGethより高いパフォーマンスと堅牢性を持っている。
また、他のクライアントにはない機能も差別化には重要だろう。
Reth固有機能としてExecution Extension(ExEx)が提供されている。
ExExは、Ethereumノードの機能を拡張するための強力なフレームワークであり、リアルタイムで高性能なオフチェーンインフラストラクチャを構築することを可能にする。
これにより以下のようなインフラストラクチャを従来の方法よりも少ないコード量で実装可能になる
- Rollup:L1の状態を監視し、L2ブロックを生成する。
- Indexor:特定のイベントやトランザクションを抽出し、データベースに保存する
- MEV Bot:新しいブロックの情報をリアルタイムで取得し、最適な取引戦略を実行する。
- Reorgトラッカー:チェーンの再編成を検出し、対応する処理を行う。
さらに、来たるべきzkELの時代にRust製のELはシェアを伸ばす可能性が高い。
ちょうど今日、Justin DrakeがzkRethというmemeを生み出した。
このようにRethはClient Diversityの健全性に必要な要件を満たしている。
もちろん技術だけがClient Diversityを改善するわけではないので、Paradigmのマーケティング力やネットワーク効果が重要だろう。
個人的に面白いのはExExがStaged Syncの副産物であり、Performanceの改善がClient Diversityに及んだ点にある。
4. さいごに
この記事ではRethが持つModularity,Performance, Client Diversityがいかにして成り立つかを解説した。特にPerformanceについて重点的に解説したが、ここでは語りきれていないので興味があればぜひ参考資料を見てほしい。
5. 参考資料
Views: 0

{kind=link}