
はじめに – Vol.15
本記事では、IPA が公開する 非機能要求グレード の「A.2 耐障害性」を対象に、
金融 IT 基盤に 30 年以上携わって得た知見をもとに “やらかしがちな” 技術課題と対策を解説します。
筆者は非機能要求グレード初版の執筆に関わった経験があり、行間を含め解説します。
シリーズ全体の構成は 👉 非機能要求グレードの歩き方 Index をご覧ください。
A.2 耐障害性
中項目「A.2 耐障害性」では、機器故障に対する対策レベルについて記述します。
本項目は「A.1.2.2 サービス切替時間」を元に策定されるため、「〇:重要項目」の指定はありません。
各小項目には、主に次の 2 つのメトリクスが示されています:
- 「機器」(いわゆる筐体)の冗長化レベル
- 「コンポーネント」(機器内の部品) の冗長化レベル
これらは物理的故障(ダウン)への基本対策ですが、以下のような“半死に” (停止していないが機能していない状態)などにも備える必要があります。
- ハング(無応答)
- スプリットブレイン(冗長化機能の SPOF )
- 輻輳(エラー多発)
- 性能劣化( OS ・ドライバの機能不全)
これらの障害は、冗長化している場合、通常ベーシックリカバリ手順(安全で確実な両系再起動手順)で復旧できます。
自動的な復旧が必要な場合は、SPOF(単一障害点)に対する2種類の冗長化や、タイムアウト監視からの切換えなどの高度な対策が必要となります。
下表は、大項目「A 可用性」-中項目「A.2 耐障害性」を抜粋したものです。
表: 「A.2 耐障害性」の小項目とメトリクス(折りたたんでいます)
| 大項目 | 中項目 | 小項目 | メトリクス(〇: 重要項目) |
|---|---|---|---|
| A 可用性 | A.2 耐障害性 | A.2.1 サーバ | A.2.1.1 冗長化(機器) A.2.1.2 冗長化(コンポーネント) |
| 〃 | 〃 | A.2.2 端末 | A.2.2.1 冗長化(機器) A.2.2.2 冗長化(コンポーネント) |
| 〃 | 〃 | A.2.3 ネットワーク機器 | A.2.3.1 冗長化(機器) A.2.3.2 冗長化(コンポーネント) |
| 〃 | 〃 | A.2.4 ネットワーク | A.2.4.1 回線の冗長化 A.2.4.2 経路の冗長化 A.2.4.3 セグメント分割 |
| 〃 | 〃 | A.2.5 ストレージ | A.2.5.1 冗長化(機器) A.2.5.2 冗長化(コンポーネント) A.2.5.3 冗長化(ディスク) |
| 〃 | 〃 | A.2.6 データ | A.2.6.1 バックアップ方式 A.2.6.2 データ復旧範囲 A.2.6.3 データインテグリティ |
以降、小項目ごとに解説します。
A.2.1 サーバ
| 小項目 | メトリクス(〇: 重要項目) |
|---|---|
|
A.2.1 サーバ サーバで発生する障害に対して、要求されたサービスを維持するための要求。 |
A.2.1.1 冗長化(機器) A.2.1.2 冗長化(コンポーネント) |
メトリクス内容(折りたたんでいます)
| 項番 メトリクス |
レベル0/1/2/3/4/5 備考 |
|---|---|
| A.2.1.1 冗長化(機器) |
0: 非冗長構成 1: 特定のサーバで冗長化 2: 全てのサーバで冗長化 【メトリクス】 |
| A.2.1.2 冗長化(コンポーネント) |
0: 非冗長構成 1: 特定のコンポーネントのみ冗長化 2: 全てのコンポーネントを冗長化 【レベル1】 |
半死にとベーシックリカバリ手順
-
本項には、サーバに関する耐障害性要件(対策方針)を記述します。
なお、クラウドサービスでは、SLA/SLOとしてavailability(可用性)が % で示され、
SLAの場合、通常、評価期間と障害と認定する停止時間が併記されます。 -
下表のようなサーバ障害は、再起動⇒待機系切替⇒ベーシックリカバリ(両系再起動)により、大半のケースが復旧します。
但し、永続データに起因する障害(DBサーバやファイルサーバの永続データの状態、ログ・作業領域あふれ、など)や、外部からのアクセスに起因する障害(過負荷、攻撃など)の場合は復旧しませんので、やみくもに再起動する運用はお勧めできません。障害状態の分類 故障例 ダウン(通常の故障) 部品の故障、OS・スレッドのダウン ハング(無応答) 部品の劣化、IO・スレッドの無応答 スプリットブレイン 正系故障時に副系に切り替わらない 輻輳(エラー多発) 部品の劣化、リトライの悪循環 性能劣化 部品の劣化、過度の滞留、ゴミの蓄積
A.2.2 端末
| 小項目 | メトリクス(〇: 重要項目) |
|---|---|
|
A.2.2 端末 端末で発生する障害に対して、要求されたサービスを維持するための要求。 |
A.2.2.1 冗長化(機器) A.2.2.2 冗長化(コンポーネント) |
メトリクス内容(折りたたんでいます)
| 項番 メトリクス |
レベル0/1/2/3/4/5 備考 |
|---|---|
| A.2.2.1 冗長化(機器) |
0: 非冗長構成 1: 共用の予備端末を設置 2: 業務や用途毎に予備端末を設置 |
| A.2.2.2 冗長化(コンポーネント) |
0: 非冗長構成 1: 特定のコンポーネントのみ冗長化 2: 全てのコンポーネントを冗長化 【レベル1】 |
特殊な使用環境を明示
- 本項には、端末の機種選定に影響する耐障害性要件(選定方針)を記述します。
なお、クラウドサービスでは、SLA/SLOとしてavailability(可用性)が % で示されます。 - オフィスで使うPC端末の場合、メトリクスの観点を記載すれば十分です。
なお、VDI(仮想デスクトップ基盤)の場合、サーバの観点も必要となります。 - 工場(粉じん対策、熱対策)、屋外(防水、対候性、振動)など特殊な使用環境に応じた耐障害性要件があれば、本項に記載します。
なお、「F. システム環境・エコロジー」に同様の項目がありますが、そちらはサーバについて記載し、端末については本項にまとめることをお勧めします。
A.2.3 ネットワーク機器
| 小項目 | メトリクス(〇: 重要項目) |
|---|---|
|
A.2.3 ネットワーク機器 ルータやスイッチなどネットワークを構成する機器で発生する障害に対して、要求されたサービスを維持するための要求。 |
A.2.3.1 冗長化(機器) A.2.3.2 冗長化(コンポーネント) |
メトリクス内容(折りたたんでいます)
| 項番 メトリクス |
レベル0/1/2/3/4/5 備考 |
|---|---|
| A.2.3.1 冗長化(機器) |
0: 非冗長構成 1: 特定の機器のみ冗長化 2: 全ての機器を冗長化 【レベル1】 |
| A.2.3.2 冗長化(コンポーネント) |
0: 非冗長構成 1: 特定のコンポーネントのみ冗長化 2: 全てのコンポーネントを冗長化 【レベル1】 |
- 本項には、ネットワーク機器の耐障害性要件(対策方針)を記述します。
クラウドサービスでは、SLA/SLOとしてavailability(可用性)が % で示されます。
なお、通信経路障害に対する耐障害性要件については、次項の「A.2.4 ネットワーク」に記載します。 - サーバ上に構築する仮想ネットワーク機器に対する耐障害性要件も本項に記述します。
A.2.4 ネットワーク
| 小項目 | メトリクス(〇: 重要項目) |
|---|---|
|
A.2.4 ネットワーク ネットワークの信頼性を向上させるための要求。 |
A.2.4.1 回線の冗長化 A.2.4.2 経路の冗長化 A.2.4.3 セグメント分割 |
メトリクス内容(折りたたんでいます)
| 項番 メトリクス |
レベル0/1/2/3/4/5 備考 |
|---|---|
| A.2.4.1 回線の冗長化 |
0: 冗長化しない 1: 一部冗長化 2: 全て冗長化する 【メトリクス】 |
| A.2.4.2 経路の冗長化 |
0: 冗長化しない 1: 一部冗長化 2: 全て冗長化する 【メトリクス】 |
| A.2.4.3 セグメント分割 |
0: 分割しない 1: サブシステム単位で分割 2: 用途に応じて分割 【レベル2】 |
通信経路の耐障害性
- 本項には、通信経路に対する耐障害性対策の要件(対策方針)を記述します。
なお、通信経路を実現する、ネットワーク機器の耐障害性要件は、前項の「A.2.3 ネットワーク機器」に記載します。 - サーバ・ミドルウェア・アプリケーションなどにより、通信経路を使い分けることで耐障害性を向上する必要がある場合、ネットワーク構成図から耐障害性対策の全体像を把握することは難しくなるため、本項に耐障害性対策方針を記載します。
- クラウドサービスの場合、リージョンへのアクセスポイントを冗長化することはできます。
しかし、リージョン内通信経路の可用性では、システムの可用性要件を満たせない場合は、マルチリージョン構成とするなどネットワーク以外から対策が必要となります。
A.2.5 ストレージ
| 小項目 | メトリクス(〇: 重要項目) |
|---|---|
|
A.2.5 ストレージ ディスクアレイなどの外部記憶装置で発生する障害に対して、要求されたサービスを維持するための要求。 |
A.2.5.1 冗長化(機器) A.2.5.2 冗長化(コンポーネント) A.2.5.3 冗長化(ディスク) |
メトリクス内容(折りたたんでいます)
| 項番 メトリクス |
レベル0/1/2/3/4/5 備考 |
|---|---|
| A.2.5.1 冗長化(機器) |
0: 非冗長構成 1: 特定の機器のみ冗長化 2: 全ての機器を冗長化 【メトリクス】 |
| A.2.5.2 冗長化(コンポーネント) |
0: 非冗長構成 1: 特定のコンポーネントのみ冗長化 2: 全てのコンポーネントを冗長化 【レベル1】 |
| A.2.5.3 冗長化(ディスク) |
0: 非冗長構成 1: 単一冗長 2: 多重冗長 【レベル1】 |
可用性と耐久性を定義
- 本項には、ストレージに関する耐障害性として、領域ごとの可用性と耐久性要件(対策方針)を記述します。
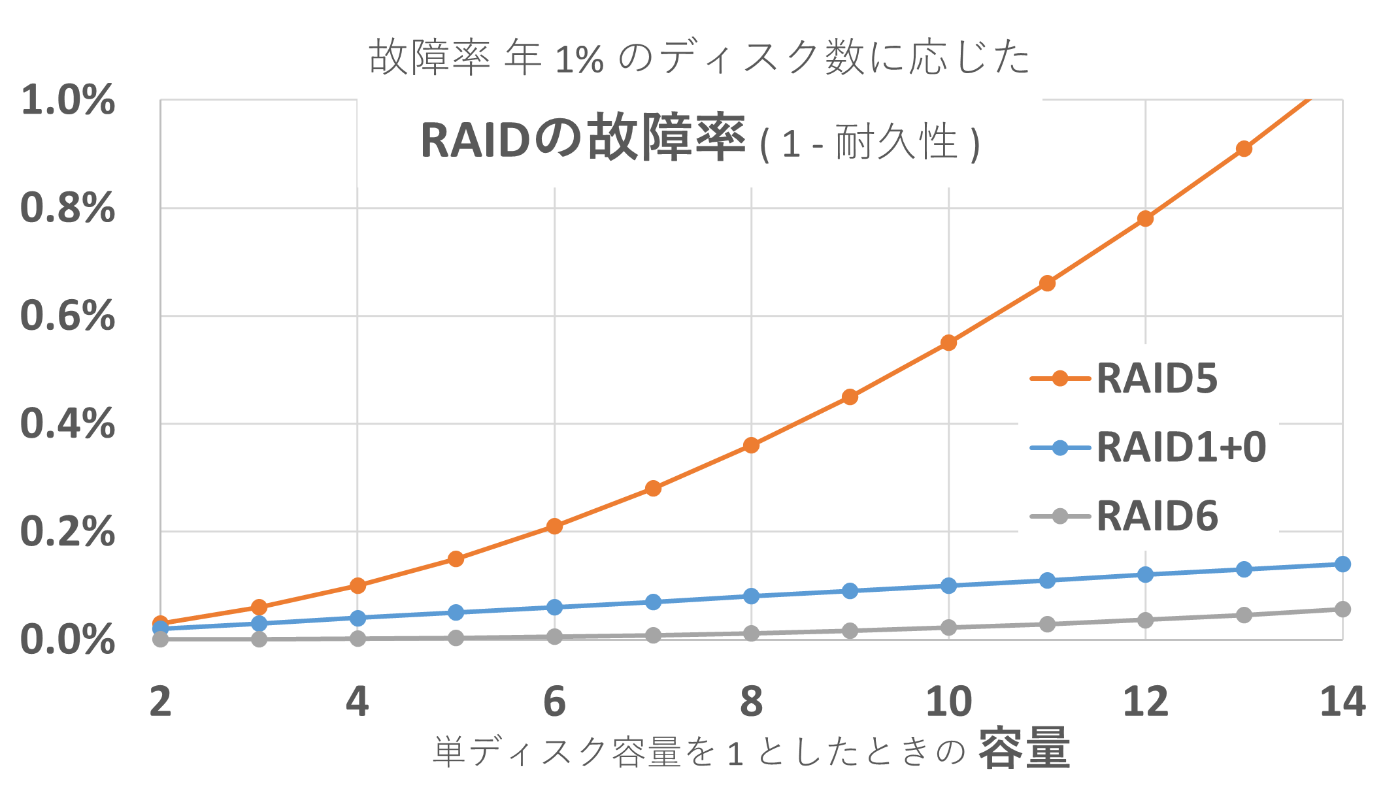
なお、クラウドサービスでは、SLA/SLOとしてavailability(可用性)とdurability(耐久性)を明確に区別して、各々 % で示されます。 - 非機能要求グレードの初版では、ディスクの冗長化レベルをRAIDで表現していましたが、2018年の改定版で、仮想化技術の成熟を踏まえて1: 単一冗長/2: 多重冗長に見直されています。
| RAID構成 | IO性能 | 耐久性 データロスト条件 |
容量効率 | 適した用途 |
|---|---|---|---|---|
|
RAID 10 (RAID 1) |
◎高速 (RAID 0) |
〇 RAID 1 ペア同時故障 |
△ 1/2 | 耐久性と高速性重視 |
| RAID 0+1 | 〇 (RAID 0 片系 障害時に劣化) |
△ 2 個故障 (RAID 0 跨り) |
△ 1/2 | なし(RAID 10に劣る) |
| RAID 5 | △ パリティ 計算負荷 |
△ 2 個故障 | ◎ -1個分 |
小容量(※)で容量効率重視 (RAID 6未対応向け) |
| RAID 6 | △ 2 パリティ 計算負荷 |
◎ 3 個故障 | 〇 -2個分 | 耐久性と容量効率重視 |
※RAID 5 は、構成ディスク数が増えると急速に耐久性が下がるため大容量には不向きです。
A.2.6 データ
| 小項目 | メトリクス(〇: 重要項目) |
|---|---|
|
A.2.6 データ データの保護に対しての考え方。 |
A.2.6.1 バックアップ方式 A.2.6.2 データ復旧範囲 A.2.6.3 データインテグリティ |
メトリクス内容(折りたたんでいます)
| 項番 メトリクス |
レベル0/1/2/3/4/5 備考 |
|---|---|
| A.2.6.1 バックアップ方式 |
0: バックアップ無し 1: オフラインバックアップ 2: オンラインバックアップ 3: オフラインバックアップ+オンラインバックアップ 【重複項目】 |
| A.2.6.2 データ復旧範囲 |
0: 復旧不要 1: 一部の必要なデータのみ復旧 2: システム内の全データを復旧 【重複項目】 |
| A.2.6.3 データインテグリティ |
0: エラー検出無し 1: エラー検出のみ 2: エラー検出&再試行 3: データの完全性を保障 (エラー検出&訂正) 【メトリクス】 |
永続データの管理機能を定める
- 本項には、データの論理破壊に対するデータ保護の要件(対応方針)を記述します。
- ファイルシステム、DBMS、メッセージング基盤など、一般に普及している永続データ管理機能は、各用途に応じたデータインテグリティ要件(A.2.6.1)を満たすデータ保護機能を備えています。
そのため、管理対象データごとに、使用する製品やサービスを示すことで、間接的にデータ保護の要件と対応方針を示すことができます。 - 一方、標準的な製品やサービスでは対応していない特殊なデータ管理要件がある場合は、本項に詳細に要件を記載する必要があります。
- なお、バックアップ(A.2.6.1⇒C.1.2.7)や復旧範囲(A.2.6.2⇒C.1.2.1)に関する要件については、本項で扱わず、重複メトリクスを持つ各小項目に記載した方が、わかりやすく整理できます。
あったら怖い本当の話
※ 実際に起きたことを、脱色デフォルメしたフィクションにして紹介します。
😱HDDが次々と…データ喪失
- RAID 6 で構成したストレージの次期ハードウェア更改まであと 1 年
- バスタブ曲線の摩耗故障期に入った模様で、数ヶ月毎にハードディスクドライブ (HDD) の故障が発生、障害時影響の少ない週末に交換を行っていました。
敗因
- 故障した HDD は、何れも同一ロットでしたが、ロット不良とは判定されていませんでした。
HDD のログを確認したところ、同一筐体内の同じロットはエラーリトライが増加していました。 - 状況から推測するに、耐久性の低いロットの HDD で構成したRAIDグループに対し、大量の更新を行い劣化が進んでいたところに、繰り返しRAID再構成の更新をかけたことにより、さらに劣化を加速させ、最終的に短時間に複数台の故障を招いたと想定されます。
- 問題のロットの HDD はすべて交換しました。
交換の際にはRAIDグループを複数の異なるロットで構成しました。 - 以下の運用をしていればデータ喪失には至らなかったと考えられます。
- 数ヶ月ごとに故障が発生するようになった段階から、即日交換
- エラー件数をチェックし、エラーが増えた HDD を予防保守として交換
再発防止
横展開として以下の対応を行いました。
- RAIDディスク故障は、原則即日交換するよう保守運用を見直し
- 当該ベンダのストレージは、月次で HDD のエラー数を確認し、閾値越えで予防保守交換
閑話休題:😱データ喪失リスク
筆者は、3~4年に1度、以下のようなデータ喪失に遭遇または耳にしています。
メディア起因の障害
- HDD の大量更新による劣化(上述の件)
- ロット不良:HDD へのダイヤモンドダスト混入
- ロット不良:HDD ヘッド高さ不足(プラッタ(円盤)との隙間)
これらは、故障時即日交換と、エラー件数の確認の対策が有効です。
制御系ソフトウェアバグによる論理破壊
- SSD の故障判定閾値設定バグ(ファームウェアバグ)
- ストレージコントローラ障害時にボリューム管理領域の論理破損(コントローラのバグ)
- ストレージリブート時にコントローラキャッシュ揮発(コントローラのバグ)
こちらは、ストレージベンダによる品質とサポート強化によってしか対策することができず、
万一遭遇した場合、バックアップからの復旧が唯一の復旧手段となります。
まとめ
本記事では、耐障害性は切替時間の要件から定まるため設計方針を定めることになることを説明しました。
最後に、NTTデータの金融高度技術本部では、ともに金融ITの未来を切り拓く仲間を募集しています。
[募集要領]
[NTTデータ 金融分野の取り組み]
Views: 0

{kind=link}