

1. 初めに
Prometheus + GrafanaでGPUサーバーの監視を行うにあたり、デフォルトの設定からの情報だと求めるmetricsの表示方法にできなかったため、勉強も兼ねてHelm Chartを自作してみました。
自作したHelm Chartは以下のレポジトリに置いています。
2. 経緯
弊研究室ではGPUを複数台載せたGPUサーバーを十数台運用していますが、その監視方法として、
-
nvidia-smiを各GPUサーバーで定期実行(Ansibleなども使わずcron手書き…) - 結果をnfsでマウントしてあるファイルサーバー上にcsvとして書き出し
- そのcsvを読み取って表示するWebアプリケーションを公開
という時代に取り残されたような監視方法を取っていました。流石に各サーバーで独自の設定を置いておくのはなということもあり、Prometheus + Grafana on Kubernetesで実装しようと思っていたのですが、デフォルトだとGPUのメトリクスを一覧で表示させようにもできないことが分かったため、PrometheusとGrafanaの間にメトリクスをカスタマイズするアプリケーションを挟む必要が出てきました。
(公式で出してくれてるDashboardもあるけど、実運用上だと別にこんな洒落たDashboardは要らない…)

3. 環境
先にオンプレの監視用サーバー2台と監視対象のGPUサーバー1台でClusterを作成しています。CNIはCalicoを使っています。
- Kubernetes: v1.32.1, v1.32.3
- Helm: v3.17.2
$ k get node -o custom-columns=NAME:.metadata.name,VERSION:.status.nodeInfo.kubeletVersion,OS-IMAGE:.status.nodeInfo.osImage
NAME VERSION OS-IMAGE
admin1 v1.32.1 Debian GNU/Linux 12 (bookworm)
admin2 v1.32.3 Debian GNU/Linux 12 (bookworm)
gpu1 v1.32.3 Ubuntu 24.04.2 LTS
また、予めGPUのmetricsを収集するために、Prometheus + Grafanaを含むkube-prometheus-stackとDCGM exporterを含むGPU operatorをHelmにて導入しています。
(この辺りもオンプレだとかなり手こずったのでどこかでまとめたい…)
- tigera-operator: v3.29.3
- kube-prometheus-stack: v0.81.0
- GPU operator: v25.3.0
$ helm list -A
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
calico tigera-operator 1 2025-04-05 18:28:43.842720625 +0900 JST deployed tigera-operator-v3.29.3 v3.29.3
gpu-operator gpu-operator 1 2025-04-05 18:57:21.82273005 +0900 JST deployed gpu-operator-v25.3.0 v25.3.0
kube-prometheus server-monitoring 1 2025-04-10 18:03:53.530031722 +0900 JST deployed kube-prometheus-stack-70.4.2 v0.81.0
$ kubectl get svc -n server-monitoring -o custom-columns=NAME:.metadata.name,TYPE:.spec.type,CLUSTER-IP:.spec.clusterIP,EXTERNAL-IP:.status.loadBalancer.ingress[0].ip,PORTS:.spec.ports[*].port
NAME TYPE CLUSTER-IP EXTERNAL-IP PORTS
alertmanager-operated ClusterIP None 9093,9094,9094
kube-prometheus-grafana NodePort 10.109.213.217 3000
kube-prometheus-kube-prome-alertmanager ClusterIP 10.107.18.241 9093,8080
kube-prometheus-kube-prome-operator ClusterIP 10.106.14.47 8080
kube-prometheus-kube-prome-prometheus NodePort 10.104.143.252 9090,8080
kube-prometheus-kube-state-metrics ClusterIP 10.109.115.244 8080
kube-prometheus-prometheus-node-exporter ClusterIP 10.100.139.200 9100
prometheus-operated ClusterIP None 9090
$ kubectl get svc -n gpu-operator -o custom-columns=NAME:.metadata.name,TYPE:.spec.type,CLUSTER-IP:.spec.cl
usterIP,EXTERNAL-IP:.status.loadBalancer.ingress[0].ip,PORTS:.spec.ports[*].port
NAME TYPE CLUSTER-IP EXTERNAL-IP PORTS
gpu-operator ClusterIP 10.103.110.170 8080
nvidia-dcgm-exporter ClusterIP 10.103.244.54 9400
4. Helm Chartの作成
目標としては、以下のdcgm metris apiのようにPrometheus HTTP APIからDCGM Exporterから収集したmetricsをPollingしてきて、内部で加工、それを9095でListenするアプリケーションの実装を目指します。単純なアプリケーションなのでGolangで書いてコンパイルし、それを含めてDocker Imageにし、さらにそのImageをDeploymentとしてデプロイする構成にしました。
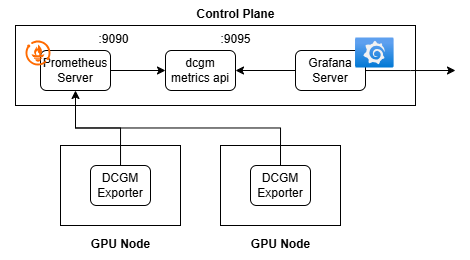
4.1. アプリの作成
PrometheusのHTTP APIからmetricsを収集する部分を書きます。
4.1.1. Prometheusからmetricsの取得
以下のDocumentによると/api/v1/query?query=で取ってこられるらしいので、取得したいmetrics名のスライスmetricNamesからURLを組み立ててGetする関数FetchPrometheusMetricsを作ります。ここで、metricNamesStrはKubernetes側の環境変数METRIC_NAMESとして渡して読み込む変数になります。
dcgm-metrics-api/pkg/cmd/prometheus.go
func FetchPrometheusMetrics(promURL string, metricNamesStr string) ([]Result, error) {
var metricNames []string
if err := yaml.Unmarshal([]byte(metricNamesStr), &metricNames); err != nil {
return nil, fmt.Errorf("failed to parse metric names: %v", err)
}
var allResults []Result
for _, metric := range metricNames {
url := fmt.Sprintf("%s/api/v1/query?query=%s", promURL, metric)
resp, err := http.Get(url)
if err != nil {
return nil, fmt.Errorf("failed to fetch metric %s: %v", metric, err)
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
body, _ := io.ReadAll(resp.Body)
return nil, fmt.Errorf("failed to fetch metric %s: status %d, body: %s",
metric, resp.StatusCode, string(body))
}
var pResp PrometheusResponse
if err := json.NewDecoder(resp.Body).Decode(&pResp); err != nil {
return nil, fmt.Errorf("failed to decode response for metric %s: %v", metric, err)
}
if pResp.Status != "success" {
return nil, fmt.Errorf("prometheus returned non-success status for metric %s: %s",
metric, pResp.Status)
}
allResults = append(allResults, pResp.Data.Result...)
}
if len(allResults) == 0 {
return nil, fmt.Errorf("no results returned from Prometheus")
}
return allResults, nil
}
4.1.2. 取得したmetricsの加工
次に、取得したmetricsを加工するMergeGpuMetricsを書きます。ここでは具体的にDCGM Exporterから取得できる温度、GPUメモリ使用率などを取得するように直書きしています。(この辺りも将来的にはカスタマイズできるようにしたい…)
dcgm-metrics-api/pkg/cmd/gpu.go
const (
MetricGPUTemp = "DCGM_FI_DEV_GPU_TEMP"
MetricGPUMemoryFree = "DCGM_FI_DEV_FB_FREE"
MetricGPUMemoryUsed = "DCGM_FI_DEV_FB_USED"
MetricGPUUtil = "DCGM_FI_DEV_GPU_UTIL"
MetricGPUMemoryUtil = "DCGM_FI_DEV_MEM_COPY_UTIL"
)
type GpuStatus struct {
Hostname string `json:"Hostname"`
DeviceID string `json:"gpu"`
UUID string `json:"uuid"`
Timestamp time.Time `json:"timestamp"`
Name string `json:"modelName"`
MemFree float64 `json:"memory_free"`
MemUsed float64 `json:"memory_used"`
MemTotal float64 `json:"memory_total"`
GPUUtil float64 `json:"gpu_utilization"`
MemUtil float64 `json:"gpu_memory_utilization"`
GPUTemp float64 `json:"gpu_temp"`
}
func MergeGpuMetrics(results []Result) ([]GpuStatus, error) {
if len(results) == 0 {
return nil, fmt.Errorf("no metrics provided")
}
gpuMap := make(map[string]*GpuStatus)
for _, result := range results {
uuid := result.Metric["UUID"]
if uuid == "" {
continue
}
status, exists := gpuMap[uuid]
if !exists {
status = &GpuStatus{
Hostname: result.Metric["Hostname"],
DeviceID: result.Metric["gpu"],
Name: result.Metric["modelName"],
UUID: uuid,
}
gpuMap[uuid] = status
}
timestamp, err := result.GetTimestamp()
if err == nil {
status.Timestamp = ConvertUTCToJST(timestamp)
}
metricName := result.Metric["__name__"]
val, err := result.GetValue()
if err != nil {
return nil, fmt.Errorf("invalid value for metric %s: %v", metricName, err)
}
switch metricName {
case MetricGPUMemoryFree:
status.MemFree = val
case MetricGPUMemoryUsed:
status.MemUsed = val
case MetricGPUUtil:
status.GPUUtil = val
case MetricGPUMemoryUtil:
status.MemUtil = val
case MetricGPUTemp:
status.GPUTemp = val
default:
return nil, fmt.Errorf("invalid metric name: %s", metricName)
}
if status.MemFree != 0 && status.MemUsed != 0 {
status.MemTotal = status.MemFree + status.MemUsed
}
}
if len(gpuMap) == 0 {
return nil, fmt.Errorf("no valid GPU metrics found")
}
statuses := make([]GpuStatus, 0, len(gpuMap))
for _, s := range gpuMap {
statuses = append(statuses, *s)
}
// Sort the statuses by Hostname and DeviceID
sort.Sort(ByHostnameAndDeviceID(statuses))
return statuses, nil
}
4.1.3. 加工したmetricsの公開
先ほど作成した関数群をHandlerとして、8080番でListenします。
dcgm-metrics-api/pkg/cmd/app.go
func MetricsHandler(w http.ResponseWriter, r *http.Request) {
promURL := os.Getenv("PROMETHEUS_URL")
if promURL == "" {
sendError(w, "PROMETHEUS_URL environment variable is not set", http.StatusInternalServerError)
return
}
metricNamesStr := os.Getenv("METRIC_NAMES")
if metricNamesStr == "" {
sendError(w, "METRIC_NAMES environment variable is not set", http.StatusInternalServerError)
return
}
results, err := FetchPrometheusMetrics(promURL, metricNamesStr)
if err != nil {
sendError(w, err.Error(), http.StatusInternalServerError)
return
}
data, err := MergeGpuMetrics(results)
if err != nil {
sendError(w, err.Error(), http.StatusInternalServerError)
return
}
w.Header().Set("Content-Type", "application/json")
if err := json.NewEncoder(w).Encode(data); err != nil {
sendError(w, "Failed to encode response", http.StatusInternalServerError)
return
}
}
// Run starts the HTTP server and sets up the metrics endpoint
func Run() error {
// Get endpoint from environment variable or use default
endpoint := os.Getenv("METRICS_ENDPOINT")
if endpoint == "" {
endpoint = defaultEndpoint
}
// Register handlers
http.HandleFunc(endpoint, MetricsHandler)
http.HandleFunc("/ready", ReadinessProbeHandler)
http.HandleFunc("/health", LivenessProbeHandler)
// Start server
port := ":8080"
log.Printf("Starting server on %s with endpoint %s", port, endpoint)
return http.ListenAndServe(port, nil)
}
dcgm-metrics-api/cmd/dcgm-metrics-api
/main.go
package main
import (
"log"
"github.com/V01d42/dcgm-metrics-api/pkg/cmd"
)
func main() {
if err := cmd.Run(); err != nil {
log.Fatalf("Failed to start server: %v", err)
}
}
ここには記載していませんが、Kubernetesでは死活監視用のProbeの設定があるため、それらをReadinessProbeHandler,LivenessProbeHandlerとして用意しています。(今回はHTTP
4.2. Dockerfileの作成
先ほど作ったプログラムを最初にgolangのコンテナでbuildし、その後buildしたバイナリだけをコピーして8080番を公開した状態で実行させるようにしました。
dcgm-metrics-api/docker
# Build stage
FROM golang:1.24.2-alpine AS builder
# Install build tools and set up environment
WORKDIR /app
COPY go.mod go.sum ./
RUN apk add --no-cache git gcc musl-dev tzdata &&
go mod download
# Build optimized binary
COPY . .
RUN CGO_ENABLED=0 GOOS=linux go build -ldflags="-w -s" -o dcgm-metrics-api ./cmd/dcgm-metrics-api
# Runtime stage
FROM scratch
# Copy required certificates and timezone data
COPY --from=builder /etc/ssl/certs/ca-certificates.crt /etc/ssl/certs/
COPY --from=builder /usr/share/zoneinfo /usr/share/zoneinfo
# Set up working directory and copy binary
WORKDIR /app
COPY --from=builder /app/dcgm-metrics-api .
EXPOSE 8080
CMD ["./dcgm-metrics-api"]
4.3. Helm Chartの作成
Helm Chart用のディレクトリを以下のように作成します。今回は上で作成したDocker Imageを動かすDeploymentとそれを公開するService用のyamlを準備します。
charts/
└── dcgm-metrics-api/
├── Chart.yaml
├── values.yaml
└── templates/
├── NOTES.txt
├── deployment.yaml
├── service.yaml
└── _helpers.tpl
deployment.yaml,service.yaml,values.yamlの記述は以下のようにしました。
dcgm-metrics-api/charts/dcgm-metrics-api/templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "dcgm-metrics-api.fullname" . }}
labels:
{{- include "dcgm-metrics-api.labels" . | nindent 4 }}
spec:
replicas: {{ .Values.replicaCount }}
selector:
matchLabels:
{{- include "dcgm-metrics-api.selectorLabels" . | nindent 6 }}
template:
metadata:
labels:
{{- include "dcgm-metrics-api.selectorLabels" . | nindent 8 }}
spec:
containers:
- name: {{ .Chart.Name }}
image: "{{ .Values.image.repository }}:{{ .Values.image.tag | default .Chart.AppVersion }}"
imagePullPolicy: {{ .Values.image.pullPolicy }}
ports:
- name: http
containerPort: 8080
protocol: TCP
env:
- name: PROMETHEUS_URL
value: {{ .Values.env.PROMETHEUS_URL | quote }}
- name: METRICS_ENDPOINT
value: {{ .Values.env.METRICS_ENDPOINT | quote }}
- name: METRIC_NAMES
value: |
{{- .Values.env.METRIC_NAMES | nindent 16 }}
{{- with .Values.extraEnv }}
{{- toYaml . | nindent 12 }}
{{- end }}
resources:
{{- toYaml .Values.resources | nindent 12 }}
{{- with .Values.nodeSelector }}
nodeSelector:
{{- toYaml . | nindent 12 }}
{{- end }}
{{- with .Values.affinity }}
affinity:
{{- toYaml . | nindent 12 }}
{{- end }}
{{- with .Values.tolerations }}
tolerations:
{{- toYaml . | nindent 12 }}
{{- end }}
livenessProbe:
{{- toYaml .Values.probes.liveness | nindent 12 }}
readinessProbe:
{{- toYaml .Values.probes.readiness | nindent 12 }}
dcgm-metrics-api/charts/dcgm-metrics-api/templates/service.yaml
apiVersion: v1
kind: Service
metadata:
name: {{ include "dcgm-metrics-api.fullname" . }}
labels:
{{- include "dcgm-metrics-api.labels" . | nindent 4 }}
{{- with .Values.service.annotations }}
annotations:
{{- toYaml . | nindent 4 }}
{{- end }}
spec:
type: {{ .Values.service.type }}
ports:
{{- toYaml .Values.service.ports | nindent 4 }}
selector:
{{- include "dcgm-metrics-api.selectorLabels" . | nindent 4 }}
{{- if .Values.service.externalIPs }}
externalIPs:
{{- toYaml .Values.service.externalIPs | nindent 4 }}
{{- end }}
{{- if .Values.service.loadBalancerIP }}
loadBalancerIP: {{ .Values.service.loadBalancerIP | quote }}
{{- end }}
{{- if .Values.service.loadBalancerSourceRanges }}
loadBalancerSourceRanges:
{{- toYaml .Values.service.loadBalancerSourceRanges | nindent 4 }}
{{- end }}
dcgm-metrics-api/charts/dcgm-metrics-api/values.yaml
replicaCount: 1
image:
# repository: dcgm-metrics-api
repository: ghcr.io/v01d42/dcgm-metrics-api
pullPolicy: IfNotPresent
# Overrides the image tag whose default is the chart appVersion.
tag: ""
env:
PROMETHEUS_URL: "http://prometheus-server:9090"
METRICS_ENDPOINT: "/metrics"
METRIC_NAMES: |
- DCGM_FI_DEV_FB_FREE
- DCGM_FI_DEV_FB_USED
- DCGM_FI_DEV_GPU_UTIL
- DCGM_FI_DEV_MEM_COPY_UTIL
- DCGM_FI_DEV_GPU_TEMP
extraEnv: []
service:
type: ClusterIP
ports:
- name: http
port: 9095
targetPort: http
protocol: TCP
annotations: {}
externalIPs: []
loadBalancerIP: ""
loadBalancerSourceRanges: []
resources:
limits:
cpu: 100m
memory: 128Mi
requests:
cpu: 50m
memory: 64Mi
nodeSelector: {}
affinity: {}
tolerations: []
probes:
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
timeoutSeconds: 3
failureThreshold: 3
4.4. Github Actionsの設定
最後にGithub ActionsにてMainブランチにPushされた場合、Docker ImageをBuildしてGitHub Container RegistryにPushするdocker_release.ymlと、このHelm Chartをchart-releaserを用いてReleaseするrelease.ymlをWorkflowとして用意しました。release.ymlの方はprometheus-community/helm-chartsのworkflowを参考にさせていただきました。(ただ、Docker ImageとHelm Chart両方をGHCRにPushする場合のversion管理が分からずdocker-releaseはややごり押し的な書き方をしてしまっています。)
dcgm-metrics-api/.github/workflows/docker_release.yml
name: Build and Push Docker Image
on:
push:
branches:
- main
paths:
- '.github/workflows/docker_release.yml'
- 'charts/dcgm-metrics-api/values.yaml'
- 'cmd/dcgm-metrics-api/**'
- 'docker/**'
- 'go.mod'
- 'go.sum'
- 'pkg/**'
jobs:
build:
runs-on: ubuntu-latest
permissions:
contents: write
packages: write
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Get chart version
id: chart_version
run: |
VERSION=$(yq e '.appVersion' charts/dcgm-metrics-api/Chart.yaml)
echo "version=$VERSION" >> $GITHUB_OUTPUT
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Log in to GitHub Container Registry
uses: docker/login-action@v3
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Build and push
uses: docker/build-push-action@v5
with:
context: .
file: docker/Dockerfile
push: true
tags: |
ghcr.io/v01d42/dcgm-metrics-api:latest
ghcr.io/v01d42/dcgm-metrics-api:${{ steps.chart_version.outputs.version }}
labels: |
org.opencontainers.image.source=${{ github.server_url }}/${{ github.repository }}
org.opencontainers.image.version=${{ steps.chart_version.outputs.version }}
dcgm-metrics-api/.github/workflows/release.yml
name: Release Charts
permissions: {}
on:
push:
branches:
- main
paths:
- '.github/workflows/release.yml'
- 'charts/dcgm-metrics-api/**'
- 'cmd/dcgm-metrics-api/**'
- 'docker/**'
- 'go.mod'
- 'go.sum'
- 'pkg/**'
jobs:
release:
permissions:
contents: write # for creating releases
packages: write # for pushing to GHCR
id-token: write # for keyless signing
runs-on: ubuntu-latest
steps:
- name: Checkout Code
uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Configure Git
run: |
git config user.name "$GITHUB_ACTOR"
git config user.email "[email protected]"
- name: Set up Helm
uses: azure/setup-helm@v4
with:
version: v3.12.0
- name: Run chart-releaser
uses: helm/[email protected]
with:
skip_existing: true
env:
CR_TOKEN: "${{ secrets.GITHUB_TOKEN }}"
CR_GENERATE_RELEASE_NOTES: true
- name: Login to GitHub Container Registry
uses: docker/login-action@v3
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Push charts to GHCR
run: |
shopt -s nullglob
for pkg in .cr-release-packages/*; do
if [ -z "${pkg:-}" ]; then
break
fi
helm push "${pkg}" "oci://ghcr.io/v01d42/charts"
done
これでgithubにてgh-pagesというbranchを作成した後、PushすればHelm Chartがreleaseされるはずです。また、以下のコマンドでhelmにてデプロイし、metricsを取得することができると思います。
$ helm repo add dcgm-metrics-api https://v01d42.github.io/dcgm-metrics-api/
$ helm install dcgm-metrics-api -n dcgm-metrics-api/dcgm-metrics-api -f values.yaml
$ kubectl run curl-test -n server-monitoring --restart=Never --image=curlimages/curl:latest --rm -it -- curl http://dcgm-metrics-api.:9095/metrics
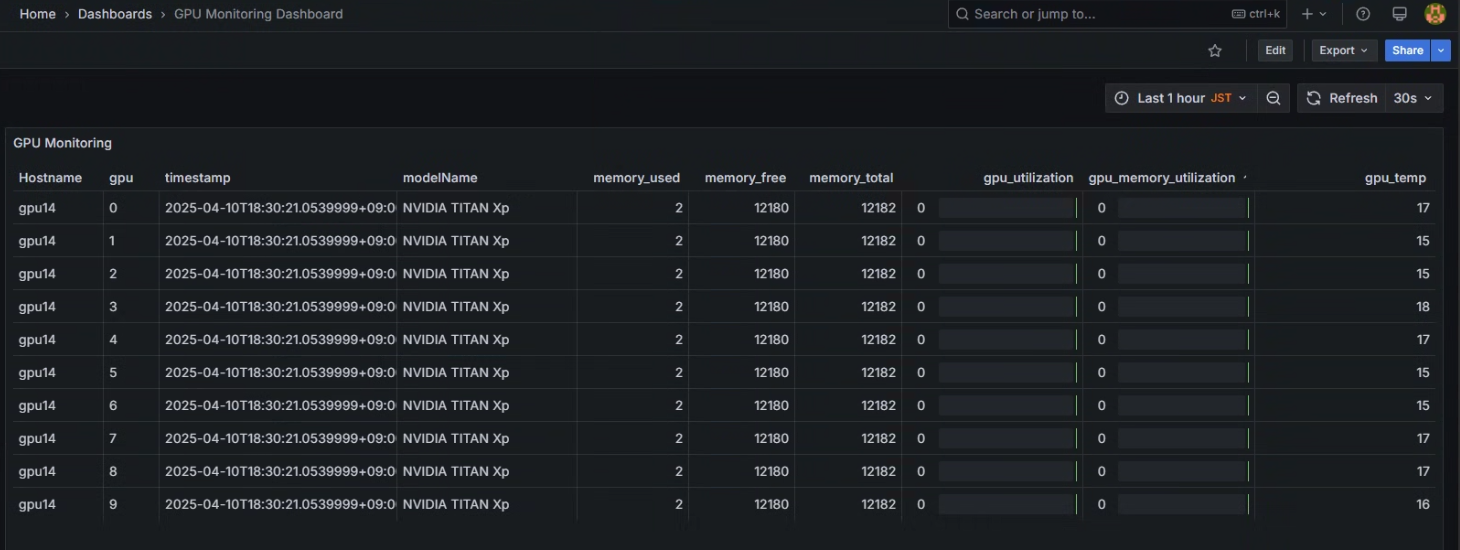
また、実際にGrafana Dashboardで連携すると以下のような感じになります。一覧でどのデバイスがどれだけ使われてるか見れて嬉しい!
5. まとめ
ひとまず一覧で表示する機能については実装できて良かったです。
ただ誰がどういうGPUのProcessを使っているのかも表示したかったのですが、DCGM Exporterで取得できるメトリクスの中には入ってないようで…多分nvidia-smiを使って自作Exporterするしかないのかなぁと思っています。
また、Github ActionsによるCDを実装したのは良いですが、docker imageとhelm chartのversionをどのように管理して公開して同期させるのが良いのか、1時間ぐらいHelm Chartを公開しているRepositoryを見ても参考になるものがあまりなかったため、そのベストプラクティスについてもどこかで調べたいと思ってます。
まだまだ勉強中なので、より良い方法やそもそも別の解決策等あると思いますが、その辺り気軽にご指摘いただけると幸いです。
6. 参考文献
Views: 0

{kind=link}