
TYMLとは、JsonSchemaよりも簡潔で厳密な仕様を持つ、任意の設定用言語(現在はiniとtoml)に対応可能なスキーマ言語です。JsonSchemaの置き換えを目標としています。
既にCLIツールとLSPサーバーをリリースしており、VSCode Marketplaceよりダウンロードして使用できます。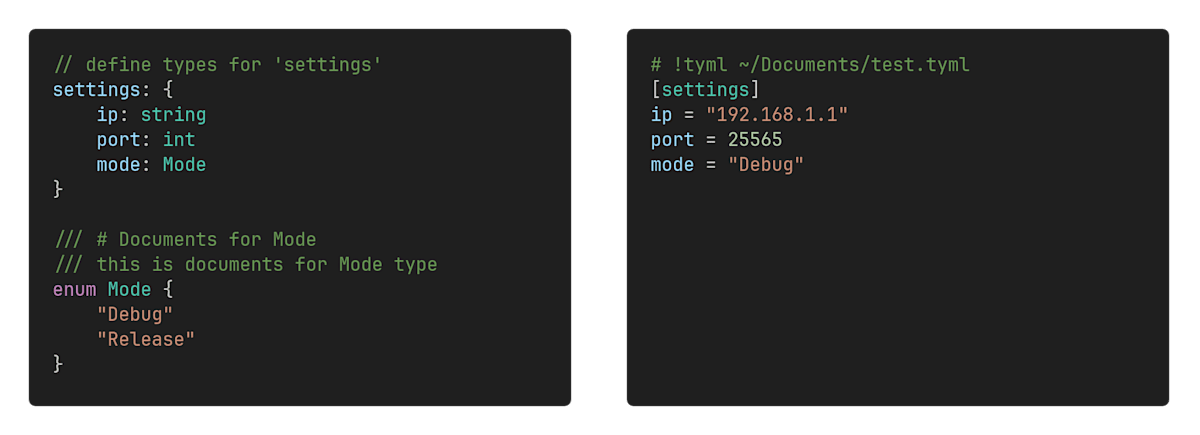
既に存在し最も普及しているスキーマ言語としてJsonSchemaが挙げられるかと思います。
しかし、これにはいくつか問題点があります。
1. 手書きしづらい
JsonSchemaは手書きにはあまり適していません。
以下のスキーマはコンバータを用いて生成しましたが、これを手書きするのは楽ではないでしょう。
{
"$schema": "http://json-schema.org/draft-06/schema#",
"$ref": "#/definitions/Welcome8",
"definitions": {
"Welcome8": {
"type": "object",
"additionalProperties": false,
"properties": {
"settings": {
"$ref": "#/definitions/Settings"
}
},
"required": [
"settings"
],
"title": "Welcome8"
},
"Settings": {
"type": "object",
"additionalProperties": false,
"properties": {
"ip": {
"type": "string"
},
"port": {
"type": "integer"
},
"mode": {
"type": "string"
}
},
"required": [
"ip",
"mode",
"port"
],
"title": "Settings"
}
}
}
ほぼ同じ内容のTYMLは以下のようになります。
settings: {
ip: string
port: int
mode: string
}
短いですね。
これなら手書きもできます。
(ただしJsonSchemaの方はいくつか付属情報があります)
2. 利用までの障壁が高め
仮にコンバータ等を使ってスキーマを生成したとしても、次にJsonSchema用の拡張機能の設定に追記する必要があります。
しかも、ファイル名でマッチングします。
同じファイル名の場合は、スキーマを別途選択してやる必要があります。
TYMLなら先頭にコメントで!tyml schema.tymlとするだけで利用可能になります。
3. 曖昧さ
JsonSchemaはデフォルトで曖昧なチェックを行います。
スキーマファイルに"additionalProperties": falseを指定しない限り、フィールドを書き忘れても、余計なフィールドを書いてもエラーにはなりません。
TYMLではデフォルトで、これらの記述は許可されません。
余計なフィールドを許可したい場合は*: intのように記述できます。
モチベーション
これらの仕様のせいなのか、便利さの割に見かける機会が少ないように筆者は感じています。
そこで、新たに導入障壁の低いスキーマ言語を用意することで、設定を書く環境を向上させるために開発しています。
殆どの設定用言語はシンプルな文法と仕様を持つものがほとんどです。
そこであらかじめ小さいパーサーを用意しておくことで、それらを組み合わせるだけで、文法チェック・型チェック・LSPまでを一気に対応させることも可能になるはずだ、という考えを元に開発しています。
多数の正規表現で構築されたlexerとparserにより構築されています。
TYMLは対応している設定言語であれば、コメントに!tymlを記入するだけでTYMLスキーマを指定できます。
settings: {
ip: string
port: int
mode: Mode
}
enum Mode {
"Debug"
"Release"
}
[settings]
ip = "192.168.1.1"
port = 25565
mode = "Debug"
[settings]
ip = 192.168.1.1
port = 25565
mode = Debug
CLIツールのエラー表記にも力を入れており、直感的に理解できるように調整しています。
Rustのariadneというライブラリを用いて表示しています。
既にVSCodeの拡張機能は公開しています。
すぐに手元のVSCodeのマーケットプレイスからお試しいただけます。
(既存のTOMLの拡張機能と競合する可能性があります)
開発言語にはRustを用いています。
LSPにも対応させる関係上、レスポンスは重要です。
Rustの高速化テクニック
パース実行時にはArcから&strを借用してコピーコストを軽減しています。
加えてallocator_apiとbumpaloを用いてO(1)でメモリを確保して、後で一斉に解放することでASTの構築にかかる時間を短縮しています。
pub fn parse_defines'input, 'allocator>(
lexer: &mut Lexer'input>,
errors: &mut VecParseError'input, 'allocator>, &'allocator Bump>,
allocator: &'allocator Bump,
) -> &'allocator Defines'input, 'allocator> {
}
高速化のための設計パターン
Arcから&strを借用すると、&strのライフタイムは単体のArcのものに限定されてしまいます。
これを回避するために内部で&'static strとArcの両方をホルダーに持たせて、使用するときにはホルダーのライフタイムに制限し直す、という解決方法をよく使用しています。
以下に実際の例を示します。
pub struct Tyml {
inner: ArcTymlInner>,
}
struct TymlInner {
source_code: ArcString>,
comments: VecRangeusize>>,
ast: &'static Defines'static, 'static>,
_allocator: BoxBump>,
...
}
impl Tyml {
...
pub fn ast'this>(&'this self) -> &'this Defines'this, 'this> {
self.inner.ast
}
...
}
ただし、これにはunsafe Rustの力を借りる必要があります。
let fake_static_ast = unsafe { transmute(ast) };
bnf_rulesで曖昧さ回避
構文を設計するにあたって、bnf_rulesという自作のパーサージェネレータを使用して、曖昧さを回避しています。
このライブラリはマクロ内にEBNF構文で書かれた文法規則を元に、コンパイル時にLR(1)パーサーを生成するライブラリです。
曖昧さがあればエラーでコンパイルが停止するため、文法を追加する際にここへ記入することで、半自動的に曖昧さのチェックを行っています。
bnf_rules! {
source ::= defines
defines ::= [ lf ] { define ( lf | "," [ lf ] ) }
define ::= documents ( element_define | type_define )
documents ::= { r"(###|///)[^\n\r]*(\n|\r|\r\n)" }
element_define ::= ( literal | "*" ) [ lf ] type_or_value
type_or_value ::= element_type [ default_value ] | default_value | inline_type_define
...
literal ::= r"\w+"
lf ::= r"\n|\r|\r\n"
}
いつかJsonSchemaを追い越せるようにこれからも開発を続けていきますので、よろしくお願いします。
気が向いたら試していただければ幸いです。
また、リポジトリの方はスターをいただけると大変励みになりますのでよろしくお願いします。
Views: 0

{kind=link}