
こんにちは。サイボウズ株式会社、生産性向上チームの平木場(@korosuke613)です。今回は Claude Code Action を全社で利用するために構築した基盤について紹介します。構築した基盤はベータ版としてアーリーアダプタにフィードバックをもらいながら改善をしているフェーズです。
本家 Claude Code Action をそのまま使うのではなく、なぜ独自システムを構築したのか、そしてどのような特徴があるかなどを紹介します。
本記事の想定読者です。
- 大規模な組織で Claude Code Action を導入したいが、次のような考慮事項が存在している
- セキュリティやログ管理の要件がある
- 利用者ごとのクォータを設定したい
- 利用開始ハードルを下げたい
- AWS を完全に理解している
生産性向上チームでは社内の開発生産性向上のために様々な基盤の整備や技術支援を行なっています。最近はさまざまな AI コーディングツールが登場しており、うまく使うことで開発生産性を向上させることができると考えています。
昨今様々なリモートコーディングエージェントツールが登場していますが、個人的には Anthropic 社の Claude Code Action に注目しています。GitHub Actions のワークフローに組み込めることから、一人のコントリビューターとしてだけでなく、プログラマブルにリモートコーディングエージェントを活用できるため、業務フローや CI/CD に対して AI の組み込みが可能となり、さらなる生産性向上を期待できるからです。そこで、Anthropic 社の Claude Code Action を広く手軽に社内で利用できる基盤を整備しようとなりました。
なお、スピード感を持って基盤構築をするために「AI 開発生産性爆アゲ業務ソン」と銘打って 2025/07/22–24 の 3 日間、次の 2 チームで活動しました。
-
リモートコーディングエージェント基盤開発
Claude Code Action を AWS 基盤込みでシュッと使える基盤を開発する -
AI Gateway 基盤開発
開発者が LLM モデルを各種プロバイダーとの契約なしにシュッと使える基盤を開発する
今回は前者のリモートコーディングエージェント基盤開発についての話になります。後者については AI Gateway を AI 開発生産性爆アゲ業務ソンで実装した話 をチェックしてください。
本記事では、組織で Claude Code Action を安全かつ効率的に利用するために構築した基盤について紹介します。
なぜ独自基盤が必要だったのか?
Claude Code Action をそのまま使うと、次の課題があります。
- 利用者ごとに Anthropic API 契約や GitHub App 作成が必要で利用開始のハードルが高い
- セキュリティポリシーの強制や実行ログの一元管理ができない
- 利用者ごとのクォータ制御ができずクラウド破産のリスクがある
基盤で実現したこと
-
利用開始の簡単化
- kintone アプリでの利用申請により、AWS 契約と GitHub 認証を一元化
- 申請から利用開始までを半自動化
-
セキュリティと運用管理の自動化
- reusable workflow によるセキュリティポリシーの強制
- Amazon Bedrock を活用した実行ログの一元保存・分析
-
コスト管理
- リポジトリごとの推論プロファイル作成によるクォータ制御
- GitHub Actions 上でのリアルタイムクォータチェック
Claude Code
Claude Code は、Anthropic の Claude AI をコマンドライン環境で利用できる公式 CLI ツールです。ターミナルから直接 Claude と対話し、コードの生成・編集・レビューなどを行うことができます。
Claude Code Action
Claude Code Action は、Claude Code を GitHub Actions 上で実行するためのワークフローです。Issue やプルリクエストのコメントをトリガーにして、リポジトリ上で自動的に Claude AI が動作し、コードの変更や提案を行います。
動作の流れ:
- GitHub Issue / PR で
@claudeでコメント - GitHub Actions ワークフロー実行
- Claude AI がリポジトリのコンテキストを理解
- 要求された作業(コード修正、レビュー等)を実行
- 結果をコメントやコミット・ブランチ作成として返す
また、最近入った mode: agent を使うと、workflow_dispatch や schedule トリガーでも動作可能になり、プログラマブルに Claude Code を利用できます。
似たツールに GitHub Copilot Coding Agent があります。Coding Agent は GitHub Copilot を契約している場合に使えるリモートコーディングエージェントです。Claude Code Action と似たようなツールですが、課金体系に大きな違いがあると言えます。
組織的に Claude Code Action を使って各々の生産性を向上させるためには、いくつかの考慮点があります。
自分は社内でのびのびと Claude Code Action を使ってもらえるように必要な要素を次だと考えました。
- 利用開始ハードルが低い
- セキュリティが自動で担保されている
- 実行ログが保持されている
- クラウド破産を防止する仕組みがある
利用開始ハードルを低くするために
利用者が利用開始をする上で一番のネックになるのは Anthropic API の契約と GitHub 認証方法の用意だと考えました。
Anthropic API の契約を一元化する
Claude Code Action を利用するには Claude API にアクセスする必要があります。主な方法は次の 4 つになります。
- Claude Pro/Max を契約
- Anthropic API を契約
- Amazon Bedrock を契約
- Google Vertex AI を契約
Claude Pro/Max は個人向けのサブスクリプションで、OAuth トークンを発行することで定額で利用できますが、個人にひもづくことから組織での利用には適していません。
Anthropic API は、最新の機能にアクセスできるものの、API キーの管理が必要で、API キーの作成の自動化ができない、利用料制限ができない、利用ログを残せない、登場したばかりでノウハウが少ないなど、やはり組織での利用には適してないと考えます。
Amazon Bedrock は AWS のサービスで、実行ログの保存、OIDC による認証、他の AWS サービスとの連携が可能です。AWS 上でワークロードを構築することで、クォータやセキュリティ、監査ログの要件を満たすことができます。
Google Vertex AI は Google Cloud のサービスですが、あまり使っておらず、詳しく調べていません。AWS と同等の機能は提供されているかなと思いますが、実際の運用経験がないため、ここでは触れません。
組織的に利用する場合は Amazon Bedrock、あるいは Google Vertex AI を利用するのが良いかと考えます。
GitHub 認証方法を一元的に用意する
Claude Code Action が Issue にコメントしたりコードをプル、プッシュしたりするためには GitHub への認証が必要です。
GitHub への認証方法には主に次の 4 つがあります。
- Claude GitHub App を利用する
-
GITHUB_TOKENを利用する - GitHub App を作成・利用する
- Personal Access Token を作成・利用する
この中で、Claude 公式の GitHub App を利用するのが最も簡単ですが、これは Anthropic 社に GitHub リポジトリの権限を与えることになります。Anthropic 社は社内の GitHub リポジトリへの読み書きができてしまうことになるため、セキュリティ上の懸念があります。
また、Personal Access Token はユーザーにひもづくトークンであるため、複数人で開発するリポジトリの GitHub Actions では使いたくありません。長命であることも使いたくない理由の 1 つです。
そうなると残ったのが GITHUB_TOKEN と独自の GitHub App 作成になります。
GITHUB_TOKEN はワークフロー上で権限を設定でき、事前の用意が不要で、短命と多くのメリットがありますが、仕様上 GITHUB_TOKEN の権限でプッシュされたコミットは他の GitHub Actions ワークフローをキックしません。そのため、Claude Code Action にコードを書かせてもそれに対する CI/CD が走らず、不便です。
独自の GitHub App は権限を細かく設定できますが、もちろん GitHub App の作成が必要で、GitHub App の秘密鍵を安全に保管する必要があり、これまた用意が面倒です。
ここまでをまとめると、次のようになります。
| 方法 | メリット | デメリット |
|---|---|---|
| Claude GitHub App | ・設定が最も簡単 | ・Anthropic社がリポジトリへの認証情報を握る |
GITHUB_TOKEN |
・事前設定不要 ・短命トークン ・ワークフローワイルで権限設定可能 |
・他のワークフローをトリガーしない |
| 独自GitHub App | ・権限を細かく設定可能 ・組織管理しやすい |
・事前準備が必要 ・秘密鍵の安全な保管が必要 |
| Personal Access Token | ・権限を細かく設定可能 ・利用方法がシンプル |
・ユーザーにひもづくため複数人開発に不適切 ・長命トークン |
組織的に使う場合、Claude GitHub App、Personal Access Token は避けたいです。GITHUB_TOKEN は準備が楽ですが、デメリットが大きいです。となると最終的には独自の GitHub App を作成するのが総合的に良さそうです。
しかし、利用者がそれぞれ独自の GitHub App を作成するのは手間がかかる上に Organization 管理者による作業が必要で面倒です。
利用者の手間を減らすために、共通の GitHub App を用意することが考えられます。Claude Code Action 呼び出し前にうまく共通の GitHub App で認証する仕組みがほしいですね。
セキュリティを自動で担保するために
社内ルールやセキュリティポリシーが存在する場合、Claude Code Action に対する制限をかけたいかもしれません。(例:許可したホストのみ通信可能にする、disallowed_tools で必ず特定のツールを禁止する)
組織の利用者に対して anthropics/claude-code-action を直接実行させずに、custom action や reusable workflow でオリジナルのアクションをラップしたものを提供することで、セキュリティポリシーを強制できます。
実行ログを保持するために
法的要件や内部統制への対応が必要な場合、すべての実行ログを一元的に保存したくなります。GitHub Actions のログは決められた保持期限がありますし、横断的に検索することは困難です。
先で紹介した Bedrock や Vertex AI を利用して、実行ログを S3 や BigQuery に保存する方法や、GitHub Actions のログを必ずどこかへ送信する方法などで実現できます。もし GitHub Actions 上でログを保存する場合はこれまた先で紹介した custom action や reusable workflow によるラップが有効です。
クラウド破産を防止するために
利用者が使いすぎてクラウド破産を免れるために、何らかのクォータを設定し、クォータを超える場合は使えないようにする仕組みが必要です。
全体のクォータ、あるいは利用者ごとのクォータを設定することが考えられます。全体のクォータについてはプラットフォーム側で予算上限を超えそうな場合に通知を飛ばすなど標準機能で解決できる場合が多いと思います。しかし、利用者ごとのクォータを設定する場合は工夫が必要になります。
利用者ごとのクォータを実現するには利用者ごとに使用量が計測できなければいけません。Amazon Bedrock や Google Vertex AI では推論プロファイル/エンドポイントを利用者ごとに用意することで、利用者ごとに使用量を計測できると考えます。
また、クォータを超えた場合に実行させないようにできる必要があります。これは即座に実行を止めたいか、あるいは anthropics/claude-code-action 実行前にクォータチェックを行い、クォータを超えている場合は実行しないようにするかの 2 パターンが考えられます。
前者は実装が面倒そうだと思ったので詳しくは考えていません。後者に関しては、custom action や reusable workflow でのラップで実現可能です。
上記の考え事を踏まえて、社内向けに anthropics/claude-code-action をラップした reusable workflow、および、利用のための基盤を開発しました。
開発方針
- 利用者が簡単に利用開始できるようにする
- 単一の専用 AWS アカウントで契約を一元化
- 専用の GitHub App をあらかじめ用意
- kintone アプリで利用リポジトリを申請・管理
- 自由度の高い利用ができるようにする
- GitHub 認証方法の選択肢を用意
- 専用の GitHub App or
GITHUB_TOKENor リポジトリ管理者用意の GitHub App
- 専用の GitHub App or
- オリジナルの Claude Code Action と同じ inputs を用意
- GitHub 認証方法の選択肢を用意
- ログ保存・分析ができるようにする
- Amazon Bedrock の推論プロファイルをリポジトリごとに用意
- Amazon Bedrock のログ機能を用いて実行ログを S3 に保存
- リポジトリごとにクォータを設定できるようにする
- Claude Code Action 実行前にクォータ超過をチェックして、超過している場合は実行しない
- reusable workflow で Claude Code Action をラップ
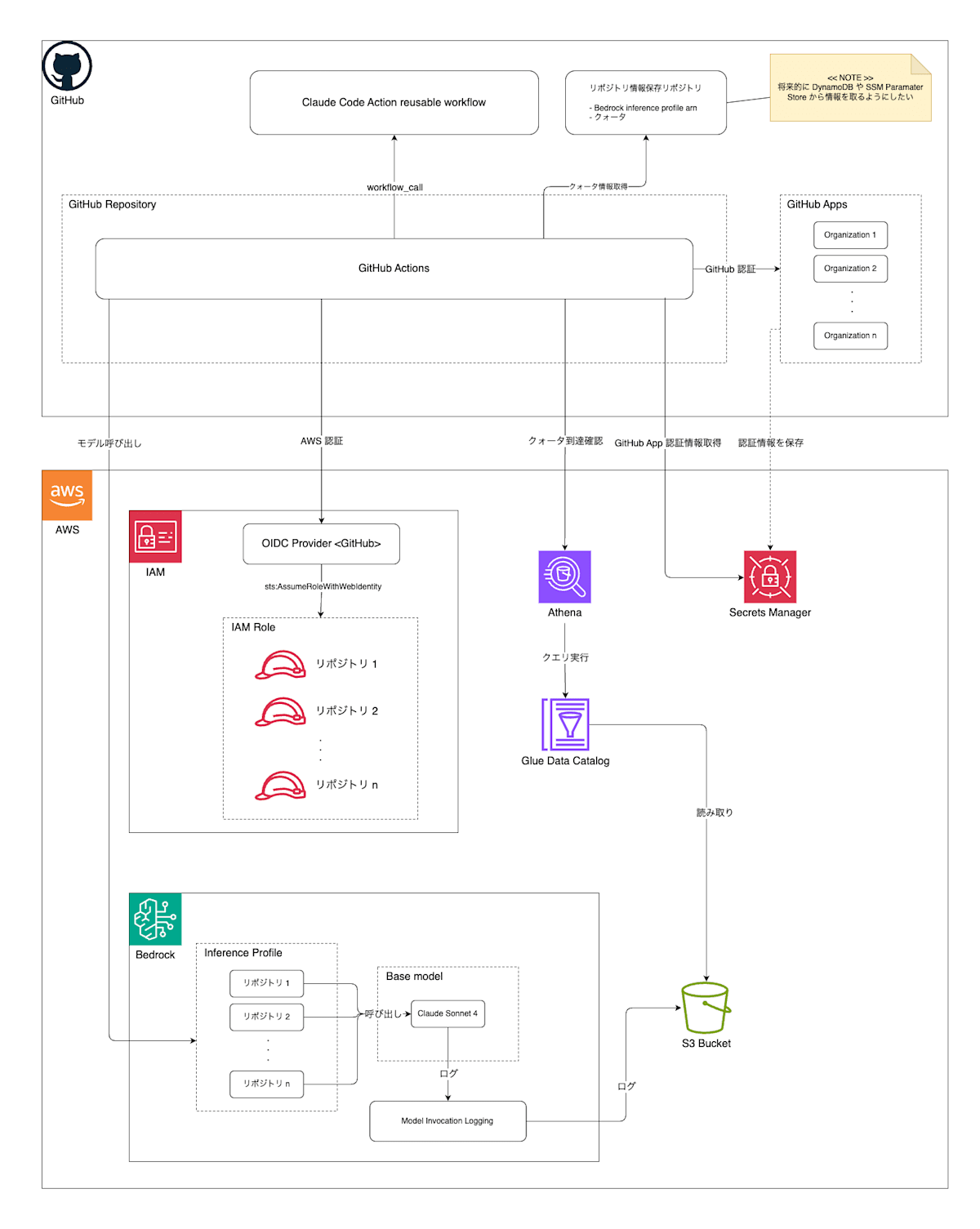
アーキテクチャ
基盤のおおまかなアーキテクチャは次のようになっています。
利用フロー
ユーザーが @claude してから完了までのおおまかなフローです。
認証の一元化
Claude Code Action を利用するには Anthropic API(via Amazon Bedrock)を使うための AWS への認証と対象リポジトリを操作するための GitHub への認証が必要です。
AWS 認証
今回、生産性向上チームで新たに作成した単一の AWS アカウントを使うことにしました。これにより利用者は新たに AWS アカウントを作ったり契約したりする必要がありません。
GitHub Actions から AWS へ認証するにはいろいろな方法がありますが、選択肢の中で最もセキュアだと考えられる OIDC、および、aws-actions/configure-aws-credentials を使った認証方法を採用しました。
次のような信頼関係を持つ IAM Role をリポジトリごとに作成し、リポジトリ名に合わせて aws-actions/configure-aws-credentials に渡す IAM Role ARN を自動的に切り替えるようにしています。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "arn:aws:iam:::oidc-provider/token.actions.githubusercontent.com"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"token.actions.githubusercontent.com:aud": "sts.amazonaws.com"
},
"StringLike": {
"token.actions.githubusercontent.com:sub": [
"repo:/:job_workflow_ref:/claude-code-action-workflow/.github/workflows/claude-code-action.yaml@*"
]
}
}
}
]
}
OIDC の条件を定める subject claim に当たる token.actions.githubusercontent.com:sub ではリポジトリ名を repo で、reusable workflow の ref を job_workflow_ref で指定しています。実は job_workflow_ref には呼び出し元ワークフローの ref ではなく reusable workflow の ref が入ります。repo のみの条件の場合、ユーザーの任意のワークフローで AWS へ認証できてしまうため、自由な API 実行を許可してしまいます。今回クォータチェックは GitHub Actions 側で行っているため、クォータチェックを回避できてしまうことから、reusable workflow の ref も条件に入れています。
GitHub 認証
次は GitHub の認証です。先に述べた通り、GitHub App と GITHUB_TOKEN の 2 つの認証方法のみサポートするようにしました。さらに、GitHub App は我々が用意したものと、利用者が用意したものの 2 つを選択できるようにしています。
困ったのがどのように秘密鍵を保管するかでした。最初は GitHub Actions の Organization Secrets や Repository Secrets に保存することを考えましたが、organization owner や repository admin の作業負担が増えることと、秘密鍵へアクセスできる人物が増えて退職者管理が面倒になることから、AWS Secrets Manager に保存することにしました。
repository owner から organization を特定し、対象の secrets manager から秘密鍵を取得、actions/create-github-app-token を使ってアクセストークンを生成するようにしています。
また、GitHub App をインストールしている他のリポジトリへのアクセスを防ぐため、actions/create-github-app-token では with.owner、with.repositories でリポジトリを指定するようにしています。
- id: create-github-app-token
uses: actions/create-github-app-token@v2
with:
app-id: ${{ steps.setup-github-credentials.outputs.app_id }}
private-key: ${{ steps.setup-github-credentials.outputs.private_key }}
owner: ${{ github.repository_owner }}
repositories: ${{ github.event.repository.name }}
また、他のリポジトリへのアクセス許可を与えたいや、他の権限を与えたいなど、柔軟に GitHub の権限を渡したい利用者向けに、利用者作成の GitHub App を利用できるオプションも用意しています。
実行ログの一元保存&分析のための準備
実行ログは Bedrock の Model Invocation Logging 機能を使って S3 に保存するようにしています。というかそれ以外の AWS 側でのログ保存方法は無さそうです。
Claude Code Action 実行のたびに S3 には次のような JSON が保存されます。
{
"timestamp": "2025-08-07T02:48:23Z",
"accountId": "",
"identity": {
"arn": ""
},
"region": "",
"requestId": "c448be01-5f60-4d31-8049-xxxxxxxxxxxx",
"operation": "InvokeModelWithResponseStream",
"modelId": "arn:aws:bedrock:::application-inference-profile/",
"input": {
"inputContentType": "application/json",
"inputBodyS3Path": "" ,
"inputTokenCount": 3,
"cacheReadInputTokenCount": 0,
"cacheWriteInputTokenCount": 28857
},
"output": {
"outputContentType": "application/json",
"outputBodyJson": ,
"outputTokenCount": 142
},
"inferenceRegion": "us-east-2",
"schemaType": "ModelInvocationLog",
"schemaVersion": "1.0"
}
大事なのは利用者を特定する modelId(inference profile arn)と利用料を計算するのに必要な input.inputTokenCount、input.cacheReadInputTokenCount、input.cacheWriteInputTokenCount、output.outputTokenCount です。これらの情報を元に、各リポジトリでどれくらいのトークンを使ったか、どれくらいのコストがかかったかを計算できます。
また、output.outputBodyJson には Claude Code が出力する JSON が保存されます。Claude Code Action 実行中に出てくる JSON 形式のログそのものが入っています。実行ログを分析したい場合はここを見ることになります。
S3 に保存されるログは AWS Glue、Amazon Athena で分析できるので、分析できる状態にします。
まずはログの JSON を元に Glue Table を作成します。
CREATE EXTERNAL TABLE `bedrock_logs_original`(
`schematype` string,
`timestamp` string,
`region` string,
`identity` structarn:string>,
`operation` string,
`modelid` string,
`requestid` string,
`schemaversion` string,
`input` structinputbodys3path:string,inputtokencount:string,cachewriteinputtokencount:string,inputcontenttype:string,cachereadinputtokencount:string>,
`output` structoutputcontenttype:string,outputbodyjson:string,outputtokencount:string>
)
PARTITIONED BY (
`datehour` string
)
ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'case.insensitive'='true',
'ignore.malformed.json'='true'
)
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3:///AWSLogs//BedrockModelInvocationLogs/us-west-2/'
TBLPROPERTIES (
'numFiles'='0',
'numRows'='0',
'projection.datehour.format'='yyyy/MM/dd/HH',
'projection.datehour.interval'='1',
'projection.datehour.interval.unit'='HOURS',
'projection.datehour.range'='2025/07/29/00,NOW',
'projection.datehour.type'='date',
'projection.enabled'='true',
'storage.location.template'='s3:///AWSLogs//BedrockModelInvocationLogs/us-west-2/${datehour}/'
)
ログのオブジェクトは /AWSLogs//BedrockModelInvocationLogs//
に保存されます(yyyy は西暦 4 桁、MM は月 2 桁、dd は日 2 桁、HH は 0-23 時までの時間 2 桁を表します)。したがって、yyyy/MM/dd/HH の形式でパーティションを作成することで日時に関するクエリを効率的に実行できます。
また、ディレクトリによっては /AWSLogs//BedrockModelInvocationLogs//
というように data ディレクトリが存在します。あったりなかったりするのでどういう条件でできるのかよくわかっていませんが、ここには実行ログの JSON が入っています。スキーマが全く異なり、クエリ実行時にエラーを吐く原因となるため、data ディレクトリを除外するビューを作成しておきます。
CREATE VIEW bedrock_logs AS
SELECT *
FROM bedrock_logs_original
WHERE "$path" NOT LIKE '%/data/%'
このビューに対してクエリを実行することで様々な分析が可能となります。
クォータチェック
先で作ったビューに対して次のクエリを実行することで、過去 n 時間のトークン使用量を取得できます。今回は過去 1 時間を例として説明します。
トークン使用量取得クエリ
SELECT
SUM(CAST(input.inputtokencount AS BIGINT)) AS input_tokens,
SUM(CAST(output.outputtokencount AS BIGINT)) AS output_tokens,
SUM(CAST(input.cachereadinputtokencount AS BIGINT)) AS cache_read_tokens,
SUM(CAST(input.cachewriteinputtokencount AS BIGINT)) AS cache_write_tokens
FROM bedrock_logs
WHERE datehour >= format_datetime(current_timestamp - INTERVAL '1' HOUR, 'yyyy/MM/dd/HH')
AND from_iso8601_timestamp(timestamp) >= current_timestamp - INTERVAL '1' HOUR
AND modelid = 'arn:aws:bedrock:::application-inference-profile/'
結果例
| # | input_tokens | output_tokens | cache_read_tokens | cache_write_tokens |
|---|---|---|---|---|
| 1 | 205 | 14778 | 1518457 | 97613 |
この例では、指定した inference profile(≒リポジトリ)において、過去 1 時間で入力トークンが 205、出力トークンが 14778、キャッシュ読み取りトークンが 1518457、キャッシュ書き込みトークンが 97613 使用されたことが示されています。
この値を元にコスト計算をし、クォータ超過確認をします。
コスト表とクォータ設定は別リポジトリで管理しています。ちなみに、クォータ設定は kintone アプリで管理し、スケジュール実行で同期するような仕組みにしています。
price.json
{
"$schema": "./price.schema.json",
"models": {
"us.anthropic.claude-sonnet-4-20250514-v1:0": {
"input_token_usd_per_1000": 0.003,
"output_token_usd_per_1000": 0.015,
"cache_read_usd_per_1000": 0.0003,
"cache_write_usd_per_1000": 0.00375
},
"us.anthropic.claude-3-5-haiku-20241022-v1:0": {
"input_token_usd_per_1000": 0.0008,
"output_token_usd_per_1000": 0.004,
"cache_read_usd_per_1000": 0.001,
"cache_write_usd_per_1000": 0.00008
}
}
}
users.json
{
"$schema": "./users.schema.json",
"inference_profile": {
"arn:aws:bedrock:::application-inference-profile/": {
"base_model_inference_profile_id": "us.anthropic.claude-sonnet-4-20250514-v1:0",
"github": {
"org": "" ,
"repo": ""
},
"quota": {
"enabled": true,
"limit_usd_hour": 3
}
},
...
}
}
この price.json、users.json と過去 1 時間のトークン使用量を元にコストを計算します。
先に示した例だと、次のような計算になります。
- 入力トークン: 205 * 0.003 / 1,000 = 0.000615 USD
- 出力トークン: 14,778 * 0.015 / 1,000 = 0.22167 USD
- キャッシュ読み取りトークン: 1,518,457 * 0.0003 / 1,000 = 0.4555371 USD
- キャッシュ書き込みトークン: 97,613 * 0.00375 / 1,000 = 0.36604875 USD
- 合計: 1.04 USD(少数第三位で四捨五入)
どうやらこのリポジトリでは過去 1 時間で 1.04 USD 使ったようですね。余裕でクォータ内です。
こういった計算を Claude Code Action 実行前に行うことで、クォータ超過を防止します。
クォータチェックを Athena のクエリ実行で実現しているのは、Bedrock のネイティブ機能では利用者ごとの時間単位のクォータ設定ができないことと、CostExplorer は料金反映に時間がかかることためです。また、Claude の API 呼び出し前にクォータチェックを行うために GitHub Actions ワークフローに組み込んでいます。
社内 Claude Code Action 基盤を利用するための準備について説明します。ユーザーが利用申請を行い、基盤側で AWS リソースを作成し、最後にユーザー側で簡単な設定作業を行います。
従来であれば利用者が次の作業を個別に行う必要がありました。
- AWS アカウントの作成・契約
- Anthropic API の契約
- GitHub App の作成・設定
- 各種認証情報の管理
基盤利用により、利用者が入力するのは次の 3 つの情報のみになります。
- GitHub Organization 名
- GitHub Repository 名
- 時間あたりの利用上限金額(USD)
本基盤を利用することで、利用者の作業は次のように削減されます。
| 項目 | 従来 | 基盤利用後 |
|---|---|---|
| AWS契約 | 各自で契約・支払い設定 | 不要(一元化済み) |
| API契約 | Anthropic API個別契約 | 不要(Bedrock経由) |
| GitHub App | 個別作成・権限設定 | 不要(共通App利用) |
| 認証情報管理 | 各自でSecrets管理 | 2つのAPIコマンド実行のみ |
| 利用開始までの時間目安 | 数日〜1週間 | 申請から半日〜1日程度 |
だいたいの流れは次のようになります。
なお、利用申請、および、ユーザー管理には kintone を利用しています。利用申請がされると、半自動的にインフラリソース構築のためのプルリクエスト(Terraform)が作られるため、管理側である我々はオペレーションミスの低減、および対応速度の向上が図れています。
まだまだこの利用開始フローは改善できる点が多いため、今後もっと良くしていきたいです。
セキュリティルールの整備
ユーザー向けマニュアルにセキュリティルールを用意しています。利用する上で見るべき社内外のドキュメントや利用禁止項目をまとめています。
利用禁止項目の一例です。一般的なもののみ挙げます。
- 🚫 GitHub Actions Secrets 読み取り権限付与(
secrets: read/write) - 🚫 GitHub Actions Workflow 変更権限付与(
workflows: write) - 🚫 デフォルトブランチ・デプロイを伴うブランチで自由に push、マージできる状態になっている(対策:ruleset で保護するようにする – force push 禁止、プルリクによるマージのみ許容、削除保護など)
また、reusable workflow という性質上、allowed_tools、disallowed_tools に渡す値を制限したり、追加したりすることも可能です。例:WebFetch を全く使えないようにするために disallowed_tools に含める。
週次・月次レポートの自動生成
利用者、および、我々がどれだけ社内 Claude Code Action が利用されてるかを簡単に把握できるように、週次・月次レポートを Issue として自動生成しています。
本当は Amazon QuickSight などの BI サービスでリッチに可視化したい気持ちもありますが、料金的にも手間的にも安上がりにするために現在は Issue でのレポートにしています。
実際に生成されるレポートは次のような感じです。
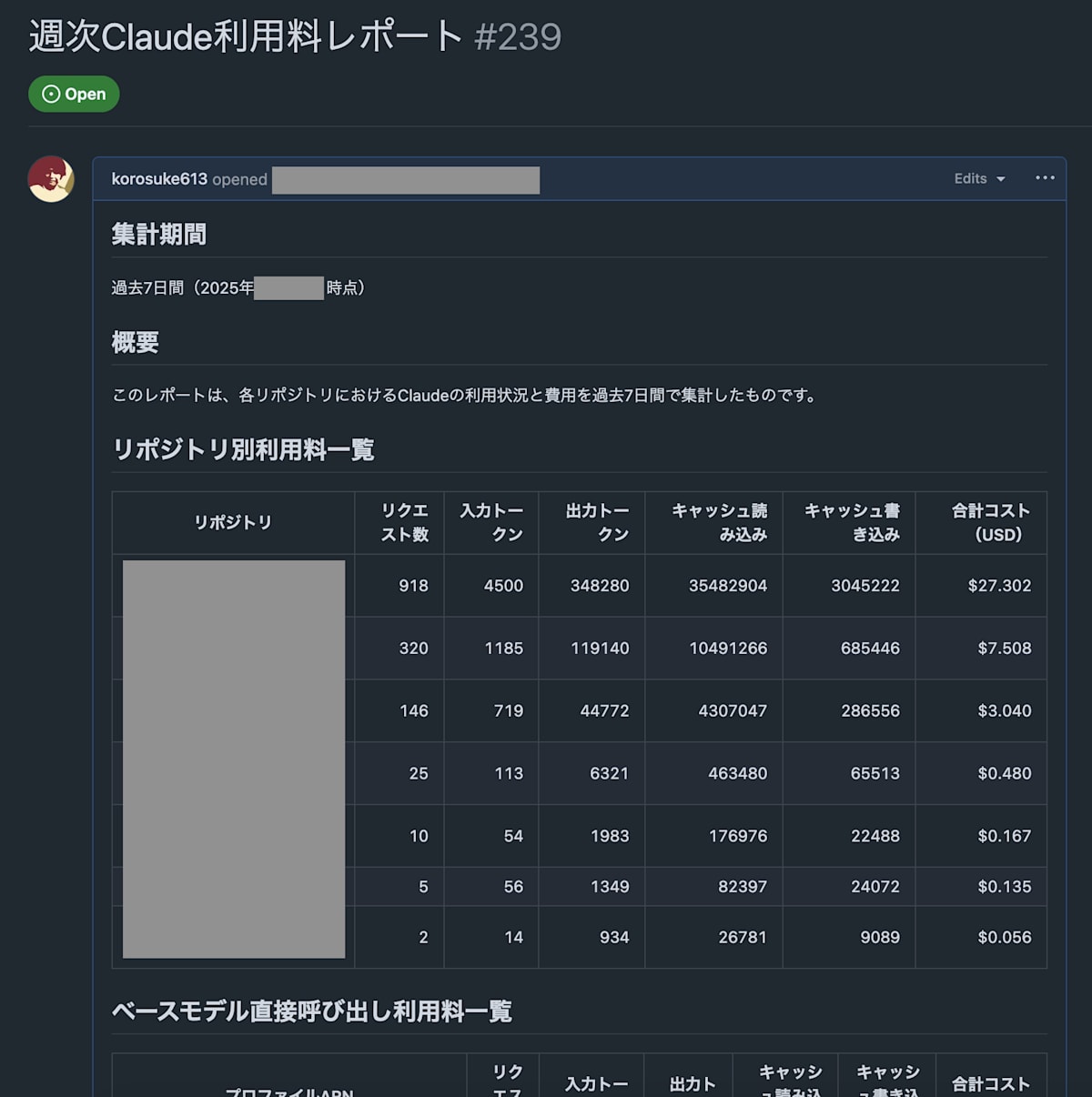
過去 1 週間分のリポジトリ別利用料例
GitHub Actions 上で次のようなクエリを実行して、各リポジトリの利用料を集計、整形し、Issue 本文を更新するという感じです。
SELECT
modelid,
SUM(CAST(input.inputtokencount AS BIGINT)) as total_input_tokens,
SUM(CAST(output.outputtokencount AS BIGINT)) as total_output_tokens,
SUM(CAST(input.cachereadinputtokencount AS BIGINT)) as total_cache_read_tokens,
SUM(CAST(input.cachewriteinputtokencount AS BIGINT)) as total_cache_write_tokens,
COUNT(*) as request_count
FROM bedrock_logs
WHERE datehour >= format_datetime(current_timestamp - INTERVAL '7' DAY, 'yyyy/MM/dd/HH')
AND from_iso8601_timestamp(timestamp) >= current_timestamp - INTERVAL '7' DAY
GROUP BY modelid
anthropics/claude-code-base-action にも対応
当初、 anthropics/claude-code-action は issue comment、pull_request comment にのみ対応していたため、workflow_dispatch や scheduled で実行するには別に存在する anthropics/claude-code-base-action を利用する必要がありました。
プログラマブルに活用できるために workflow_dispatch や scheduled での実行は不可欠だったため、claude-code-base-action 用の reusable workflow も用意していました。
しかし、最近、anthropics/claude-code-action がエージェントモード(mode: agent)を追加し、workflow_dispatch や scheduled に対応したため、必ずしも anthropics/claude-code-base-action を利用する必要がなくなりました。
base action の reusable workflow は一応残していますが、今後無くしていく予定です。
間違いのないコスト分析ができるように inference profile に コスト配分タグを設定
Amazon Bedrock でモデル呼び出しにかかったコストを Cost Explorer で分析するためには、inference profile にコスト配分タグを設定する必要があります。
本基盤ではクォータチェックの節で書いたように、Athena でログ分析をすることでコスト分析は可能です。しかし、呼び出し単価の変更やバグなどで計算が間違ってしまう可能性を否定できません。本当にかかった額を正確に把握するためには Cost Explorer でも分析できるに越したことはないです。
inference profile は利用リポジトリごとに作成しているので、オーナー、リポジトリ名をそれぞれタグ付けし、コスト配分タグに指定しています。これにより、Cost Explorer でもリポジトリごとのいくら使ったかすぐに把握できます。
まだまだベータ版で社内フィードバックをもらっている段階なのもあり、課題が盛りだくさんです。
- anthropics/claude-code-action の更新についていくのが大変
- 更新頻度が高く、仕様変更も多い(破壊的変更は少なめだが)
- Renovate で PR は作成させているが、把握が困難なので Claude Code にレビューと新機能対応もさせたりしている
- セキュリティと利便性のトレードオフ
- セキュリティを重視すると、利用者の利便性が下がることがあるため、どこまでセキュリティを重視するかの判断が難しい
- public リポジトリ対応する?
- public リポジトリでの利用は考えることが多く、現状別途 Anthropic API を契約してもらい、本家を使う方法が無難
- 真面目に考えたらプロンプトインジェクションリスクを低くするのがむずそうで、会社の public リポジトリで使うのは厳しいのでは?となってる
- public リポジトリでの利用は考えることが多く、現状別途 Anthropic API を契約してもらい、本家を使う方法が無難
- GHES 対応する?
- GitHub Enterprise Server 向けには作ってないので現状 GHES では利用できない
- 特にイントラネット上に GHES があると OIDC が無理ゲーに近い。Google Cloud は回避策があるが、調べた限り AWS ではその回避策が使えない
- 最近 Bedrock が API キーの吐き出しに対応したので方法は増えてきてるかも
- GitHub Enterprise Server 向けには作ってないので現状 GHES では利用できない
- 社内 LLM API キー発行基盤で発行した API キーの活用
- 同じく開発生産性爆アゲ AI 業務ソンで作られた社内 LLM API キーを活用することで Amazon Bedrock は必要なくなるが、社内 LLM API キー発行基盤はまだクォータ設定できなかったりベータ状態なので、要件が満たされたら今後活用できるようにしたい
- もっと利用者が Claude Code Action を活用しやすくするために活用事例を増やす・共有する
- Claude Code Action は便利ではあるが、まだまだ使い方を模索中であり、活用方法がわからない人も多い。どんどん活用事例を増やしていきたい
- 生産性向上チームでの活用事例
- Issue のプランニングや調査、プルリクエストの実装
- コードレビュー
- Renovate の PR が作られたら自動でレビュー
- 毎日の定時に昨日からの main ブランチの差分を読ませ、どういう変更があったかレポートさせる
開発生産性 AI 業務ソン + αで社内 Claude Code Action 基盤を作りましたが、これの開発にも多分に AI の力を借りました。特にクォータチェック用の Go のコードや、Athena のクエリ、その他もろもろだいぶ AI に最初のコードを書いてもらいました。やっぱり便利ですね。
現在この基盤は社内でベータという扱いにしており、アーリーアダプターを見つけてフィードバックをもらいながら改善を進めているフェーズです。まだまだリモートコーディングエージェント、および、本基盤が役に立つものなのかはわからないので、早めにどんどん社内フィードバックを得て、今後の判断につなげたいですね。実は無くても良いと判断したら普通に撤退します。
でも正直うまく活用してもらうことへの難しさを感じています。まずは使いやすい環境を用意しましたが、どのように使うと便利かはあまりまだ提示できてないため、もっと活用方法を広げていく必要があると思っています。なぜリモートで動くと嬉しいのかをしっかりと示す必要もあるかなと思っています。
あまり Claude Code Action 自体はちょくちょくブログ記事なんかも出てますが、あまり組織的に使う事例を見なかったので今回本記事を執筆しました。コメントとかあればどしどしご連絡ください。
Views: 0

{kind=link}