
株式会社イルシル様の依頼で、フロントエンドの近代化とパフォーマンス分析を行った事例を紹介します。
「イルシル」は、生成AIでスライド資料作成を自動化し、誰でも簡単にスライドやパワポが作れるサービスで、スライドのデザインは1,000種類以上あり、入力したテキストからスライドを自動生成できるだけでなく、オリジナルで作成することも可能です。
いわゆる、複雑フロントエンドの事例です。ブラウザ上でAI経由でスライドを生成して、それをUIから編集でき、最終的には PDF や パワーポイントとしてエクスポートします。
LCP や CLS ではなく、 TBT やメモリリークの調査がメインになります。
長くなったので最初に要約します。以下の内容を含みます。
- 泥臭い CRA => Vite 移行
- Chrome DevTools によるメモリリークの調査
- バンドル結果の静的チャンク分析
- リファレンス実装を用意してClineにやらせる
- Cypress => Playwright
- jest => vitest
本記事は、実際に複合的にコード改修とパフォーマンス改善をすると何をやることになるか、という話です。
相談内容: ゴールの設定
AIによるスライド生成というドメインなので、巨大な管理画面でコードも複雑になっている。
パフォーマンス改善しつつ、将来的な伸びしろを担保できる状態にしたい。
プロジェクトの分析
とりあえずコードを動かして読んでいきます。
見た感じ、ライブラリが古めで、それぞれが絡まり合って段階的なアップデートが困難な状況に陥っていました。
- 基本的な構成
- create-react-app
- react
- recat-router
- recoil
- TypeScript (一部 .js)
- テスト
- Node.js はフロントエンドツールチェーンとしてのみ使用
- 特定の Node.js へのバイナリ依存がある
- 明確に deprecated になったツールチェーンへの依存
- create-react-app
- recoil
@testing-library/react-hooks
- 大部分は TypeScript だが、一部 .js が残っている
みたところ、技術的な負債として顕著なのが create-react-app, 通称 CRA です。過去に React 公式の推奨フレームワークでしたが、今現在は開発の停止が宣言されています。
CRA の実体は webpack のデフォルトプリセット集です。vite と同じように ゼロコンフィグなバンドル環境なのですが、10年前のフロントエンドの黎明期に生まれたため独自の loader が多いです。
プロジェクトの成長過程を追うと、次のような過程を踏んだように見えます。
- CRA でスキャッフォルド
- ある時点で開発環境で、特定の Node バージョンへの依存が発生
- バイナリ依存により、連鎖的にパッケージの更新が困難に
- CRA ロックインにより、エコシステム側との乖離が大きくなっている
確認したところ node-canvas は今現在は使っていないようでした。負債発生源ですが、今となっては package.json から消すだけのようです。
計測のための準備
コードの近代化とパフォーマンス改善という内容ですが、事前にある程度ツールチェーンを整理しないと計測自体が困難そうに見えました。なので、最初に計測可能な状態を作ります。
とにかく、CRA をどうにかする必要があります。 CRA を eject (CRA非依存の webpack config に変換) することで辻褄をあわせることは可能ですが、出力が膨大なことが知られています。
eject に成功したとしてもそれに価値を見出すのが難しいかもしれません。
というわけで、実現可能かはともかく、一旦 vite 化可能かの過程を踏んでみます。
- テストは一旦落として、 node を最新まで上げる
- CRA => Vite 移行したブランチを作る
- 手動テストで動作確認
- Vite ブランチで vite-bundle-analyzer で計測
- 段階的に一時的に無効化したテストを復旧
- ついでに cypress => playwright, jest => vitest を試す
最悪、一旦 vite-bundle-analyzer のチャンク分析結果を持ち帰ることができればヨシの精神です。
一応 webpack, rspack も検討しましたが、CRA の独自性を考えるとおそらくコストがそう変わらない、ならば vite でもいい、という判断をしました。
vite build を成功させる
経験的なものですが、基本的には webpack => vite として、以下を念頭に作業を行います。
- バンドラが異なってもチャンク分割処理のセマンティクスは同じ
- 最終的にやりたいのはチャンク分析と
import()によるチャンク分割になるはず
- 最終的にやりたいのはチャンク分析と
- CRA の独自部分の何を踏んだかを確認
- それ以外で問題が起きるとしたら、内部的に CJS => ESM になることによるモジュール解決部分
とりあえず vite のセットアップからやってみます。
$ rm package-lock.json
$ npm install
$ npm add vite -D
$ mv public/index.html index.html
ライブラリモードでない vite は index.html をエントリポイントにビルドを行います。
index.html には vite のエントリポイントを追記します。
index.html
script type="module" src="./src/index.js">script>
ビルドしてみましょう。
当然、ビルドできません。(注: ここのログは保存してませんでした)。盛り上がってきましたね。
ここから、 src/index.js を対象に、ソースコードをコメントアウトしながら二分探索して、問題が起きる箇所を特定します。
まずビルドを通し、その後ブラウザ上でランタイムの検証を行います。
vite: .js の JSX に対応
CRA のローダーだと .js 拡張子でも、babel を経由することで JSX リテラルを展開しています。
つまり .js 拡張子でも次のコードが処理できていました。
src/index.js
ReactDOM.render(App />, root);
vite だとこの仕組みはないので、とりあえず vite.transformWithEsbuild (実質 esbuild) を引っこ抜いて、.js を変換する loader をでっち上げます。
import { defineConfig, transformWithEsbuild } from "vite";
export default defineConfig({
resolve: { extensions: [".js", ".jsx", ".ts", ".tsx"] },
plugins: [
{
name: "transform-jsx",
transform(code, id) {
if (id.endsWith(".js")) {
return transformWithEsbuild(code, id, { loader: "jsx" });
}
},
},
],
}
本当は .js => .tsx にしたほうがいいのですが、やってみたところ大量の型違反が検知されました。既存コードのTSで書かれた範囲は妥当な状態に見えるので、割れ窓を作るよりかは、この状態を尊重した方が良さそうに見えます。
vite: .svg のローダー
CRA の仕組みで .svg を React のコンポーネントとして読み込んでいます。
これを同等の vite-plugin-svgr で書き換えます
import svgr from "vite-plugin-svgr";
export default defineConfig({
plugins: [svgr()],
});
インターフェースが違うので正規表現で一気に書き換えます。
コード例
- import { ReactComponent as Complete } from "./img/complete.svg";
+ import { default as Complete } from "./img/complete.svg?react";
svgr のオプションで ?react をつけない方法もあるのですが、vite/client の組み込みのアセットローダーの期待する型と衝突します。これをさらに修正するのも面倒で、そもそも ReactComponent => default のシンボル書き換えが必要なので、ここに関しては diff が多くなるのは仕方ないという判断をしました。
vite: 環境変数の対応 process.env.REACT_APP_
CRA のビルド時、 REACT_APP_* のプレフィックスがついた環境変数を参照できます。
vite にも同等の仕組みがありますが、 import.meta.env.VITE_APP_* に書き換える必要があります。
機械的な置換を行うと量が膨大なため、vite の define で明示的に注入することにしました。
export default defineConfig({
define: {
"process.env.REACT_APP_XXXX": JSON.stringify(process.env.REACT_APP_XXXX),
},
});
この時点でビルドは通るようになりました。このプロジェクトにおける CRA と vite の差分は、基本的に .svg と .js のローダー部分だけと言えそうです。
ランタイム修正をやっていく
ビルドできたとはいえ、実際のブラウザ上でロードしてみたところランタイムエラーで動かない箇所がありました。
これを段階的につぶしていきます。
ランタイム修正: recoil
どうやら古い recoil の Provider 周りが vite + cjs の環境で動作が怪しそうです。
特に根拠なくガチャガチャやった結果なのですが、結果的には、recoil のバージョンを最新に上げることで解決しました。
これはおそらく ESM と CJS のモジュール解決経路やシングルトンインスタンスの持ち方の問題だと思われます。
とはいえ、 recoil も開発が止まっています。今後どうするかはともかく、一旦 API が似ている jotai に移行しません?という提案をしたところ、元々検討中ということで、後で書くテストコードは jotai で書きました。
ランタイム修正: @loadable/component => React.lazy
コードを見たところ @loadable/component というライブラリを使っています。これは自分の知る限り React.lazy 導入以前に「SSRのために」チャンク処理をクライアント・サーバーで共通化するライブラリです。
ここはスタックトレースの見通しを良くするため、標準の React.lazy に置き換えました。
import { lazy } from "react";
const Login = lazy(async () => {
const { Login } = await import("../pages/Login");
return { default: Login };
});
動いているものを触るな、というのはよく言われますが、そもそもここは標準処理が提供されている中で古い非標準なライブラリを使っているケースなので、リスクは高くないと判断しました。
と、色々やってエッジケースはありつつも一通りの機能が表面的に動くようになりました
パフォーマンス分析: バンドルサイズ
ランタイム処理まで動いている、つまり必要なコードがロードに成功しているという状態なので、この状態でバンドル分析を行います。
今回は vite-bundle-analyzer を使います。
$ npx vite-bundle-visualizer
例えば こういうデータが取れます。
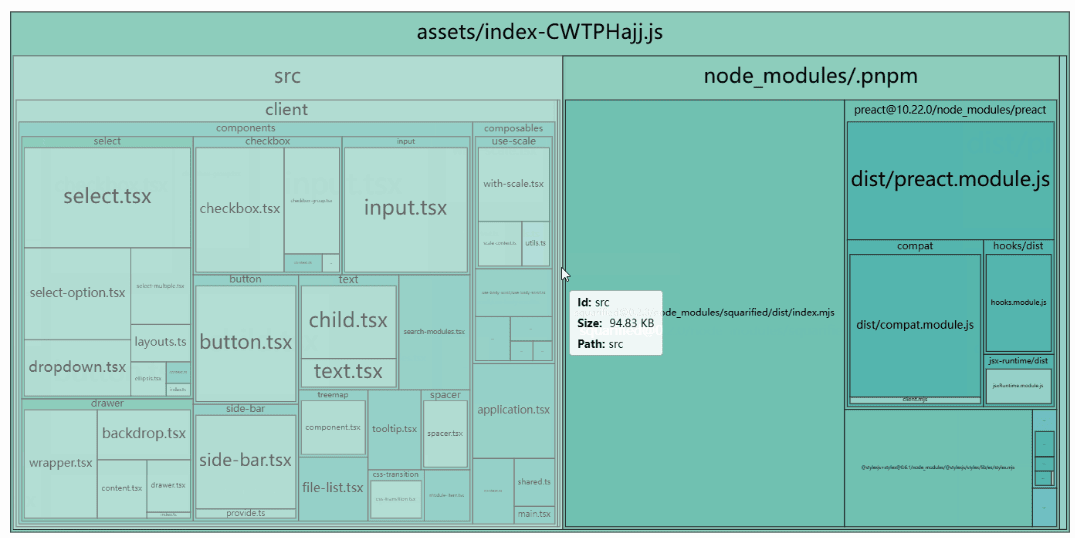
だいたい、タイルの大きさがそのままビルドサイズに比例します。
分析した結果、このような所見を得ました。
- スライド編集画面がページがすごいサイズ
- 複雑UIはそういうものという認識
- とはいえオフロードしたい
- 巨大 UI コンポーネント
- PDF 変換関連が重い
- gzip 関連
- jszip
- pako
- 標準APIでどうにかなる
そもそも複雑UIなので、サイズが大きいのは仕方ない側面があります。ただ、その上で最適化の余地が多々あり、とくに巨大なライブラリを使わないケースでも評価してCPUブロッキングを起こしてる問題は早期に解決したいですね。
巨大ライブラリをオフロードするのに、動的 import() に書き換えてランタイムで動的に分岐を書き分ける必要があります。例えばこういうやつですね。
async function load(type: "a" | "b") {
if (type === 'a') return import("./lib/a")
if (type === 'b') return import("./lib/b")
}
また、gzip 関連はライブラリに依存せずにブラウザ標準APIから使うことができます。
クロスブラウザ対応を確認しつつ Web 標準にある機能はライブラリを使わない、というのがフロントエンドのチューニングで大事な原則です。
一応この時点で Lighthouse の分析も行いましたが、基本的にはバンドルサイズによるTBTの問題で、やはりチャンク制御がパフォーマンス改善のメインになりそうです。
ランタイム分析: メモリリークの調査
スライドの枚数が増えると重くなる、という話だったので DevTools のメモリプロファイラでメモリリークの調査を行いました。開発ビルドではなく、プロダクションを対象に行いました。
プロファイラ経由のメモリ調査という難しそうですが、マイクロベンチマークでない限りは大雑把にヒープの差分を見るだけです。以下を参考に操作します。
どのようなパターンで重くなるかを事前にヒアリングしておきました。
それに対応する操作をして、そのヒープ差分を確認します。基本的に、 Chrome DevTools > Memory を開き、以下の手順を踏みます。
- Heap Snapshot をとる (Take Snapshot #)
- ブラウザ上で重くなりそうなUI操作を行う
- 再度 Snapshot をとり、操作前の Heap Snapshot と比較 (Comparsion 2 – 1)
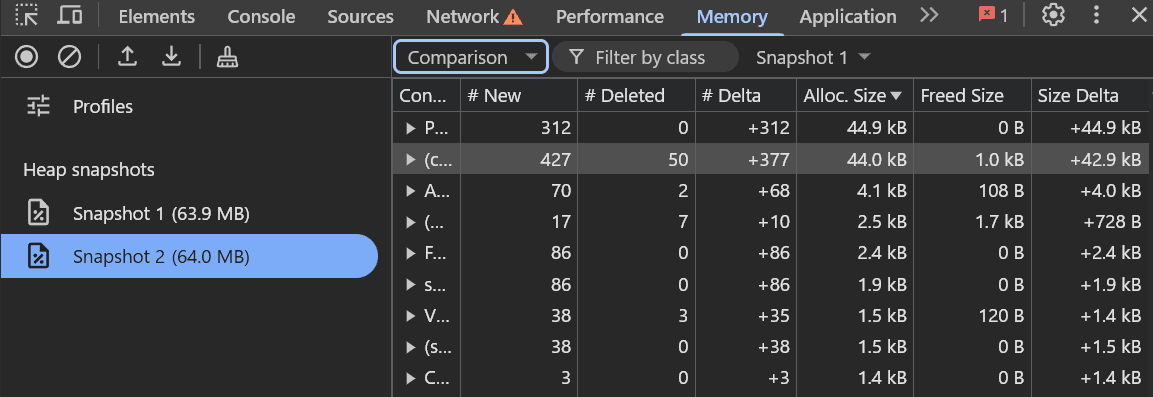
特に Size Delta を注視します。
もうちょっと詳しく言うと、段階的に細かいステップに砕いて計測しました。
- 同じ操作を何度も繰り返して、本当に重くなるかをプロファイラ上で確認
- 要素A 要素B 要素C, 要素D…と新しい要素を選択
- メモリが線形に増えるならオブジェクト数に比例した分だけヒープを消費する
- これが問題になるならリリース解法処理が必要
- 要素A 要素B を交互に選択
- メモリが増えないなら、同じ処理に対するキャッシュは効いてる
- 要素A 要素B 要素C, 要素D…と新しい要素を選択
- メモリリークが確認できたシナリオで、より小さなステップでスナップショットを比較
- Major GC に注意。何も操作せずに放置してメモリが減るなら、GC によって解放されている。
これによって機械的に何のインスタンスが増えているかはある程度判明します。
とはいえ、コードの改善にはドメイン知識が必要です。プロファイラを追うだけだとインスタンスの生成手順を確認するのが難しいですが、「そのときに何の処理を実行しているか」というドメイン知識があれば類推可能になります。
実際に今回こういうデータが観測できました。Set 型のモデルが肥大化しています。
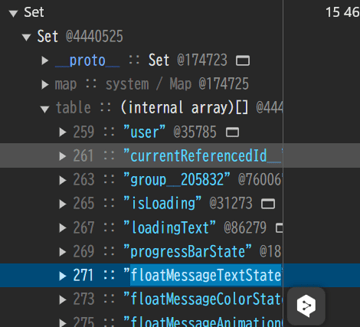
変数名もライブラリの内部変数ではなく、アプリケーション側のドメインだと推測できます。このオブジェクトを生成する箇所を終えば、問題が特定できます
問題はわかった。じゃあ次にどうするか?
今の状態を整理しましょう。
- node のメジャーバージョンとバンドラの変更というビッグバン的な変更
- それを前提とした静的解析/動的解析の問題特定
- 既存のテストは落ちている
この状態で相談したところ「一瞬開発を止めて、Vite 移行ブランチを手動テストシナリオを厚めにガッとやる」という話になりました。「我々はベンチャーなので」ということらしいです。
というわけで、vite のブランチは任せつつ、その先で落ちたテストの復旧や移植をしていきます。
テストを復旧していく
基本的に、ランタイムを正として、テスト側を追従します。
eslint の修正
落ちたものは、 eslint-config-react-app 関連のルールです。そもそもCRAが存在しなくなったので動かないのは当然と言えます。
これは単に抜くこととしました。
E2E cypress => playwright
node 本体バージョンを更新したことで cypress の E2E テストランナーが動かなくなっていました。
調査が難しい上に、 cypress 自体があまり活気がない、というか近年の E2E は playwright の普及速度が凄まじいので、このタイミングで playwright に置き換えてしまうのを試してみました。
こういうライブラリの変更って今までは難しい作業だったのですが、2025年の我々には強力な武器があります。そうです、AI ですね。
ライブラリの切り替えは、AIが得意な翻訳作業に相当するので、かなり高い精度で自動化できます。
とはいえ、セットアップだけは自分でやります。
$ npm init playwright@latest
設定例
playwright.config.ts
export default defineConfig({
testDir: "./e2e",
fullyParallel: true,
forbidOnly: !!process.env.CI,
retries: process.env.CI ? 2 : 0,
workers: process.env.CI ? 1 : undefined,
reporter: "dot",
testIgnore: [
"e2e/xxxx.spec.ts",
],
projects: [
{
name: "chromium",
use: { ...devices["Desktop Chrome"] },
},
],
});
セットアップできたら、手元の Cline でこういうプロンプトを流しました。
cypress から playwright にテストコードを置き換えていきます。
`cypress/*` から `e2e/*` の下にコードを移植します。
まず機械的に TypeScript の型が通る、同等のコードに書き換えてください。
ここで生成されたコードの例です。
test("メールアドレス、パスワードのいずれかでも欠けているとログインボタンを押せない", async ({
page,
}) => {
const loginButton = page.getByRole("button", { name: "ログイン" });
await expect(loginButton).toBeDisabled();
await page.locator(EMAIL_FIELD).fill("[email protected]");
await expect(loginButton).toBeDisabled();
await page.locator(EMAIL_FIELD).clear();
await page.locator(PASSWORD_FIELD).clear();
await page.locator(PASSWORD_FIELD).fill("testpassword");
await expect(loginButton).toBeDisabled();
});
まず機械的に全部のコードを移植したあと、それぞれを修正していきます。
以下のコマンドを実行し、対応するテストコードを修正してください。
今の実装は正しいとして、 src 以下のソースコードは修正せず、e2e 以下のテストコードのみを修正します。
npx playwright test e2e/login.spec.ts
多少セットアップの不備は見つかりつつも、まず最初にターゲットとしたテストシナリオが動いてることは確認できました。
どうしても直せないときは、目視でデバッグします。
$ npx playwright test e2e/login.spec.ts --headed
目視で playwright の操作を追い、そこから推測される失敗の内容をAIに対してフィードバックします。「フォームは入力できたけど、Sumbit 押せてないように見える」みたいな内容を根気よく伝えます。
Human in the loop というやつですね。
お金がかかっていいなら Cline のブラウザ操作モードによるスクリーンショット入力をやってもいいかもしれません。今の性能で直せるか不明ですが。
ついでに playwright test の sharding 設定もやってしまいます。
一旦は、重要なケースを通すのに留めつつ、あとは泥臭く治すものとして testIgnore で列挙するにとどめて次に行きます。
export default defineConfig({
testIgnore: [
"e2e/xxxx.spec.ts",
"e2e/yyyy.spec.ts",
],
});
jest => vitest 移行
jest は有名なテストランナーですが、現時点では明確に ES Modules の扱いに難があります。
そもそも commonjs ファーストな設計で、CJS と ESM の評価優先度の根本的な問題で、 jest.mock() は require を動的に書き換えるので、それより速く評価される ESM の中身を差し替えることができません。
import a from "./a";
jest.mock('./a');
なので jest mock のために commonjs として実行する必要があるのですが、 近年は ESM のみで配布されるライブラリも増えています。
一応 experimental なサポートはありますが, あんまり使っている話を聞いたことがありません。
というわけで、近年では vite との相性も含めて vitest がよく使われているという状況です。
まあ vitest はほぼ jest のクローンなのでこれも機械的に置き換えるだけのが難しくありません。
設定を書きます。
vitest.config.ts
import { defineConfig } from "vitest/config";
import svgr from "vite-plugin-svgr";
export default defineConfig({
plugins: [
svgr(),
],
test: {
globals: true,
environment: "jsdom",
setupFiles: ["./test/_setup.ts", "./test/mock/index.ts"],
exclude: [
"**/node_modules/**",
"**/dist/**",
"**/cypress/**",
"**/e2e/**",
],
},
});
vite/vitest で合わせたことで、テストランナーでも svgr が使えるのが楽になります。
vitest と jest の表面的な違いは、 import {describe, it} from "vitest" と import が必須なことですが、一旦 globals を有効にすることで同じ挙動に合わせます。
あとはAIにこのドキュメントを読ませてコードを書き換えさせます
$ deno run -A npm:@mizchi/readability https://vitest.dev/guide/migration.html -o docs/jest-to-vitest.md
Cline にやらせる例。
@/docs/jest-to-vitest.md を読んで、既存の jest のコードを vitest に移行する。
コードを書き換えたら、 npx vitest --run file> で確認する。
一件ずつやっていく。
Meta 周辺の OSS (React, Webpack, Jest) は ESM 対応が弱く CJS 前提のものが多いです。
vitest による テストカバレッジ計測
テストカバレッジ、つまりユニットテストの実行によってコードの何割が評価されたかを取得できるようにしておきます。
test.coverage.include を指定することで、カバレッジ計測対象を指定できます。
vitest.config.ts
export default defineConfig({
test: {
coverage: {
reportsDirectory: "./coverage",
include: ["src/**/*.{ts,tsx}"],
},
},
});
これを実行する例
$ npx vitest --run --coverage
...
% Coverage report from v8
-------------------|---------|----------|---------|---------|-------------------
File | % Stmts | % Branch | % Funcs | % Lines | Uncovered Line
-------------------|---------|----------|---------|---------|-------------------
All files | 60.63 | 75 | 60 | 60.63 |
app | 0 | 0 | 0 | 0 |
root.tsx | 0 | 0 | 0 | 0 | 1-75
routes.ts | 0 | 0 | 0 | 0 | 1-11
-------------------|---------|----------|---------|---------|-------------------
機械的なテストカバレッジの数値を見るのは賛否両論あるとは思いますが、自分はAIによるコーディングの補助を自動化するために一定以上の数値が必要だと思っています。ユニットテストが書きづらいフロントエンドでも 60% 以上ほしいところ。
具体的には Meta のAIによる自動テストコード生成の論文を読んでください。めちゃくちゃ参考になります。
今後の指針: 同じ構成のリファレンスプロジェクトを用意
複雑 UI の複雑性に耐えるには、UI とロジックの分割、そしてコンポーネントのユニットテストの厚さが必要です。
現状で複雑UIの実装負荷が高いのは、テストパターンのアイデアが少なく、巨大コンポーネントへの testing-library のテスト(実質的にヘッドレスE2E)と実行負荷の高い E2Eに依存しがちな傾向があるように見えます。これはテストピラミッド的にコスパが悪い状態です。
私見ですが、そもそもユニットテストを書くという意識がないと、複雑UIの抱える制御可能なロジックを抽出できません。UIコンポーネント内の複雑な状態を外からテストするより、純粋なビジネスロジックのが遥かにテストを書くコストが低いです。ユニットテストを書く意識により、責務を分離した良い設計へのアフォーダンスが生まれます。
というわけで、同じライブラリスタックでリファレンス実装用のプロジェクトを用意しました。
このプロジェクトは react-router のボイラープレートに以下のテストパターンを用意しています。
- 純粋なロジックのユニットテスト
- コンポーネントテスト
- ReactRouter のルーティングコンポーネントのテスト
- hooks のテスト
- jotai を使ったコードのテスト
- Playwright のテスト
- Playwright のスナップショットテスト
また、これを元にテストコードを自動生成させるプロンプトを用意しました。
あなたの役割は、フロントエンドのエキスパートとしてテストコードを追加することです。カバレッジ 100%を目指します。
最初に `npx vitest --run --coverage --reporter=dot` を実行して、テストが通っていることと、現在のテストカバレッジを確認します
カバレッジが低いものから優先に、テストコードをユーザーに提案します。
テストは必ず一件ずつ追加して、`npx vitest --run ` でテストが通過することを確認します。
...
プロンプト全文はこちら
テストとカバレッジは人間のためでもありますが、AI 生成コードをバリデーションするものと考えるのがよいかもしれません。
ある程度機械的にカバレッジを増やしつつ、自信が持てない部分にE2Eを書くというのが個人的にコスパがよいフロントエンド開発だと思っています。
まとめ
また、フロントエンドのスタックは同世代のものと組み合わせる事はできても、異なる世代のものと組み合わせるのが困難です。
自分は大雑把にこういう認識があります。
- jQuery のグローバル変数による解決
- 2013: commonjs/webpack
- 2017: ESM
- 2019: TypeScript First
- 2021: パフォーマンス志向(No IE)
古いボイラープレートのまま近代化改修しようとしても、噛み合いません。
このプロジェクトは当時は枯れていたであろう CRA を採用したことで、 逆に足かせになってしまっていました。なので、CRA の呪いを解くことが最重要でした。
また、パフォーマンス改善するという視点だと、ほぼ IE 用の後方互換を捨てた最新のライブラリを採用するのが、手っ取り早いことが多いです。そのためにそれらと噛み合うバンドラーを更新する必要がありました。
自分の経験的には、複雑UIのパフォーマンス改善はほとんどバンドルチャンクの静的解析と、評価されるコードを減らすことによる Total Blocking Time の排除になります。
… とはいえ
自分も、可能なら段階的に問題を解決したかったのですが、至るところにデッドロックがあり困難でした。異なる世代間の辻褄を合わせるワークアラウンドを積み重ねるより、一気にやってしまうことが今回のケースでは有効だったと思います。
自分の作業手順の反省点もあり、 vite => playwright ではなく、先に E2E の playwright をやるべきだった気がします。E2E はスモークテストなので、バンドラーとは独立して進められたはず…
Views: 2

{kind=link}