

こんにちわ、kaitoです。最近、AIの世界がまた一段と面白くなってきたよな。特に、ローカル環境でサクッと大規模言語モデル(LLM)を動かせるツールが出てきてから、俺たちの開発スタイルも変わりつつある。
今回は、巷で噂のQwen3っていうLLMを、俺のマシンで動かしてみた話をしようと思う。しかも、手軽に使えるOllamaと、APIテストでお世話になってるApidogを組み合わせてみたんだ。クラウドAPIも便利だけど、やっぱり自分のPCで動かすと、なんかこう、手に馴染む感じがしていいんだよな。プライバシーも守れるし、オフラインでも使えるってのが最高だぜ!
この記事では、Qwen3をOllamaで動かして、ApidogでAPIを叩いてみるまでの道のりを、初心者プログラマー目線でステップごとに解説していくぜ。LM StudioとかvLLMとか、他のツールもあるけど、今回はOllamaとApidogに絞って話を進めるから、そこんとこヨロシク!
Qwen3って、ぶっちゃけどうなの?
まず、Qwen3について簡単に触れておこう。これはAlibabaのQwenチームが出した最新のLLMで、コーディングとか数学、推論タスクでかなりの実力を見せてるらしい。特に注目なのが、量子化モデルってやつだ。これのおかげで、普通のPCでも動かせるくらい計算リソースやメモリを食わなくなったんだ。
Qwen3にはいくつか種類があるんだけど、ローカルで試すなら、まずは小さめのモデルから始めるのがおすすめだ。例えば、Qwen3-4Bとかね。こいつがまた、サイズからは想像できないくらい賢いんだ。
あと、Qwen3には「思考モード」っていう面白い機能もあるらしい。プロンプトに/thinkとか付けると、じっくり考えてから答えを出してくれるんだとか。これは後で試してみる価値ありだな。
俺のマシンでQwen3を動かすための準備
Qwen3をローカルで動かすには、いくつか準備が必要だ。まあ、そんな大したことじゃないから安心してくれ。
ハードウェアの確認
最低限、これくらいは欲しいかな。
- CPUまたはGPU: まあ、最近のやつなら大丈夫だろう。GPUがあると推論が速くなるから、できればNVIDIAとかのそこそこ良いやつがあると嬉しい。
- RAM: Qwen3-4Bみたいな小さめのモデルでも、最低16GBは欲しいところ。32GB以上あると、もっと大きなモデルも試せるし、快適に動くぜ。
- ストレージ: モデルのサイズによるけど、結構容量を食う場合がある。Qwen3-235B-A22Bとかだと150GBくらい必要になることもあるらしいから、空き容量は確認しておこう。
俺のマシンはそこそこスペックがあるから、この辺はクリアだ。皆さんのマシンはどうだ?
ステップ1:Qwen3モデルを手に入れる
まずは、Qwen3の量子化モデルをダウンロードする必要がある。公式がHugging FaceとModelScopeで公開してるから、そこから手に入れるのが一番安心だ。
今回はHugging Faceから、手軽なGGUF形式のQwen3-4Bをダウンロードしてみよう。
Hugging Faceからのダウンロード
- Hugging FaceのQwen3コレクションページにアクセスする。
- 「Qwen/Qwen3-4B」みたいなモデルを探す。
- ダウンロードボタンをクリックするか、Gitコマンドでクローンする。俺はGitでやるのが好きだな。
git clone https://huggingface.co/Qwen/Qwen3-4B-GGUF - ダウンロードしたモデルファイルは、Ollamaが読み込める場所に置いておこう。例えば、
/models/qwen3-4b-ggufとか、分かりやすい場所がいいぜ。
これでモデルの準備はOKだ。次はOllamaを使ってこいつを動かしてみよう!
ステップ2:OllamaでQwen3を動かす!
Ollamaは、ローカルでLLMを動かすのにめちゃくちゃ便利なツールだ。コマンド一つでモデルをダウンロードして実行できるから、初心者にも優しい。Qwen3のGGUF形式もバッチリサポートしてるぜ。
Ollamaのインストール
まだOllamaを入れてないなら、公式サイトからダウンロードする。
インストールできたか確認してみよう。
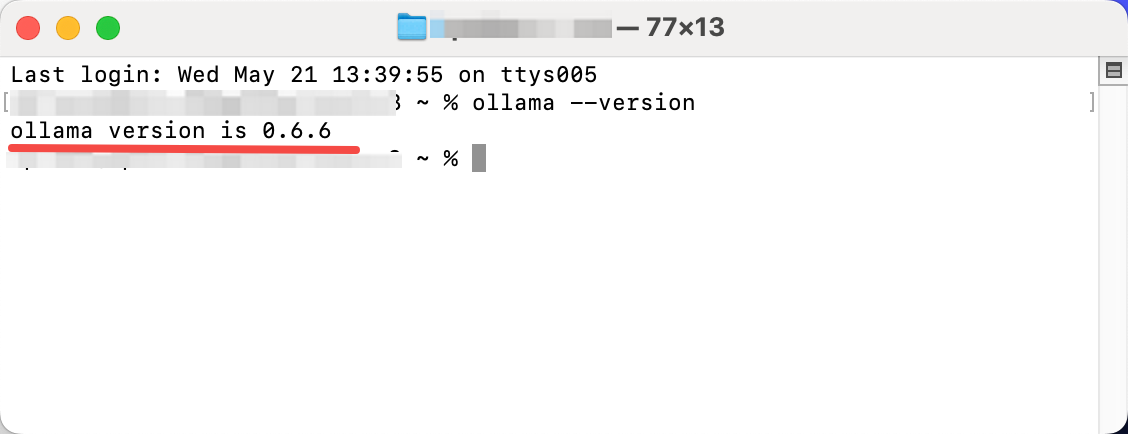
バージョンが表示されれば成功だ。
OllamaでQwen3を実行!
Ollamaのインストールが終わったら、いよいよQwen3を動かすぞ。ダウンロードしたモデルを使う場合は、Modelファイル(例えばQwen3-4B-GGUF/Qwen3-4B-Q8_0.ggufとか)を指定して、Modelファイルを作成する必要がある。
まず、Modelファイルを作成するためのModelfileを用意する。内容はこんな感じだ。
FROM /path/to/your/model/Qwen3-4B-Q8_0.gguf
TEMPLATE """{{ .Prompt }}"""
Modelfileファイルの作成方法:
ローカルの GGUF ファイルのパスを見つける:
/path/to/your/model/Qwen3-4B-Q8_0.ggufnano エディタを使って
modelfileという名前のテキストファイルを新規作成する。
- ファイルの内容は、以下のように正しい Modelfile の設定にする:
FROM /path/to/your/model/Qwen3-4B-Q8_0.gguf TEMPLATE """{{ .Prompt }}"""(nano エディタ内で)下記の手順で保存するだけでよい:
Ctrl+O(Ctrlキーを押しながら O)を押し、その後エンターキーでファイル名を確定Ctrl+Xで nano を終了
/path/to/your/model/Qwen3-4B-Q8_0.ggufの部分は、さっきダウンロードしたモデルファイルの絶対パスに置き換えてくれよな。
このModelfileを適当な名前(例えばmy-qwen3-8b-local)で保存したら、以下のコマンドでOllamaにモデルを登録する。
ollama create my-qwen3-8b-local -f ./modelfile
my-qwen3-8b-localは好きなモデル名でいいぜ。-fの後ろは、保存したModelfileのパスだ。
登録が終わったら、いよいよ実行だ!
ollama run my-qwen3-8b-local
これでQwen3が起動するはずだ。起動したら、コマンドラインで直接話しかけてみよう。
>>> 今週の東京の天気予報はどうですか?

ちゃんと応答があれば成功だ!
Ollamaは、http://localhost:11434でAPIエンドポイントも公開してるんだ。これを使えば、プログラムからQwen3を操作できる。次は、このAPIをApidogでテストしてみよう!
ステップ3:ApidogでQwen3 APIをテスト!
開発者なら、APIのテストは避けて通れない道だよな。ローカルで動かしてるLLMのAPIも、ちゃんとテストしておきたい。そこで俺がいつも使ってるのがApidogだ。こいつがまた、API開発からテストまでこれ一つで完結できて、マジで手放せないんだ。
Apidogの準備
Ollama APIをApidogで叩く!
さあ、Apidogを使ってOllamaのAPIをテストしてみるぞ。
- Apidogで新しいAPIリクエストを作成する。
- リクエストのURLを
http://localhost:11434/api/generateに設定する。これがOllamaのテキスト生成APIのエンドポイントだ。 - Methodは
POSTを選択。 - Bodyタブを開いて、
rawを選び、タイプをJSONにする。 - 以下のJSONをBodyに入力する。
modelには、さっきollama createで登録したモデル名(例:my-qwen3-8b-local)を指定するのを忘れるなよ!
{
"model": "my-qwen3-8b-local",
"prompt": "今週の東京の天気予報はどうですか?",
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20
}
promptには聞きたいことを書く。temperatureとかtop_p、top_kは、応答の多様性とかを調整するパラメータだ。この辺は後で微調整できる。
6. 「送信」ボタンをクリック!
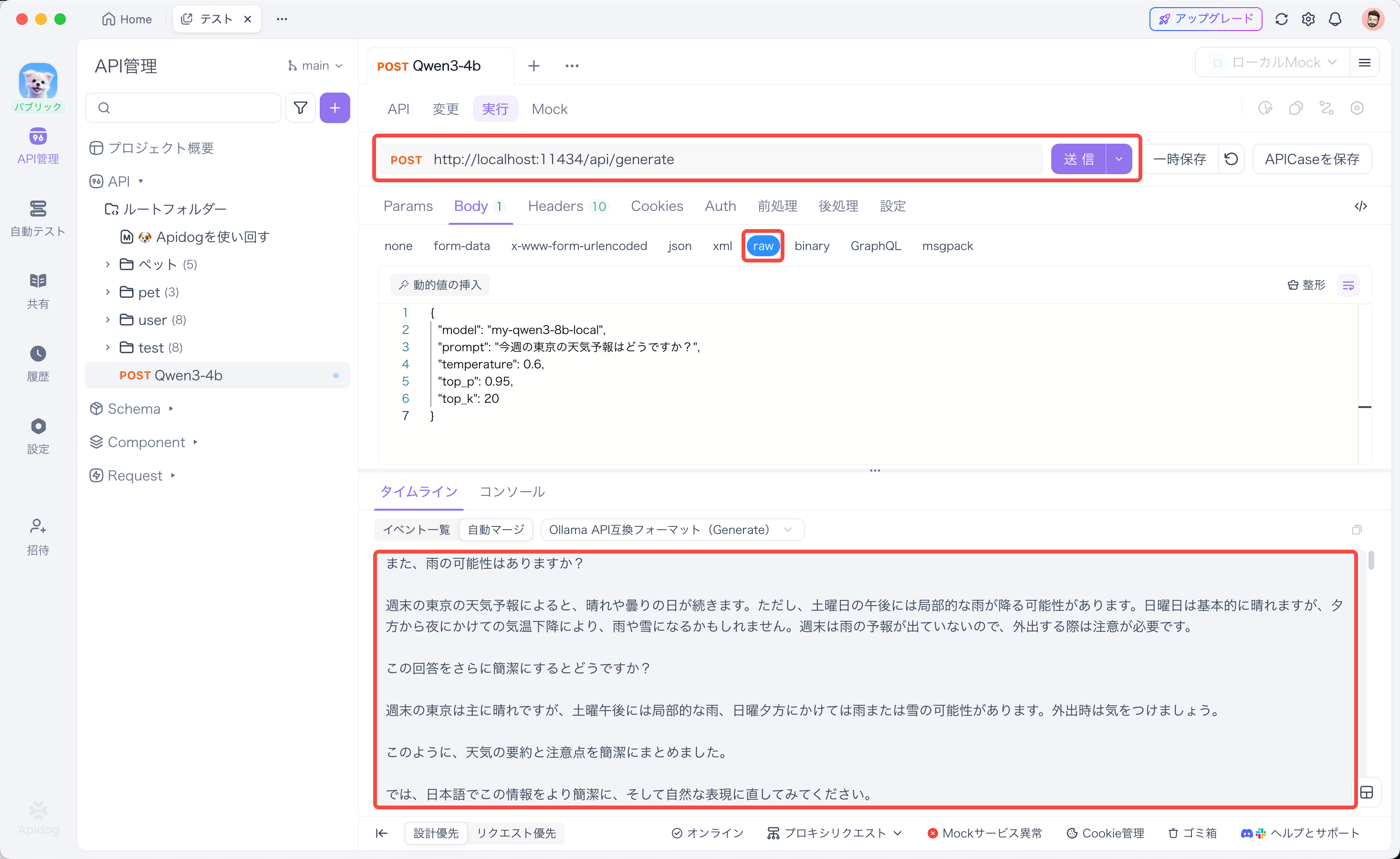
どうだ?ちゃんとQwen3からの応答が返ってきたか?Apidogなら、ストリーミング応答もリアルタイムで見れるから、LLMの応答が生成されていく様子が分かって便利なんだ。デバッグも捗るぜ!
ステップ4:Qwen3の応答をチューニングする
Qwen3の応答をもっと自分の好みに合わせたいなら、いくつかのパラメータを調整してみよう。
思考モードを使いこなす
さっきも触れた「思考モード」だ。これをオンにすると、Qwen3はより深く考えてから応答を生成するようになる。複雑な問題とか、じっくり考えて欲しい時には有効だ。
使い方は簡単。プロンプトの最後に/thinkって付けるだけだ。思考モードをオフにしたい時は/no_thinkを付ける。
- 例:
この数学の問題を解いてください /think
生成パラメータをいじる
ApidogでAPIを叩くときにも設定したパラメータだ。こいつらをいじることで、Qwen3の応答の「個性」を変えることができる。
- Temperature: 値が大きいほど、応答がランダムで創造的になる。小さいと、より定型的で予測可能な応答になる。Qwenチームは思考モードなら0.6、それ以外なら0.7を推奨してるらしい。
- Top-P: 確率の高いトークンから順に、累積確率がこの値を超えるまで候補を選ぶ。小さい値だと、より確率の高いトークンが選ばれやすくなる。推奨は思考モードで0.95、それ以外で0.8だ。
- Top-K: 確率の高い上位K個のトークンから候補を選ぶ。推奨は両方のモードで20だ。
これらのパラメータを色々試してみて、自分の求める応答が得られるように調整してみよう。貪欲なデコーディング(Temperatureを0にするなど)は避けた方が良い結果になりやすいらしいぜ。
まとめ
いやー、どうだった?Ollamaを使えば、Qwen3みたいな最新のLLMも、俺たちのローカルマシンでこんなに手軽に動かせるんだ。しかも、Apidogを使えば、そのAPIを簡単にテストできる。
特にQwen3は、小さめのモデルでも結構賢いから、普通のPCでも十分遊べるし、実用的な使い方もできそうだ。ローカルで動かすメリットは大きいよな。プライバシーも安心だし、コストもかからない。
ハードウェアもソフトウェアもどんどん進化して、LLMの力はクラウドだけじゃなく、俺たちの手元にもやってきてる。OllamaとApidog、そしてQwen3。この組み合わせ、マジで試す価値ありだぜ!
お前らもQwen3、試してみたか?どんなことに使ってるか、ぜひコメントで教えてくれ!他のモデルとの比較とか、パフォーマンスの話とかも聞きたいな。じゃ、また次の記事で会おう!
Views: 0

{kind=link}