
🧠 概要:
概要
この記事では、Difyを用いて自動で情報を収集し、それを要約してNotionに書き込み、Slackで通知するシステムの構築方法が解説されています。主に、非エンジニア向けに手順を詳細に説明し、AIを利用した効率的な情報収集の方法を紹介しています。
要約
- 目的: Difyを使って自動情報収集システムを作る。
- 手順の概要:
- Google Apps Scriptを使用してDifyのワークフローを定期的に実行。
- 特定のキーワードで記事を検索 (Tavily AIを使用)。
- 取得した記事をDeep Seekで要約。
- Notionに要約を保存。
- Slackへの通知を実施。
- システムのメリット: 情報収集の自動化により、手動での入力作業を削減できる。
- コスト: 月1円ほどで運用可能。
- 必要なアカウント: Dify、Slack、Notion、Googleなどのアカウントが必要。
- プロンプトの自動化: 質問文の入力を不要にするシステムを構築。
- 最終的な目的: 定期的な情報収集を自動化し、時間を効率的に使うこと。

こんにちは。非エンジニア向けに自動化アイディアを発信しているまのっちと申します。
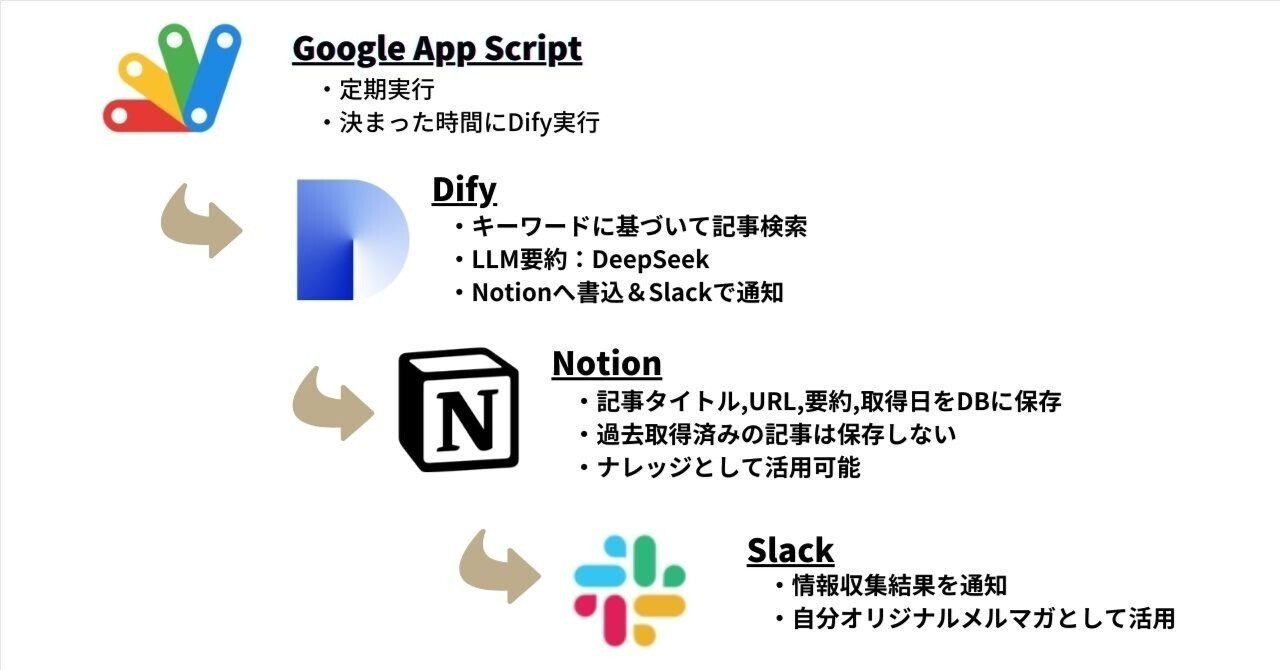
今回は、Difyで作る「完全自動」の情報収集システムを紹介します。
決まった時間に、決まったテーマ(たとえばAIやテック関連)でWeb検索を実行。その検索結果をLLMで要約し、Notionに保存、さらにSlackで通知するというシステムです。
「私自身が実用的で長く運用できるDifyアプリを作りたい」と思い、今回トライしました。
プロンプトを入力するのって、面倒に感じませんか?
生成AIが普及によって、情報収集が格段に楽になりましたよね。以前ならGoogle検索で一件ずつWebページを開いて調べていたのが、今ではAIに聞けば、まとまった答えが一発で返ってくる。
夢のような時代ですね。
しかし、「毎回、質問文を入力するのは面倒くさい」と感じることはありませんか?
短い質問でも、スマホやPCで入力して、送信するだけでもちょっとした手間です。
特に「最新情報を追いかけたい」と思っていても、 毎回、似たような検索を手動で繰り返すのは、地味にしんどい…。
「問いかける作業」も自動化して、もっと楽に情報収集できないかと考えてました。
Difyのワークフローで情報収集→Notion書き込み&Slack通知を実装
そこで、完全自動で情報を収集するシステムをDifyで構築しました。
仕組みは以下の通りです。
 Dify自動情報収集システム
Dify自動情報収集システム
-
Google Apps ScriptでDifyワークフローを定期実行
-
あらかじめ設定したキーワードで、Tavily AIを使って記事検索
-
記事をDeep Seekで要約
-
Notionに書き込み
-
Slackでも通知
Difyワークフローの全体像

出力サンプル
 Slackの通知
Slackの通知 Notionへの出力
Notionへの出力
ランニングコストは月1円ほど
Difyでは、基本的にAIのAPIを使ったときに料金が発生します。
今回のワークフローでは、TavilyとDeepSeekの2つのAIを使用しています。
・Tavily
PerplexityのようなWeb検索APIで、キーワードに基づいてWeb上の記事を複数収集します。
大変便利なツールですが、なんと最大月1000回までは、無料で使えます。とても良心的です。
・Deep Seek今回は日本語での要約に使っています。
こちらは従量課金制ですが、他のモデルに比べて安価に使うことができます。
今回のケースは日本語訳だけのライトな使用で、毎日実行しても月1円ほどで済む計算です。
「従量課金制」と聞くと、高額な請求になるのでは、と不安に思う方もいるかもしれません。
ですが実際は、プリペードカードのような仕組みで、チャージした金額(例えば5ドル)が上限となるので、それ以上に請求されることはありません。
誰かにリサーチを依頼することを考えると、破格のコストパフォーマンスと言えますね。
前提
以下の各種アカウントが必要になります。
Dify, Slack, Notion, Googleについてはアカウント取得済みである前提で話を進めます。(各APIの取得方法については、解説いたします。)
-
Dify
-
Slack
-
Notion
-
Googleアカウント
-
Tavily(Dify上で設定)
-
Deep Seek API(Dify上で設定)
なお、Difyにはローカル版とクラウド版がありますが、今回はクラウド版を前提にアプリケーションを構築します。
それではここからは、アプリケーションの構築方法をステップバイステップで解説していきます。
0. Difyワークフローの立ち上げ
Difyのスタジオ画面から「最初から作成」を選択

「ワークフロー」を選択し、アプリ名・アイコン・説明(任意)を設定します。
説明欄には動作概要を記入しておくと、後から振り返った際に分かりやすいです。

1. Tavilyの設定
Tavilyで記事を取得できるように、設定していきます。
1)Tavilyのインストール
初めてTavilyを使用する場合は、インストールが必要となります。
「ツール」タブを選択します。

検索窓から「Tavily」などと入力すると、表示されるのでこちらを選択します。

2)APIキーの取得
初めはAPIキーの取得が必要となります。
「認証する」を選択。

次の画面で「取得方法」を選択

Tavilyのwebサイトへ遷移します。Googleアカウントなどでログインします。
 Tavilyへのログイン
Tavilyへのログイン
ログイン後、トップ画面が表示されます。APIキーをコピーします。
 APIキーをコピー
APIキーをコピー
Difyの画面に戻り、「認証の設定」にて先ほどコピーしたAPIキーを貼り付けます。「保存」を押すと認証完了です。

3)ワークフローへの配置
ワークフローへTavilyブロックを配置します。
開始ブロックの「+」を押すと次のブロックを設置できます。
その中から、「ツール」→「Tavily」→「Tavily Search」を選択します。

様々なTavily Searchブロックでは、様々なパラメータが設定できますが、今回は検索クエリのみ設定します。
検索クエリによって様々なジャンルの記事を取得できます。
今回は、最新のAI・テック関連を収集するクエリに設定します。
英語での入力となりますが、これもChatGPTに聞けばクエリを生成してくれます。
(“AI” OR “artificial intelligence” OR “generative AI” OR “robotics” OR “cloud” OR “technology” OR “IT” OR “startup” OR “hardware” OR “funding” OR “trends” OR “breakthrough”) AND (2025) site:techcrunch.com OR site:venturebeat.com OR site:theverge.com

4)動作テスト
先ほど設定した検索条件でどんな情報が取得できるか、テストしてみます。
Tavily Searchブロック右上の▶️を押します。

次の画面で「実行開始」を選択。

すると、「出力」側に取得結果が表示されます。
エラーとなる場合は、APIキーが間違っている可能性が高いので、もう一度TavilyのWebページに戻って確認してみましょう。

このように、Tavilyからどんな情報が取得できるか、簡単にテストできます。
さまざま検索クエリを試してみて、調整していくといいでしょう。
2. Tavilyで取得した情報を配列としてまとめる
次にTavilyで取得した情報を「配列(リスト)」というデータ型に変換しま
す。
Tavilyのレスポンスは1つの大きなJSON文字列として返ってきます。
しかしこのままでは、Difyのイテレーションブロックで、1件ずつ処理できないため、配列として整形する必要があります。
まずは、コード実行を選択します。

入力変数として、「Tavily Search / json Array[Object]」を選択、変数名はなんでもいいのですが、ここでは「json」とします。

これで、コードブロックにTavilyで取得した記事情報が渡ります。
次に「PYTHON3」の欄に以下のコードを貼り付けます。
from datetime import datetimesearch_date = datetime.now().strftime('%Y-%m-%d') def main(json): items = [] if not json or "results" not in json[0] or not json[0]["results"]: return {"items": items} for item in json[0]["results"]: items.append({ "タイトル": item.get("title", ""), "要約": item.get("content", ""), "URL": item.get("url", ""), "取得日": search_date }) return { "items": items, "search_date": search_date }
 完成形
完成形
最後に出力変数を設定します。
注目してPythonコードの return の部分です:
 Python上での出力変数の設定
Python上での出力変数の設定
このように書くことで、Pythonブロックの処理結果(整形された記事データと検索日)を、items と search_date という2つの「名前付きの値」として返しています。
これらを「出力変数」の欄で以下のように設定します。
 DifyのUI上での出力変数の設定
DifyのUI上での出力変数の設定
このように、出力変数はPythonコード上とDifyのUI上の2箇所で設定する必要があります。
私はよく、DifyのUI上の設定を忘れて、エラーになることがありました。みなさんも注意しましょう。
ここまで完成したら一度実行してテストしてみましょう。
右上の「実行」を押します。

すると数秒で処理が完了すると思います。
右側の「Test Run」から「実行追跡」をクリックすると、各ブロックごとの入出力結果を確認できます。

実行結果のうち、「コード実行」のブロックにて、以下のように記事が5件、itemsリストに格納されていれば成功です。
{ "items": [ { "タイトル": "Here are the types of AI companies enterprise VCs want to ...", "要約": "The AI startup market is sprawling, from companies looking to develop new chips, to those using AI to build robots, to others looking to use AI to create niche solutions for industry-specific workflows. Mark Rostick, a vice president and senior managing director at Intel Capital, told TechCrunch that now that the large foundational models have been established — at least in his opinion — the next interesting area to invest in is AI solutions for specific tasks. “It’s still very early innings here, and I believe that momentum for AI infrastructure will continue into 2025, particularly as agentic frameworks proliferate, new model paradigms (including reasoning) develop, edge AI advances, and UI/UX of AI applications evolve (including computer use),” Janelle Teng, a vice president at Bessemer Venture Partners, said.", "URL": "https://techcrunch.com/2025/01/20/here-are-the-types-of-ai-companies-enterprise-vcs-want-to-back-in-2025/", "取得日": "2025-05-22" }, { "タイトル": "Why 2025 will be the year of AI orchestration", "要約": "We give you the inside scoop on what companies are doing with generative AI, from regulatory shifts to practical deployments, so you can share", "URL": "https://venturebeat.com/ai/three-ways-2025-will-be-the-year-of-agentic-productivity/", "取得日": "2025-05-22" }, { "タイトル": "AWS report: Generative AI overtakes security in global tech ...", "要約": "The AWS Generative AI Adoption Index, which surveyed 3,739 senior IT decision makers across nine countries, reveals that 45% of organizations plan to prioritize generative AI spending over traditional IT investments like security tools (30%) — a significant shift in corporate technology strategies as businesses race to capitalize on AI’s transformative potential. “I’d say another big piece that’s an unlock to getting into production successfully is customers really working backwards from what business objectives they’re trying to drive, and then also understanding how will AI interact with their data,” Pathak told VentureBeat. For organizations still hesitant to embrace generative AI, Pathak offered a stark warning: “I really think customers should be leaning in, or they’re going to risk getting left behind by their peers who are.", "URL": "https://venturebeat.com/ai/aws-report-generative-ai-overtakes-security-in-global-tech-budgets-for-2025/", "取得日": "2025-05-22" }, { "タイトル": "Here are the 19 US AI startups that have raised $100M or ...", "要約": "Runway, which creates AI models for media production, raised a $308 million Series D round that was announced on April 3, valuing the company at $3 billion. On March 25, Nexthop AI, an AI infrastructure company, announced that it had raised a Series A round led by Lightspeed Venture Partners. AI coding startup Turing closed a Series E round on March 7 that valued the startup, which partners with LLM companies, at $2.2 billion. AI research and large language model company Anthropic raised $3.5 billion in a Series E round that valued the startup at $61.5 billion. AI legal tech company Harvey raised a $300 million Series D round that valued the 3-year-old company at $3 billion.", "URL": "https://techcrunch.com/2025/04/23/here-are-the-19-us-ai-startups-that-have-raised-100m-or-more-in-2025/", "取得日": "2025-05-22" }, { "タイトル": "Google launches new initiative to back startups building AI", "要約": "Google launches new initiative to back startups building AI On Monday, Google announced the launch of its AI Futures Fund, a new initiative that seeks to invest in startups that are building with the latest AI tools from Google DeepMind, the company’s AI R&D lab. The fund will back startups from seed to late stage and will offer varying degrees of support, including allowing founders to have early access to Google AI models from DeepMind, the ability to work with Google experts from DeepMind and Google Labs, and Google Cloud credits. Google also has its Google for Startups Founders Funds, which supports founders from an array of industries and backgrounds building companies, including AI companies.", "URL": "https://techcrunch.com/2025/05/12/google-launches-new-initiative-to-back-startups-building-ai/", "取得日": "2025-05-22" } ], "search_date": "2025-05-22"}3. イテレーションブロックの配置
イテレーションとは「繰り返し処理」のことです。
配列に格納された複数のデータを、1件ずつ順番に処理したいときに使います。
今回のワークフローでは、先ほど配列に変換した items の中に複数の記事情報が入っています。
それらを1件ずつ取り出して、Notionに1件ずつ書き込んでいく処理を行うために、このイテレーションブロックを使います。
イテレーションブロックを配置後します。
入力変数に、先ほどコードブロックで処理したitemsを選択します。

出力変数はこの段階では空欄にします。後ほど設定します。
4. 配列の展開
ここでは、itemsリストの中から1件ずつ記事データを取り出し、それぞれ変数title, summary, url, dateに格納していきます。
まず入力変数には、配列から取り出された1件分のデータを受け取りたいので、「item」を選択します。

「PYTHON3」の欄には以下のコードを貼り付けます。
import json def main(item): title = item.get("タイトル", "") summary = item.get("要約", "") url = item.get("URL", "") date = item.get("取得日", "") return { "title": title, "summary": summary, "url": url, "date": date }出力変数は以下のように設定します。
 出力変数
出力変数
このブロックでの設定は以上です。
先ほどから配列にまとめたり、配列から取り出したりと少しややこしく感じるかもしれません。
ですが、配列の中身を変数として取り出しておくことで、後続のHTTPリクエストで記述がシンプルになります。
私は初め、HTTPリクエストブロック内で配列を展開して、各要素ごとにリクエストを送ろうとしましたが、Difyの仕様上、それができませんでした。
そこで、HTTPリクエストの前に、配列をコードブロックで展開するという流れに至りました。
何を言っているかよく分からないと思いますが、
要するに、ここでの配列の展開は、各要素ごとにHTTPリクエストを送るために必要であるのです。
5.HTTPリクエスト:Notionへの書き込み
完成形では、
配列展開→重複判定→Notionへの書き込みという流れですが、
まずはこの中で最も重要なNotionへの書き込み機能を実装してみましょう。
この処理はワークフローの中核であり、最優先で動作確認したい部分です。
1)Notion DBの設定
ここでは、Notionアカウントを設定済みであることを前提に説明していきます。
まだお持ちでない方では、個人利用であれば無料で開設できます。
Notionの使い方に関して詳しく触れませんが、単なるメモアプリにとどまらず、データベース機能を備えた情報集約ツールとして非常に優れています。これ機に活用してみましょう。
①Notion上にデータベース(DB)を作る
ログイン後、画面左側「プライベート」の「➕」をクリックします。

ページタイトルを設定します。
本文中で、「/db」とメニューが表示されるので、データベース(フルページ)を選択します。

以下のように新しいページにテーブル(DB)が作れます。

次にDBにデータを入れるための準備(=プロパティの設定)をします。
表中の「Aa 名前」をクリック→「タイトル」と入力します。
 タイトルプロパティの設定
タイトルプロパティの設定
他のプロパティも設定していきます。
「➕」を選択→「要約」と入力→③を選択
 要約プロパティの設定
要約プロパティの設定
「URL」の設定:
「URL」という種類のプロパティがあるので、そちらを選択します
 URLプロパティの設定
URLプロパティの設定
「取得日」の設定:
「日付」という種類のプロパティに「取得日」と命名します。
 取得日プロパティの設定
取得日プロパティの設定
完成形は以下の通りです。
 完成形
完成形
※Notion DBの設定における注意点
DifyからNotionに正しく書き込むためには、Notionのデータベースで設定するプロパティ名・プロパティの種類と、Dify側で指定するフィールド名・型を一致させる必要があります。
ここでは、
・タイトル → タイトル型(Notionの「タイトル」プロパティ)
・要約 → テキスト型
・URL → URL型(またはテキスト型でも可)
・取得日 → 日付型
のように正しく設定する必要があります。
この「名前」と「型」の対応が正しくないと、エラーが発生したり、データが記録されなかったりするため注意が必要です。
2)NotionとDifyの連携
DifyからNotionへアクセスできるように設定していきます。
そのために、インテグレーションを作成する必要があります。
インテグレーションとは、Difyなどの外部アプリケーションがNotionと通信するための「鍵」のようなものです
インテグレーションには、
-
Internal(インターナル):自分のワークスペースだけで使う用(非公開)
-
Public(パブリック):他の人にも使ってもらうために共有する用(公開)
の2種類あります。
今回は個人利用を想定しているので、インターナルを選びます。
まずは下記URLからNotionアカウントへログインします。
「新しいインテグレーション」を選択します

①インテグレーション名を記入→②「内部(=インターナル)」を選択→③「保存」 を押します。

「インテグレーション設定」をクリックします

インテグレーションのアクセストークンが発行されるので、メモ帳にコピーしておきます。
後ほどのHTTPリクエストブロックの認証設定で使います。
 インテグレーションのアクセストークンが発行
インテグレーションのアクセストークンが発行
先ほど作成したNotionのDBに戻り、DB側からインテグレーションにアクセス権を付与します。
右上の「•••」を選択→「接続」→「Dify情報収集用」(先ほど設定したインテグレーション名) を選択します

「はい」を選択

これで、「Dify情報収集DB」というデータベースに対して、インテグレーションからアクセスできるようになりました。
長くなりましたが、Notion側の設定はこれで完了です。
3)HTTPリクエストブロックの設定
Difyワークフローに戻ります。
「HTTPリクエスト」ブロックを設置します。
 HTTPリクエストブロックを配置
HTTPリクエストブロックを配置
DifyワークフローからNotionにアクセスできるように、認証設定をします。
HTTPリクエストブロック内から「認証なし」を選択

次の画面で「APIキー」を選択

API認証タイプを「Bearer」、
APIキーに先ほど発行した、インテグレーションのアクセストークンを貼り付けます。

次にHTTPメソッド、エンドポイント、ヘッダーを設定します。
①HTTPメソッドは「POST」を選択
②エンドポイントは以下を使用
③ヘッダーの設定
Content-Type application/json
Notion-Version 2022-06-28

これでDifyがNotionと通信するために必要な設定が完了しました。
次は、Notionに書き込むデータ(=リクエストボディ)を設定します。
ボディのデータ形式は「JSON」を選択

NotionのデータベースIDは、DBのURLに含まれます。
URLは、Notionの右上「•••」から「リンクをコピー」を選択、メモ帳に貼り付けます。

“www.notion.so”から”?”まで文字列が、データベースIDとなります。
https://www.notion.so/1ef42w7199de80772ed0f16c76920aaa?v=1ef42a7699fc80d48564000ca1a73530&pvs=4
太字がデータベースID例
{ "parent": { "database_id": "ここにNotionのデータベースIDを入力"}, "properties": { "タイトル": { "title": [{ "text": { "content": "{{title}}"} }] }, "要約": { "rich_text": [{ "text": { "content": "{{summary}}" } }] }, "URL": { "url": "{{url}}" }, "取得日": { "date": { "start": "{{date}}" } } }}4)HTTPリクエストブロック単体でテスト
HTTPリクエストブロック内右上の「▷」選択

入力欄に以下を入力します。
dateに関しては、「2022-09-29」のように日付でなければなりません。
“test”などの文字列を入力するとエラーになります。

Notion側にデータが追加されれば成功です!

もしエラーが出たら…
設定内容をもう一度丁寧に見直してみましょう。
-
特にリクエストボディは、添付の画像と一字一句一致しているでしょうか?
-
“properties”内のカラム名(「タイトル」や「要約」など)は、Notionと一致してますか?
-
同じく”properties”内の”title” や “rich_text” といったプロパティの型指定は、Notionと一致していますか?
-
その他、データベースIDやアクセストークンに誤りはありませんか?
6. HTTPリクエスト:重複判定
この記事が気に入ったらチップで応援してみませんか?

Views: 0

{kind=link}