
前回、下記のようにプロンプトエンジニアリングを終わらせてくれる期待を込めてDSPyの紹介をした。
DSPyの機能の一つであるプロンプト最適化の大きな役割の1つはLLMに与えるガイドラインをデータセットから作り出してしまうというものである。前回の記事で、データセットからNARUTOの主人公ナルトの口調を真似て言葉を言い換えるエージェントが作成できた(僕はナルトに詳しいのでマニュアルでも書ききれるが…)。
ここでいくつかキーワードを抑えてほしい。DSPy内で利用されるプロンプト最適化の最新の手法はGAPEである。そのGAPEを性能で一貫して上回ったのが今回紹介するACE(Agentic Context Engieering) という手法だ。
https://arxiv.org/html/2510.04618v1 Figure1参照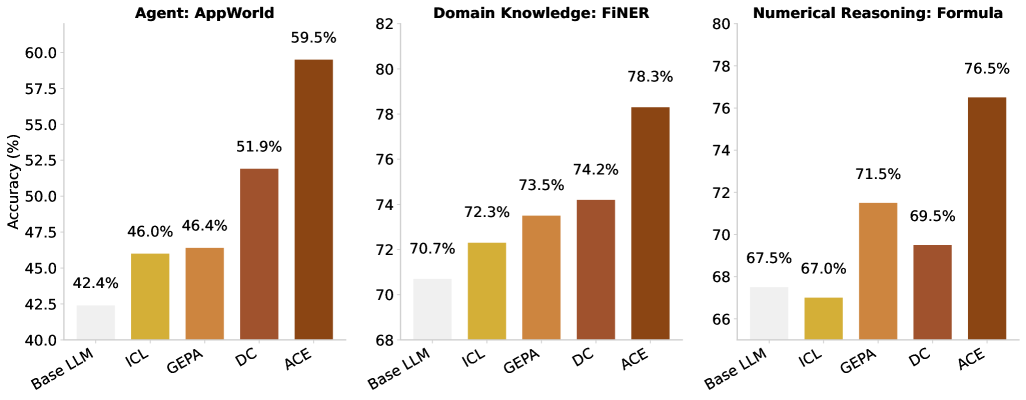
ICLはIn-Context-Learningの略で、fewshotの事例をプロンプトに入れ込むなど、いわゆる自前で作るマニュアルのプロンプトだとひとまず考えていい。GAPEは明確にICLよりも良い立ち位置にいる。DCというのはDynamic CheatSheetと呼ばれる手法で今回は紹介しないが、GAPEに対してタスクによっては優位な立場にある手法だ。ACEはDCを正統進化させたものという立ち位置だが、今から把握するならDCはひとまず飛ばして良いだろう。今回は、明確にGAPEを3つのタスクで凌駕したACEについて解説する。
┌────────────────────────────────────────┐
│ LLMの振る舞いを変えるための手段(大分類) │
└────────────────────────────────────────┘
│
├─ 🔴 Fine-Tuning(全重み更新)
│
├─ 🟠 PEFT(部分的に重みを更新)
│ │
│ ├─ LoRA / QLoRA
│ ├─ BitFit / Adapter / etc.
│ │
│ └─ Prompt Optimization(モデル内部に埋め込む/Soft系)
│ ├─ Prefix-Tuning(Soft Prompt)
│ ├─ Prompt-Tuning(Soft Prompt / P-Tuning系)
│ └─ P-Tuning v2 / AdapterPrefixなど
│
└─ 🟢 Context Adaptation(重みは一切いじらない)
│
├─ In-Context Learning(Few-shot含む)
│
├─ Prompt Optimization(自然言語プロンプトを最適化)
│ ├─ GAPE
│ ├─ MIPROv2
│ ├─ OPRO
│ ├─ Reflexion系
│ └─ 人手によるプロンプト設計・洗練
│
└─ ACE(外部メモリ+プロンプト+ICLの動的適応)
まず、ACEはプロンプト最適化には属さない。GAPEやMIPROv2はプロンプト最適化の手法の一種であるがACEは少し違う枠組みである。学習済の基盤LLMに対して振る舞いを操作する方法はいくつかある。言葉の階層がぐちゃぐちゃになる前に、上記の図から言葉を抜粋して説明する。
ややこしさの原因は Prompt Optimization がPEFT側にもContext Adaptation側にもいるかららしい。これは自分もまとめていて混乱したし、本当にそういうコンセンサスがあるのか自信が無い。意見があったら是非お願いします。
Fine-Tuning
LLMの重みを適応させたいデータセットを使って訓練する。なじみのある普通の教師あり学習みたいなものである。大きな計算資源がない限り手を出さない分野であるので、一般人はそういう手段を取れることは少ないかと思う。そもそも必ずしも世の中のLLMに重みを変更する手段が公開されているとも限らない。
PEFT(Parameter-Efficient Fine-Tuning)
これに属する方法として、低ランク差分を扱うLoRAやQLoRAなどがある。他にも勝手にレイヤーを追加して訓練したり、バイアスだけを訓練したりなどの方法がある。とにもかくにも全ては訓練しないけどちょっとだけ変更を加える系をまとめてPEFTと呼ぶ。
Context Adaptation
Context AdaptationはLLMの重みは触らず、入力を作ったり修正したりして振る舞いを向上する。訓練を伴わないLLMの振る舞いの向上方法をすべて指すと思ってよい。例えばClosed WeightなLLMを利用して、医療ドメインに特化した振る舞いをさせるために行う工夫はすべてここに該当するだろう。
Prompt Optimization
Promptをデータから訓練する。非常にややこしい。Promptをモデル内部に埋め込む場合もあれば、自然言語として直接的に扱う場合もある。前者は一般にPEFTの一種とされている模様(モデルの重みではないだろ…?と思うけど、勝手に層を追加して学習したりするのもPEFTと呼ばれているので、モデル内の何かを訓練してればすべてPEFTらしい)。ややこしさの原因はどちらかというと「PEFTが重みを訓練している」の意味が多分にあいまいだからな気がしている。なんだか転移学習って言われていた内容までPEFTの一種のようになっているので、言葉がいたずらに大きくなっているように思う。
一方でGAPEやMIPROv2はモデル外部の値(自然言語の空間)で最適化を行っているのでPEFTには属さずContext Adaptationの範疇だそうだ。
ということでPrompt Optimizationという考え方は、何やらプロンプトを自動化するくらいの意味であり、プロンプトと呼んでいるものがLLMの層を一つでも通った後を考えているのか、自然言語のままで考えているのかでPEFTなのかContext Adaptationなのかが変わるらしい。ややこしい。ってか、本来のモデルのパラメータをすべてフリーズしてるものは全部Fine-Tuningとは言わなくないか…?
GAPE
先に述べてしまったが、Prompt Optimizationに属する手法の一つで、Context Adaptation側。Chatを使う人はご存じの通り、良い感じのプロンプトを定型文として作成しておくと思い通りに動いてくれたりする。これを人手で作るのではなく、良い感じに動いたときの入力と出力を与えて、それらを再現するためのシステムプロンプト相当を最適化で求めようという方法。最適化の中でLLMの出力を別のLLMでフィードバック評価する(リフレクション)。これが効くらしく、スカラー値で評価するより言葉で評価した方が良いらしい。
ちなみに、システムプロンプトはLLMにとって潜在変数の初期状態(あるいは前半の状態)を与えるようなものである。RNNやLSTMなどのように同じく自己回帰結合を持つモデルに関して、本来のモデルパラメータをフリーズしたのち、潜在変数を推論時にのみパラメータ化して特定タスクに適応させる手法はロボット制御の世界では随分前から存在し、Parametric Biasと呼ばれる。
まずGAPEと何が変わったのかを先に示しておく。
| 観点 | GAPE | ACE |
|---|---|---|
| 最適化対象 | システム/ユーザプロンプト | プロンプト+外部メモリ+ICL例 |
| タイミング | オフライン/バッチ中心 | 推論時(オンライン) |
| 反省形式 | LLMによる言語フィードバック | Reflection + 外部蓄積 |
| 結果の継承 | 1回固定 or 再生成 | 継続的に成長 |
| 応用範囲 | 単発タスク想定 | 継続タスク・エージェント向け |
- 最適化対象が“プロンプト文”単体ではない
→ ICL例・外部知識・履歴・思考方針なども含む「Context丸ごと」 - 処理タイミングが推論時に限定される(オンライン)
→ 学習フェーズを前提としない。PEFT系みたいに重みを更新しない。 - 連続タスクを前提に外部状態を保持する
→ 初期プロンプトを良くするというより、(次回の)初期プロンプトを逐次更新し続ける。
初期プロンプトを作っているという点でACEは「Prompt Optimizationの上位互換」にも見えるし、良い事例をプロンプトに埋め込んでくれる「ICLの強化版」でもあるし、外部メモリとしてこれまでの取り組みをまとめてくれるので「RAG」的でもあるが。今のところ何か一つの手法に分類するのは難しそうだから “Context Adaptationの権化” という表現にした。
ACEの中身:3つの役割に分かれた分業スタイル
ACE(Agentic Context Engineering)は、プロンプトを一回きりで最適化して終了する類の手法ではなく、人間の「試行 → 反省 → 記録 → 再利用」に対応する処理を、そのままLLM向けに持ち込んだフレームワークになっている。これを成立させるために役割が3つに分けられている。
① 外部メモリ(External Memory):進化するプレイブック
ACEでは、プロンプトを1枚用意して終わりにするのではなく、戦略・失敗例・方針などを蓄積する外部メモリを前提にしている。これはDynamic Cheatsheet(DC)の系統で、単なるテキストの塊ではなく「箇条書き(bullets)」による構造化が行われる。
内容としては、再利用可能な戦術、ドメイン知識、典型的な失敗モードなどが小さな単位で保持される。要約というよりスロット化された知識の集合に近い。
② コンテキスト再構成(インクリメンタル更新)
ACEは、毎回コンテキスト全体を書き換えるような方法は取らない。Reflectorが抽出した「学習すべき内容」を小さな差分(デルタ)として保持し、それをCuratorが既存のメモリに統合する。これにより、全文再生成によるコストや崩壊を避けながら、必要な部分だけを順次更新していく。
このやり方の利点として、余計な冗長化を防ぎ、計算コストやレイテンシも抑えられる(実際に既存手法より大幅に短縮されると報告されている)。DCの設計をベースにしつつも、ACEでは統合ロジックがより確定的で破綻しにくい。
③ Reflection(自己フィードバック)
Reflectorは、出力や推論の過程から教訓や失敗パターンを自然言語で抽出する専用の役割になっている。GAPEの場合も反省的プロンプト更新は行うが、最終的には1枚のプロンプトに落とし込む方向に寄る。ACEは違っていて、抽出されたフィードバックを、項目化された知識として外部メモリ側に送る。
Curatorはそれをデルタエントリとしてまとめ、外部メモリへ組み込む。コンテキスト全体を維持しながら拡張していく方式なので、プロンプト崩壊が起きにくく、記憶の破棄ではなく成長が起きる。アブレーションスタディでも、このReflectorとCuratorの分業が性能向上に必須であることが示されている。
まとめ
この構造のおかげで、ACEはプロンプト単体ではなく「コンテキスト全体」を進化対象にしており、ICLやGAPEの限界を越える土台を持っている。一方で、ここのモジュールが最適な作りであるのかは分からない。上手に組み合わせることでGAPEやICLを一様に超えてきているので方向性としては間違っていないのだろうと思う。
ただしReflectorの性能に大きく依存する旨が書かれており、ここは具体的にどのように解決していくのかは経過観察が必要そう。ここに大きなコストの掛かるLLMを使いだしてしまえば、最初から推論LLMをいい奴にすれば良い、みたいな話になりかねない気もする。(定額プランでLLM使い放題ならいいかもしれんけど……)
DSPyのモチベーションは、人手でのプロンプトエンジニアリングを排除し、LLMの振る舞いをプログラムにしようということなので、たぶんACEも実装されるのではないだろうか?勝手に期待している。DSPyはスタンフォード大学が主体となっているし、今回のACEもスタンフォード大学が名を連ねている。ただ、どうもモジュールとして綺麗になりそうな雰囲気ではないので、DSPyの思想に取り込むには相応に実装コストが掛かりそうかもしれない。
また、Serena MCP を使うだけでもコーディングAIとしての振る舞いは非常に良くなった経験がある(Claude)。Serenaはgrepして力技で探すのではなく、言葉の意味単位で検索を掛けられるような工夫がされていて、要はコードの検索ツールとして非常に優秀であった。一方で適宜Serena Memoryに作業を引き継げるようにまとめてくれる機能があった。
まとめた情報を検索して別セッションで再開できるというのは非常に便利であったが、おそらくメモリへのまとめ方自体が最適化されているわけではないだろうし、無論、まとめるタイミングや内容、更新をすべきかなどを判断してくれるものではなかった。
Serenaによる使い勝手の向上を考えれば(検索が強いことを除いて)ACEのメモリの方がはるかに高度になっていると考えられるので、実際にいろいろと体験が良くなるのではないかと期待している。
Views: 2

{kind=link}