
潜んでいるリスク、一番苦手なリスクです!どうも、whatasoda です。
モノリシックなサービスでは、サービスの成長とともに 1 つのアプリケーションの中にさまざまな性質の処理が混在するようになります。Node.js のようなシングルスレッドで処理が実行されるランタイムでは、複数の処理を走らせる場合に 1 つしかないスレッドを取り合う形で互いの処理を待機させ合うような振る舞いをすることがあります。
技術スタックを TypeScript に統一しているダイニーでは当然バックエンドの API サーバーを Node.js 上で実行しています。過去、「注文の受付」や「会計処理」といったリアルタイム性が求められる処理と、「売上の集計」や「CSV ファイルの生成」といったバッチ系の重たい処理が一部共存していたことがありました。
そういった環境で実行される処理同士が干渉し合うことで、レイテンシやエラー率に影響が出てしまうような問題が発生していましたが、現在は Cloud Run (Google Cloud の Container-based なフルマネージドなプラットフォーム)のサービスを分割したり、一部のパッケージにパッチを貼ったりすることで対策をしています。
この記事では、Node.js の特性を踏まえつつ、処理同士の干渉の影響をどのように回避するのかを解説します。
スレッド占有によるリクエストタイムアウトを再現する
まずは実際に起こり得る問題を見てみましょう。今回は、極端に重たい処理を意図的に発生させる実験を行うことで、実際のアプリケーションで起こり得る問題を紐解いていきます。実験につかう処理では以下の内容を実装します。
- Google のトップページに
httpsモジュールを使って HEAD リクエストを送る -
setTimeoutによるタイムアウトと socket 自体のタイムアウトをそれぞれ設定する -
setImmediateを使って Event Loop の決まった位置(check フェーズ)に重たい処理を挿入する
Event Loop について詳しくは後述しますが、 Node.js の非同期的な処理をコントロールしている枠組みのようなものです。いくつかの種類のフェーズがあり、それを何周もループし続けながら処理が進んでいきます。
import * as https from "https";
type Result =
| { status: "success"; data: { date: string | undefined } }
| { status: "failure"; reason: string };
const fetchDateFromGoogle = ({ timeout }: { timeout: { timer: number; socket: number } }) =>
new PromiseResult>((resolve) => {
let timeoutTimer: ReturnTypetypeof setTimeout> | null = null;
timeoutTimer = setTimeout(() => {
timeoutTimer = null;
console.log("timeout");
resolve({ status: "failure", reason: "setTimeout" });
}, timeout.timer);
const req = https.request(
"https://www.google.com/",
{ method: "HEAD", timeout: timeout.socket },
(res) => {
if (timeoutTimer) {
clearTimeout(timeoutTimer);
timeoutTimer = null;
}
const data = { date: res.headers.date };
console.log("response");
resolve({ status: "success", data });
res.resume();
},
);
req.on("error", (error) => {
console.log(error);
req.destroy();
});
req.on("timeout", () => {
console.log("socket hang up, destroying request...");
req.destroy();
});
req.end();
});
const startCheckLoop = (callback: () => void) => {
const next = () => {
setImmediate(() => {
console.log("[check]");
callback();
next();
}).unref();
};
next();
};
const blockThread = ({ weight }: { weight: number }) => {
for (let i = 0; i weight; i++) {
Array.from({ length: 65536 });
}
};
const main = async () => {
console.log("Experiment Started!");
let checkCount = 0;
startCheckLoop(() => {
checkCount++;
if (checkCount > 1) {
blockThread({ weight: 100 });
}
});
console.log(
await fetchDateFromGoogle({
timeout: {
timer: 1000,
socket: 10000,
},
}),
);
};
void main();
なお、今回用意したスクリプトはかなり不安定で、実行マシンの性能やネットワークの安定度などによって結果が左右します(inspector の有無でも結構変わります)。この先はタイミングが噛み合ってうまく事象を再現できたときの結果を元に説明をしていきますが、私の手元ではそもそも HTTPS リクエストが成立せずに socket hang up になって失敗してしまうことが殆どでした。そのため、手元で試す際はタイムアウトや weight などを調整しながらやってみてください。
今回、検証には node --experimental-strip-types experiment-thread-block.ts のように実行して試すことにしました。これだけでも結果を見ることはできますが、--inspect-brk を使って更に詳しく処理の流れを追いかけてみました。 --inspect-brk をつけた状態で実行すると、最初は Debugger の接続を待機します。 Google Chrome などのブラウザの開発者ツールを開くと以下の画像のような Node.js のアイコンが表示されているはずです。それをクリックすると新しくウインドウが開かれて Node.js に Debugger がアタッチされます。
以下が実行時の出力です。
node --inspect-brk --experimental-strip-types experiment-thread-block.ts
Debugger listening on ws://127.0.0.1:9229/e7efefa7-0e31-4f2d-98a3-ddf00bd6aa77
For help, see: https://nodejs.org/en/docs/inspector
Debugger attached.
Experiment Started!
(node:29499) ExperimentalWarning: Type Stripping is an experimental feature and might change at any time
(Use `node --trace-warnings ...` to show where the warning was created)
[check]
[check]
[check]
[check]
[check]
[check]
timeout
{ status: 'failure', reason: 'setTimeout' }
response
[check]
Waiting for the debugger to disconnect...
ここからは DevTools の Performance タブから計測をした結果を元に処理の流れを追いかけていきます。

まずは全体の流れです。(いくつかフィルターして非表示にしています)これだけだと何が何やらさっぱりなので、もう少し細かく見ていきましょう。

処理が開始するタイミングです。なんやかんや実行されていますが、このあたりは単に HTTP リクエストを送っているだけです。

すこし時間を進めてみると、一番上の段が「run」から色々違うものに変化しています。

ズームしてみると、 「processTicksAndRejections」や「processImmediate」などであることが分かります。 1 つ目の「processImmediate」には「consoleCall」というものがあります。これは setImmediate に仕込んでいた console.log でしょう。一方で 2 つ目の「processImmediate」では「blockThread」の呼び出しがあります。初回はスキップするようにしていましたが、 2 回目以降の「processImmediate」では毎回「blockThread」によって一定以上の時間スレッドが占有されるようになっています。
「onlookupall」というのもありますが、おそらく HTTP リクエスト関連か、今回の実験に直接関係のないなにかでしょう。

さらに進めてスレッドが開放されるとまた違うものが出てきました。 TLSSocket などの単語があるので、 HTTPS 関連の処理が走っているようです。
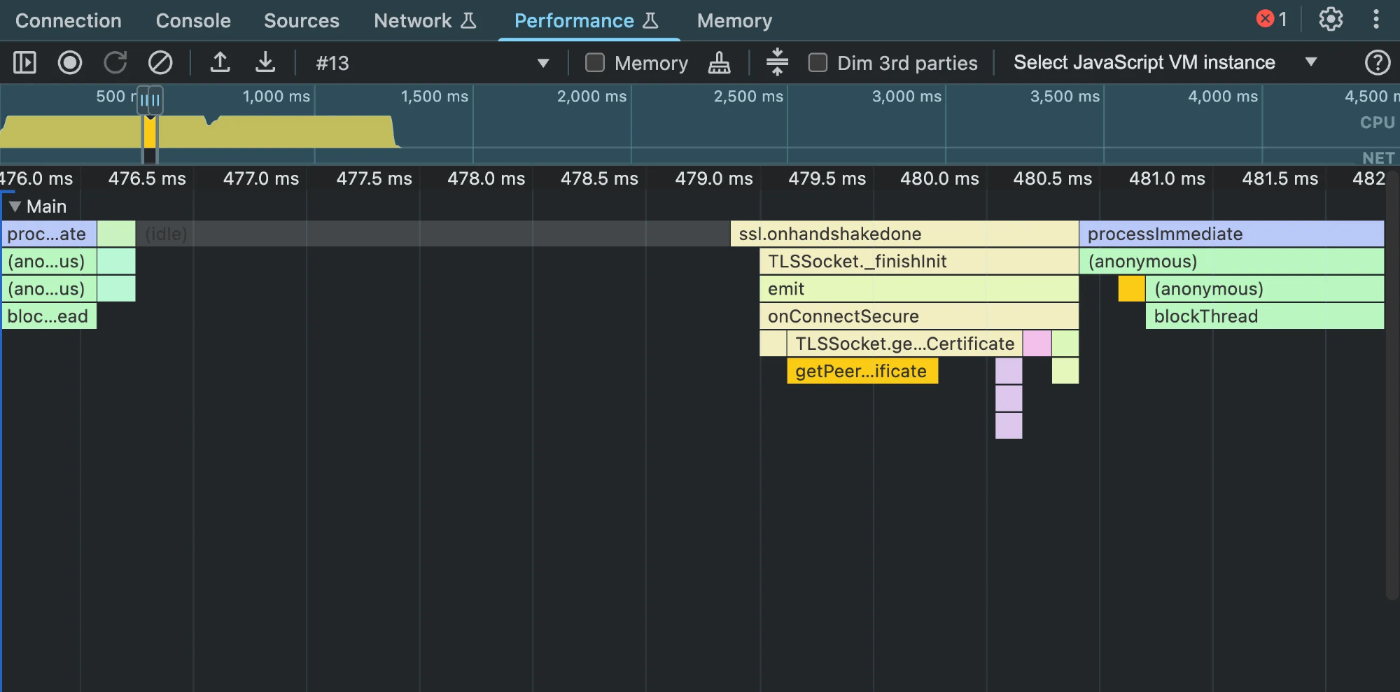
こちらも同様に HTTPS 関連ですね。
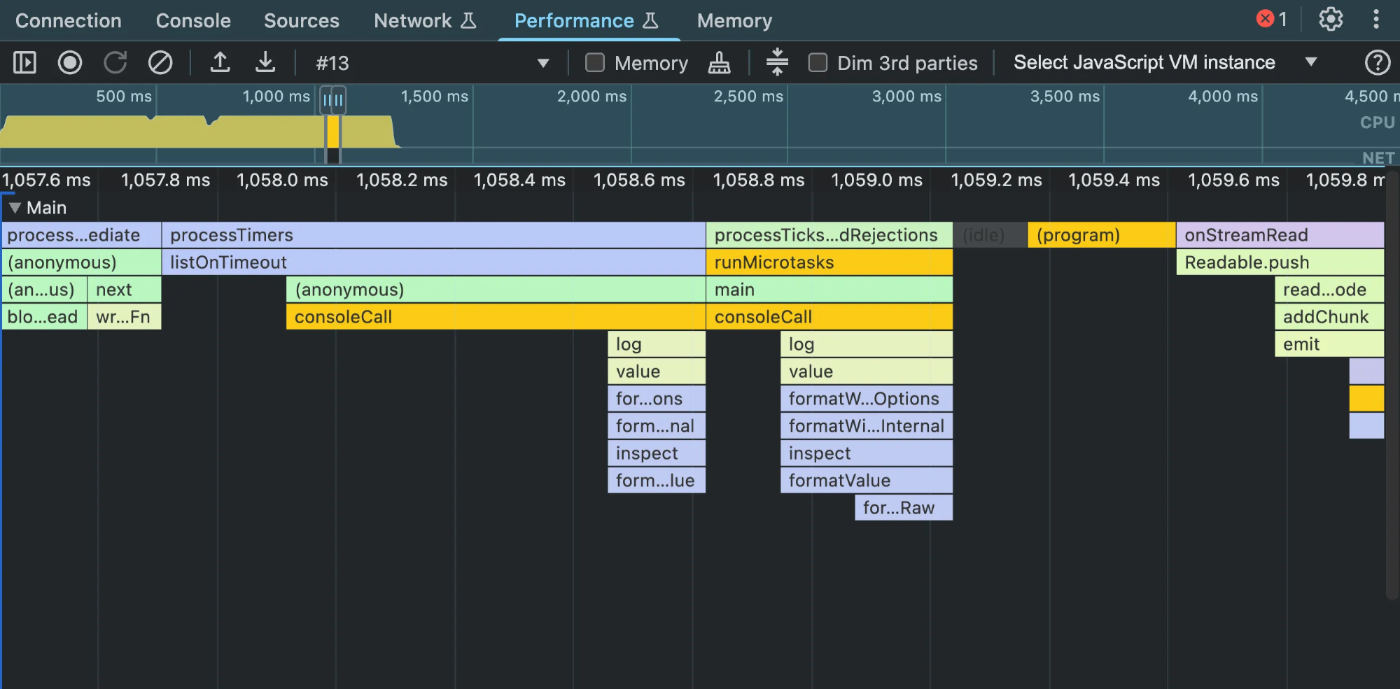
さらに時間を進めていくつかの「processImmediate」を越えた先に、今度は「processTimers」が登場しました。今回のコードの中で timers に該当するものを使っているのは setTimeout によるタイムアウトのみです。その次に来た「processTicksAndRejections」を見てみると、「main」という表記があります。ここでは setTimeout の callback が実行されて Promise を resolve し、 main 関数内で await した結果を console.log で出力する、ということが行われているわけです。しかし、直後に実行されている処理を見てみると「onStreamRead」というものがあります。これは HTTP リクエストに対するレスポンスが返ってきたことで実行されているものです。
それぞれが実行されたタイミングについて確認しましょう。「processTimers」と「onStreamRead」との間の時間の差は僅か 2 ms 程度です。たまたまギリギリタイムアウトに間に合わなかったということもあるかも知れませんが、これは一定再現性のある現象です。おそらくレスポンスデータそのものはスレッドが占有されている間にローカルマシンに到達しているでしょう。にも関わらずタイムアウトになってしまうのは Event Loop の中のフェーズの順番が関係しています。
次のセクションでは Event Loop について見ていきますが、今回の実験の結果を整理しましょう。
- スレッドが占有されている間は他の処理は停止する(Event Loop も停止する)
- スレッド解放後は進行が再開される
- 「
setTimeoutの callback が実行するフェーズ(timers)」が「HTTP レスポンスを処理するフェーズ(poll)」よりも前に実行されると、データがプロセスに届いていてもタイムアウトになることがある
一応 onStreamRead の中身をみておく

一応「onStreamRead」の中身を見てみますが、実装と見比べても HTTP レスポンスを処理している箇所であることは間違いなさそうです。この後は数回「processImmediate」が実行されたあとでプロセスが終了しています。
Node.js は Event Loop に沿って処理が進む
まずは Node.js の Event Loop について軽く確認しておきましょう。そもそも、 Event Loop とは何でしょうか? Node.js の公式ページには以下のような説明があります。
The event loop is what allows Node.js to perform non-blocking I/O operations — despite the fact that a single JavaScript thread is used by default — by offloading operations to the system kernel whenever possible.
Since most modern kernels are multi-threaded, they can handle multiple operations executing in the background. When one of these operations completes, the kernel tells Node.js so that the appropriate callback may be added to the poll queue to eventually be executed. We’ll explain this in further detail later in this topic.
要は Node.js が non-blocking に I/O オペレーションを実行できるようにしているもので、実際に I/O を担っている処理からの通知を受け取ってよしなにコールバックを呼び出してくれる存在のようです。Event Loop は以下のような複数のフェーズを順番に処理していき、ループします。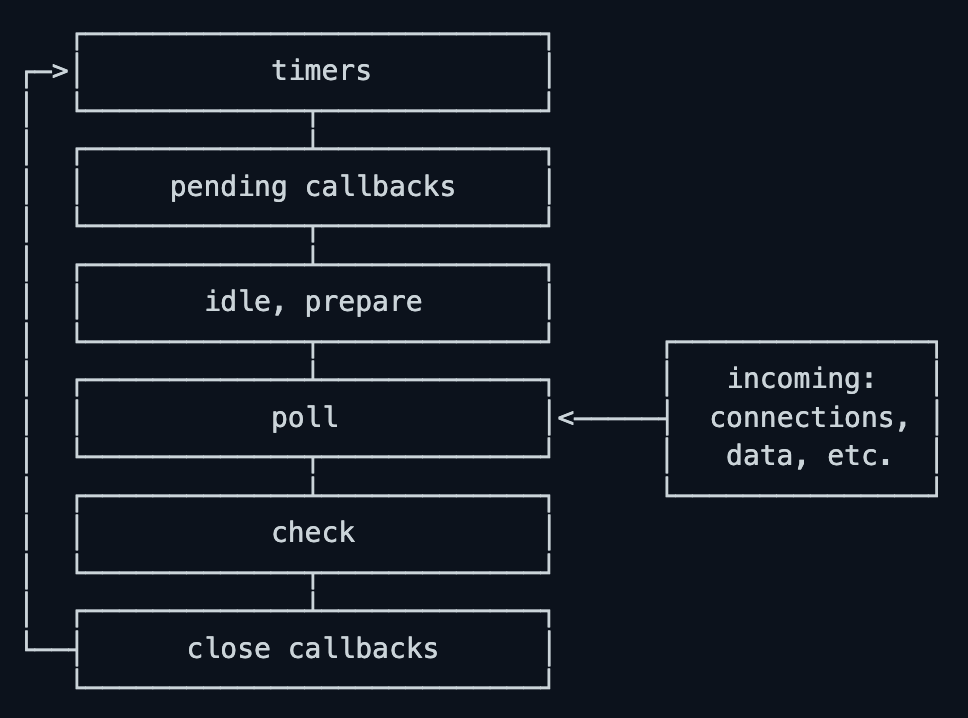
また、以下のような説明があります。
Each phase has a FIFO queue of callbacks to execute. While each phase is special in its own way, generally, when the event loop enters a given phase, it will perform any operations specific to that phase, then execute callbacks in that phase’s queue until the queue has been exhausted or the maximum number of callbacks has executed. When the queue has been exhausted or the callback limit is reached, the event loop will move to the next phase, and so on.
ここで確認しておきたいのは、 Event Loop は次のフェーズに進む前に現在のフェーズによって発行された callback を実行するという点です。あるフェーズで Promise.resolve().then(() => { ... }) が実行されたとき、 then に入れた callback は次のフェーズに進む前に実行されると考えておけば一旦は OK です。
各フェーズの説明も見てみましょう。
Phases Overview
- timers: this phase executes callbacks scheduled by
setTimeout()andsetInterval().- pending callbacks: executes I/O callbacks deferred to the next loop iteration.
- idle, prepare: only used internally.
- poll: retrieve new I/O events; execute I/O related callbacks (almost all with the exception of close callbacks, the ones scheduled by timers, and
setImmediate()); node will block here when appropriate.- check:
setImmediate()callbacks are invoked here.- close callbacks: some close callbacks, e.g.
socket.on('close', ...).
今回は timers ・ poll ・ check の 3 つに注目します。 timers では setTimeout や setInterval のコールバック実行されます。 poll では I/O イベントを取得し、それに関するコールバックが実行されます。 check では setImmediate のコールバックが実行されます。
実験結果を改めて見てみる
先ほどの実験では setImmediate を使って check フェーズに重たい処理を挿入していました。つまり「poll と timers の間に重たい処理を挟む」実験をしていたわけです。となると先程の実験の結果は以下のようにまとめることができます。
「poll と timers の間に実行される処理によってスレッドが占有されていると、スレッド占有中にレスポンスが来ていても、スレッド解放後は先に timers が実行されるためリクエストがタイムアウトしたものとしてアプリケーションが解釈してしまうことがある」
ところで、バックエンド API サーバーでは、そのアプリケーションプロセス単体でなにかが完結することはほぼなく、データベースや他の API などと通信しながら機能を実現することが殆どでしょう。Node.js がプロセス外から受け取ったデータを処理するのは poll のフェーズなので、個別の処理の重たい軽いに関係なく、バックエンド API サーバーを構成する処理の殆どは poll のあとに集中する傾向にある、と考えることができないでしょうか?
Event Loop には他にもフェーズがありますが、上記の内容を踏まえると殆どのフェーズは意識の外に置くことができるでしょう。また、 Event Loop はループしているので、「どちらのフェーズが先に実行されるか」は「どこでループを区切るか」で見え方が変わります。多くの処理が集中する poll の直後を Event Loop の区切りと考えると、フェーズが実行される順番は以下のように考えることができます。
check → timers → poll
今回は実験のために check フェーズで重たい処理を行いましたが、通常のアプリケーションであれば setImmediate に重たい処理が入ることはまずないはずなのでこれも無視すると、シンプルに 「timers のほうが poll よりも先に実行されると考えることができる」 わけです。そう思うと、今回実験で再現したタイムアウトは割と起き得る現象であると想像できそうです。
とはいえ今回は極端な実験を行いました。実世界ではどのようなときにどのような問題が発生するのでしょうか?
重い処理が軽い処理を邪魔する
モノリシックな構成のアプリケーションでは、以下のような処理が同居しがちです。(括弧内はダイニーでの例)
- リアルタイム性が求められる処理(注文、会計など)
- 計算量が多い処理(売上集計など)
- 定期実行されるバッチ処理(メッセージ配信など)
- 高頻度のポーリング処理(プリンタ連携など)
過去、これらの処理の一部が同居している時期があったのですが、比較的軽めの処理でデータベース接続のタイムアウトが発生するという現象が時々発生していました。調査してみると、同じインスタンスで同じタイミングに、取得するデータ量が多いクエリが実行されていました。受け取ったデータをアプリケーション内に読み込むための処理によってスレッドが占有され、データベースへの接続を確立するための処理の一部がブロックされていたのです。 poll 後に長くスレッドが占有されたことで、次の poll が実行されるまえに timers で setTimeout の callback が実行され、 Promise が reject されてしまったのです。
今回はこの事例については深く触れません。もし興味があれば、以前 NestJS MeetUp で登壇した際の資料を参照してください。

どう対策するか
このような問題への対策として 3 種類の方法をご紹介します。
1. 実行するマシンを分けてしまう
まず最もシンプルでおすすめするのは「実行するマシンを分けてしまう」ことです。この方法では、今回紹介したタイムアウトエラー関連の問題に限らず、単にレイテンシに影響が出るというような問題も解消することができます。こちらは実際にダイニーで採用している方法です。
ダイニーの場合は Cloud Run を使っているので、 Cloud Run のサービスを分けて処理の領域毎の干渉を防いだり、同時実行数を調整して同じ領域の処理同士の干渉を抑制したりしています。
インフラレベルでの分割を行うためにはアプリケーションの分割も必要になります。マイクロサービスとして分割するというのも考えられますが、そこまでやるのはコストが高く、他の事情も考慮しながら進めるべきです。やりたいことは「処理の傾向毎に実行するマシンを分けること」なので、ダイニーでは以下のように実現しています。
- API をいくつかのグループに分類し、 NestJS のモジュールとしてまとめる
- 環境変数によって読み込むモジュールを切り替えるように実装し、その単位で Cloud Run のサービスを用意する
- 開発時にローカルで立ち上げるプロセスでは全てのモジュールを読み込むようにする
- クライアント側では、用途に応じて呼び出し先を切り替える
さて、「処理の傾向毎に」という表現をしましたが、どのように分ければ良いのでしょうか?絶対的な正解はないですが、ダイニーでの例をご紹介します。
- リクエスト量の多い処理:インフラのスケーリング戦略と合わせやすい
- リアルタイム性の有無:即時性が求められ、サービス利用者への影響が大きいものを優先的に分離
- 明らかにスレッドを長く占有する処理:特にバッチ処理やデータ分析系は必ず分離すべき
2. setTimeout のあとに setImmediate してからタイムアウトエラーにする
こちらの方法はタイムアウトエラーに特化したもので、ダイニーでもまだ検証中の方法になります。先に説明した方法では同じ領域の API 同士も干渉を起こす場合がありますが、この方法ではそういった場合にも対応できる可能性があります。
まずは先ほど簡略化した Event Loop を見てみましょう。
check → timers → poll
これはループしているものなので、以下のように考えることもできます。
timers → poll → check
元の問題は poll の前に timers が実行され、そこでタイムアウトエラーが発行されることで、あと一歩で処理を続行できたのにエラーになってしまうというものでした。であればそのエラーの発行タイミングを後ろ(check フェーズ)に回してしまおうというのがこの方法の発想です。実際に先ほど例に出した実験用の実装を例に試してみましょう。
const fetchDateFromGoogle = ({ timeout }: { timeout: { timer: number; socket: number } }) =>
new PromiseResult>((resolve) => {
let timeoutTimer: ReturnTypetypeof setTimeout> | null = null;
let immediateTimer: ReturnTypetypeof setImmediate> | null = null;
timeoutTimer = setTimeout(() => {
timeoutTimer = null;
console.log("timeout");
immediateTimer = setImmediate(() => {
immediateTimer = null;
console.log("immediate");
resolve({ status: "failure", reason: "setTimeout" });
});
}, timeout.timer);
const req = https.request(
"https://www.google.com/",
{ method: "HEAD", timeout: timeout.socket },
(res) => {
if (timeoutTimer) {
clearTimeout(timeoutTimer);
timeoutTimer = null;
}
if (immediateTimer) {
clearImmediate(immediateTimer);
immediateTimer = null;
}
const data = { date: res.headers.date };
console.log("response");
resolve({ status: "success", data });
res.resume();
},
);
req.on("error", (error) => {
console.log(error);
req.destroy();
});
req.on("timeout", () => {
console.log("socket hang up, destroying request...");
req.destroy();
});
req.end();
});
やっていることは単純です。もともと setTimeout の callback の中で実行していた内容を、そのまま実行するのではなく setImmediate を挟んでから実行するだけです。
パラメーターも少し調整してみます。
const main = async () => {
console.log("Experiment Started!");
let checkCount = 0;
startCheckLoop(() => {
checkCount++;
if (checkCount > 4) {
blockThread({ weight: 800 });
}
});
console.log(
await fetchDateFromGoogle({
timeout: {
timer: 1000,
socket: 10000,
},
}),
);
};
今回は inspector なしで実行してみました。というのも、 inspector をつけていると追加の処理が挟まるのか、あまりうまくいかなかったからです。実行してみると以下のような結果になりました。 timeout のログが出てから success として判定されています。
$ node --experimental-strip-types experiment-thread-block.ts
Experiment Started!
(node:41680) ExperimentalWarning: Type Stripping is an experimental feature and might change at any time
(Use `node --trace-warnings ...` to show where the warning was created)
[check]
[check]
[check]
[check]
[check]
timeout
response
{ status: 'success', data: { date: 'Thu, 05 Jun 2025 12:40:25 GMT' } }
[check]
理論上はこれでタイムアウトを回避できますが、今回の実験では他の処理が一切なく、またほぼすべての check フェーズでスレッドを占有するようにしているため、あまり結果が安定しませんでした。 setImmediate を数回使ったり setTimeout の duration を 0 に設定したものを使い次の timers phase にタイムアウト判定をしたりすれば安定するかもしれません。もしなにかいい方法を知っている方がいれば是非コメントをいただければと思います。
3. 重たい処理を軽くする
そもそも重たい処理がなければ問題は発生しません。であればそれを軽くすれば良いわけです。とはいえどんな処理が重たいかは場合によりけりです。万能の解決法はありませんが、弊社ダイニーの ogino さんが実際に重たい処理を改善するまでの記録を記事にしてくれています。是非読んでみてください。
まとめ
Node.js はシングルスレッドで動作するため、重たい処理が他の処理の遅延やタイムアウトを引き起こすリスクがあります。本記事では Event Loop の仕組みに注目し、処理の干渉がどのように発生するかを実験を通じて確認しました。
- 重たい処理は poll のあとに集中しやすい
- 重たい処理のあとは setTimeout が poll より先に評価されることが多い
- 結果として、レスポンスが届いていてもタイムアウトになることがある
この問題に対する対応方法も 3 つ紹介しました。
- 実行環境を分離する(インフラ と アプリケーション 両方を分離する)
- Event Loop の特性に合わせて迂回する
- 重たい処理そのものを改善する
普段 Event Loop を意識することはあまりないかもしれませんが、その特性を理解することは Node.js アプリケーションの安定性向上につながります。
おしらせ
ダイニーの Platform Team では Node.js アプリケーションがより安定して実行できるようにすることで、飲食業界の未来を支えています。そんなダイニーのエンジニアリング組織について知りたい方は以下のページをご覧ください。
Views: 1

{kind=link}