
こんにちは、松尾研究所 シニアデータサイエンティストの浮田です。
生成AI界隈がLLM、AIエージェント、マルチエージェントと複雑化する中、Googleが公開した Agent Development Kit(ADK) が注目を集めています。ADKはマルチエージェントや本番運用 (デプロイやObservabilityなど) にも対応したAIエージェント開発フレームワークで、AIエージェントの活用をさらに広げるツールとなっています。
この記事では、ADKを使ってキャッチコピーを自動生成するマルチエージェントを構築した過程を紹介します。複数の役割を持つエージェントをどのように設計し、連携したか、また結果どのような出力が生成されたかもあわせて紹介します。
キャッチコピーを考える
広告や記事見出しなどのキャッチコピーを考える際には、サービスを利用する具体的なペルソナを設定した上で、そのターゲット層に響くような文章を考えることが重要です。さらに、可能なら
- ペルソナは1人分とは限らないため、複数ペルソナを設定する
- 一度キャッチコピーの初案を考えた後に、ペルソナに当てはまる人からフィードバックをもらい、キャッチコピーを改善する
までを出来れば、より優れたキャッチコピーが作成できると考えられます。
しかし、実際にはここまで作り込むのは大変です。そこで、このようなキャッチコピーの作成 (+ ペルソナからのフィードバック) をマルチエージェントで実装し、自動化することを考えました。
マルチエージェントの全体像
今回実装するマルチエージェントの全体像は図の通りです。
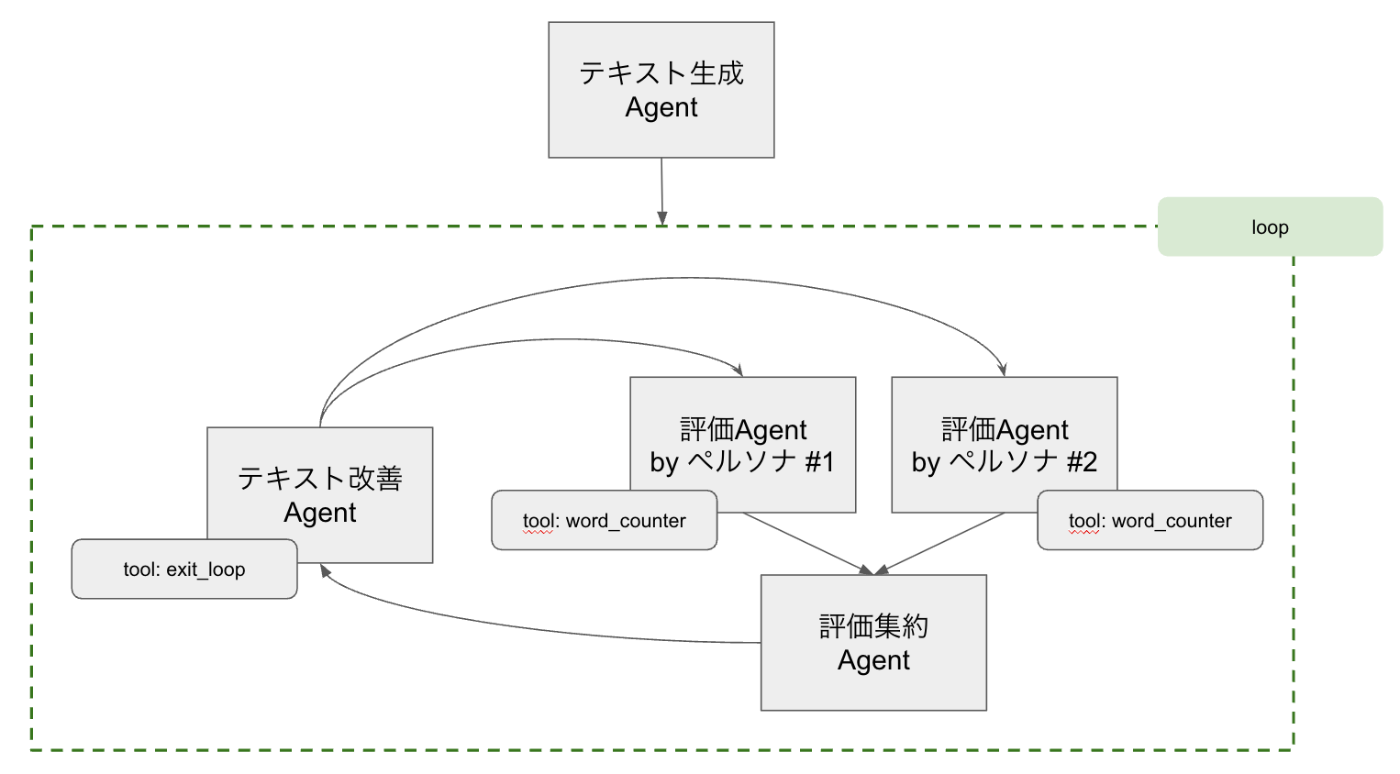
エージェント
用意するエージェントは以下の5種類です。
- テキスト生成Agent
- 評価Agent by ペルソナ #1
- 評価Agent by ペルソナ #2
- 評価集約Agent
- テキスト改善Agent
「評価Agent by ペルソナ #1 (以下、評価Agent1)」と「評価Agent by ペルソナ #2 (以下、評価Agent2)」は2体の異なるペルソナを持つ評価Agentとなります。
キャッチコピー生成プロセスの概要
キャッチコピーを生成するプロセスは以下です。
- まず、テキスト生成Agentが初案を作る
- 評価Agent1と評価Agent2がそれぞれ4点満点の評価をつける
- 評価集約Agentがこれらの評価を集計する
- テキスト改善Agentが、評価フィードバックをもとに改善案を提示する
- 2に戻る
2から5のプロセスを何度か繰り返し、後述する「停止条件」を満たせばループを終了し、最終的なキャッチコピー案を出力します。
実装のためのフレームワーク
このようなマルチエージェントを実装する際、愚直に一つ一つのエージェントとエージェント間の結合を実装しても良いですが、エージェント構築フレームワークを使うことでシンプルに実装できます。最近では以下のようなフレームワークが登場しています。
今回は、中でも比較的新しいADKを使ってみます。なお、AWS社のStrands Agentsも気になっていますが、執筆時点では、今回実装しようとしているループ構造に対応しているかがわかりませんでした。 ADKには LoopAgent クラスでループ構造が明示的に用意されていたため、ADKを活用します。
実装
ここから具体的な実装に入ります。それぞれのエージェントを用意した後に、全体のグラフ構造を定義します。なお上図の補足として、
- LLMにはOpenAIのGPT-4oを使います。ADKはGeminiがデフォルトですが、個人的にはGPTのほうが使い慣れており、ここではGPTを使います。
- テキストを生成する際には「キャッチコピーを考える時に参考にするべき例」として、別のキャッチコピーの事例をコンテキストに与えることとします。
事前準備
まず必要なライブラリや状態管理のkey、LLMモデルなどを定義します。GPTを使う場合はLiteLLMのインターフェイスでモデルを呼び出します。
import requests
from dotenv import load_dotenv
from google.adk.agents import LlmAgent, LoopAgent, SequentialAgent
from google.adk.models.lite_llm import LiteLlm
load_dotenv(override=True)
STATE_CURRENT_TEXT = "current_text"
STATE_EVAL1 = "evaluation1"
STATE_EVAL2 = "evaluation2"
STATE_EVAL_AGGREGATED = "evaluation_aggregated"
model = LiteLlm(model="openai/gpt-4o")
テキスト生成Agent
初案を作成するテキスト生成Agentです。以下のようにエージェント名、使用するモデル、エージェントの説明、インストラクション、出力の保存先をそれぞれ記述します。
initial_writer_agent = LlmAgent(
name="InitialWriterAgent",
model=model,
description="Agent to generate initial text.",
instruction=f"""
あなたは優れたコピーライターです。候補のキャッチコピーを5個程度考えてください。
タイトル以外は出力しないでください。
なお、他のライターたちは以下のようなキャッチコピーで評価を得ていますので参考にしてください: {reference_texts}
""",
output_key=STATE_CURRENT_TEXT,
)
評価Agent
2体の異なるペルソナを持つエージェントから評価してもらいます。実装はほぼ同じなので1体分のコードのみ記載します。
def word_counter(word: str) -> int:
"""
文字列の長さを返す関数
"""
return len(word)
evaluator1_agent_in_loop = LlmAgent(
name="EvaluatorAgent1",
model=model,
description="Agent to evaluate the generated text based on persona.",
instruction=f"""
# あなたのペルソナ
{persona1}
# Task
ライターが考えたキャッチコピーを評価します。
{{current_text}} のキャッチコピーを以下の1-4点で評価し、評価結果を理由とともに出力してください。
4: いいねを押したい, 3: 読んでみたい, 2: 特に何とも思わない, 1: 面白くない
キャッチコピーが不適切な場合は、厳しく評価してください。
また、キャッチコピーの長さを `word_counter` ツールで計算し、40文字を超えている場合は、長すぎるのでその旨を理由に書いて1点減点してください。
""",
output_key=STATE_EVAL1,
tools=[word_counter],
)
テキスト生成Agentと基本的には同じですが、いくつか異なる点もあります。
- テキスト生成Agent・テキスト改善Agentは生成した文章を
STATE_CURRENT_TEXT(="current_text") に出力するので、これを評価Agentのinstructionで使用します。 - 生成されたキャッチコピーが長すぎる場合には罰則を入れています。文字数を正確に計算するために
word_counter関数を用意し、tools引数で呼び出しています。今回は40字を超えていると1点減点するようにしています。
評価集約Agent
評価Agent1・評価Agent2からの評価を集約します。各評価は evaluation1, evaluation2 に出力されるので、これらを評価集約Agentのinstructionで使用します。出力は STATE_EVAL_AGGREGATED に保存します。
evaluation_aggregator_agent_in_loop = LlmAgent(
name="EvaluationAggregatorAgent",
model=model,
description="Agent to aggregate evaluations from multiple evaluators.",
instruction=f"""
{{current_text}}という各キャッチコピーにつき、以下の評価がつきました。
# {persona1} からの評価
{{evaluation1}}
# {persona2} からの評価
{{evaluation2}}
これらの評価を、キャッチコピーごとにまとめ直して出力してください。
""",
output_key=STATE_EVAL_AGGREGATED,
)
テキスト改善Agent
def exit_loop(tool_context):
print(f" [Tool Call] exit_loop triggered by {tool_context.agent_name}")
tool_context.actions.escalate = True
return {}
refiner_agent_in_loop = LlmAgent(
name="RefinerAgent",
model=model,
description="Agent to refine the text based on the evaluation.",
instruction=f"""
あなたは優れたコピーライターです。
あなたが以前考えたキャッチコピーは{{current_text}}ですが、これに対して、以下の評価がつきました (それぞれ4点満点)。
# 評価
{{evaluation_aggregated}}
# Task
評価結果をキャッチコピーごとによく読み、まずは「評価者全員が"4点 (いいねを押したい) "と評価したコピー」が存在するかを判定してください。
* もし存在するなら、 `exit_loop` ツールを実行してください。
* そうでなければ、評価を改善するためにキャッチコピーをブラッシュアップし、改善したキャッチコピーを出力してください (最大5個)。
なお、他のライターたちは以下のようなキャッチコピーで評価を得ていますので参考にしてください: {reference_texts}
""",
tools=[exit_loop],
output_key=STATE_CURRENT_TEXT,
)
ここでは停止条件として exit_loop 関数を作成しています。もし全評価者が満点をつけていたなら、それ以上改善する必要はないため、 exit_loop ツールを呼び出しループを停止します。
停止しない場合は STATE_CURRENT_TEXT に改善案を出力し、再度ループを回します。
グラフ構造の定義
これまでに用意したエージェントをノードとするグラフ構造を作ります。ループの部分は LoopAgent クラスを用いて簡単に書けます。またテキスト作成Agentとループの部分はワークフローとなるので、 SequentialAgent クラスを用います。これで最初に示した図の構造が出来上がりました。
refinement_loop = LoopAgent(
name="RefinementLoop",
sub_agents=[
evaluator1_agent_in_loop,
evaluator2_agent_in_loop,
evaluation_aggregator_agent_in_loop,
refiner_agent_in_loop,
],
max_iterations=5,
)
root_agent = SequentialAgent(
name="TextGenerationAgent",
sub_agents=[initial_writer_agent, refinement_loop],
description="Agent to manage a sequence of tasks related to text generation.",
)
LoopAgent には max_iterations 引数があり、今回は5に設定しています。すなわち、このループは 「全評価者が満点をつけていた場合」もしくは「ループが5回回った場合」のいずれかに停止 するものとなります。
実験
このマルチエージェントを実際に動かしてみましょう。私はちょうど今、執筆中のこのブログのタイトルをどうすべきか悩んでいるので、このブログのタイトルをこのマルチエージェントに作ってもらいましょう。
追加の準備
ペルソナには以下の2人を設定します。技術ブログなので、技術に強い方に読んでもらいたいですし、広くエンジニア全般に読んでもらいたいです。
persona1 = "技術ゴリゴリのデータサイエンティスト。生成AIやLLMに関心が高い"
persona2 = "エンジニア。バズ狙いの誇張したワードは嫌い"
またテキスト作成・テキスト改善時には「参考にすべき例」をコンテキストに与えていますが、この実験ではZennのTechカテゴリーのトレンド記事のタイトルを入れてみます。
def fetch_articles() -> list[str]:
url = "https://zenn-api.vercel.app/api/trendTech"
response = requests.get(url).json()
return [article["title"] for article in response]
reference_texts = fetch_articles()
実行
フォルダ構成は以下のようにします。
.env
agent/
├── __init__.py
└── agent.py
.env には OPENAI_API_KEY の環境変数を設定します。
.env
OPENAI_API_KEY={APIキーの値}
agent.py にコードを記述します。
全体のコード
agent.py
import requests
from dotenv import load_dotenv
from google.adk.agents import LlmAgent, LoopAgent, SequentialAgent
from google.adk.models.lite_llm import LiteLlm
load_dotenv(override=True)
STATE_CURRENT_TEXT = "current_text"
STATE_EVAL1 = "evaluation1"
STATE_EVAL2 = "evaluation2"
STATE_EVAL_AGGREGATED = "evaluation_aggregated"
model = LiteLlm(model="openai/gpt-4o")
persona1 = "技術ゴリゴリのデータサイエンティスト。生成AIやLLMに関心が高い"
persona2 = "エンジニア。バズ狙いの誇張したワードは嫌い"
def fetch_articles() -> list[str]:
url = "https://zenn-api.vercel.app/api/trendTech"
response = requests.get(url).json()
return [article["title"] for article in response]
reference_texts = fetch_articles()
initial_writer_agent = LlmAgent(
name="InitialWriterAgent",
model=model,
description="Agent to generate initial text.",
instruction=f"""
あなたは優れたコピーライターです。候補のキャッチコピーを5個程度考えてください。
タイトル以外は出力しないでください。
なお、他のライターたちは以下のようなキャッチコピーで評価を得ていますので参考にしてください: {reference_texts}
""",
output_key=STATE_CURRENT_TEXT,
)
def word_counter(word: str) -> int:
"""
文字列の長さを返す関数
"""
return len(word)
evaluator1_agent_in_loop = LlmAgent(
name="EvaluatorAgent1",
model=model,
description="Agent to evaluate the generated text based on persona.",
instruction=f"""
# あなたのペルソナ
{persona1}
# Task
ライターが考えたキャッチコピーを評価します。
{{current_text}} のキャッチコピーを以下の1-4点で評価し、評価結果を理由とともに出力してください。
4: いいねを押したい, 3: 読んでみたい, 2: 特に何とも思わない, 1: 面白くない
キャッチコピーが不適切な場合は、厳しく評価してください。
また、キャッチコピーの長さを `word_counter` ツールで計算し、40文字を超えている場合は、長すぎるのでその旨を理由に書いて1点減点してください。
""",
output_key=STATE_EVAL1,
tools=[word_counter],
)
evaluator2_agent_in_loop = LlmAgent(
name="EvaluatorAgent2",
model=model,
description="Agent to evaluate the generated text based on persona.",
instruction=f"""
# あなたのペルソナ
{persona2}
# Task
ライターが考えたキャッチコピーを評価します。
{{current_text}} のキャッチコピーを以下の1-4点で評価し、評価結果を理由とともに出力してください。
4: いいねを押したい, 3: 読んでみたい, 2: 特に何とも思わない, 1: 面白くない
キャッチコピーが不適切な場合は、厳しく評価してください。
また、キャッチコピーの長さを `word_counter` ツールで計算し、40文字を超えている場合は、長すぎるのでその旨を理由に書いて1点減点してください。
""",
output_key=STATE_EVAL2,
tools=[word_counter],
)
evaluation_aggregator_agent_in_loop = LlmAgent(
name="EvaluationAggregatorAgent",
model=model,
description="Agent to aggregate evaluations from multiple evaluators.",
instruction=f"""
{{current_text}}という各キャッチコピーにつき、以下の評価がつきました。
# {persona1} からの評価
{{evaluation1}}
# {persona2} からの評価
{{evaluation2}}
これらの評価を、キャッチコピーごとにまとめ直して出力してください。
""",
output_key=STATE_EVAL_AGGREGATED,
)
def exit_loop(tool_context):
print(f" [Tool Call] exit_loop triggered by {tool_context.agent_name}")
tool_context.actions.escalate = True
return {}
refiner_agent_in_loop = LlmAgent(
name="RefinerAgent",
model=model,
description="Agent to refine the text based on the evaluation.",
instruction=f"""
あなたは優れたコピーライターです。
あなたが以前考えたキャッチコピーは{{current_text}}ですが、これに対して、以下の評価がつきました (それぞれ4点満点)。
# 評価
{{evaluation_aggregated}}
# Task
評価結果をキャッチコピーごとによく読み、まずは「評価者全員が"4点 (いいねを押したい) "と評価したコピー」が存在するかを判定してください。
* もし存在するなら、 `exit_loop` ツールを実行してください。
* そうでなければ、評価を改善するためにキャッチコピーをブラッシュアップし、改善したキャッチコピーを出力してください (最大5個)。
なお、他のライターたちは以下のようなキャッチコピーで評価を得ていますので参考にしてください: {reference_texts}
""",
tools=[exit_loop],
output_key=STATE_CURRENT_TEXT,
)
refinement_loop = LoopAgent(
name="RefinementLoop",
sub_agents=[
evaluator1_agent_in_loop,
evaluator2_agent_in_loop,
evaluation_aggregator_agent_in_loop,
refiner_agent_in_loop,
],
max_iterations=5,
)
root_agent = SequentialAgent(
name="TextGenerationAgent",
sub_agents=[initial_writer_agent, refinement_loop],
description="Agent to manage a sequence of tasks related to text generation.",
)
agent/ ディレクトリの外で、以下で実行します。
[user]: と入力が促されるので、今回の記事のタイトルを作ってもらうように指示を入力します。
[user]: 技術記事のタイトルを考えて。記事の内容は、LLMのマルチエージェントツールであるGoogle社のAgent Development Kit (ADK) に関するものです。このツールを使い、キャッチコピーを自動生成するマルチエージェントを構築した過程を紹介します。複数の役割を持つエージェントをどのように設計し、連携したか、また結果どのような出力が生成されたかもあわせて解説します。タイトルには"Google ADK", "マルチエージェント", "キャッチコピー" (もしくは"コピーライティング") のキーワードを含めたいが、誇張した単語は避けてください。
結果
1ターン目
まず生成・評価した結果はこちらです。いずれも2~3点の評価は得られつつも、4点満点は付きませんでした。
1. 「Google ADKによるマルチエージェント設計でキャッチコピー自動生成」
- 評価合計: 6点
- 評価詳細:
- 技術ゴリゴリのデータサイエンティスト: 3点 (読んでみたい)
- エンジニア: 3点 (読んでみたい)
- 理由概要: キーワードを含み、端的に内容を伝えるが、インパクトや具体的な利点が不足している。
2. 「Google ADKを用いたマルチエージェントの連携とコピーライティングの実践」
- 評価合計: 6点
- 評価詳細:
- 技術ゴリゴリのデータサイエンティスト: 3点 (読んでみたい)
- エンジニア: 3点 (読んでみたい)
- 理由概要: 読者に興味を引く内容で、文もまとまっているが、インパクトや新規性が不足。
3. 「マルチエージェントを活用したGoogle ADKでのキャッチコピー生成の試み」
- 評価合計: 6点
- 評価詳細:
- 技術ゴリゴリのデータサイエンティスト: 3点 (読んでみたい)
- エンジニア: 3点 (読んでみたい)
- 理由概要: 試みという言葉が興味を引くが、特に強調すべき独自性や深い洞察が不足。
4. 「Google ADKを基にしたマルチエージェントシステムでのコピーライティングの導入」
- 評価合計: 4点
- 評価詳細:
- 技術ゴリゴリのデータサイエンティスト: 2点 (特に何とも思わない)
- エンジニア: 2点 (特に何とも思わない)
- 理由概要: 文字数が長く、内容が冗長なため、インパクトに欠けている。
5. 「Google ADKを駆使したキャッチコピー生成におけるマルチエージェントの役割と設計」
- 評価合計: 4点
- 評価詳細:
- 技術ゴリゴリのデータサイエンティスト: 2点 (特に何とも思わない)
- エンジニア: 2点 (特に何とも思わない)
- 理由概要: 文字数が長すぎ、内容が複雑で読みにくい。明確な方向性が不足。
2ターン目
1ターン目の結果を受けて、2ターン目での生成・評価結果はこちらです。全体的に評価値は改善傾向にあります。特に5個中2個で全員4点満点の評価が付き、今回の実験では2ターンで終了しました。
1. 「Google ADK × マルチエージェントで進化するキャッチコピー作成の未来」
- 評価合計: 6点
- 評価詳細:
- 技術ゴリゴリのデータサイエンティスト: 3点 (読んでみたい)
- エンジニア: 3点 (読んでみたい)
- 理由概要: インパクトがあり、未来を強調するが、具体的な利点が不足している。
2. 「マルチエージェント活用術:Google ADKで変わるキャッチコピー生成」
- 評価合計: 8点
- 評価詳細:
- 技術ゴリゴリのデータサイエンティスト: 4点 (いいねを押したい)
- エンジニア: 4点 (いいねを押したい)
- 理由概要: 簡潔で利点と変化を明確に伝え、実用性が感じられるため高評価。
3. 「Google ADKとマルチエージェント連携による革新的コピーライティング」
- 評価合計: 8点
- 評価詳細:
- 技術ゴリゴリのデータサイエンティスト: 4点 (いいねを押したい)
- エンジニア: 4点 (いいねを押したい)
- 理由概要: 革新性を強調し、連携の具体性もあり、期待感がある。
4. 「Google ADK活用法:マルチエージェントで独創的なコピーを生み出す方法」
- 評価合計: 6点
- 評価詳細:
- 技術ゴリゴリのデータサイエンティスト: 3点 (読んでみたい)
- エンジニア: 3点 (読んでみたい)
- 理由概要: 独創性に期待感はあるが、内容が一般的過ぎ具体性が不足。
5. 「キャッチコピー生成の新時代—Google ADKとマルチエージェント改革」
- 評価合計: 6点
- 評価詳細:
- 技術ゴリゴリのデータサイエンティスト: 3点 (読んでみたい)
- エンジニア: 3点 (読んでみたい)
- 理由概要: 新時代と改革という言葉で興味を引くが、具体的情報が不足。
複数の案の評価が満点となりましたが、あとは私の主観で2番目の「マルチエージェント活用術:Google ADKで変わるキャッチコピー生成」を採用し、本記事のタイトルにしました。
まとめ・今後の展望
このようにマルチエージェントを組み立てることで、現実世界のように「案出し」と「複数のペルソナからのフィードバック」のループを回すことができます。今回は本記事のタイトル生成に活用しましたが、広告など様々な場面で活用できると考えています。
また今回は簡単な実装としましたが、より洗練するなら以下の方向が考えられます。
ペルソナをAIで作り込む
生成AIを用いてペルソナを生成する事例が研究・ビジネスともに発展しています。今回の評価Agentのペルソナは短文で与えましたが、別途生成AIを用いてより具体的なペルソナを作り込む方向が考えられます。
各エージェントの出力を厳格化
例えば評価Agentには「評価結果を理由とともに出力してください。」とだけ指示していますが、評価Agentが毎回確実に評価結果の数値と理由を両方出力してくれる保証はありません。Structured outputを使うことで確実に期待する出力を得られるようになります。
本番稼働
ADKはGoogle Cloudとの相性が良くObservabilityなどにも対応していることから、Google Cloud上で動かし、Observabilityの仕組みも整えることが考えられます。
Views: 0

{kind=link}