

最近、AIの世界がマジで熱いんですよね。特に大規模言語モデル(LLM)の進化が半端ないです。昨日、Qwenチームが新しいモデル「Qwen3」をリリースしたんですが、これがかなりのモンスターなんですよ。コーディングや数学、推論タスクでめちゃくちゃ良い成績を出してるんです。
僕は普段からローカルでAIモデルを動かすのが好きなんですけど、今回はLMStudioを使ってQwen3を自分のマシンで動かしてみました。クラウドAPIも便利ですけど、やっぱり自分のPCで動かせると、プライバシーの心配もないし、コスト管理もしやすいんですよね。それに、オフラインでも使えるのが最高です!
Qwen3って何がすごいの?
Qwen3は2025年4月29日にリリースされた第3世代のLLMで、前のバージョンから大幅に進化しています。特に推論能力が向上していて、Mixture-of-Experts(MoE)というアーキテクチャを採用したモデルもあります。
モデルのバリエーション
Qwen3には様々なサイズのモデルがあります:
-
MoEモデル:
- Qwen3-235B-A22B(総パラメータ235B、活性パラメータ22B)
- Qwen3-30B-A3B(総パラメータ30B、活性パラメータ3B)
-
密モデル:
- Qwen3-32B
- Qwen3-14B
- Qwen3-8B
- Qwen3-4B
- Qwen3-1.7B
- Qwen3-0.6B
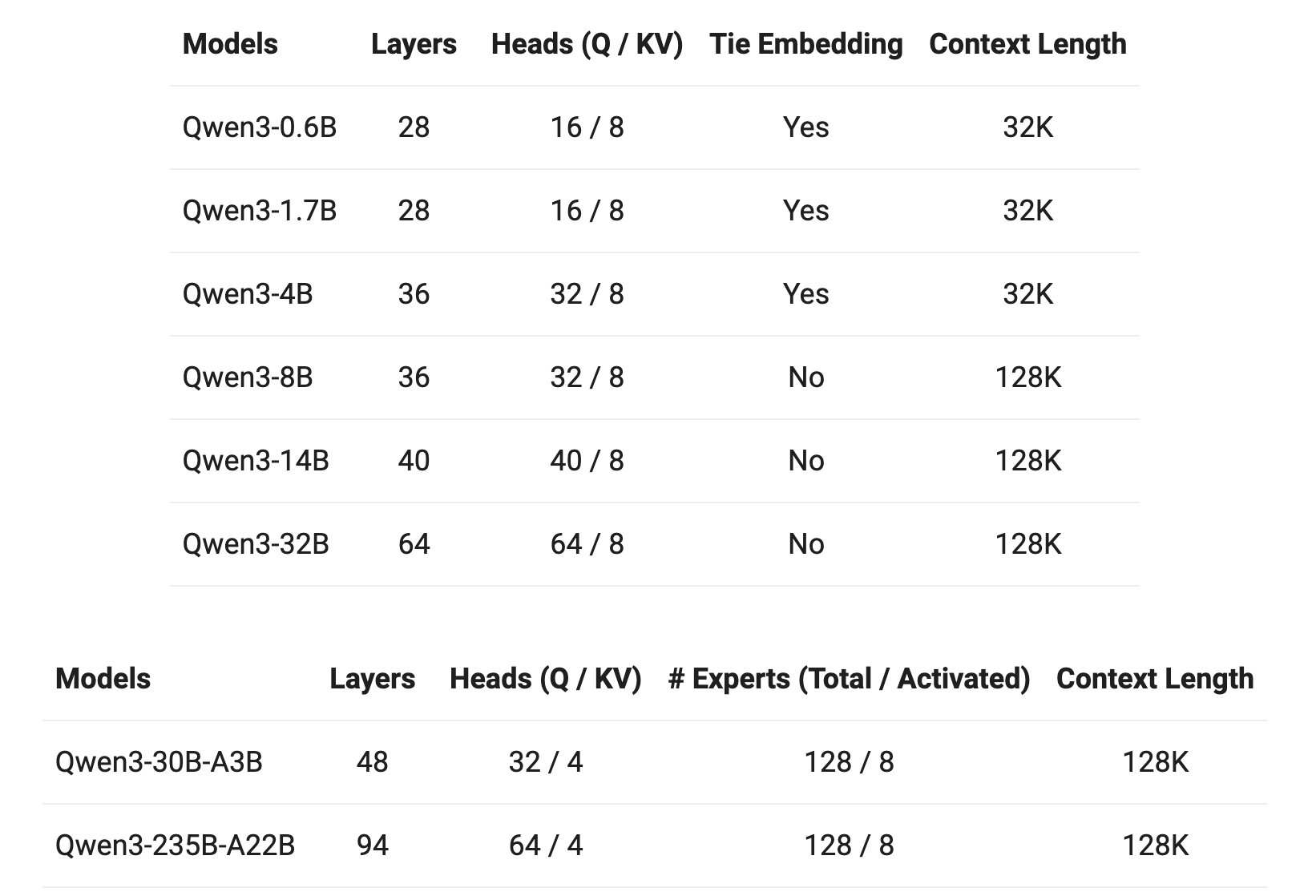
全部Apache 2.0ライセンスでオープンソース化されているのがすごいですよね!
技術的な特徴
-
思考モードの切り替え
- 思考モード:複雑な問題に対して段階的に推論を行い、深く考えた上で回答
- 非思考モード:シンプルな質問に対して即座に回答
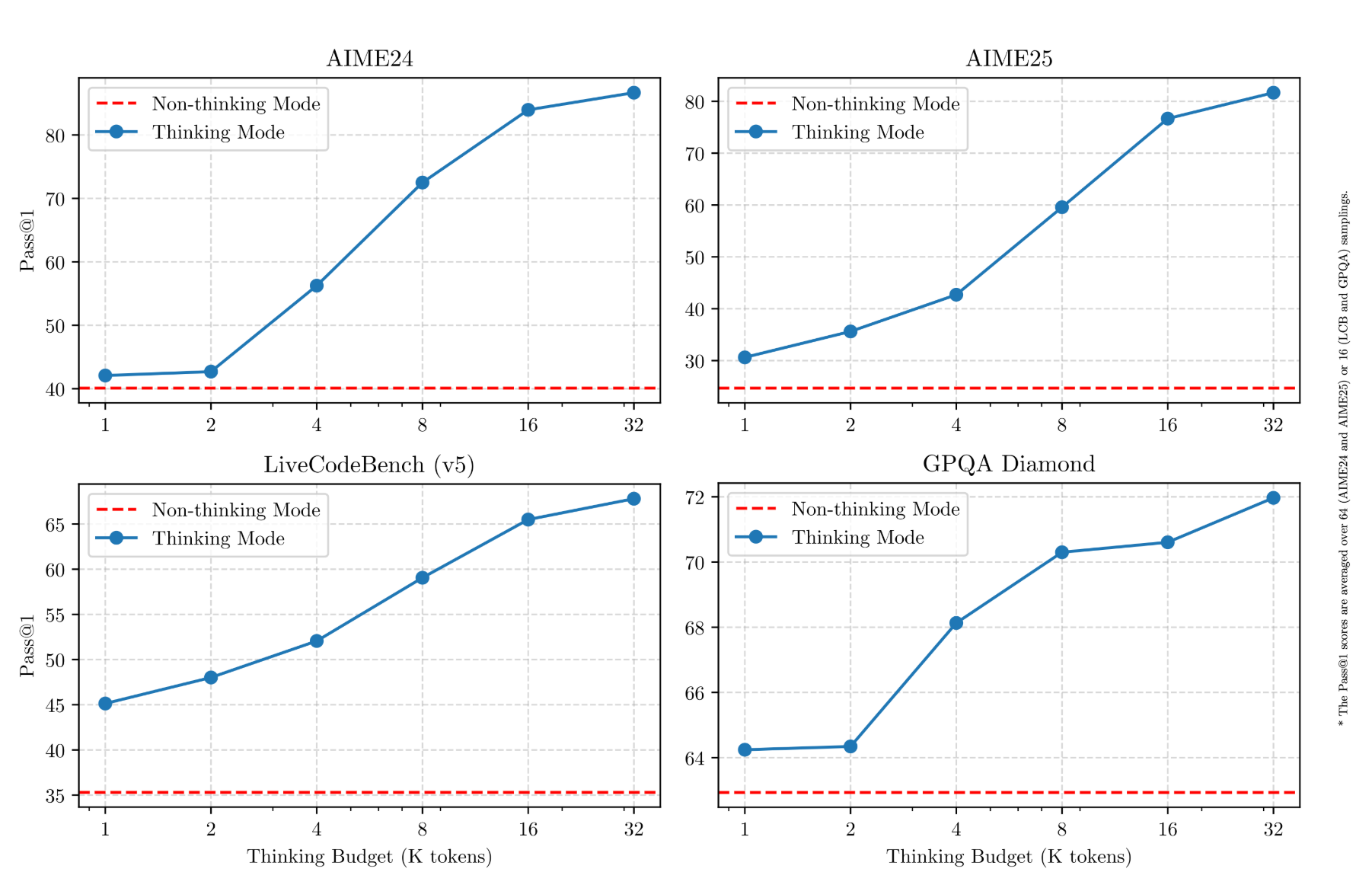
これ、実際使ってみると便利ですよ。複雑な問題は「よく考えて」って指示できるし、簡単な質問はサクッと答えてくれる。
-
多言語サポート
119言語・方言をサポートしているので、日本語でも問題なく使えます。 -
エージェント機能の強化
コード生成能力が向上していて、プログラマーとしては嬉しい限りです。 -
トレーニング方法の進化
ベンチマークパフォーマンス
驚くべきことに、Qwen3の小さいモデルが前世代の大きなモデルと同等以上のパフォーマンスを発揮しています:
-
Qwen3-1.7B≈Qwen2.5-3B -
Qwen3-4B≈Qwen2.5-7B(一部の側面ではQwen2.5-72B-Instructに匹敵!) -
Qwen3-8B≈Qwen2.5-14B -
Qwen3-14B≈Qwen2.5-32B -
Qwen3-32B≈Qwen2.5-72B
特にSTEM、コーディング、推論タスクでの性能向上が著しいです。MoEモデルに至っては、活性パラメータが全体の約10%だけなのに、大きな密モデルと同等のパフォーマンスを発揮するんですよ。これはトレーニングと推論のコストを大幅に削減できるということです。
LMStudioでQwen3を動かす方法
LMStudioは、LLMをローカルで簡単に動かせるツールで、複雑な設定なしでモデルを管理・実行できます。コマンドラインツールとAPIサーバーも提供しているので、開発者にとっても使いやすいんですよね。
インストールと設定
まず、LMStudioをインストールして、少なくとも一度は起動しておく必要があります。その後、コマンドラインツール「lms」をブートストラップします。
macOSやLinuxの場合:
~/.lmstudio/bin/lms bootstrap
Windowsの場合:
cmd /c %USERPROFILE%/.lmstudio/bin/lms.exe bootstrap
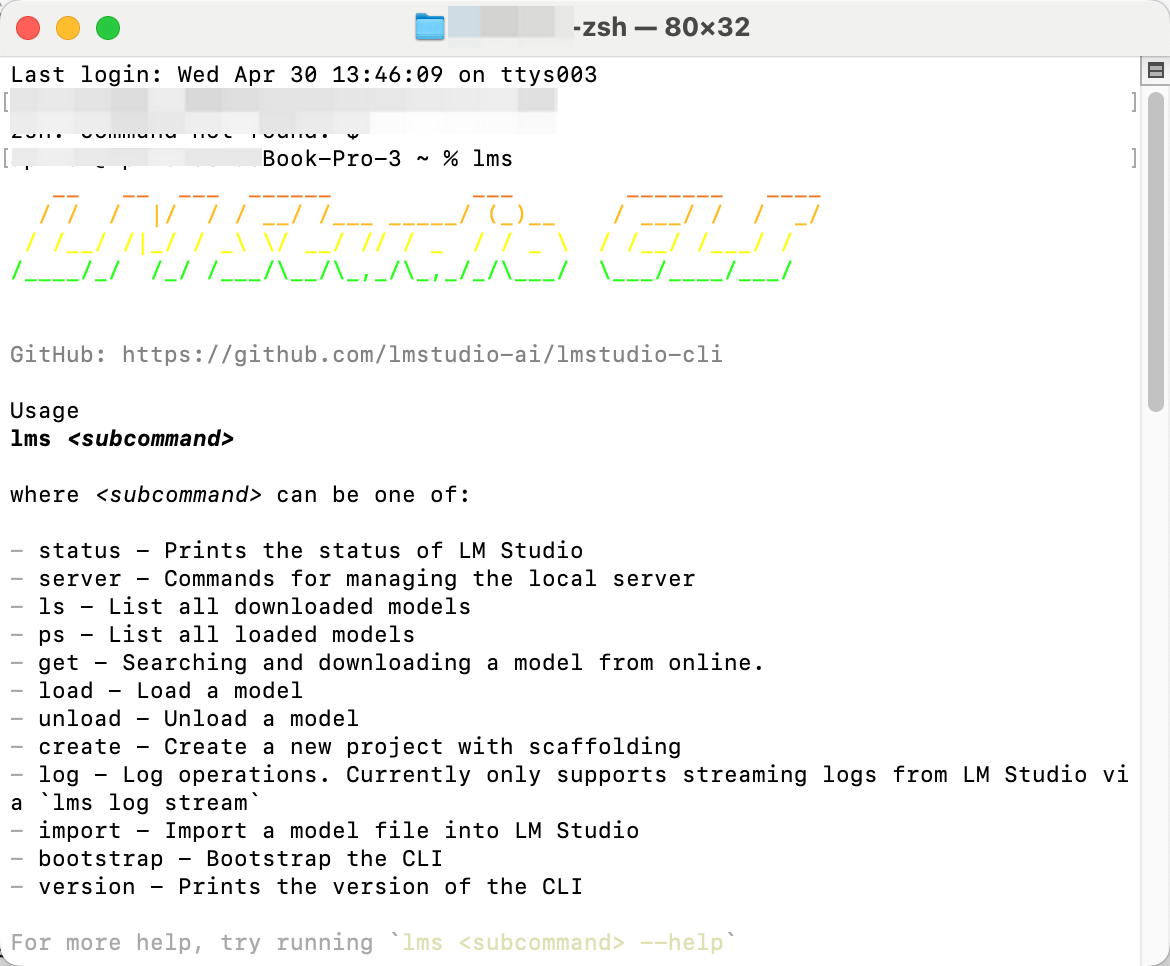
インストールを確認するには、新しいターミナルウィンドウを開いてlmsコマンドを実行します:
以下のような出力が表示されるはずです:
lms - LM Studio CLI - v0.2.22
GitHub: https://github.com/lmstudio-ai/lmstudio-cli
Usage
lms
where can be one of:
- status - Prints the status of LM Studio
- server - Commands for managing the local server
- ls - List all downloaded models
- ps - List all loaded models
- load - Load a model
- unload - Unload a model
- create - Create a new project with scaffolding
- log - Log operations. Currently only supports streaming logs from LM Studio via `lms log stream`
- version - Prints the version of the CLI
- bootstrap - Bootstrap the CLI
For more help, try running `lms --help`
Qwen3モデルのダウンロードと実行
LMStudioは様々なモデルをサポートしていて、Qwen3も含まれています。利用可能なQwen3モデルは以下の通りです:
qwen3:0.6bqwen3:1.7bqwen3:4bqwen3:8bqwen3:14bqwen3:32b-
qwen3:30b-a3b(小型MoEモデル)
例えば、1.7Bパラメータモデルをダウンロードして実行するには:
このコマンドでモデルがダウンロードされ、インタラクティブなチャットセッションが開始されます。
APIサーバーの起動と停止
APIとして使用する場合は、サーバーを起動します:

使用が終わったら停止します:
コードからQwen3を呼び出す
curlを使用する場合:
curl http://localhost:1234/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3-1.7b",
"messages": [
{ "role": "system", "content": "Always answer in rhymes." },
{ "role": "user", "content": "Introduce yourself." }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
}'
Pythonを使用する場合:
from openai import OpenAI
# ローカルサーバーに接続
client = OpenAI(base_url="http://localhost:1234/v1",
api_key="lm-studio")
completion = client.chat.completions.create(
model="qwen3-1.7b",
messages=[
{"role": "system", "content": "Always answer in rhymes."},
{"role": "user", "content": "Introduce yourself."}
],
temperature=0.7,
)
print(completion.choices[0].message)
TypeScriptを使用する場合:
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: "lm-studio", // 実際には必要ありません
baseUrl: "http://localhost:1234/v1"
});
async function main() {
const chatCompletion = await client.chat.completions.create({
messages: [{ role: 'user', content: 'Say this is a test' }],
model: "qwen3-1.7b",
});
}
main();
ApidogでLMStudioのAPIをテストする
個人的に、APIのテストにはApidogがめちゃくちゃ便利だと思います。LMStudioのAPIモードと相性が良くて、リクエストの送信や応答の確認が簡単にできるんですよ。
Apidogを使ってLMStudioのAPIをテストする方法は以下の通りです:
- 新しいAPIリクエストを作成
- エンドポイントに
http://localhost:1234/v1/chat/completionsを設定 - リクエストを送信し、リアルタイムタイムラインで応答を監視
- JSONPath抽出機能を使って応答を自動的に解析(この機能はPostmanより優れていると思います)
ストリーミング応答をテストする場合は、リクエストボディに "stream": true を追加します:
{
"model": "qwen3-1.7b",
"messages": [
{ "role": "system", "content": "必ず韻を踏んで答えてください。" },
{ "role": "user", "content": "自己紹介をしてください。" }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
}
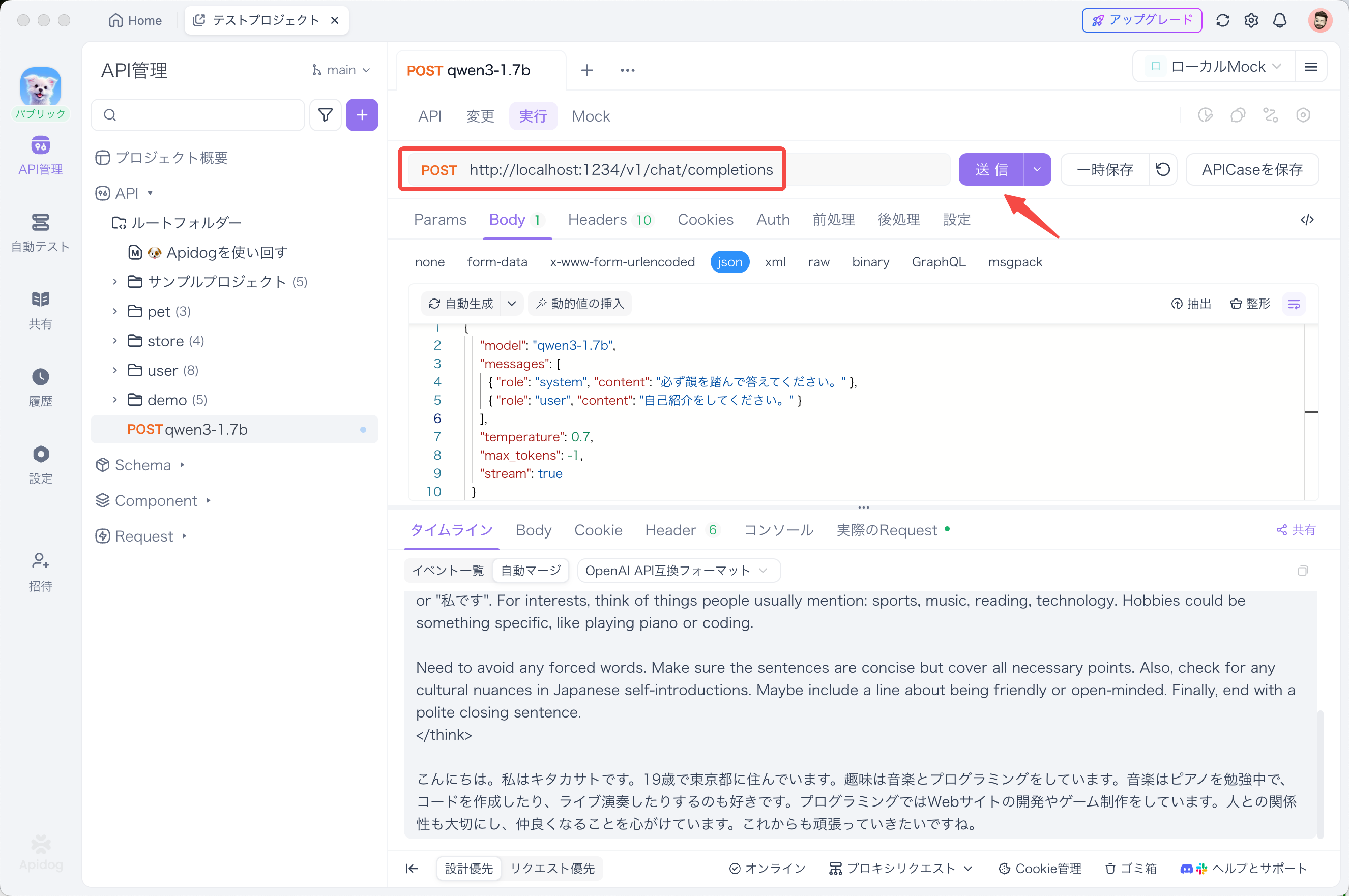
Apidogの強化されたストリーミング機能を使えば、ストリーミングメッセージが統合されて、デバッグが簡単になります。これは実際のアプリケーション開発で非常に役立ちますよ。
まとめ
Qwen3は本当に素晴らしいモデルで、特に小さいサイズのモデルでも前世代の大きなモデルと同等以上のパフォーマンスを発揮するのが印象的です。LMStudioを使えば、これらの強力なモデルを簡単にローカルで実行できるので、プライバシーを確保しながら、コスト効率よく最新のAI技術を活用できます。
個人的には、Qwen3-4Bが特に気に入っています。比較的小さいサイズながら、驚くほど高性能で、普通のPCでもスムーズに動作します。ハイブリッド思考モードや多言語サポートなどの機能も、実際のプロジェクトで非常に役立ちます。
ハードウェアとソフトウェアのエコシステムが進化し続ける中で、大規模言語モデルの力はますます民主化され、クラウドサーバーから私たちのローカルマシンへと移行しています。LMStudioとApidogを使ってQwen3を試してみて、このローカルAI革命の最前線を体験してみてください!
皆さんも試してみましたか?どんな用途に使っているか、コメント欄で教えてくださいね。また、他のモデルとの比較や、パフォーマンスの違いについても議論できたら嬉しいです。
Views: 1

{kind=link}