

はじめに
国内の企業において人事領域におけるデータの活用がなかなか進まないという現状をよく耳にします。
人事施策においても「データに基づいた意思決定」を取り入れたいという企業はとても多いと思いますが、特に”人”に関わる人事領域(HR)においては、まだまだ経験や勘に頼る部分が大きく、これらに基づいた意思決定が根強く残っているというのが現状ではないでしょか。
必ずしも人事施策の意思決定をデータに頼る必要はないですが、従業員の離職防止、適材適所の配置、公平な評価と報酬、採用効率の向上など…、これらの課題に対し、データ分析の結果を参考にすることは強力な相棒かつ武器になると思います。
ということで前置きが長くなりましたが、今回はPythonのWebアプリ用のフレームワークであるStreamlitを使ってHR Analytics Dashboard(以下、HRAD)の試作品(簡易版) を作成したので投稿させていただきました。HRADでは、仮の分析用データセットとしてIBMが公開している人事データセットを用いて、離職分析、給与分析、パフォーマンス分析、予測シミュレーションなど、多角的に人事分析を行えるような設計にして実際に分析結果を可視化するツールとなるように実装しました。
この記事を通して、
- HRデータ分析ではデータをどのように分析して可視化できるのか?
- Streamlitを使えば、個人でもどれくらいの人事データ分析ダッシュボードが作れるのか?
- 人事施策にデータサイエンスの知識がどのように応用できるのか?
といった点をかいつまんでお伝えできればと思います。HR担当者の方、人事データ分析に興味のある方、Streamlitを使って何か作ってみたい学習者の方などの参考になれば嬉しいです。
※この記事で書いていないこと
- 各分析結果の解釈の仕方などは、ここでは書いていません。
目次
簡単なプロフィールと開発の背景
少しだけ自己紹介させてください。私はこれまで人材紹介業、社労士業などの経験を経て、現在は機械学習やAIの分野に強く興味を持って学んでいる最中です。
また、社会人大学生として経済学部にて確率統計や金融論を専攻するかたわら、独学ではありますが金融機械学習、LLM(FineTunigの記事)、深層学習、個人でのWEBアプリ開発(個人開発の記事)など興味のおもむくままに勉強しているといった具合です。エンジニア経験もIT業界での勤務経験もないため、技術的な部分の発信内容に不備があるかもしれませんがどうかご容赦いただけますと幸いです。
これまでの学びを通して、いまでは理論だけでなく「実際に手を動かして価値を生み出す」ことの重要性を痛感しています。特に、経済学で学ぶ人的資本論やインセンティブ設計、統計学や機械学習で学ぶ予測モデリングは、HR領域とも非常に親和性が高いと感じています。
HRADの開発は、これらの知識やスキルを統合して実用的な形にするためのチャレンジでもありました。また、以前MediNoteというWebアプリをNext.jsとFirebaseで開発した経験から、今回はPythonエコシステム内で完結し、迅速なプロトタイピングの開発が可能なStreamlitを選択しました。
※まだまだ、プロトタイプの簡易版ですのでその点ご承知おきください。
HRAD(プロトタイプ)の機能の紹介・できること
HRADは、左側のサイドバーから分析したいテーマを選択するだけで、様々な角度から人事データを可視化・分析ができます。以下に主な機能を紹介していきたいと思います。
- HR Analytics Dashboard
- ダッシュボード構成(Streamlitで実装)
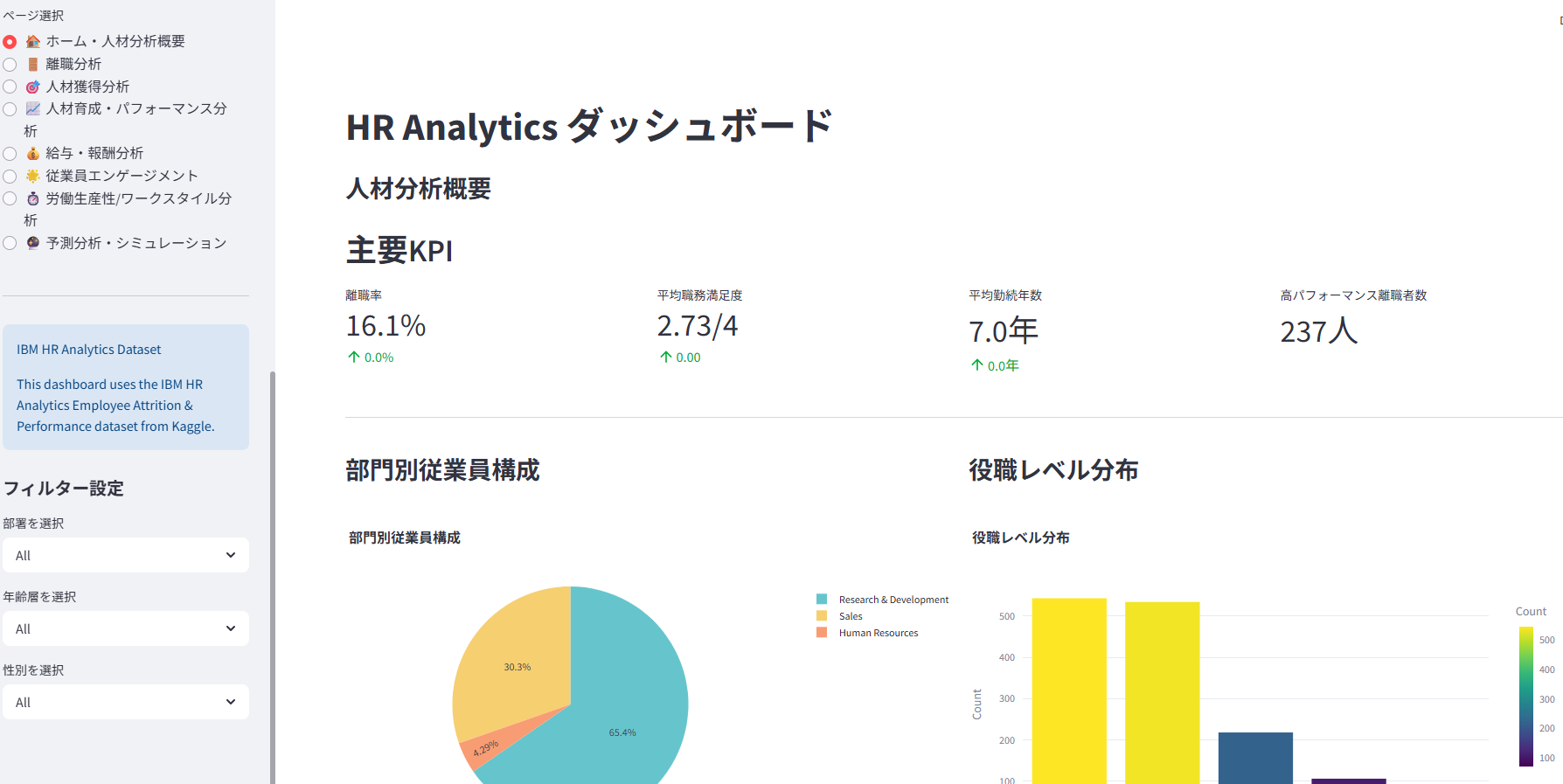
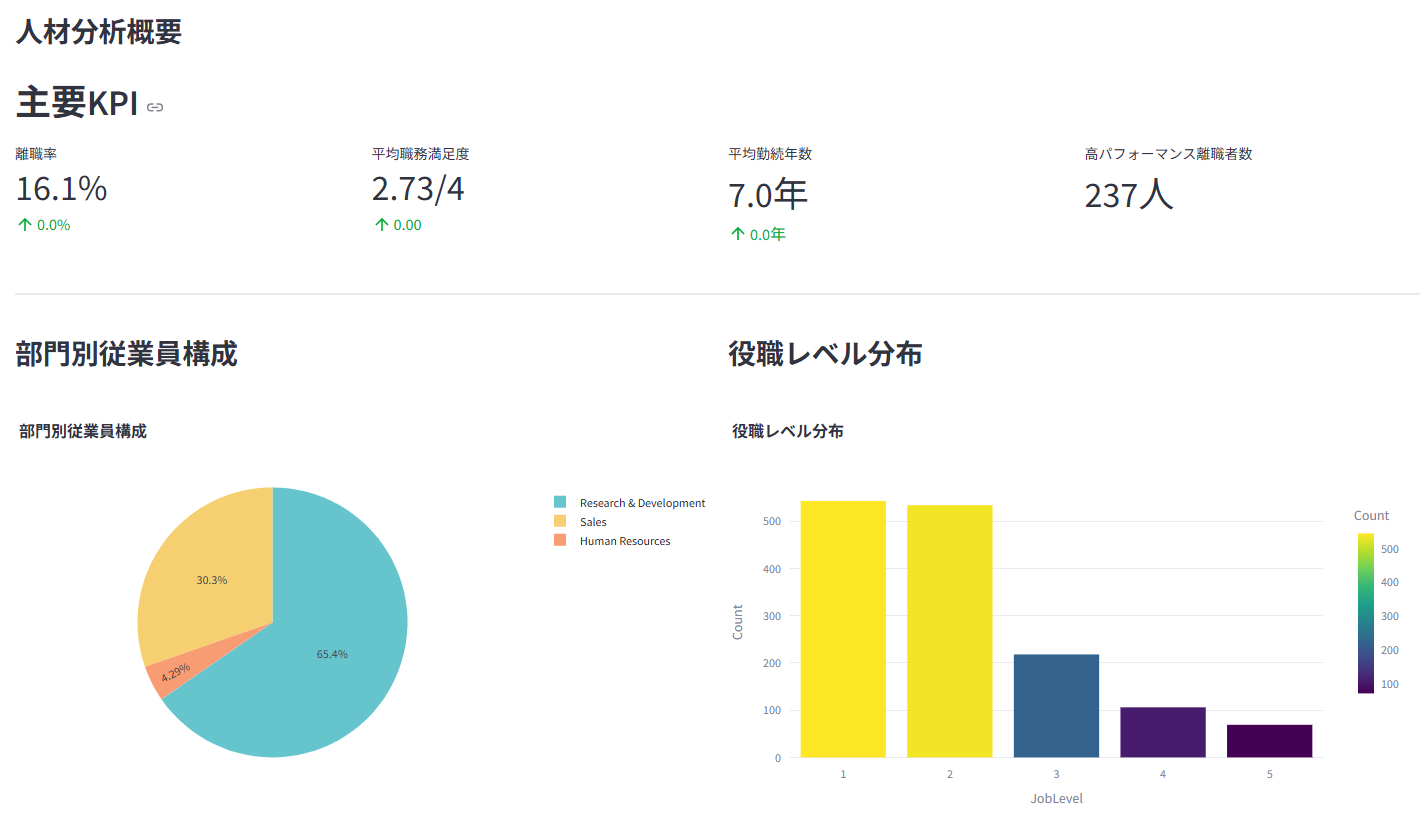
1. 🏠 ホーム・人材分析概要
- 従業員数、平均年齢、平均勤続年数、全体離職率などの主要KPIを一目で把握。
- 部門別従業員構成や役職レベル分布を可視化。
- データ全体の概要と品質(欠損値など)を確認。
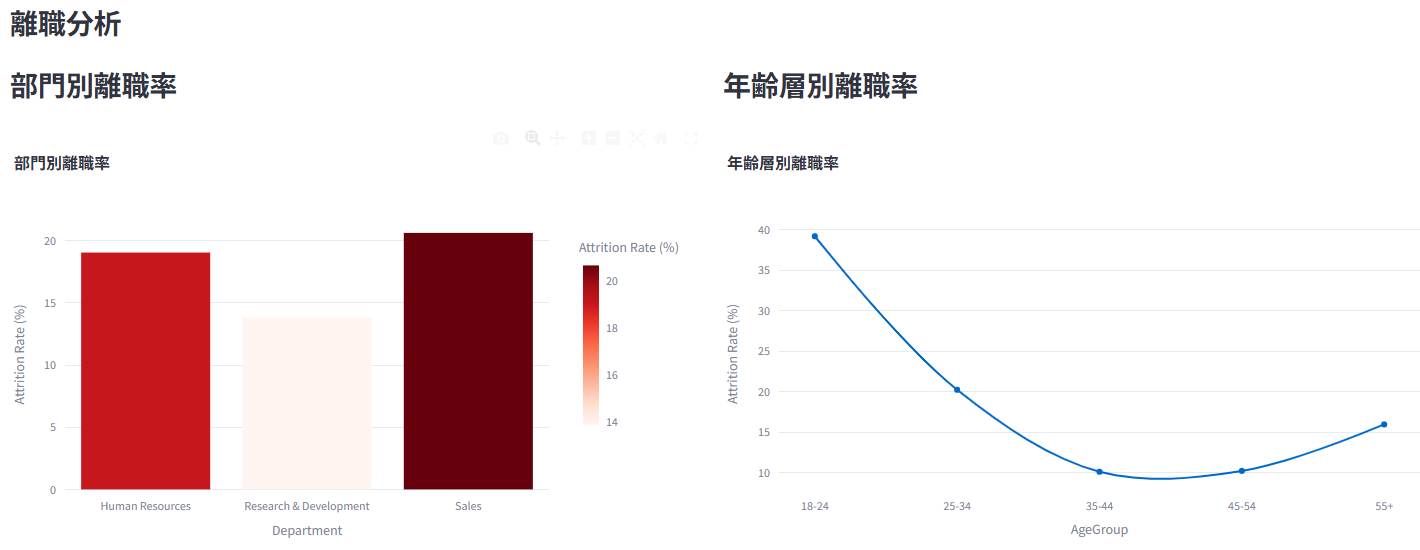
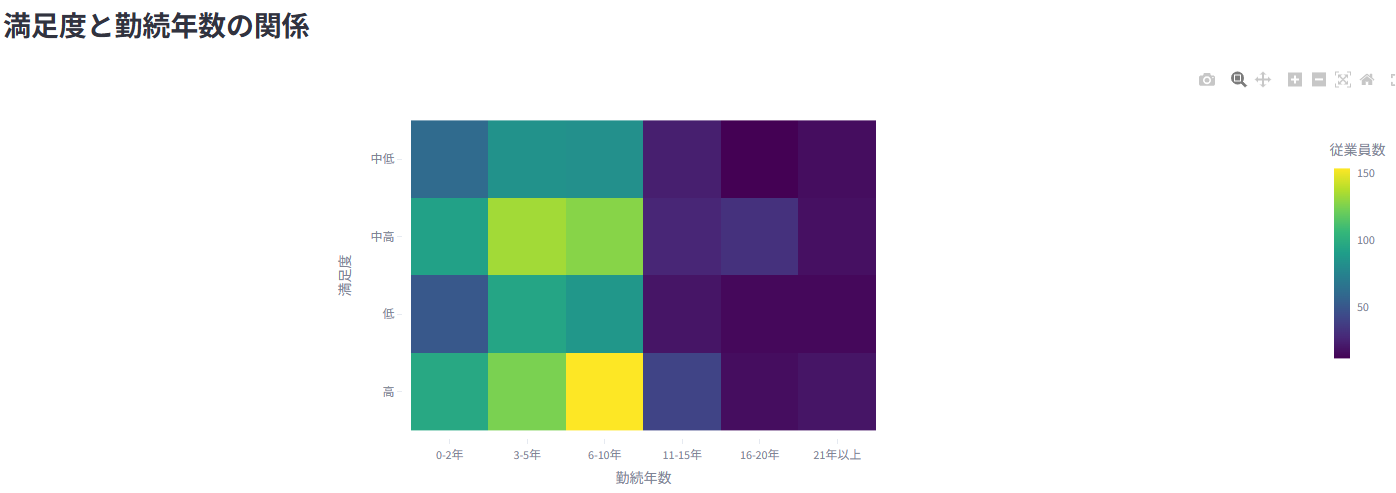
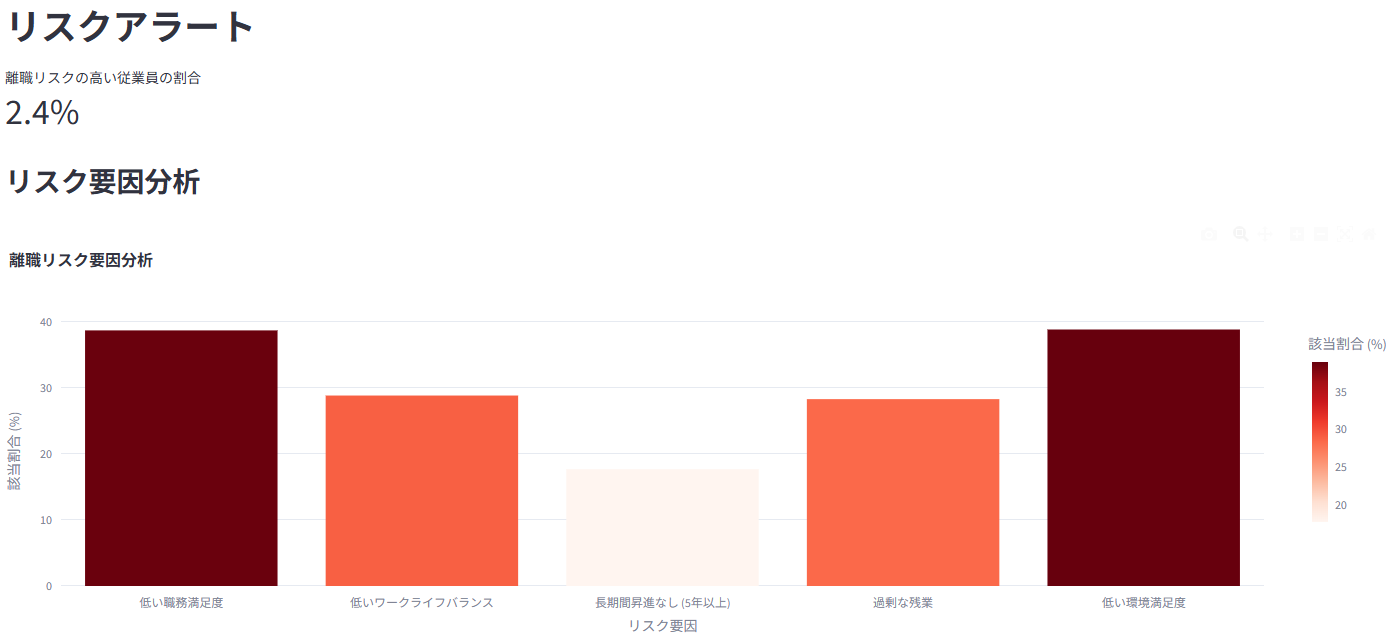
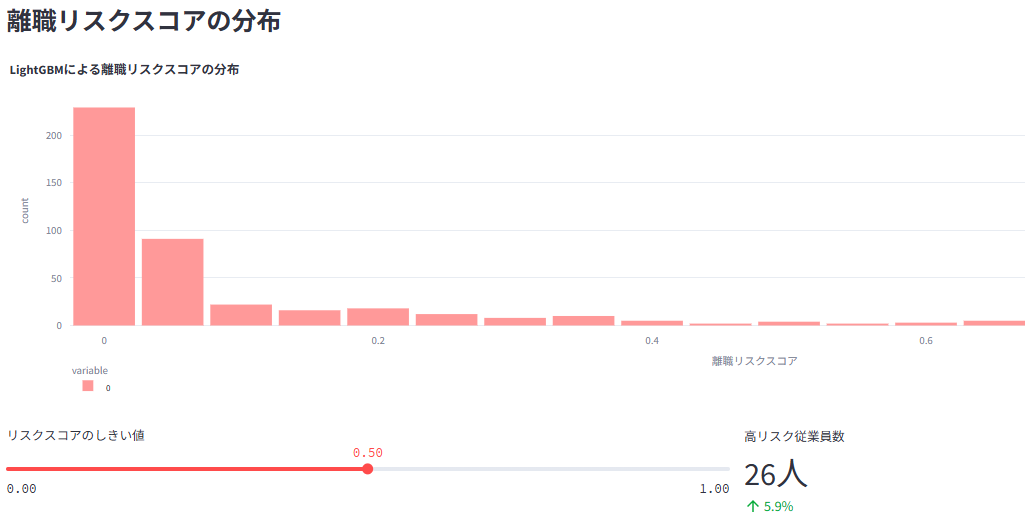
2. 🚪 離職分析
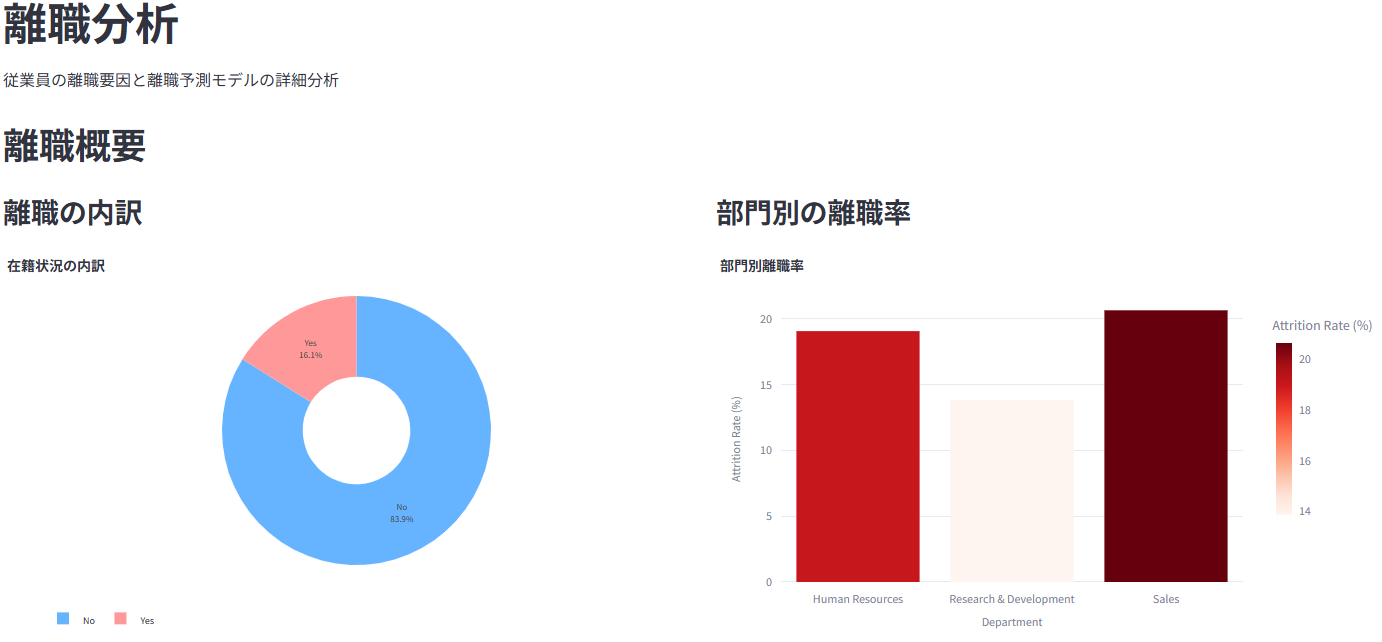
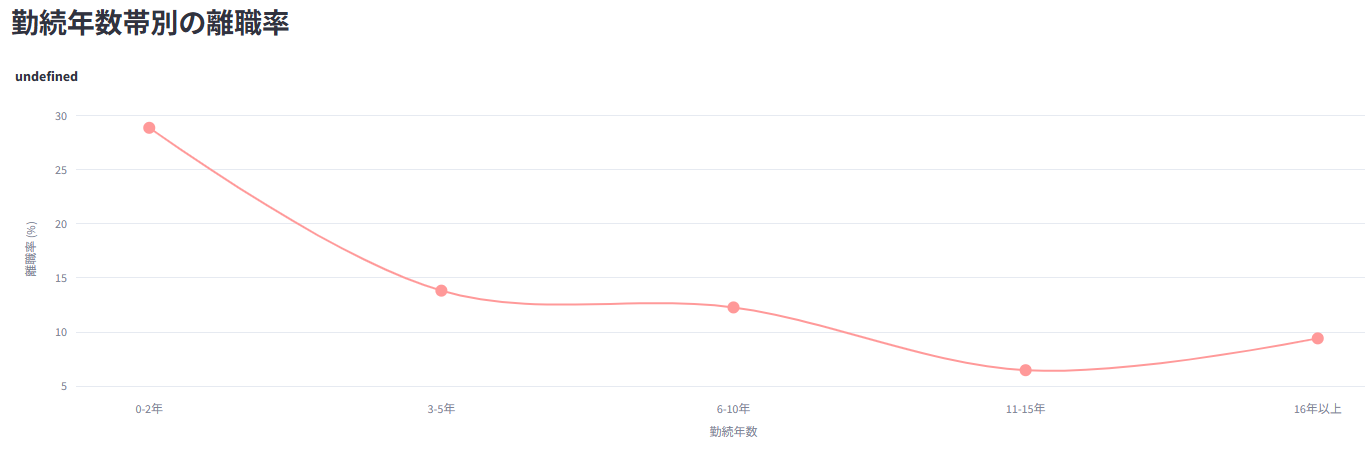
全体の離職状況、部門別・年齢層別などの離職率をグラフ表示
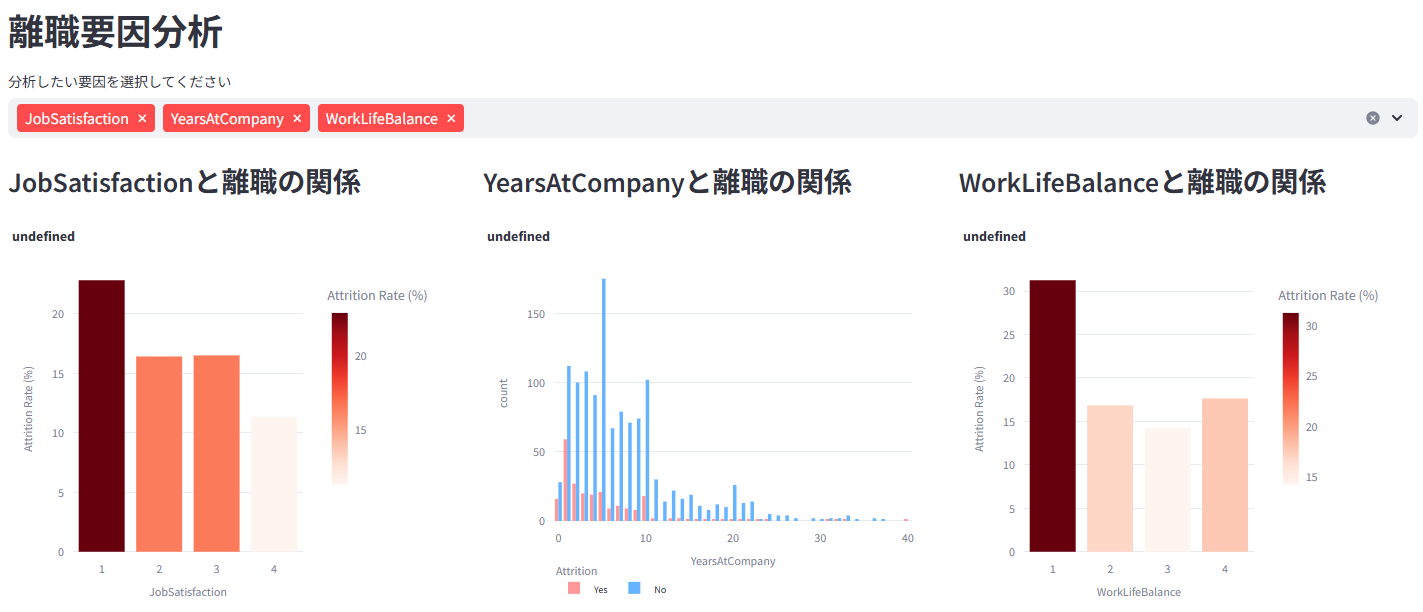
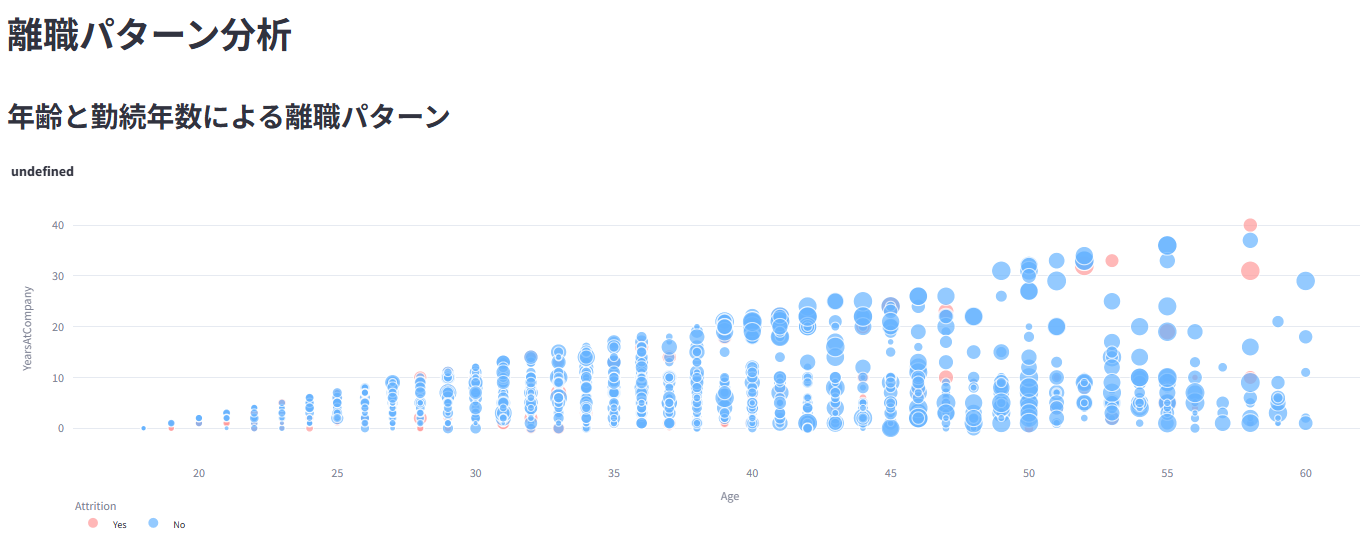
職務満足度、残業、勤続年数など、様々な要因と離職の関係性を分析して可視化
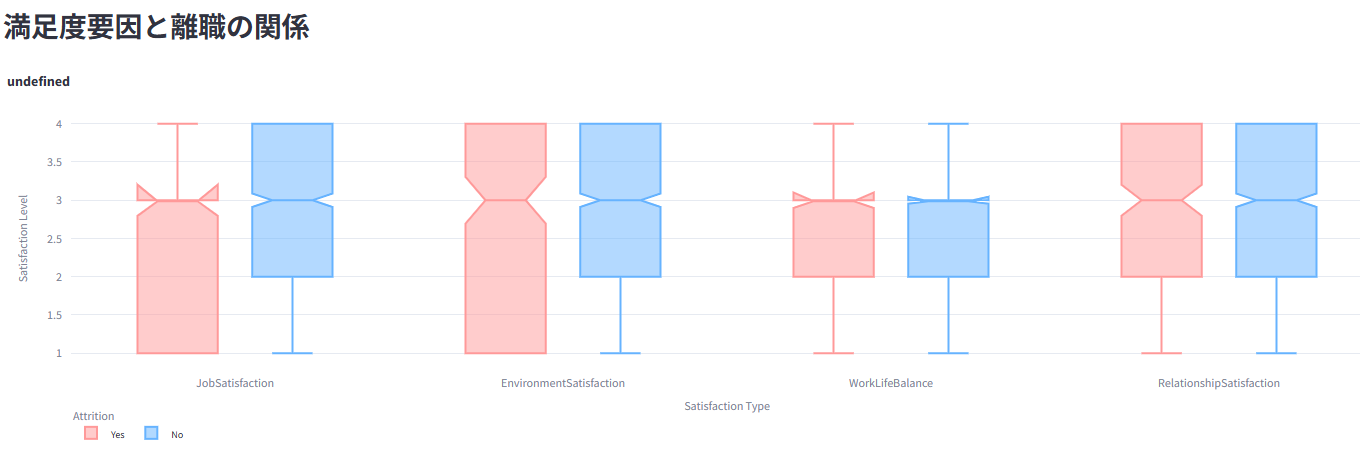
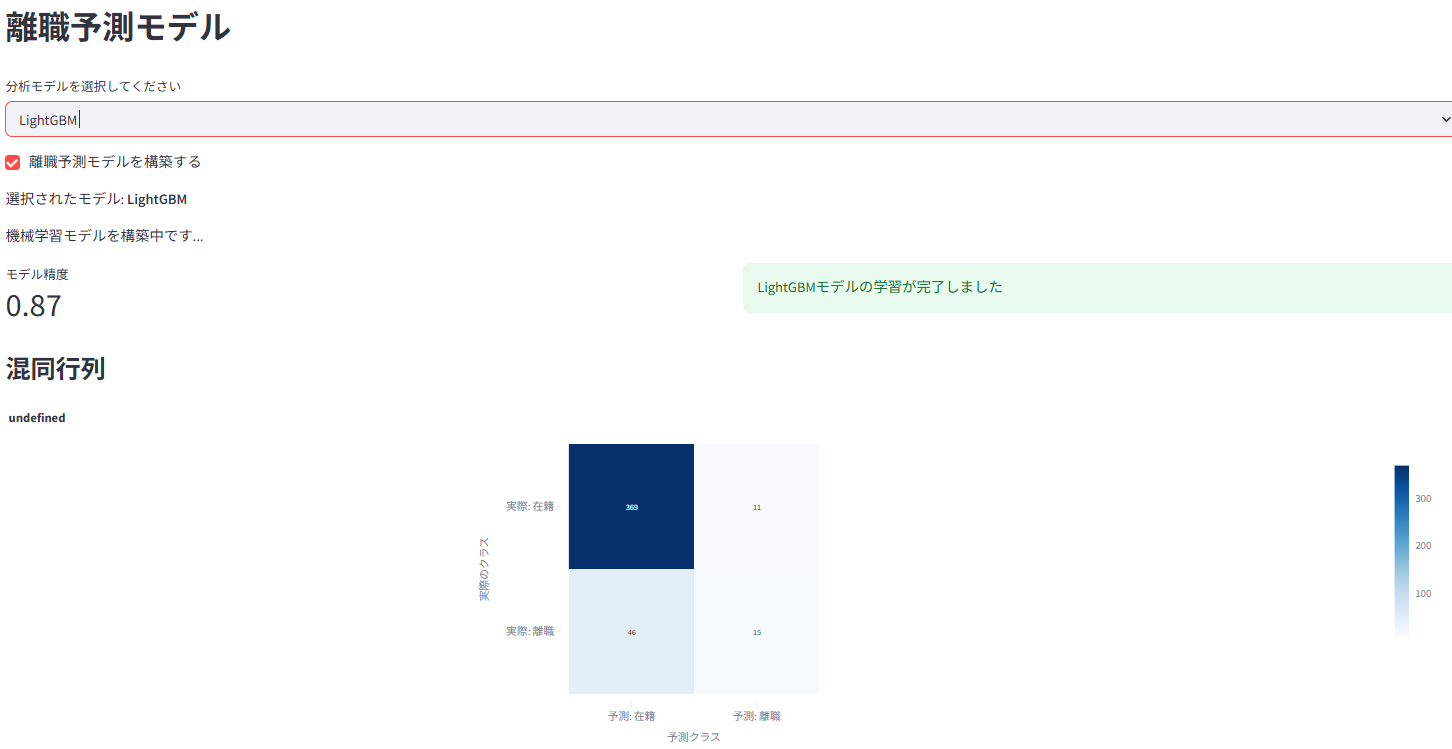
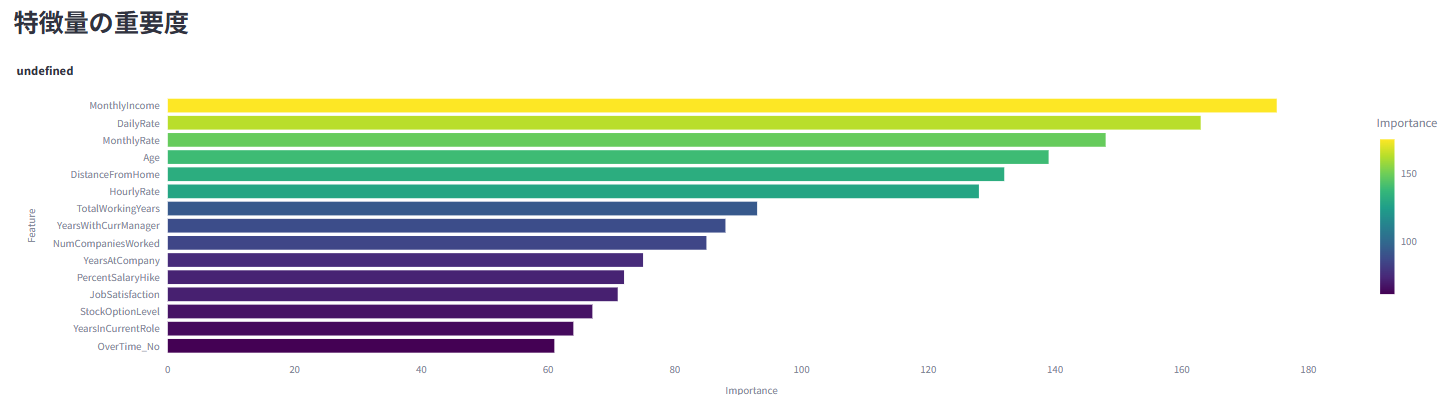
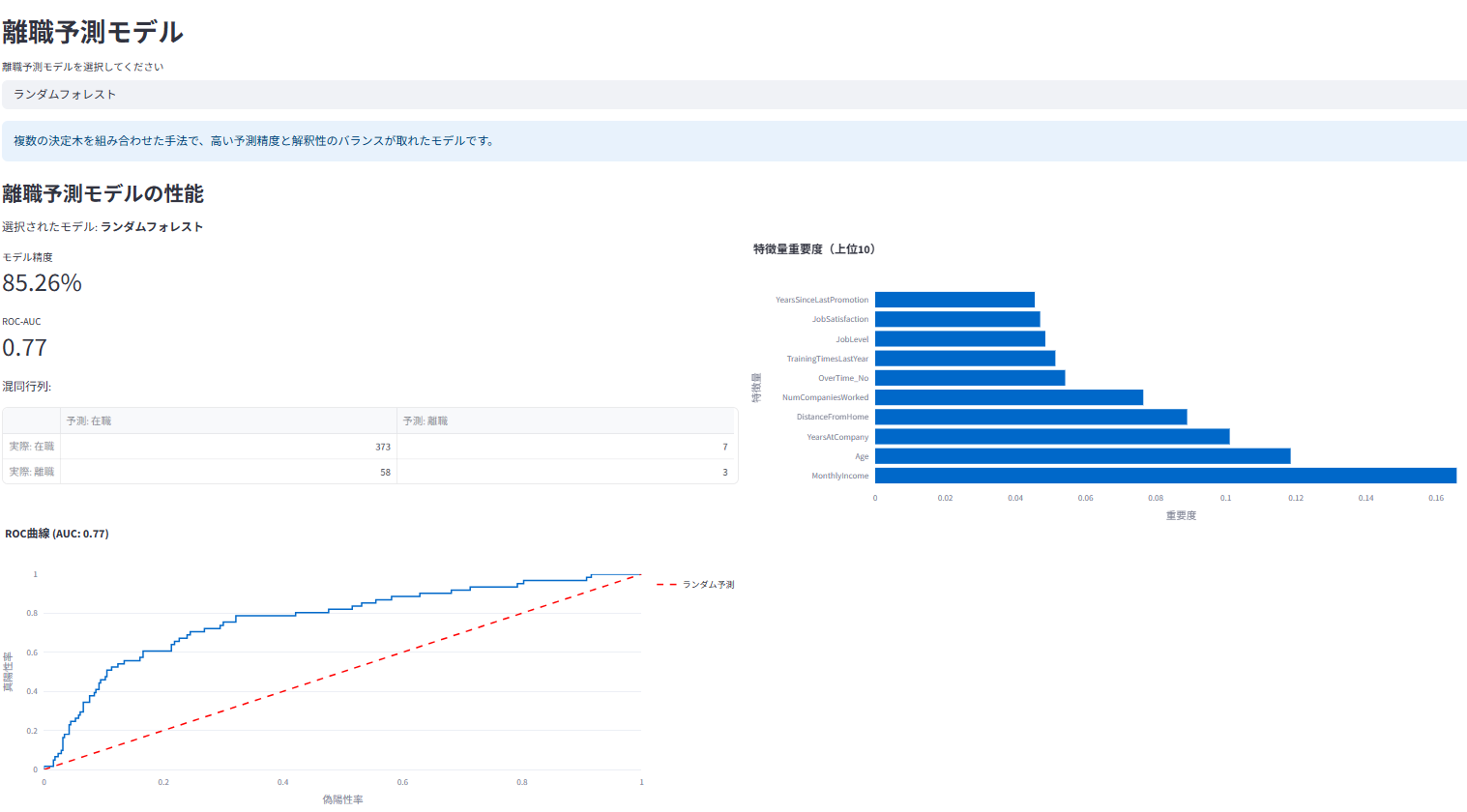
機械学習モデル(LightGBM、XGBoost、RandomForestなど5つのモデルから選択可)を用いた離職予測と、その要因の重要度を表示
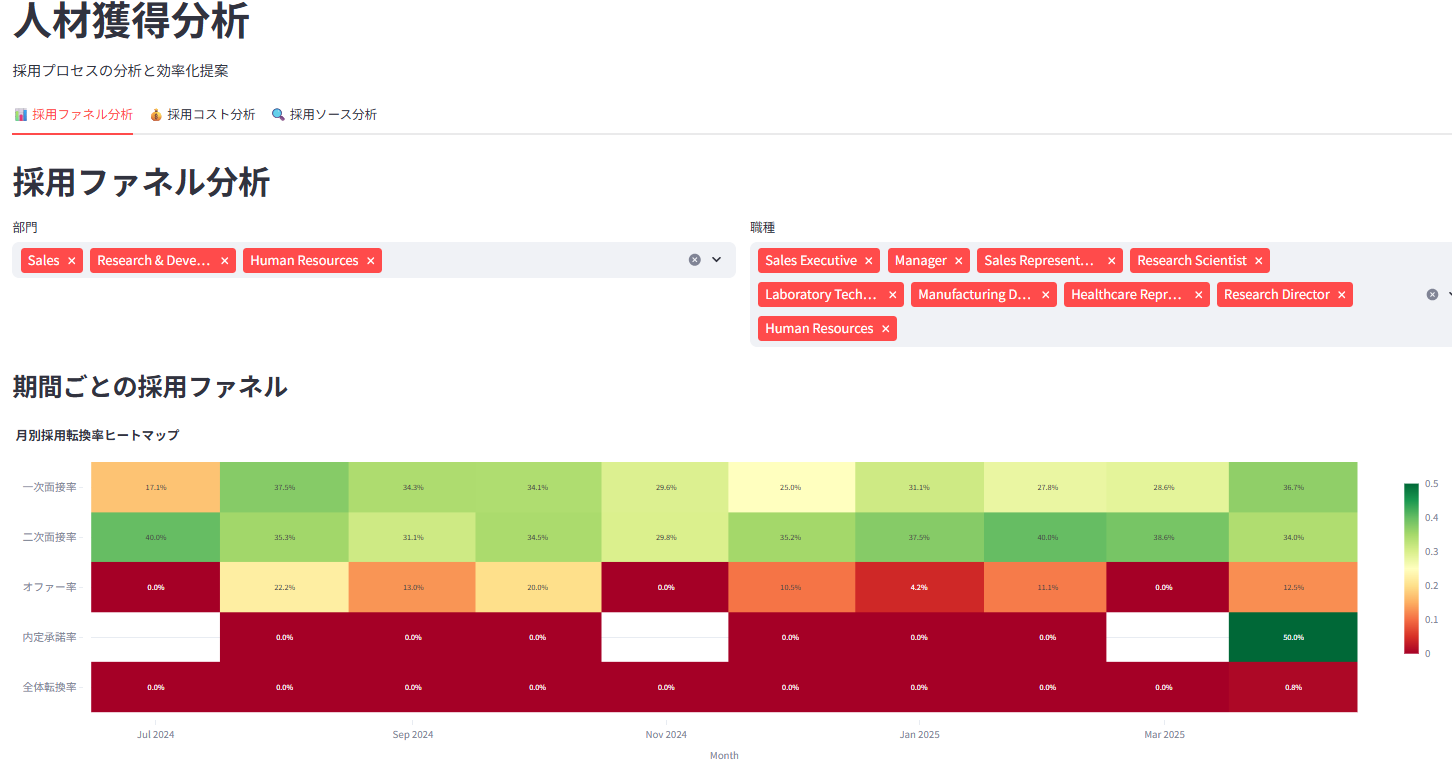
3. 🎯 人材獲得分析 (ダミーデータ)
採用ファネル(応募から内定承諾までの各段階の通過率)を可視化し、ボトルネックを特定

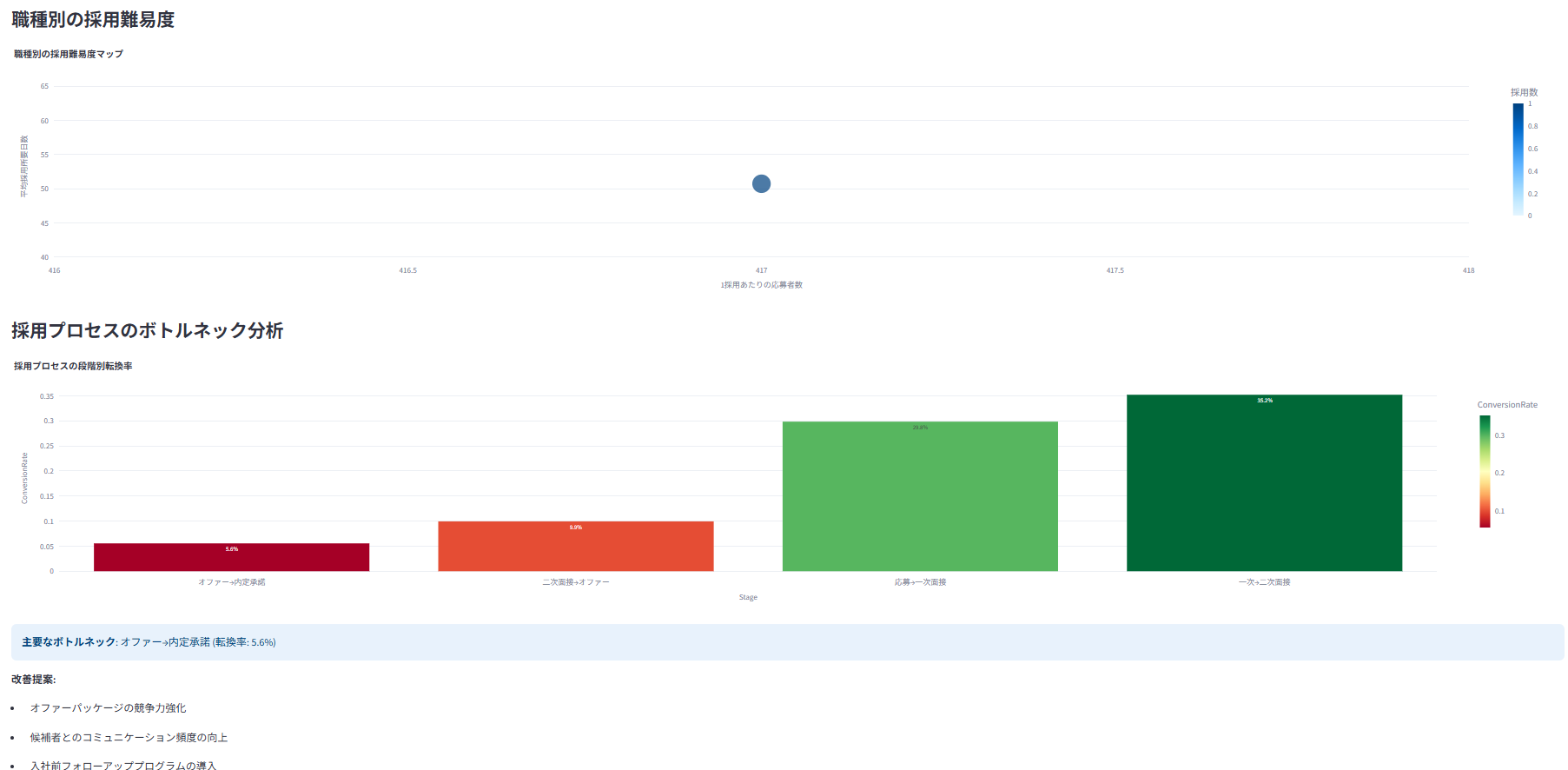
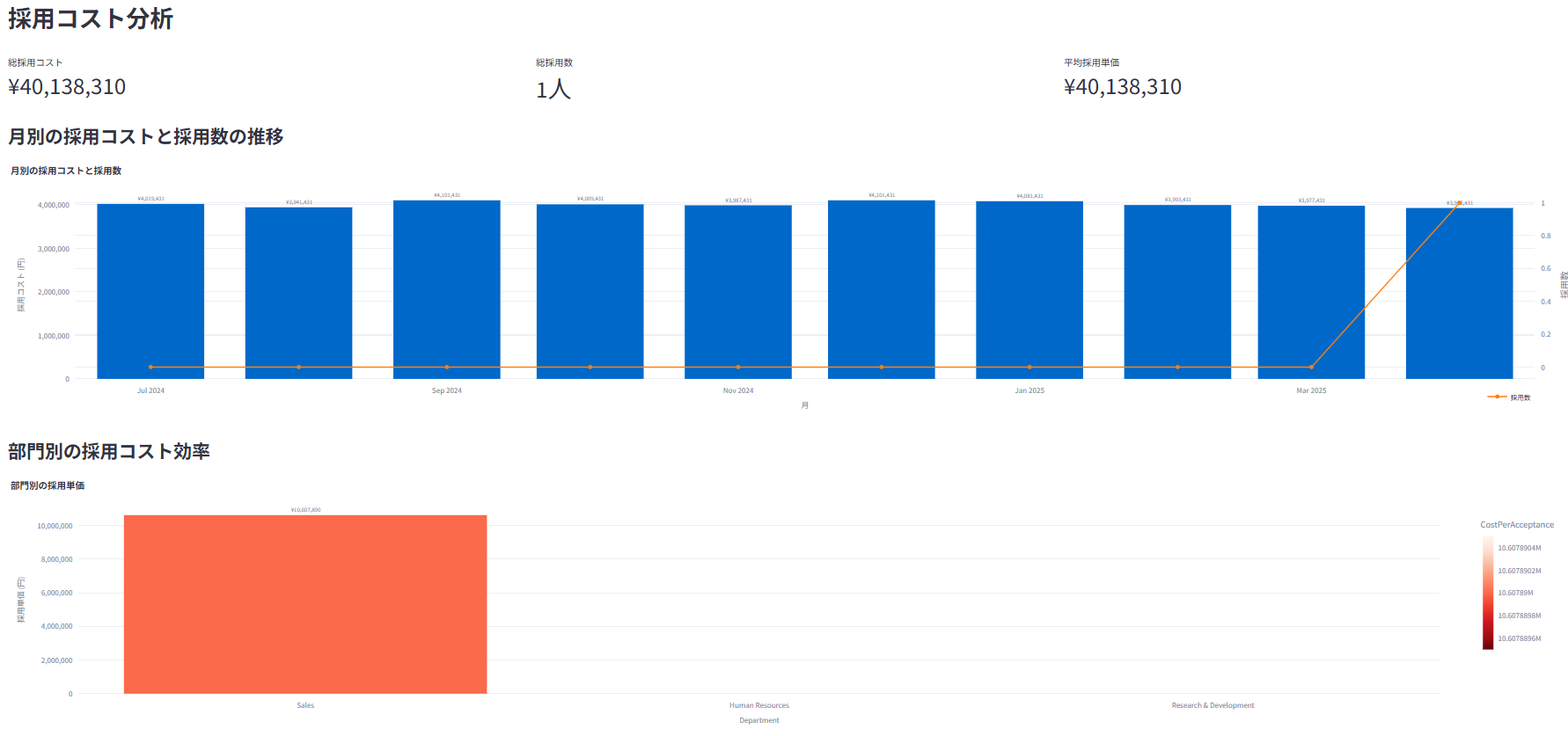
採用チャネルごとの効果(採用数、採用単価など)を分析
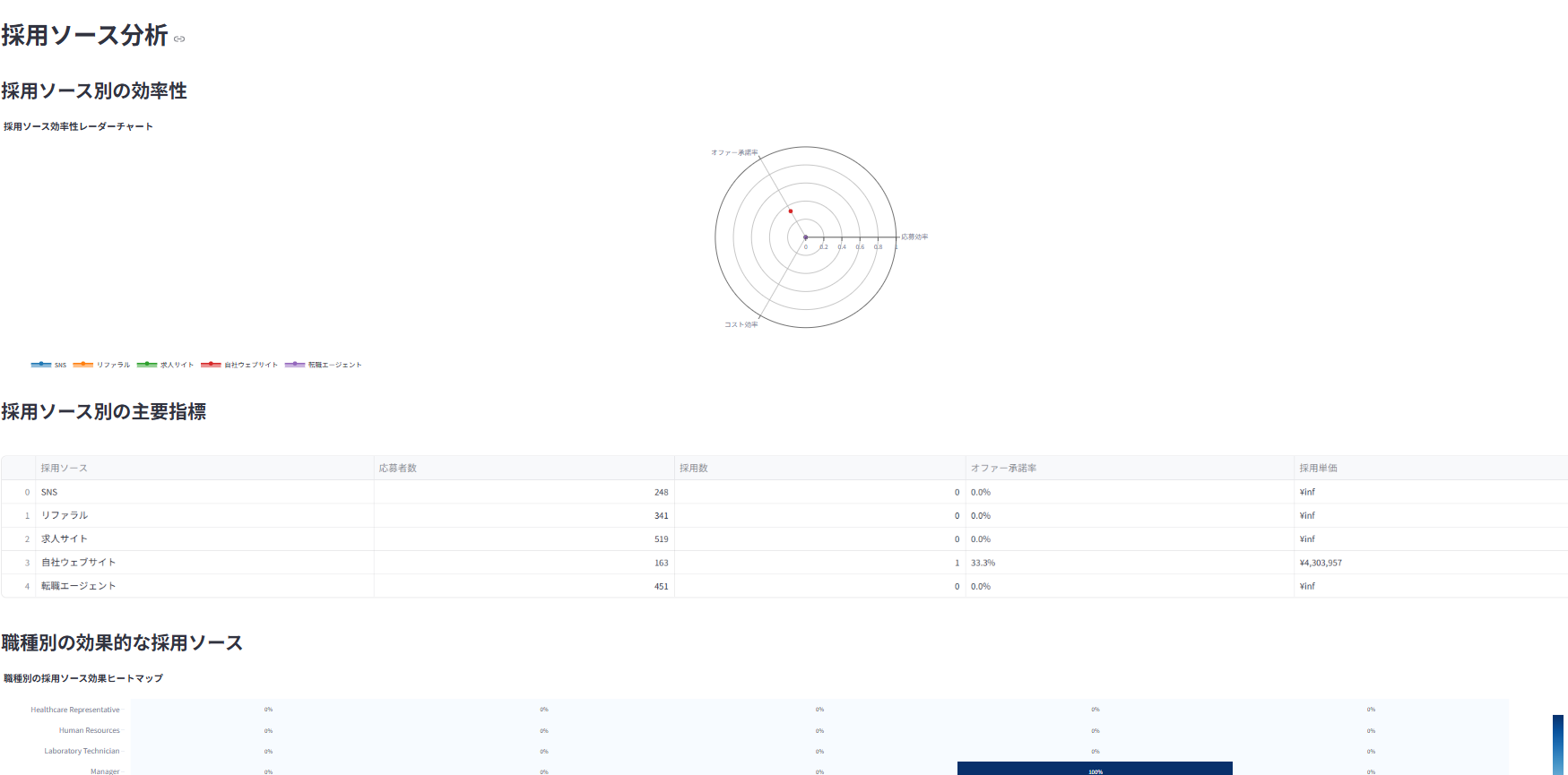
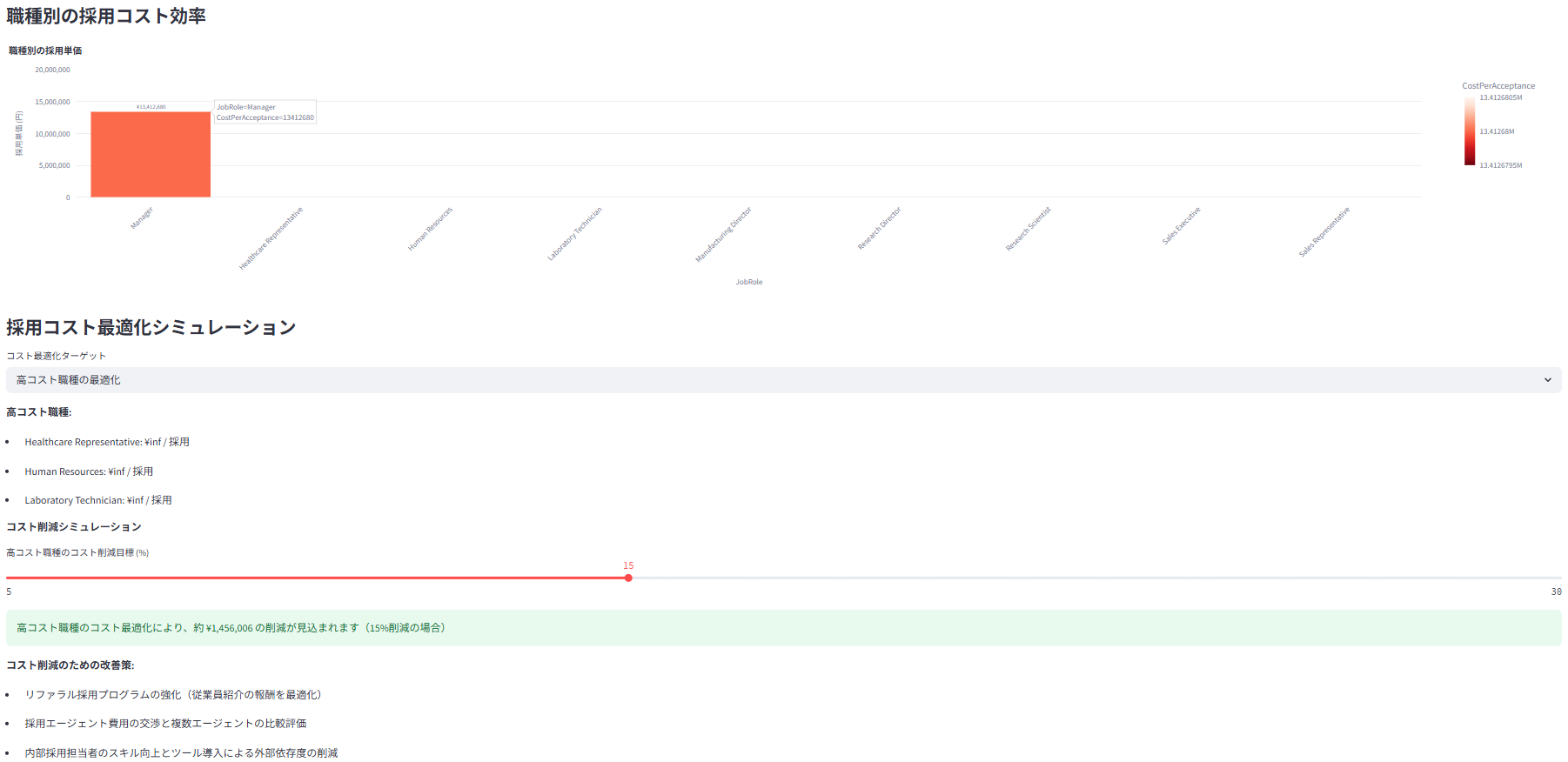
採用コストの分析と最適化シミュレーション
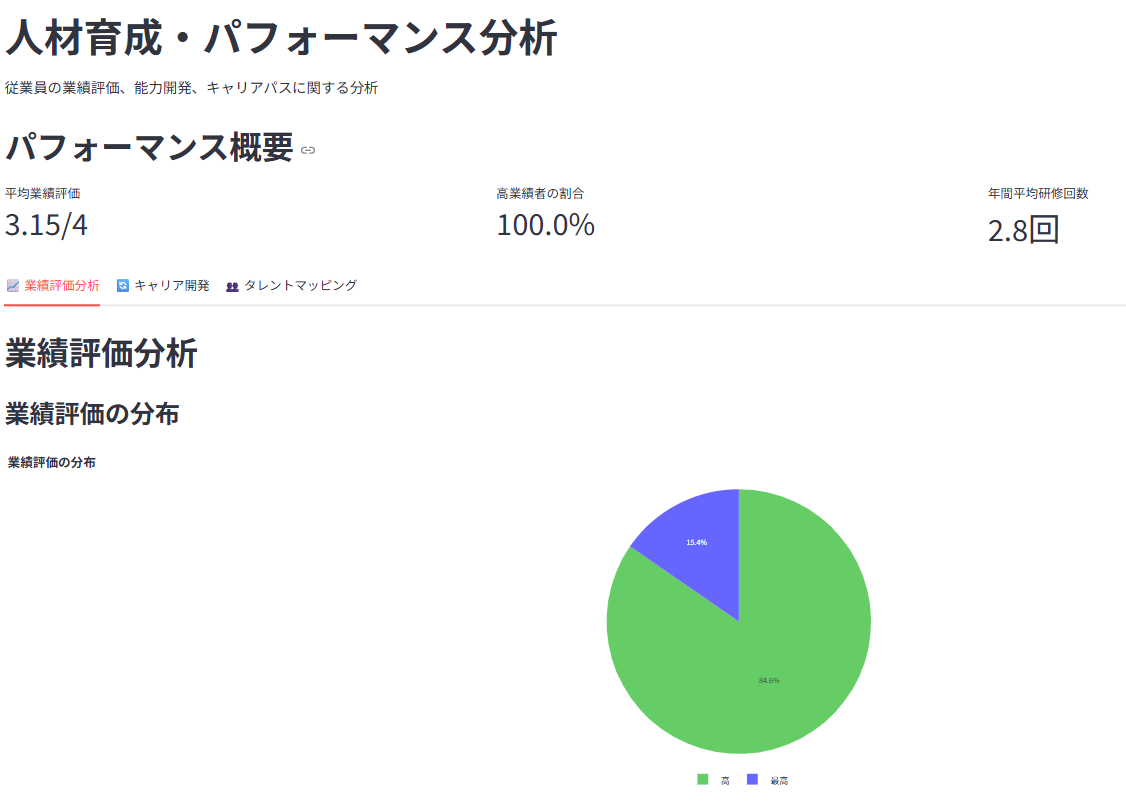
4. 📈 人材育成・パフォーマンス分析 (一部ダミーデータ)
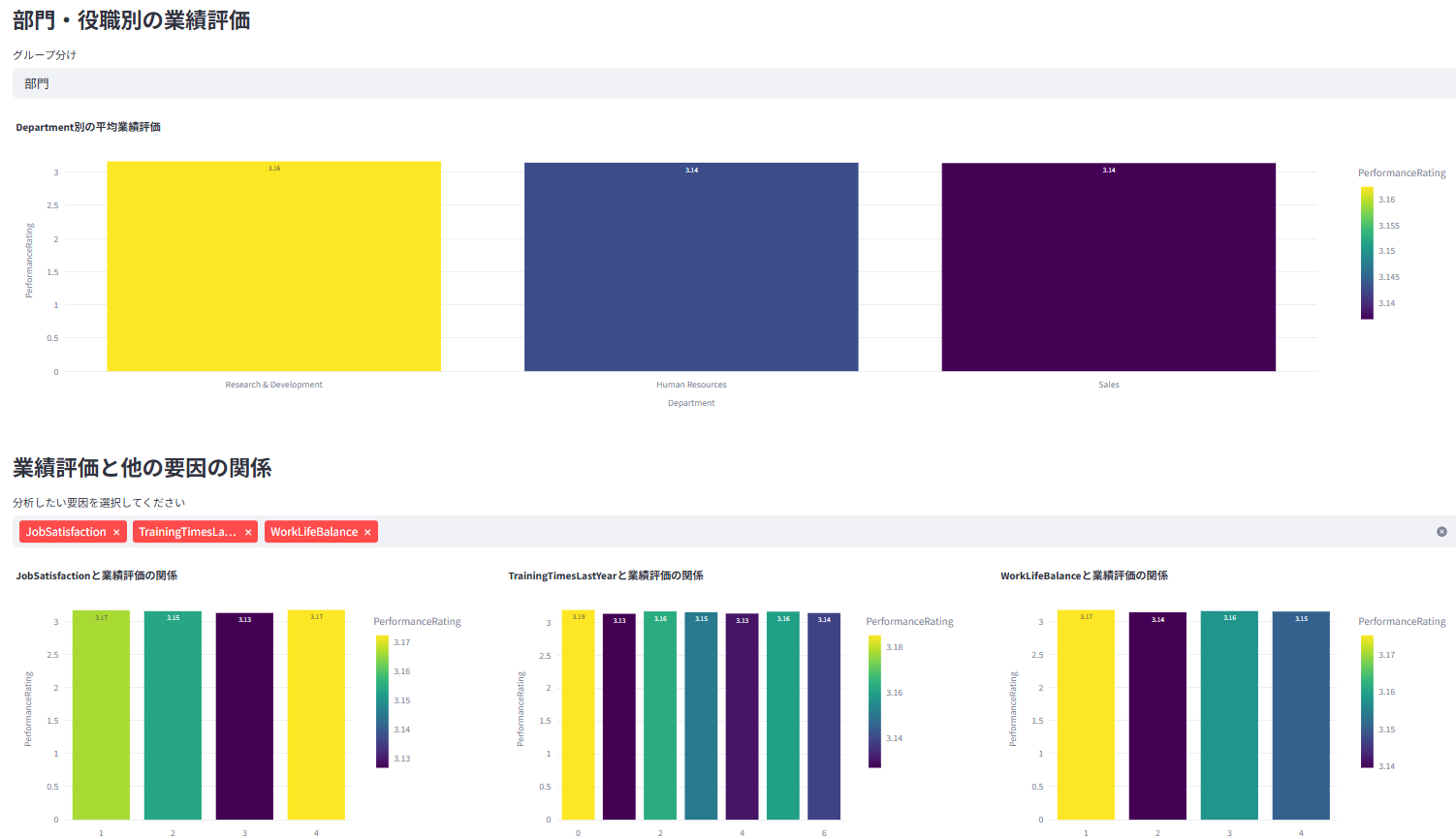
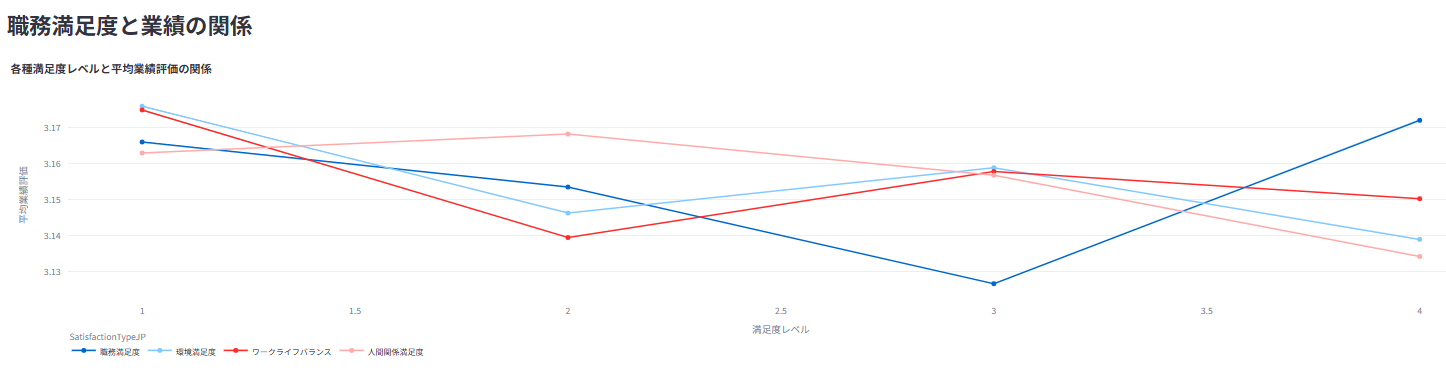
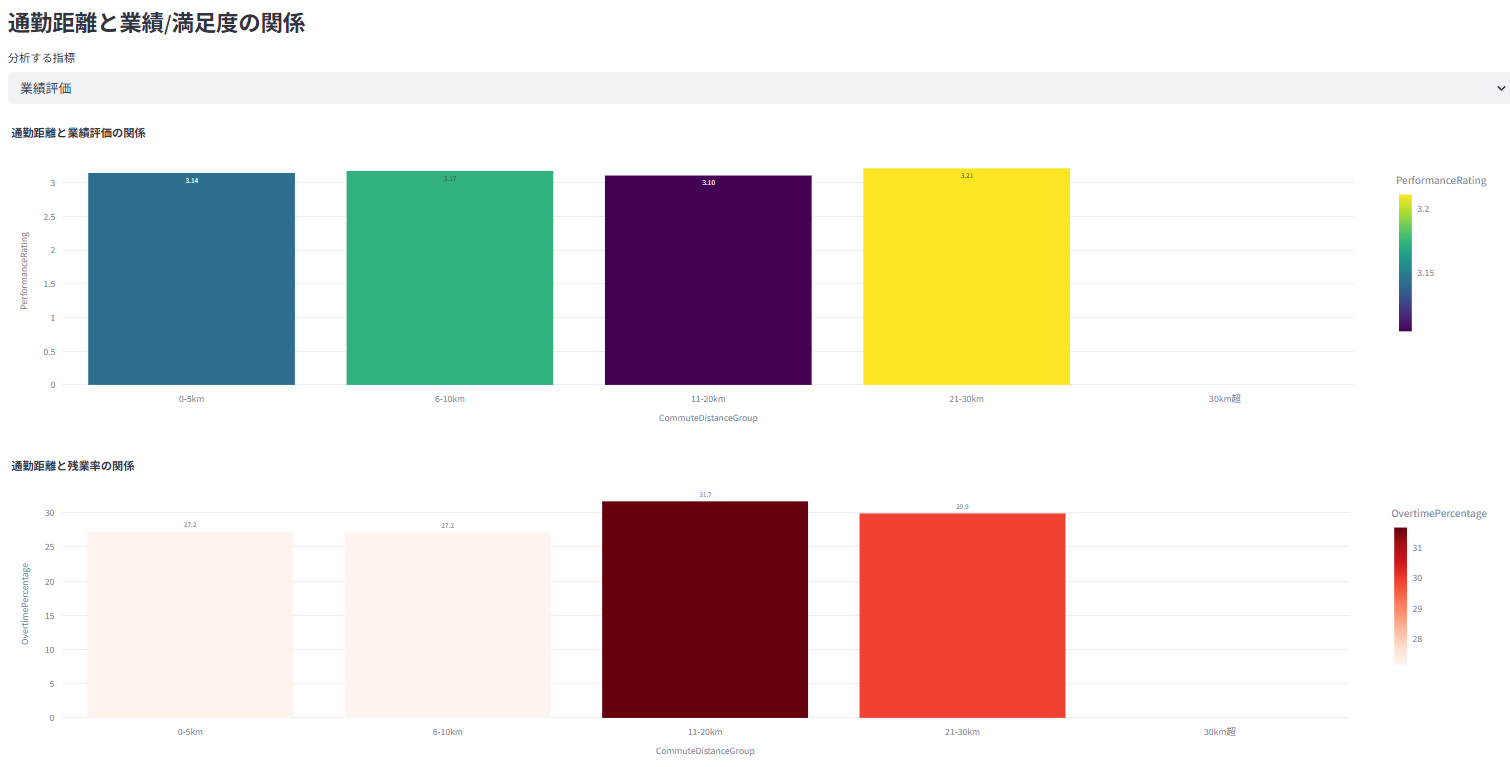
業績評価の分布や、部門・職種別の傾向を分析、また業績評価と各種要因との関係などを可視化
業績とポテンシャル(ダミー生成)による9boxタレントマップを作成し、人材ポートフォリオを把握

K-meansクラスタリングによるタレントセグメンテーション
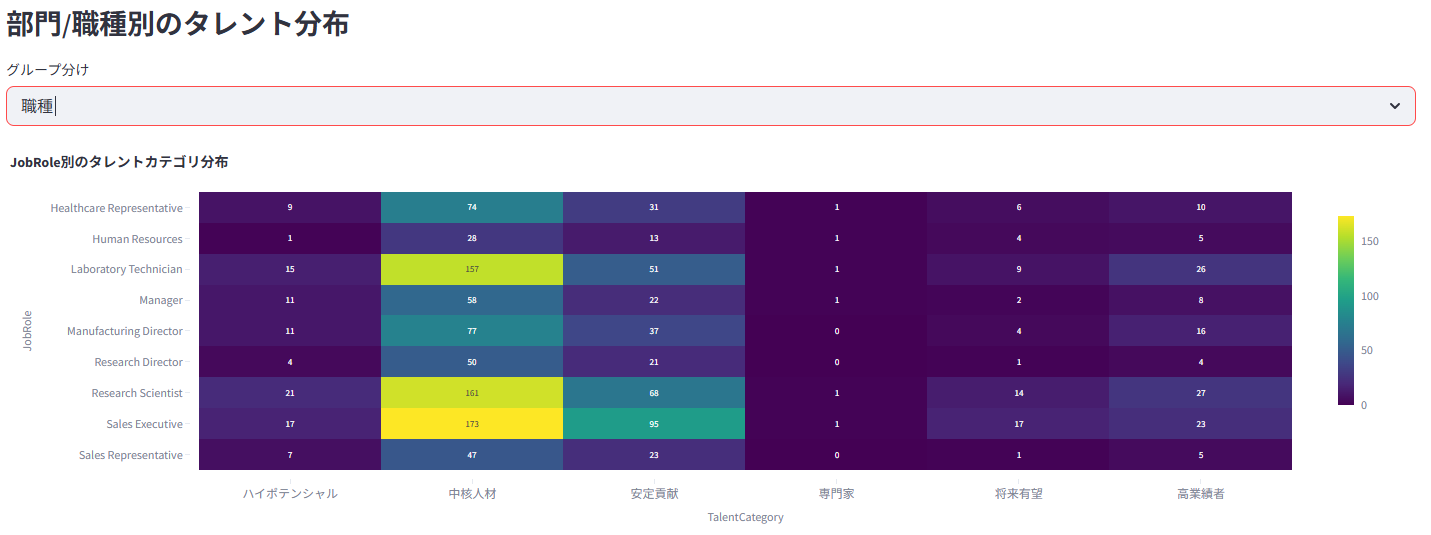
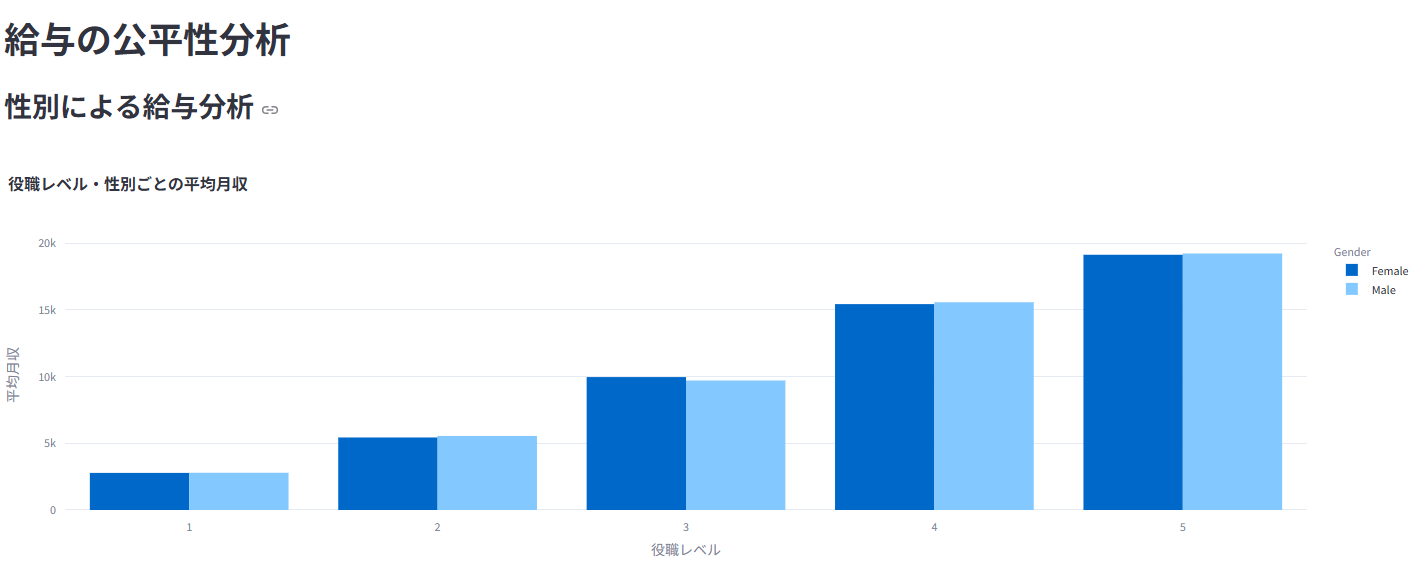
5. 💰 給与・報酬分析
月収の分布や、職種・等級別の給与水準を箱ひげ図などで比較
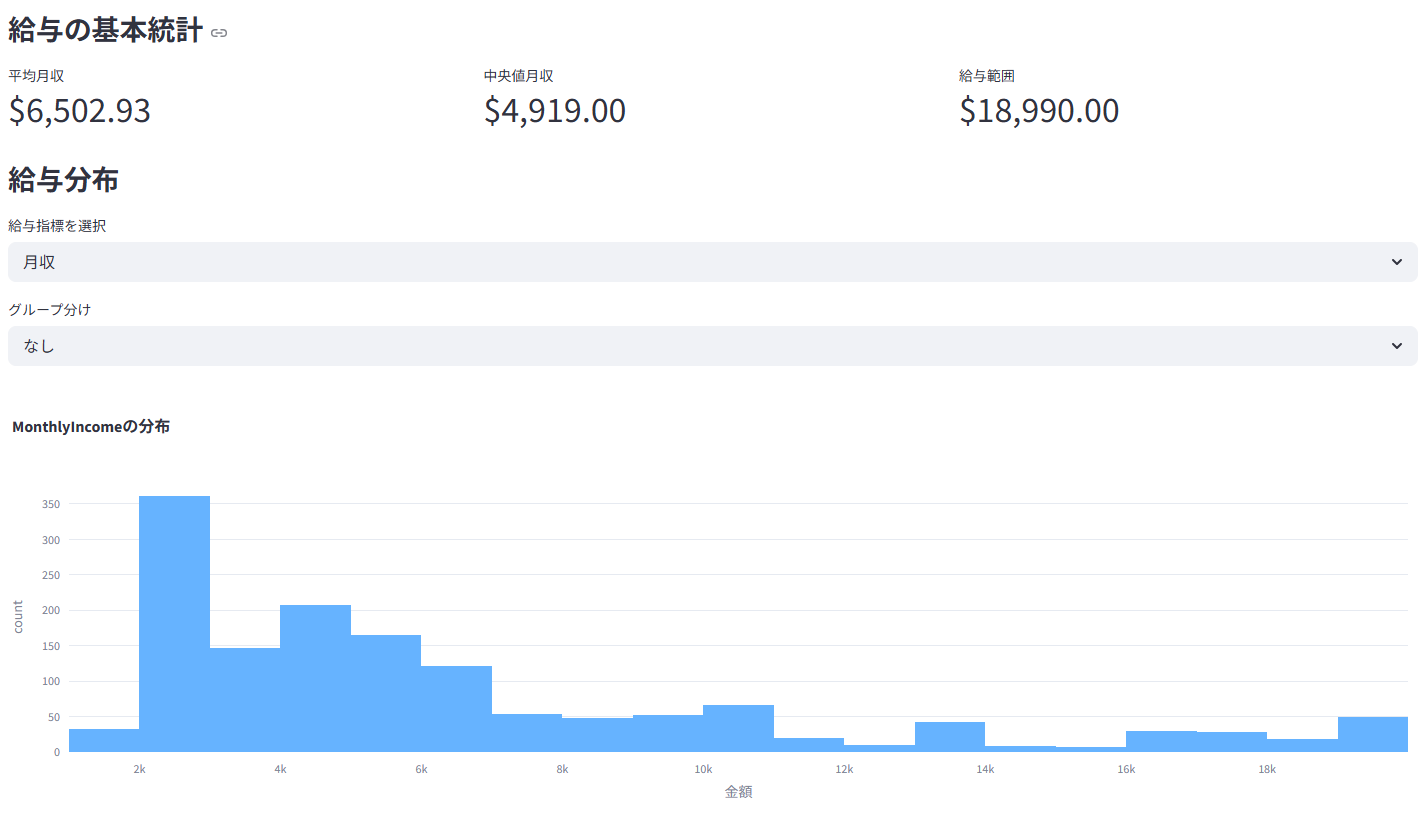
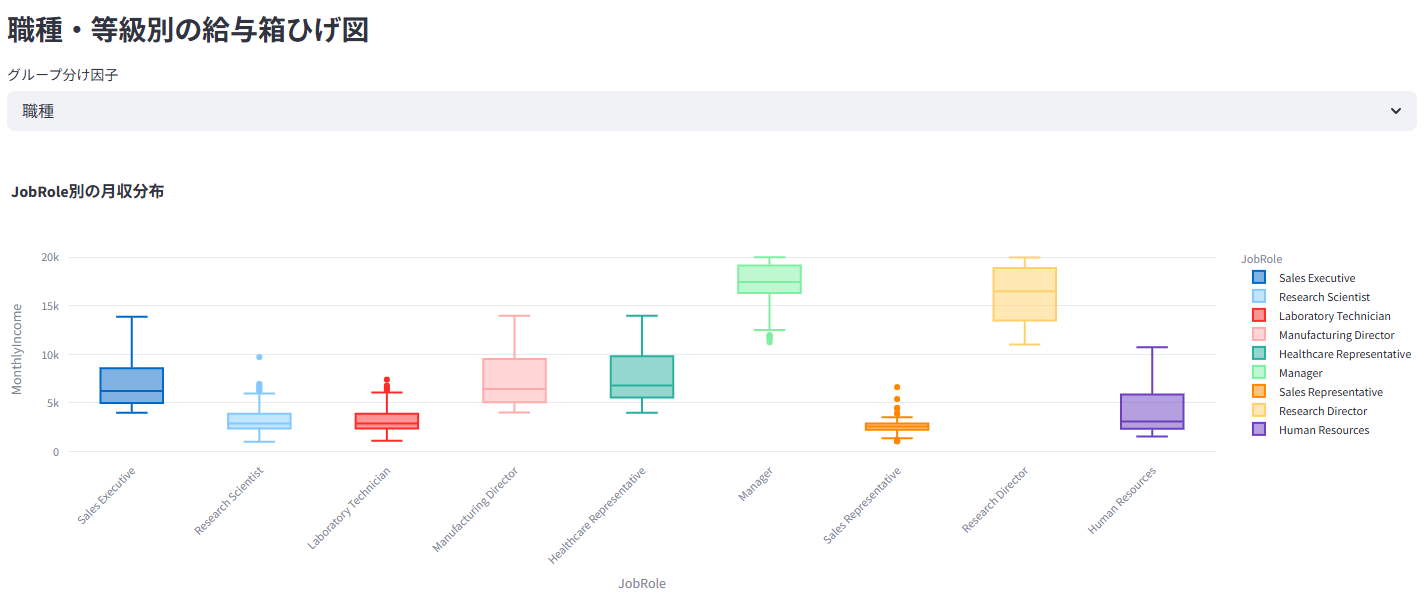
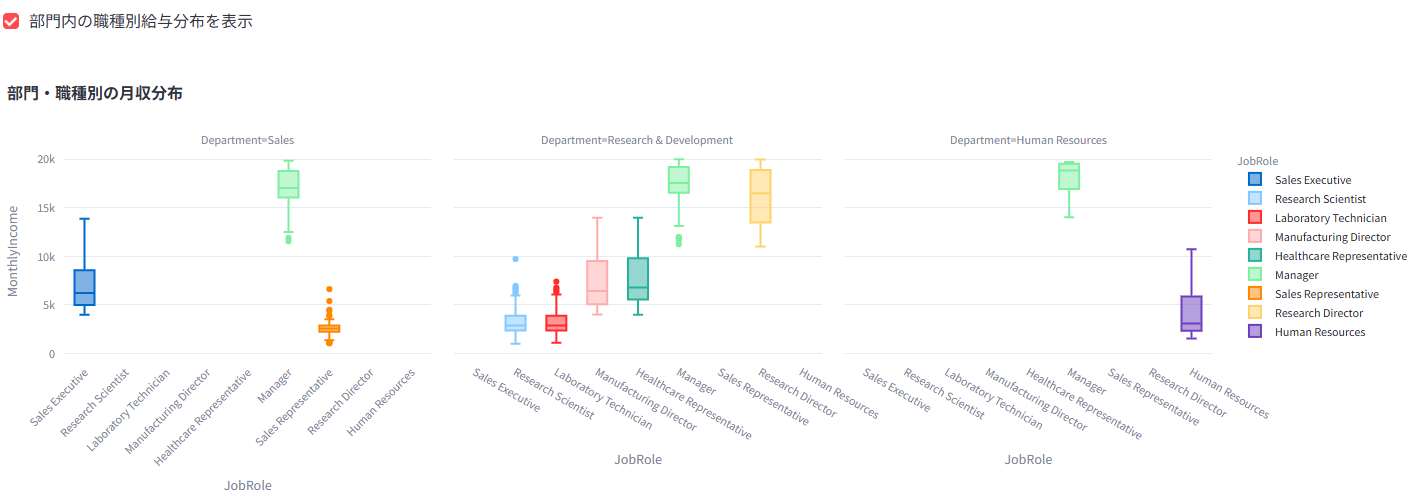
業績評価や勤続年数と給与の関係性などを分析
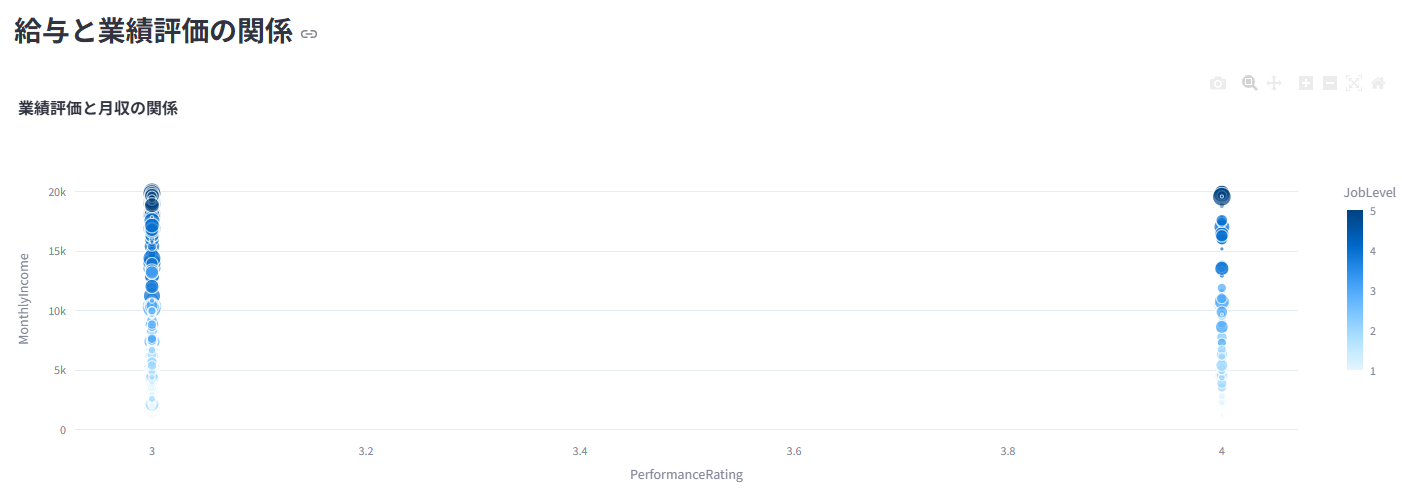
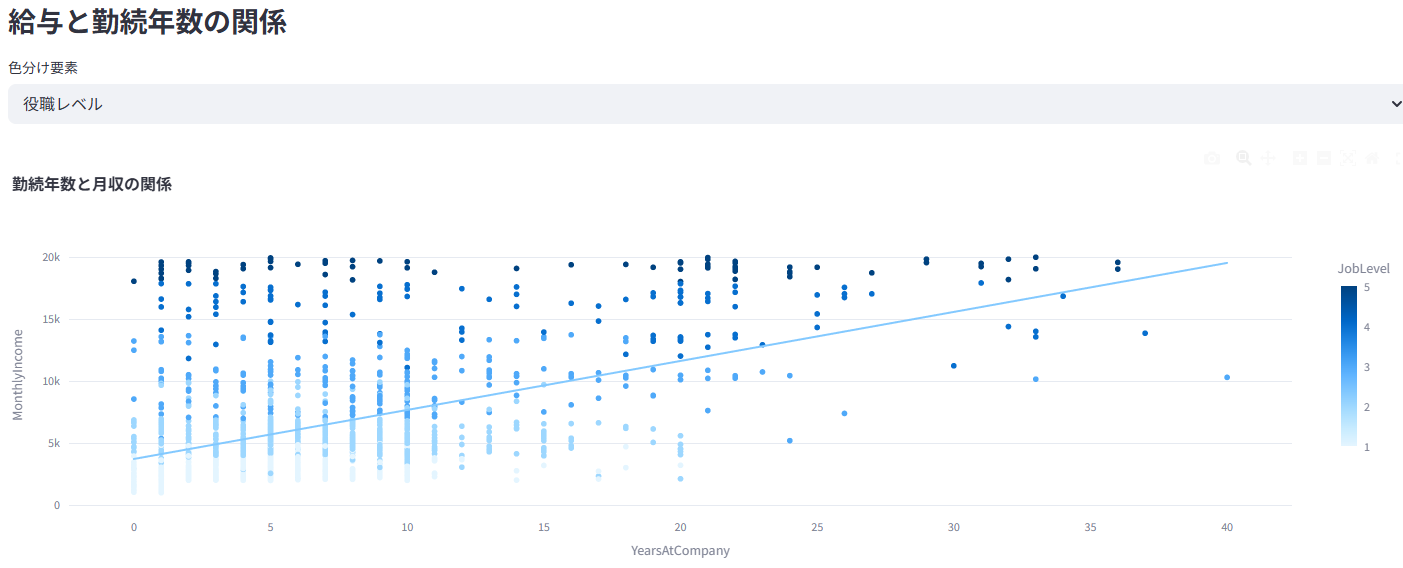
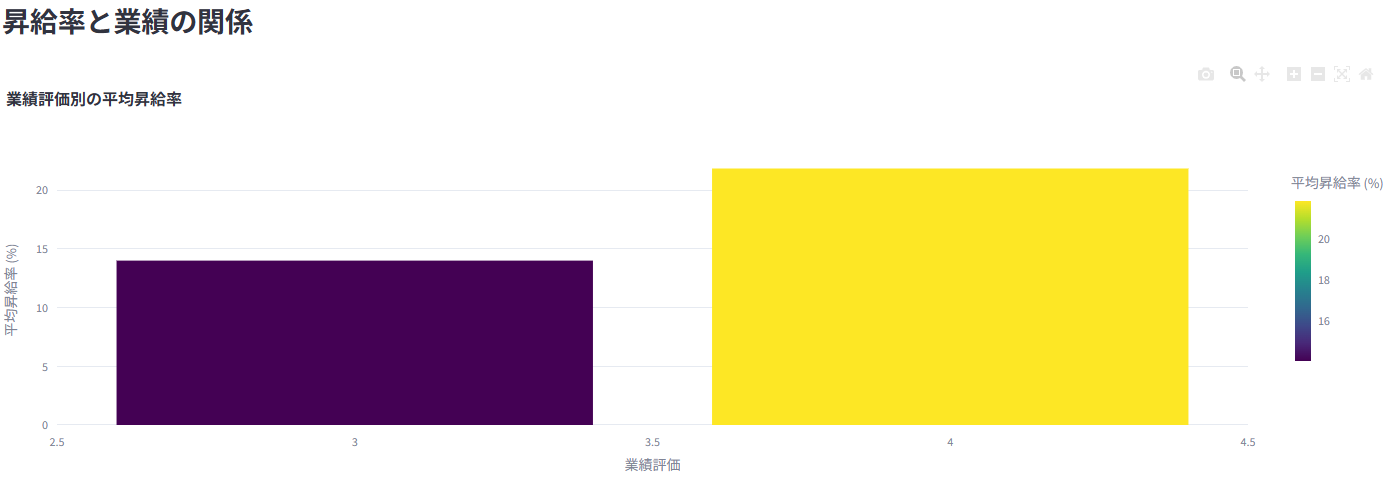
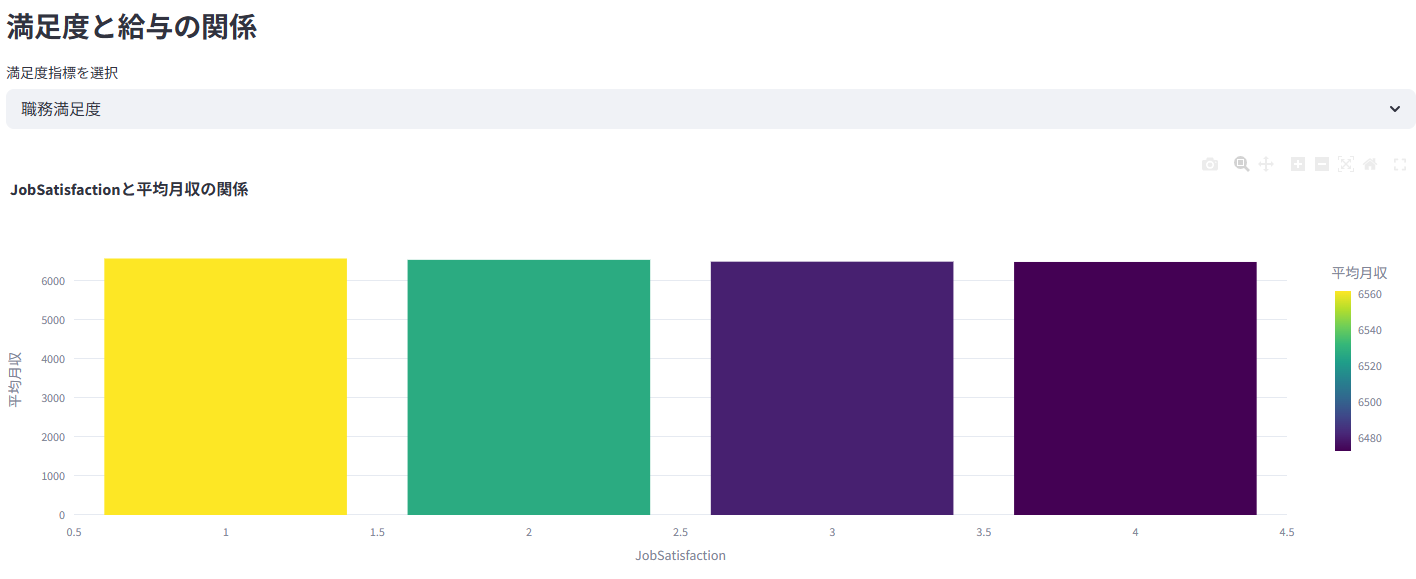
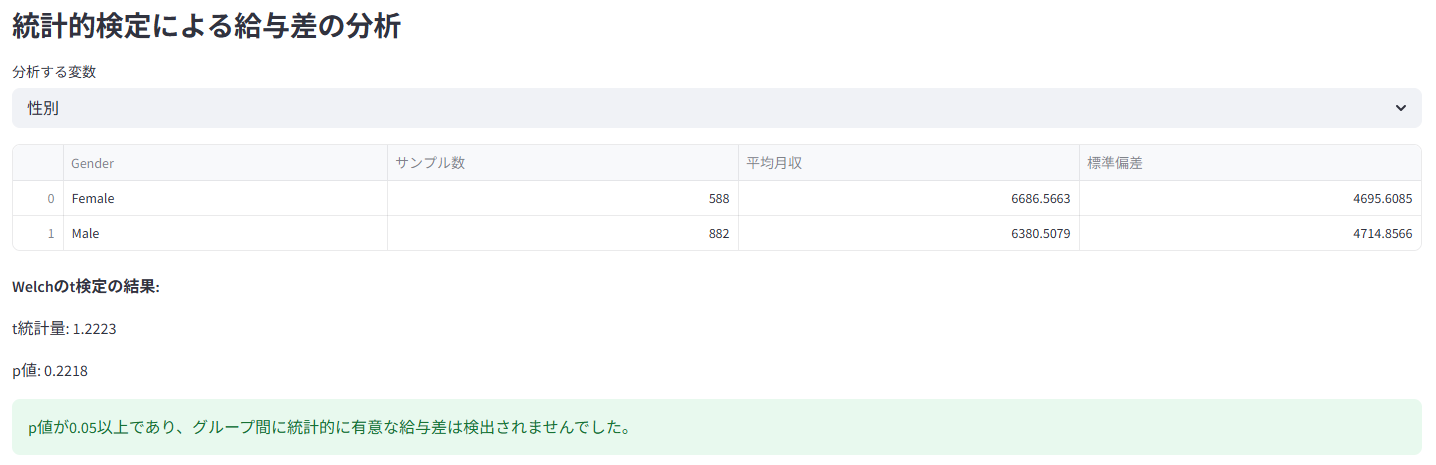
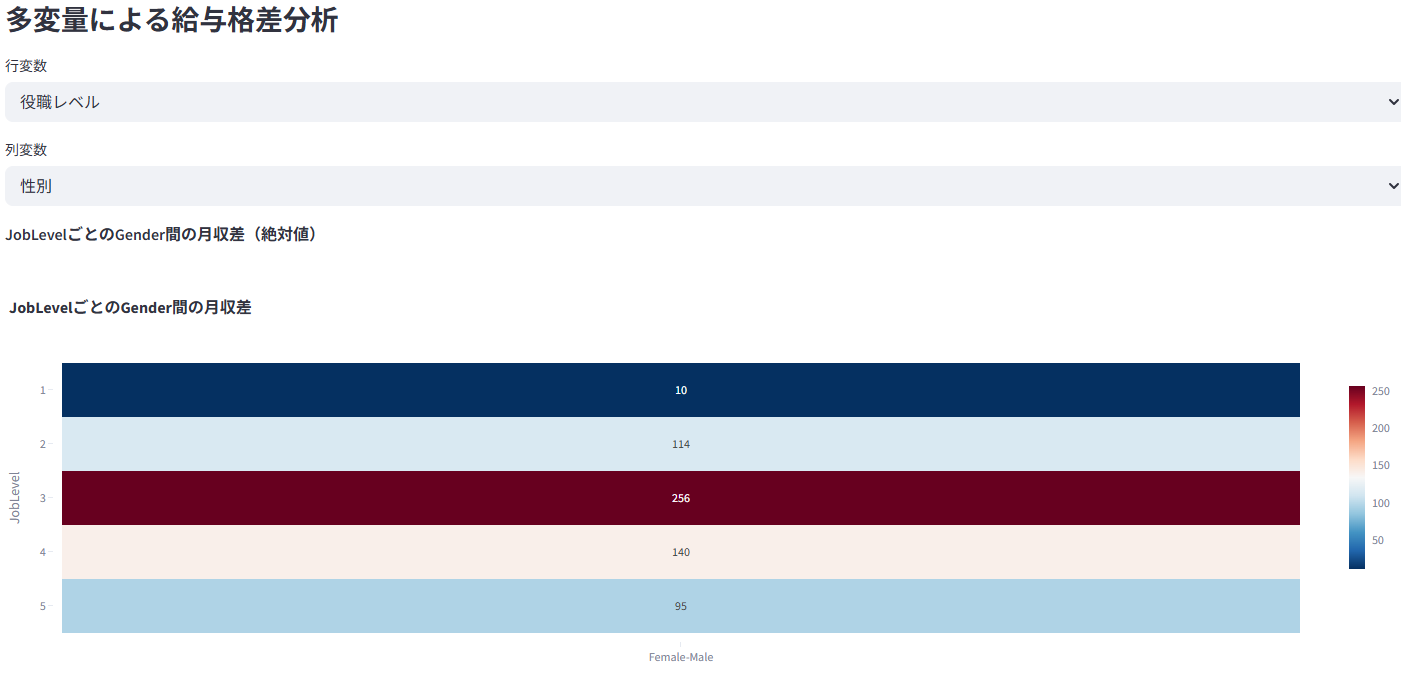
性別や部門間での給与差を統計的に(t検定/ANOVA)検証し、公平性を評価
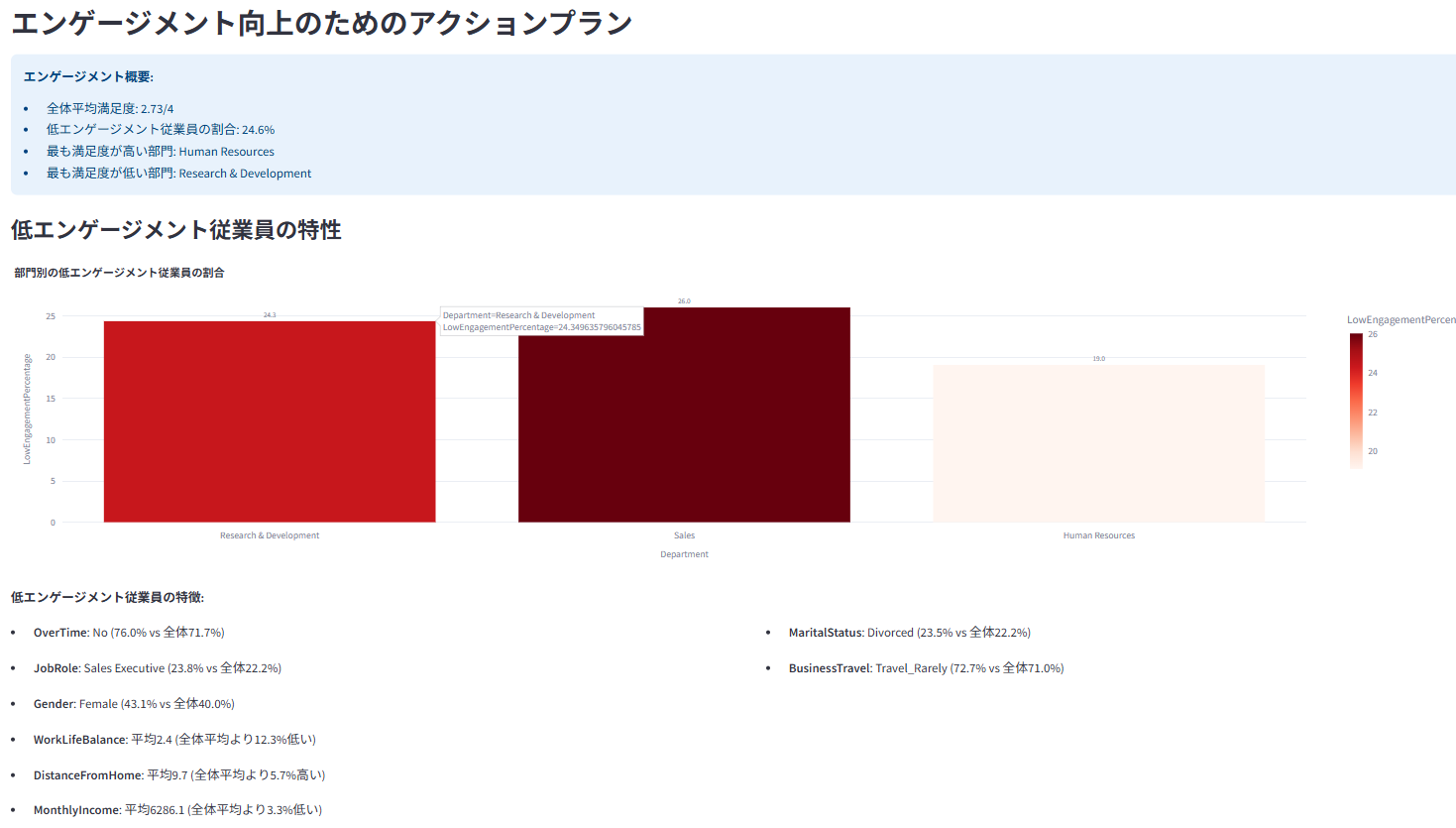
6. 🌟 従業員エンゲージメント
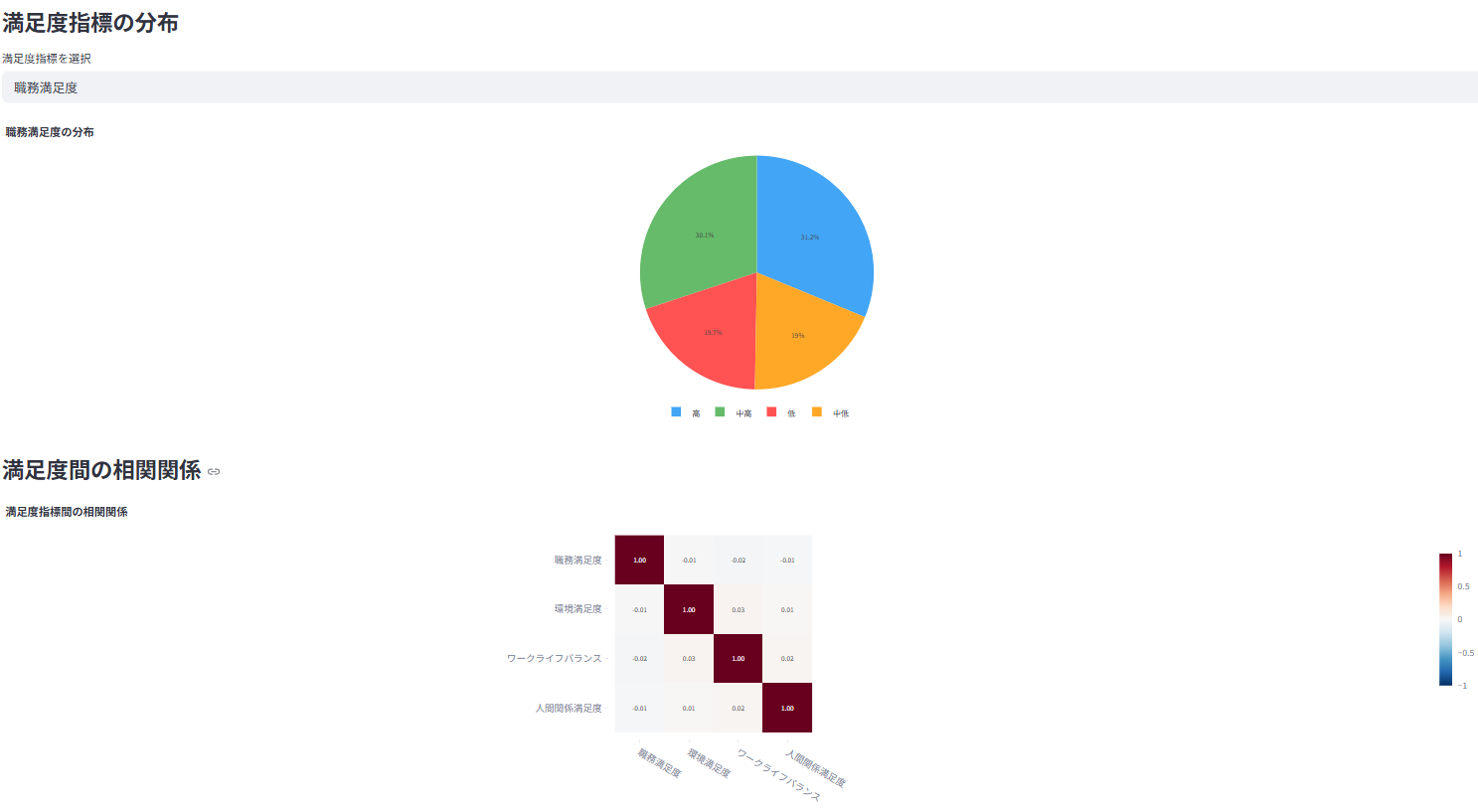
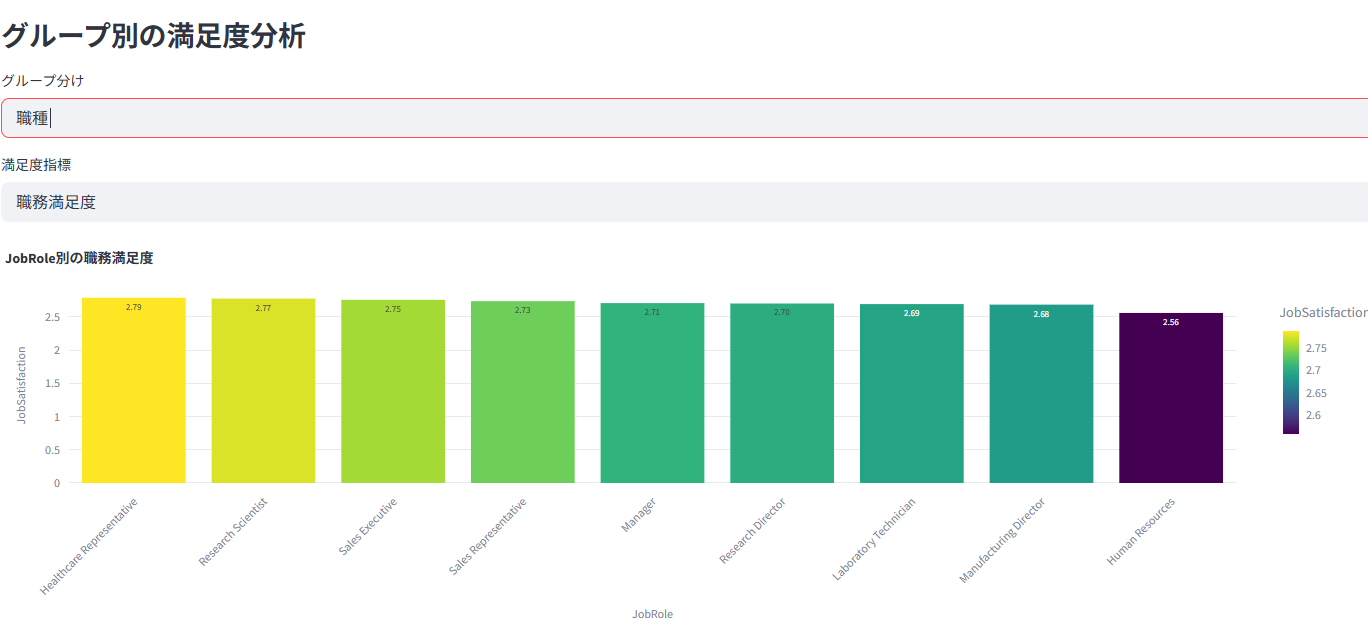
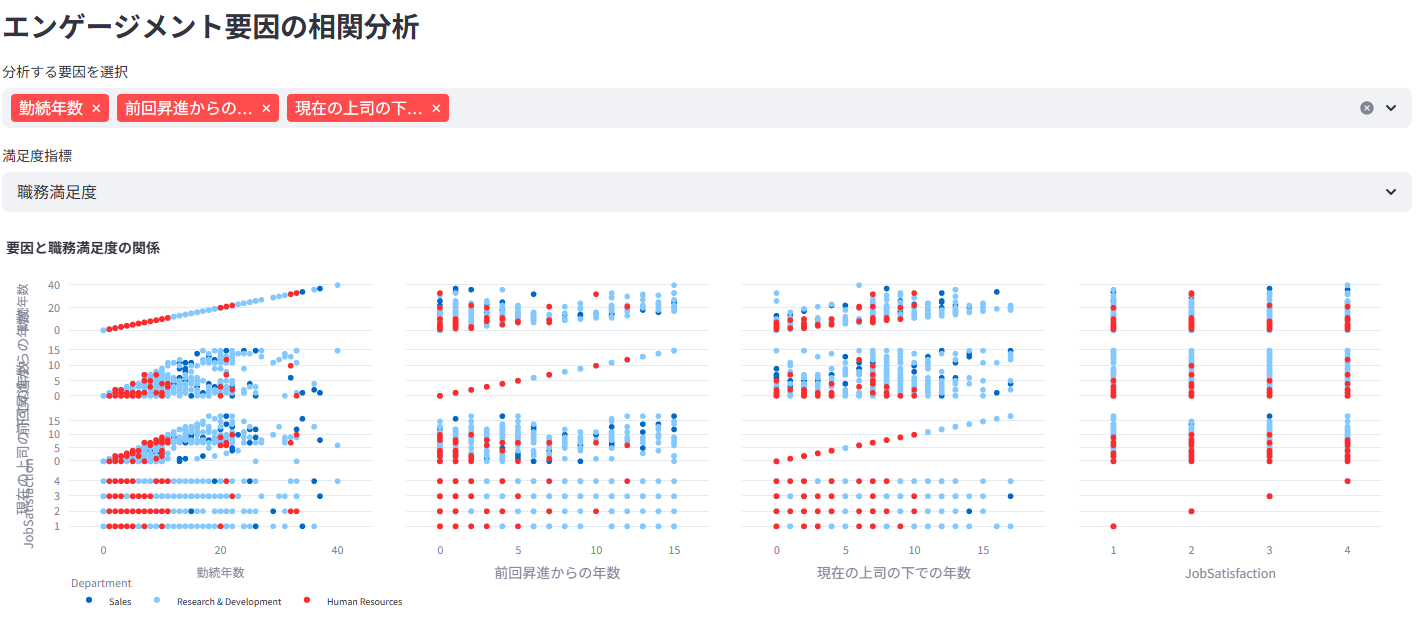
職務満足度、環境満足度、ワークライフバランスなどの分布と相関を分析
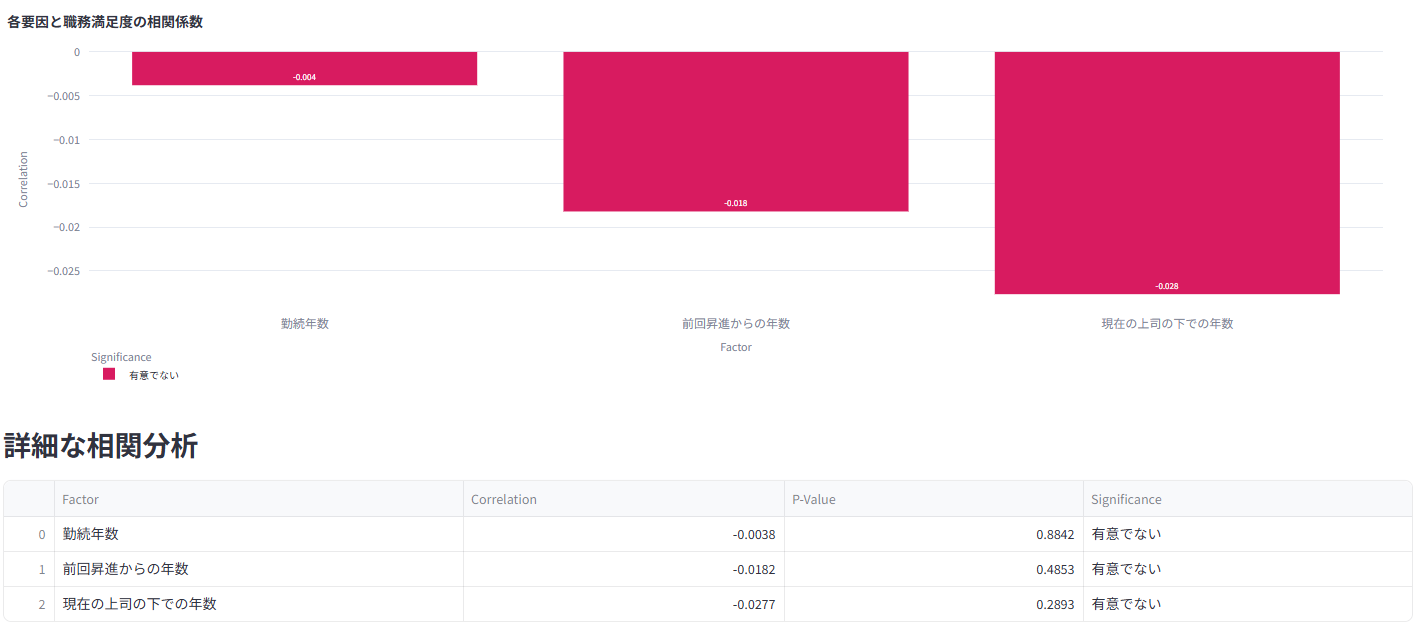
残業や特定の属性がエンゲージメントに与える影響を統計的に評価
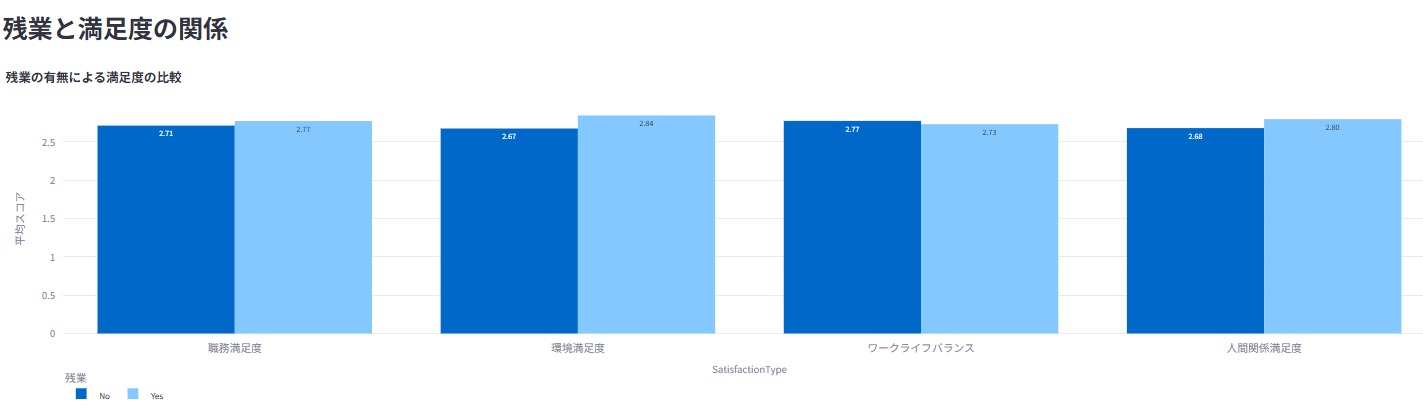
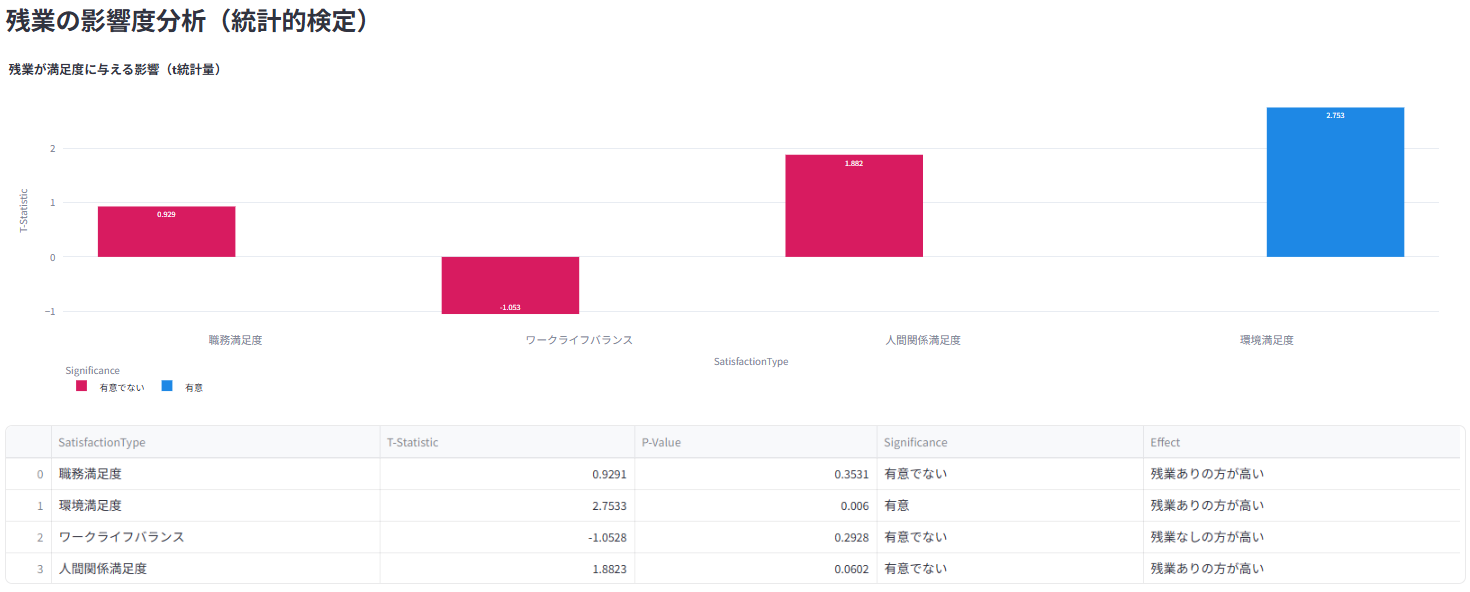
低エンゲージメント従業員の特性を特定し、改善のためのアクションプランを提示

7. ⏱️ 労働生産性/ワークスタイル分析
残業時間、出張頻度などのワークスタイルを分析
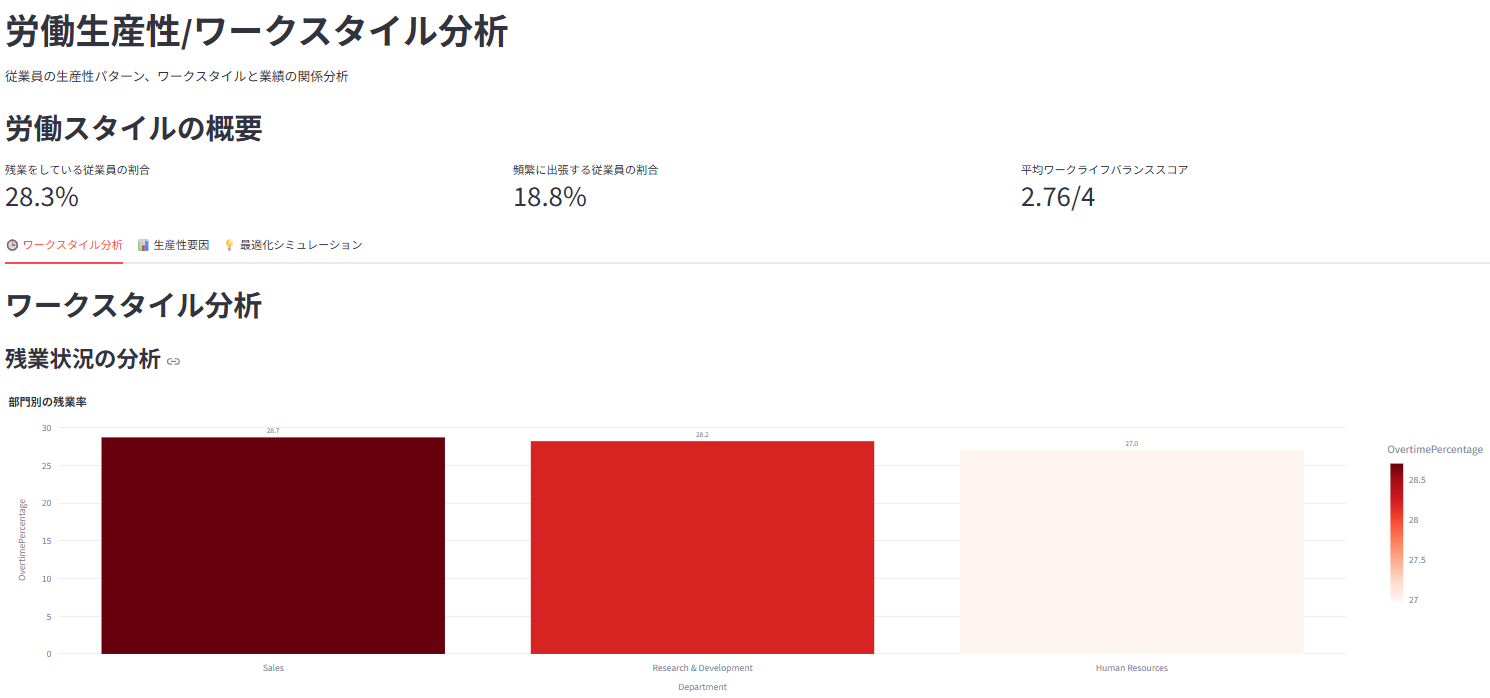
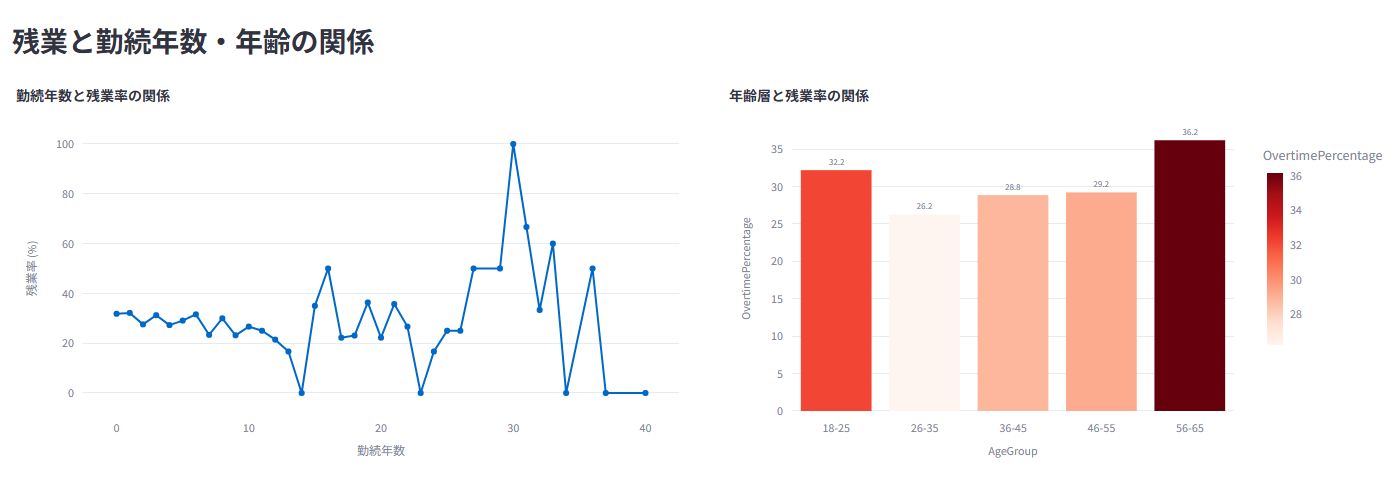
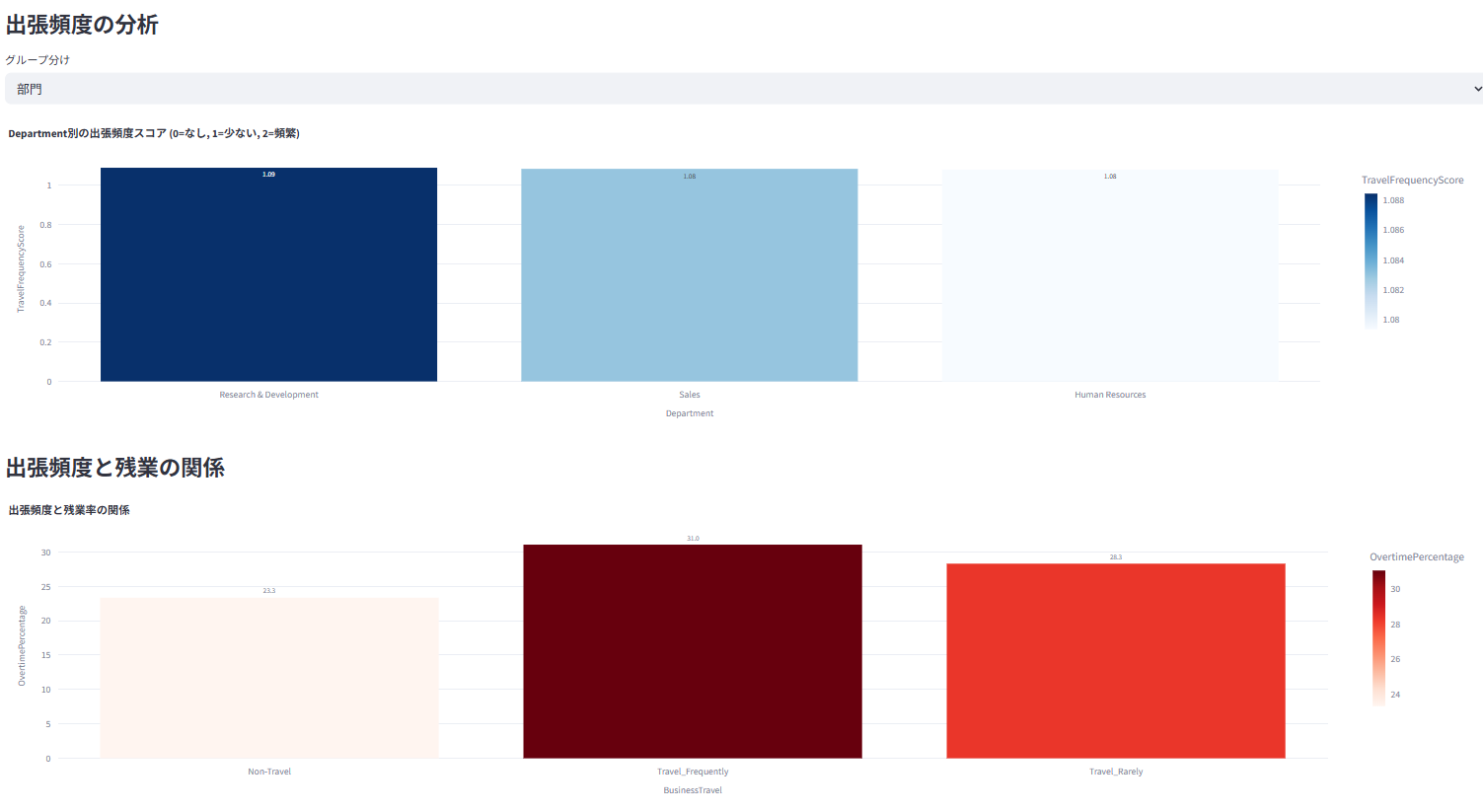
ワークライフバランスや残業が業績評価に与える影響を可視化

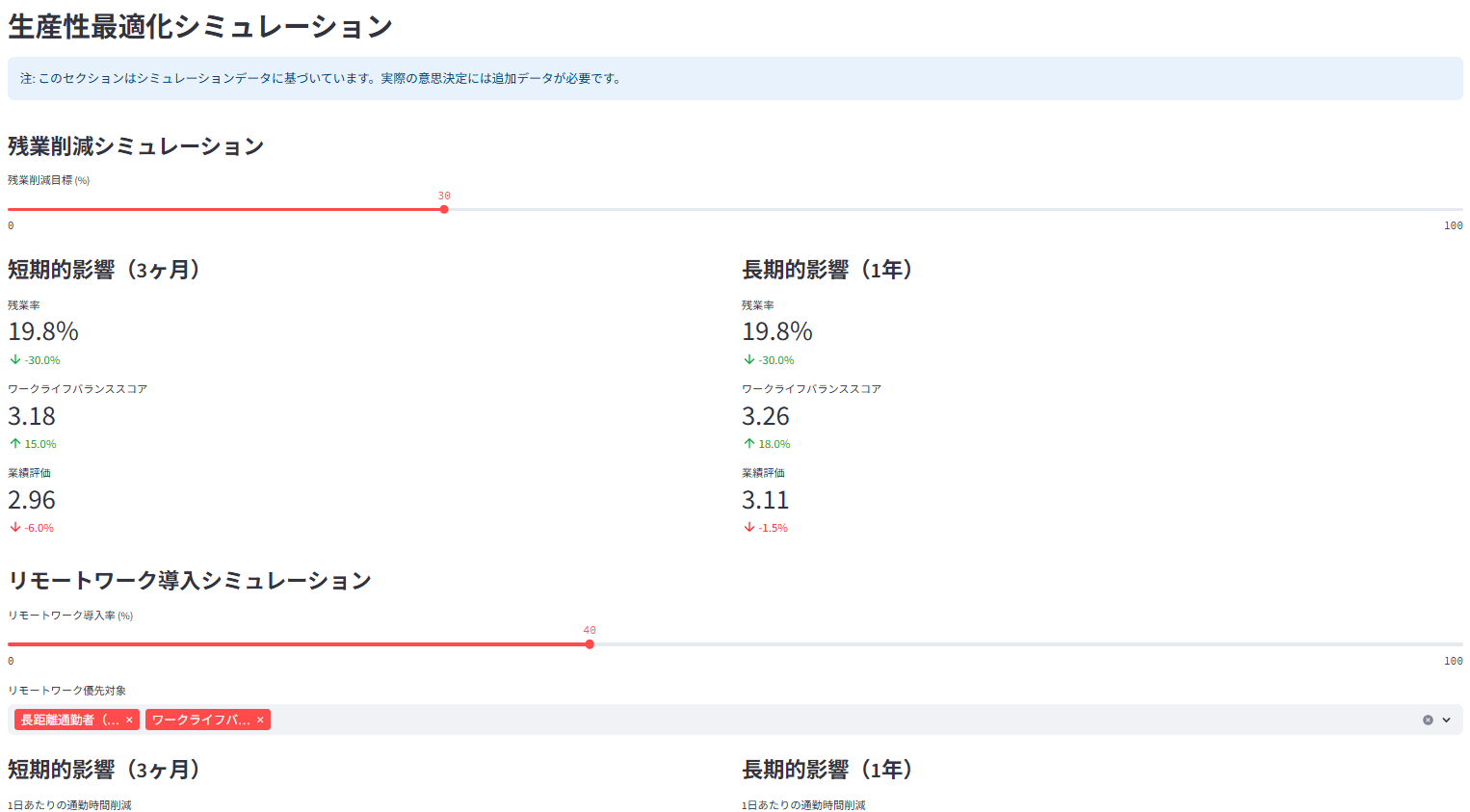
残業削減やリモートワーク導入が生産性指標に与える影響をシミュレーション(仮定に基づく)
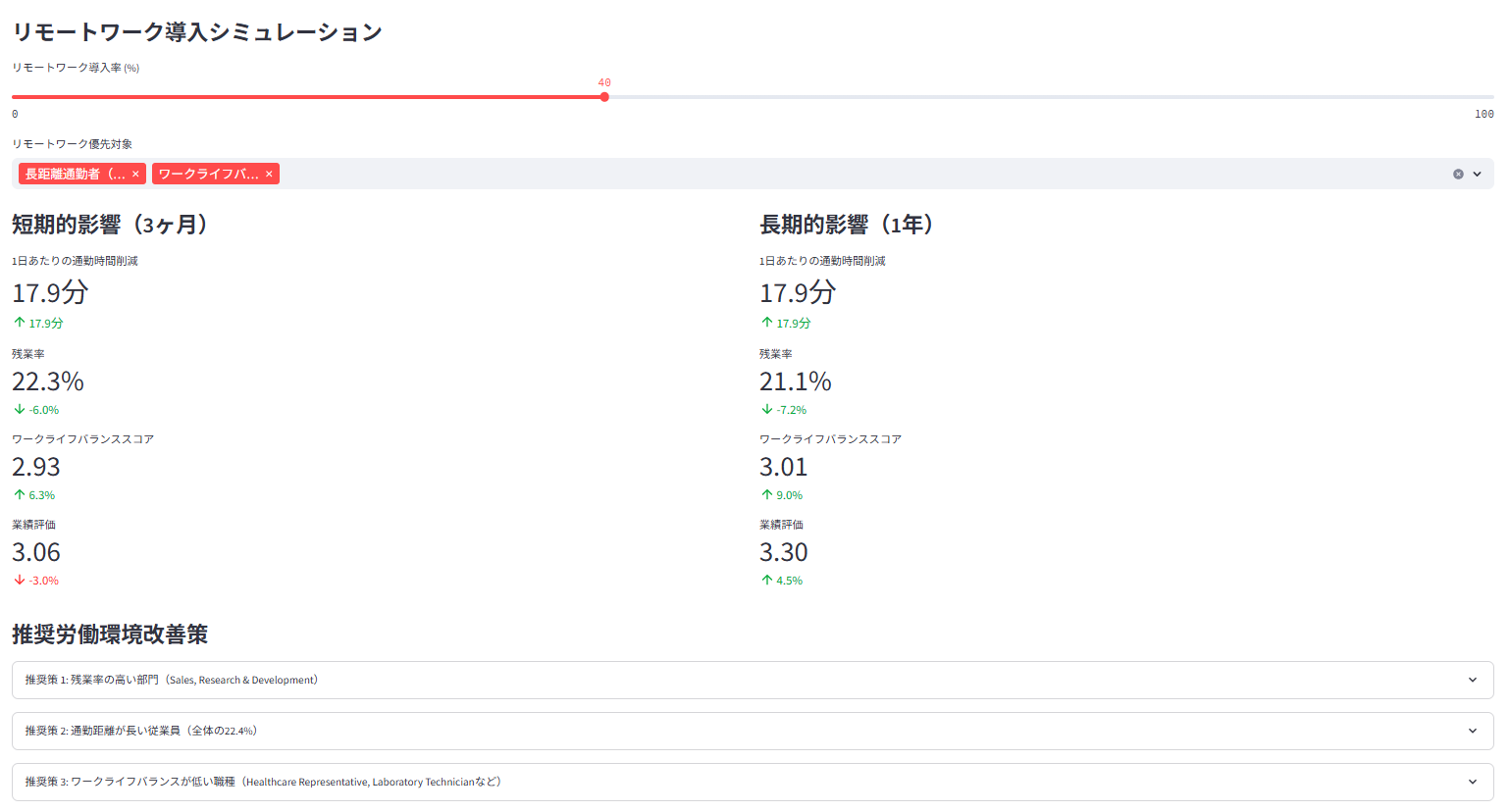
8. 🔮 予測分析・シミュレーション
離職予測モデルの詳細評価(精度、AUC、混同行列など)と比較
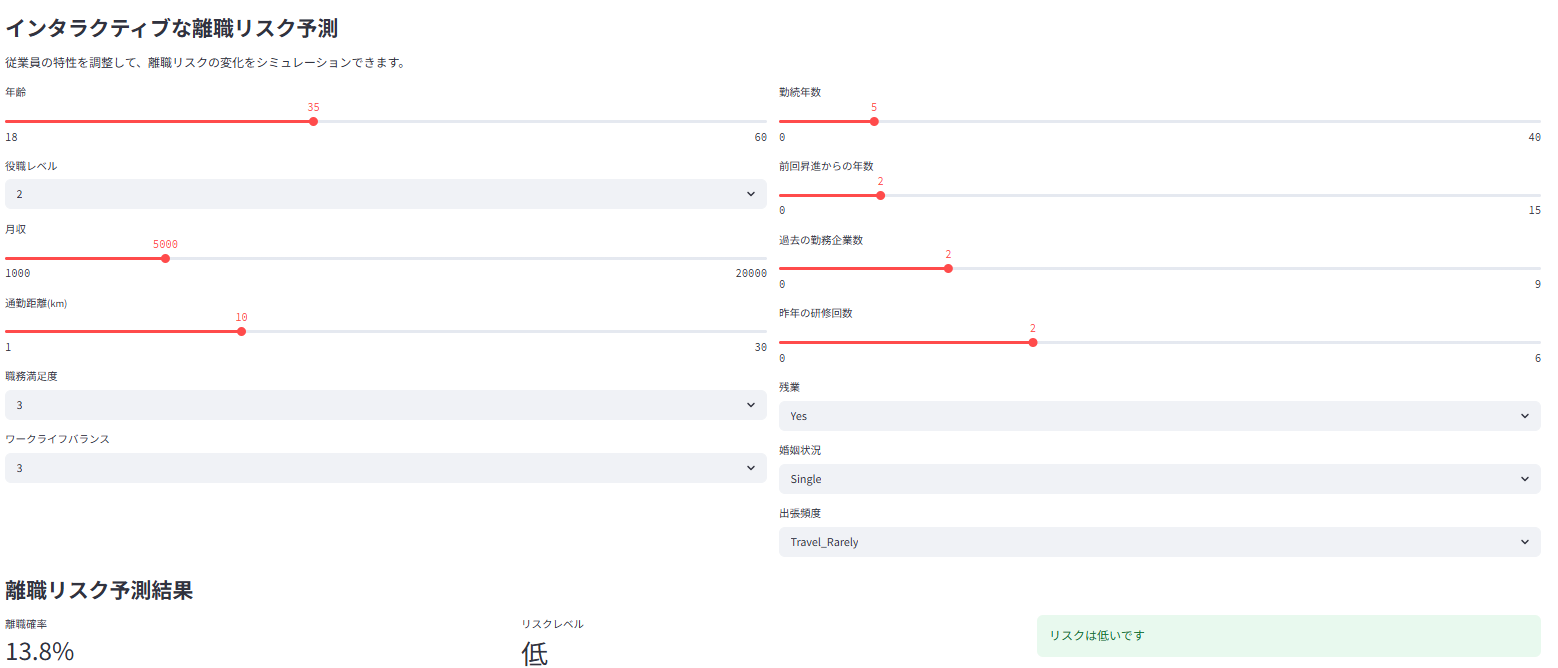
スライドバーを用いたUIで、特定の従業員の離職リスクをリアルタイムに予測
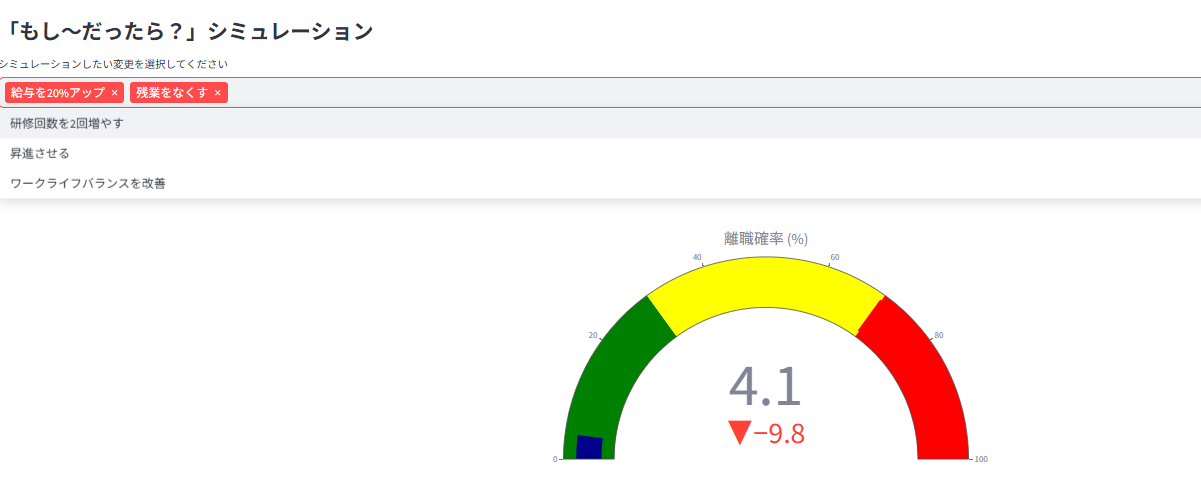
「もし給与を上げたら?」「もし昇進させたら?」といった施策の効果をシミュレーションし、離職確率の変化をゲージチャートで表示
給与予測モデルの評価と比較
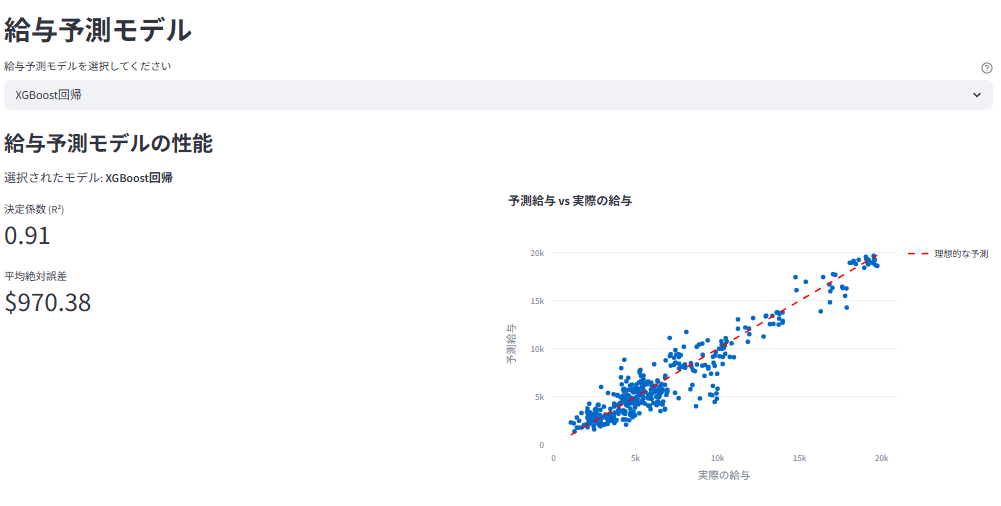
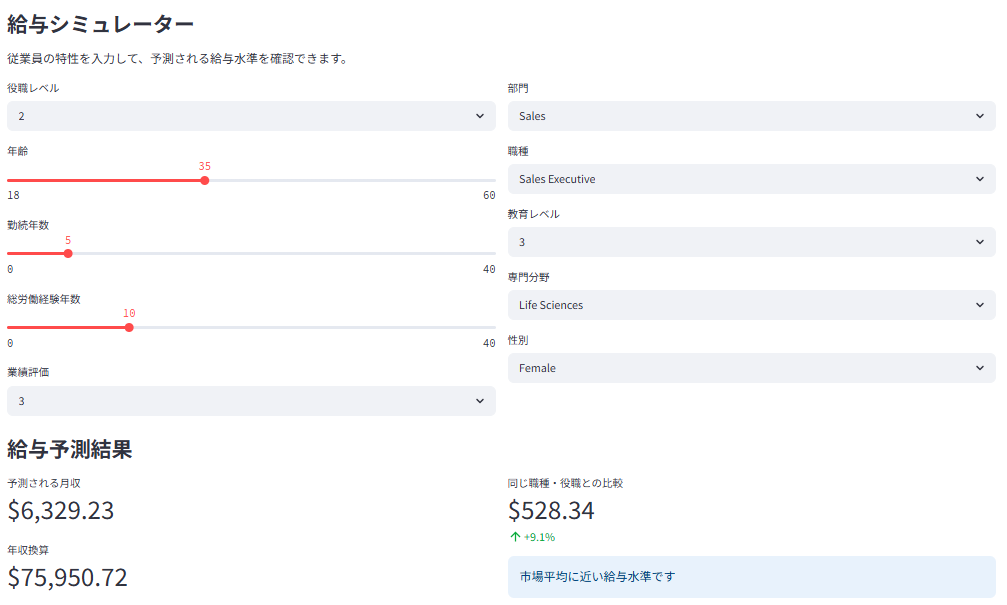
スライドバーを用いた給与シミュレーターで、属性に応じた予測給与と市場比較を表示
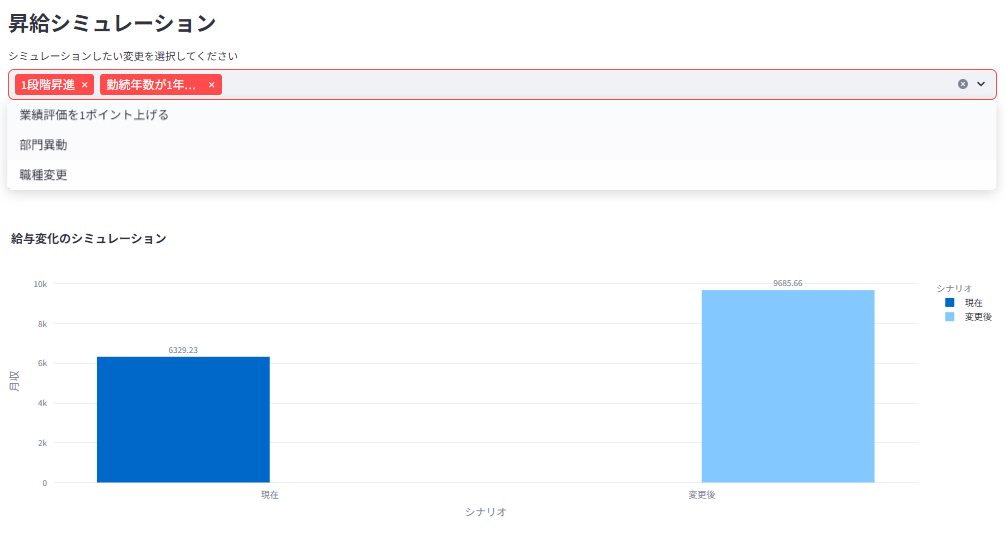
「1段昇進」「勤続年数が1年増える」などの場合で昇給シミュレーションし、給与の変化を棒グラフで可視化
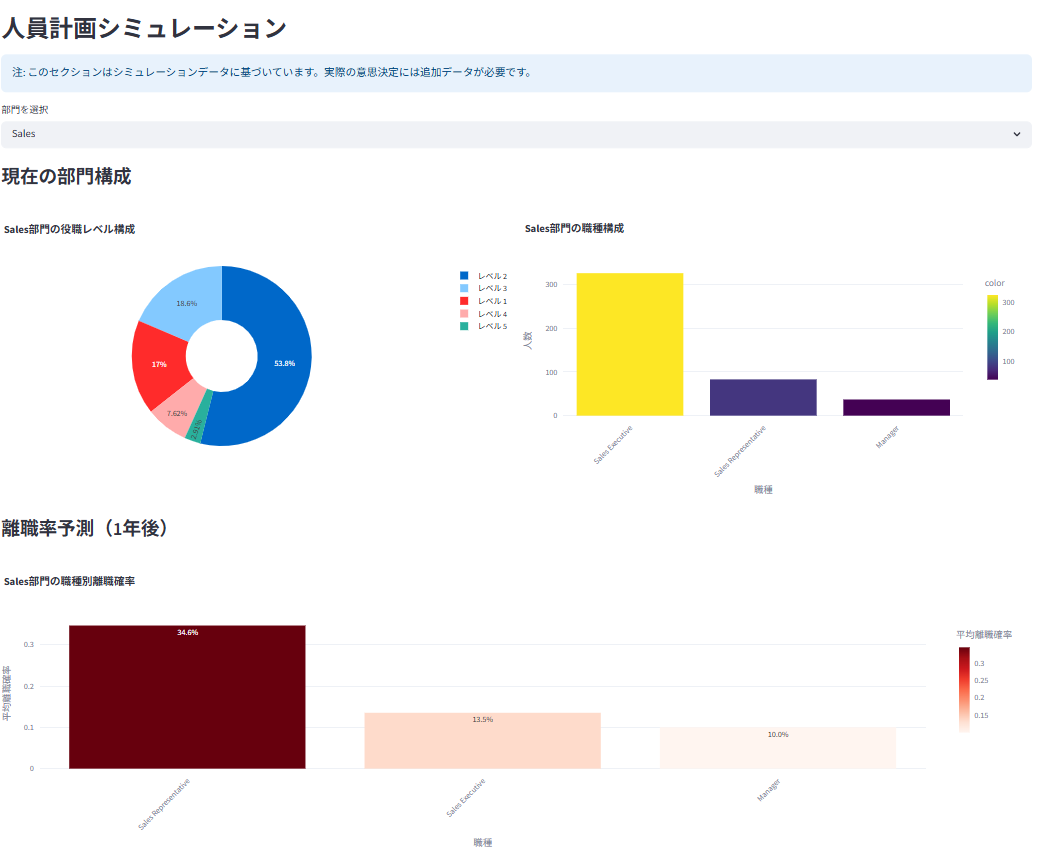
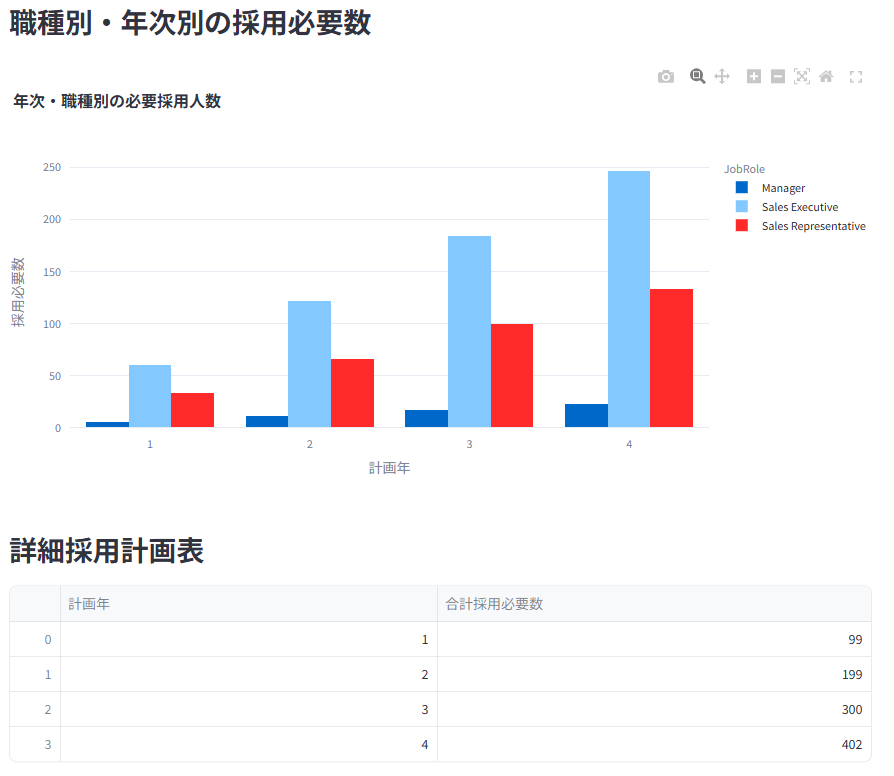
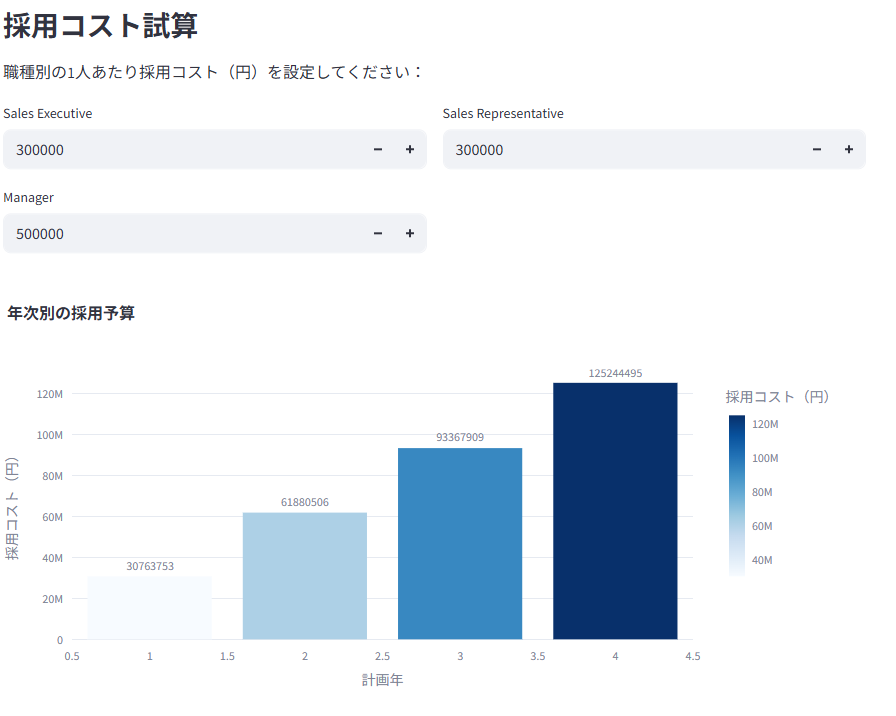
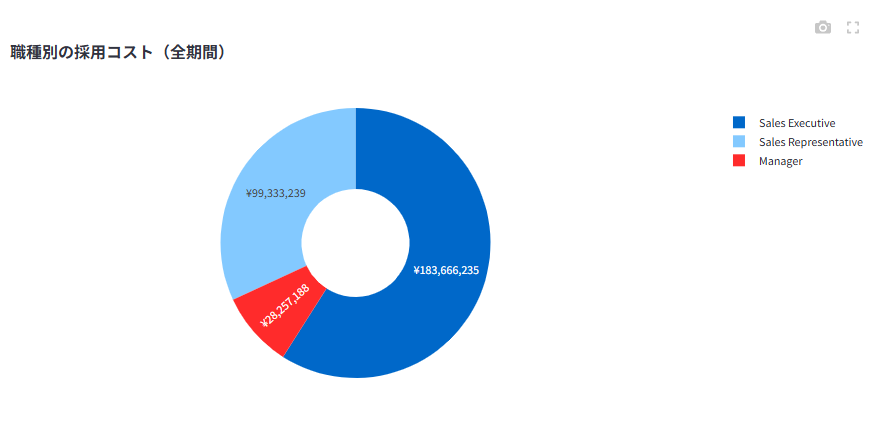
人員計画シミュレーションにより、将来の成長率と予測離職率に基づいた年次・職種別の必要採用人数と採用コストを試算

使用した分析モデルについて
HR Analytics Dashboard(HRAD)の予測機能(離職予測、給与予測)では、複数の機械学習モデルを利用できるようにしました。
-
離職予測(分類問題)
- ロジスティック回帰(確率論に基づく線形モデル)
- ランダムフォレスト(複数の決定木を組み合わせたアンサンブル学習モデル)
- 勾配ブースティング(前の木の誤差を次の木が修正していく連続的なブースティングモデル)
- XGBoost(高度に最適化された勾配ブースティングモデル)
- LightGBM(高速なトレーニングと予測ができる軽量な勾配ブースティングモデル)
これらのモデルを比較検討し(詳細はmodel_comparison.ipynb参照)、UI上では分析するユーザーがいずれかのモデルを選択して結果を確認できるようにしました。精度だけでなく、SHAPライブラリを用いてモデルの予測根拠を可視化し、解釈可能性も重視しました。例えば、「月収の低さ」や「残業の多さ」などの各種要因が、具体的にどの程度離職確率を高めているかを直感的に理解できるようにしました。
-
給与予測(回帰問題)
- 線形回帰
- ランダムフォレスト回帰
- 勾配ブースティング回帰
- XGBoost回帰
- LightGBM回帰
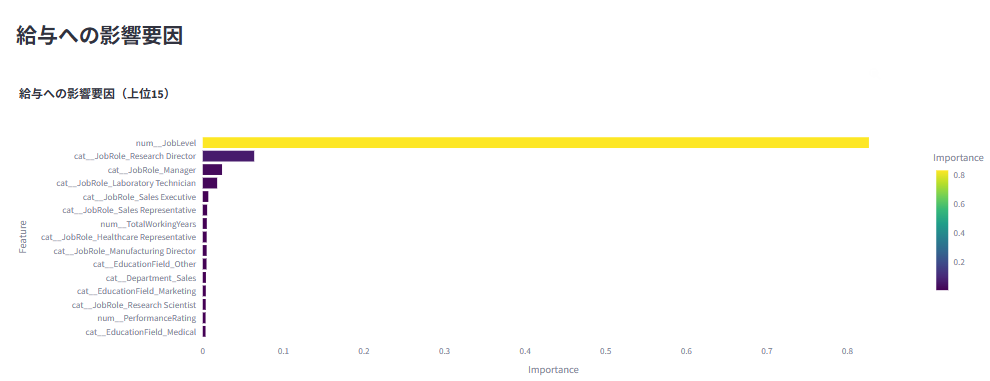
こちらも同様に複数モデルを用意し、分析するユーザーが選択可能の仕様としました。決定係数R²スコアや平均絶対誤差MAEで精度を評価しつつ、どの特徴量(役職レベル、経験年数など)が給与に強く影響しているかを分析できるようになっています。
これらのモデル選択と比較機能を取り入れることで、単一のモデルに依存せず、多角的な視点から予測と要因分析ができるようにしました。
技術スタック・アーキテクチャについて
技術スタック
HRADでは主に以下の技術スタックで実装しました。
- 言語: Python 3.12.4
- フレームワーク: Streamlit
- データ操作: Pandas, NumPy
- 可視化: Plotly, Matplotlib, Seaborn
- 機械学習: Scikit-learn, XGBoost, LightGBM
- モデル解釈: SHAP
- 環境管理: venv, requirements.txt
- その他: Git, GitHub
技術状況連携図
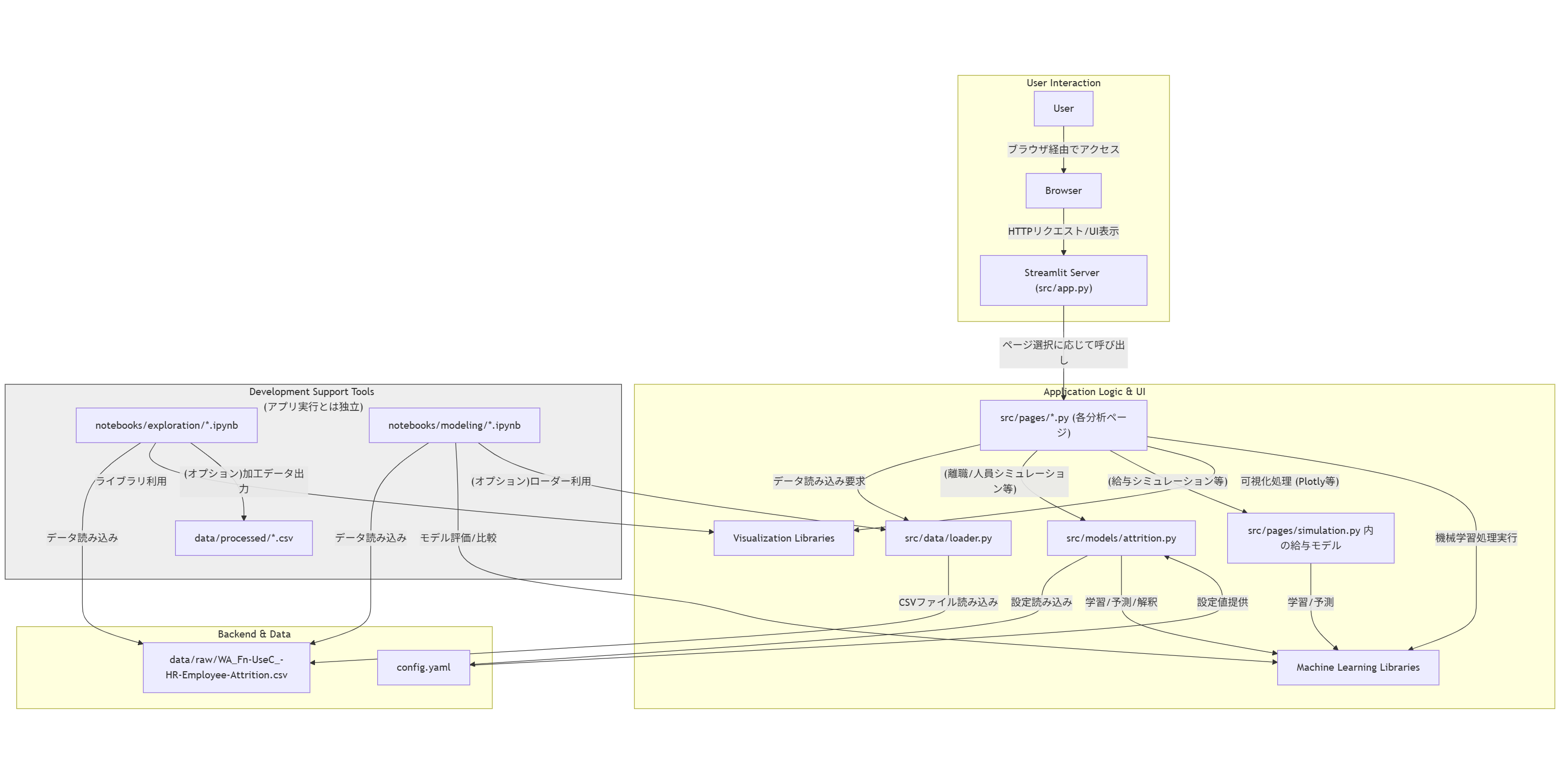
基本的な構成は、src/app.py がエントリーポイントとなり、各分析ページ (src/pages/*.py) の show() 関数を呼び出す形のシンプルなものにしています。データ読み込み (src/data/loader.py) やモデル関連処理 (src/models/attrition.py) はモジュール化してなるべく拡張可能性や管理のしやすさを残すようにしました。
今後の改善点(現時点ではできないこと)
作ってはみたもののHRADはまだまだ試作段階の簡易版なので、改善点も山盛りです。実際に完全な設計書通りの実装になっていないため、作っただけの空ファイルも散乱している状態です。ひとまず、改善点(現時点ではできないこと)は以下の通りです。
- データ連携: 現状はCSVファイルのみ対応ですが、データベース接続やAPI経由でのデータ取得に対応できるように拡張したい。
-
分析機能の拡充
- user_guide.md(ユーザーガイド)にも記載している通り、人材獲得、人材育成・パフォーマンス(現状は一部ダミーデータ)、エンゲージメント、生産性分析を実データに基づいてさらに深掘りしたい
- パフォーマンス予測、ハイパフォーマー分析、スキルギャップ分析などを追加したい
-
予測モデルの高度化
- ハイパーパラメータ最適化 (Optunaなど) の導入したい
- 時系列要素を考慮した離職予測を導入したい
- AutoMLの活用検討(あくまで検討なのでやるかどうか未定)
-
UI/UXの改善
- レスポンシブデザインの強化(取り入れてはいるがところどころ微調整は必要)
- よりインタラクティブで直感的な操作性(グラフのドリルダウンなど)
- ユーザー権限管理、認証機能(本番運用を想定する場合は必須)
- 他ツール連携: Slack通知、レポーティング機能など
まとめ
今回は、私が作成したHR分析ダッシュボード「HRAD」について分析機能、分析モデル、技術スタック、今後の改善点などを投稿させていただきました。
シンプルな実装が可能なStreamlitを使うことで、人事関連の経験、統計、機械学習、そしてPythonでのデータ分析を学習してきた知識を活かして、比較的短期間でアプリを構築することができたように思います。
経済学や統計学、機械学習の知識は、HRというドメインにおいても非常に有用であり、データに基づいた客観的な分析も取り入れることで、より良い組織作りや人材戦略に貢献できる可能性を秘めていると感じています。
今回紹介したHRADシステムはまだまだ発展途上なので実用的ではない点も多いのですが、この記事を読んでくださった方が人事データ分析やStreamlitでの何かしらの開発に興味を持つきっかけとなれば嬉しいです。
こちらがGitHubリポジトリですのでよかったら覗いてみてください:https://github.com/yf591/hr-analytics-dashboard
ユーザーガイド:https://github.com/yf591/hr-analytics-dashboard/blob/main/docs/user_guide.md
また、Google colabで実行して見られるようにしたので、もしよかったら見てみてください。
最後までお読みいただき、ありがとうございました。
Views: 2

{kind=link}