
最近はClaude Codeのsub-agentsの登場なども背景に、マルチエージェントという言葉が語られる機会がグッと増えたなと感じます(AIエージェント開発だけでなく、活用の文脈でも)
一方で、シングルエージェントについて語る企業や記事の存在もあります。
この記事は、いくつかの文献を参照しながら、シングルエージェントやマルチエージェントの概念や差分について整理した内容です。
基本的・長期的には並列稼働も前提としたマルチエージェントな構成が増えていくのだろうと思う一方で、シングルエージェントの利点やメリットが強調される理由も認識しておけると良いなと。
はじめに
前述の通り、最近はマルチエージェントという言葉が浸透してきていることを感じます。
マルチエージェントと言わずとも、プロンプトやステップを分割することで性能が上がったとする研究などの存在は、数年前から数えきれないほどです。
Anthropicは、幅優先探索型のリサーチタスクにおいて、マルチエージェントシステムにより、約90%の性能向上を達成したと報告しています。
分割統治の原則に違わず、マルチエージェントやワークフロー・ステップの分割が有用であることに疑問はありません。
その上で、疑問に思うのは、マルチエージェントがいつでも万能な存在なのか?という点です。
その事を考える上で思い出したのが、Cognition AI(Devinの開発元)が2025年6月12日に公開した記事です。
「マルチエージェントを作るな」と題した記事の中で、サブエージェント間のコンテキスト共有の欠如が、いかにシステムの信頼性を損なうかを語っています。
こちらは少し前の記事ですが、All Hands は「Don’t Sleep on Single-Agent Systems」と題した記事を公開しています。
コーディングエージェントを提供する2社が、シングルエージェントについて言及する記事を公開してるのは気になリます。
この一見相反する主張の背後には、何があるのでしょうか?
両者の主張は、同じ問題を異なる角度から見ていることがわかります。
その背景には、これまた目にする機会が増えているコンテキストエンジニアリング、AIシステムの情報アーキテクチャ設計の問題があります。
AIサマリ
- AI開発において、複数のエージェントが協調する「マルチエージェント」と、単一で完結する「シングルエージェント」のどちらが優れているかという議論があります。
- マルチエージェントは、リサーチのような並列処理しやすい 「読み込み中心」 のタスクで高い性能を発揮しますが、エージェント間の情報共有(コンテキスト共有)が難しく、エラーが増えやすいという欠点も指摘されています。
- 一方、シングルエージェントは、コーディングのような一貫性が厳しく求められる 「書き込み中心」 のタスクにおいて、コンテキストを維持しやすく信頼性が高いとされています。
- 結論として、どちらか一方が万能なわけではなく、タスクの特性(並列化のしやすさ、一貫性の要件)やコストを考慮し、最適なアーキテクチャを選択することが重要です。
AIエージェントの定義とマルチエージェントを表すもの
複数論文等からの正確な定義・まとめは割愛しますが、ざっくりだけ定義とか概念には触れておきます。
オライリーのAI Engineering本から抜き出すと、エージェントとは 「Environment(環境)と Action(行動)により規定される存在」 です。
そして、環境はエージェントが駆動する場そのものであり、エージェントが対象とするユースケースにより定義されます。大抵の場合はインターネットが環境となります。(インターネットからドキュメントをスクレイピングさせたい場合、環境はインターネット、料理ロボットであれば、キッチン)
アクションはAIエージェントが実行できる一連の能力であり、基本的には、いわゆる「ツール」と呼ばれるものによって拡張されます。ウェブ検索やコード実行ツールなどです。
その上で、マルチエージェントとは何を指すのでしょうか?
GoogleのAI Overviewによると、マルチエージェントは、「自律的に思考・行動するAIエージェントが複数組み合わさり、互いに協調・連携してタスクを遂行する仕組み」です。
再度オライリーのAI Engineering本から参照すると、「システムがプラン生成、プラン検証、プラン実行の三つの独自のプロンプト・ツールを保持するコンポーネントがあるなら、これはマルチエージェント」 と述べています。
(こうなってくると、もはやシングルエージェントでいられる方が難しそうに感じます)
Cognitionの主張
Cognitionの主張のポイントは、信頼性の高いエージェントを構築するためのコンテキストエンジニアリング の重要性です。
彼らは、現在のエージェント開発の状態を 「まだ素のHTMLとCSSで遊んでいる段階」 と表現し、堅牢なエージェントシステムを構築するための原則が必要だと説いています。
マルチエージェントアーキテクチャは、彼らが提唱する2つの原則(コンテキストの完全な共有、暗黙の決定の同期)を破りやすく、エラーが雪だるま式に膨らむ(compounding errors) リスクが高いと考えているのです。
個々のメッセージだけでなく、コンテキストとエージェントのトレース全体を共有する(Share context, and share full agent traces, not just individual messages)
彼らが挙げる「Flappy Bird」のクローン開発の例を紹介します。
- タスク: Flappy Birdのクローンを作る
- サブタスクA: 動く背景と土管を作る → サブエージェントAが担当
- サブタスクB: 上下に動く鳥を作る → サブエージェントBが担当
このアーキテクチャの典型的な失敗例は、サブエージェントAが「スーパーマリオ」風の背景を作り、サブエージェントBがゲームアセットに見えないリアルな鳥を作ってしまうことです。
最終的に、スタイルがバラバラで一貫性のない成果物を統一するという難題に向き合います。
この失敗の原因を「コンテキストの共有不足」だと指摘します。
究極的には、一方のエージェントが行ったツールコール、対話履歴、そしてそこから生じたすべての決定の軌跡(=エージェントのトレース全体) が、もう一方に共有されなければならないのです。
(そして、そのコントロール・共有がとても難しい)
人間世界でもステークホルダーが増えたら、認識揃えたり、合意を取る、行動に一貫性を持たせるの大変だよね!と言い換えるとわかりやすいかもしれません。
アクションには暗黙の決定が含まれる(Actions carry implicit decisions, and conflicting decisions carry bad results)
「行動は暗黙の決定を含み、矛盾する決定は悪い結果をもたらす」 というマルチエージェントシステムにおけるコンテキストの共有をやりきる難しさを指摘しています。
上記の例をさらに掘り下げると、サブエージェントAとBは、それぞれがビジュアルスタイルやゲームの物理法則といった 「暗黙の決定」 を独自に行っていました。
これらの決定が共有・同期されなかったため、最終的な成果物に矛盾が生じたのです。
例えば、コードを書くときは、ライブラリ選定、命名規則、デザインパターンら、無数の暗黙の決定の元に行動が行われています。これが共有されないと一貫性が崩壊するという指摘です。
特にコーディングのような一貫性が重要なタスクでは、この問題は致命的になるとしています。
深津氏の投稿も似たような問題を彷彿とさせます。
シングルスレッドアーキテクチャの利点
これらの原則を最も簡単かつ確実に守る方法として、「シングルスレッドの線形エージェント」アーキテクチャを推奨しています。

引用: https://cognition.ai/blog/dont-build-multi-agents#applying-the-principles
このアプローチの利点は以下の通りです。
| 利点 | 理由・詳細 |
|---|---|
| 連続的なコンテキスト | すべての決定とアクションが一つの流れに沿って実行されるため、コンテキストが失われたり、分岐したりすることがない。 |
| 一貫性の担保 | すべてのステップが先行するステップの完全なコンテキストを継承できるため、「暗黙の決定」が矛盾するリスクを排除しやすい。 |
| デバッグの容易さ | 問題が発生した場合、単一の実行履歴を追うだけで原因を特定しやすい。 |
コンテキストウィンドウの枠内に収まる限り、シンプルなシステムでいられる構成・シングルエージェントの利点を推してると認識しました。
図の通り、単純に複数LLM・ステップが存在するかではなく、依存性や並列の有無、複数の並列サブエージェントの存在が論点となりそうです。
長期的な可能性については認めた上で、現時点ではエージェント間でコンテキストを共有する難しさの方が勝るという判断のようです。
2025年現在、複数のエージェントを協力して実行することは、脆弱なシステムを生み出すだけであることは明らかです。意思決定が分散しすぎ、エージェント間でコンテキストを十分に共有することができません。
引用: https://cognition.ai/blog/dont-build-multi-agents
ただし、シングルエージェントの課題(複雑なタスクにおけるコンテキストウィンドウのオーバーフロー)にも言及しています。
後述しますが、これらの課題に対応するために、「履歴を重要なイベントや決定に圧縮する専用のLLMを導入する」といった、原則を守りつつスケールさせるための高度なコンテキストエンジニアリングにも取り組んでいるとのことです。
ちなみに、All Handsは「Don’t Sleep on Single-Agent Systems」の中で、同様にコンテキスト共有などの問題について触れた上で、「強力なモデル、強力なツール、そして多機能なプロンプトがあれば、十分太刀打ちできるのでは」と述べています。
そして、重要なのは、マルチエージェントを完全に否定していない点です。
大抵のケースでは原則を破るほどの価値はない、慎重にコンテキスト共有の仕組みが設計されていない限り、デフォルトのアプローチとしてマルチエージェントを選ぶべきではない ということで、KISSの原則(Keep It Simple, Stupid)に基づいたものと捉えると納得度は高いです。
なので、単純化すると 「シンプルな実装から始めよう!」だと理解しています。
Anthropicのマルチエージェントの実証
Anthropicのリサーチエージェントは、オーケストレーター・ワーカーパターンを採用しています。
AIエージェント領域を追いかけている人にとっては、ここ数年間は頻繁に遭遇する、お馴染みの存在です。
- LeadResearcher:クエリを分析し、戦略を立案、3-5個のサブエージェントを同時展開
- サブエージェント群:異なる観点から並列に情報を探索
- CitationAgent:ソースの正確な引用処理を担当
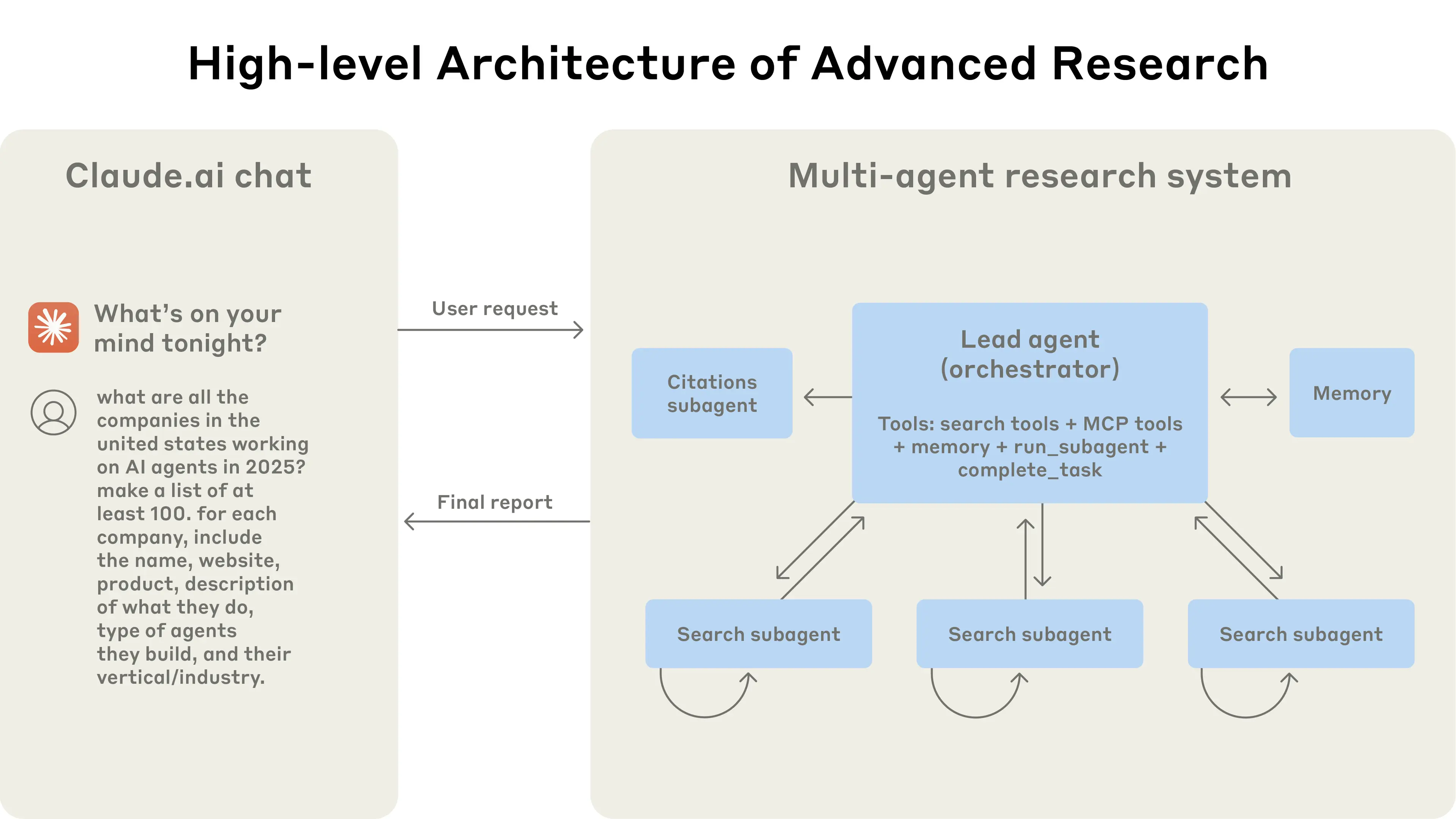
引用: https://www.anthropic.com/engineering/multi-agent-research-system
Anthropicの記事では、上記のオーケストレーターパターンにより、複雑なリサーチタスクで最大90%の性能向上を実現したと述べています。
押さえておく必要があるのは、対象となるタスクの特性です。
LangChainが提示するタスク特性による選択
ここで新たな記事を紹介しますが、LangChainもまた、「How and when to build multi-agent systems」と題して、マルチエージェントをいつ構築するかについて述べています。
(LangChainは、以前のBig ModelとBig Workflowsの時もそうでしたが、こういう議論に積極的に介在してくるので読者としてはありがたい気持ち)
LangChainは両者の主張を統合?し、タスク特性に基づく判断基準を提示しています。
それは、読み込み or 書き込みでの分類です。
- 読み込み中心:リサーチ、分析、データ収集 → マルチエージェント向き
- 書き込み中心:コード生成、コンテンツ作成 → シングルエージェント向き
この分類の背後にも、前述のコンテキスト分離の問題があります。
読み込みタスクでは、複数のエージェントが異なる情報を収集しても矛盾は生じにくい。
しかし、書き込みタスクでは、複数のエージェントが生成する出力の一貫性を保つことが極めて困難になるため、シングルエージェントの方が適しているという主張です。
Anthropicが取り組んだリサーチタスクは、複数の情報源を並行調査する典型的な 読み込み中心のタスク で、サブエージェント間のコンテキストが多少ずれても、最終的に情報を統合すれば問題になりにくい。
Cognitionが主戦場とするコーディングは、変数名から設計思想まで、全てが一貫している必要がある典型的な 書き込み中心のタスクです。コンテキストが少しでもずれれば、全体が破綻する可能性があります。
つまり、両者はそれぞれの得意なドメインに最適なアーキテクチャを主張しているという内容です。
Anthropicも課題やトレードオフについては、複雑性が増すことによる影響があること、マルチエージェントが現時点では得意とは言えないタスクもあることを語っています。
| 課題 | 説明 |
|---|---|
| トークン使用量が15倍 | 通常のチャット対話と比較して大幅なコスト増(エージェントは約4倍、マルチエージェントは約15倍) |
| パフォーマンス向上の80%はトークン使用量で説明可能 | 計算リソースをぶん回してるだけという見方もできる |
| 調整の複雑性 | エージェント数が増えると複雑性が急速に増大 |
| エラーの伝播 | 小さな問題が全体のエージェント軌道を狂わせる可能性 |
| 非決定論的動作 | デバッグと再現性が困難 |
実際に、並列化しているのはリサーチ(読み込み)部分であり、最終的なレポート作成(書き込み)はメインエージェントが一括して行っています。
- リサーチフェーズ:マルチエージェントで並列探索
- 統合フェーズ:シングルエージェントで一貫性のある出力生成
とはいえ、読み込み中心のマルチエージェントの実装が簡単というわけではなく、依然として高度なコンテキストエンジニアリングが必要だとしています。
LangChainのBenchmarking Multi-Agent Architecturesも面白いです。
マルチエージェントが有効な条件・ポイント
ここまでの内容も踏まえて、Anthropicのマルチエージェントがなぜ効果的だったのか?を改めて整理します。
計算リソースの賢い並列投入
Anthropicの分析で興味深いのは、BrowseComp評価における80%はトークン使用量、つまり計算リソースの投入量で説明できるという点です。
マルチエージェントシステムは、シングルエージェントのコンテキストウィンドウの限界を超えて、問題を解決するのに十分なリソースを並列で賢く投入するためのアーキテクチャだったということです。
マルチエージェントシステムが機能する主な理由は、問題を解決するために十分なトークンを消費するのを助けるからです。私たちの分析では、BrowseComp評価(閲覧エージェントが探しにくい情報を見つける能力をテストする)におけるパフォーマンスの分散の95%を3つの要因が説明しました。トークン使用量自体が分散の80%を説明し、ツールコール数とモデルの選択が他の2つの説明要因であることがわかりました。
引用: https://www.anthropic.com/engineering/multi-agent-research-system?ref=blog.langchain.com
読み込み中心の並列探索
論文調査のような「オープンエンドなリサーチタスク」だったことは、一つの要因として抑える必要はありそうです。
これは複数の情報源を並行して調べられる、まさにLangChainの言う 「読み込み中心」のタスク です。
Anthropic自身も、現時点でのマルチエージェントの特性として、「コーディングのように、全てのエージェントが同じコンテキストを共有する必要があるタスクには、現在のマルチエージェントは得意ではない」 としています。
動的なコンテキスト管理
コンテキストエンジニアリングは「プロンプトエンジニアリングを超えた概念」で、動的に適切なコンテキストをAIエージェントに提供することが重要になります。
Cognitionは下記のような圧縮や予測を含んだ、動的なコンテキスト管理の必要性を謳っており、まさしくコンテキストエンジニアリングのイメージ通りなラインナップです。
- 賢い圧縮:専用のLLMモデルが履歴を「重要な詳細、イベント、決定」に圧縮
- 予測的キュレーション:将来の決定に必要な情報を予測して保持
- 階層的メモリ:異なる時間スケールで情報を保持
これは単純な要約ではなく、大切に扱われるコンテキスト、それを限られたコンテキストウィンドウに、最も価値の高い情報だけを配置するテクニックであり、プロダクトやドメインごとの差分によりAIエージェントの挙動や馴染みが変わってくる、大きな要因になりえます。
まず言えることは、少なくともIMFという観点からはAGIはどうでもよいということだ。つまりAGIが来るか来ないか、あるいは既に到来しているかは、少なくともAIやSaaSのGTMという観点からはどうでもよい。それよりもユーザーの手元のタスクに対して正しい知性で問題解決できるかのほうが重要だろう。ここでいう知性には反応速度、思考の深さ、幻覚の有無と程度、空気を読む力など、様々な側面があり、どの側面がどれだけ大事かは、タスクによって異なる。巷ではGPT-5が数学のとある問題に対して有意義な貢献をしたと話題にもなったが、そんな革新性が求められるタスクは商売のうえでは殆ど存在しない。どれだけ知性があったところで、ユーザーから必要とされなければ価値はなく、高くも売れはしない。いかにユーザーが求めている知性をパッケージ化するかにIMFの成功はかかっている。
シングル vs マルチの判断基準
ここまでシングルエージェントとマルチエージェントの対比について整理してきました。
今までの記事や議論を元に、判断基準を整理すると下記のようになるでしょうか。
| 検討項目 | 確認するポイント |
|---|---|
| タスクの並列化可能性 | 各サブタスクは、他のタスクから独立して実行可能か? |
| 各サブタスクの結果を統合する作業は、単純か、それとも複雑か? | |
| コンテキスト共有の必要性 | 全てのエージェント(サブタスク)が、常に同じ情報を参照する必要があるか? |
| エージェントごとの「暗黙の決定」が、他のエージェントの作業と衝突するリスクはあるか? | |
| 経済的価値 | 最大で15倍にもなるトークンコストを支払う価値があるタスクか? |
| 並列化による時間短縮や性能向上のメリットは、コスト増を上回るか? | |
| ドメイン特性 | 書き込み中心(例: コーディング)→ シングルエージェントを推奨 |
| 読み込み中心(例: 分析)→ マルチエージェントを検討 | |
| 上記を組み合わせたハイブリッドアプローチの可能性も探る |
タイトルに書いておいてなんですが、「マルチエージェント vs シングルエージェント」という二項対立は、誤った問いかけなのは間違いありません。
AIエージェントシステムも、ソフトウェアシステムであることには変わらず、内部がマルチエージェントかシングルエージェントかも、ユーザーにとって本質的に関係ない話ではあるので、
- どのようにユーザーに最大の価値を提供できるか?
- 与えられたタスクと制約の中で、最も信頼性の高いシステムは何か?
- エンジニアリングリソースを最も効果的に活用する方法は?
の観点でアーキテクチャを選定するべきでしょう。
その上で、マルチエージェントが最適であればマルチエージェントの開発、そしてそれに伴うLLMOpsやコンテキストエンジニアリングに格闘することになります。
(シングルエージェントも変わりませんが..!)
まとめ
シングルエージェントとマルチエージェントの特性や使い分けをどのように考えたら良いかを整理してきました。
中長期的には、タスク特性に応じたデザインパターンの確立に伴うアーキテクチャ選定などのナレッジの浸透、Zepなどのコンテキストエンジニアリングのための専門ツールの発展や、そもそもモデルの性能向上によるアプローチの変化などなどが起こるのでしょう。
(どこで見つけたのか不明ですが、記事の叩きに書いてた)また、Gartnerの予測では、「真のエージェント技術」を提供する企業は130社のみ(数千社が主張する中で)だそうです。
真のエージェント技術が何かはわかりませんが、タスクの本質を見極め、最もシンプルで信頼性の高いアプローチを選択することが求められいると感じました。
追加で書きたいこと・読みたいものがどんどん出てくるのですが、キリがないので、今回は以上です!また次回!
(OpenAIのA practical guide to building agentsは、書き終わってから、存在を思い出しました)
参考
Appendix.
記事に収められなかったやつ。もはや次回以降の記事のため、自分が忘れないためのメモ
- AIリーダブルなデータベースという概念 is 何
- 「AIが効率的に消費できる構造化された情報ストア」
- (従来通り?メモリと呼ぶ方が適切かもしれないが)
- 単なるデータベースではなく、エージェントの思考や決定のトレースやログとしても活用できてこそ。少なくとも「for AIエージェント」という観点では
- 完全なエージェントによるトレース:出力だけでなく、すべての決定過程を含む
- 決定履歴と根拠:なぜその選択をしたかの理由を保持
- 失敗したアプローチと学習事項:試行錯誤の歴史も重要な文脈
- 現在の状態と制約:今何ができて何ができないかの明確な把握
- MSAは新しい問題ではない
- 現在議論されている「エージェント間の情報共有」の難しさは、LLM登場以前のマルチエージェントシステム研究で数十年来の中心課題
- “An Introduction to MultiAgent Systems” by Michael Wooldridge
- “A Concise Introduction to Multi-agent Systems and Distributed Artificial Intelligence”
- 人間をどこに介在させるか?
- エージェント同士だけでなく、人間がプロセスを理解し、介入しやすいかも重要な判断基準
- プロセスを人間が把握・修正する必要があるタスクでは、シングルエージェントが有利な場合があるか
- “Measuring the ‘Good’ in Human-AI Interaction” (Google AI Blog)
- (9/2追記)エージェントの対話プロトコル、MCPやA2Aでコンテキスト共有の問題は解決できるのか?
- (9/2追記)動的なエージェント編成(Dynamic Agent Composition)とその際のコンテキスト共有と評価
- (9/2追記)シングルエージェント or マルチエージェントにおけるコンテキストエンジニアリングの差分
Views: 0

{kind=link}