
Claude Sonnet 4.5は、Anthropicが2025年9月30日にリリースした最新のAIモデルです。公式発表によると、「世界最高のコーディングモデル」「複雑なエージェント構築に最も強力なモデル」として位置づけられています。
AWSのAmazon Bedrockでも利用可能となっています。
今回は、AI駆動の開発支援ツールのAmazon Q Developerを用いて、Claude Sonnet 4.5(最新モデル)とClaude Sonnet 4.0(Amazon Q Developerで選択できる4.5以外では最新のモデル)の2つに、同じAWS Summit Japan 2025 の生成AIエージェントハッカソン課題を与えて、実際にプロダクト開発対決をさせてみました。
⚠️ 重要な前提
この記事は1回の試行結果を記録したものです。
AIは同じプロンプトでも毎回異なる出力をします。特に今回のように「自由にテーマを決めて開発する」という課題では、最初のテーマ選択によって開発の方向性が大きく変わります。
- 今回の結果が両モデルの性能差を示すものではありません
- 複数回試行すれば異なる結果になる可能性が高いです
- あくまで「こういうケースもあった」という一例としてお読みください
ハッカソンの審査基準
AWS Summit Japan 2025 の生成AIエージェントハッカソンのテーマは、「使いたおして『○○』を実現するAIエージェント爆誕祭」 でした。
従来の「AIをどう活用するか」という問いから一歩進んで、「AIエージェントを限界まで使い倒すことで、人は何を実現したいのか」という本質的な問いに向き合うことがテーマでした。
以下の5つの観点で審査が行われました:
- 有用性
- ユースケースの明確さ
- アプリケーションの品質
- 創造性
- AIエージェントの使い倒し度
最優秀賞の審査員コメント:
- 「本物の製品のようで驚いた」
- 「完成度が高い!1ヶ月で作ったと思えないUIの完成度」
つまり、実際に動作する完成度の高いアプリケーションが評価されています。
実験の設定
両モデルに以下旨の同じ指示を与えました:
「このAWS Summit Japan 2025 の生成AIエージェントハッカソンの開催報告ブログを読んで内容を理解してください。あなたもハッカソンに参加して開発してください。」
評価方法: 両モデルが「完成した」と報告した時点で開発を終了し、その状態で評価しました。
それぞれが作ったアプリ
Claude Sonnet 4.5が作った「CurioBot」
テーマ: 知的好奇心の探求
トピックを入力すると、AIが5つの探求方向を提案。クリックするとさらに深掘りできる。

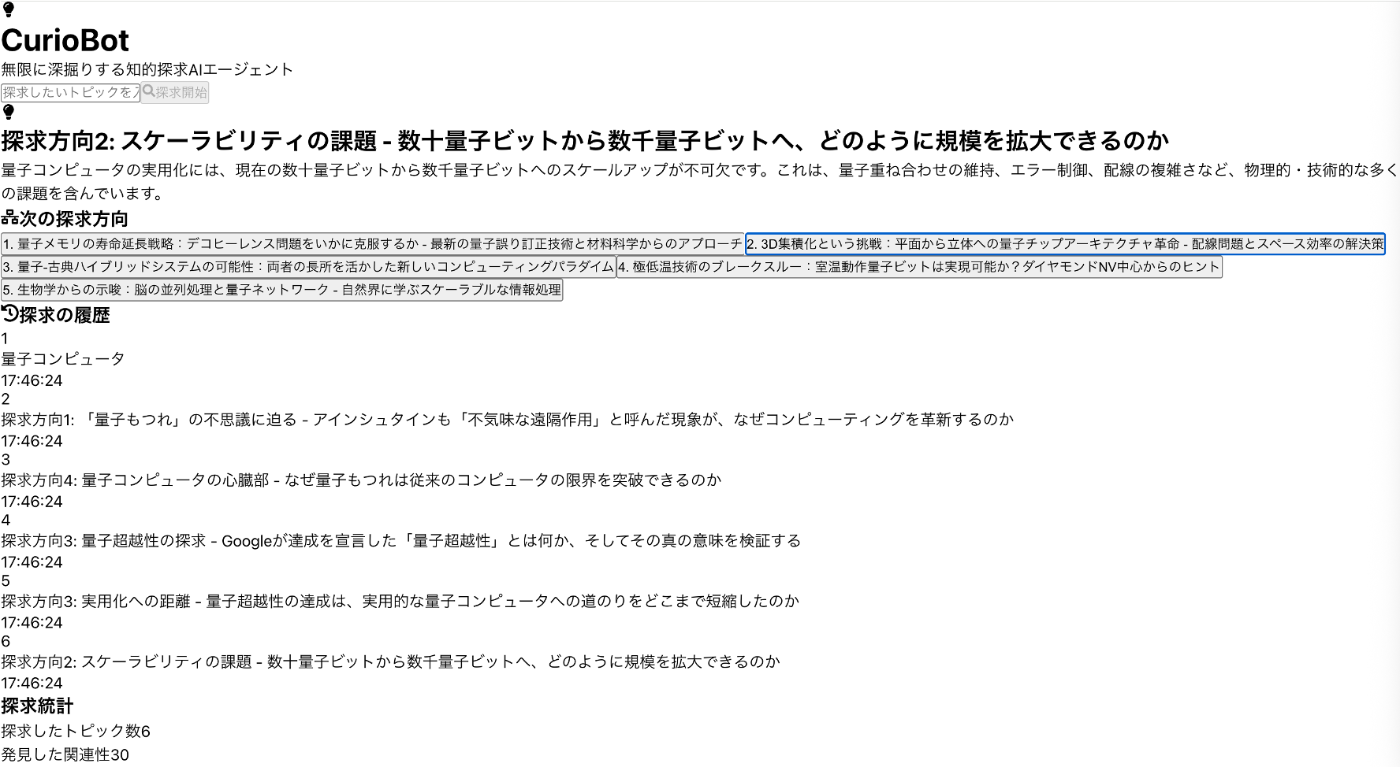
※アーキテクチャ図はAIが構築後に自分で作成したものです
※実際のアプリ動作の様子については本ブログの一番下のほうにある動画をご参照ください。
動作状況: ✅ 完全に動作
実際に使ってみた例:
入力: "量子コンピュータ"
↓
AIの提案:
1. 量子もつれの原理と応用
2. 暗号技術への影響
3. 量子supremacyへの道
4. 量子エラー訂正の挑戦
5. 宇宙の謎を解く鍵 ← 意外な関連性
↓
クリックでさらに深掘り...
サーバレス構成でコスト効率良くAmazon Bedrockと連携してAI深掘りを実現させています。
Claude Sonnet 4.0が作った「StudyMax AI」
テーマ: 学習効率最大化
個人の学習パターンを分析し、最適な学習計画を提案。

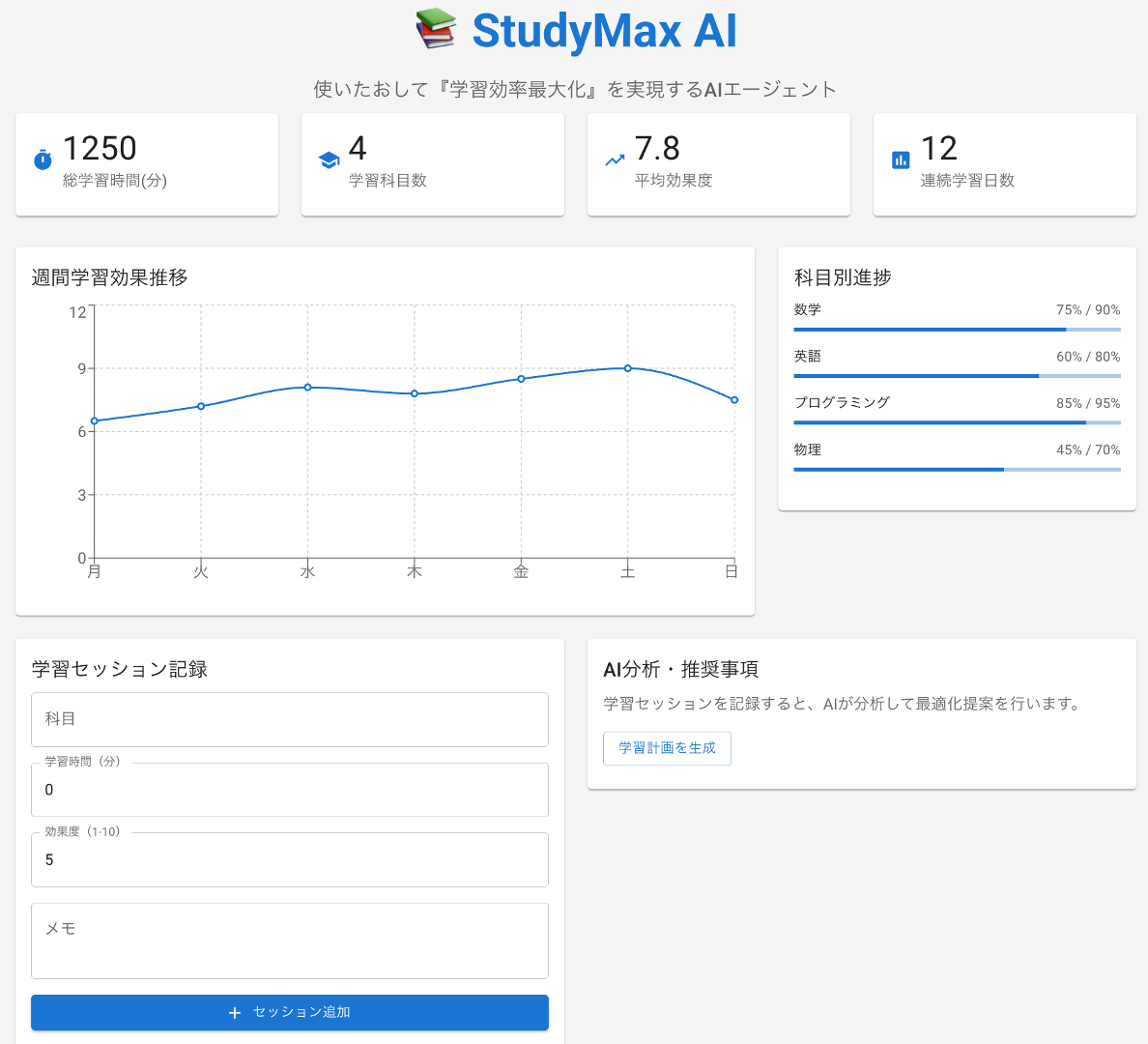
※アーキテクチャ図はAIが構築後に自分で作成したものです
※実際のアプリ動作の様子については本ブログの一番下のほうにある動画をご参照ください。
動作状況: ❌ 動作せず
こちらも似たようなサーバレス構成でデプロイ済みですが:
- UIは表示される
- すべてのボタンが反応しない
- 「学習セッション記録を追加」→ 無反応
- 「学習計画を生成」→ 無反応
問題の調査
なぜStudyMax AIは動かないのか?技術的に調査しました。
APIエンドポイントのテスト
curl https://gfjbbuc99a.execute-api.us-east-1.amazonaws.com/prod/analyze-learning-pattern
Response:
{
"message": "StudyMax AI API is running"
}
すべてのエンドポイントが同じレスポンスを返す。これはLambda関数がスタブ(仮実装)のままであることを示しています。
CurioBotとの比較
CurioBot(Claude Sonnet 4.5)のLambda:
def lambda_handler(event, context):
response = bedrock.invoke_model(...)
result = json.loads(response_body['content'][0]['text'])
table.put_item(Item={...})
return {
'statusCode': 200,
'body': json.dumps({
'topic': topic,
'summary': result['summary'],
'suggestions': result['suggestions']
})
}
StudyMax AI(Claude Sonnet 4.0)のLambda:
def lambda_handler(event, context):
return {
'statusCode': 200,
'body': json.dumps({
'message': 'StudyMax AI API is running'
})
}
開発プロセスの比較
Claude Sonnet 4.5のアプローチ
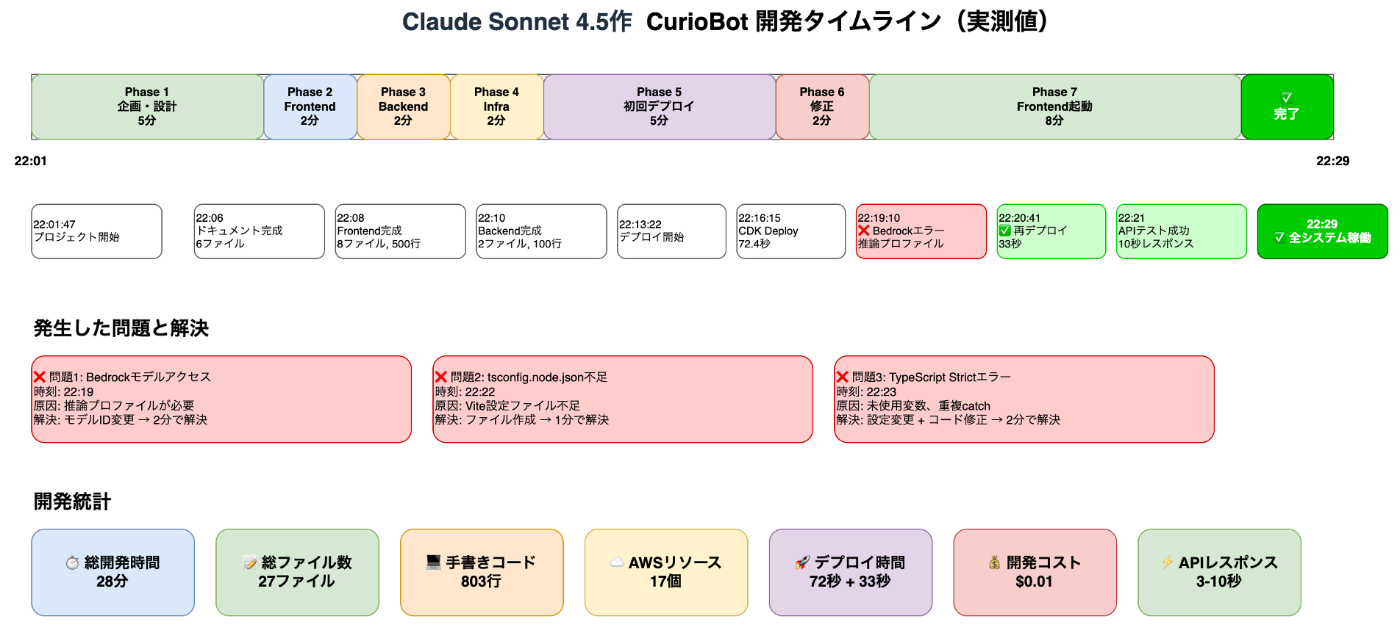
※AIが構築後に開発ログから自分で作成したものです
特徴: 「まず動かす」
- 最小限の機能で動作確認
- エラーが出たら即座に修正
- 段階的に機能追加
Claude Sonnet 4.0のアプローチ

※AIが構築後に開発ログから自分で作成したものです
特徴: より本格的な機能を最初から実装
- 認証機能(Cognito)
- CloudFront配信
- Material-UIでリッチなUI
問題点:
- 時間をかけて実装したが、最終的に動作しない
- デバッグ時間が不足
- 統合テストを実施せずに「完成」と報告
ハッカソン審査基準に基づく評価
実際のAWS Summit Japan 2025 の生成AIエージェントハッカソンの審査基準に従って、両アプリを評価してみます。
1. 有用性
CurioBot(Claude Sonnet 4.5作): ⭐⭐⭐⭐☆
- 「もっと知りたい」という普遍的なニーズに対応
- 学習、研究、趣味など幅広い用途
- 実際に使える状態
StudyMax AI(Claude Sonnet 4.0作): ⭐☆☆☆☆
- 学習効率化という明確なニーズ
- ただし、動作しないため有用性を評価できない
2. ユースケースの明確さ
CurioBot(Claude Sonnet 4.5作): ⭐⭐⭐⭐☆
- 「知的好奇心の探求」という明確なテーマ
- 誰でも理解できるシンプルなユースケース
StudyMax AI(Claude Sonnet 4.0作): ⭐⭐⭐⭐☆
- 「学習効率最大化」という明確なテーマ
- ユースケース自体は優れている
3. アプリケーションの品質
CurioBot(Claude Sonnet 4.5作): ⭐⭐⭐⭐☆
- ✅ 完全に動作する
- ✅ エラーハンドリング実装済み
- ✅ レスポンシブUI
- ✅ 履歴保存機能
- △ 認証機能なし(MVP段階)
StudyMax AI(Claude Sonnet 4.0作): ⭐☆☆☆☆
- ❌ フロントエンドが動作しない
- ❌ バックエンドAPIが未実装(スタブのみ)
- ❌ ボタンが反応しない
- ❌ 実際に使えない
- △ UIデザインは良い
実際のハッカソンでの評価基準:
「本物の製品のようで驚いた」「完成度が高い!」
→ 動作しないアプリは評価対象外になる可能性が高い
4. 創造性
CurioBot(Claude Sonnet 4.5作): ⭐⭐⭐☆☆
- 「意外な関連性」を提案する機能
- 知識の広がりを可視化
- シンプルだが新しい体験
StudyMax AI(Claude Sonnet 4.0作): ⭐⭐⭐⭐☆
- 個人最適化という先進的なアプローチ
- マルチモーダル対応の設計
- ただし、実装が完成していない
5. AIエージェントの使い倒し度
CurioBot(Claude Sonnet 4.5作): ⭐⭐⭐⭐☆
- ✅ マルチステップ推論(トピック分析→提案生成)
- ✅ コンテキスト保持(履歴を考慮)
- ✅ 創造的発見(意外な関連性)
- ✅ 実際に動作して確認できる
StudyMax AI(Claude Sonnet 4.5作): ⭐☆☆☆☆
- 学習パターン分析の設計
- 個人最適化の構想
- ただし、実際に動作しないため評価不能
総合評価
| 項目 | Claude Sonnet 4.5 | Claude Sonnet 4.0 |
|---|---|---|
| 開発時間 | 28分 | 50分 |
| 総コード行数 | 803行 | 883行 |
| 動作状況 | ✅ 完全動作 | ❌ 動作せず |
| 総合評価 | ⭐⭐⭐⭐☆ | ⭐⭐☆☆☆ |
| ハッカソン予想 | 予選通過〜決勝進出? | 予選落ち確実 |
学んだこと
1. 「動くもの」の重要性
どんなに野心的な設計でも、動かなければ評価されない。
Claude Sonnet 4.0は50分かけて多機能なアプリを実装しましたが、最終的に動作しませんでした。一方、Claude Sonnet 4.5は28分でシンプルなアプリを作り、確実に動作させました。
2. MVP(Minimum Viable Product)の価値
Claude Sonnet 4.5のアプローチは、スタートアップでよく使われるMVP思考そのものでした:
- 最小限の機能で動作確認
- ユーザーフィードバックを得る
- 必要な機能を後から追加
3. 複雑さはリスク
認証、CDN、フレームワークなど、多くの要素を組み合わせると、それだけ失敗のリスクが高まります。
動画
今回の試行を動画にまとめました。本ブログには載せなかった、Amazon Q DeveloperでのClaude Sonnet 4.5と4.0のコーディング競争状況の様子や、アプリ実行時の様子を含めています。動画中のスライドや自動音声は、Claude Sonnet 4.5がこのブログ記事を参考にして作成してくれています。
まとめ
今回の結果(1回の試行)
- Claude Sonnet 4.5: 28分、シンプル、完全動作
- Claude Sonnet 4.0: 50分、複雑、動作せず
今回の実験では、ハッカソンの基準においてCurioBot(Claude Sonnet 4.5作)の方が圧倒的に高く評価されるという結果になりました。
この記事が、AIを活用した開発の可能性と課題を考えるきっかけになれば幸いです。
「動くものを作る」という基本の重要性を、改めて認識させられる実験でした。
あらためて、重要な注意点
- これは1回の試行結果です
- 異なるテーマや指示では結果が変わる可能性があります
- モデルの優劣を示すものではありません
Views: 0

{kind=link}