

この記事では、ミニPC1台を使って Kubernetes 環境を構築するまでの流れを、数回に分けてまとめていきます。
第1回となる今回は、Kubernetes とは何か、なぜ使われるのか、そして Kubernetes の基本的なコンポーネントについて整理していきます。
環境構築手順は次回以降に扱います。
また、この記事は以下を目的として書いています。もし間違ったことを言っていればぜひご指摘ください!
- 自分自身の Kubernetes スキル整理
- アウトプットを通じた理解の定着
この記事を執筆するにあたり、 Kubernetes の全体像を把握する上でとても参考になった書籍として、以下の本を挙げさせていただきます。
📘 『Kubernetes完全ガイド(青山 真也 様)』
Kubernetes の機能や仕組みについて、非常に丁寧に網羅されており、Kubernetes の学習において大変参考になりました(ページ数は600ページ以上に及びます!!!)。
本記事でも、当該書籍で得た知識や構成をかなり参考にしています。
これから Kubernetes を学ぶ方には、ぜひ一読をおすすめします!!!
この本には値段以上の価値があります!!!
なお、本記事では、当該書籍で得た知識や構成を参考にしつつ、一部は自分でも調査を行い、自分の言葉で表現することを心がけています。
ただ、それでも万が一、記載内容が書籍の表現と酷似していると感じられる箇所がありましたら、ご指摘いただけますと幸いです。
真摯に対応し、必要に応じて修正いたします。
Kubernetes(クバネティス、またはクーバネティス。略して「K8s」)は、コンテナ化されたアプリケーションをデプロイしたり、スケールさせたりといった管理作業を自動化するためのオープンソースプラットフォームです。
もともとはGoogle社内で使われていた「Borg」というコンテナ管理システムの経験をもとに、オープンソースとして作られました。
2014年に公開され、2015年にバージョン1.0へ到達したタイミングで、Linux Foundation 傘下の Cloud Native Computing Foundation(CNCF)に移管されています。
現在は CNCF を中心に、多くの開発者・エンドユーザー・クラウドベンダーたちによってコミュニティ開発が進められています。
ちなみに、CNCF では Kubernetes 以外にもさまざまなオープンソースプロジェクトをホストしており(containerd、Fluentd、Prometheus など)、各プロジェクトには成熟度が設定されています。
成熟度は以下の3段階です。
- Graduated(成熟済み)
- Incubating(育成中)
- Sandbox(実験中)
Kubernetes は最上位の「Graduated」に認定されています。
これは単にソフトウェアとして安定しているだけでなく、開発体制や運営プロセスも高い水準にあると CNCF に評価された証です。
(※Graduated は直訳すると「卒業」ですが、プロジェクトがCNCFから離れるわけではありません。)
いまや Kubernetes はコンテナオーケストレーション分野のデファクトスタンダードとなっています。
この普及の大きな後押しとなったのが、各クラウドベンダーによるマネージド Kubernetes サービスの展開です。
2014年、Google Cloud Platform が「Google Kubernetes Engine(GKE)」をリリースしたのを皮切りに、2017年にはMicrosoft Azure が「Azure Kubernetes Service(AKS)」、AWS が「Elastic Kubernetes Service(EKS)」を提供開始しています。
コンテナ技術(たとえば Docker )が普及したことで、「アプリケーションをコンテナ化すれば、どこでも手軽に動かせる」というメリットが広く知られるようになりました。
しかし、実際にコンテナをプロダクション環境(本番運用)で使おうとすると、次のような課題に直面します。
- 複数ノードにコンテナを分散して配置する
- コンテナのスケジューリング(どのノードにコンテナを配置するかを決める)
- ローリングアップデート(無停止でアプリを更新する)
- スケーリング/オートスケーリング
- コンテナのヘルスチェックと再起動(セルフヒーリング)
- サービスディスカバリ(サービス同士の場所を探す仕組み)
- ロードバランシング(リクエストを分散させる)
- コンテナに関するデータ管理
- ログ収集・監視
- Infrastructure as Code
- その他エコシステムとの連携や拡張
たとえば、Docker 単体だと1台のホスト上でコンテナを動かすのは得意ですが、複数のサーバーにまたがってコンテナをスケールさせたり、障害発生時に自動でリカバリしたりといった大規模運用は苦手です。
そこで登場するのが Kubernetes です。
Kubernetes は、こうした複雑な運用を自動化するための仕組みを数多く持っています。
次章では、Kubernetes を使うことでどんなことができるのか、具体的に見ていきます。
4-1. 宣言的なコードによるインフラ管理
Kubernetes では、YAML や JSON 形式で記述した「宣言的なコード」(これをマニフェストと呼びます)によって、コンテナやクラスタ内のリソースを管理します。
これにより、コードによるインフラ管理(Infrastructure as Code, IaC) が実現できます。
たとえば、以下のようなマニフェストを適用するだけで、アプリケーションのデプロイやスケールが簡単に行えます。
sample-deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-deployment
spec:
replicas: 3
selector:
matchLabels:
app: example
template:
metadata:
labels:
app: example
spec:
containers:
- name: example-container
image: nginx:latest
ports:
- containerPort: 80
このように、「どう動かすか」ではなく「どうなっていてほしいか」 を宣言するだけで、Kubernetes が状態を維持してくれます。
(上のコード例では、「コンテナが常に3つ起動された状態にしてほしい」と宣言しているイメージです)
さらに、コードでリソースを記述することで冪等性も担保されます。
つまり、別の Kubernetes 環境でも、同じマニフェストを適用すれば同じ状態が再現されます。
4-2. スケーリングとオートスケーリング
Kubernetes では、複数のサーバー(ノード)をまとめてクラスタとして管理します。
このクラスタ上に、コンテナイメージを元にアプリケーションをデプロイしますが、同じコンテナを複数(レプリカ)同時に起動することもできます。
(例:Webサーバーのコンテナを3台起動)
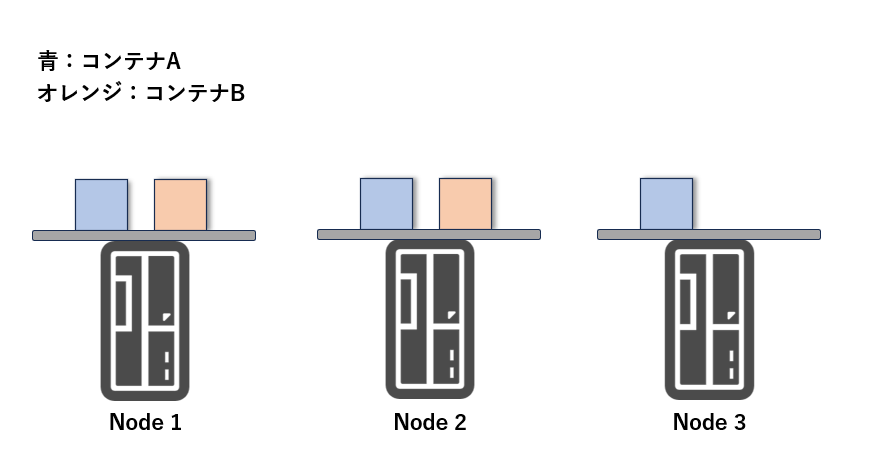
コンテナを複数台稼働させることで、負荷分散によってリクエストを各コンテナに分散させたり、1台が落ちても他の台が稼働し続けることで耐障害性を確保できます。
さらに、Kubernetes は 負荷に応じてコンテナ数を自動的に増減(オートスケーリング) することも可能です。
アクセスが増えたときにはコンテナを スケールアウト し、少ないときには スケールイン することで、効率よくリソースを活用できます。
・アクセス増加時にコンテナをスケールアウトするイメージ図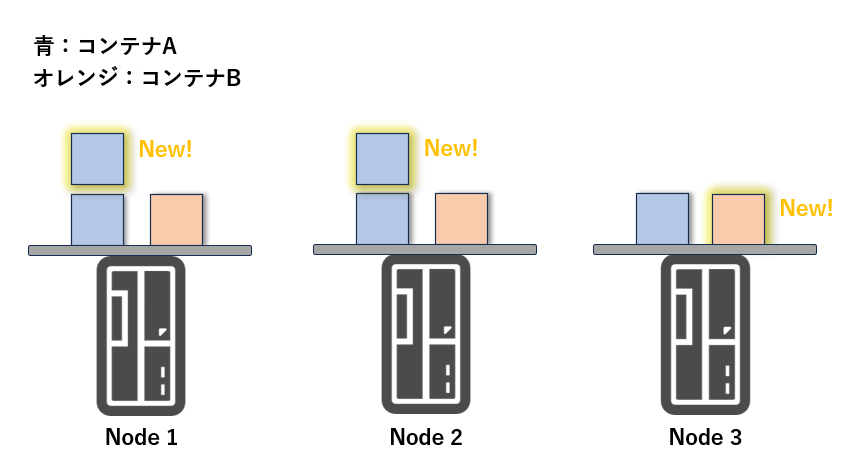
4-3. スケジューリングによる適切な配置
コンテナを Kubernetes ノードに配置する際、どのノードに配置するかを決めるステップを「スケジューリング」と呼びます。
このスケジューリングでは、アプリケーションのワークロードの特徴やノードの性能を考慮し、コンテナを各ノードに割り当てます。
例えば、以下のように配置を制御できます。
- 「ディスクI/Oが多い」コンテナ → SSD搭載ノードに配置
- 「CPUを多く使う」コンテナ → 高性能CPUノードに配置
また、AWS や GCP などのマネージド Kubernetes では、複数のアベイラビリティゾーンにコンテナを分散配置することも可能です。
・スケジューリングのイメージ図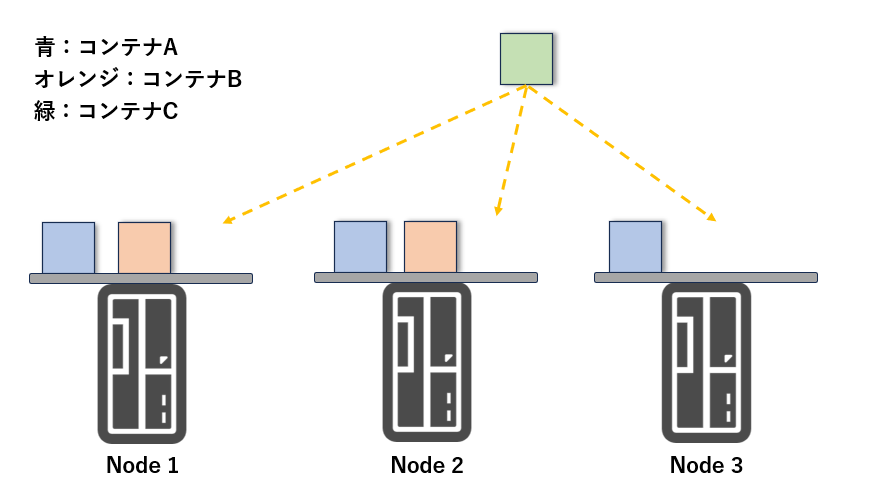
スケジューリングの仕組み
Kubernetes では、ノードにラベルを付け、これをもとにスケジューリングのルール(ポリシー)を設定します。
例:
-
disktype=ssdラベルのノードにだけコンテナを配置
このルールのことを Affinity(アフィニティ)と呼び、逆に「この条件には合致しないノードに配置したい」場合はAnti-Affinity と呼びます。
スケジューリングのプロセス
Kubernetes のスケジューリングは、以下の2ステップで行われます。
-
フィルタリング
必要なリソースやラベル条件に合致するノードを絞り込みます。
(例:十分なCPUメモリがあるか、disktype=ssdのラベルがあるか) -
スコアリング
絞り込んだノードに順位付けを行い、最適なノードを決定します。
(例:Podをできるだけ複数ノードに分散させる、コンテナイメージがすでにあるノードを優先)
4-4. ローリングアップデートとロールバック
Kubernetes では、Pod の更新時にサービスを止めずに少しずつ更新をかけることができます。
この仕組みを「ローリングアップデート」と呼びます。
例えば、新しいバージョンのアプリケーションをデプロイする際に、現在稼働している Pod を一部ずつ順番に新バージョンに入れ替えていくイメージです。
これにより、サービスを稼働させたまま、ユーザー影響を最小限にしつつアップデートが可能になります。
補足
一括で一気に Pod を入れ替える「 Recreate 方式」も選べますが、Kubernetes の標準ではローリングアップデートが推奨されています。
・ローリングアップデートのイメージ図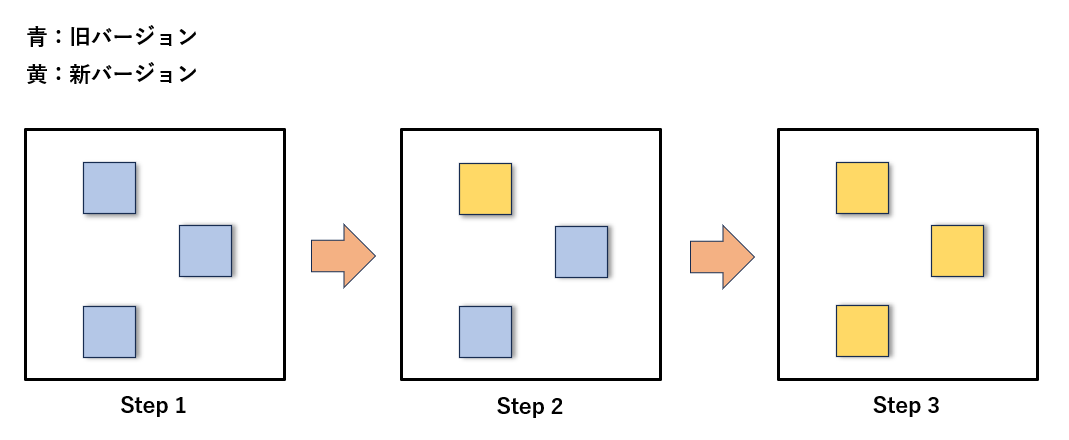
さらに、Kubernetes にはロールバック機能があり、もし新しいバージョンに問題があった場合でも、以前の安定したバージョンにすぐ戻すことができます。
これにより、安全性の高いリリース運用が可能です。
・ロールバックのイメージ図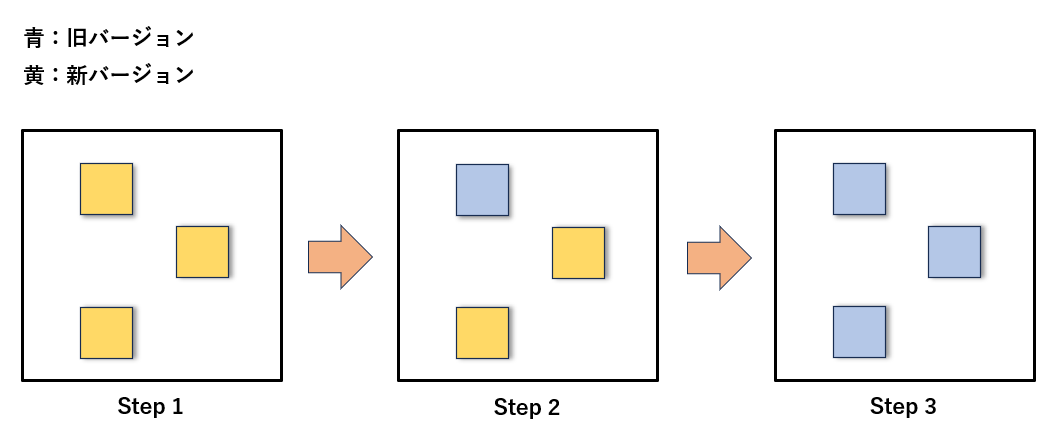
4-5. リソース管理と制御
Kubernetes では、コンテナをノードに配置する際、ノードのCPUやメモリの空き状況を考慮して、適切なノードにコンテナをスケジューリングします。
そのため、ユーザー側でどのノードにコンテナを配置するかを細かく管理する必要はなく、「どれくらいのリソースを使うか」だけを宣言する 形でシステムを運用できます。
具体的には、以下のようなリソース制御が可能です。
- Requests: このコンテナが 最低限必要 とするCPUやメモリ量
- Limits: このコンテナが 使用できる最大 のCPUやメモリ量
リソース制限はPod内の各コンテナ部分の定義に記載します。spec.containers[].resources 内に、Requests および Limits としてリソース量を定義します。
CPUは基本的にコア数での指定になりますが、1 vCPU(仮想CPU。コア数に相当)を 1000 millicores(m)とする単位で指定します。
例えば、1コア相当のCPUリソースを指定する場合は 1000m と記載します。
sample-pod.yml
apiVersion: v1
kind: Pod
metadata:
name: sample-pod
spec:
containers:
- name: sample-container
image: nginx:latest
resources:
requests:
cpu: "250m" # 最低限必要なCPU (0.25コア)
memory: "256Mi" # 最低限必要なメモリ (256MiB)
limits:
cpu: "500m" # 最大で使用できるCPU (0.5コア)
memory: "512Mi" # 最大で使用できるメモリ (512MiB)
スケジューリング時の動作は以下のようになります。
- ノードに Requestsで指定された分の空きリソース がない場合、そのノードにはコンテナは配置されません。
- Limits は、あくまでコンテナが 実行時に使用できる上限 を制限するものです。ノードへのスケジューリング時には、Requestsの値が重視されます。
この機能を活用することで、各コンテナにリソースを適切に分配し、他のコンテナへの影響を抑えつつ安定稼働 させることができます。
さらに、ノードのリソースが不足した場合は、新たにノードを追加してスケールアウトすることも可能です。
4-6. セルフヒーリングによる自動復旧
Kubernetes では、コンテナのプロセス監視を行い、障害が発生した場合に自動で復旧(セルフヒーリング)を実行します。
具体的には、コンテナのプロセスが停止したり、応答がない場合に障害と判断し、コンテナを再起動 したり、別のノードに再スケジューリング します。
また、ノードに障害が発生し、そこで動作していたコンテナが停止した場合も、Kubernetes はそのコンテナを 別の正常なノードに再配置 することで、サービスの継続を図ります。
・セルフヒーリングのイメージ図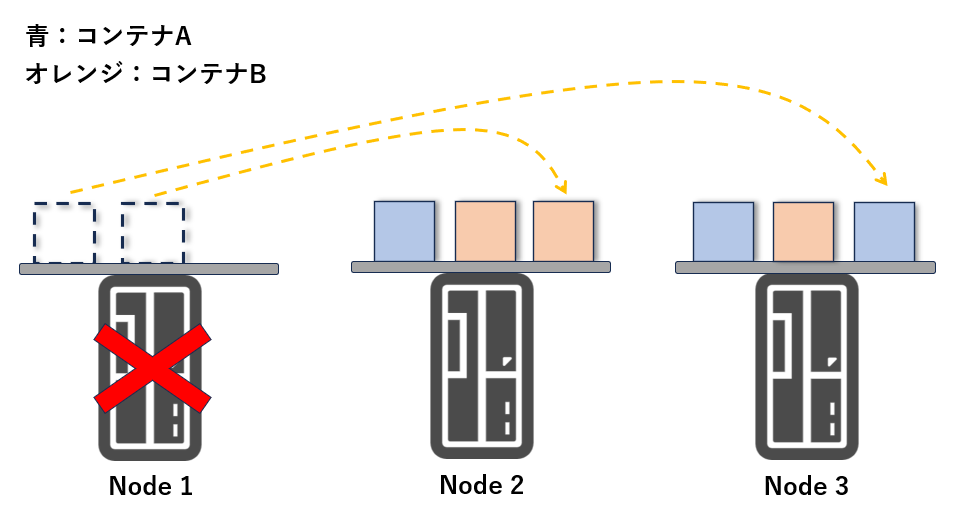
セルフヒーリングの実行条件は、単にプロセスの停止だけでなく、以下のような ヘルスチェック (Liveness Probe / Readiness Probe / Startup Probe) に基づいて判定することができます。
- HTTP での応答確認
- 指定したエンドポイントに HTTP GET リクエストを実行し、ステータスコードが 200〜399 でなければ失敗と判断
- TCP での応答確認
- TCP セッションが確立できなければ失敗と判断
- コマンド実行による状態チェック
- 指定したコマンドを実行し、終了コードが0でなければ失敗と判断
これにより、より細かくアプリケーションの状態を監視し、自動復旧を行うことができます。
4-7. ロードバランシング
複数台で構成されたアプリケーションを、あたかも1つのサービスとしてユーザーに提供するには、複数のインスタンスを束ねて1つの接続先(エンドポイント)として公開する必要があります。
従来の仮想マシンベースの構成では、ロードバランサーを用意し、リクエストを複数の仮想マシンに分配するよう設計します。そして、ロードバランサー自体のアドレスをユーザーに公開し、それをエンドポイントとして利用します。
Kubernetes でも同様に、Service や Ingress といったリソースを用いてロードバランシングを実現できます。Service を定義することで、特定の条件に合致するコンテナ群(Pod)を束ね、自動でルーティングされるエンドポイントを提供します。
・ロードバランシングのイメージ図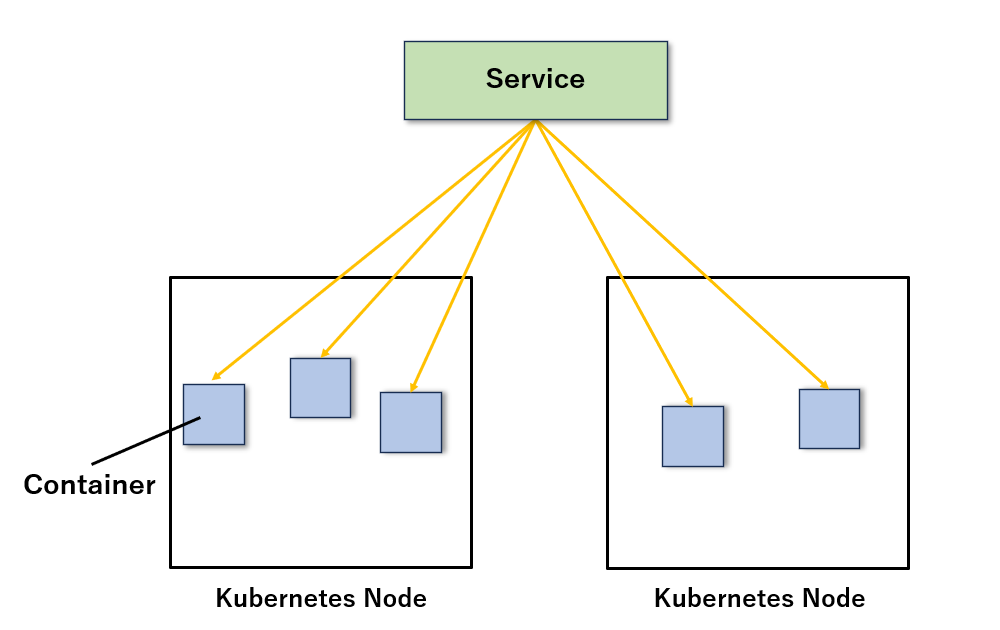
また、Kubernetes のロードバランシングには以下のような自動化された利点があります。
- コンテナがスケールアウト/スケールインされた場合、Service に自動的に追加・削除される
- コンテナに障害が発生した場合は、ヘルスチェックに基づき自動でルーティング対象から除外される
- ローリングアップデート時には、更新対象のコンテナを事前にルーティング対象から外し、更新完了後に再接続する
このように、Kubernetes ではロードバランサーとしての役割に加え、可用性確保や運用負荷軽減に必要なオペレーションを自動で実行してくれます。
そのため、Kubernetesにエンドポイント管理を任せることで、システムの冗長性と保守性を高いレベルで両立できます。
4-8. サービスディスカバリ
サービスディスカバリとは、特定の条件に合致するメンバーを列挙したり、名前からエンドポイント(通信先のIPやポート)を解決する機能です。
Kubernetes においては、Service に属する Pod の一覧取得 や、Service 名からアクセス先のIPアドレスやポートを解決すること を指します。
Kubernetes では、機能ごとに小規模なアプリケーションを分割し、連携させて構築する「マイクロサービスアーキテクチャ」が一般的です。
このような構成では、各サービス(コンテナ)が互いに通信する必要があるため、サービス間の参照方法(=サービスディスカバリ)が重要になります。
Kubernetes では、Service というリソースを通じて、各 Pod にアクセス可能な名前解決とルーティングを提供します。
Service によるディスカバリがあることで、各マイクロサービスは他の Service 名を使ってアクセスすることが可能になり、Pod のIPが変わっても接続先が安定する仕組みになります。
Kubernetes におけるサービスディスカバリの方法
Kubernetes では、以下の3つの方法でサービスディスカバリが実現されます。
- 環境変数によるディスカバリ
- DNS Aレコードによるディスカバリ
- DNS SRVレコードによるディスカバリ
環境変数を利用したサービスディスカバリ
Service を作成すると、その情報が自動的に Pod 内の環境変数として注入されます。
これにより、Pod 内のアプリケーションはその環境変数を参照して、接続先のIPアドレスやポート番号を取得できます。
ただし、以下のような注意点があります
- Pod の起動時点で存在していた Service のみが環境変数に反映されます。
- Pod 起動後に作成されたServiceや、既存 Service の変更・削除は環境変数に自動反映されません。
# Pod内の環境変数を確認し、特定のServiceに関連するものを表示
kubectl exec -it my-pod -- env | grep -i my_service
環境変数を使った接続は、Service の変更が伴うような動的な環境においては信頼性が低いため、後述のDNSを用いた接続方法が推奨されています。
DNS Aレコードを使用したサービスディスカバリ
Service で払い出されたエンドポイントにアクセスする際、上記で説明したIPアドレスを直接指定する方法がありますが、Kubernetes では Service 名に対応するDNS名が内部DNSに自動登録されるため、DNS名を使った接続が推奨されます。
Service リソースを作成すると、Kubernetes の内部DNSに以下のような形式で Aレコード(IPアドレスを返すDNSレコード) が登録されます。
たとえば、my-service という名前の Service を default ネームスペースに作成した場合、以下のDNS名でアクセス可能になります。
my-service.default.svc.cluster.local
このDNS名は、アプリケーション側から見ると 固定の接続先 として利用できるため、Service の再作成などでClusterIP が変わった場合でも、DNS名を通して常に最新のIPに接続できます。
DNSでの接続が推奨される理由
- Service の再作成時に、内部IP(ClusterIP)が変更されます 。
- IPアドレスを直接指定している場合は、その都度アプリケーションの設定ファイルを変更する必要があります。
- 一方、DNS名で接続していれば、Service 名を変えない限り常に同じ名前でアクセスできるため、設定ファイルを変更する必要がありません。
このように、DNSを用いたサービスディスカバリは、動的な構成変更に強く、マイクロサービス間の連携において非常に有効です。
Kubernetes のポータビリティを保つ上でも、極力 Service 名による名前解決を行うようにするのがよいです。
DNS SRVレコードを使用したサービスディスカバリ
Kubernetes の Service では、Aレコード以外にも SRVレコード を使って、ポート情報を含むサービスのエンドポイントを取得することができます。
SRVレコードは、DNSのレコードタイプの1つで、特定のサービス名とプロトコルに基づき、対応するホスト名とポート番号の情報を返す仕組みです。
Kubernetes においては、Service の spec.ports[].name に設定されたポート名と、spec.ports[].protocol に設定された プロトコル(通常は TCP) をもとに、SRVレコードが内部DNSに自動で登録されます。
・SRVレコードの形式
[_ServiceのPort名].[_Protocol].[Service名].[Namespace名].svc.cluster.local
たとえば、以下のような Service があるとします。
sample-clusterip.yaml
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: ClusterIP
ports:
- name: "http-port"
protocol: "TCP"
port: 8080
targetPort: 80
selector:
app: my-app
この場合、登録されるSRVレコードは以下のようになります。
_http-port._tcp.my-service.default.svc.cluster.local
このSRVレコードをクエリすることで、対象エンドポイントのIPアドレスとポート番号の情報を取得できます。
Aレコードではポート番号の情報が取得できないため、ポート番号も含めて名前解決したい場合にSRVレコードが有効です。
4.9 データの管理
Kubernetes では、クラスターの構成情報や状態を保存するために、etcd と呼ばれる分散キーバリューストア(KVS)をバックエンドとして使用しています。
etcd には、コンテナや Service、ConfigMap、Secret など、Kubernetes リソースに関するすべての情報が保存されます。
・データ保存のイメージ図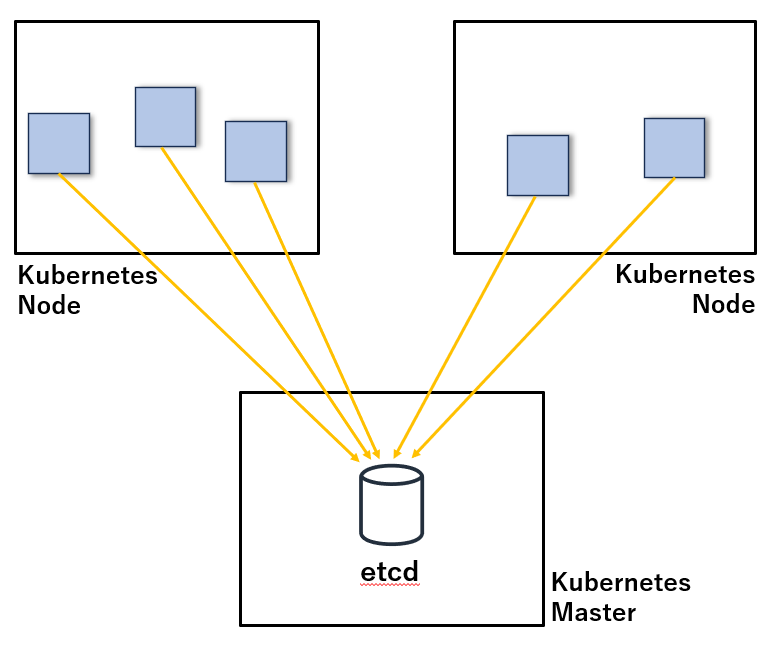
5.1 Kubernetesのアーキテクチャ
Kubernetes クラスターは、大きく分けて「Control Plane(制御プレーン、Master Node とも呼ぶ)」と「Node(ワーカーノード)」に分かれます。
これらのコンポーネントは、kube-apiserverを中心に連携しながら、クラスターの運用を支えています。
それぞれのコンポーネントについて、以下に記載していきます。
5.2 etcd
etcd は、CoreOS 社が主体となって開発している OSS の分散 Key-ValueStore(KVS)です。
Kubernetes においてはデータストアとしての役割を担っており、Kubernetes クラスターに登録される全ての情報はetcdに保存されます。
etcd は分散システムに強い設計となっており、複数台のノードでクラスターを構成することで、冗長性と可用性を確保できます。
このクラスターでは、常に1台のリーダーノードが存在し、万が一リーダーノードが停止した場合でも、残りのノードの中から新しいリーダーが自動で選出され、サービスは継続されます。
一方、etcd を1台構成で運用している場合は、リーダーが停止するとサービス継続が困難になり、データ損失のリスクも高まるため、単一障害点(SPOF:Single Point of Failure)となります。
そのため、本番環境では最低でも3台構成のetcdクラスターが推奨されます。
また、障害対策として定期的に etcd のスナップショット(バックアップ)を取得しておくことも重要です。
スナップショットがあれば、etcd の破損や全ノードの停止といった深刻な障害からの復旧が可能になります。
5.3 kube-apiserver
kube-apiserver は、Kubernetes クラスターの中核を担うコンポーネントで、Kubernetes API を提供します。
ユーザーや他のコンポーネントは、kube-apiserver を通じて Kubernetes クラスターとやり取りします。
(kube-apiserver とのやり取りはHTTPS通信で行われます)
たとえば、Kubernetes のCLIツールである kubectl を使って Deployment や Service などのリソースを作成・変更・削除する際、kubectl はその操作内容を kube-apiserver に HTTP リクエストとして送信します。
また、kube-scheduler や kube-controller-manager、kubelet などの他のコンポーネントも、リソースの状態確認や操作を行う際に kube-apiserver を通じてアクセスします。
高可用性対応
本番環境では、kube-apiserver を複数台構成し、クライアントからのリクエストはロードバランサ経由で振り分けることで、可用性を確保します。
この構成により、1台の kube-apiserver が障害を起こしても、他のインスタンスがリクエストを処理し続けることが可能です。
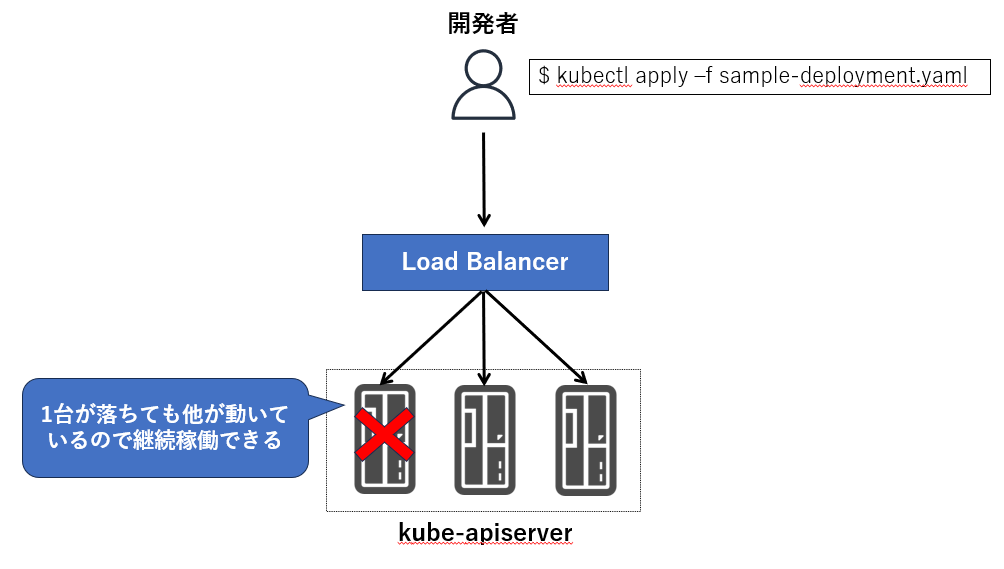
etcd との関係
リソース操作のリクエストが kube-apiserver に送信されると、その内容は最終的に etcd に永続化されます。
このやり取りも kube-apiserver が仲介しており、Kubernetes クラスタの状態管理における中心的な役割を担っています。

5.4 kube-scheduler
kube-scheduler は、Kubernetes における Pod のスケジューリング(どのノードに配置するかの判断) を担うコンポーネントです。
Kubernetes クラスタ内で ノードに割り当てられていない Pod(Pending 状態の Pod) を検出すると、その Pod をどのノードにスケジュールするかを決定します。
スケジューリング判断には、以下のような複数の要素が考慮されます。
- 各ノードの CPU やメモリなどのリソース使用状況
- Pod に指定されたリソース要求(requests/limits)
- Pod に設定されたスケジューリング条件(特定のラベルを持つノードに配置、等)
適切なノードが決まると、kube-scheduler は kube-apiserver に対してリクエストを送り、
対象 Pod のマニフェスト内の spec.nodeName に スケジューリング先ノードの名前 を書き込みます(=etcd に永続化される)。
補足
kube-scheduler が行うのは 「どこに配置するかを決める」 までです。
実際にそのノード上で Pod を起動させるのは、そのノード上で稼働している kubelet の役割です。
5.5 kube-controller-manager
kube-controller-manager は、Kubernetes における各種コントローラーを実行するコンポーネントです。
Kubernetes における「コントローラー」とは、クラスター内の状態を継続的に監視し、マニフェストで定義された“望ましい状態”に保つための制御ループ(control loop)です。
たとえば、Deployment で指定されたレプリカ数と実際に動作している Pod の数が一致しない場合、コントローラーが差分を検知し、不足していれば新たに Pod を作成するなどして調整を行います。
コントローラーには Deployment コントローラーや、ReplicaSet コントローラー、Job コントローラーなど各リソースに対応したコントローラーが多数あり、これらは一つの実行ファイルにまとめてコンパイルされ、単一のプロセスとして動作します。
また、kube-controller-manager は高可用性構成を取ることが可能で、複数台構成による冗長化もサポートされています。
5.6 kubelet
kubelet は、各 Kubernetes ノード上で動作するエージェントであり、Pod の起動・管理を担うコンポーネントです。
kube-apiserver によって Pod の情報が etcd に登録され、kube-scheduler によって配置先ノードが決定されると、対象ノード上の kubelet がその情報を検知します。
そして、指定された Pod を起動するために、コンテナランタイムに対して命令を送り、自身のノード上にコンテナを起動します。
コンテナランタイムは、高レイヤランタイム(例: containerd、CRI-O)と低レイヤランタイム(例: runc)で構成されており、kubelet は高レイヤランタイムとやり取りを行います。
kubelet と高レイヤコンテナランタイムの通信は、CRI(Container Runtime Interface) という標準インターフェースに基づいて行われます。CRI に準拠したランタイムであれば、Kubernetes において利用可能です。
また、高レイヤランタイムと低レイヤランタイムの通信は、OCI(Open Container Initiative) の仕様に準拠しています。
以前は、Docker が主なコンテナランタイムとして使われていましたが、Docker 自体は CRI に準拠していなかったため、Kubernetes では dockershim という中間レイヤーを用いて kubelet と Docker をつないでいました。
しかし、Kubernetes v1.24 で dockershim が廃止され、Docker は公式にサポート対象外となりました。
現在は containerd や CRI-O のような CRI 対応のコンテナランタイムが主流です。
この辺りの経緯については、以下の公式ブログも参考になりますので、興味があればぜひ読んでみてください。
5.7 kube-proxy
kube-proxy は、各 Kubernetes ノード上で動作するネットワークプロキシのコンポーネントであり、Service リソースを介した通信を適切な Pod にルーティングする役割を担います。
Service リソースは Kubernetes 内での Pod 間通信や外部からのアクセスをPodに転送するための仕組みですが、kube-proxy はその裏側で、実際にどの Pod にトラフィックを流すか という転送処理を実現しています。
kube-proxy は、iptables や IPVS といった Linux のネットワーク機能を利用して、Kubernetes ノード上のネットワークルールを構成します。
これにより、クラスター内外から Service 宛てに届いた通信を、該当するバックエンド Pod に転送することが可能になります。
なお、kube-proxy は以下のようなモードで動作します。
- iptables モード(デフォルト):iptables を使って転送ルールを設定する。シンプルで多くの環境で使われている。
- IPVS モード:より高性能なロードバランシングが可能。大量の Service や Pod がある環境で有利。
5.8 CNI plugin
Kubernetes クラスターでは、複数のノード上で多数の Pod が動作します。
これらの Pod 同士がノードの枠を超えて通信できるようにするには、仮想的なネットワークを構築する必要があります。
このネットワークの構築と管理を担うのが CNI(Container Network Interface)Plugin です。
CNI Plugin によって、各 Pod にクラスター内で一意な IP アドレスが割り当てられ、ノードをまたいだ Pod 間通信が可能になります。
これにより、Pod はまるで同じネットワークに存在しているかのように互いに通信できます。
Kubernetesでは、Flannel や Calico 等、様々な CNI Plugin を利用することができます。
5.9 CoreDNS
CoreDNS は、Kubernetes クラスター内で 名前解決(DNS) や サービスディスカバリ を提供するコンポーネントです。
これは CNCF がホストする OSS プロジェクトの1つで、Kubernetes のクラスター DNS として稼働する柔軟かつ拡張性の高い DNS サーバーです(Go言語で実装されています)。
前章のサービスディスカバリでも触れましたが、Kubernetes では Service に対して以下のような DNS 名が自動的に割り当てられます。
Kubernetes 上の Pod は、このような DNS 名を通じて他の Service にアクセスできます。
この DNS 名の解決を担っているのが、クラスター内 DNS サーバーである CoreDNS です。
CoreDNS は、kube-apiserver と連携して Service の作成を検知し、それに対応する Aレコード(IPアドレス) を自動的に登録します。
これにより、Pod からの問い合わせに対して正しい IP アドレスを返すことができます。
なお、以前は kube-dns という別の DNS 実装が用いられていましたが、Kubernetes v1.21 以降、kubeadm による新規クラスター構築では CoreDNS が唯一のサポート対象となりました。
現在、「kube-dns」という名前は クラスター内 DNS 機能の総称 として名残的に使われることがありますが、実際に稼働しているのは CoreDNS です。
実際に、以下のコマンドを実行すると、kube-system という(コントロールプレーンに属する)Namespace 内で CoreDNS の Pod が動作していることが確認できます。
kubectl get pods -n kube-system -l k8s-app=kube-dns

ここまで、Kubernetes の持つ役割や、Kubernetes を構成する代表的なコンポーネントについて整理してきました。
この記事は、次回の「ミニPCを使った Kubernetes 構築手順」記事に向けた 事前の知識整理編 としての位置づけになります。
Kubernetes は一見複雑なシステムですが、各コンポーネントの役割や連携関係を理解しておくことで、構築や運用時の全体像がグッと見えやすくなります。
次回はいよいよ、手元のミニPCを使って Kubernetes を構築していきます。
ぜひ次回もあわせてご覧いただければと思います!
Views: 0

{kind=link}